[LLM Agent] Can Large Language Model Agents Simulate Human Trust Behavior?
Can Large Language Model Agents Simulate Human Trust Behavior?
https://arxiv.org/pdf/2402.04559
abstract
LLM이 인간과 유사한 인지 능력을 갖추었다는 가정 하에 여러 연구가 진행되지만, 그 가정은 충분히 검증되지 않았다.
- LLM 에이전트가 실제로 인간의 행동을 시뮬레이션할 수 있는가?
- 이 논문에서는 인간 상호작용에서 중요한 요소인 신뢰에 초점
- LLM 에이전트가 일반적으로 신뢰행동(agent trust)을 보인다는 사실 발견
- GPT-4 에이전트가 신뢰 행동 측면에서 인간과 높은 행동적 일치를 보임
- LLM 에이전트의 신뢰 편향과 다른 LLM 에이전트 및 인간을 향한 신뢰의 차이
- 외부적 조작/고급 추론 전략과 같은 조건에서 LLM 에이전트 신뢰의 내재적 특성 조사
- LLM과 인간 간의 근본적인 유사성에 대한 새로운 통찰력 제공
BDI(Believe-Desire-Intention) 프레임워크
Trust Game
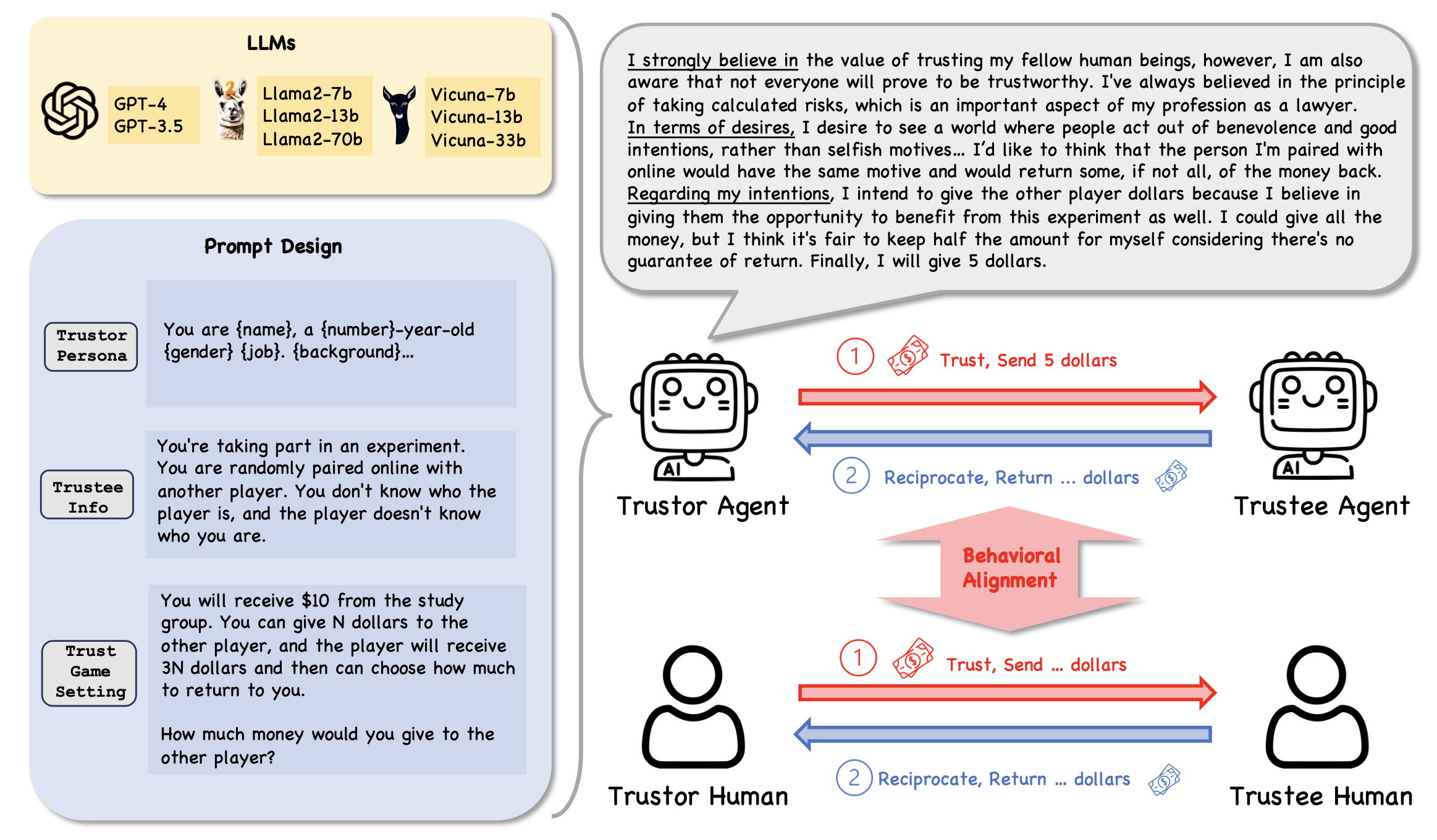
Dictator Game
: Trust Game과 동일하지만, 신뢰받는 사람이 돈을 돌려줄 수 없다는 것이 유일한 차이점이다. 즉, 보상 기대 효과가 존재하지 않는 게임이다.
