💡 Stomp + Kafka로 실시간 채팅 구현하기
1. 🙋🏻개요
앞선 포스팅에서는 Stomp와 RabbitMQ를 이용하여서 실시간 채팅을 구현하였다.
RabbitMQ를 이용해서 Stomp만 사용하였을 때 발생하는 내부 메시지 브로커의 문제를 해결할 수 있었다.
사실 1대1 채팅이나 소규모 채팅방 같은 경우에는 RabbitMQ가 빠른 속도로 메시지를 전송 할 수 있기 때문에 적합하다고 생각한다.
하지만 이번 snail에서 진행하는 "외국인 가정 정착 지원 어플리케이션"은 1대1 채팅방 뿐만 아니라, 모임, 모임 일정등 1대 다 채팅방도 많이 있고, 무엇보다 많은 인원이 채팅에 참가할 수 도 있는 대규모 채팅방의 가능성이 있기 때문에 Kafka를 선택하기로 하였다.
그리고, 우리 서비스는 MSA 아키텍쳐를 사용하기 때문에, MSA에 좀 더 적합한 Kafka를 통해 채팅을 구현하여 보고자 한다.
2. 주요 이슈
1) 메시지를 Producer를 통해 저장 vs Consumer를 통해 저장
Producer에서 DB에 저장
장점
- 즉시 저장: 메시지가 생성되자마자 DB에 저장되므로 데이터 유실 가능성이 줄어든다.
- 단순성: 메시지 전송과 저장이 한 곳에서 이루어지므로 코드가 단순해질 수 있다.
단점:
- 성능 저하: Producer가 메시지를 생성할 때마다 DB에 접근해야 하므로 성능이 저하될 수 있다.
- 확장성 문제: 많은 메시지가 생성될 경우, DB에 대한 부하가 증가할 수 있다.
Consumer에서 DB에 저장
장점:
- 성능 향상: Producer는 메시지를 Kafka에 전송하는 역할만 하므로 성능이 향상될 수 있다.
- 확장성: Consumer를 여러 개 두어 부하를 분산시킬 수 있다.
단점:
- 복잡성 증가: 메시지를 Kafka에서 읽어와 DB에 저장하는 로직이 추가되므로 시스템이 복잡해질 수 있다.
- 데이터 유실 가능성: Consumer가 메시지를 처리하기 전에 장애가 발생할 경우, 메시지가 유실될 가능성이 있다.
위와 같은 장단점이 존재하기 때문에 우리의 프로젝트 상 특성을 고려해야하였다.
우리 프로젝트의 특성상 채팅이 중요한 요소였기도 하고, 사용자의 채팅을 확실하게 관리할 수 있는게 더 좋다고 생각하였다.
또한, 생각하여 봤을때, Consumer에서 DB를 저장하게 되면, 하나의 DB에 여러개의 Consumer가 동일한 DB를 저장하려고 접근하는 것이 성능적인 측면을 감소시킬 수 있겠다고생각하였다.
따라서, Producer에서 보낼 메시지를 Kafka 브로커로 전송을 한 후, 전송이 제대로 성공하면 DB에 저장하여, 메시지의 유실을 막아주길 결정하였다.
3.카프카 설정 - ec2 인스턴스 3개 중 1개 사용
위 방식은 카프카 초기 설정을 참고하여서 그 이후 진행과정을 기록하였다.
1) EC2 서버(카프카 Broker 존재)에 zookeeper 와 kafka 실행
// EC2 서버 접속
$ ssh -v -i "kafka-test.pem" ec2-user@{본인 EC2 Public Ip)
// kakfa 설치된 파일로 이동
$ cd kafka_2.12-2.5.0
// 동작중인 프로세스 확인
$ jps -m
// zookeeper 실행
$ bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
// kafka 실행
$ bin/kafka-server-start.sh -daemon config/server.properties- EC2 서버에 zookeeper와 kafka를 실행한다.
- EC2는 카프카 Broker를 담당하기 때문에 먼저 실행하여야 한다.
2) Local 서버에 zookeepr와 kafka 실행
// kakfa 설치된 파일로 이동
$ cd kafka_2.12-2.5.0
// zookeeper 실행
$ bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
// kafka 실행
$ bin/kafka-server-start.sh -daemon config/server.properties- local환경에서 EC2 환경에 구성된 카프카 Broker로 연결하기 위해서 zookeeper와 kafka를 실행한다.
