
인덱스의 정의
- DB 테이블에 대한 조회 속도를 올려주는 자료구조
- B-Tree를 사용한다.
- 해당 칼럼의 데이터를 정렬 한 후 별도의 메모리 공간에 데이터의 물리적 주소를 올려서 만듦
인덱스 만들기
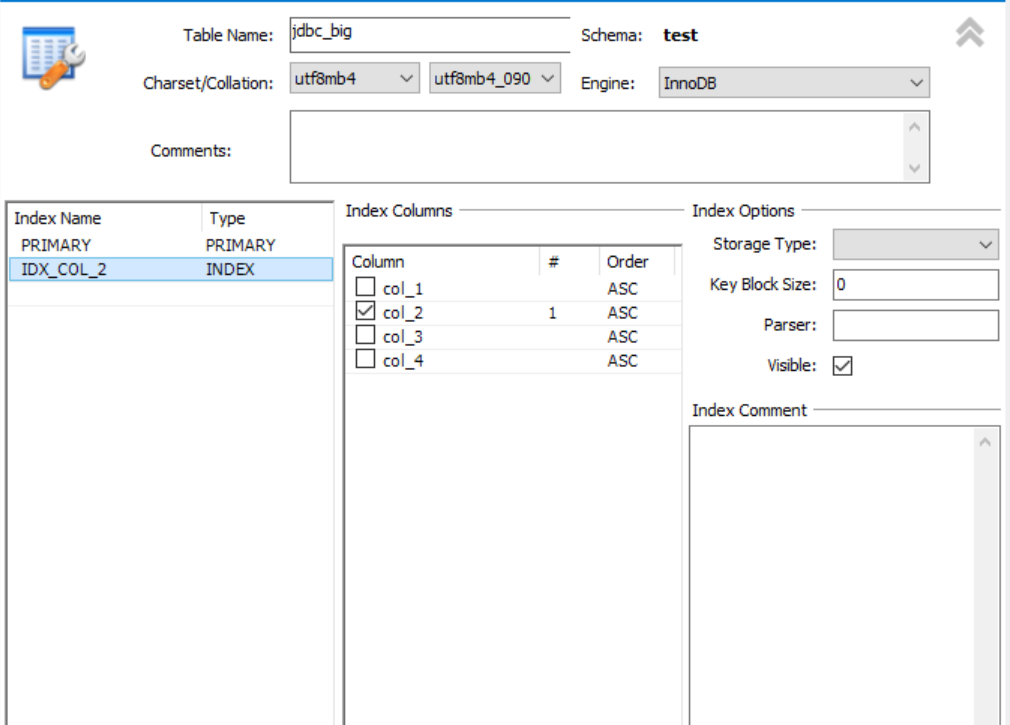
이렇게 칼럼 하나를 인덱스로 정의해도 되고
-- col_2에 대한 인덱스 생성
CREATE INDEX idx_col_2
ON jdbc_big (col_2);이런식으로 코드로 짜줘도 된다.
인덱스 자료구조
해시 테이블 (Hash Table)
해시 테이블은 Key와 Value를 한 쌍으로 데이터를 저장하는 구조이다.
O(1)의 시간복잡도가 생긴다.
그러나 해시 테이블은 인덱스에서 자주 사용되지 않는데, 해시 테이블은 등호 연산에 최적화 되어있어서 원하는 자료를 찾기위해 >,<가 자주 쓰이는 특성과 어울리지 않는다.
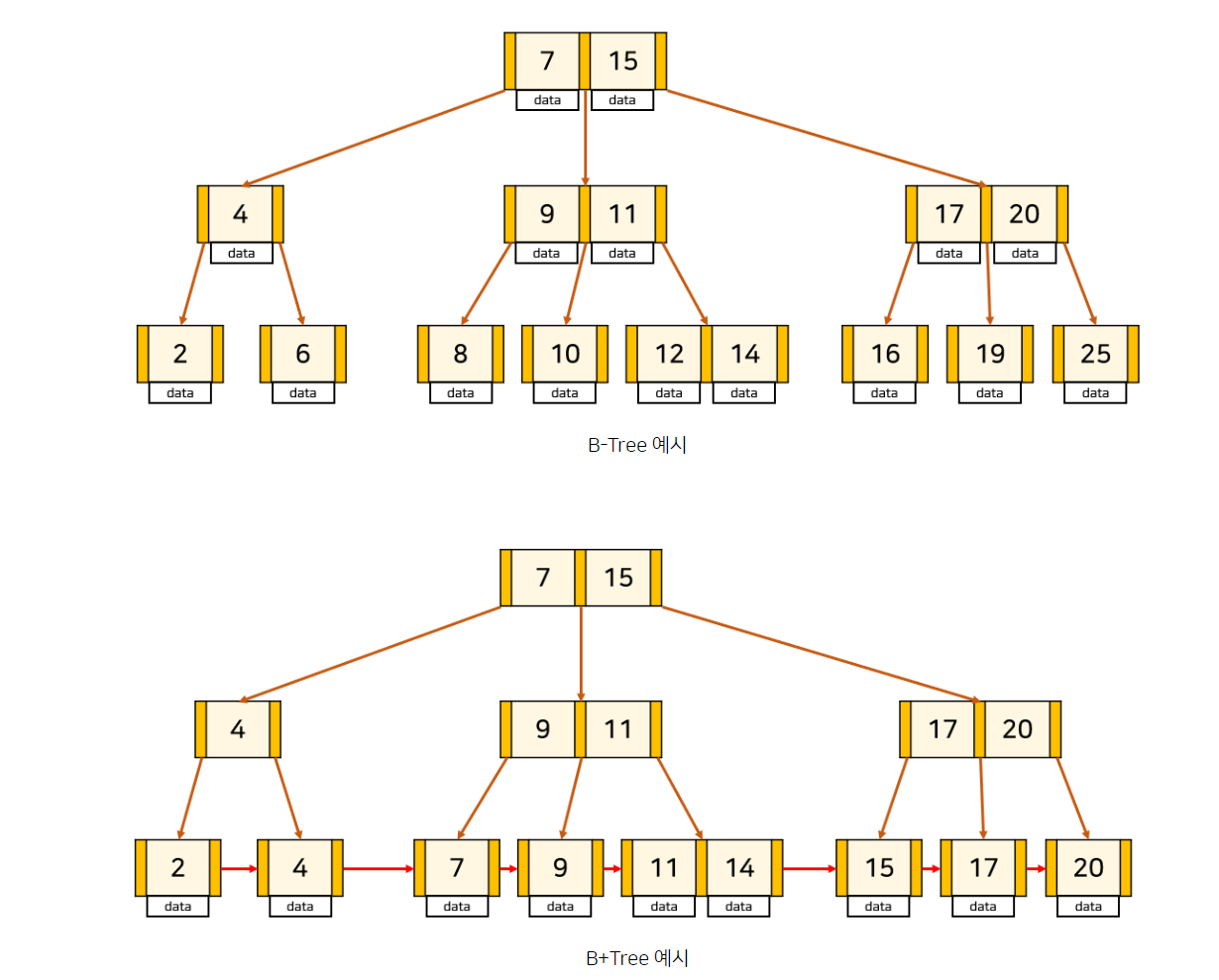
B+TREE
B Tree와 B+Tree가 있다.
기존의 B Tree는 데이터 검색을 위해서 트리의 모든 노드를 방문해야 하는 문제가 있는데 이것을 해결한 것이다.
B+TREE는 Leaf node에만 데이터를 저장하고 Leaf node가 아닌 node에는 자석 포인터만 저장한다.
그리고 Leaf node끼리는 Linked list로 연결되어 있다.
출처 : https://rebro.kr/167B+Tree의 장점
- leaf node를 제외하고 데이터를 저장하지 않기 때문에 메모리를 더 확보하고 node에 더 많은 포인터를 가질 수 있기 때문에 트리의 높이가 더 낮아지므로 검색 속도를 높일 수 있다.
