LLM: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (RAG)
RAG
2020.05
https://arxiv.org/pdf/2005.11401
abstract & introduction
LLM so far: downstream NLP task를 fine tuning하여 sota 달성, but knowledge-intensive task에서는 성능이 떨어짐
- Hallucination
- 예측 근거 제공 불가
- 추가 학습을 시키지 않으면 지식 업데이트(확장/수정) 제한적
Pre-trained parametric memory + non-parametric memory 를 결합한 RAG 모델 제안
Parametric: pretrained seq2seq model
Non-parametric: Wikipedia의 dense vector index
RAG 모델의 두 가지 방식:
Conditions on the same retrieved passages across the whole generated sequence: RAG-sequence
Use different passages per token: RAG-token
세개의 ODQA 태스크에 대해 sota 달성, 언어 생성 작업에서도 더 풍부하고 사실적인 언어
매개변수 기반의 seq2seq 모델, task specific retrieve and extract architecture 능가
KIT란?
Knowledge Intensive Task
단순히 질문에 답변하거나 간단한 데이터를 처리하는 것을 넘어서, 광범위하고 복잡한 지식에 의존해야 하는 작업이다.
외부 지식에 의존해 문제를 해결해야 함
사실적 정보나 전문 지식에 대한 접근과 활용이 필수적
Fact checking, open-domain question answering, slot filling 등의 태스크로 구성
ODQA를 포함하는 개념
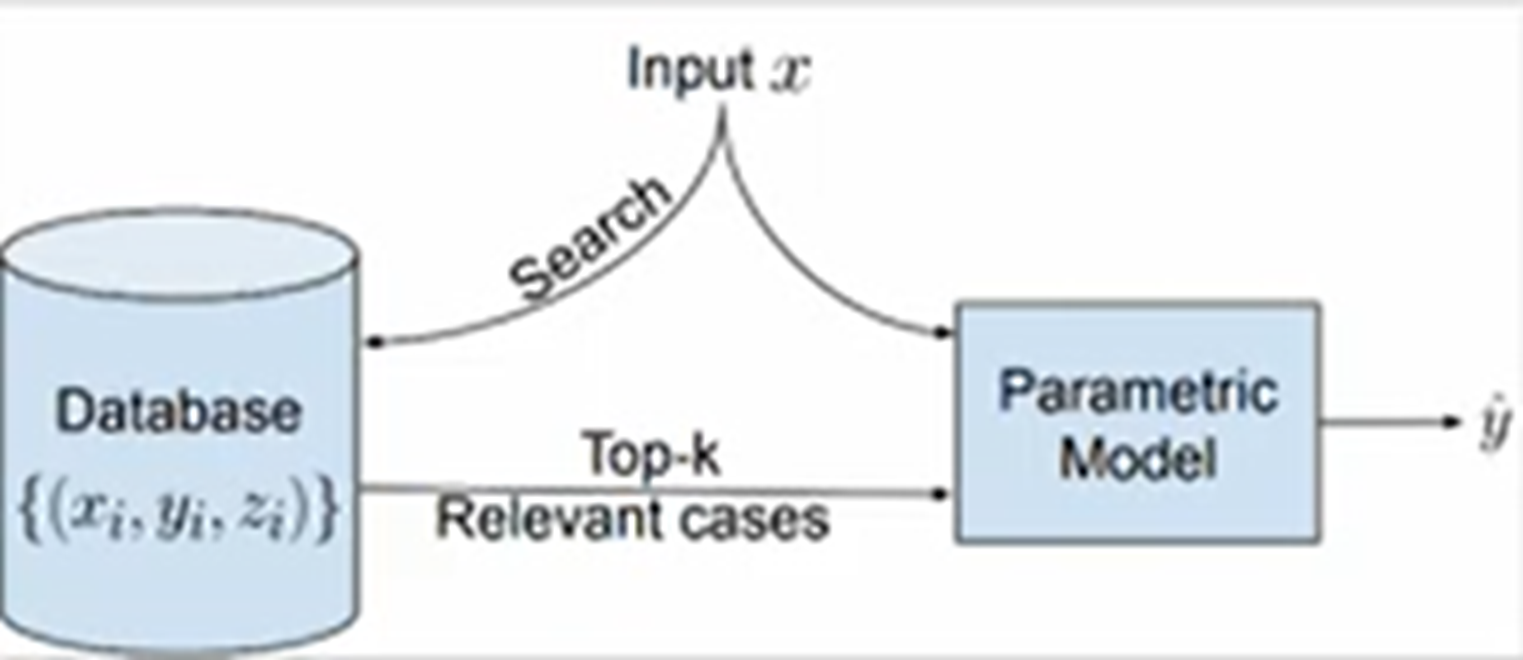
ODQA란?