- 참고 포스터에서 local에 EC2 public IP를 통해서 Kafka를 연결하였기 때문에, 해당 폴더로 들어가서 바로 zookeeper와 kafka를 실행한다.
3) Local 터미널에서 EC2서버에 Topic 생성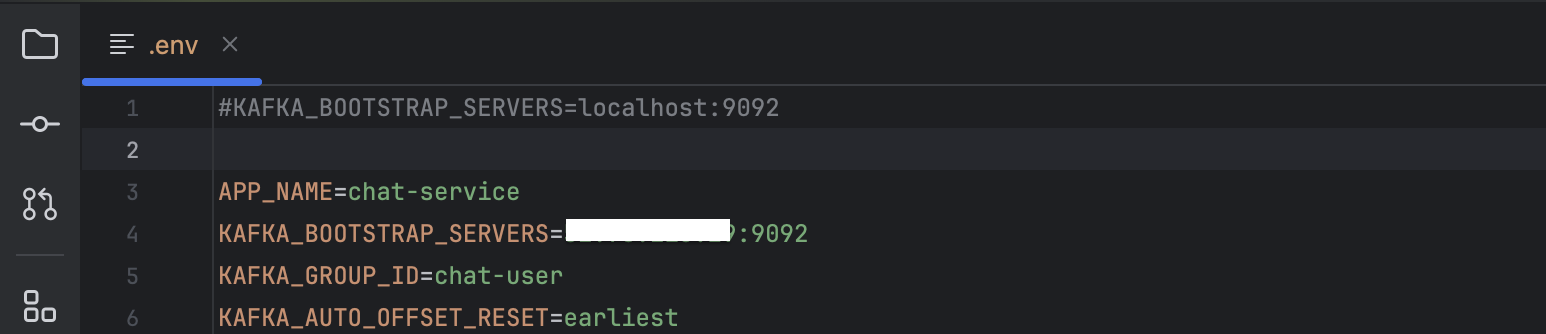
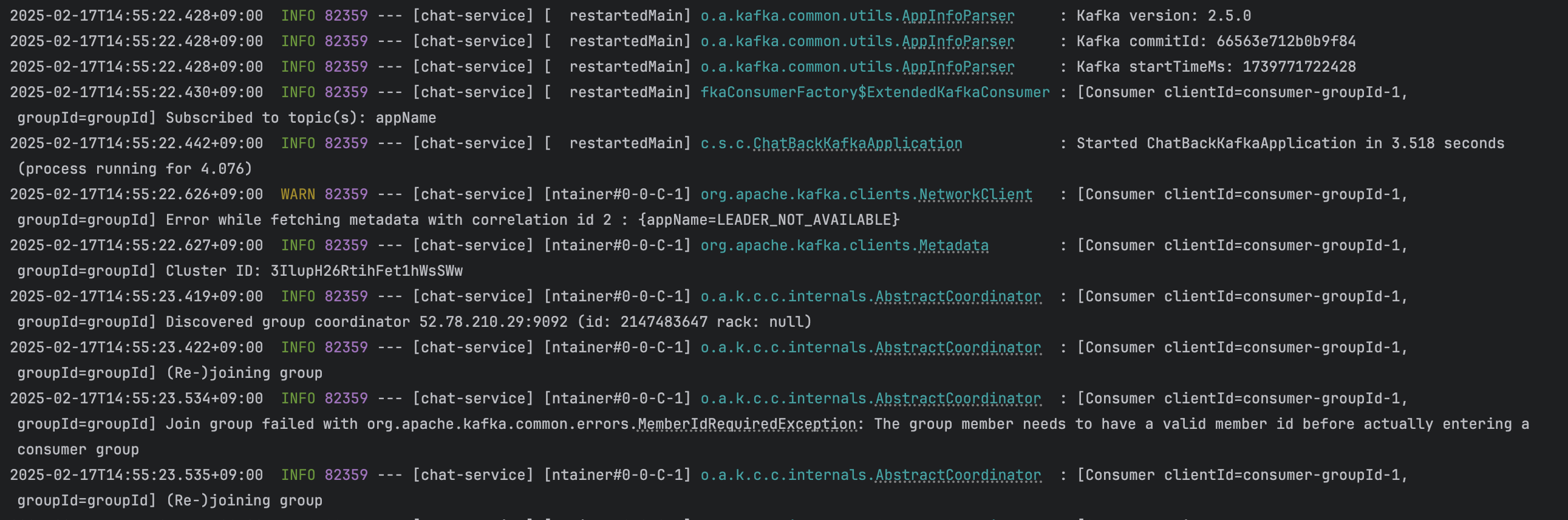
$ bin/kafka-topics.sh --bootstrap-server {본인 EC2 Public Ip}:9092 --create --topic chat-test --partitions 3- 만들어둔 채팅 Kafka 설정에 맞춰서 Topic을 생성하고, 테스트를 진행하였다.
