Difference in two means with known population variances
use z statistic
두 모평균의 차이는 xˉ1−xˉ2로 나타낼 수 있다.
이를 예시에 적용해보면, 두 브랜드의 치약이 동일하게 효과적인가? / 두 브랜드의 타이어가 다르게 닳는가? 등이 있다.
CLT에 따라, x_1과 x_2의 표본의 크기가 모두 충분히 클 때(≥30), xˉ1−xˉ2도 정규분포를 따른다.
ex. Suppose we want to conduct a hypothesis test to determine whether the average annual wage for an auditing manager is different from the average annual wage of an advertising manager, where auditing managers are population 1 and advertising managers are population 2.
A random sample of 34 auditing managers is taken.
A similar random sample is taken of 32 advertising managers.
The sample of auditing managers has a sample mean of $98,959 and a known population standard deviation of $12,709
The sample of advertising managers has a sample mean of $95,433 and a known population standard deviation of $15,997
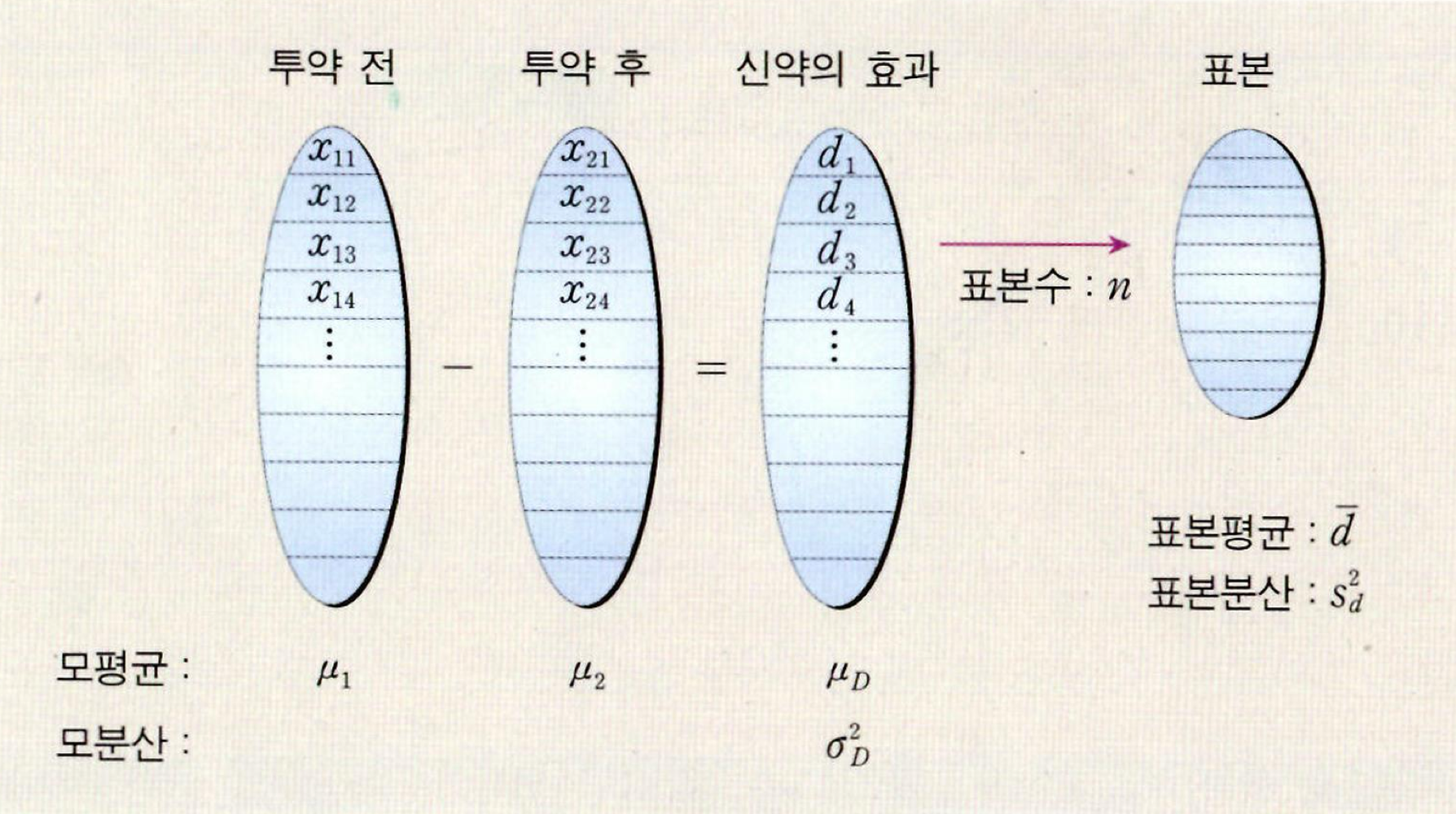
독립이 아닌 두 모집단의 차이이다. dependent samples, related samples를 다루기 위한 수단이다. Matched-pairs, correlated t test 로도 불린다.
