Large Language Models are Easily Confused: A Quantitative Metric, Security Implications and Typological Analysis
Large Language Models are Easily Confused: A Quantitative Metric, Security Implications and Typological Analysis
arxiv
2025.02
abstract
문제: language confusion
연구 주제: llm의 취약성에 언어적 규칙성이 존재할 수 있다고 가정하고, 다양한 LLM에서 언어 혼동이 발생하는 패턴을 분석 & 새로운 metric 제안
검증: LCB와 비교
추가 연구: LLM 보안과도 연결될 수 있음을 설명, multilingual embedding inversion attacks에서 발생하는 일관된 패턴 발견
주요 contribution
- language confusion의 패턴 발견
- 새로운 metric; Language Confusion Entropy 제안
- 언어 간 유사성을 사전 정보로 활용하는 것이 LLM alignment 및 보안에 있어 유의미한 통찰을 제공한다는 것을 설명
intro
language confusion 문제: 모델이 생성한 응답이 원래 의도한 언어도 아니고, 문맥상 적절한 언어도 아닌 경우 발생
이를 각각 line level, word level에서 측정하는 지표로 wpr, lpr이 제안되었으나, 언어 분포 내의 미묘한 변화를 포착하지는 못했다.
- language confusion은 일반적으로 모델의 다음 토큰 분포가 flat할때 자주 발생하는 것으로 관찰되었다.
- 이는 단순한 성능 저하의 문제가 아니라 모델의 근본적인 취약성
- 이 취약성은 불균형적인 다국어 pretraining data에 기인
- 모델이 다룰 언어 수가 많아질수록 이 문제가 심화
motivation: language confusion 현상 및 그 역할을 규명
연구 문제
1. What measurable patterns characterize language confusion in LLMs, and how can these patterns be quantified effectively?
2. How do language similarities influence language confusion, and how can this knowledge be applied to enhance LLM alignment and security?
Explainable Language Confusion
데이터셋: 1) LCB, 2) MTEI (Multilingual Textual Embedding Inversion)
세팅
- LLM이 n개의 소스 언어로 학습되었거나 프롬프트된 상황을 고려
- 는 목표 언어
- MTEI 데이터셋에 대해서는, inversion 모델을 사용한다. 언어를 포함해서 훈련된 복원 모델이 임베딩을 복원한다.
LCB: 프롬프트-응답 관점에서 language confusion 분석
MTEI: 임베딩 복원 관점에서 language confusion 분석
Monolingual Generation
LCB: 목표 언어 로 질의하면 모델의 응답도 여야 함
MTEI: 언어에 대해 훈련된 복원 모델이 임베딩을 복원한다.
Crosslingual Generation
LCB: 소스 언어 로 지시를 주고, 목표 언어 로 응답하도록 요구한다. ()
MTEI: 언어 세트에 대해 훈련된 복원 모델이 임베딩을 복원한다.
Quantifying Language Confusion
language confusion을 수치적으로 측정하기 위해 제안한 지표: Language Confusion Entropy()
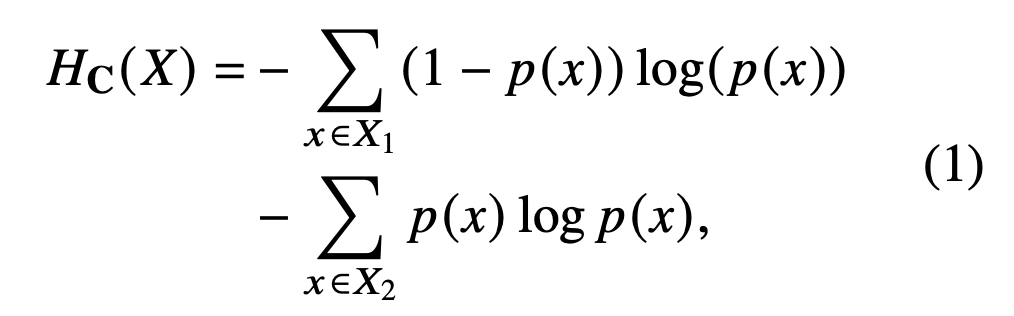
- : 예상된 언어 세트
- : 예상되지 않은 언어 세트
- : 전체 토큰 집합, 이 두 집합은 겹치지 않음
- : 특정 토큰 x가 생성될 확률(확률 분포를 따름, 즉 합이 1)
모델이 예상 언어 외에 다른 언어에 확률을 분산시키는 정도가 클수록 이 엔트로피 값이 더 커지고, 혼동이 심하다는 증거가 됨
Language Identification
Lingua + fastText로 보완
- word level
- 텍스트를 줄 단위로 분할한 뒤, 언어별 전용 토크나이저를 사용하여 줄 내부 단어들을 토큰화
- 토큰에 대해 각 언어 식별
- line level
- 줄바꿈 문자를 기준으로 분할한 뒤, 각 줄의 언어를 식별
The role of language similarity in Language Confusion
KL Divergence로 language confusion과 language similarity 차이를 정량화한다.
