1. lower bound & upper bound
이진 탐색이 정렬된 데이터에서 찾고자 하는 target data가 있는지 검색하는 알고리즘이라면, lower bound와 upper bound는 target data의 하한선 위치와 상한선 위치를 찾을 수 있는 알고리즘이다.
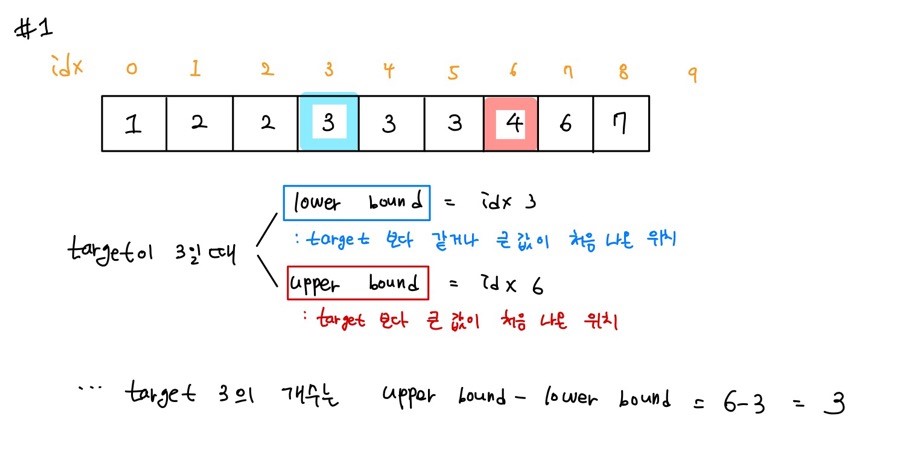
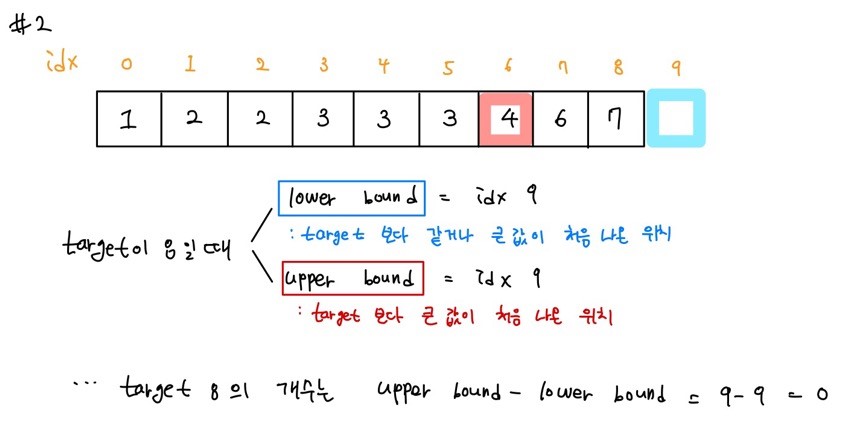
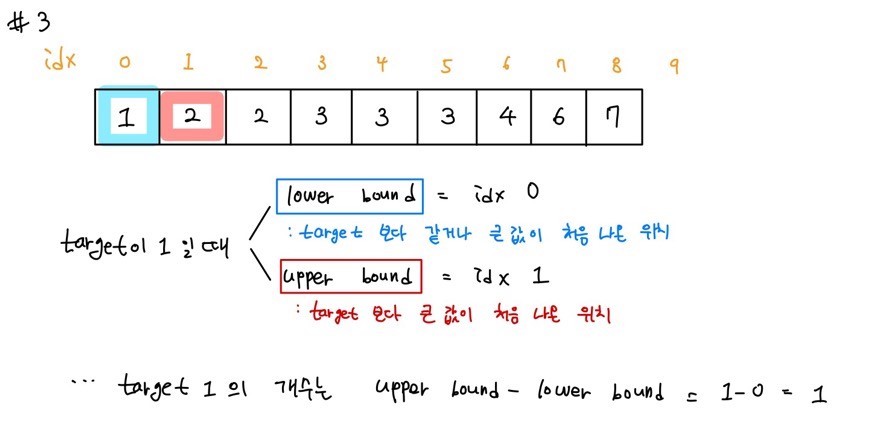
target data의 개수 = upper bound - lower bound
이진 탐색을 기반으로 동작하기 때문에 시간 복잡도는 O(logN)이며 정렬된 데이터에서 사용할 수 있는 기법이다.
