Collection이란?
컬렉션이란 데이터들을 모아놓은 집합이다.
컬렉션 프레임워크란 컬렉션을 효율적으로 다룰 수 있는 자료구조로 구현된 클래스와 인터페이스들이다.
*자료구조란 컴퓨터 프로그램에서 데이터를 처리하기 위해 만들어진 구조를 말한다.
Collection Framework 특징
Collection Framework 구조
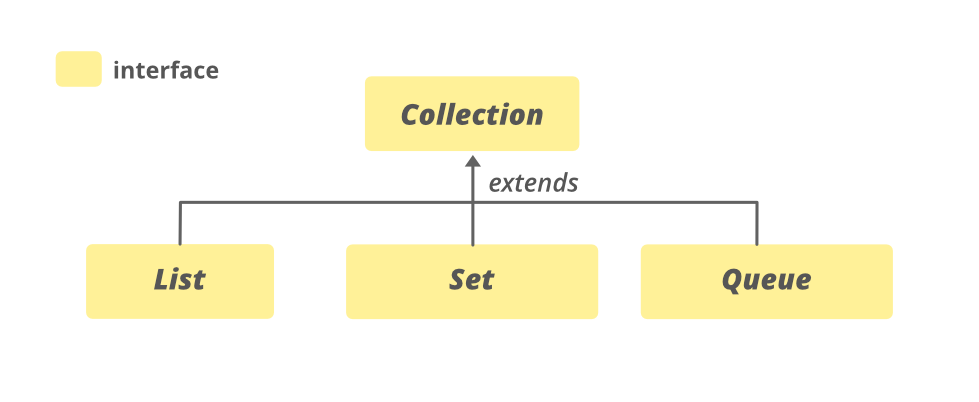
Collection Framework 는 가장 상위 인터페이스로 Collection 인터페이스가 있고 Collection 인터페이스를 상속받은 List, Set, Queue 인터페이스와 별도의 Map 인터페이스가 있다.
Collection Framework 종류
Collection Interface
java.util 패키지에 있으며 컬렉션 프레임워크의 가장 상위 인터페이스로 모든 자식 인터페이스들이 데이터들을 다루기 위해 사용하는 자료구조와 알고리즘을 제공한다.
Collection 인터페이스를 상속받은 인터페이스는 List, Set, Queue 인터페이스가 있다.
이 외에 Collection 인터페이스를 상속받지 않지만 컬렉션 인터페이스로 사용되는 Map 인터페이스가 있다.
이 글에선 List 먼저 다뤄볼 것이다.
List Interface
- 동일한 타입의 데이터들이 들어간다.
- 데이터의 저장 순서가 유지되며 데이터 중복을 허용하는 구조의 컬렉션 인터페이스이다.
List 인터페이스를 구현하는 클래스로는 ArrayList, LinkedList, Vector, Stack이 있다.
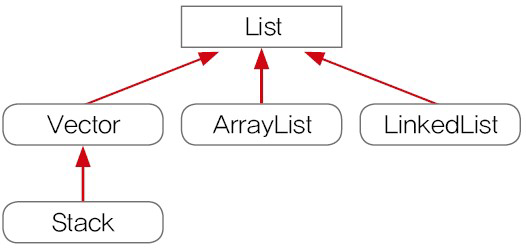
ArrayList
ArrayList는 크기 조정이 가능한 배열이다.
배열은 처음에 할당된 크기만큼만 사용할 수 있지만 ArrayList는 계속해서 요소를 추가할 수 있다. → How?
ArrayList 원리
ArrayList의 요소를 추가하는 메서드인 add() 메서드의 코드를 봐보자.
import java.util.Arrays;
//ArrayList 클래스 내부 코드 분석
public class ArrayListTest {
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length) // 요소를 add하려고 하는데 기존 만들어진 ArrayList보다 큰 경우
elementData = grow();
elementData[s] = e;
size = s + 1;
}
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity)); //새로운 배열을 만들어 복사한다.