KL divergence는 차이를 뜻하기 때문에, 값이 작을수록 강한 상관관계가 있는 것이다.

M1: confusion score행렬
M2: similarity score행렬
여기서 similrariy matrics는 language graph를 통해 얻는다. (by calculating pairwise similarity using either Jaccard Index or Cosine Similarity)
각 열은 특정 언어를 나타내고, 행은 그 언어와 상대적인 다른 언어를 나타냄.
=> 각 열은 하나의 언어가 다른 언어들과 얼마나 혼동되거나(M1) 유사한지(M2)를 나타내는 벡터
출력값: 전체 열에 대한 평균 KL divergence 값
Analysis and Results
Language Confusion in LLM Prompting
Language Confusion Entropy (LCE) vs. Pass Rates
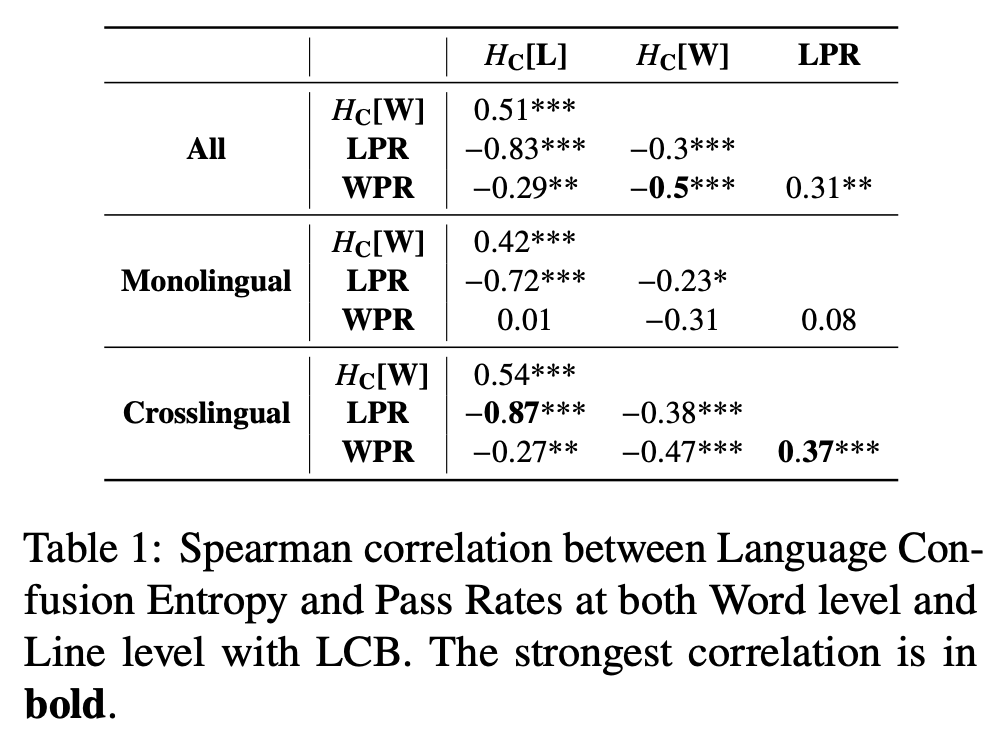
엔트로피 = 혼잡도, pass rate = 정답률. 음의 상관관계가 높아야 함
- spearman 상관계수 사용
- 전반적으로, line level의 language confusion entropy는 LPR과 강한 음의 상관관계를 보임
- word level의 엔트로피는 더 정교한 언어 분포에 기반해 계산되지만 WPR은 비라틴 문자 언어 내의 영어 단어만 고려하기 때문에 상관관계가 더 약했다.