- . Full scan을 하는 경우 B+Tree는 leaf node에만 데이터가 저장되어 있고, leaf node끼리 linked list로 연결되어 있기 때문에 선형 시간이 소모된다. 반면 B-Tree는 모든 node를 확인해야 한다.
인덱스의 장단점
- 검색 성능 향상:
인덱스를 사용하면 특정 조건에 맞는 데이터를 빠르게 찾을 수 있습니다. 예를 들어, WHERE 절이나 JOIN 절에서 자주 사용되는 컬럼에 인덱스를 생성하면 검색 속도가 크게 향상됩니다.- 정렬 속도 향상:
ORDER BY 절을 사용할 때 인덱스가 생성된 컬럼을 기준으로 정렬하면 정렬 속도가 빨라집니다.- 고유성 보장:
UNIQUE 인덱스를 사용하면 데이터베이스에 중복된 값이 삽입되는 것을 방지할 수 있습니다.- 성능 최적화:
인덱스를 사용하면 쿼리 최적화기가 최적의 실행 계획을 수립할 수 있어, 쿼리 성능이 최적화됩니다.
- 디스크 공간 사용 증가:
인덱스를 생성하면 데이터 외에도 인덱스 자체가 디스크 공간을 차지합니다. 대규모 데이터셋에 다수의 인덱스를 생성하면 디스크 공간이 많이 소모될 수 있습니다.- 쓰기 성능 저하:
데이터가 삽입, 업데이트 또는 삭제될 때마다 인덱스도 함께 업데이트되어야 하므로, 쓰기 작업의 성능이 저하될 수 있습니다. 특히, 빈번한 쓰기 작업이 있는 경우 인덱스가 성능에 미치는 부정적인 영향이 클 수 있습니다.- 복잡성 증가:
적절한 인덱스를 설계하고 관리하는 것은 복잡할 수 있습니다. 잘못된 인덱스를 생성하면 성능 저하를 초래할 수 있습니다.- 인덱스 재구성 필요:
시간이 지나면서 데이터가 변경되면 인덱스가 비효율적으로 변할 수 있습니다. 따라서 주기적으로 인덱스를 재구성하거나 다시 빌드해야 할 필요가 있습니다.

개발자를 꿈꿔요