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
@HotSpotIntrinsicCandidate
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
}ArrayList에 새로운 요소를 추가할 때 기존 ArrayList의 크기와 비교하여 만약 크다면 newCapacity 메서드를 통해 새로운 ArrayList 만들고 기존 ArrayList에 있던 요소 값들을 다 복붙하여 넣는 방식이다.
즉, ArrayList는 배열과 동일한 원리이다.
배열에서도 기존 배열보다 더 큰 배열을 만들고 싶을 때 새로운 배열을 추가하여 안에 있는 요소들을 복붙하는 방법을 사용해야한다.
이 과정을 ArrayList는 내부적으로 알아서 해줄 뿐이였다.
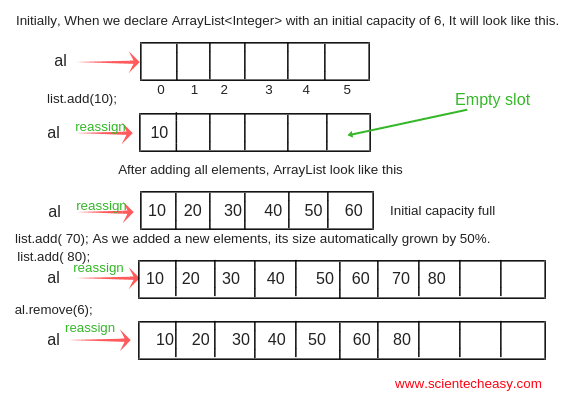
위 그림이 ArrayList의 원리를 잘 보여줘서 가져왔다.
list.add()를 통해 점점 데이터를 삽입하다가 초기 설정한 크기가 꽉 찼을 때 자동으로 크기를 1.5배 늘려 데이터를 추가한다.
Q. remove()도 동일할까?(크기를 늘릴 필요가 없는 경우에도 동일할까?
데이터가 가득 찬 상태에서 데이터 하나를 제거한다면 배열을 또 만들어서 복사를 할지 아니면 요소만 삭제되는 것인지? 제거 후 ArrayList의 크기의 변동이 있을지??
한번 확인해봤다.
import java.util.ArrayList;
public class RemoveArrayList {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
System.out.println(list.size());
for(int i=0 ; i<10 ; i++) { //ArrayList는 처음 제공되는 사이즈를 10으로 주기 때문에 10개의 요소를 넣어봤다.
list.add(i, ""+i+"");
}
System.out.println(list.size()); //size = 10
//요소 하나를 삭제
list.remove("3");
System.out.println(list.size()); //size = 9
}
}→ remove()를 시행하면 ArrayList의 크기는 삭제한 요소만큼 준다.
ArrayList의 remove() 메서드 코드를 보면 삭제하려는 요소의 인덱스를 받아 제거 후 원본 배열의 제거한 요소 인덱스의 이전 요소들과 제거한 요소의 인덱스부터 마지막 요소까지 복사하여 새로운 배열에 넣는다.
즉, 제거하는 방법도 요소를 제거 후 나머지 요소들을 복사하여 새로운 배열을 생성하여 넣는 방법이다.
remove() 메서드 분석 해보기
public class RemoveMethod {
// 1. Object로 삭제
public boolean remove(Object o) {
final Object[] es = elementData;
final int size = this.size;
int i = 0;
found: {
//Object의 값이 null인 경우
if (o == null) {
for (; i < size; i++)
if (es[i] == null)
break found;
//Object의 값이 null이 아닌 경우
} else {
for (; i < size; i++)
if (o.equals(es[i]))
break found;
}
return false;
}
// 요소와 index를 fastRemove에 넘김
fastRemove(es, i);
return true;
}
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
//제거된 index부터 마지막까지의 데이터 요소값을 복사하여 arraycopy 메서드를 통해 새로운 배열에 넣음
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
//배열의 마지막 값을 null로 바꾼다.
es[size = newSize] = null;
}
@HotSpotIntrinsicCandidate
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length); RemoveMethod {
}
//2. index로 삭제
public E remove(int index) {
//index를 받아와 해당 인덱스에 저장되어있는 Object를 찾아옴
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
//동일하게 fastRemove() 메서드로 인덱스와 데이터를 넘김
fastRemove(es, index);
return oldValue;
}
}참고 : https://velog.io/@kimsy8979/java-ArrayList-내부-동작-분석
- *Index란?