Open-Domain Question Answering task
질문이 주어지면 그 질문에 가장 적절한 자료를 찾고 / 그 자료에서 정답을 찾는 task
대규모의 외부 데이터를 바탕으로 함
Question) 양조의 과정은 어떤 것이 있나요?
Passage) 양조가 이루어지는 데에는 제맥아, 제분, 담금, 끓임 등의 과정을 거친다
Answer) 제맥아, 제분, 담금, 끓임
위처럼 passage에서 answer를 찾는다.
연속된 토큰으로 이루어진 경우가 많으며, 연속된 토큰이 아닐 경우 성능이 떨어지는 문제가 있을 수 있다.
(참고 https://www.youtube.com/watch?v=gtOdvAQk6YU)
methods
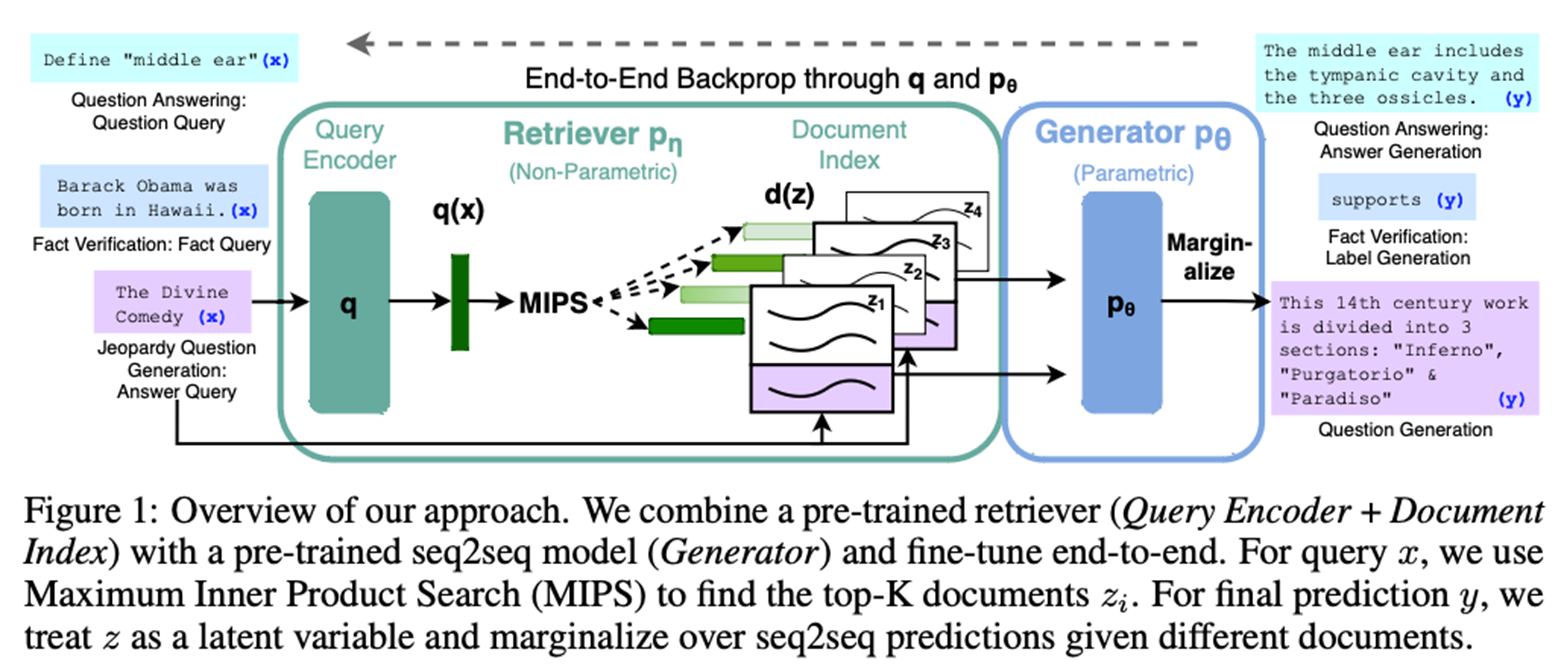
Retriever: p에타
input: seq x (query)
doc z 검색
Generator: p세타
input: seq x(original query), z(검색된 passage), y_1:i-1(previous tokens)
output: target seq y
-
RAG-sequence
동일한 문서를 사용하여 각 target token 예측