- 위와 같이 설정을 진행하고 SpringBoot를 실행하니, 해당 Broker와 연결되고 Consumer도 생성된것을 확인할 수 있다.
4) Local 터미널을 통해서 데이터를 넣고 확인하기
// Kafka Producer로 데이터 넣기
$ bin/kafka-console-producer.sh --bootstrap-server {본인 EC2 Public IP}:9092
--topic chat-service
// Kafka Consumer로 넣은 데이터 확인
$ bin/kafka-console-consumer.sh --bootstrap-server {본인 EC2 Public IP}:9092
--topic chat-service --from-beginning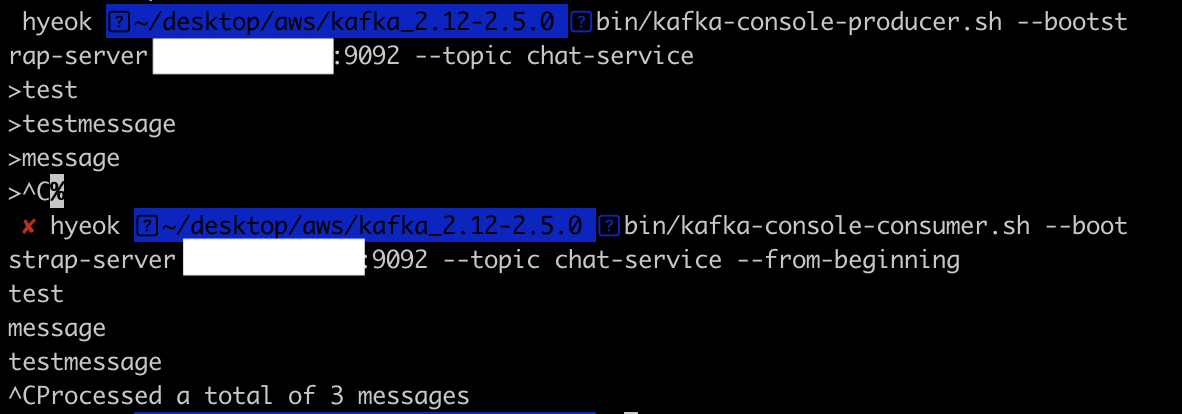
- 터미널을 통해서 EC2 서버에 만들어 놓은 Kafka Broker에 생성한 Topic으로 Producer가 데이터를 넣으면, 해당 Topic을 구독하고 있는 Consumer는 Topic에 저장된 데이터를 확인할 수 있다.
5) 채팅서버에 적용해보기 - 1개의 인스턴스 사용
우선적으로 띄워놓은 EC2 서버와 내가 구현한 채팅 서버와 잘 연결이 되고, KafKa를 통한 통신이 잘 이루어지는 지 확인하기 위해서 EC2 서버 1개를 대상으로 적용을 진행하였다. 향후 이번에 연결한 인스턴스를 Leader Broker로 지정하고, 나머지 2개를 Follower Broker로 지정하여서, replication가 잘 이루어져, 통신이 잘 이루어지는 지 확인해볼 생각이다.
1. KafkaProducerConfig.java
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.producer.bootstrap-servers}")
private String prod_bootstrap_server;
// Kafka에서 메시지를 생성하는 역할을 하는 Producer 객체 생성
@Bean
public ProducerFactory<String, ChatMessageDto> producerFactory() {
Map<String, Object> config = new HashMap<>();
// 카프카 클러스터 주소 세팅 - 현재 열려있는 카프카 브로커 주소
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, prod_bootstrap_server);
// serializer key & value 세팅
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(config);
}
// Kafka Producer 객체 템플릿
@Bean
public KafkaTemplate<String, ChatMessageDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}- 카프카의 Broker로 메시지나 데이터를 보내줄 Producer의 설정 파일이다.
