vLLM & sgl
vLLM
vLLM이란
LLM을 효율적으로 서빙하는 데 사용되는 오픈소스 엔진 (모델 배포/서빙)
실시간 서비스로 배포하고 싶다 => vLLM이 적합하다. 서빙에 최적화
an LLM serving system that achieves
(1) near-zero waste in KV cache memory and
(2) flexible sharing of KV cache within and across requests to further reduce memory usage
KV cache: LLM이 쓸 기억 공간

: Memory layout when serving an LLM with 13B parameters on NVIDIA A100
여기서 parameter는 조절할 수 없고 KV cache를 잘 활용하는 것이 중요하다. KV cache는 request에 따라 동적(dynamic)으로 활용된다.
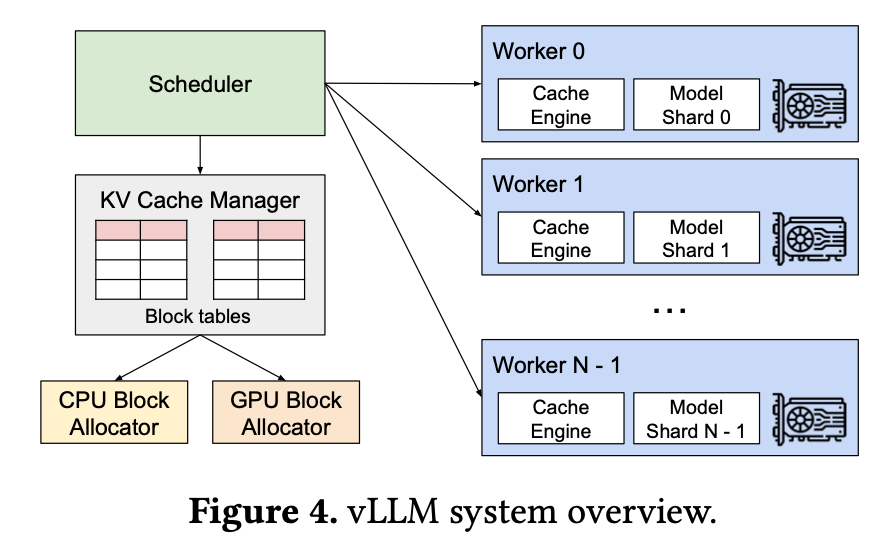
Paged Attention
=> 수천 개 request를 병렬 처리할 수 있음
기존: 각 토큰마다 KV cache를 새로 할당 - 한 사람의 request마다 긴 연속된 공간을 줬음
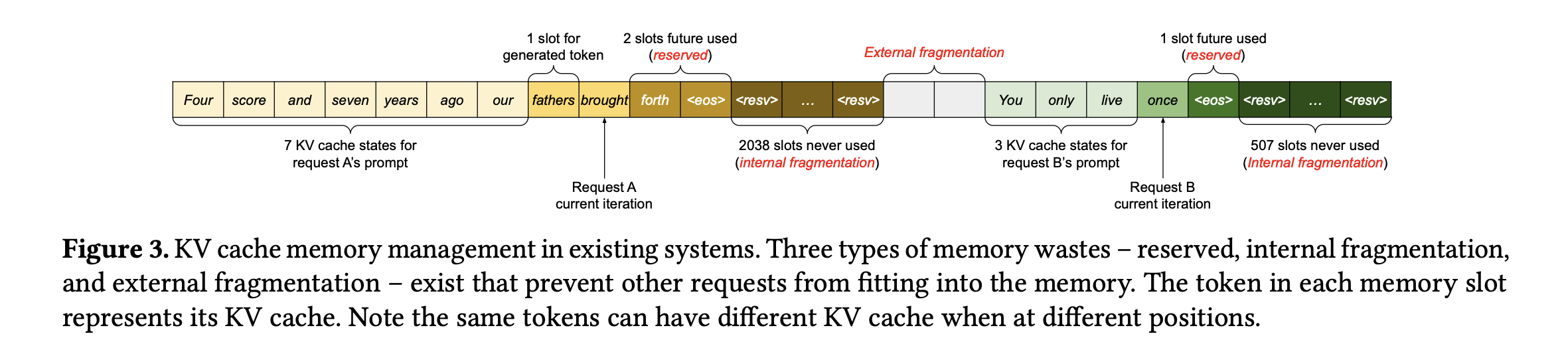
이때 메모리의 공간을 대부분 생성가능한 최대 길이로 할당한다.
