1️⃣ Index 란 ?
데이터베이스 인덱스는 추가적인 쓰기 작업과 저장 공간을 활용해 데이터베이스 테이블에 저장된 데이터의 검색 속도를 향상시키기 위한 자료구조이다.
책의 맨 앞에 목차 페이지가 없다면, 우리는 원하는 내용을 찾기 위해서 최악의 경우, 책의 모든 부분을 넘겨서 찾아야 할 것이다. 데이터 베이스의 인덱스는 책의 목차 페이지와 같은 역할을 하게 된다. 따라서 인덱스가 적용되는 경우, 조회 기능에 대한 성능이 향상된다.
2️⃣ Index 관리
- INSERT : 새로운 데이터에 대한 인덱스를 인덱스 테이블에 추가해야 한다.
- DELETE : 사용하지 않는 데이터에 대한 인덱스를 “사용하지 않음” 상태로 바꿔야 한다.
- UPDATE : 기존의 인덱스를 “사용하지 않음” 처리 하고, 갱신된 데이터에 대한 인덱스를 추가
3️⃣ Index 구현 자료구조
B-TREE 구조란?
자식 2개 만을 갖는 이진 트리(Binary Tree)를 확장하여 N개의 자식을 가질 수 있도록 고안된 것이다. 좌우 자식간의 균형이 맞지 않는 경우에 매우 비효율적이기 때문에 항상 균형을 맞춘다는 의미에서 균형 트리(Balanced Tree)라고 불린다.
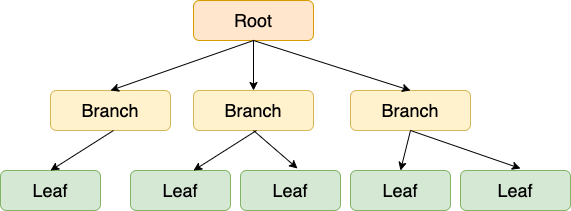
루트노드 - 브랜치 노드 - 리프 노드 로 구성되었다.
B-Tree 는 처음 생성 당시는 균형 트리이지만, 테이블 갱신 (INSERT/UPDATE/DELETE)의 반복을 통해서 서서히 균형이 깨지고, 성능도 악화된다. 어느정도 자동으로 균형을 회복하는 기능이 있지만, 갱신 빈도가 높은 테이블에 작성되는 인덱스 같은 경우 인덱스 재구성을 해서 트리의 균형을 되찾는 작업이 필요하다.
B+TREE 구조란?
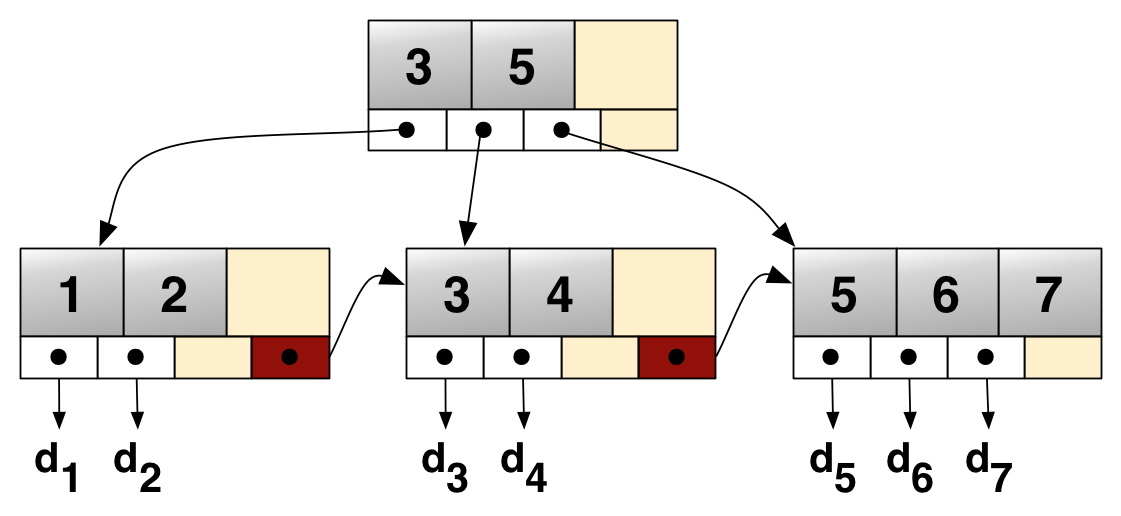
B-Tree의 확장 개념으로 B-tree의 경우, internal 또는 branch 노드에 key와 data를 담을 수 있다. 하지만, B+Tree의 경우 브랜치 노드에 key만 담아두고, data는 담지 않는다. 오직 리프 노드에만 key와 data를 저장하고, 리프 노드끼리 Linked List로 연결되어 있다.
MySQL에서는 어떤 자료구조를 이용할까?