2. 그림으로 이해하기
lower bound : target data와 같거나 큰 데이터가 처음 나온 위치를 반환 (하한선)
upper bound : target data보다 큰 데이터가 처음 나온 위치를 반환 (상한선)
3. 동작 원리 & 코드
1. lower bound
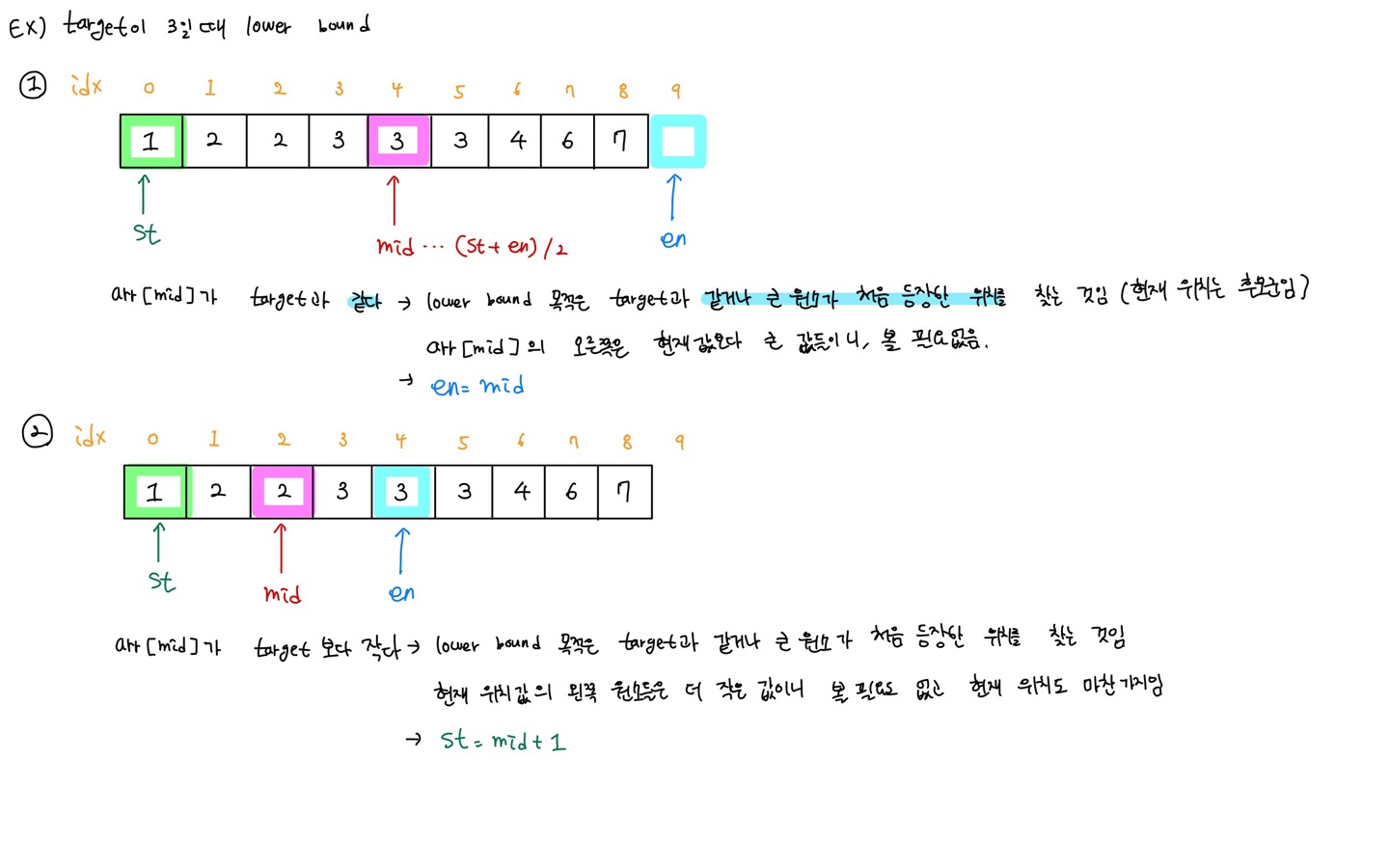
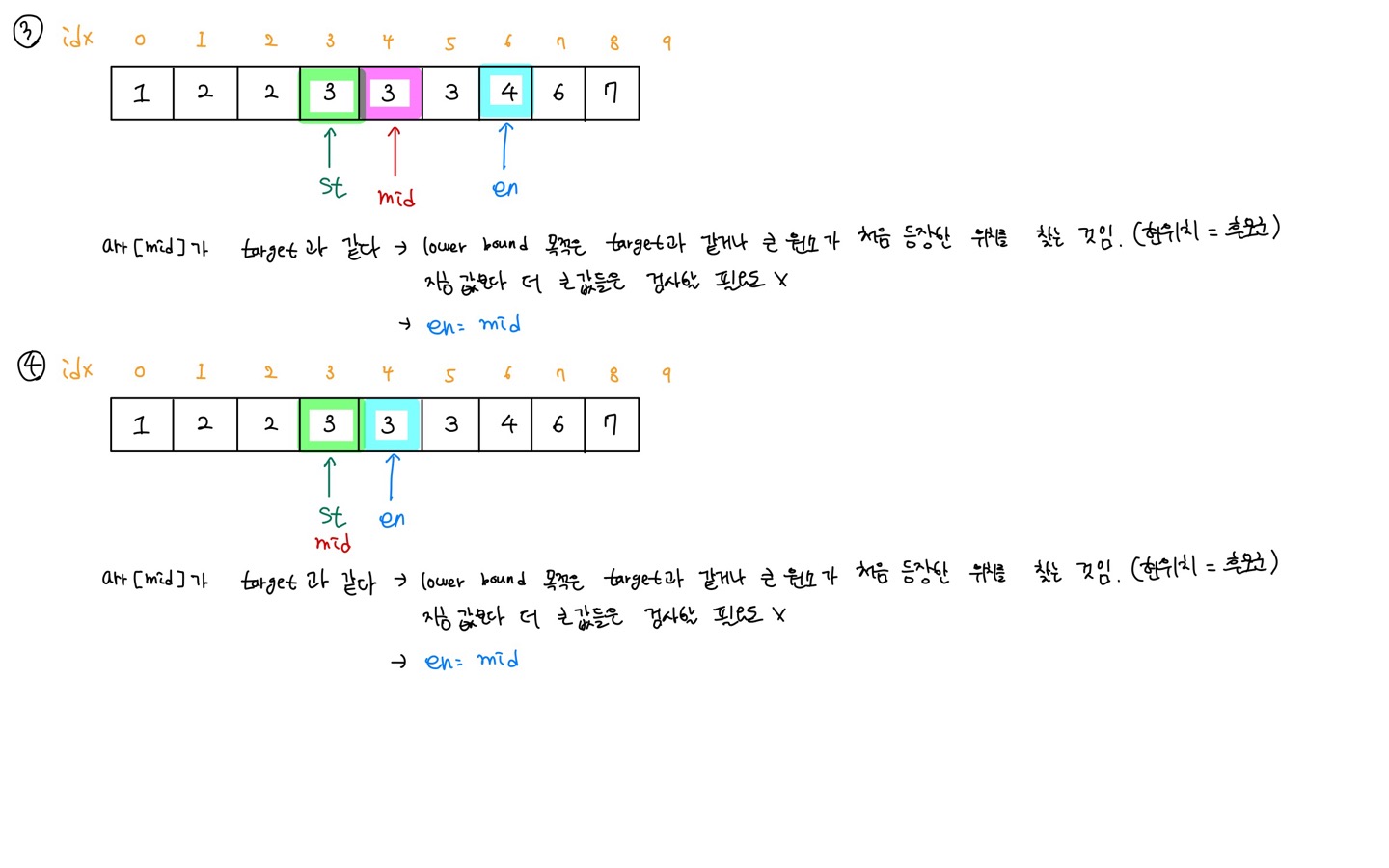
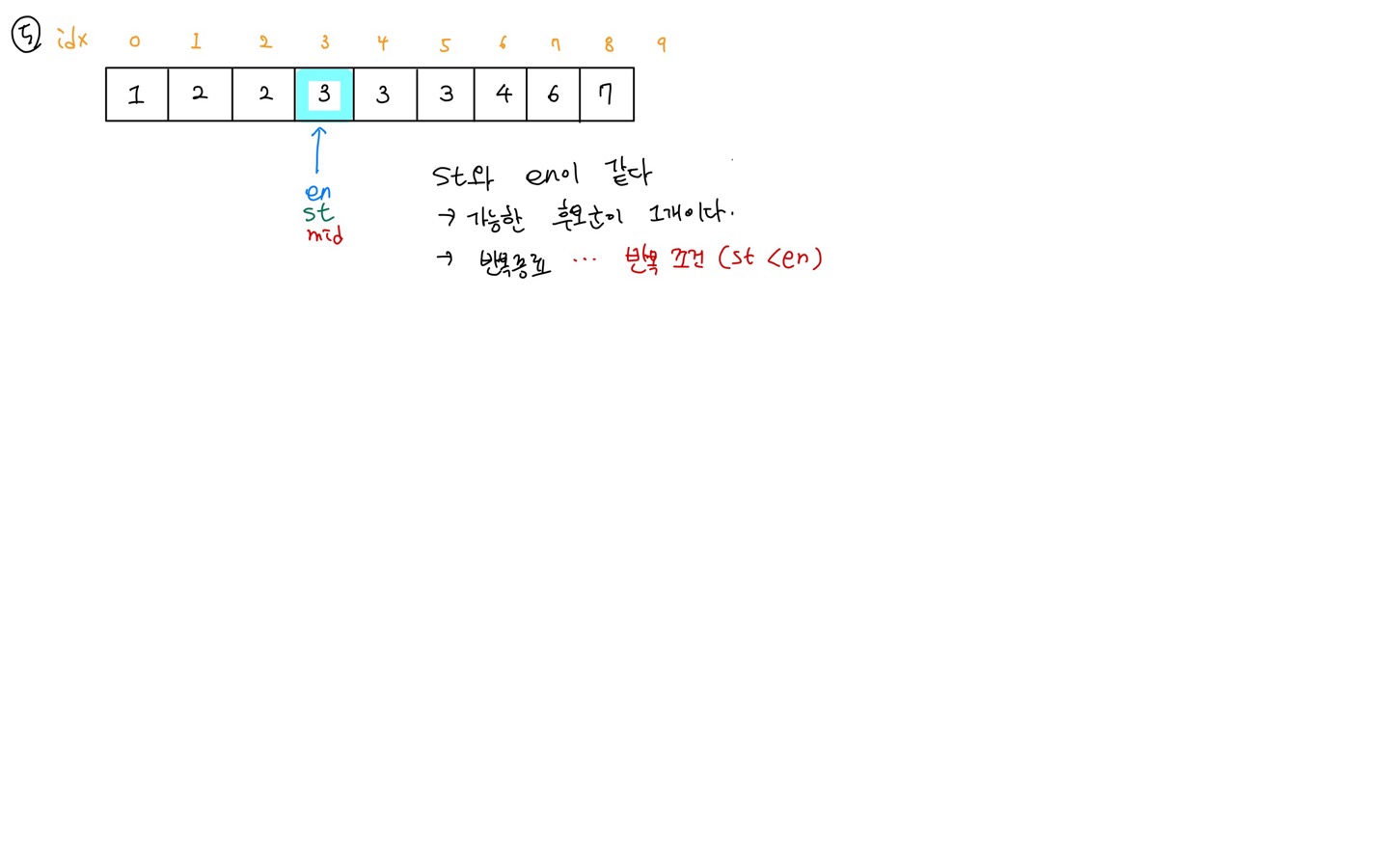
target data와 같은 원소 혹은 큰 원소가 최초로 나온 지점의 위치를 반환
방법
- 배열의 왼쪽을 가리키는 포인터 변수 st = 0, 배열의 오른쪽을 가리키는 포인터 변수 en = 배열의 크기로 설정한다.
