
1) ShardingSphere란?
- 분산 데이터베이스 미들웨어 오픈소스 솔루션
- Heterogeneous Language 및 Cloud Native 같은 다양한 상황에 적용 가능한 데이터 샤딩, 분산 트랜잭션 및 데이터베이스 오케스트레이션 기능을 제공
- 4.0 부터 Apache 사에서 제공 (현재 5.X 개발 중)
2) 주요 기능
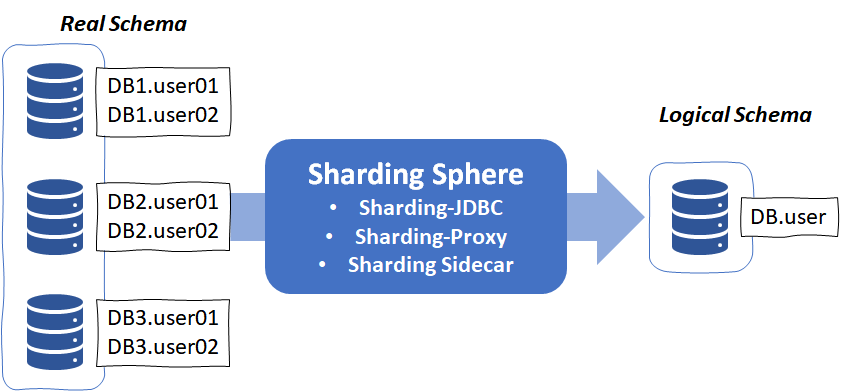
샤딩스피어는 분산된 DB, 테이블을 세 개의 독립된 솔루션을 통해 하나의 Logic Table로서 접근 가능하도록 합니다.
3) Sharding-JDBC
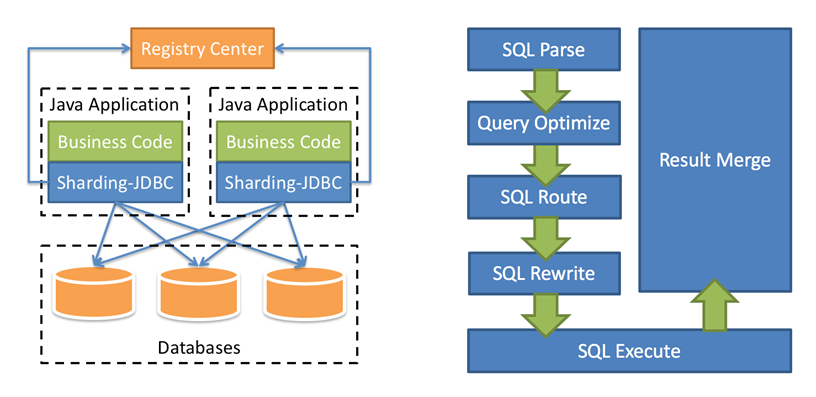
Sharding JDBC는 자바 어플리케이션 위에서 JDBC 형태로 동작합니다.
Java Application의 비즈니스 코드에 따라 로직 테이블이 포함된 SQL을 실행하면 오른쪽과 같은 처리를 거쳐 DB에 접근합니다.
-
SQL Parse:
SQL문을 형태소 단위로 분해 -
Query Optimize:
분해한 SQL문을 최적화 -
SQL Route:
샤딩 룰, 샤딩 키등을 분석해 대상 DB, TABLE 선정 -
SQL Rewrite:
선정 된 DB, TABLE에 기반하여 SQL문 재작성 -
SQL Execute:
재작성된 SQL문 실행 -
Result Merge:
각 SQL문 결과들을 Merge하여 하나의 테이블에 접근한 것 같은 통합된 ResultSet을 제공
Paging Dialect 지원
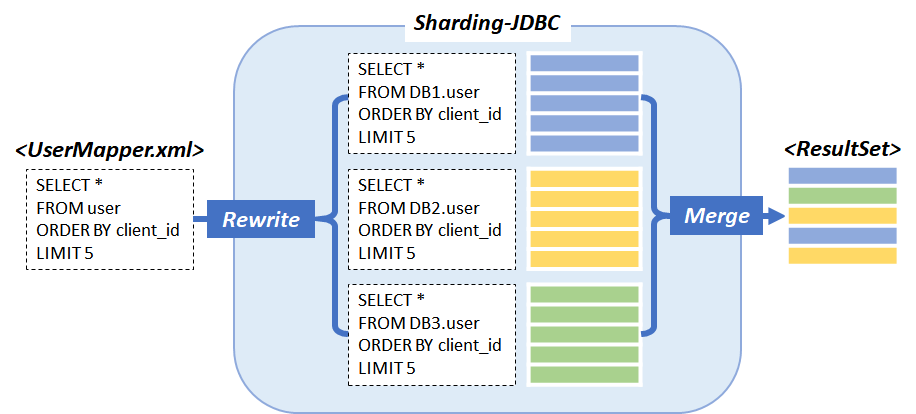
Sharding JDBC 내에서 샤딩 룰에 맞는 DB, TABLE에 대해 SQL문을 재 작성합니다. 이 때, LIMIT, rownum 같은 Paging Dialect도 지원합니다.