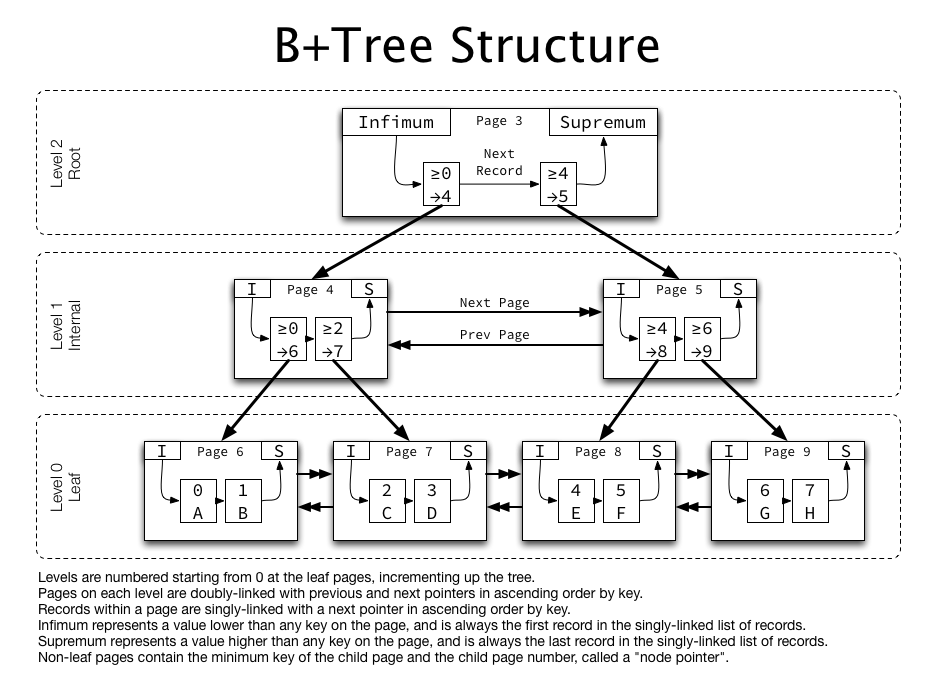
- MySQL은 InnoDB를 이용하기 때문에, InnoDB에서 이용되는 B+Tree를 이용한다고 볼 수 있을 것 같다.
- InnoDB에서 사용된 B+Tree는 단순한 B+Tree의 구조와는 조금 다른 것 같다.
- 같은 레벨의 노드들끼리는 Linked List가 아닌 Double Linked List를 사용했고, 자식 노드로는 Single Linked List로 연결되어 있다.
- key의 범위마다 찾아가야 할 페이지 넘버가 있는데, 해당 페이지 넘버를 통해 곧바로 다음 노드로 넘어간다.
4️⃣ 테스트
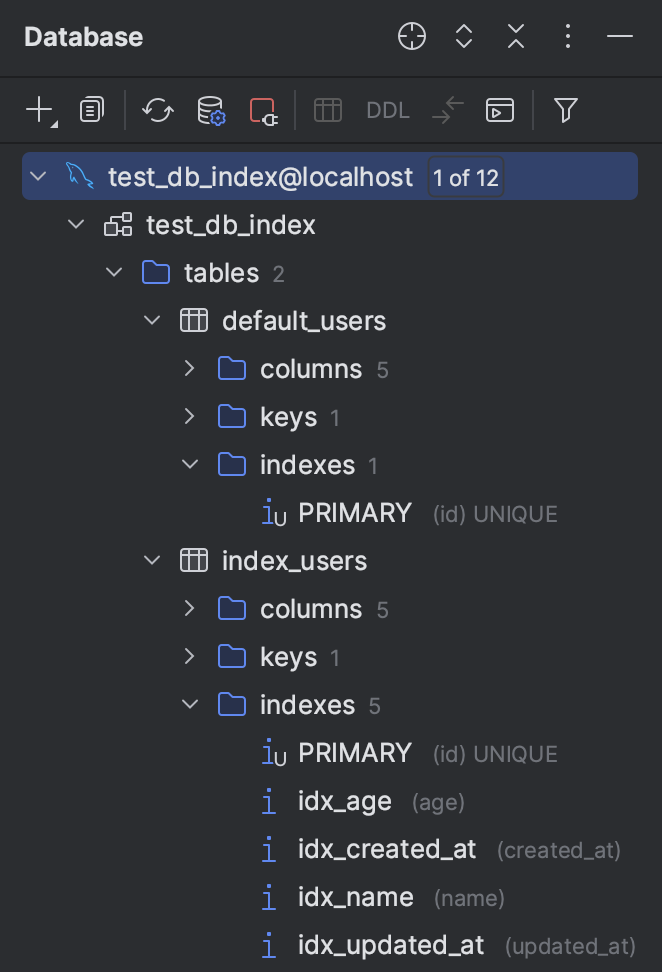
- IndexUser → 모든 컬럼에 Index가 적용된 User
@Table(name = "index_users", indexes = {