- 현재 실습 기준으로 bootstrap-server는 {나의 Ec2 Public IP}:9092이고, .env파일을 통해 유출되지 않도록 처리를 해둔 상태이기 때문에, @Value를 통해 bootstrap_server의 값을 받아와서 진행하도록 설정하엿다.
- ProducerConfig 파일은 Kafka Broker에게 보내줄 데이터를 생성하는 역할을 하는 Producer 객체(Factory)와 Producer 사용을 위한 템플릿 객체로 이루어져 있다.
- Producer 객체를 생성할 때는 기본적으로 3가지 설정을 진행한다. (추가적 설정 필요)
=> 데이터를 전송할 Broker의 주소
=> Key & Value 직렬화 ( Java 객체를 네트워크로 전송하기 위해 바이트 스트림으로 변환)
( Dto -> JSON)
2. KafkaConsumerConfig.java
@Configuration
public class KafkaConsumerConfig {
private final KafkaProperties kafkaProperties;
@Value("${spring.kafka.consumer.bootstrap-servers}")
private String cons_bootstrap_server;
@Value("${spring.kafka.consumer.group-id}")
private String cons_group_id;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String cons_auto_offset_reset;
public KafkaConsumerConfig(KafkaProperties kafkaProperties) {
this.kafkaProperties = kafkaProperties;
}
// Kafka 메시지 수신하는 Consumer 객체 생성
@Bean
public ConsumerFactory<String, ChatMessageDto> consumerFactory(){
// Kafka에서 받은 메시지를 서버에 전달할 때 ChatMessageDto 객체로 변환해주는 Json 역질렬화
JsonDeserializer<ChatMessageDto> deserializer = new JsonDeserializer<>();
// 역질렬화 할 수 있는 패키지 지정
deserializer.addTrustedPackages("com.song.chatpractice.kafka.dto");
Map<String,Object> props = new HashMap<>();
// 카프카 클러스터 주소 세팅 - 현재 열려있는 카프카 브로커 주소
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, cons_bootstrap_server);
// 카프카 Consumer group Id 세팅 - 모든 서버에 메시지 전송을 위해서는 모두 다른 아이디 설정 필요
props.put(ConsumerConfig.GROUP_ID_CONFIG, cons_group_id);
// 카프카 Consumer offset 세팅 ( offset을 사용할 수 없거나 정보를 찾을 수 없을 떄 option)
// earlist - 가장 처음부터 읽기 , latest - 가장 마지막부터 읽기
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, cons_auto_offset_reset);
// 카프카 deserializer 설정
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, deserializer);
return new DefaultKafkaConsumerFactory<>(props, new StringDeserializer(), deserializer);
}
// Kafka 메시지를 수신 & 처리하는 리스너 컨테이너
@Bean
public ConcurrentKafkaListenerContainerFactory<String, ChatMessageDto> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, ChatMessageDto> kafkaListenerContainerFactory
= new ConcurrentKafkaListenerContainerFactory<>();
kafkaListenerContainerFactory.setConsumerFactory(consumerFactory());
return kafkaListenerContainerFactory;
}
}- 카프카의 Broker에 있는 Topic에서 데이터를 받아오는 Consumer의 설정 파일이다.
- Consumer의 설정 파일에서도 bootstrap 주소와 group-id, auto-offset-reset값을 .env파일로부터 받아와서 사용하였다.
- Consumer도 객체를 생성하는 Factory와 Kafka 메시지를 수신하는 리스너를 생성하는 Factory로 나누어져 있다.
- Consumer 객체를 생성하는 Factory는 기초적으로 5개의 세팅이 필요하다.
=> 데이터를 받아올 Broker의 주소
=> Consuemr 그룹 Id ( 같은 그룹의 Id를 가진 Consumer들이 메시지를 분산)
=> 데이터를 읽어오는 초기 오프셋 설정 (earlist / latest)
=> Key & Value 역질렬화 ( 네트워크에서 오는 바이트 스트림을 Java 객체로 변환)
( JSON -> Dto) - 추가적으로 JSON으로 넘어온 데이터를 내가 만든 Dto에 맞게 바로 역직렬화 해주기 위해서 추가 설정을 진행하였다.
