문자열 알고리즘 문제 풀이에 약점이 있다 느껴 최근 문자열 문제를 풀이하는 중
문자열 뒤집기 문제를 만났다.
문자열 뒤집기는 말그래도 주어진 문자열을 거꾸로 뒤집으면 되는데 직관적으로 생각할 수 있는 알고리즘의 시간 복잡도는 linear한 방법을 사용하게 될 것이므로 O(n)이다.
1번 방법
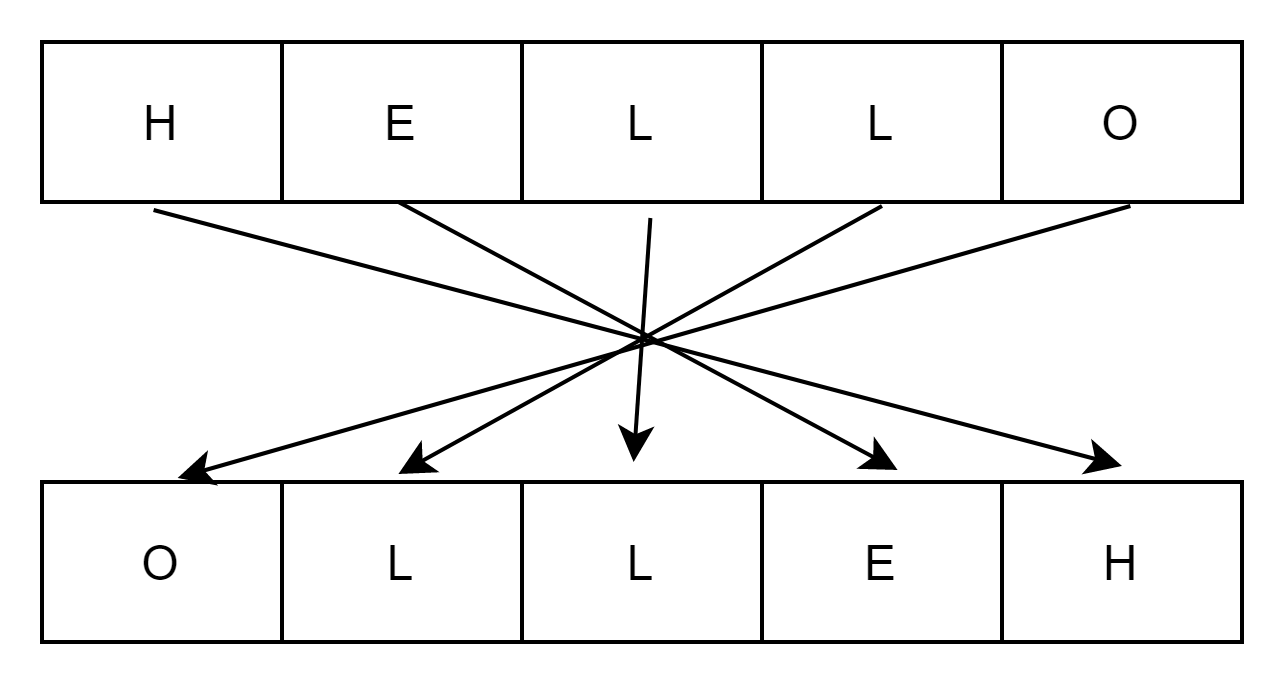
하지만 문자열이 충분히 긴 경우 이보다 더 짧게 문자열을 뒤집을 방법이 없을까 고민을 해보았다.
2번 방법
문자열 또한 배열이기때문에 문자열의 앞부분부터 맨 뒤에 부분과 바꿔주는 방법을 생각했다.