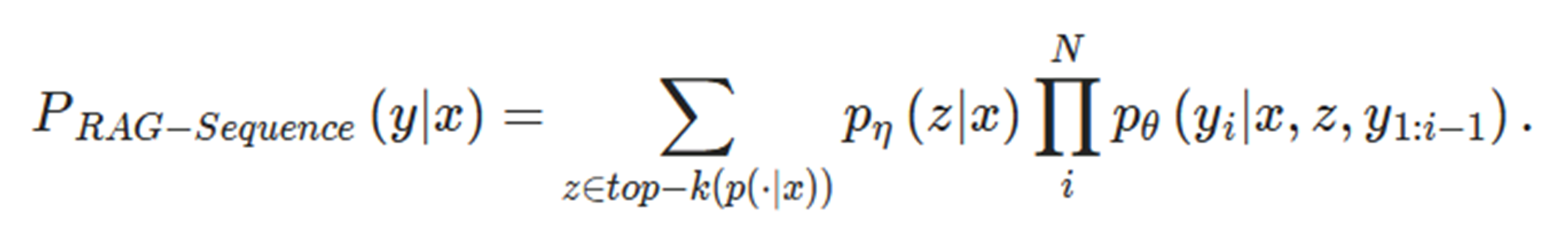
-
RAG-token
다른 문서를 기반으로 각 target token 예측
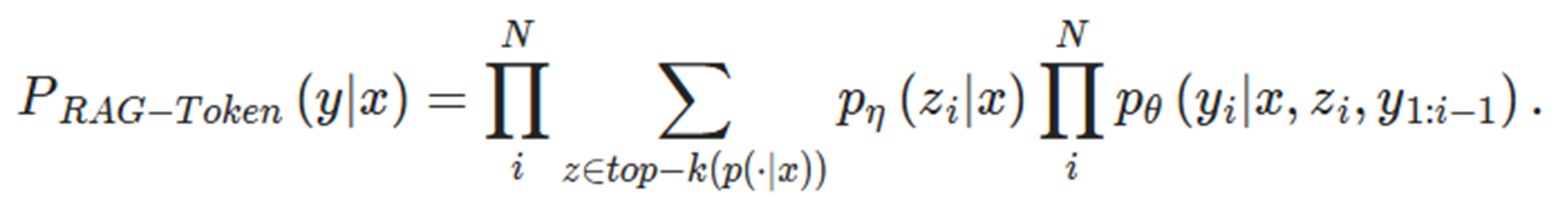
수식에 공통으로 p에타, p세타가 있는데 RAG-token만 모든 z를 다 고려하고 있다는 차이점이 있음
Retriever: DPR
DPR: Dense Retrieval 기반의 정보 검색 시스템
질문과 문서를 벡터 공간에 임베딩하여 유사도 계산
문맥적 의미를 반영한 dense vector를 생성
Dual Encoder 구조
Query Encoder
질문을 입력받아 벡터 공간으로 임베딩
Passage Encoder
데이터베이스에 있는 모든 문서를 임베딩 벡터로 변환하여 미리 저장
검색
두 벡터 간의 내적을 계산하여 유사도가 높은 상위 k개의 문서를 반환 - MIPS (Maximum Input Product Search)
TriviaQA question과 Natural Question 으로 미리 fine-tuning 된 모델 사용
검색한 문서의 weight를 결정하여, 답변 생성 과정에 영향을 미침
Generator: BART
Generator로 BART-large모델(pretrained seq2seq)을 사용