- Kafka 메시지를 수신하는 리스너를 생성하는 Factory를 통해 리스너를 생성하면 @KafkaListner 어노테이션이 붙은 메소드가 kafka 메시지를 수신한다.
( 여러 스레드에서 동시에 메시지를 처리할 수 있게 해줌)
3. ChatMessageServiceImpl.java(Producer - sendMessage)
/* 설명. Kafka Producer의 sendMessage */
@Override
public void sendMessage(String roomId, ChatMessageDto chatMessageDto) {
// Kafka로 메시지 전송 (다른 서버들도 메시지를 받을 수 있도록)
String topicName = appName; // Kafka Topic 설정
log.info("메시지 보낸 토픽 이름 {}: 보낸 메시지 {}", topicName, chatMessageDto);
// ListenableFuture가 deprecated 되었음으로 대체
CompletableFuture<SendResult<String, ChatMessageDto>> future
// Kafka로 메시지 전송 ( 비동기 통신은 try-catch보다 completableFuture 사용)
= kafkaTemplate.send(topicName, roomId, chatMessageDto);
future.whenComplete((result, ex) -> {
if (ex == null){
log.info("메시지가 {}에 잘 전송되었습니다.", topicName);
// 메시지 전송 성공시 DB에 저장
ChatMessage chatMessage = new ChatMessage();
chatMessage.setRoomId(chatMessageDto.getRoomId());
chatMessage.setSender(chatMessageDto.getSender());
chatMessage.setMessage(chatMessageDto.getMessage());
chatMessage.setType(ChatMessage.MessageType.valueOf(chatMessageDto.getType().name()));
chatMessage.setSendDate(LocalDateTime.now());
chatMessageRepository.save(chatMessage);
log.info("{}가 잘 저장되었습니다..", chatMessage);
} else {
log.error("Kafka 토픽에 메시지 전송 실패 {}: {}",topicName, chatMessageDto, ex);
}
});
}
- Kafka Producer는 SendMessage를 통하여 Topic Name과 동일한 Kafka Broker의 Topic의 Leader Partition으로 데이터를 전송한다.
=> Topic이 존재하지 않을 경우
1) auto.create.topics.enable=true 설정이 되어있다면, Broker가 자동으로 Topic생성
(partition과 replication 갯수가 1개로 고정되어서 추가 설정이 불가능)
2) auto.create.topics.enable=false 설정이 되어있다면, 메시지 전송 실패
(이와 같은 방식으로 진행하여 필요한 Topic을 수종으로 생성하는 것을 "권장") - Kafka의 send()는 비동기 방식으로 처리되기 때문에, CompletableFuture 메소드를 사용하여 전송 처리의 오류 핸들링을 진행하였다.
( 제대로 전송이 되면, DB에 메시지를 저장하고, 제대로 처리가 안되면, error를 발생시키도록 하였다)
4. ChatMessageServiceImpl.java(Consumer - receiveMessage)
/* 설명. Kafka Consumer의 receiveMessage */
@KafkaListener(topics = "${APP_NAME}", groupId = "${KAFKA_GROUP_ID}")
public void receiveMessage(ChatMessageDto chatMessageDto) {
log.info("Received message in group {}: {}", "groupId", chatMessageDto);
// 모든 WebSocket 서버가 Kafka 메시지를 받아서 WebSocket으로 전달!
simpMessagingTemplate.convertAndSend("/topic/room/" + chatMessageDto.getRoomId(), chatMessageDto);
}- Kafka Consumer는 receiveMessage를 통해 topic에 해당하는 이름의 토픽을 리스닝 하면서, Broker로부터 GroupId에 해당하는 Consumer 그룹으로 데이터를 가져온다.
- 가져온 데이터를 Websokcet을 사용하여 해당 토픽을 구독하고 있는 사용자들에게 메세지를 전달해준다.
위의 추가적인 코드들을 통해서 다른 서버의 Kafka Broker를 등록하고 해당 경로로 데이터를 보내고 받으면서, 채팅 서버를 구성하였다.
