Eval; G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment
G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment
2023.05
abstract
- NLG 시스템이 생성한 텍스트의 품질을 자동으로 측정하는건 어렵다
- 기존의 문제점
- BLEU, ROUGE와 같은 reference-based metrics
- relatively low correlation with human judgements
- 특히 창의성, 다양성이 요구되는 과제 x_x
- reference-free metrics로 LLM 사용 제안
- human references가 부족한 과제에서도 적용 가능하다는 장점
- still have lower human correspondence than medium-size neural evaluators
- BLEU, ROUGE와 같은 reference-based metrics
- 그래서 제안하는 G-EVAL, LLM에 CoT와 form-filling 패러다임을 적용한 프레임워크. GPT-4를 기반 모델로 사용
- text summarization, dialogue generation에서 실험 진행
- 인간 평가와의 spearman correlation이 0.514에 도달: 이전의 모든 방법을 크게 능가
- 추가로,
- LLM 기반 evaluator의 행동 분석
- LLM이 편향을 가질 수 있다는 잠재적 우려 강조
추가 자료
Reference-based metrics란?
NLG가 생성한 텍스트의 품질을 평가할 때 미리 준비된 인간 작성의 정답(reference)와 비교하는 방법을 의미한다.
1. BLEU
- 주로 기계 번역 평가에 사용됨
- 생성된 텍스트와 참조 텍스트 간의 n-gram(단어나 단어 조합) 일치를 측정
- 단어 일치율 + 문장 내의 어순 고려
- ROUGE
- 주로 텍스트 요약 평가에 사용됨
- 생성된 요약문과 참조 요약문 간의 n-gram, 단어의 길이, 문장 일치 등을 비교
framework
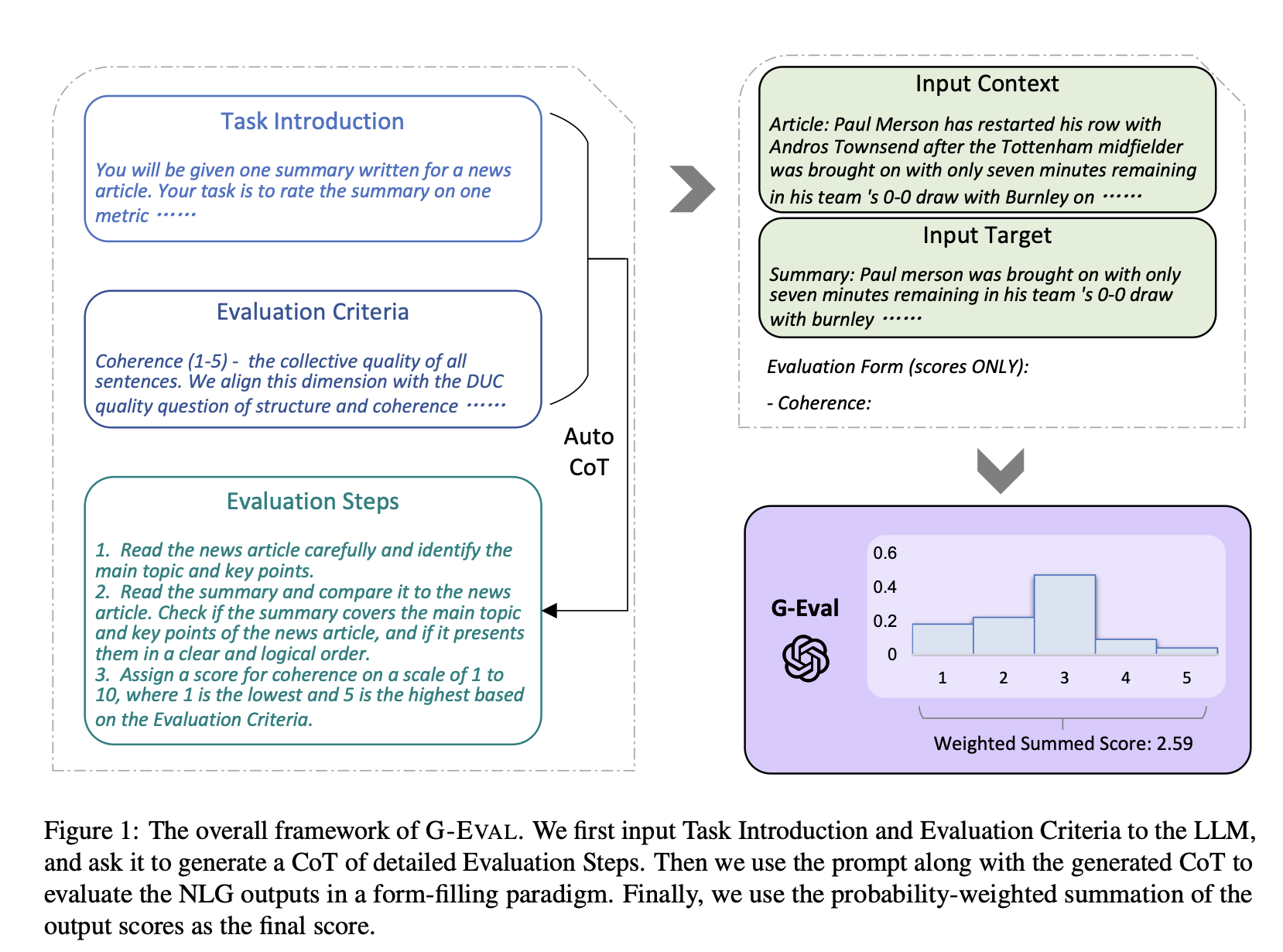
프레임워크의 단계
1. LLM에 입력
- Task Introduction
- Evaluation Criteria
- CoT 생성
Auto CoT로 detailed Evaluation Steps를 만들게 함 - 평가 수행
생성된 CoT와 prompt를 함께 사용하여 NLG output들을 평가한다. 평가는 form-filling paradigm, 즉 정해진 양식에 맞춰 기록된다.
이 단계에서는 LLM이 평가를 위한 구체적이고 논리적인 단계들을 스스로 도출하게 됩니다. - 최종 점수 산출
평가 점수에 LLM이 예측한 확률을 반영하기 위해, 확률 가중치를 적용하여 최종 점수를 산출한다.
ex) LLM의 예측 확률: 1점(5%), 2점(10%), 3점(30%), 4점(50%), 5점(5%)면 확률을 가중치로 반영하여 연속적인 점수를 얻을 수 있다.
method
G-Eval의 세 가지 구성요소
1) 평가 태스크의 정의와 원하는 평가 기준을 포함하는 프롬프트
2) LLM으로 생성한, 구체적인 평가 단계를 설명하는 CoT