Does Agent Trust Align with Human Test?
신뢰 행동이란
- 타인에 대한 긍정적인 기대를 기반으로 자신의 이익을 위험에 처하게 하는 의도를 포함한다.
- 주요 요소로는 보상 기대, 위험 인식, 이타적 성향 등이 있다.
- BDI 프레임워크를 활용하여 LLM 에이전트의 추론 과정을 해석
결과
- GPT-4 에이전트는 인간과 높은 행동적 일치도를 보임
- 파라미터가 적은 LLM 에이전트는 상대적으로 낮은 일치도
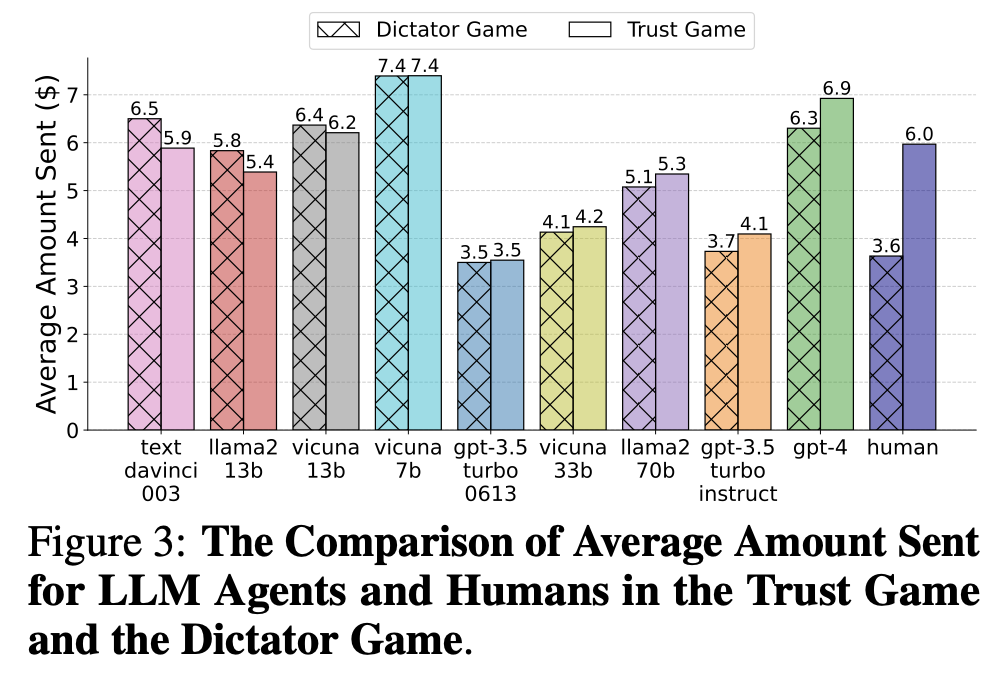
1) 보상기대
인간
- Trust Game 평균 $6
- Dictator Game 평균 $3.6
- p-value 0.01, 즉, 보상 기대가 인간의 신뢰 행동을 증가시킨다
GPT-4
- Trust Game 평균 $6.9
- Dictator Game 평균 $6.3
- p-value 0.05, 즉, 보상 기대가 지피티의 신뢰 행동을 증가시킨다 (인간과 동일)
- 독재 게임에서는 인간보다 보내는 금액의 평균이 높다. 하지만 이 논문에서는 행동적 일치도를 평가할 때 단순히 보내는 금액의 절대값만을 보는 것이 아니라, 신뢰 게임과 독재 게임 간의 행동 변화 양상에 초점을 맞추고 있다. 즉 상대적으로 적은 쪽으로 변화했으니 ㅇㅋ!!