@Index(name = "idx_name", columnList = "name"),
@Index(name = "idx_age", columnList = "age"),
@Index(name = "idx_created_at", columnList = "created_at"),
@Index(name = "idx_updated_at", columnList = "updated_at")
})- CommonUser → Index가 적용되지 않은 User
Test1 : 인덱싱 적용이 될 때와 되지 않았을 때 단순 INSERT 시간 비교
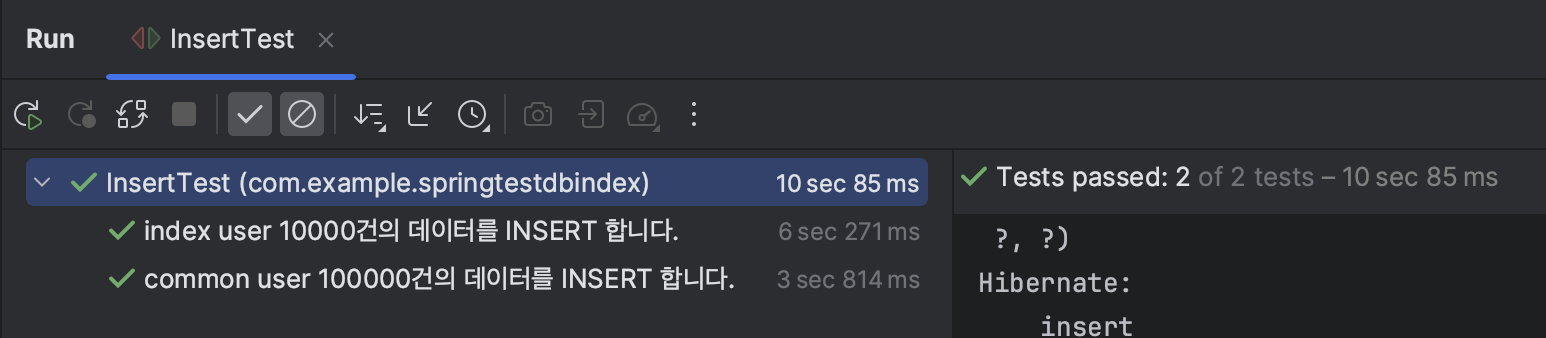
모든 컬럼에 index가 적용된 user와 일반 user 10000개를 INSERT 해보았을 때 데이터의 수가 10000개 밖에 안됨에도 수행시간에서 약 두배의 차이가 나는 것을 알 수 있다.