3) return token의 확률에 기반한 점수 계산 함수
prompt
예를 들어, 텍스트 요약 태스크에서는 프롬프트(1번)가 다음과 같이 주어질 것이다.
You will be given one summary written for a news article. Your task is to rate the summary on one metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
Evaluation Criteria:
Coherence (1-5) - the collective quality of all sentences. We align this dimension with the DUC quality question of structure and coherence whereby ”the summary should be well-structured and well-organized. The summary should not just be a heap of related information, but should build from sentence to sentence to a coherent body of information about a topic.”
Auto CoT
LLM이 더 논리적인 평가 과정을 거칠 수 있도록 하는 중간 사고 단계
프롬프트에 아래의 내용(예시)을 추가해서 LLM이 자동으로 CoT를 생성할 수 있게 한다.
Evaluation Steps:
1. Read the news article carefully and identify the main topic and key points.
2. Read the summary and compare it to the news article. Check if the summary covers the main topic and key points of the news article, and if it presents them in a clear and logical order.
3. Assign a score for coherence on a scale of 1 to 5, where 1 is the lowest and 5 is the high
scoring function
목표 텍스트를 생성할 조건부 확률을 평가 지표를 사용하는 기존의 GPTScore과 달리, G-Eval은 직접적인 평가 방식을 사용한다.
채점 함수는 프롬프트, 자동 생성된 CoT, 입력 맥락, 평가할 대상 텍스트와 함께 LLM을 호출한다.
예를 들어, 텍스트 요약본의 일관성을 평가할 때 프롬프트, CoT, 뉴스 기사, 요약문을 concatenate 후 각 평가 항목별로 1-5점을 출력하도록 LLM을 호출할 것이다.
채점 함수의 두 가지 이슈:
1. 일부 평가 작업에서 특정 점수가 지나치게 자주 등장하는 경향이 있다(예: 1~5점 척도에서 3점이 많음). 이로 인해 점수 분포의 분산이 낮아지고, 인간 평가와의 상관성이 떨어질 수 있다.
2. LLM은 일반적으로 정수 점수만 출력하는 경향이 있으며, 프롬프트에서 소수점을 포함한 값을 요청하더라도 이를 잘 따르지 않는다. 이로 인해 생성된 텍스트 간의 미묘한 차이를 반영하지 못하는 동점(tie) 문제가 발생할 수 있다.