- 탐색하는 배열 범위의 가운데 원소를 가리키는 포인터 변수 mid = (st + en) / 2로 설정한다.
- arr[mid] < target
- arr[mid]는 lower bound의 후보군도 아님
- arr[mid] 기준 왼쪽 데이터 값은 더 작고, 왼쪽은 탐색할 필요가 없음
- 따라서 st 포인터 변수는 mid + 1 로 재설정한다.
- arr[mid] >= target
- arr[mid]는 lower bound의 후보군임
- arr[mid] 기준 오른쪽 데이터 값은 더 큼.
- target의 하한선(= 같거나 더 큰)을 찾는 것이 목표이므로 en 포인터를 mid값으로 설정한다.
- st > en을 만족할 때 까지 2~4번 과정을 반복한다.
방법 (그림)
lower bound 코드 구현 (c++)
#define _CRT_SECURE_NO_WARNINGS
#include <bits/stdc++.h>
#include <iostream>
#include <stdio.h>
#include <string>
#include <math.h>
using namespace std;
int main(void)
{
int arr[] = { 1,2,2,3,3,3,4,6,7 };
int st = 0;
int en = 9;
int mid;
int target = 3;
// 숫자 3의 lower bound 구현 -> 결과 : 3
while (st < en)
{
mid = (st + en) / 2;
if (arr[mid] < target) // 현위치가 target보다 작음 -> 왼쪽 원소들과 현위치는 검사할 필요도 없음
{
st = mid + 1;
}
else // arr[mid] >= target (lower bound의 후보군이 되는 위치임)
{
en = mid;
}
}
printf("target = %d의 lower bound는 %d입니다\n", target, en);
}lower bound 코드 구현 (python)
arr = [1,2,2,3,3,3,4,6,7]
st = 0
en = 9
target = 3
while (st < en):
mid = (st + en) // 2
if (arr[mid] < target):
st = mid + 1
else: #arr[mid] >= target
en = mid
print(target, "의 lower bound는", en, "입니다")2. upper bound