To combine the input x with the retrieved content z when generating from BART, we simply concatenate them
Training
검색할 document 에 대한 direct supervision 없이 공동으로 학습
Adam optimizer를 사용
Document encoder 는 고정(비용 문제), query encoder 와 generator 만 finetuning
experiment
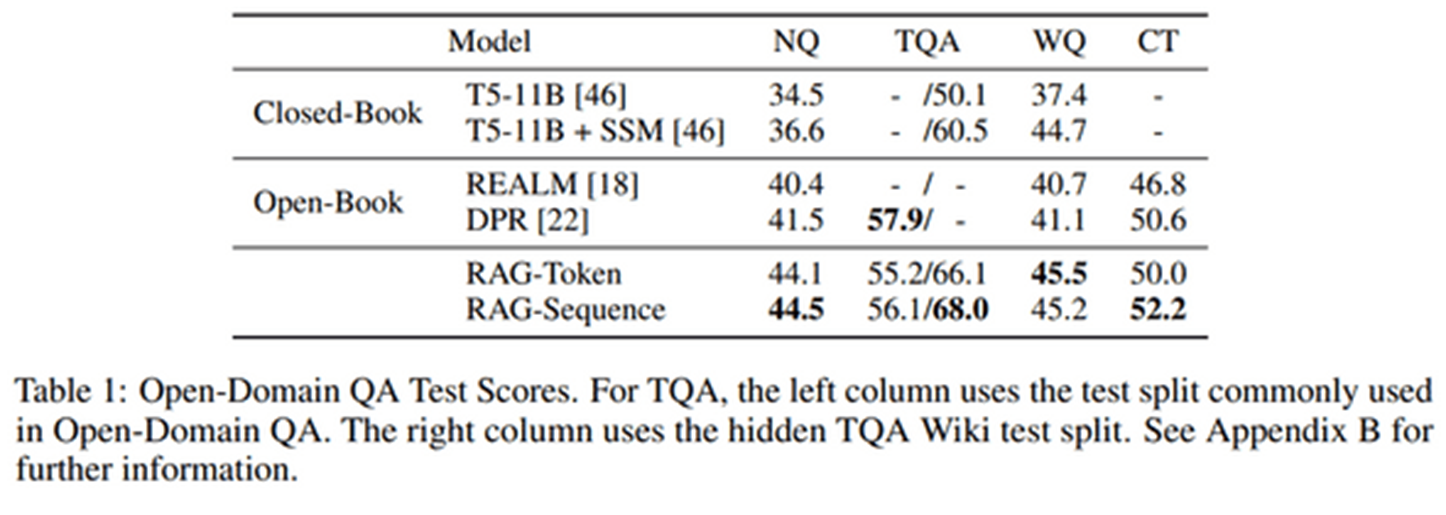
ODQA 하나 빼고 sota
closed-book: 외부 데이터를 사용하지 않았다 - 기존의 사전학습으로만 진행되는 LLM
open-book: 외부 데이터를 썼다 - 기존의 retrieval LM
open-book 모델들과 RAG 비교하면 됨
conclusion
LM의 사전학습 단계에 검색 기능을 더한 REALM / 생성 기능이 없는 DPR과 달리
- RAG는 검색 모델 + 생성 모델을 통합하는 새로운 아이디어 제시
- Knowledge-intensive task에 있어 성능 향상
- Hallucination 해결 방안 제시