예를 들면, 다이어트하기 전과 한 달 후의 몸무게처럼 동일한 개체에 대해 실험 전과 실험 후의 측정값의 차이를 추론할 수 있다. 두 모집단의 표본의 크기는 같아야 한다.
COMPANY 123456789 YEAR 1 P/E 8.938.143.034.034.515.220.319.961.9 YEAR 2 P/E 12.745.410.027.222.824.132.340.1106.5d−3.8−7.333.06.811.7−8.9−12.0−20.2−44.6
H0:D=0Ha:D=0
이렇게 데이터가 주어졌을 경우 각 짝 자료에 대해 차이(d)를 구하고, 그 평균과 분산도 직접 계산한다.
n=9,dˉ=−5.033,sd=21.599
t=sd/ndˉ−D=21.599/9−5.033−0=−0.70
귀무가설을 두 모집단에 차이가 없다는 것으로 설정했기 때문에 D=0 이다.
−3.355 < − 0.70 < 3.355 이기 때문에 H0 기각 실패
신뢰구간은 다음과 같다.
dˉ−tnsd≤D≤dˉ+tnsd,df=n−1
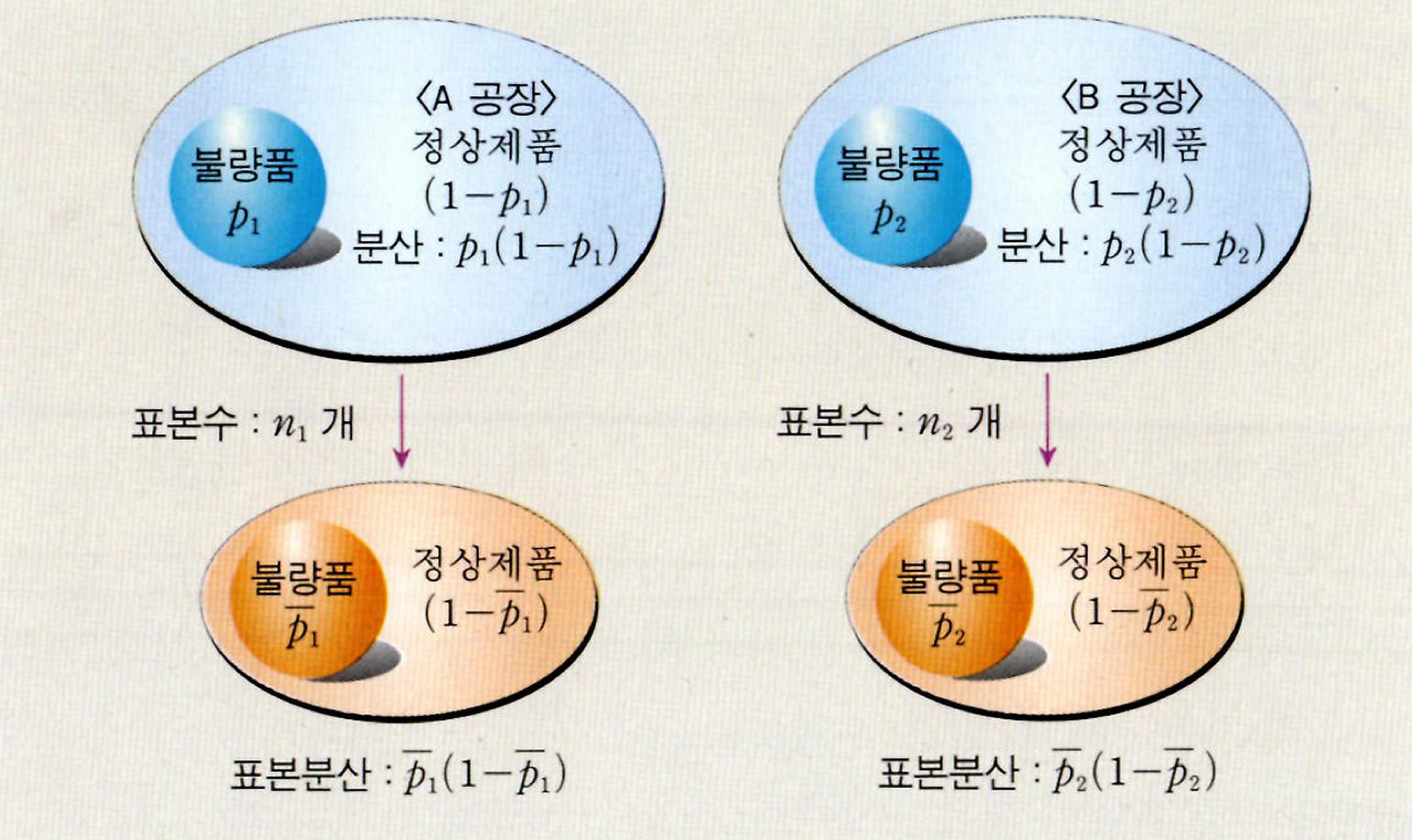
Difference in two population proportions
use z statistic
A집단의 불량률이 높은지, B집단의 불량률이 높은지 검정할 수 있다.
p1,p2는 모비율이다. q1=1−p1,q2=1−p2
CLT를 적용하려면, n1p^1,n1q^1,n2p^2,n2q^2>5여야 함을 잊지 말아야 한다.
pˉ=n1+n2x1+x2=n1+n2n1p^1+n2p^2 and qˉ=1−pˉ
Difference in two population variances
use F distribution
F분포란?
카이제곱분포는 한 정규모집단의 모분산을 추론하는 데에 사용되었다면, F분포는 두 정규모집단의 분산을 비교하는 데에 사용된다.
독립적인 카이제곱 변수 χn2와 χm2이 있을 때, X=χm2/mχn2/n는 자유도가 n, m인 F분포를 따른다.
X∼Fn,m
If X∼tn then X2∼F1,n
