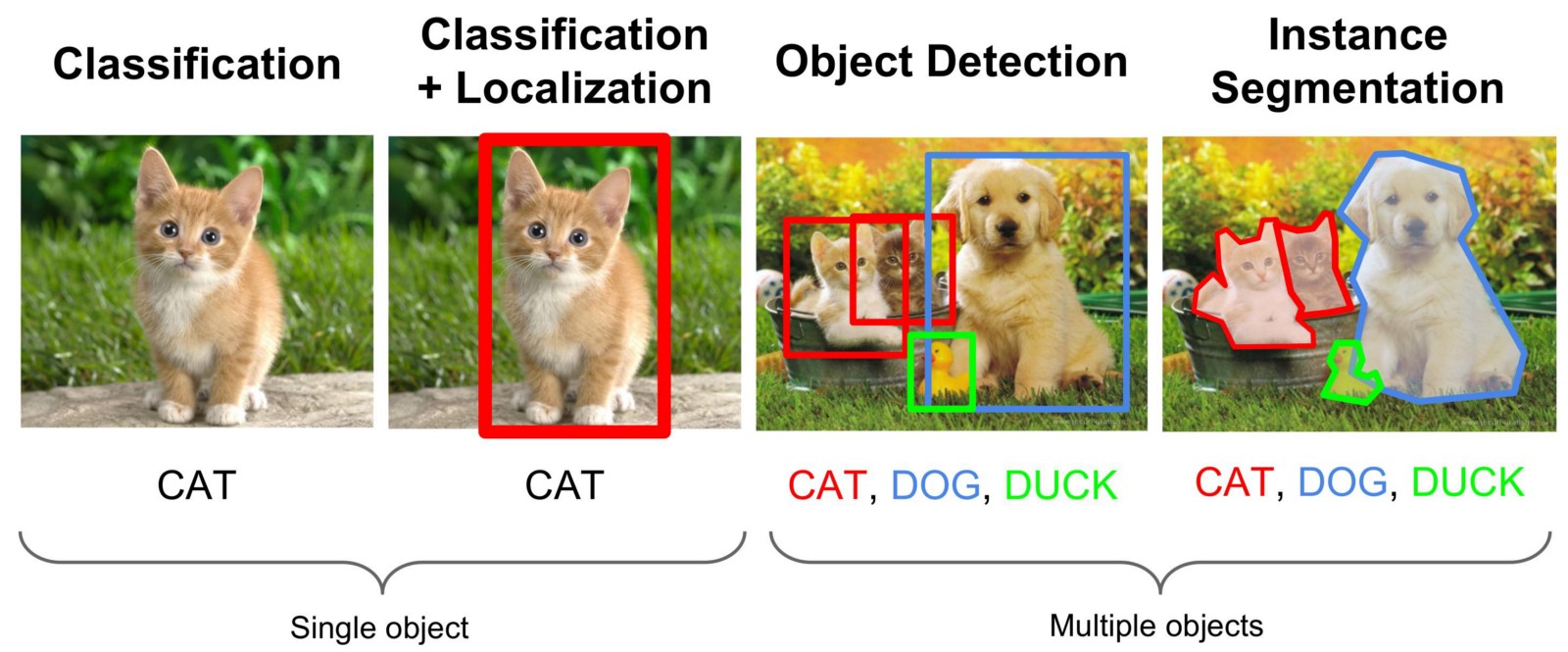
Object Detection
object localization
object localization은 bounding box를 이용해 식별한 객체의 위치, 범위를 나타내기 위해 사용하고, 이를 위해 앞에서 다룬 image classification은 softmax 결과값에 객체의 중심 좌표, 가로길이와 세로길이에 대한 값을 추가한다.
이것으로 bounding box를 그려 객체가 어디까지 위치해 있는지 표시한다