TestOrder를 지정하지 않았을 때
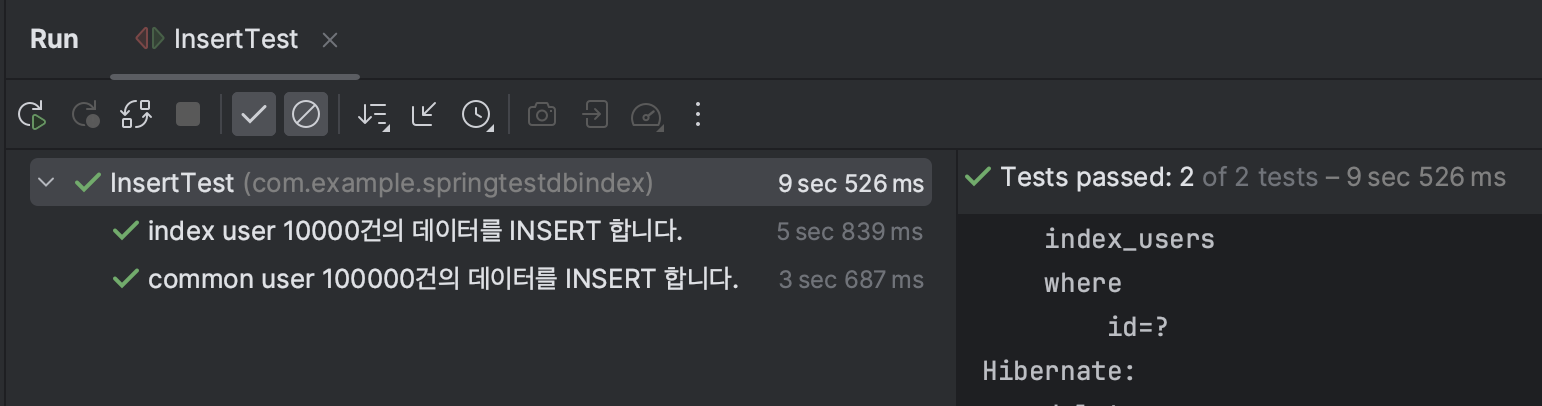
TestOrder를 지정했을 떄
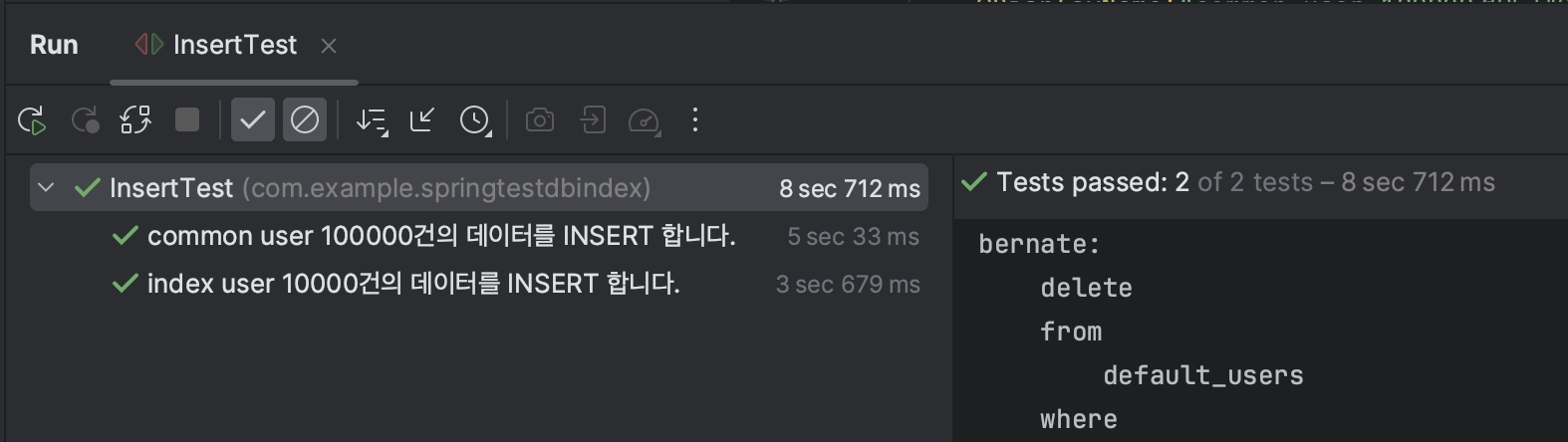
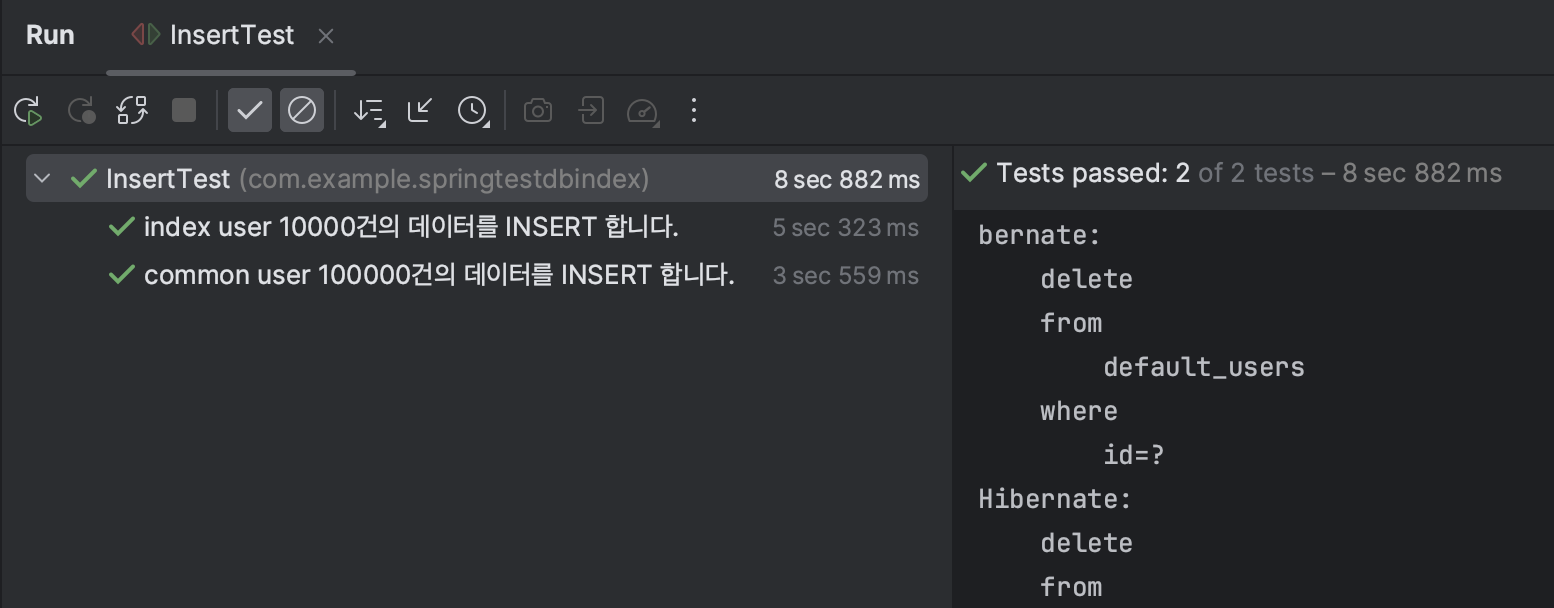
❓index user에 대한 입력이 훨씬 느리게 발생할 것을 예상하고 진행한 테스트 였는데, 먼저 INSERT 한 테이블의 속도가 느리게 발생하는 것을 확인했다..
미리 5000개의 데이터를 넣어두고, insert 하는 방식으로 변환
- 기존의 인덱스가 존재할 때에, 새로운 데이터의 인덱스를 넣기 위해 재정렬 하는 과정에서 수행시간이 느려지기 때문에 미리 데이터를 넣어 둔 상태에서 테스트를 진행해야 된다고 생각했다.
