프로젝트 진행하면서 많은 사원들이 사용하는 서비스이다 보니, 조회가 많이 일어나 부하가 많이 걸릴 것 같다 라는 생각이 들어
Spring Batch와Scheduler를 통해서 대용량 데이터를 처리해보자!!+) 이는 매우 거만한 생각이였다.. Monitorting 없이 부하가 많이 걸릴 거라고 예측하고 진행하는 행동은 좋지 못한 행동이다..
실질적으로 기업에서도 Batch 를 사용하려면 여러 조건을 거쳐서 결정 후 진행한다고 한다.. 앞으로는 개연성을 먼저 따져보는 습관을 들여야겠다..🥲
1. Batch를 사용하는 기준
- 수백만건의 데이터에 수백만건의 조회 같은 대용량 트래픽
- 모니터링을 위해서 여러가지 테이블의 계산된 값이(연산 등?) 들어가는 테이블(전제는 1번일 경우)
위의 기준은 예측이나 예상을 통해서 확정하는 것이 아닌, Montoring 시스템을 통해서 실질적인 부하를 측정해 본 후, 결정해야한다.
간단한 예시를 들어보자면, Batch 같은 경우는 휴먼계정처리와 같은 곳에 많이 사용되는데,
휴면 계정을 처리하기 위해서는 수많은 회원 데이터를 한번에 조회하는 경우에는 실질적으로 부하가 많이 발생하기 때문에, Batch와 Scheduler를 이용해서 6개월에 한번씩과 같은 특정 기간마다 서비스 접속이 없는 시점에 한번에 처리하는 데 사용된다.
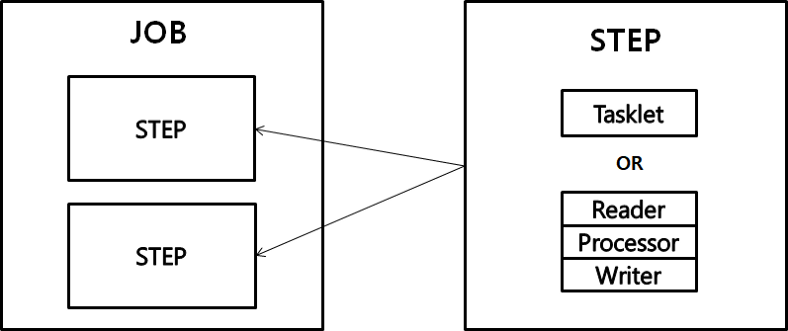
2. 구현 코드
- Batch Config 파일
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.configuration.annotation.JobScope;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.PlatformTransactionManager;
@Slf4j
@Configuration
@RequiredArgsConstructor
public class BatchConfig {
private final String JOB_NAME = "checkJob";
private final String STEP_NAME = "checkStep";
@Bean
public Job checkJob(JobRepository jobRepository, PlatformTransactionManager transactionManager){
return new JobBuilder(JOB_NAME, jobRepository)
.incrementer(new RunIdIncrementer())
.start(checkStep(jobRepository, transactionManager))
.build();
}
@Bean
@JobScope
public Step checkStep(JobRepository jobRepository, PlatformTransactionManager transactionManager){
return new StepBuilder(STEP_NAME, jobRepository)
.tasklet(checkTasklet(), transactionManager)
.build();
}
@Bean
@StepScope
public Tasklet checkTasklet(){
return new Tasklet(){
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext context) throws Exception {
log.info("Spring batch check Suceess");
// 원하는 비지니스 모델 추가
return RepeatStatus.FINISHED;
}
};
}
}- Batch Scheduler 파일
import org.springframework.batch.core.*;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.util.Collections;
@Component
public class BatchScheduler {
private final JobLauncher jobLauncher;
private final Job checkJob;
@Autowired
public BatchScheduler(JobLauncher jobLauncher, Job checkJob) {
this.jobLauncher = jobLauncher;
this.checkJob = checkJob;
}
@Scheduled(cron = "0 03 00 * * ?", zone = "Asia/Seoul")
public void testJobRun() throws JobInstanceAlreadyCompleteException, JobExecutionAlreadyRunningException,
JobParametersInvalidException, JobRestartException {
JobParameters jobParameters = new JobParameters(
Collections.singletonMap("requestTime", new JobParameter(System.currentTimeMillis(), Long.class))
);
jobLauncher.run(checkJob, jobParameters);
}
}- DDL 파일 (자동으로 생성되는 테이블을 미리 생성)
DROP TABLE IF EXISTS BATCH_STEP_EXECUTION_SEQ;
DROP TABLE IF EXISTS BATCH_STEP_EXECUTION_CONTEXT;
DROP TABLE IF EXISTS BATCH_JOB_EXECUTION_CONTEXT;
DROP TABLE IF EXISTS BATCH_JOB_EXECUTION_PARAMS;
DROP TABLE IF EXISTS BATCH_JOB_EXECUTION_SEQ;
DROP TABLE IF EXISTS BATCH_JOB_SEQ;
DROP TABLE IF EXISTS BATCH_STEP_EXECUTION;
DROP TABLE IF EXISTS BATCH_JOB_EXECUTION;
DROP TABLE IF EXISTS BATCH_JOB_INSTANCE;
# spring batch & scheduler 테이블
CREATE TABLE BATCH_JOB_INSTANCE
(
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY,
VERSION BIGINT,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE = InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION
(
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
VERSION BIGINT,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL,
END_TIME DATETIME(6) DEFAULT NULL,
STATUS VARCHAR(10),
EXIT_CODE VARCHAR(2500),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED DATETIME(6),
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE (JOB_INSTANCE_ID)
) ENGINE = InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS
(
JOB_EXECUTION_ID BIGINT NOT NULL,
PARAMETER_NAME VARCHAR(100) NOT NULL,
PARAMETER_TYPE VARCHAR(100) NOT NULL,
PARAMETER_VALUE VARCHAR(2500),
IDENTIFYING CHAR(1) NOT NULL,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION (JOB_EXECUTION_ID)
) ENGINE = InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION
(
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL,
END_TIME DATETIME(6) DEFAULT NULL,
STATUS VARCHAR(10),
COMMIT_COUNT BIGINT,
READ_COUNT BIGINT,
FILTER_COUNT BIGINT,
WRITE_COUNT BIGINT,
READ_SKIP_COUNT BIGINT,
WRITE_SKIP_COUNT BIGINT,
PROCESS_SKIP_COUNT BIGINT,
ROLLBACK_COUNT BIGINT,
EXIT_CODE VARCHAR(2500),
EXIT_MESSAGE VARCHAR(2500),
LAST_UPDATED DATETIME(6),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION (JOB_EXECUTION_ID)
) ENGINE = InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT
(
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION (STEP_EXECUTION_ID)
) ENGINE = InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT
(
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION (JOB_EXECUTION_ID)
) ENGINE = InnoDB;
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ START WITH 1 MINVALUE 1 MAXVALUE 9223372036854775806
INCREMENT BY 1 NOCACHE NOCYCLE ENGINE =InnoDB;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ START WITH 1 MINVALUE 1 MAXVALUE 9223372036854775806
INCREMENT BY 1 NOCACHE NOCYCLE ENGINE =InnoDB;
CREATE SEQUENCE BATCH_JOB_SEQ START WITH 1 MINVALUE 1 MAXVALUE 9223372036854775806
INCREMENT BY 1 NOCACHE NOCYCLE ENGINE =InnoDB;+) 현재는 개연성 문제로 더이상 개발을 진행하지 않아, 상세 내용은 향후 정리할 예정

매일매일 차근차근 나아가보는 개발일기