micro GPT 순서도 다이어그램
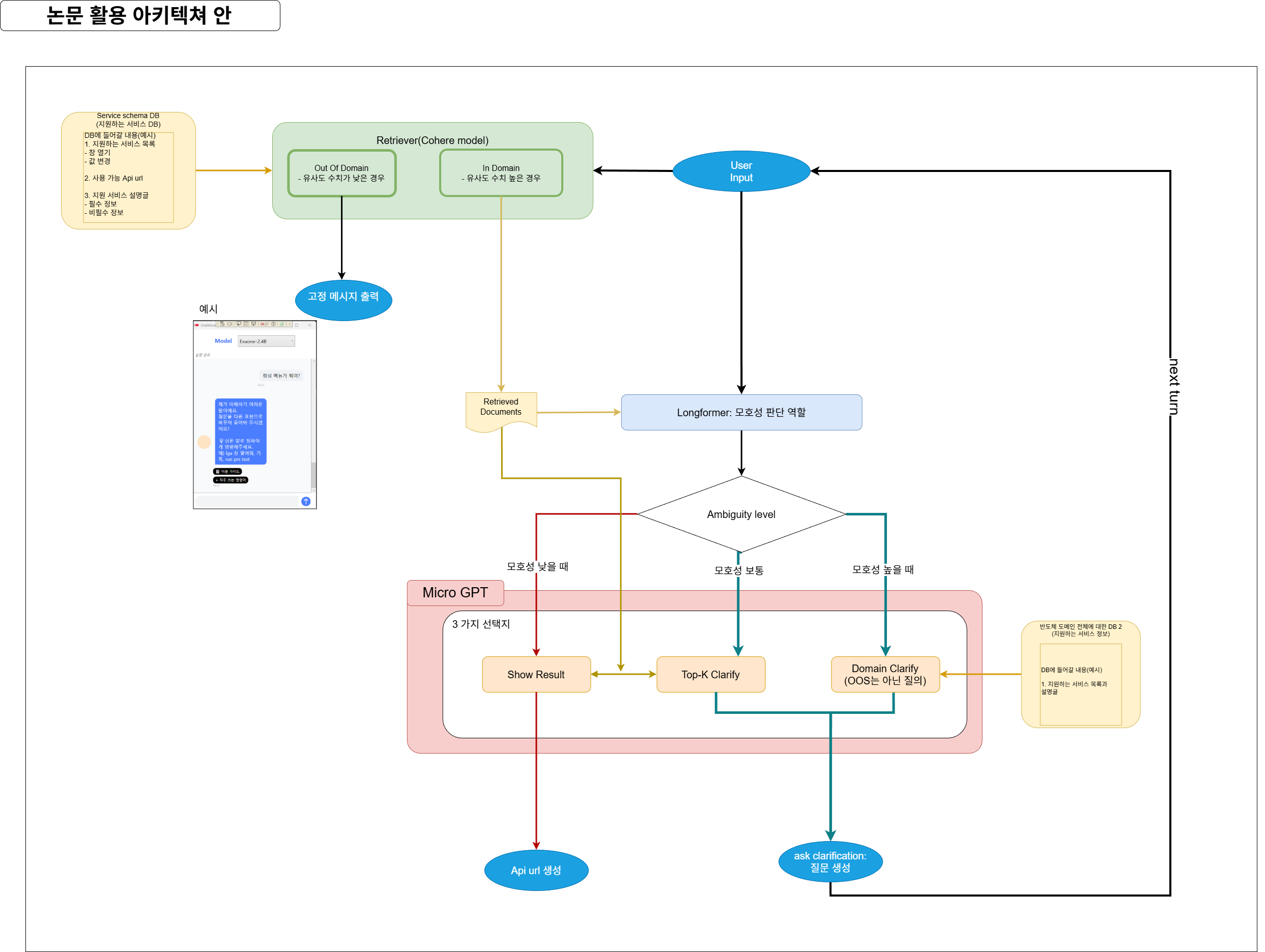
논문 기반 MicroGPT 아키텍처 설계안
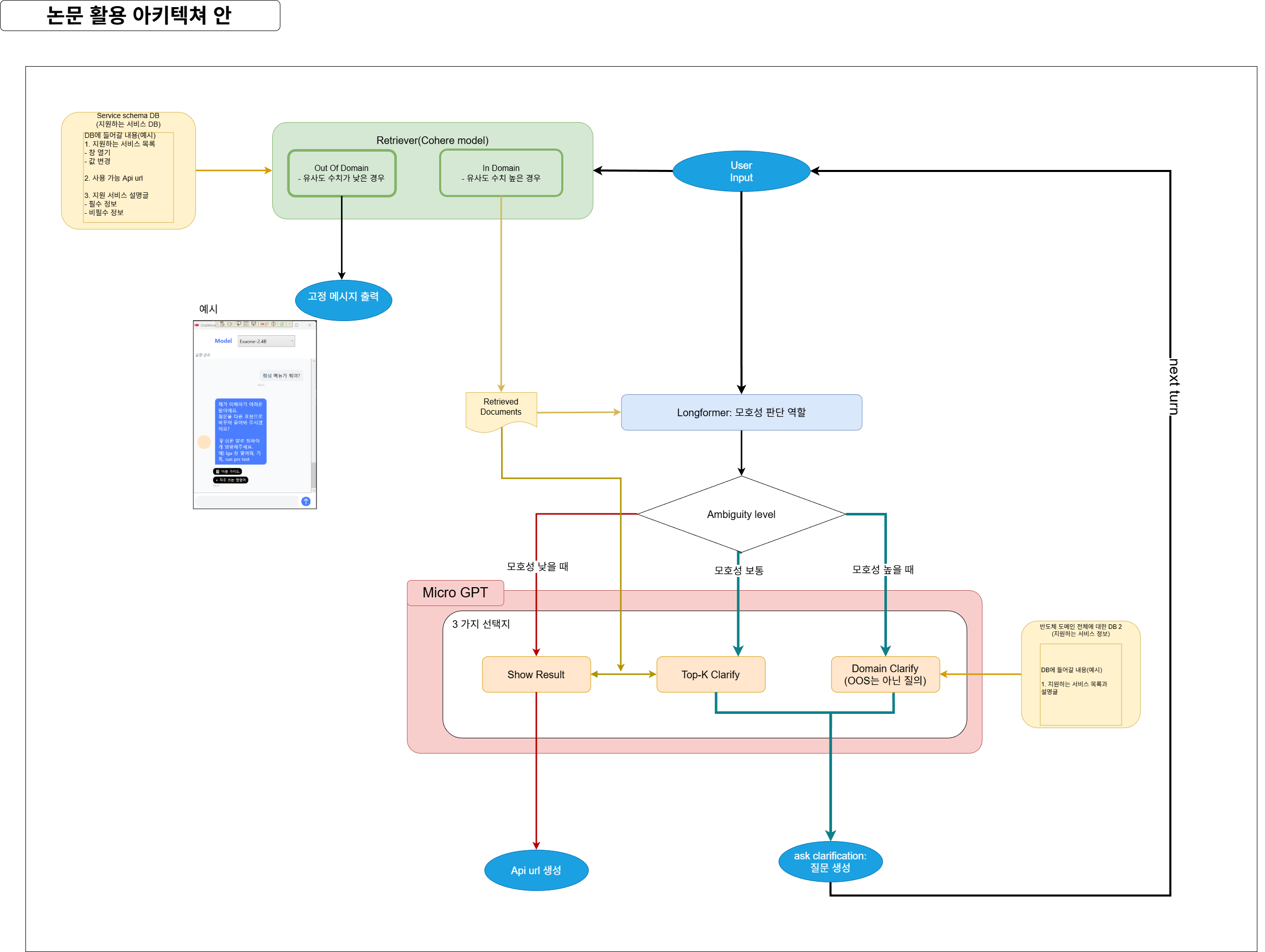
주제: 반도체 도메인 내에서의 의도분류와 모호성 판단을 통한 사용자 의도 정확도 향상을 위한 구조 제안
이번에 설계한 MicroGPT 아키텍처를 설명합니다. 본 아키텍처는 단순히 검색된 정보를 답변하는 RAG(Retrieval-Augmented Generation)를 넘어, 사용자의 질의가 모호할 때 능동적으로 되묻고(Clarification), 반도체 도메인을 벗어난 질의(OOS)를 효율적으로 차단하는 데 초점을 맞추었습니다. 이를 위해 최근 연구된 ASK: Aspects and Retrieval based Hybrid Clarification in Task Oriented Dialogue Systems와 Intent Detection in the Age of LLMs논문을 융합하였습니다.
아키텍처 상세 설명
본 시스템은 크게 (1) 검색 및 범위 판별(Retriever & OOS), (2) 모호성 분석(Ambiguity Analyzer), (3) 동적 명확화 및 답변 생성(Clarification & Response)의 3단계로 구성됩니다.