@BeforeAll
void setUp() {
commonUserRepository.deleteAll();
indexUserRepository.deleteAll();
for(int i=0; i<5000; i++) {
commonUserRepository.save(
CommonUser.builder()
.name("setup test"+i)
.age(random.nextInt(100) + 1).build()
);
}
for(int i=0; i<5000; i++) {
indexUserRepository.save(
IndexUser.builder()
.name("index test"+i)
.age(random.nextInt(100) + 1).build()
);
}
}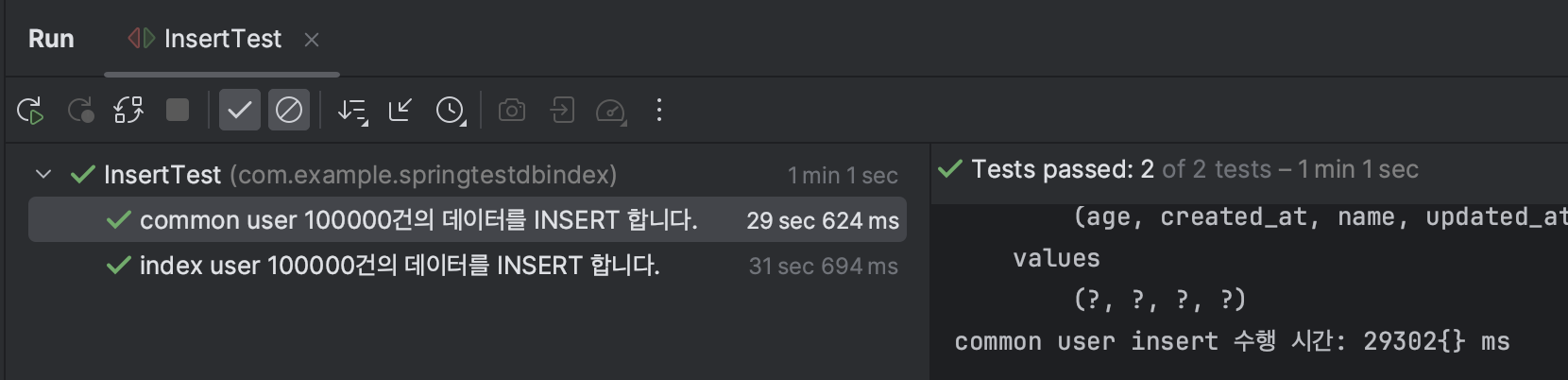

→ 작은 차이였지만, 예상대로 index를 적용한 테이블에서 INSERT를 수행하는 경우에 더 많은 시간이 수행되었다.
Test2 : user의 age = 63 조회 시간 비교 → index를 타서 조회가 훨씬 빠르게 이루어질 것
