Introduction
1-1. 기계 번역의 발전 과정
기계번역 : 인간이 사용하는 자연 언어를 컴퓨터를 사용하여 다른 언어로 번역하는 일
Seq2Seq까지는 고정된 Context Vector를 이용하여 기계번역을 함
1-2. SMT
Statistical Machine Translation; 통계 기반 기계 번역을 의미
긴 문장 처리가 어려운 특성을 가지고 있어서 N-gram으로 인접한 일부 단어만 고려
Related Work
2-1. DNN ; Deep Neural Network
까다로운 learning task에도 훌륭한 성능을 보이는 강력한 model
Large DNN은 라벨링 되어 있는 training set에 network의 매개변수를 지정할 수 있는 정보가 충분하다면 Supervised Backpropagation을 활용하여 학습 가능
하지만 고정된 크기의 입력을 필요로하며 순서 정보를 손실한다는 한계가 존재
2-2. RNN ; Recurrent Neural Network
시퀀스 데이터를 처리하기 위한 신경망 구조로, 이전 단계의 출력을 현재 단계의 입력으로 사용하여순환적으로 정보를 처리
하지만 long-term dependency문제가 존재하는데, 이는 hidden layer의 과거 정보가 마지막까지 전달되지 못함을 의미
2-3. LSTM ; Long Short-Term Memory
RNN의 특별한 구조로, 장기의존성을 학습할 수 있는 딥러닝 프레임워크
이전 단계의 정보를 memory cell에 저장해서 흘려보냄
현재 시점의 정보를 바탕으로 과거의 내용을 얼마나 잊을지 곱해주고, 그 결과에 현재의 정보를 더해서 다음 시점으로 정보를 전달
Model
3-1. 논문 배경
LSTM보다 활용하여 효율적인 기계 번역 아키텍처인 seq2seq를 제안
Transformer 등장 전까지 State of the art(SOTA) 기록하던 model
3-2. 모델 구조
encoder와 decoder에 각각 LSTM이 사용됨
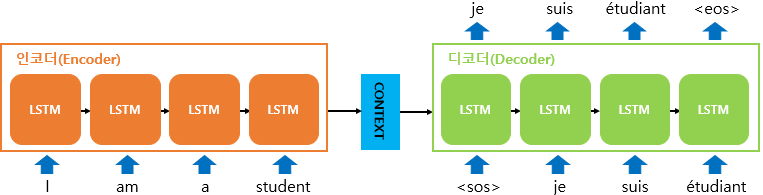
출처 : [WIKIDOCS](https://wikidocs.net/24996)-
이때 encoder에는 sentence가 단어별로 토큰화되고, 단어 토큰이 순서대로 각 시점마다 입력됨
그렇게 되면 data의 구성은, <SOS> 단어들 <EOS>가 됨 -
encoder
: lstm의 과정으로 현시점의 단어와 이전 시점의 hidden state가 다음 hidden state가 됨
-
Context vecotr
: <EOS>를 만날 때 바로 직전 hidden state가 마지막 state가 되고 그것이 바로 Context Vector가 됨 -
Decoder
: Context Vector가 Decoder의 첫 시점에 입력되는 <SOS>와 만나서 단어를 번역하기 시작함
이때 번역된 단어가 recurrent로 다시 들어오고 다음 번역 단어를 예측하는 과정을 반복하고 <EOS>로 마무리됨
3-2-1. Embedding Layer
문자는 문자그대로 사용하여 one hot encoding되면 차원이 매우 커지면서 메모리 문제, 시간 복잡도 문제 등 원활한 계산이 어려움
따라서 학습을 위해 모든 문자를 숫자화하는 Word embedding을 진행하므로써 차원 축소를 함
이런 임베딩 과정으로 현재 시점t에서의 hidden state는 과거 시점(t-1, t-2, ...)의 동일한 셀에서의 모든 은닉 상태의 값들의 영향을 누적해서 받아온 값이 됨