이를 해결하기 위해, 연구진은 LLM이 출력하는 토큰의 확률을 활용하여 점수를 정규화하고, 확률 가중치를 주는 방식을 제안했다.
: 점수별 확률
experiments
SummEval, Topical-Chat, QAGS 세 가지 벤치마크 데이터에 대해 요약/대화 생성 태스크 평가를 진행하였다.
특이사항
- GPT-3.5: temperature=0
- 모델의 결정력을 높이기 위해 temperature=0으로 설정함
- temperature가 낮을수록 같은 입력시 비슷한 출력, 낮은 temp = 0 or 0.1, 높은 temp = 1 이상
- GPT-4: n=20, temperature=1, top_p=1
- GPT-4는 개별 토큰의 확률을 직접적으로 출력하지는 않기 때문에, 확률을 추정하기 위해 20번 샘플링 진행
- top_p=1: 모든 가능한 단어들을 다 고려한다(1점~5점까지 다 가중치 곱해서 더하니까)
- top_p는 nucleus sampling 기법에서 사용되는 파라미터로, 텍스트 생성 시 모델이 출력할 후보 단어들을 확률 값에 따라 정렬하고, 그 중에서 상위 p%의 확률을 가진 단어들만을 선택하여 샘플링하는 방식이다. 즉 확률 낮은 애들은 아예 고려하지 않게 필터링하는 품질 개선용 파라미터.