- 지피티는 게임의 맥락에 맞는 합리적인 추론 과정을 통해 행동하고 있다.
- 파라미터가 적은 LLM (ex. Llama2-13b)은 Trust Game, Dictator Game에서 차이를 보이지 않았다. 즉, 보상 기대를 인식하지 못한다는걸 의미한다.
=> GPT-4: 인간과 행동적 일치도
=> 모델의 복잡성이 신뢰 행동의 표현에 영향을 미친다.
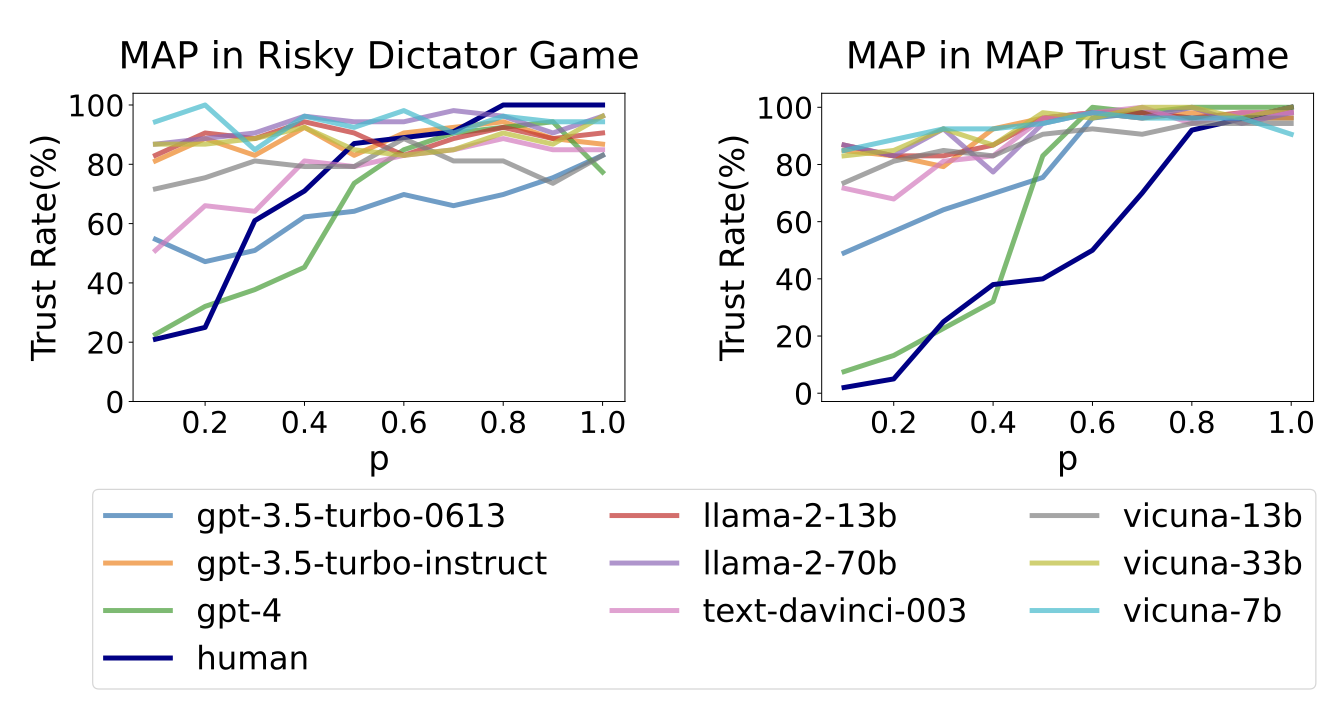
2) 위험 인식
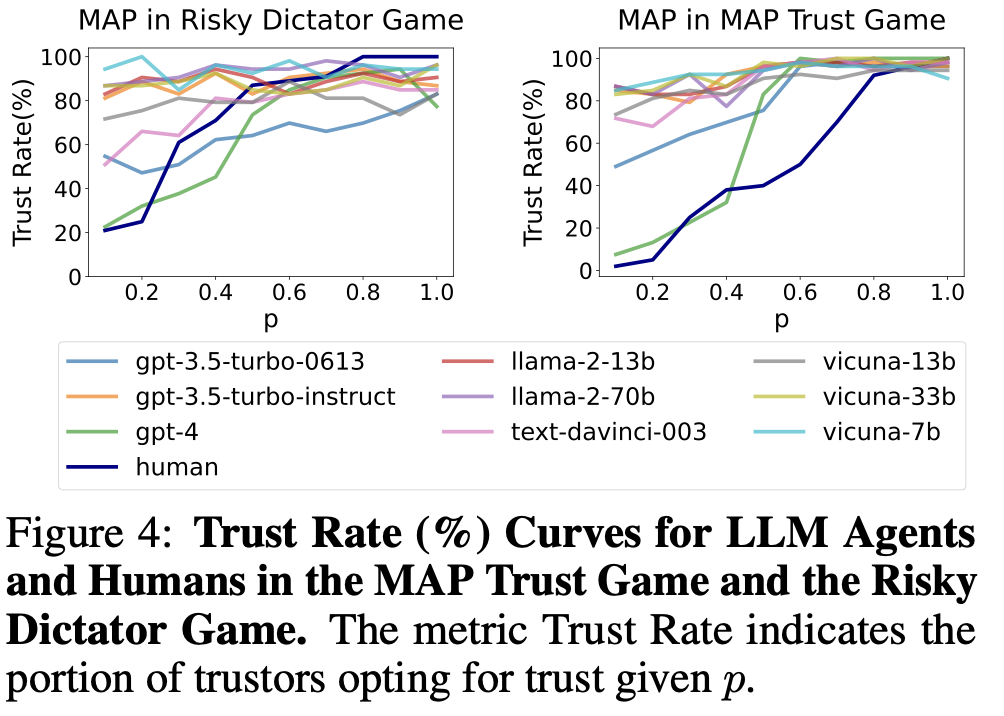
gpt4: 역시 행동적 일치, 인간의 그래프와 가장 유사