인덱스란 배열과 리스트같이 순서가 있는 메모리 구조에서 데이터의 위치를 말한다.
데이터의 위치를 의미하기 때문에 데이터를 검색할 때 사용된다.
인덱스의 시작은 ‘0’부터이며 1씩 증가한다.
인덱싱 기반이라고 함은 데이터가 순서대로 들어가 있다는 것을 말하며 ArrayList는 순서대로 데이터가 저장되어있기 때문에 인덱스 기반 구조라고 할 수 있다.
엑셀에서도 인덱스라는 개념이 있다. 이때의 인덱스는 행과 열을 말한다. 즉 데이터가 순서가 있는 구조에서 데이터 위치를 나타낼 때 사용된다.
ArrayList 동기화
ArrayList는 내부적으로 동기화 작업이 이뤄지지 않아 외부에서 동기화 작업을 별도로 해줘야한다.
ArrayList 클래스 동기화하는 방법
- Collections.synchronizedList()
Collections.synchronizedList(ArrayList<T> 참조변수);JDK1.2이후 사용 가능한 방법이다.
synchronizedList는 매개면수로 ArrayList 타입 변수를 인자로 보내 해 List 전체에 동기화를 보장하는 방법이다.
- Collections.synchronizedList()
Collections 클래스에는 SynchronizedCollection를 상속받고 List 인터페이스를 구현하는 SynchronizedList 클래스가 있으며 이 클래스는 synchronizedList 메서드로 받아온 List를 SynchronizedList의 생성자로 받아 작업을 수행하는 흐름이다.

생성자로 받은 ArrayList는 SynchronizedList의 부모 클래스인 SynchronizedCollection 클래스의 생성자로 넘어가지는데 SynchronizedCollection의 메서드들을 보면 다 synchronized 키워드로 감싸져있다.
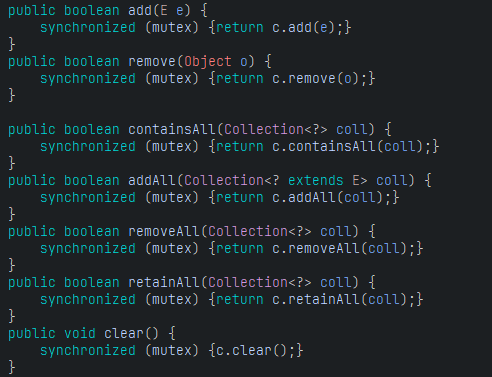
이런 식으로 ArrayList에서 구현되는 자체 메서드에는 synchronized 키워드가 없지만 synchronizedList() 메서드를 통해 synchronized 키워드가 사용되는 메서드를 통해 동기화 작업이 가능하도록 하는 방법이다.
*해당 내용은 ArrayList 뿐만 아니라 Set, Map에서 나오는 동기화 클래스와도 동일하다.
CopyOnWriteArrayList(COWL) 클래스
CopyOnWriteArrayList<T> threadSafeList = new CopyOnWriteArrayList<T>();JDK1.5부터 사용 가능한 방법이다.
CopyOnWriteArrayList 클래스는 원본 배열의 복사본을 만들어 임시 배열을 만들고 그 임시 배열을 가지고 작업을 수행한다.
ReentrantLock 클래스를 사용하는 방법으로 배열의 복사 작업을 하기 때문에 synchronizedList보다는 느리다.
CopyOnWirteArrayList를 통해 복사본 데이터를 수정하고 다른 작업자가 수정 작업을 진행할 시에는 또다른 복사본 데이터를 가지고 작업을 수행하기 때문에 여러 스레드들이 동시에 한 데이터에 접근하여 발생할 수 있는ConcurrentModificationException 에러가 발생하지 않는다.