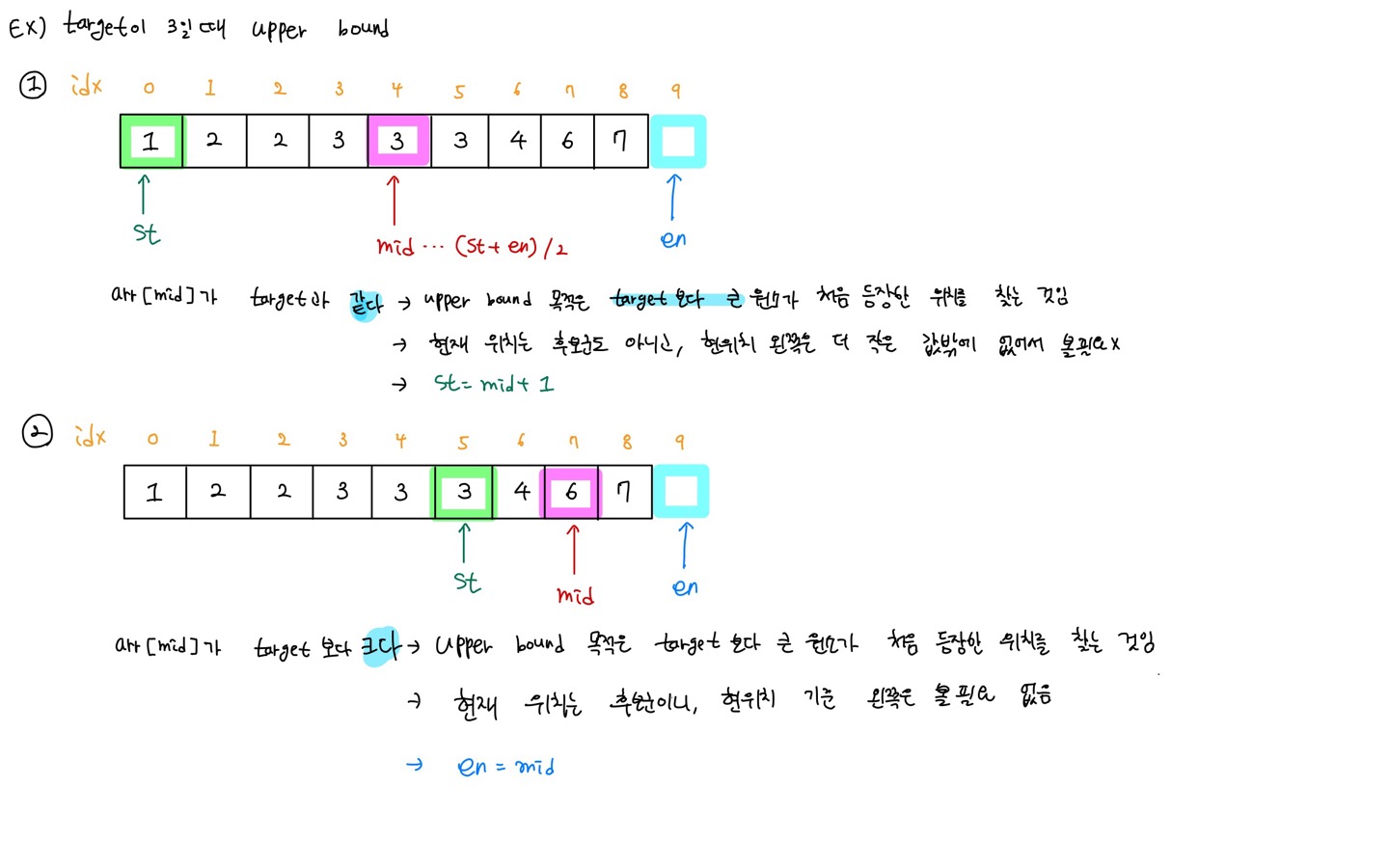
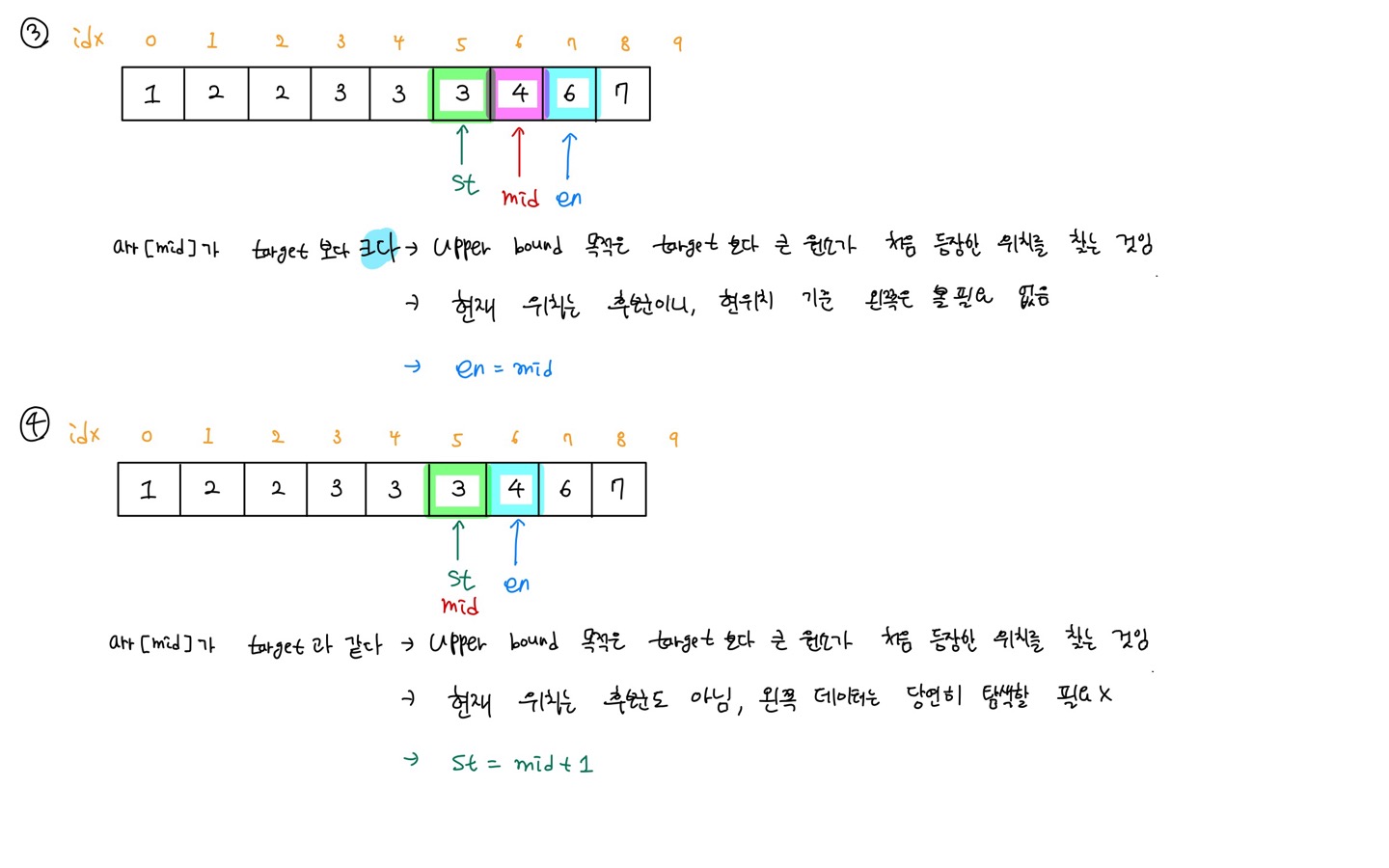
target data보다 큰 원소가 최초로 나온 지점의 위치를 반환
방법
- 배열의 왼쪽을 가리키는 포인터 변수 st = 0, 배열의 오른쪽을 가리키는 포인터 변수 en = 배열의 크기로 설정한다.
- 탐색하는 배열 범위의 가운데 원소를 가리키는 포인터 변수 mid = (st + en) / 2로 설정한다.
- arr[mid] <= target
- arr[mid]는 lower bound의 후보군도 아님
- arr[mid] 기준 왼쪽 데이터 값은 더 작고, 왼쪽은 탐색할 필요가 없음
- 따라서 st 포인터 변수는 mid + 1 로 재설정한다.
- arr[mid] > target
- arr[mid]는 lower bound의 후보군임
- arr[mid] 기준 오른쪽 데이터 값은 더 큼.
- target의 상한선(= 더 큰)을 찾는 것이 목표이므로 en 포인터를 mid값으로 설정한다.
- st > en을 만족할 때 까지 2~4번 과정을 반복한다.