- top_p가 1이라는건 상위 100%니까 후보에 있는 모든 애들을 최종 점수 계산에 다 반영한다는 의미
SummEval 벤치마크 실험결과
요약문 평가에 사용되는 벤치마크 데이터셋
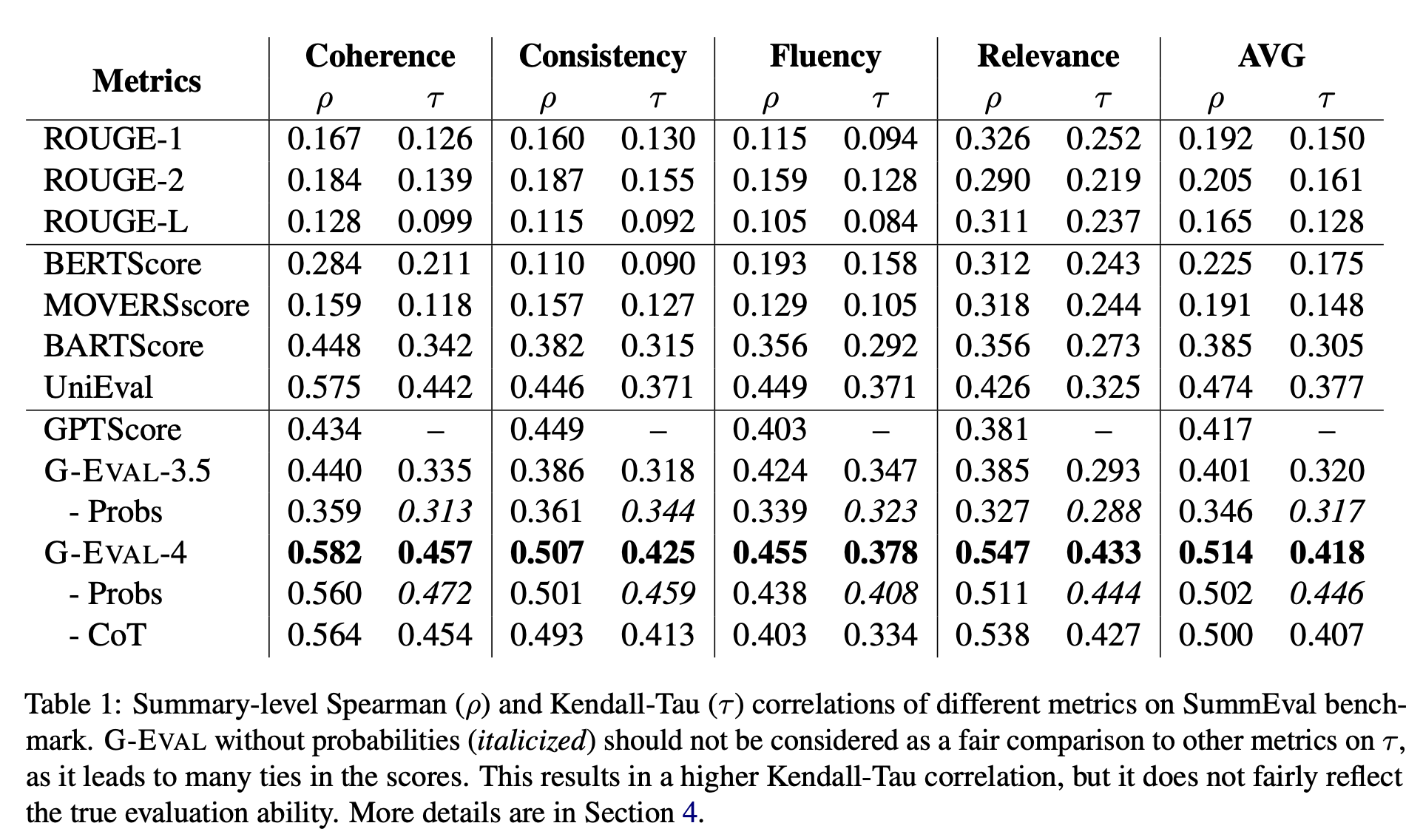
- Probs(이탤릭체) 가 확률 가중치 반영하지 않은 것: 오히려 성능이 떨어짐
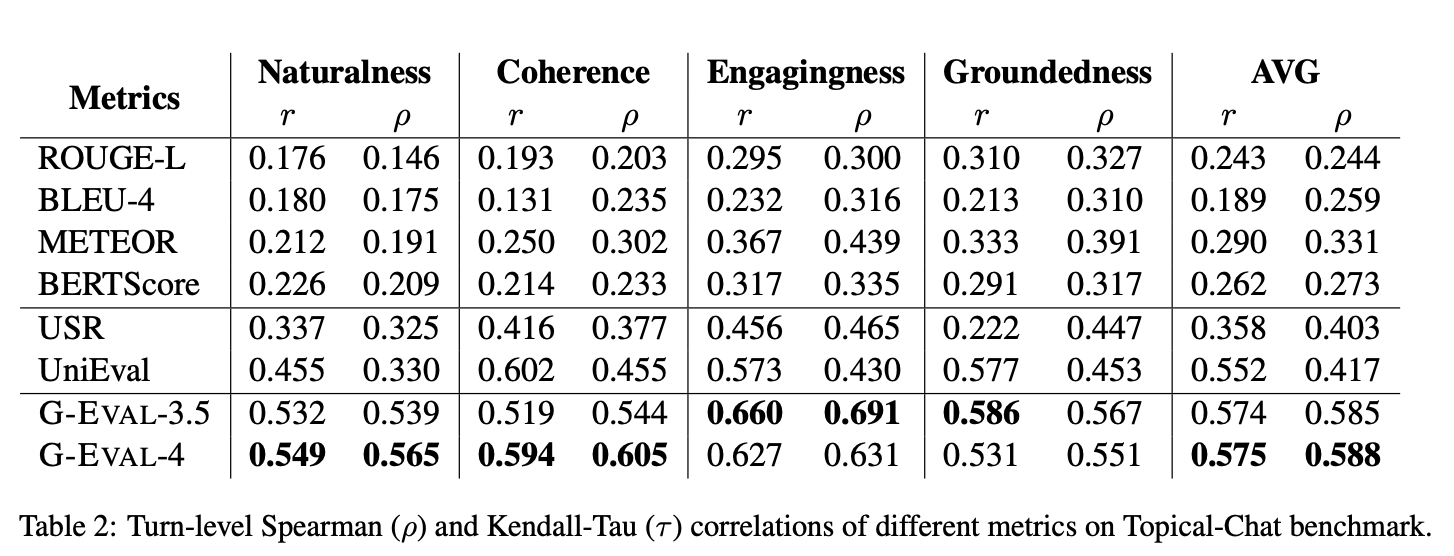
Topical-Chat 벤치마크 실험결과
지식을 필요로 하는 대화 응답 생성 평가에 사용되는 벤치마크 데이터셋
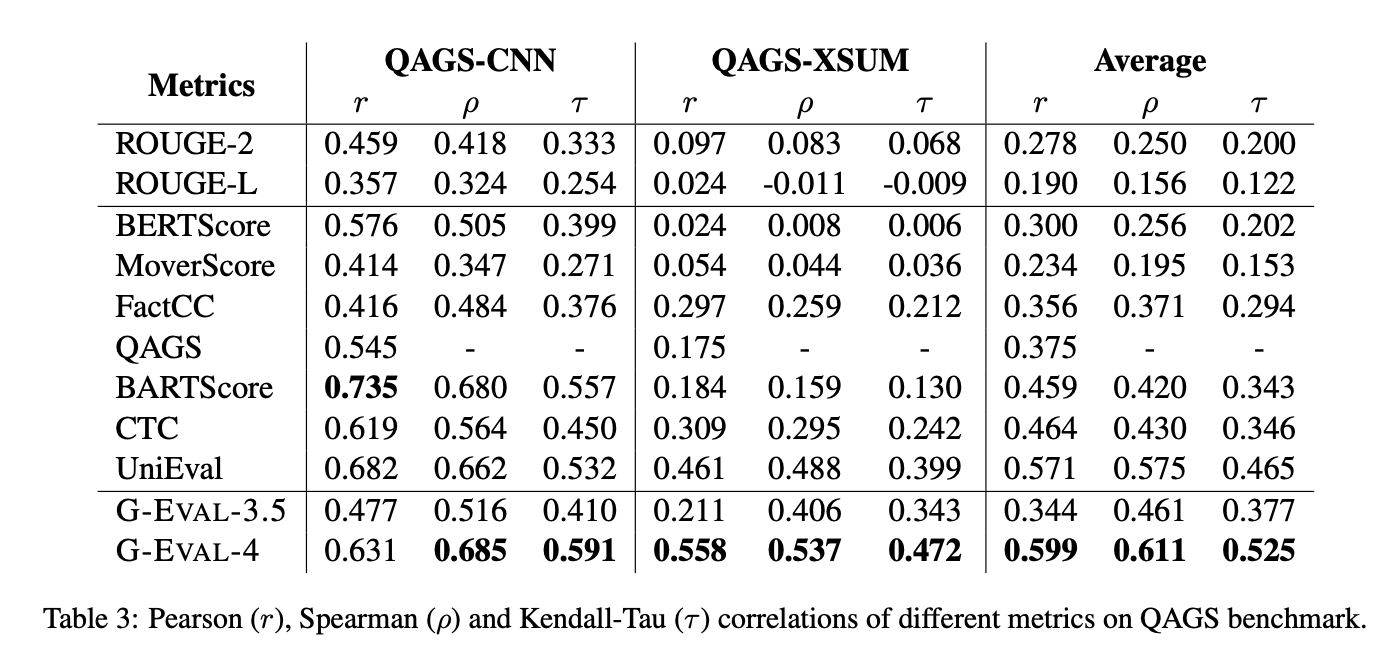
QAGS 벤치마크 실험결과
요약 태스크에서 hallucination 평가에 사용되는 벤치마크 데이터셋
analysis
Will G-EVAL prefer LLM-based outputs?
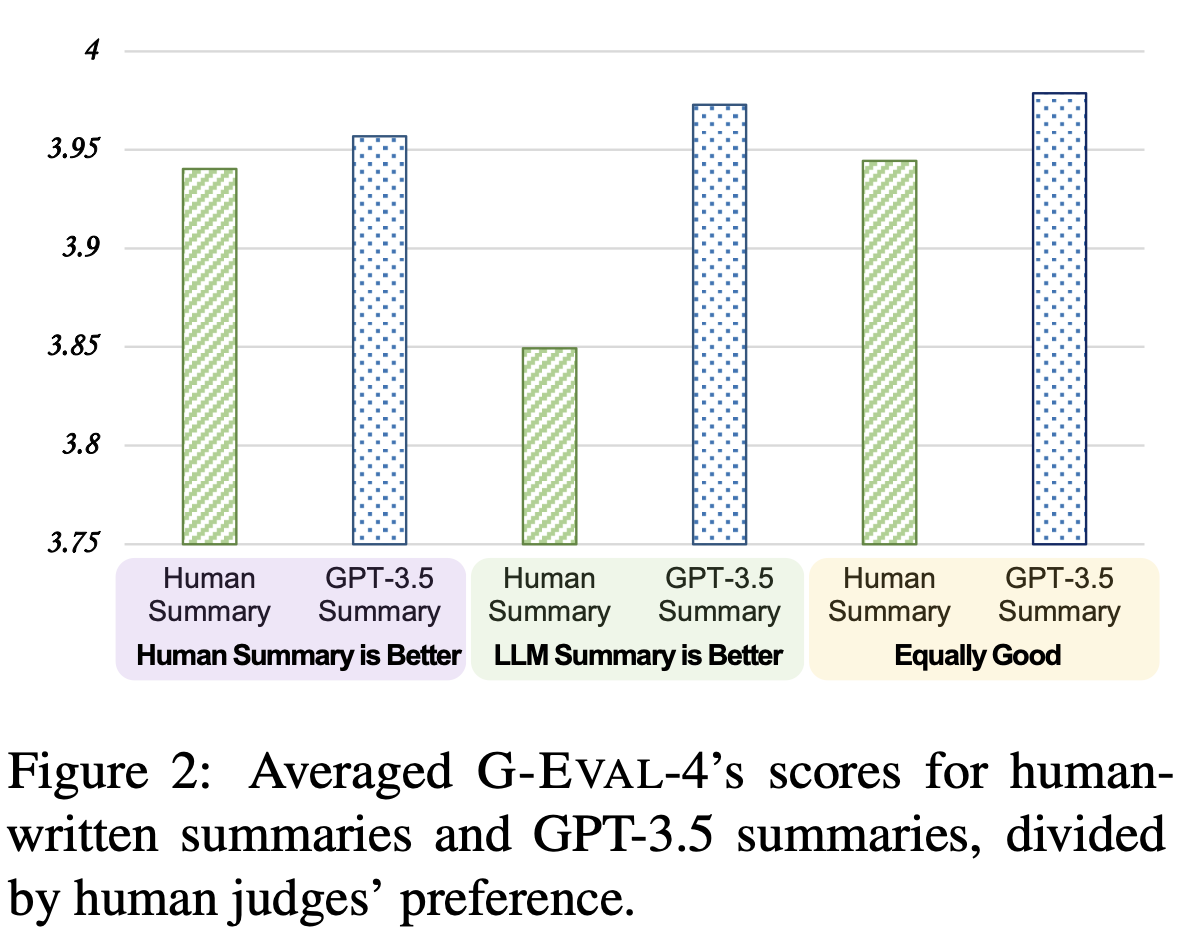
G-Eval-4 에게 사람의 요약과 GPT-3.5의 요약의 품질을 비교하라고 했을 때, 항상 GPT-3.5의 요약을 선호하는 결과를 보였다. (= 편향이 있다)