LinkedList
LinkedList는 데이터들이 저장되어있는 메모리 공간들이 각각 연결되어있는 리스트 구조로 이루어진 인터페이스이다.
여기서 각각의 연결체들을 ‘노드’라고 한다.
LinkedList의 원리
LinkedList는 노드가 데이터 요소의 정보를 담고 있으며 어느 노드랑 연결되어있는지에 대한 정보도 갖고 있다.
LinkedList 내부 코드를 분석해보자.
public class LinkedListTest {
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient int size = 0;
/**
* Pointer to first node.
*/
transient Node<E> first;
/**
* Pointer to last node.
*/
transient Node<E> last;
}
private static class Node<E> {
//데이터 요소에 대한 정보
E item;
//다음으로 연결된 노드에 대한 정보
Node<E> next;
//이전 연결된 노드에 대한 정보
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}LinkedList 또한 Index 기반의 구조로 각 노드들의 순서를 나타낸다.
다음 노드의 정보와 이전 노드의 정보의 유무를 통해 첫번째 인덱스 노드인지 마지막 노드인지 알 수 있다.
LinkedList는 수정 작업 시 각 노드가 참조하고 있는 이전과 다음 노드의 정보만 수정하면 되기 때문에 삭제나 추가 작업이 간단하다.
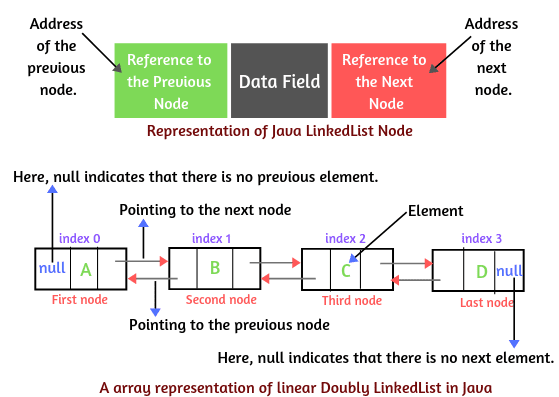
그림과 같이 첫번째 노드는 prev 노드 정보가 null이며 next 노드 정보가 다음에 저장된 노드를 가리키게 된다.
두번째 노드는 prev 노드 정보가 첫번째 노드를 참조하고 있고 next 노드 정보는 세번째 노드를 참조한다.
이렇게 이전과 다음 양 방향으로 노드를 참조하는 구조이며 마지막 노드는 next 노드 정보는 null이고 prev 노드 정보는 본인을 next 노드 정보로 참조하고 있는 노드일 것이다.
ArrayList vs LinkedList
| ArrayList | LinkedList | |
|---|---|---|
| 공통점 | 데이터의 저장 순서가 유지된다. | |
| 데이터 중복을 허용한다. | ||
| 차이점 | 초기 정해진 용량이 있다. | 정해진 용량이 없다. |
| index 기반의 자료구조이다. | index 기반이 아닌 각각의 메모리 공간이 서로를 참조하여 연결된 구조이다. | |
| index 기반으로 검색, 조회 작업이 수월하다. 시간 복잡도 : O(1) | index 기반이 아닌 연결된 노드들을 따라가야하기 때문에 검색, 조회 작업이 느리다. 시간 복잡도 : O(N) | |
| 새로운 데이터를 추가할 시 더 큰 배열을 생성하여 데이터들을 넣는다. 시간복잡도 : O(N) | 새로운 데이터를 추가시 새로운 노드를 만들어 추가할 인덱스 이전과 다음 노드 데이터로 설정하여 연결시킨다. 시간 복잡도 : O(1) | |
| 데이터를 삭제 시 새로운 작은 배열을 생성하여 나머지 데이터들을 복사하여 넣는다. | 데이터를 삭제 시 해당 노드와 연결되어있는 노드들의 prev, next 노드 정보들을 수정함으로써 연결을 끊어 삭제한다. | |
| → ArrayList는 검색, 조회 작업이 많이 사용되는 데이터 구조에서 사용하는 것이 좋다. | → LinkedList는 삭제, 수정 작업이 많이 요구되는 데이터 구조에서 사용된다. |
그렇다면 ArrayList와 LinkedList의 시간복잡도는 왜 그럴까?
