
📒 UNION
두 개 이상의 SELECT문의 결과를 합쳐 하나의 결과 집합으로 반환한다.
이때, 교집합(중복 데이터)는 1번만 출력된다.
📌 문법
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION
SELECT column1, column2, ...
FROM table2
WHERE condition2;
📌 예제
아래와 같은 테이블 2개가 있다고 가정해보자.
-- 테이블 1: employees
+----+--------+
| id | name |
+----+--------+
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
+----+--------+
-- 테이블 2: managers
+----+--------+
| id | name |
+----+--------+
| 2 | Bob |
| 4 | David |
| 5 | Emily |
+----+--------+
UNION을 사용하여 두 테이블의 데이터를 합칠 수 있다.
📌 SQL문
SELECT id, name
FROM employees
UNION
SELECT id, name
FROM managers;
📌 결과
+----+--------+
| id | name |
+----+--------+
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
| 4 | David |
| 5 | Emily |
+----+--------+
-> EMPLOYEES 테이블과 MANAGERS테이블 중 Bob이 중복된 데이터인데, 중복된 데이터는 한번만 출력되는 것을 확인할 수 있다.
❓ 중복된 행이 그대로 결과에 포함되고 싶다면? UNION ALL을 사용하자!
📒 UNION ALL
UNION과 마찬가지로 두 개 이상의 SELECT문의 결과를 합치는데 사용된다.
BUT, 중복된 행을 제거하지 않고 모든 행을 결과 집합에 포함시킨다.
📌 문법
SELECT column1, column2, ...
FROM table1
WHERE condition1
UNION ALL
SELECT column1, column2, ...
FROM table2
WHERE condition2;
📌 예제
아래와 같은 테이블 2개가 있다고 가정해보자.
-- 테이블 1: employees
+----+--------+
| id | name |
+----+--------+
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
+----+--------+
-- 테이블 2: managers
+----+--------+
| id | name |
+----+--------+
| 2 | Bob |
| 4 | David |
| 5 | Emily |
+----+--------+
📌 SQL문
SELECT id, name
FROM employees
UNION ALL
SELECT id, name
FROM managers;
📌 결과
+----+--------+
| id | name |
+----+--------+
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
| 2 | Bob |
| 4 | David |
| 5 | Emily |
+----+--------+
-> UNION ALL을 사용하여 중복이 허용되며, 중복된 행 Bob이 모두 결과 집합에 출력되는 것을 확인할 수 있다.
📒 INTERSECT(교집합)
두 개 이상의 SELECT문의 결과 중에서 공통된 행만을 반환하는데 사용된다.
즉, 첫 번째 SELECT문과 두 번째 SELECT문의 결과에서 동일한 행만 결과에 포함된다.
📌 문법
SELECT column1, column2, ...
FROM table1
WHERE condition1
INTERSECT
SELECT column1, column2, ...
FROM table2
WHERE condition2;
📌 예제
아래와 같은 테이블 2개가 있다고 가정해보자.
-- 테이블 1: employees
+----+--------+
| id | name |
+----+--------+
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
+----+--------+
-- 테이블 2: managers
+----+--------+
| id | name |
+----+--------+
| 2 | Bob |
| 4 | David |
| 5 | Emily |
+----+--------+
📌 SQL문
SELECT id, name
FROM employees
INTERSECT
SELECT id, name
FROM managers;
📌 결과
+----+--------+
| id | name |
+----+--------+
| 2 | Bob |
+----+--------+
-> INTERSECT를 사용하여 두 테이블의 공통된 행인 Bob만 출력된 것을 확인할 수 있다.
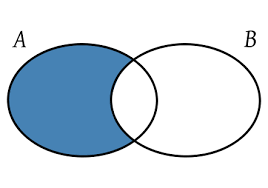
📒 MINUS(차집합)
두 개 이상의 SELECT문의 첫 번째 SELECT문의 결과에서 두 번째 SELECT문의 결과를 제외한 행을 반환한다.
EX) A테이블 MINUS B테이블이면 아래와 같은 결과가 나타난다.
📌 문법
SELECT column1, column2, ...
FROM table1
WHERE condition1
MINUS
SELECT column1, column2, ...
FROM table2
WHERE condition2;
📌 예제
아래와 같은 테이블 2개가 있다고 가정해보자.
-- 테이블 1: employees
+----+--------+
| id | name |
+----+--------+
| 1 | Alice |
| 2 | Bob |
| 3 | Carol |
+----+--------+
-- 테이블 2: managers
+----+--------+
| id | name |
+----+--------+
| 2 | Bob |
| 4 | David |
| 5 | Emily |
+----+--------+
📌 SQL문
SELECT id, name
FROM employees
MINUS
SELECT id, name
FROM managers;
📌 결과
+----+--------+
| id | name |
+----+--------+
| 1 | Alice |
| 3 | Carol |
+----+--------+
-> MINUS를 사용하여 첫 번째 테이블의 결과에서 두 번째 테이블의 결과를 제외한 행만 얻는 것을 확인할 수 있다.