이렇게 재작성된 SQL문을 각각 실행하여 나온 결과 값을 Merge 합니다.
이 때, SQL의 ORDER BY, LIMIT을 인식해 전체 결과를 다시 ordering 후 5개를 선정해, 하나의 테이블에서 SQL을 수행한 것과 동일한 결과값을 도출해냅니다.
Sharding-Sphere는 이 외에도 다양한 SQL Dialect를 지원하고 있습니다. 그러나 모든 SQL문이 지원되는 것은 아니기에, 공식 홈페이지의 Unsupported SQL문 항목을 참고할 필요가 있습니다.
4) ShardingSphere의 장점
Sharding key로 1/n 조회
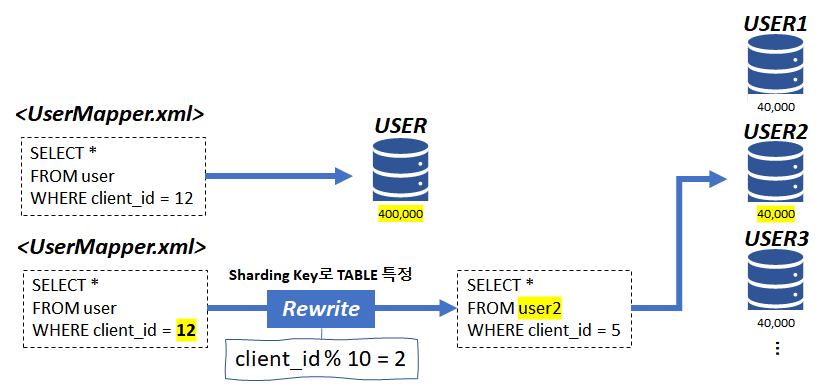
분산 테이블을 하나의 테이블처럼 사용

병렬 처리 효과
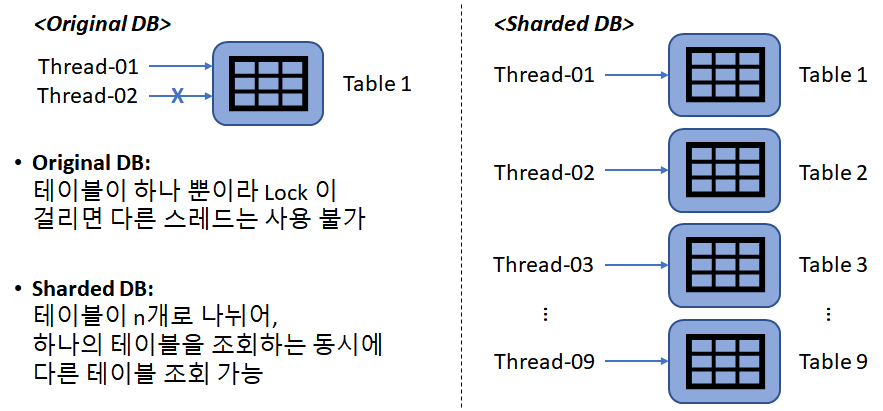
참고
https://shardingsphere.apache.org/document/
https://www.soscon.net/content/data/session/Day%202_1430_2.pdf