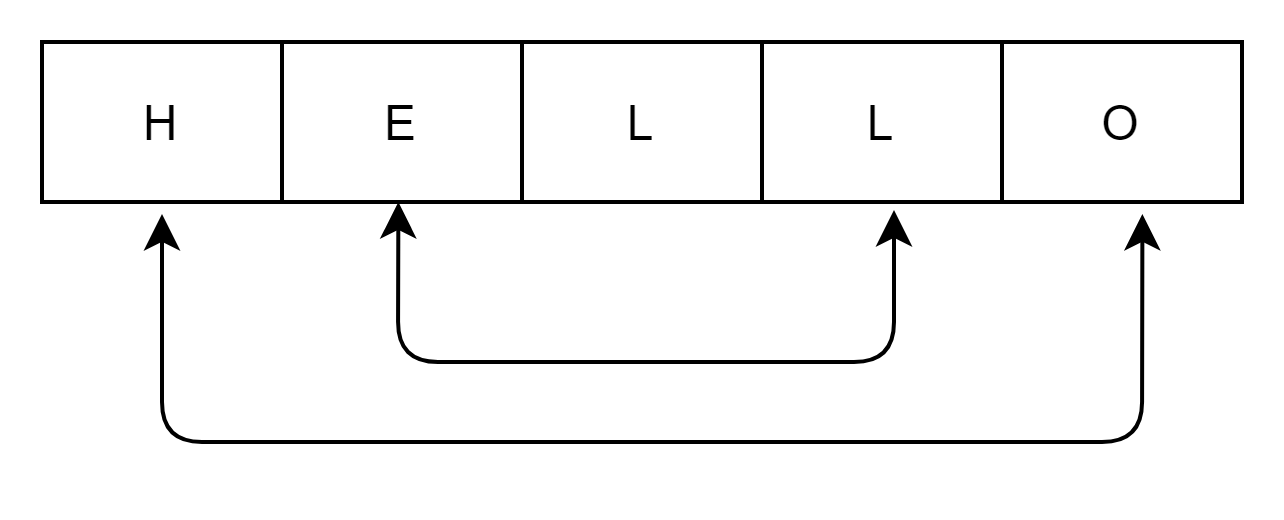
이런 식으로 생각할 수 있는데 이렇게 하면 O(n)인 것은 동일하지만 내부적으로 n/2 만큼 동작하기 때문에 시간을 더 줄일 수 있다.
또 자바에는 StringBuilder 라이브러리에 reverse라는 메소드를 제공하고 있다. 이를 사용했을 때 linear한 방법과 얼마나 시간 차이가 나는지 알아보았다.
천만개의 단어를 가진 문자열을 뒤집었을 때 결과다.
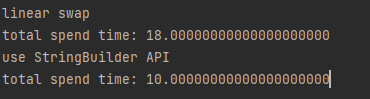
대충 이정도 차이가 났다. 왜 이런 차이가 났는지 자세히 알아보자.
https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/StringBuilder.html#reverse()
자바11 api 문서의 StringBuilder 항목을 보면 알 수 있다. 설명을 읽어 보면 리버스한 문자열의 k번째에 들어가야할 문자는 기존 문자열의 n-k-1의 문자와 같기 때문에 바꿔주는 것으로 얻을 수 있다고 설명하고 있다.
즉, 2번 방법을 사용하고 있음을 알 수 있다.
문자열 뒤집기를 통해 같은 결과를 얻더라도 간단한 휴리스틱 적용으로 시간을 절약할 수 있음을 알아보았다.
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
public class Main {
static int Answer;
static int n, m;
static int[] p, rank, arr;
static ArrayList<String> ans;
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
String str = "A".repeat(1000000);
String rstr = "";
System.out.println("linear swap");
double start = System.currentTimeMillis();
StringBuilder sb = new StringBuilder();
for (int i = str.length() - 1; i >= 0; i--) {
sb.append(str.charAt(i));
}
rstr = sb.toString();
double end = System.currentTimeMillis();
System.out.println("total spend time: " + String.format("%.20f", end - start));
System.out.println("use StringBuilder API");
start = System.currentTimeMillis();
sb = new StringBuilder(str);
rstr = sb.reverse().toString();
end = System.currentTimeMillis();
System.out.println("total spend time: " + String.format("%.20f", end - start));
bw.flush();
bw.close();
br.close();
}
}