따라서 object localization의 label 값은 검출값, class 값, bounding box으로 이루어져 있다.
만약 객체가 존재하지 않는다면 검출값이 0이 되고 나머지 요소들은 무관항이 된다.
손실함수로 log like feature, Squared Error를 사용할 수 있다.
landmark detection
신경망은 x,y 좌표를 가지는데 이는 이미지에서 특정 지점을 나타내고, 특징점이라고 한다.
특징점은 신경망에서 객체를 인식하는 좌표가 되는데 사람의 눈을 찾고자 한다면 눈의 특정 위치에 특징점을 두면 된다. 눈에서 더 나아가 얼굴 전체의 좌표를 받으려면 신경망의 출력층에서 원하는 좌표만큼을 추가하면 된다.
다른 이미지들과의 비교를 위해선 특징점들의 위치를 일관되게 해줄 필요가 있다.
landmark detection의 출력 유닛은 특징점 갯수 * 2 + 1개의 값을 가지는데 특징점의 x좌표, y좌표, 검출값으로 이루어져 있다.
object detection
-Sliding Window Algorithm
sliding window algorithm이란 window의 크기를 정하고 이미지에 window를 옮겨가면서 해당 window 안에 찾고자 하는 객체가 있으면 1을, 없으면 0을 출력하여 객체를 인식하는 방식이다.
window가 작으면 계산비용이 크지만 정확도가 높고, window가 크면 계산비용이 작지만 정확도가 떨어진다는 단점이 있다.
Convolutional Implementation Sliding Windows
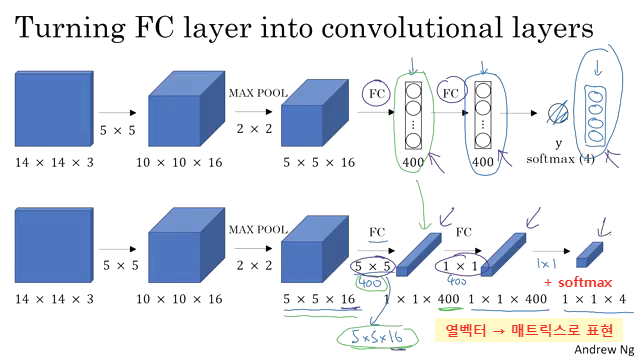
합성곱을 이용한 Sliding Window Algorithm 구현
fully connect 층을 구현 할 때 기존 신경망과 다르게 convolution 연산을 이용해준다.
따라서 fully connect층이 열벡터가 아닌 matrix로 표현된다.
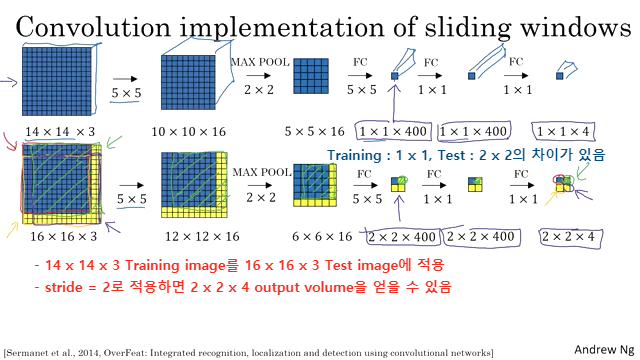
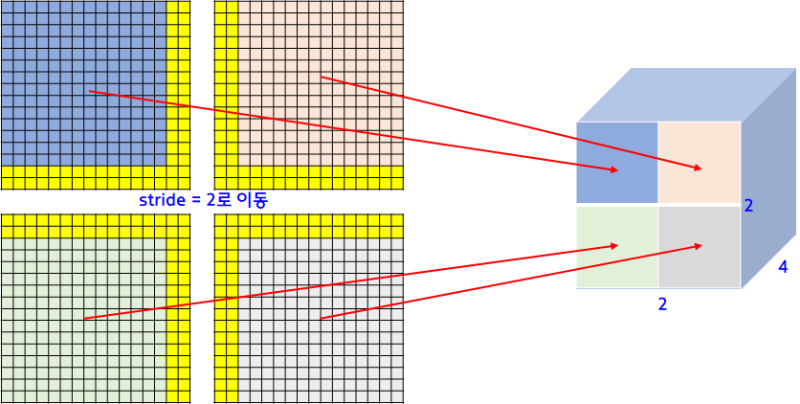
각각의 Window가 Sliding 하면서 Activation과 Max Pooling을 거치게 되어 마지막 Ouput Volume에 대응되는 각 픽셀의 Prediction 값은 처음 이미지의 Window에 대응
Intersection Over Union

예측한 범위와 실제 위치가 겹치는 범위 / 알고리즘에서 나온 결과값이 나타내는 범위 + 실제 객체가 위치한 범위
일반적으로 0.5 이상이면 예측이 정확한 것으로 봄, 좀 더 정확하게 하려면 기준 값을 높여줌
Nonmax Suppression
객체 하나가 감지가 여러번 될 수 있는데 감지한 부분 안에 객체가 있을 확률 값이 가장 높은 부분만 남기고 나머지는 버림

1.Pc <= Threshold(Ex. 0.6) 인 grid의 Box는 제거합니다.
2.Pc 중 가장 큰 값을 가지는 grid를 선택합니다.
3.위에서 선택된 grid의 box와 IOU가 0.5 이상인 box는 모두 제거 합니다.
Anchor Boxes
지금까지의 객체 감지 알고리즘의 문제점은 하나의 격자가 하나의 물체만 인식이 가능
한 격자 내에 2개의 객체가 있을 경우 Anchor Box 사용