방법 (그림)
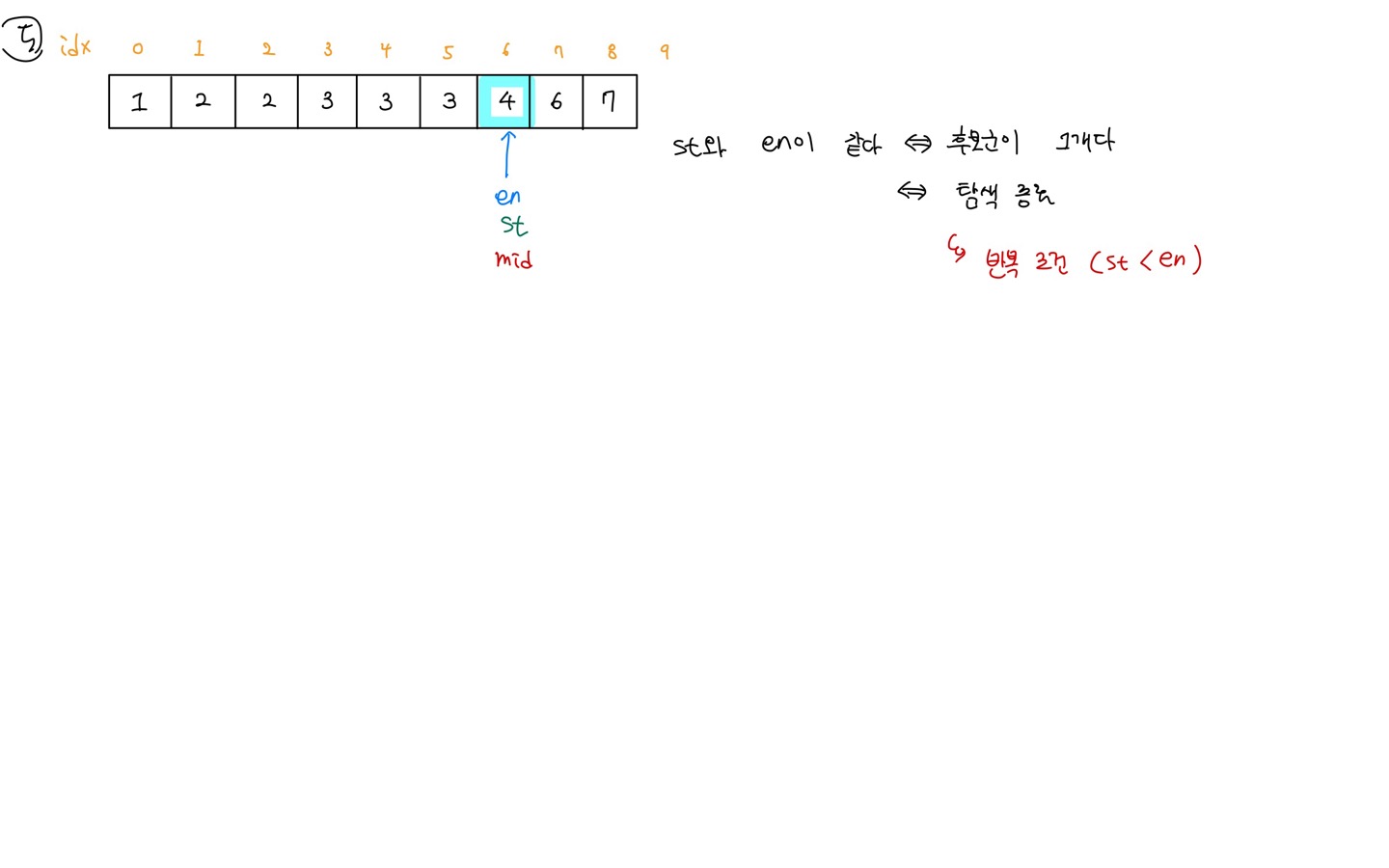
upper bound 코드 구현 (c++)
#define _CRT_SECURE_NO_WARNINGS
#include <bits/stdc++.h>
#include <iostream>
#include <stdio.h>
#include <string>
#include <math.h>
using namespace std;
int main(void)
{
int arr[] = { 1,2,2,3,3,3,4,6,7 };
int st = 0;
int en = 9;
int mid;
int target = 3;
// 숫자 3의 upper bound 구현 -> 결과 : 6
while (st < en)
{
mid = (st + en) / 2;
if (arr[mid] <= target) // 현위치가 target보다 작음 -> 후보군도 아님 -> 왼쪽 원소들과 현위치는 검사할 필요도 없음
{
st = mid + 1;
}
else // arr[mid] > target (upper bound의 후보군이 되는 위치임)
{
en = mid;
}
}
printf("target = %d의 lower bound는 %d입니다\n", target, en);
}upper bound 코드 구현 (python)
arr = [1,2,2,3,3,3,4,6,7]
st = 0
en = 9
target = 3
while (st < en):
mid = (st + en) // 2
if (arr[mid] <= target):
st = mid + 1
else: #arr[mid] > target
en = mid
print(target, "의 upper bound는", en, "입니다")
저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!