① 1단계: 검색 및 Out-of-Scope (OOS) 탐지
• 사용자 입력이 들어오면 먼저 Cohere 기반의 Retriever가 작동합니다. 이때 단순히 문서를 검색하는 것 뿐만 아니라, 질의가 반도체 후공정 도메인에 부합하는지 판단합니다.
• 참고 논문 적용: Intent Detection in the Age of LLMs 논문에서 강조한 바와 같이, LLM이 모든 질의를 처리하게 하면 비용과 환각(Hallucination) 위험이 큽니다. 따라서 유사도 점수가 낮은 경우 Out Of Domain 으로 분류하여 고정 메시지를 출력하고 LLM 연산을 방지하는 효율적인 라우팅 전략을 채택했습니다.
② 2단계: Longformer 기반 모호성 분석 (Ambiguity Analyzer)
• 도메인 내(In-Domain) 질의로 판단된 경우, 검색된 문서(Top-K)와 질의를 Longformer 모델에 입력하여 모호성 수준(Ambiguity Level)을 판단합니다.
• 참고 논문 적용: ASK 프레임워크 논문의 핵심인 'Ambiguity Analyzer'를 도입했습니다. 이 모듈은 질의가 명확한지, 검색 결과만으로 해결 가능한지, 아니면 도메인 지식(Aspects)을 이용해 더 넓은 범위의 질문을 해야 하는지를 결정합니다.
③ 3단계: 모호성 수준에 따른 3-Track 처리 전략 분석된 모호성 수준에 따라 에이전트는 다음 세 가지 중 하나의 행동을 취합니다.
• Track A: Show Result (모호성 낮음)
o 질의가 명확하고 검색된 문서에 정답이 있는 경우입니다. LLM이 즉시 답변을 생성하거나, 필요한 경우 Service Schema DB를 참조하여 API URL을 생성해 사용자에게 제공합니다.
• Track B: Top-K Clarify (모호성 보통)
o 질의가 다소 불분명하지만, 검색된 Top-K 문서 내에서 해결 가능한 경우입니다. 검색된 문서 내용을 바탕으로 사용자에게 선택지(Option)를 주는 질문을 생성하여 의도를 좁힙니다.
• Track C: Domain Clarify (모호성 높음)
o 질의가 매우 포괄적이어서 검색 결과만으로는 적절한 답변이 불가능한 경우입니다(예: "패키징 불량 이슈"라고만 입력한 경우).
o 이때는 ASK 논문의 'Domain Aspects' 개념을 활용하여, 미리 구축된 '반도체 도메인 DB(Aspects Info)'를 기반으로 "어떤 공정 단계에서의 불량인가요?"와 같은 거시적인 질문을 생성합니다.
기대 효과
이 아키텍처를 통해 기존 시스템이 가진 '부정확한 질의에 대한 엉뚱한 답변' 문제와 '도메인 외 질의에 대한 리소스 낭비' 문제를 동시에 해결할 수 있을 것으로 기대합니다. 특히 반도체 공정과 같이 전문 용어와 세부 공정이 복잡한 도메인에서, 사용자의 의도를 단계적으로 파악하여 정확한 동작을 제공하는 데 최적화된 구조입니다.
교수님의 피드백을 반영하여 세부 구현을 진행하고자 합니다.
전체 동작 흐름(요약)
-
사용자 입력
· 사용자가 프롬프트를 입력한다. -
Retriever 단계
· 입력된 프롬프트를 기준으로 문서에서 유사도가 높은 내용을 검색한다.
2.1 유사도가 낮은 경우
· 고정 메시지를 채팅창에 출력한다.
· 프로세스를 종료한다.
2.2 유사도가 높은 경우
· 다음 단계(Longformer)로 진행한다. -
Longformer 단계
· 사용자 프롬프트와 Retriever가 검색한 문서를 비교한다.
· 프롬프트의 모호성(Ambiguity)을 수치로 산출한다.
3.1 모호성이 낮은 경우 (프롬프트가 명확한 경우)
· API URL을 출력한다.
· 프로세스를 종료한다.
3.2 모호성이 보통인 경우
· Retriever가 찾은 문서 중 상위 K개 문서를 참고한다.
· 이를 기반으로 추가 질문을 생성한다.
· 프로세스를 종료한다.
3.3 모호성이 높은 경우
· Retriever를 사용하여 전체 문서를 재검색한다.
· 재검색 결과를 기반으로 추가 질문을 생성한다.
· 프로세스를 종료한다.