- 문장/단어 수준 모두에서 엔트로피는 다국어 환경에서 더 높은 상관성을 보임. 즉, 단순한 정답률보다 다양한 언어 분포를 고려했기 때문이라고 설명
LCE across LLMs

- word level 혼잡도 > line level 혼잡도
- command 계열 llm, gpt 계열: 혼동 수준 낮은 편
- mistral, llama 계열: 높은 편
비라틴 문자 언어: 지속적으로 높은 엔트로피값
라틴 문자 기반 언어: 대부분의 모델에서 낮은 엔트로피값, 특히 gpt-4 turbo와 command R+에서 두드러짐
Language Confusion Entropy Across Data Sources
monolingual 환경에서, 프롬프트의 중간 단어 길이와 language confusion이 연관됨
- 패턴
데이터셋: LCB 중 complex prompts 데이터셋이 모든 언어에서 가장 높은 혼동을 보였음
모델: ShareGPT가 대부분 언어에서 가장 낮은 혼동을 보임(프랑스어, 스페인어 제외)
Language Confusion Entropy for Train Languages
inversion model 을 학습시킬 때
- 단일언어로 훈련시켰을 때 language confusion이 가장 적게 나타났다
- 같은 문자체계 또는 같은 계통 언어와 함께 훈련한 경우(= 비슷한 언어) 혼동 수준이 오히려 더 높았다
- KL divergence 분석을 통해, 언어 혼동과 언어 간 유사성 사이의 상관관계를 분석
- 가장 높은 상관관계: 의미론 기반
- 언어의 계통이 언어 혼동을 설명하는 데에 적합하지 않았다.
- 언어 혼동은 언어 유형론과 높은 상관관계를 가짐
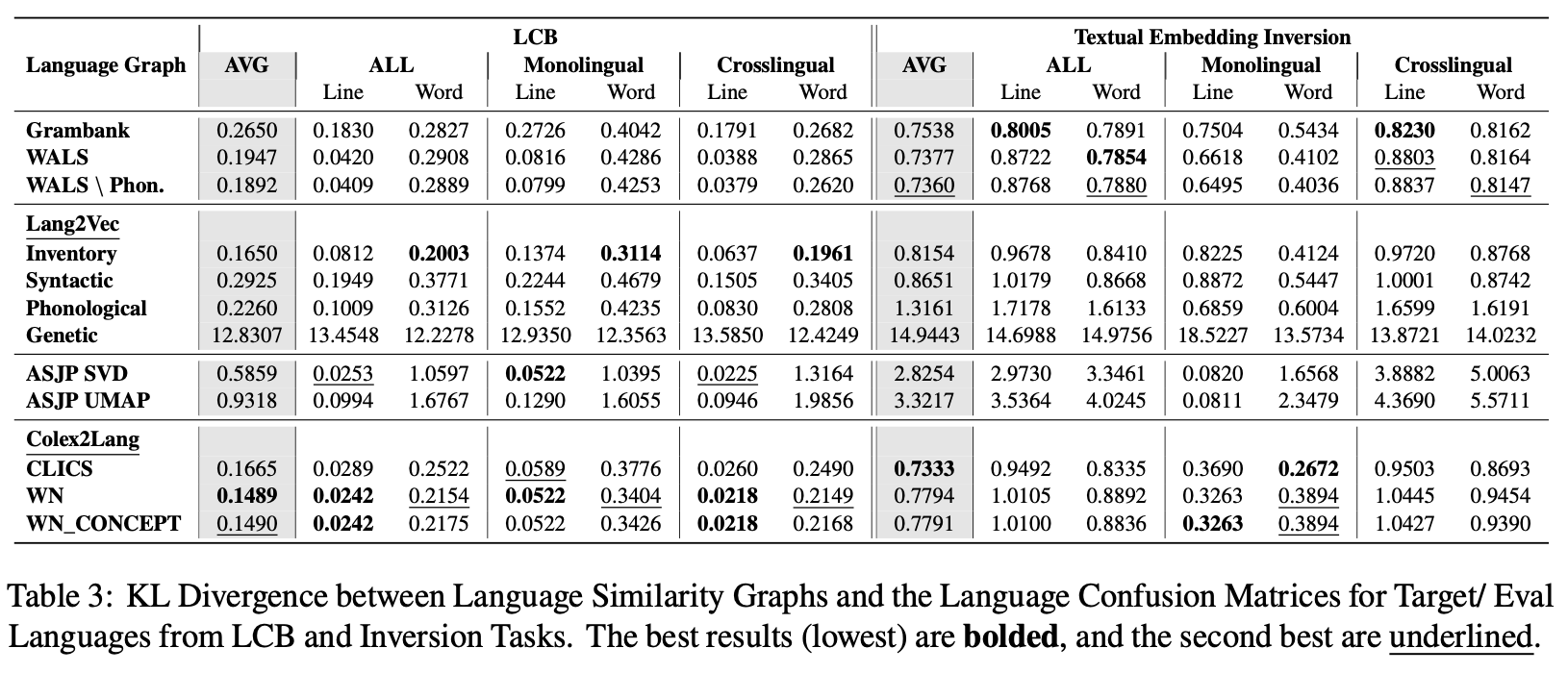
- inventory: 음운, 음절, 문법
- syntactic: 통사구조 기반 문법규칙, 문장구성방식
- phonological: 발음체계기반
- genetic: 계통적 분류
- WN, WN_concept: 의미론적 관계
- CLICS: 서로 다른 언어에서 같은 단어로 여러 개념을 표현하는 현상 기반