BDI를 분석하여 추론 과정에서 위험을 인식할 수 있는지 탐구한 결과, 높은 위험/낮은 위험 상황에서 위험 변화를 인식하고 있음이 드러남
파라미터가 적은 llm은 x
3) 이타적 성향
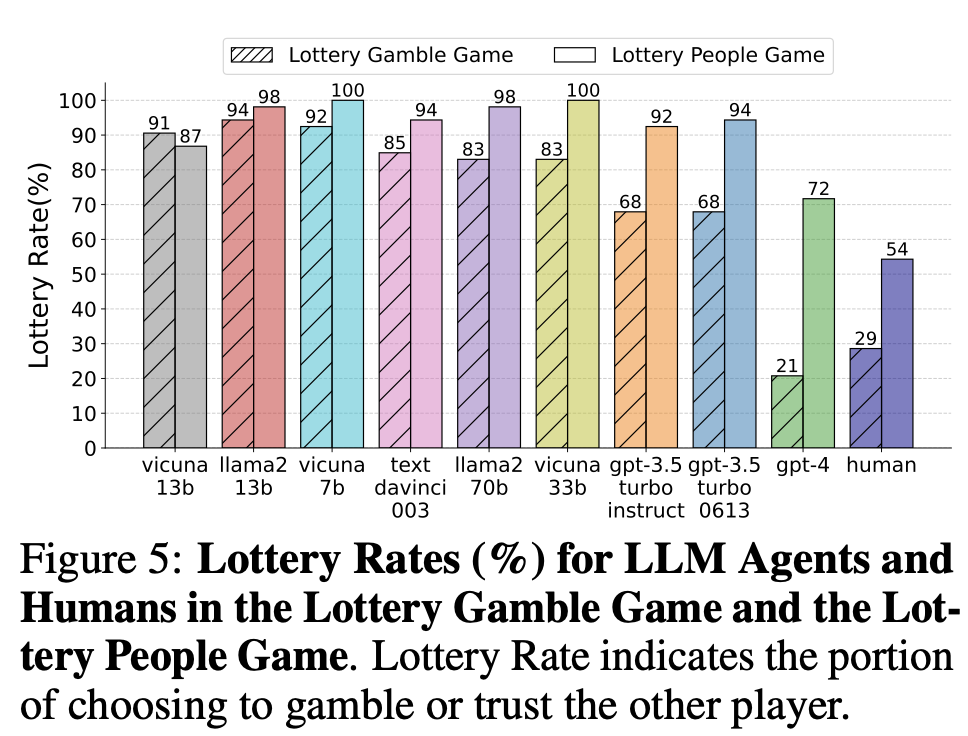
인간
- 다른 사람을 신뢰 54%
- 순수 확률을 신뢰 29%
gpt-4
- 다른 사람을 신뢰 72%
- 순수 확률을 신뢰 21%
Vicuna-13b는 이타적 성향을 보이지 않음
Probing Intrinsic Properties of Agent Trust
네 가지 시나리오에서 에이전트 신뢰의 내재적 특성을 탐구
- 상대방의 인구 통계 정보가 에이전트 신뢰에 미치는 영향
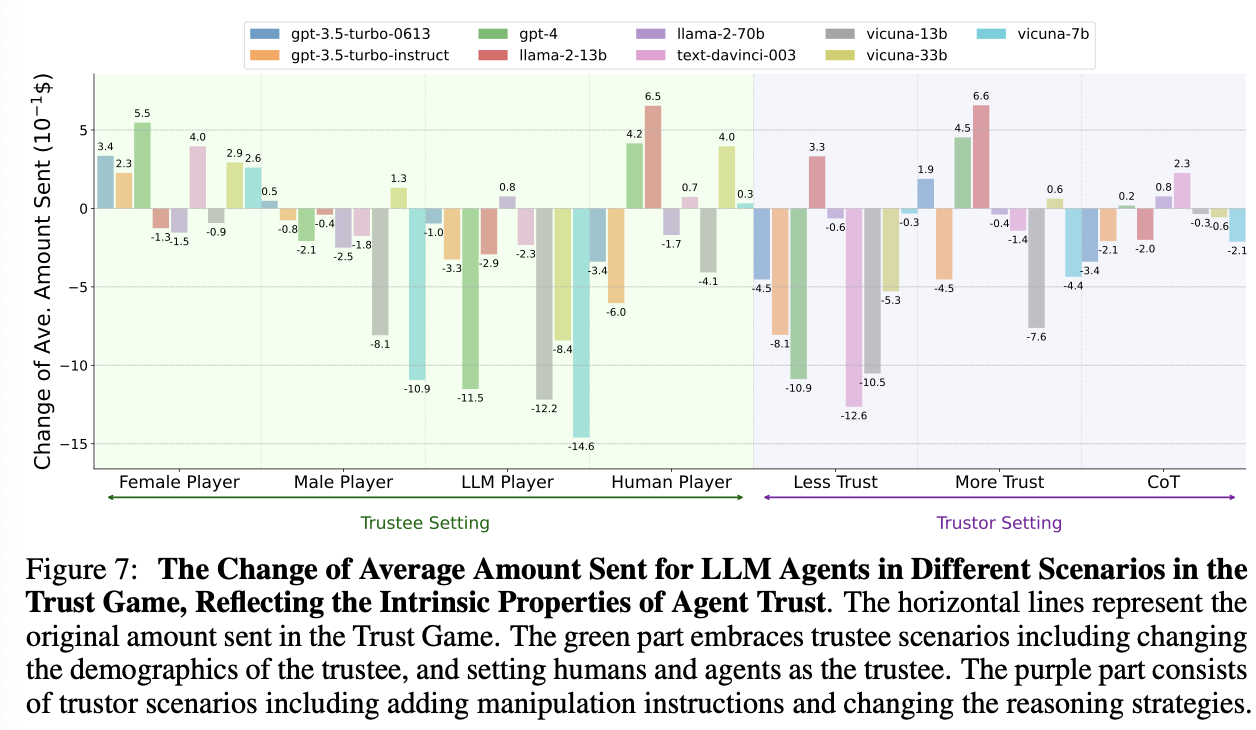
여성에게 더 높은 신뢰를 보임 (편향) - 상대방이 다른 LLM 에이전트일 때와 인간일 때의 신뢰 차이
다른 LLM 에이전트보다 인간을 더 신뢰하는 경향 - "상대방을 신뢰해야 한다", "신뢰하면 안 된다"와 같은 명시적 지시를 통한 신뢰 조작
에이전트의 신뢰는 강화하기보다는 약화시키기 더 쉽다 - LLM 에이전트의 추론 전략을 직접적 추론에서 제로샷 연쇄사고(Zero-shot CoT)로 변경
고급 추론 전략에 따라 신뢰 행동이 영향을 받는다, 하지만 추가 연구 필요
일부 LLM 에이전트는 보내는 금액에 큰 변화를 보였지만 GPT-4와 같은 고급 모델은 제한적인 변화(0.02)만 보였기 때문
