
정규화
정규화란?
관계형 데이터베이스 설계 과정에서 데이터의 일관성, 최소한의 데이터 중복, 최소한의 데이터 유연성을 위해 사용된다. 정규화는 데이터베이스 테이블을 여러 테이블로 분할하고, 이러한 테이블 간의 관계를 정의함으로써 데이터를 더 효율적으로 저장하고 관리하기 위해 분해하는 과정이다.
정규화의 장점
- 불필요한 데이터를 제거하여 데이터의 중복을 최소화할 수 있기 때문에 저장공간을 효율적으로 이용할 수 있게 된다.
- 각종 이상 현상(Anomaly)를 방지할 수 있다.
- 테이블 데이터 집합이 논리적, 직관적으로 구성된다. (자료 구조가 안정적으로 변화한다.)
- 다양한 관점에서의 쿼리를 지원한다.
- 데이터 무결성 유지
정규화의 단계
1차 정규화
복수의 속성값을 갖는 속성 분리
PK(Primary key)에 대한 Atomic Value 확보
2차 정규화
주 식별자 전체에 종속적이지 않은 속성의 분리
부분 종속 속성(Partial Dependency Attribute)을 분리
3차 정규화
속성에 종속적인 속성의 분리
이전 종속 속성(Transitive Dependency)의 분리
1차 정규화
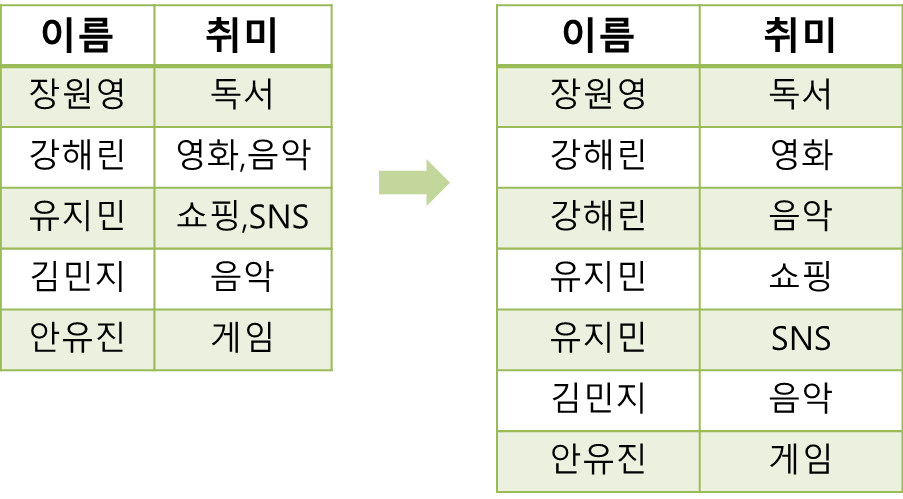
위 그림은 이름과 취미를 표현한 데이터인데 이름 하나에 취미가 2개 들어가 있는 사람들이 있다. 강해린과 유지민의 취미를 쪼개 '원자값'을 가지게 하는 것이 1차 정규화라 할 수 있다.
PK 하나에 두 개의 값을 나온다면 이걸 나눠주는 것이다.
2차 정규화

여기서 PK 값이 학생번호와 강좌이름이기 때문에 "강좌이름 -> 강의실"이 종속되어 있다.
여기서 몇 가지 문제점이 생기는데
- 삭제이상 -> 3번째 행 402번을 지우면 스포츠경영학 자료 자체가 사라진다.
- 삽입이상 -> 새로운 과목과 새로운 강의실이 생겨도 지원학생이 없다면 NULL 값으로 삽입해야하는 문제 발생한다.
- 수정이상 -> 1번째 행 데이터베이스 강의실을 변경할 경우 2번째 행의 데이터 불일치가 생긴다.
즉 PK 값이 두 개일 경우 이에 종속되는 데이터로 인해 꼬임현상이 발생한다.