3-2-2. 모델 식
궁극적인 목표는 의 조건부 확률이 높은 것을 선택함
이는 입력 문장이 들어왔을 때의 출력 문장에
대한 조건부확률임
의 조건부확률은 softmax를 통해 다음에 등장할 확률이 높은 단어를 예측하도록 함
이때 는 context vector를 의미
3-3. 모델 특징
모델의 특징을 총 정리하면 다음 3가지로 정리할 수 있음
- 인코더와 디코더로 두 개의 LSTM을 가짐
- encoder
- decoder
- 4-layered LSTM
- 앞선 설명과 그림은 이해가 쉽도록 1-layered LSTM으로 표현되어있지만 실제로는 4계층의 LSTM으로 구성되었음- 아래의 예시 사진은 2-layered LSTM이고 과 는 각 layer의 Context Vector를 의미
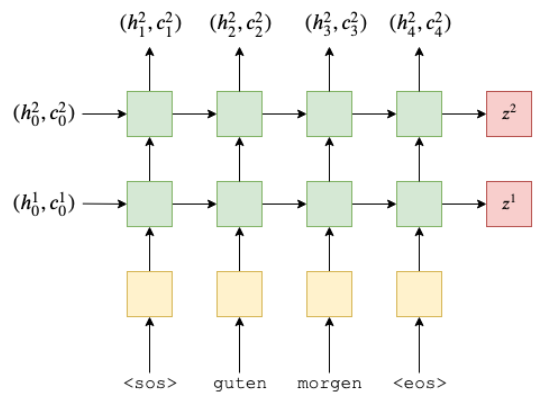
출처 : https://github.com/bentrevett/pytorch-seq2seq
- 아래의 예시 사진은 2-layered LSTM이고 과 는 각 layer의 Context Vector를 의미
- Input Sequence의 입력 순서 뒤집기(revesed)
- 앞선 설명에서는 문장의 단어 토큰의 입력 순서가 순차적인데 실질적으로 좋은 효과를 내기 위해서는 토큰의 입력 순서가 역(reverse)이 되어야 함
그 이유는 아래에서 자세히 설명
- 앞선 설명에서는 문장의 단어 토큰의 입력 순서가 순차적인데 실질적으로 좋은 효과를 내기 위해서는 토큰의 입력 순서가 역(reverse)이 되어야 함
3-3-1. Reversing the source sentence
실험을 통해 단어의 순서를 거꾸로 뒤집었을 때 BLEU score 증가하여 성능이 개선된 것 확인
BLEU Score는 아래에서 설명
- 단어가 순차적으로 나열된 경우, source와 target에서의 연결되는 단어쌍 사이의 거리가 모두 동일
- 단어가 역순으로 나열된 경우, source나 target sentence에서 앞에 위치한 단어일수록 source와 target에서의 연결되는 단어쌍 사이의 거리가 점점 가까움
그러나 순차적, 역순 두 경우 모두 단어쌍 사이 거리에 대한 평균값이 동일하고, 이에 따라 수학적으로 고려해보았을 때 두 결과의 차이가 크면 안됨
그럼에도 reversed의 결과가 더 좋은 것에 누구도 명확한 해석은 불가능하지만 sequential problem으로 그 이유를 유추 가능
Sequential problem에서는 앞쪽에 위치한 data가 뒤의 모든 data에 영향을 주기 때문에 앞에 위치한 data일 수록 중요도가 더 높다고 할 수 있는데
이러한 이유로 decoder 부분에서 앞쪽에 먼저 예측되는 단어가 중요하게 됨
decoder의 앞 쪽 단어의 유추가 잘 되기 위해서는 더 많은 가중치와 영향력이 가해지는 encoder의 마지막 cell과 decoder의 첫 cell이 가까울수록 좋은 예측이 가능하다고 생각하면 reversed의 결과가 더 좋은 성능을 보인다고 생각할 수 있음
Experiments
4-1. 성능지표 ; BLUE SCORE
Bilingual Evaluation Understudy Score의 줄임말
- 기계 번역의 성능이 얼마나 뛰어난가를 측정하기 위해 사용되는 대표적인 방법
- 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에
대한 성능을 측정
4-2. dataset