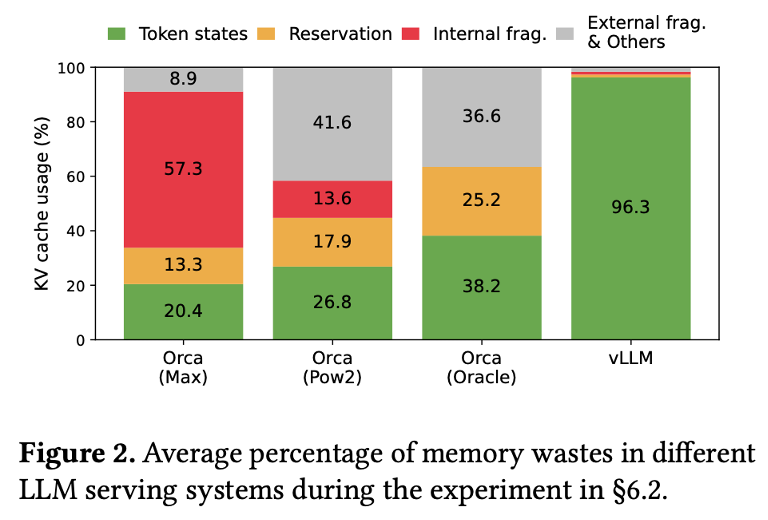
문제: 메모리의 파편화(조각조각 남음), 한꺼번에 여러 사람 처리하기 어려움
(1) reserved: 실제로 사용되는 공간
(2) internal fragmentation: 최대 길이에 도달 전 생성완료 되어 KV cache가 이루어지지 않은 공간
(3) external fragmentation: 각 request마다 사전에 할당된 공간의 크기가 다르기 때문에 생기는 할당 공간끼리의 비어 있는 공간
vLLM은 PagedAttention을 사용해 KV cache를 페이지 단위로 관리한다.
(페이지: GPU 메모리를 작은 조각으로 나눈 단위)
사용 코드
서버 실행 명령어
python3 -m vllm.entrypoints.openai.api_server \
--model facebook/opt-1.3bor
파이썬에서 직접 사용
from vllm import LLM, SamplingParams
# 모델 로드
llm = LLM(model="facebook/opt-1.3b")
# 생성 파라미터 설정
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=100)
# 프롬프트 입력
prompts = ["오늘 날씨 어때?", "vLLM의 특징은 뭐야?"]
outputs = llm.generate(prompts, sampling_params)
# 출력
for output in outputs:
print(output.outputs[0].text)메모리 사용을 효율적으로 해주는 것이지, 단일 inference 속도를 높이는 것은 아니다.
실제 코드 적용
llm = LLM(model="mistralai/Mistral-7B-Instruct-v0.1")
sampling_params = SamplingParams(temperature=0.8, max_tokens=128)이걸로 모델, 파라미터 등을 다 가져옴
- 모델, gen_kwargs 등 코드 필요없고 허깅페이스 모델을 내부적으로 자체 로딩 시스템으로 처리함
원래 넣었던
model = AutoModelForCausalLM.from_pretrained(
new_model_id, torch_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(new_model_id)
model.eval()이나, 파라미터 설정 등을 넣을 필요가 없었음
- 로그를 자동으로 찍어주는 것 같았음
INFO 05-08 23:58:25 [loader.py:458] Loading weights took 1.89 seconds
INFO 05-08 23:58:26 [gpu_model_runner.py:1347] Model loading took 13.4967 GiB and 3.030535 seconds
INFO 05-08 23:58:32 [backends.py:420] Using cache directory: /root/.cache/vllm/torch_compile_cache/ff91c8d4bb/rank_0_0 for vLLM's torch.compile
INFO 05-08 23:58:32 [backends.py:430] Dynamo bytecode transform time: 6.53 s
INFO 05-08 23:58:38 [backends.py:118] Directly load the compiled graph(s) for shape None from the cache, took 4.611 s
INFO 05-08 23:58:39 [monitor.py:33] torch.compile takes 6.53 s in total
INFO 05-08 23:58:41 [kv_cache_utils.py:634] GPU KV cache size: 53,456 tokens
INFO 05-08 23:58:41 [kv_cache_utils.py:637] Maximum concurrency for 32,768 tokens per request: 1.63x
INFO 05-08 23:59:06 [gpu_model_runner.py:1686] Graph capturing finished in 26 secs, took 0.51 GiB
INFO 05-08 23:59:07 [core.py:159] init engine (profile, create kv cache, warmup model) took 40.80 seconds등등
SGL
Supervised Fine-tuning Library
Deepseek 팀에서 공개한, SFT를 빠르게 할 수 있게 해주는 라이브러리
=> LLM을 파인튜닝하는 데 사용 (학습 단계)
특징
- 데이터 포맷 자동 처리
- LoRA 지원: 적은 리소스로도 모델 파인튜닝 가능
사용법
- 터미널에서 sgl train config.yaml 으로 실행시킨다.
config.yaml 예시
base_model: deepseek-ai/deepseek-llm-7b-base
tokenizer: null # null이면 base_model 기준으로 자동 설정됨
dataset:
path: data/train.jsonl # {"prompt": "...", "completion": "..."} 형식의 JSONL 파일
val_path: data/val.jsonl # 검증용 데이터 (선택)
max_seq_length: 2048
output_dir: output/sgl_run
training:
per_device_train_batch_size: 2
per_device_eval_batch_size: 2
gradient_accumulation_steps: 8
num_train_epochs: 3
learning_rate: 2e-5
lr_scheduler_type: cosine
warmup_ratio: 0.03
weight_decay: 0.1
logging:
eval_strategy: steps
eval_steps: 500
save_strategy: steps
save_steps: 500
logging_steps: 100
use_lora: true # LoRA 사용 여부
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