- ArrayList
ArrayList의 조회 작업은 해당 index에서 가져오기만 하면 되기때문에 수행하는 작업 단계는 갯수 상관없이 1이다.
추가 작업은 해당 배열을 받아서 배열의 크기(데이터 갯수)만큼 복사 작업을 해야한다. 그래서 n.. 인건가요??
- LinkedList
LinkedList의 add() 메서드는 추가되는 노드의 앞과 뒤 연결 노드들만 바꿔주면 되어서 배열의 크기과는 상관없이 O(1)이다.
검색 작업은
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}인자로 받은 index의 크기가 사이즈의 절반보다 작다면 Node의 첫번째부터 다음다음 엄어가면서 조회를 하고 크다면 뒤에서부터 노드를 검색해온다.
그렇기 때문에 받은 인자의 수가 클수록 그만큼 조회 작업이 이뤄져서 O(N)이다.
Vector
Vector는 크기 조정이 가능한 배열을 구현하는 클래스이며 배열과 동일하게 인덱스 기반의 구조를 가지고 있다.
ArrayList와 똑같은 것 같지만 Vector 클래스는 내부적으로 ‘동기화’ 구현이 가능하다.
Vector 클래스의 add() 메서드를 살펴보면 synchronized 키워드가 붙어있다.
package java.util;
public class Vector<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
...
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
...
}즉, 내부적으로 Vector의 데이터 추가 작업 시 동기화가 적용된다는 것이다.
Stack
Stack 클래스는 Vector 클래스의 하위 클래스로 후입선출 기반 구조의 컬렉션 클래스이다.

스택 클래스는 앞의 컬렉션 클래스와 다르게 데이터 추가는 push(), 제거는 pop() 메서드를 사용한다.
Stack 클래스 또한 Vector의 하위 클래스이기 때문에 동기화가 구현되어있다.
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}Stack의 pop, push 모두 Vector 클래스의 add와 remove 기능 메서드를 사용하며 그 외에 Vector의 메서드를 재정의한 메서드는 5개 뿐으로 크게 바뀐 사항은 없다.
정리해 보자면..
ArrayList → +동기화 → Vector
Vector → 후입선출 구조 → Stack
출처
https://docs.oracle.com/javase/8/docs/technotes/guides/collections/overview.html
https://docs.oracle.com/javase/8/docs/technotes/guides/collections/index.html
http://www.tcpschool.com/java/java_collectionFramework_concept
https://www.geeksforgeeks.org/how-to-learn-java-collections-a-complete-guide/
https://docs.oracle.com/javase/tutorial/collections/intro/index.html
https://www.infoworld.com/article/2077421/abstract-classes-vs-interfaces-in-java.html
https://docs.oracle.com/javase/7/docs/api/org/omg/PortableServer/POAManagerPackage/State.html
https://docs.oracle.com/javase/tutorial/java/IandI/abstract.html
https://dinfree.com/lecture/language/112_java_6.html
https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html
https://beginnersbook.com/2013/12/java-arraylist/
https://www.geeksforgeeks.org/synchronization-arraylist-java/
https://www.javatpoint.com/java-arraylist
https://howtodoinjava.com/java/collections/arraylist/synchronize-arraylist/
http://asuraiv.blogspot.com/2020/02/java-synchronizedlist-vs.html
https://docs.oracle.com/javase/8/docs/api/java/util/Collections.html#synchronizedList-java.util.List-
https://www.mygreatlearning.com/blog/why-is-time-complexity-essential/
(https://superlang.medium.com/점근적-분석과-big-o-표기법-f8e9557aac9f)
https://www.geeksforgeeks.org/stack-class-in-java/
https://www.geeksforgeeks.org/stack-data-structure/
https://www.geeksforgeeks.org/java-util-vector-class-java/
https://docs.oracle.com/javase/8/docs/api/java/util/Vector.html