추정 가능한 이유
1. 고품질의 NLG 아웃풋은 애초에 평가하기가 어렵다
2. 모델이 생성과 평가에서 같은 평가 기준을 공유할 수 있다
The Effect of Chain-of-Thoughts
SummEval 벤치마크 평가 결과 보면 CoT 포함 여부에 따라 비교했을 때 CoT가 포함된 경우 훨씬 높은 성능을 보임. 즉 CoT 효과 있다.
The Effect of Probability Normalization
SummEval 벤치마크 평가 결과 보면 확률 정규화 여부에 따라 비교했을 때
- 요약 태스크에 있어서는 probability를 활용했을 때 오히려 성능이 떨어짐
- 저자는 그 이유를 일치하는 쌍(concordant pairs)과 일치하지 않는 쌍(discordant pairs)의 수를 기반으로 하는 Kendall-Tau 상관관계의 계산 방법에 기인한다고 설명했다.
- 확률 가중치를 사용하지 않았을 때 동점이 많이 발생하는데, 이때 일치하는 쌍의 비율이 높아져서 더 높은 상관관계가 나왔으나 이는 모델의 실제 능력을 반영하지는 못한다.
- 정규화된 점수가 더 미묘한 차이를 잘 반영한다는 사실은 spearman correlation 결과로 확인할 수 있다.
The Effect of Model Size
SummEval, QAGS 벤치마크에서 모델 크기에 따라 비교했을 때 G-Eval-4가 G-Eval-3.5보다 더 높은 상관관계를 보인다.
Topical-Chat 벤치마크의 Engagingness와 Groundedness에서는 예외 발생: 모델 크기는 Consistency, Relevance에 있어 더 큰 효과
main contributions
-
LLM-based metrics는 기존의 reference-based/free metrics보다 인간 평가와의 상관관계가 높다. 특히 dialogue response generation(대화 응답 생성) 개방형, 창의적인 NLG 작업에서 우수하다.
-
prompt와 instruction에 민감하다. CoT를 사용하면 더 많은 context와 guidance를 제공받아 성능이 향상될 수 있다.
-
기존의 이산적(discrete) 점수를 해당 토큰의 확률을 활용하여 세밀한 연속적 점수(fine-grained continuous)로 제공 가능: 더 정밀한 결과 표현
-
LLM이 생성한 텍스트를 선호하는 bias의 가능성: self-reinforcement의 위험성 내포