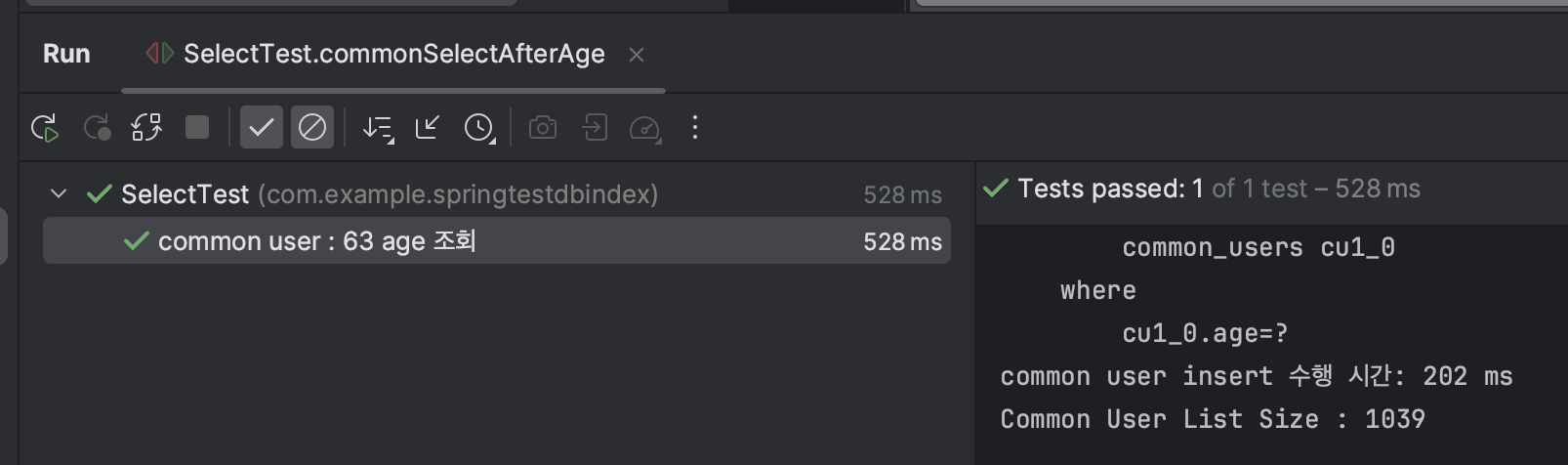
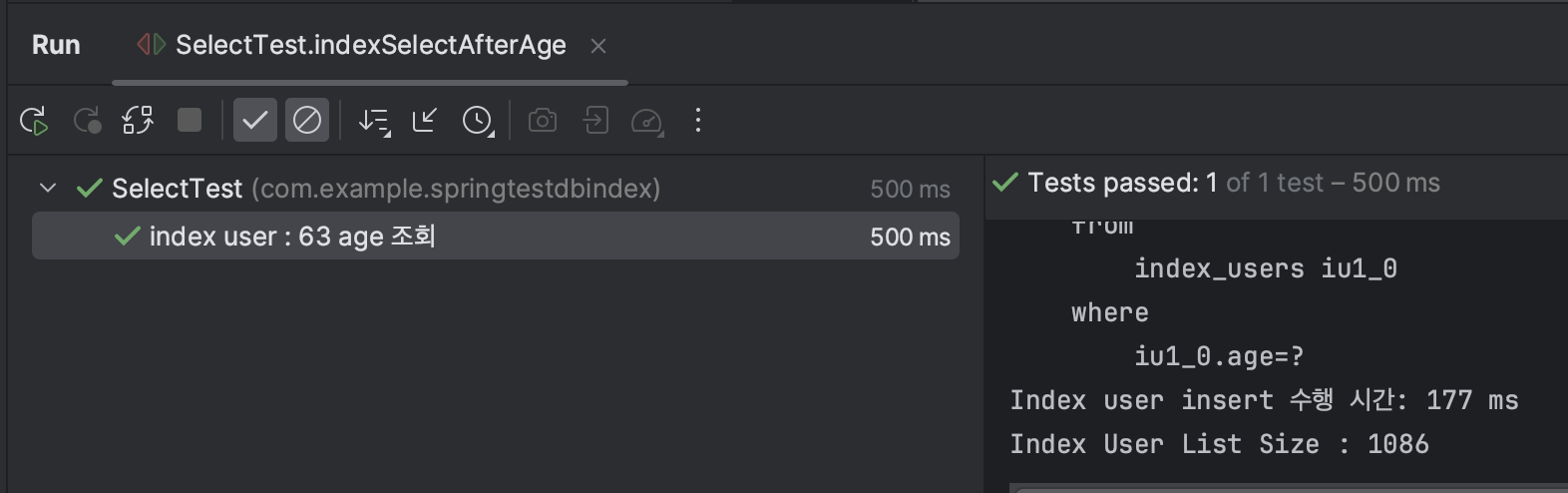
→ 생각보다 조금의 차이가 났다. 그래서 실제로 인덱스를 잘 타고 있는 것인지 확인해 보았다. 그리고 int 값이여서 조금의 차이였던 것 같다는 생각에 name 컬럼으로 다시 테스트를 진행해 보았다.
type = ref, possible_keys ≠ null → 인덱스 탄다



→ 인덱스는 잘 타고 있는 것을 확인했다. name 기준 테스트를 한번 더 진행해 본다.
Test3 : user의 name = '~~~ test93421'
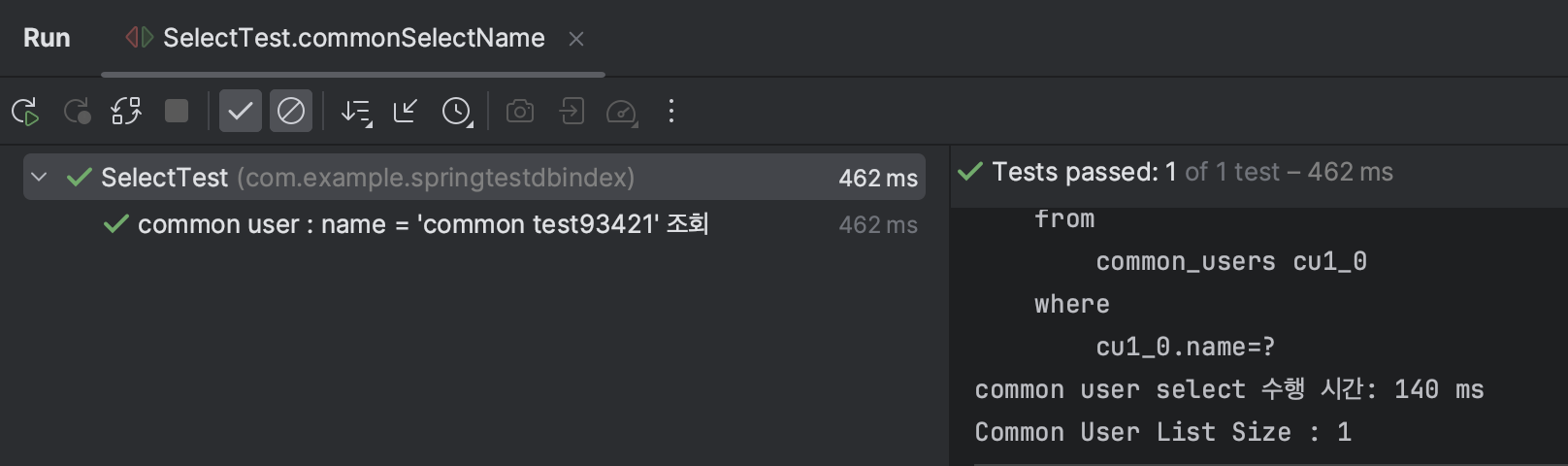 수행시간 : 140 ms
수행시간 : 140 ms
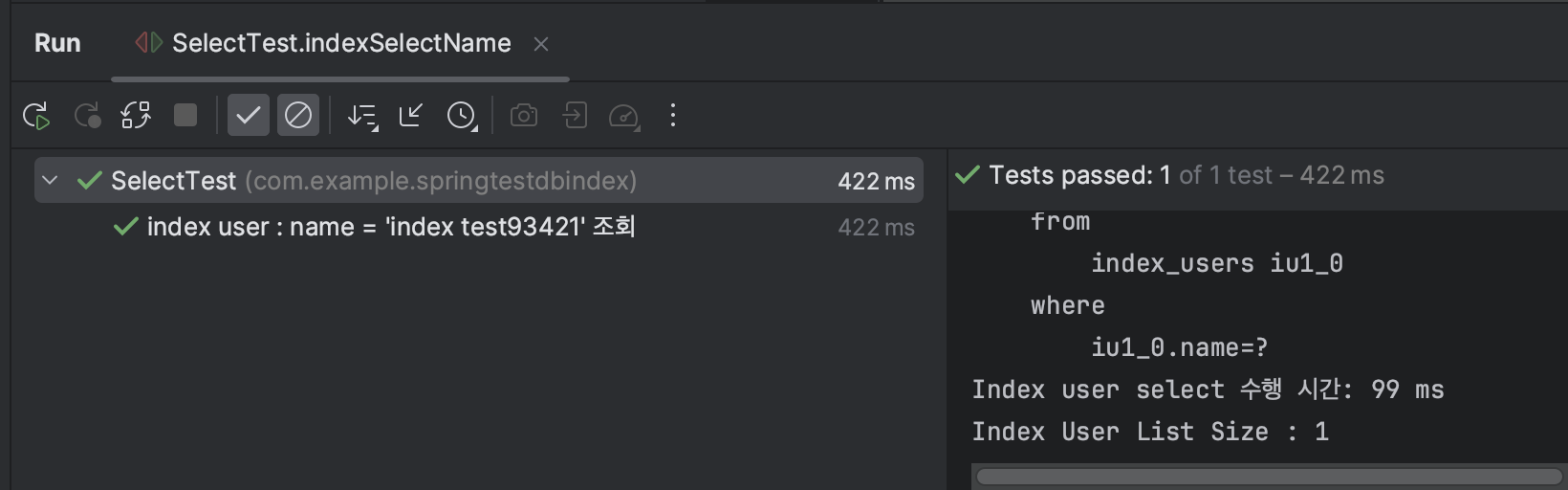
수행시간 : 99 ms
SELECT * FROM default_users u WHERE u.name = 'common test93421';→ 10000건의 데이터에서 약 1.414배의 시간 차이를 보임을 확인할 수 있었다.