결과 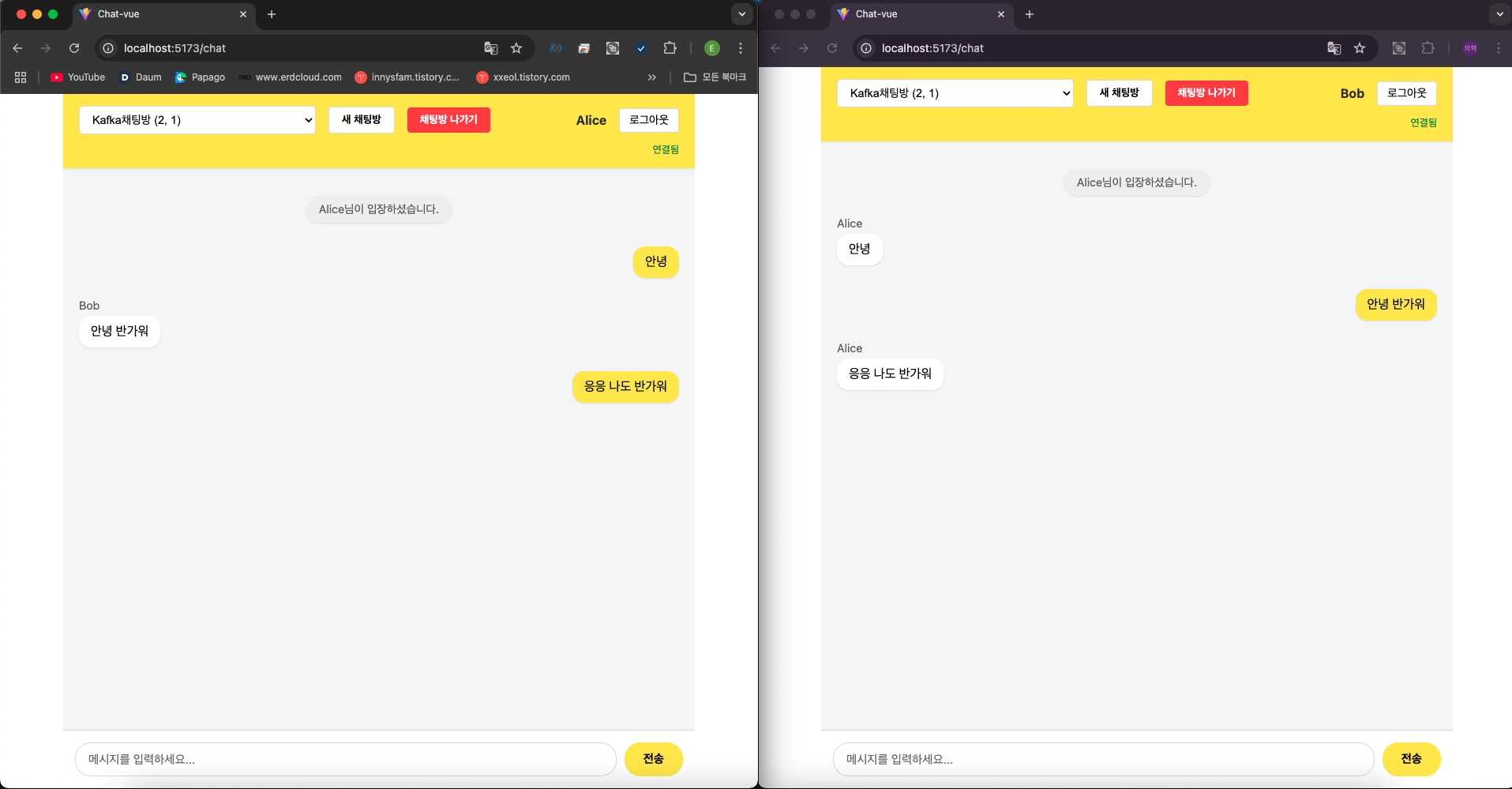
- Kafka를 통한 채팅 서비스가 잘 작동하는 것을 확인할 수 있다.
- EC2 1개를 이용하여 채팅 서비스 실습을 진행하여 보았고, EC2 3개를 이용해서 기본 권장사항인 Broker 3개를 띄워서 통신 호환이 잘 되는지도 살펴볼 생각이다.
