문제
Pytorch 기반의 모델 학습 코드를 실행하던 중 기존 대비 학습 시간이 급격하게 떨어지는 문제가 발생했다.

원래 배치당 50초~1분 걸리던게 갑자기 3~4분으로 늘어났다.
특정 모듈을 하나 추가 했을 뿐이라 우선적으로 device를 전부 확인해서 cuda에 올라가있는지 확인했다. 하지만 cpu 연산 명령어는 없었다..

GPU-Util 부분에서 GPU 완벽하게 사용하지 않는 문제점을 발견했다.
물론 watch 명령어로 nvidia-smi를 확인하면 99%를 사용하는 구간이 분명 존재했다. 하지만 top 명령어를 확인해보니 문제점이 발견되었다.
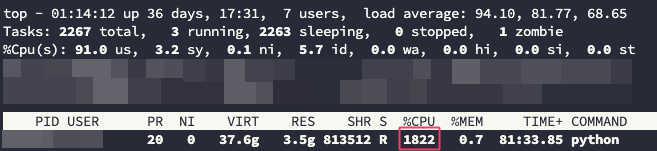
보통 모델 학습을 돌리면 CPU %가 100%이하로 출력되는데 1800~2000%의 소모량을 보이고 있었다.
CPU 코어를 엄청 잡아먹고 있었던 것으로 확인되었다...
해결 방법
https://discuss.pytorch.org/t/cpu-usage-extremely-high/52172

train이 진행되는 코드 최상단에 아래 코드 한줄을 추가했더니 정상화되었다.
기본값은 서버 내 CPU를 전부 다 사용한다고 한다.
torch.set_num_threads(1)set_num_threads 코드는 사용할 CPU 스레드의 수를 설정하는 함수이다.
이걸 1로 설정해서 PyTorch가 CPU 연산에서 사용하는 스레드 수가 줄어들면서, CPU에서 수행되는 병렬 연산의 오버헤드가 줄어들기 때문에 다시 속도가 정상적으로 돌아온 것이었다.
내가 추가한 모듈에 병목을 일으키는 코드가 많이 있었던 것 같다.

다시 배치당 학습시간이 50초대로 나왔으며,

cpu도 정상적으로 출력되는 것을 확인할 수 있었다.

그리고 gpu 소모량도 다시 원상복구된 것을 확인할 수 있었다.
4일을 이거때문에 삽질했는데 코드 한 줄로 디버깅되었다는거에서 허탈했지만 그대로 다시 연구 진행할 수 있어서 다행이다,,

언승이 화이팅!