마지막으로 update를 진행하면, 기존의 데이터의 index를 “사용안함” 처리 + 새로운 index 추가 로 인덱스 테이블에서 수행해야 하는 일이 많아진다. 조금 더 극명한 시간 차이를 기대하고 테스트를 수행해 보았다.
Test4 : age가 63인 user의 name update
@Transactional
@Modifying
@Query("UPDATE CommonUser u SET u.name = :newName WHERE u.age = :age")
void updateNameByAge(int age, String newName);@Query 어노테이션을 이용해, UPDATE 문을 직접 작성했다.
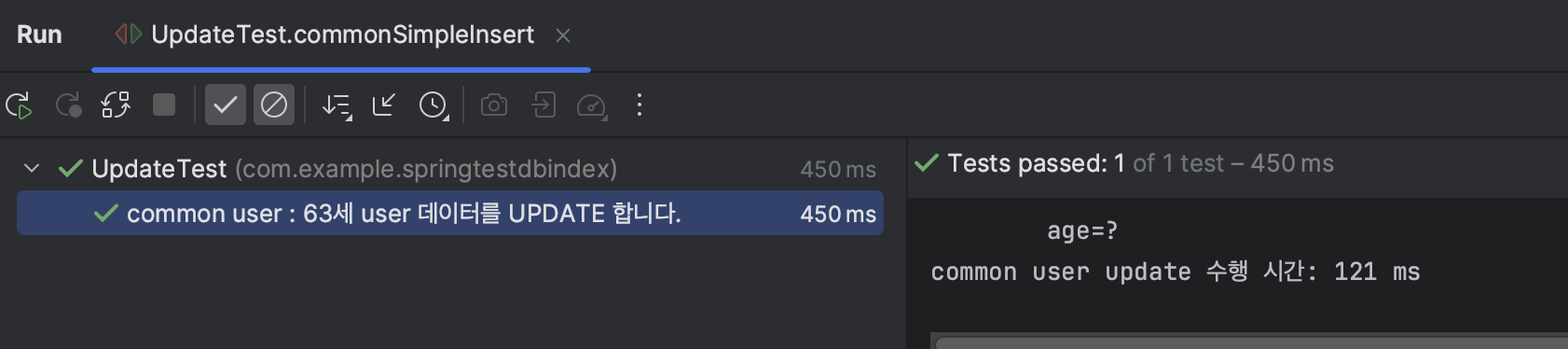 수행시간 : 121 ms
수행시간 : 121 ms
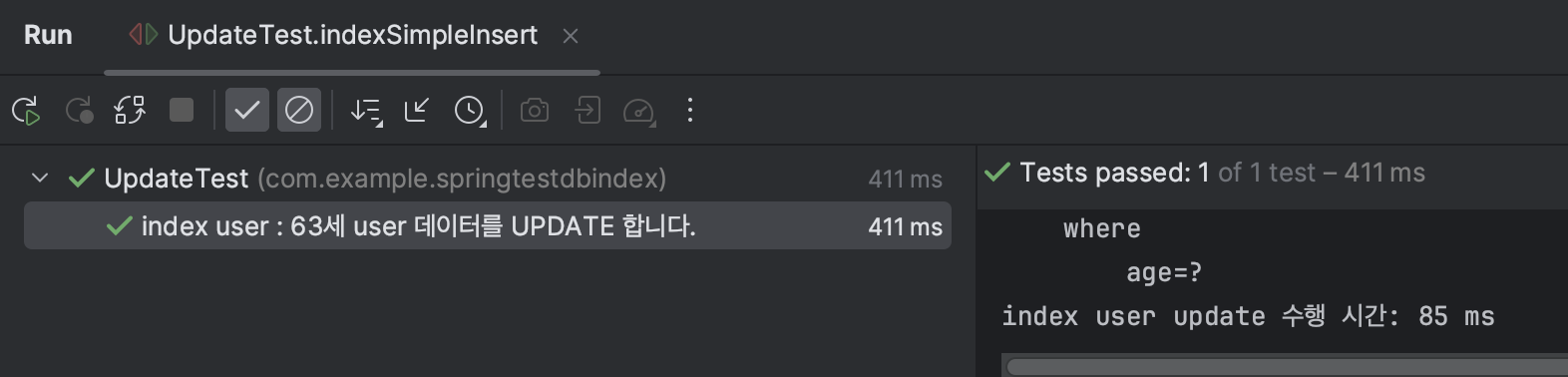 수행시간 : 85 ms
수행시간 : 85 ms
→ 약 1.423배의 차이를 보이는 것을 확인했다.