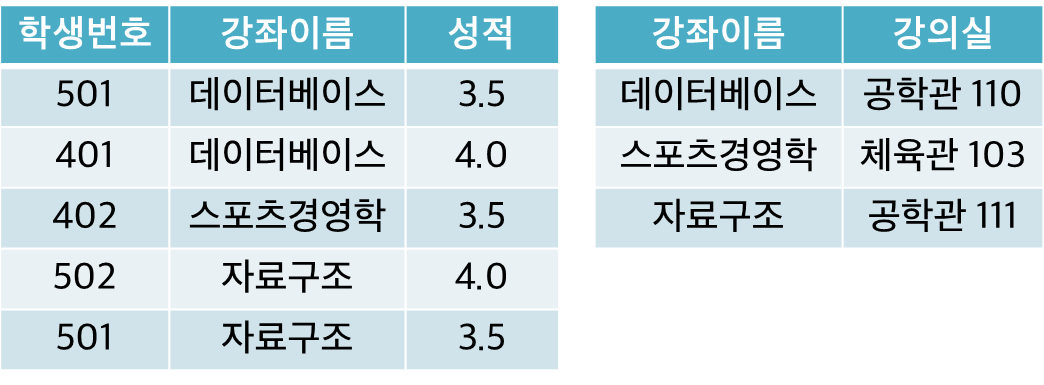
이렇게 [학생번호, 강좌이름] -> 강의실의 종속성의 경우에, 학생번호나 강좌이름 중 하나를 제거해도 종속성은 유지되기 때문에
수강강좌(학생번호, 강좌이름, 강의실, 성적)
-> 수강(학생번호, 강좌이름, 성적), 강의실(강좌이름, 강의실)
이 형태로 나누면 해결이 가능하다
3차 정규화
제3 정규화는 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다.
이행적종속
A -> B, B -> C 일 때, A -> C의 관계를 가지게 되는 것

위 표에서도 문제점이 발생하는데
- 삭제이상 -> 402번 학생이 수강을 취소하면 스포츠경영학 과목 수강료에 대한 정보가 사라진다.
- 삽입이상 -> 컴퓨터입문 과목이 생긴다고 가정할 때, 학생이 없어 NULL 값으로 삽입해야하는 문제 발생
- 수정이상 -> 데이터베이스 수업 수강료를 15,000원으로 변경할 경우 데이터 불일치 발생
위 표에서 PK 값은 학생번호, 나머지는 강좌이름과 수강료이다. 원래는 수강료가 PK 값인 학생번호에 종속되어 있어야 하지만 수강료는 강좌이름에 또 종속되어 있다.
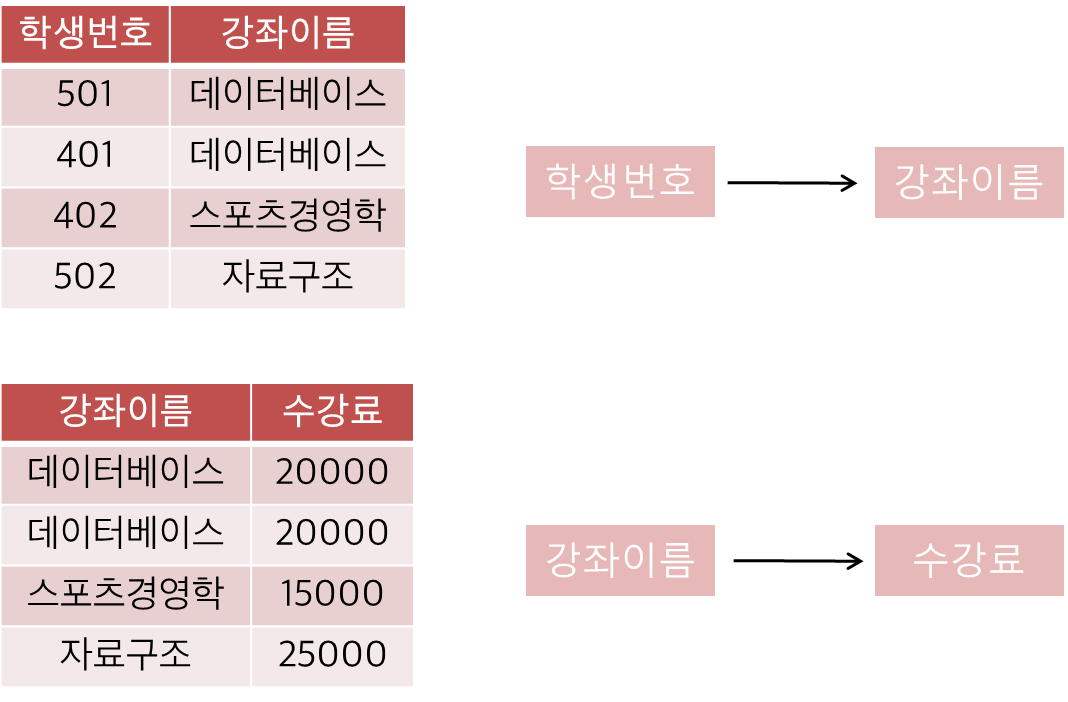
이렇게 이상현상을 일으키는 (강좌이름, 수강료)를 분해하여 따로 만들어준다.