Fα,n,m is defined to be the value that satisfies Pr(X>Fα,n,m)=α where Pr(X>Fα,n,m)=α
F1−α,m,n=Fα,n,m1
P(X>Fa,n,m)=a
P(1/X<1/Fa,n,m)=a
P(1/X>1/Fa,n,m)=1−a
1/X=Y∼Fm,n
Thus F1−a,m,n=1/Fa,n,m
검정
samples must be random and independent
Each population must have a normal distribution
H0:σ12=σ22
test statistic: F=s22s12∼Fn1−1,n2−1
step1.
H0:σ12=σ22Ha:σ12=σ22
(two-tailed)
step2.
Since the population is normally distributed, the F test for the ratio of the variances can be used
step3.
type I-error : α=0.05
step4.
Two-tailed test with α/2=0.025,ν1=n1−1=9,ν2=n2−1=11
The critical F value for the upper tail is F0.025,9,11=3.59
How to compute the lower tail value using the table?
Use 1/F0.025,11,9≈1/3.92=0.26. Why?
Remember the property: F1−α,m,n=Fα,n,m1
step5.
데이터에서 표본분산 구했다고 가정 F=s22s12=0.020230.11378=5.62
The observed F value 5.62 is greater than the upper-tail critical value 3.59. Thus, reject the null hypothesis and conclude that the population variances are not equal.