→ 인덱스도 잘 타고 있음을 확인했다.
🚀 MySQL EXPLAIN 사용법은 다음 링크를 참고했다.
MySQL Explain 실행계획 사용법
5️⃣ 어떤 컬럼에 인덱스를 적용하면 좋을까
단순하게 생각한다면,
WHERE절에 자주 사용되는 컬럼:- 자주 사용되는 검색 조건이 있는 컬럼에 인덱스를 적용하면 쿼리의 성능이 향상됩니다. 예를 들어, 검색 조건이
WHERE username = 'some_value'인 경우,username컬럼에 인덱스를 생성할 수 있습니다.
- 자주 사용되는 검색 조건이 있는 컬럼에 인덱스를 적용하면 쿼리의 성능이 향상됩니다. 예를 들어, 검색 조건이
JOIN절에 사용되는 컬럼:- JOIN 연산이 수행되는 컬럼에도 인덱스를 적용하는 것이 좋습니다. JOIN 연산 시 인덱스가 있다면 두 테이블 간의 매칭이 훨씬 빠르게 이루어집니다.
ORDER BY및GROUP BY절에 사용되는 컬럼:- ORDER BY나 GROUP BY 절에 사용되는 컬럼에 인덱스를 적용하면 정렬 및 그룹화 작업이 효율적으로 이루어집니다.
UNIQUE제약을 가진 컬럼:- UNIQUE 제약을 가진 컬럼에는 인덱스를 자동으로 생성합니다. 이는 중복을 방지하고 빠른 검색을 위해 필요합니다.
LIKE연산이 사용되는 컬럼:- LIKE 연산에서 와일드카드(
%)를 사용하는 경우, 해당 컬럼에 인덱스를 적용하면 검색 성능이 향상됩니다.
- LIKE 연산에서 와일드카드(
- 범위 검색이나
BETWEEN연산이 사용되는 컬럼:- BETWEEN 연산이나 범위 검색이 많이 사용되는 경우, 해당 컬럼에 인덱스를 적용하면 검색 속도가 향상됩니다.
- 적은 카디널리티를 가진 컬럼:
- 적은 카디널리티를 가진 컬럼(고유한 값이 적은 경우)에 인덱스를 적용하면 효과적일 수 있습니다.
- 자주 갱신되지 않는 컬럼:
- 인덱스를 생성하면 인덱스를 갱신하는 오버헤드가 발생하므로, 자주 갱신되지 않는 컬럼에 인덱스를 적용하는 것이 성능에 도움이 될 수 있습니다.
위의 부분들은 우리가 조금만 생각한다면 충분히 떠올릴 수 있는 부분일 것 같다.
6️⃣ 옵티마이저와 실행 계획
이에 대해서 찾아보는 중에 옵티마이저와 실행 계획 수립에 대한 글을 보게 되었다. 데이터를 분석해서 SQL문에 대해 최적의 실행방법을 결정하는 역할을 하는 옵티마이저에 대한 글을 조금 더 찾아보고 공부하면 좋을 것 같다.
아직 수많은 데이터를 관리하는 서비스 운영을 해본 것이 아니기 때문에 인덱스를 적용했을 때의 효율을 크게 와 닿도록 느껴본 적이 없었다. 아주 간단한 테스트였지만, 직접 수행하고 숫자로 보면서 앞으로 회사에 취업하게 되거나, 운이 좋게 프로젝트로 큰 서비스를 운영하게 된다면 분명 프로그램 성능향상에 꼭 필요할 것이라는 생각을 했다. MySQL에서는 unique 값인 ID 값에 자동으로 인덱스를 생성하게 되는데, 서비스 필요에 따라 다른 컬럼에도 인덱스를 적용해볼 수 있었으면 좋겠다.