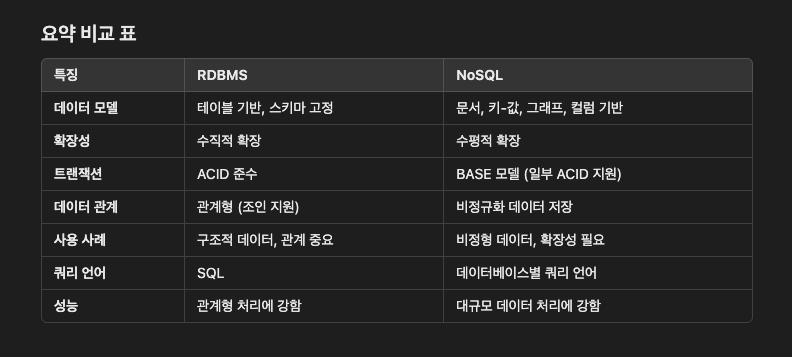
RDBMS
데이터 모델
- 데이터를 테이블에 저장하고, 데이터는 행과 열의 형태로 구조화된다.
- 각 테이블은 schema에 의해 정의되고, 스키마는 데이터의 구조를 엄격히 규정한다.
- ex) MySQL, Oracle DB 등
확장성
- 수직적 확장(Scale-up)에 적합함.
- 더 많은 리소스(CPU, RAM)를 가진 서버로 교체하거나 업그레이드
- 분산 시스템 지원은 제한적이며, Sharding과 같은 작업은 복잡하다.
트랜잭션
- ACID(Atomicity, Consistency, Isolation, Durability) 특성을 엄격히 준수함.
- 데이터 일관성이 중요한 애플리케이션에 적합하다.(예- 금융, ERP)
데이터 관계
- 데이터 간의 관계를 관계형으로 정의
- 데이터가 서로 강하게 연관된 경우 적합함.
쿼리 언어
- SQL을 사용하여 데이터를 정의, 조회, 수정
- 쿼리 표준화가 잘 되어있음
성능
- 복잡한 쿼리와 데이터 관계 처리가 빠르지만, 대규모 데이터 처리에는 상대적으로 느릴 수 있음
NoSQL
데이터 모델
- 데이터 모델이 유연하며, 데이터는 다양한 형식으로 저장된다.
- 문서(Document): JSON, BSON 등(예- MongoDB)
- 키-값(key-value): Key와 Value 쌍(예- Redis)
- 그래프(Graph): 노드와 관계
- Wide-Column Store: 테이블 기반이지만, 스키마가 느슨함(예- Cassandra)
- 스키마가 없거나 동적으로 변화 가능
확장성
- 수평적 확장(Scale-out)에 적합함.
- 여러 서버에 데이터를 분산 저장하고, 노드를 추가하여 용량과 성능 확장
- 클라우드 환경에서 대규모 데이터를 처리하는데 유리하다.
트랜잭션
- 일반적으로 BASE(Basically Available, Soft state, Eventually consistent) 모델을 따름.
- 데이터 일관성보다 가용성과 속도 중시
데이터 관계
- 관계형 데이터 모델이 없음
- 데이터를 비정규화상태로 저장
쿼리 언어
성능
- 단순한 읽기/쓰기 작업에서 높은 성능
- 복잡한 트랜잭션 처리에는 부적합할 수 있음