WMT 14' : English to French Dataset
4-3. Decoding and Rescoring
: Source sentence
: Target sentence
: Training set
- Train 과정
- 는 3-2-2에서 언급한 조건부 확률식을 의미
- S에 일대일로 매칭되는 T가 출력되도록
학습 - log로 확률값이 높아지는 방향으로 학습
- Test 과정
- 매번 문장이 주어질 때마다 가장 높은
확률을 가지는 T_hat을 반환 - Beam search decoder를 사용
- 매번 문장이 주어질 때마다 가장 높은
4-3-1. Beam search decoder
논문에서는 left to right Beam search decoder라고 표현됨
매시점 가장 확률이 높은 후보를 선택하는 greedy searh decoder와 모든 경우의 수를 고려한 후에 누적확률이 가장 높은 후보를 선택하는 방법의 절충안
특정 깊이만큼만 확률을 확인하여 결과적으로 출력 문장의 확률이 더 높은 경우를 얻는 누적 확률 방법
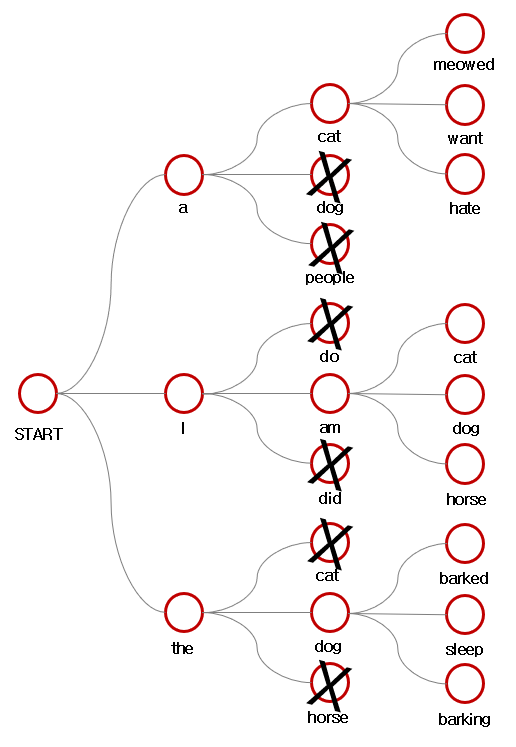
출처 : https://blog.naver.com/PostView.naver?blogId=sooftware&logNo=221809101199&redirect=Dlog&widgetTypeCall=true&topReferer=https%3A%2F%2Fwww.google.com%2F&directAccess=false위의 이미지 예시는 Beam Size k=3인 경우
- <SOS> 입력을 바탕으로 나온 예측 값의 확률 분포 중 가장 높은 확률 3개를 선택
- 3개의 beam에서 각각 다음 예측 값(자식 노드)의 확률 분포 중 가장 높은 3개를 선택
- 총 =9개의 자식 노드 중 누적 확률 순으로 상위 3개를 선택
- 뽑힌 상위 3개의 자식 노드를 새로운 beam으로 설정 후, 해당 beam으로 상위 3개의 자식 노드를 생성
- 3,4의 과정을 <EOS> 토큰을 만날 때까지 반복
최종적으로 가장 높은 누적 확률값을 선택
4-4. Training Details
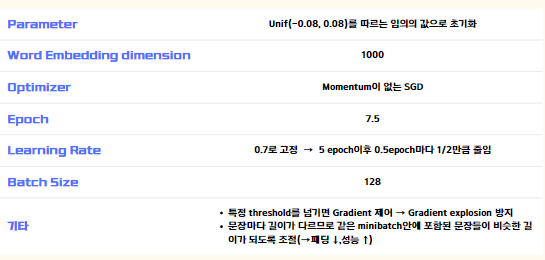
출처 : esyooon 개인 ppt자료Result
- Input 순서를 반대로 입력한 경우, 올바르게 입력한 결과보다 성능이 더 좋음
- Reversed LSTM을 여러 개(5개) 앙상블한 결과가 좋음
- Beam size가 커짐에 따라 성능이 향상하지만, k=2와 k=12의 성능 차이가 크지 않음
- 전통적 방식의 SMT(Baseline System)보다 SMT + LSTM의 성능이 더 좋음
- Dataset에 대하여 가장 좋은 결과와 SMT + LSTM의 결과에 큰 차이가 없으므로 딥러닝 기법의 유의함이 드러남
Conclusion
- LSTM을 깊게 쌓아 기존에 존재했던 SMT와 비교했을 때 더 좋은 성능이 나올 수 있음을 실험을 통해 잘 나타남
- 입력 단어의 순서를 바꾸는 것이 기존 데이터 셀 그대로 이용하는 것보다 더욱 성능을 개선
- 상대적으로 덜 최적화된 단순한 방식이 SMT 방식을 능가하였기에 앞으로의 실험
으로 번역 정확도가 증가함을 기대
동아리에서 Seq2Seq 발제를 맡았어서 제가 이해한 부분을 더 잘 녹여내고자 노력했읍니다..^^
이걸 읽게 되는 여러분들도 멋진 이해가 되셨길 바라며..ㅎㅎㅎㅎ
다른 논문들도 이만큼 이해해야하는데 어렵네요 ㅠ.ㅠ
그렇지만 화이팅
