HTTP의 변천사 (0.9부터 3까지)
1990년대 초 웹이 탄생하고나서 지금까지 웹과 인터넷 기술은 나날이 변화해가고 있다. HTTP는 1989년 팀 버너스 리에 의해 제안된 인터넷의 하이퍼 텍스트 시스템이다. HTTP는 태초의 규칙을 지키되 크고 작은 기능이 개선되면서 지금까지도 웹 통신의 중요 요소로 자리잡고 있다. 그렇다면 HTTP의 초기 모습은 어땠는지 시대별로 살펴보자
HTTP/0.9
- HTTP의 초기 버전이다. 초기 인터넷 속도는 느리고, 웹의 기능은 정보만을 보여주는 역할이었기에 HTML을 가져오기만 하는 GET 동작만이 유일했다.
- 데이터 상태를 표현하는 헤더가 없었다
- 상태코드가 없어, 문제가 발생했을 때 특정 html 파일을 오류에 대한 설명과 함께 보내졌다.
- 초기 버전에서는 0.9라는 숫자도 붙지 않았는데 HTTP/1.0이 나오고나서 이전 버전과 구분하기 위해 이름이 바뀌었다.
HTTP/1.0
- HTTP가 웹의 발전에 따라 다양한 기능들이 추가되었는데 1996년 RFC라는 공식 인터넷 기술 문서에서 기능을 정리하며, HTTP/1.0이 나오게 되었다.
- 헤더가 생겼다!
- HTTP/1.0 버전부터 HTML 파일 외에도 이미지나 파일 등 다양한 데이터를 주고 받는 형태로 발전
HTTP/1.0의 단점
🤨 통신마다 새 연결을 맺여야 했다.
요청하는 컴퓨터와 응답하는 컴퓨터가 데이터를 통신하기 위해 TCP 연결을 하고 요청과 응답을 한번씩 주고받고 나면 그 연결을 끊고 다시 새 연결을 하는 방식이었다. 이러한 방식의 문제점은 같은 컴퓨터 사이에서 여러 개의 콘텐츠를 요청할 때도 콘텐츠별로 매번 새 연결을 맺어야 했다는 점이다. 한 번 클라이언트와 서버가 연결이 되면 TCP에서는 데이터를 검증하기 위한 핸드셰이크가 이루어지는데 한 번의 핸드셰이크만하더라도 시간이 어느 정도 소요되기에, 데이터를 여러 번 주고 받느라 이 과정을 몇 번 반복하다보면 성능이 떨어질 수밖에 없다.
😵💫이전 요청에 대한 응답이 도착해야만 다음 요청을 보낼 수 있었다.
말 그대로 이전 요청에 대한 응답이 도착해야만 다음 요청을 보낼 수 있었다. 이랬을 때의 단점은 앞선 요청에 대한 응답이 늦거나 문제가 생겨 돌아오지 않으면 뒤의 요청들은 계속 기다려야 한다는 점이다.
문제를 개선해보자, HTTP/1.1
- 모호한 기능들을 개선하여 표준화하였고 앞서 본 두 개의 문제를 해결하는데 초점을 맞춘 것이 HTTP/1.1 이다.
Persist connection (지속성 연결상태)
한 번 TCP 연결을 맺으면 따로 연결을 끊지 않는 이상 연결을 유지하는 기능
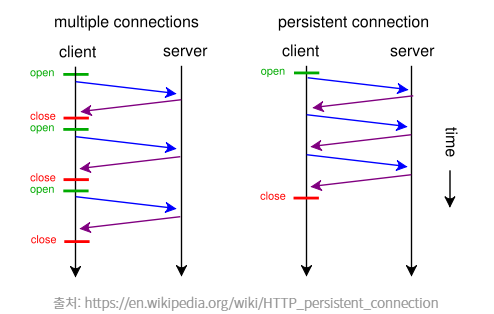
지정한 timeout동안 연속적인 요청 사이에 커넥션을 닫지 않고 연결을 유지하게 된다. 그래서 매 데이터마다 수행했던 핸드셰이크 과정이 생략 가능하게 되면서 서버나 CPU의 메모리 자원을 절약할 수 있게 되었다!
파이프라이닝 (pipelining)
첫번째 요청에 대한 응답이 완전히 전송되기 이전에 두 번째 전송 요청을 가능하게 하는 기법
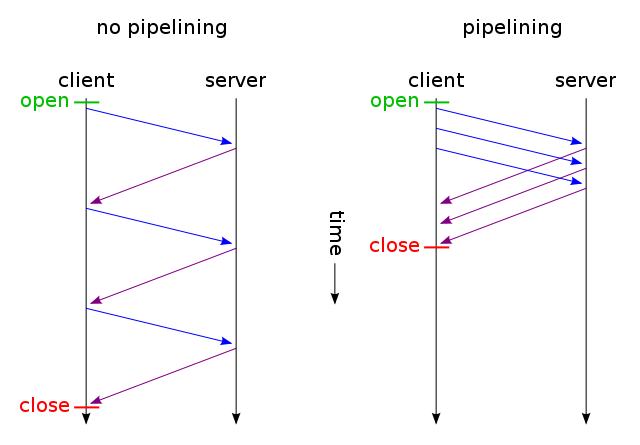
HTTP/1.0의 문제점으로 이전 요청에 대한 응답이 도착해야만 다음 요청을 보낼 수 있다는 점이 있었다. 이를 해결하기 위한 방안이 HTTP/1.1에서의 파이프라이닝 기법이다. 파이프라이닝 기법이 도입되면서 이전 응답과 상관없이 여러 개의 요청을 보낼 수 있게 되었고 그 결과 불필요한 지연을 막고 더 빠른 통신이 가능해졌다.
HTTP/2
- 성능 및 속도 개선
- 스트링다중화 (multiplexed streas)
- 서버 푸시 (server push)
- 바이너리 프레이밍 (binary framing)
HTTP/3
- 멀티 플렉싱
