💡 연결리스트에 대해서 알아보자!!
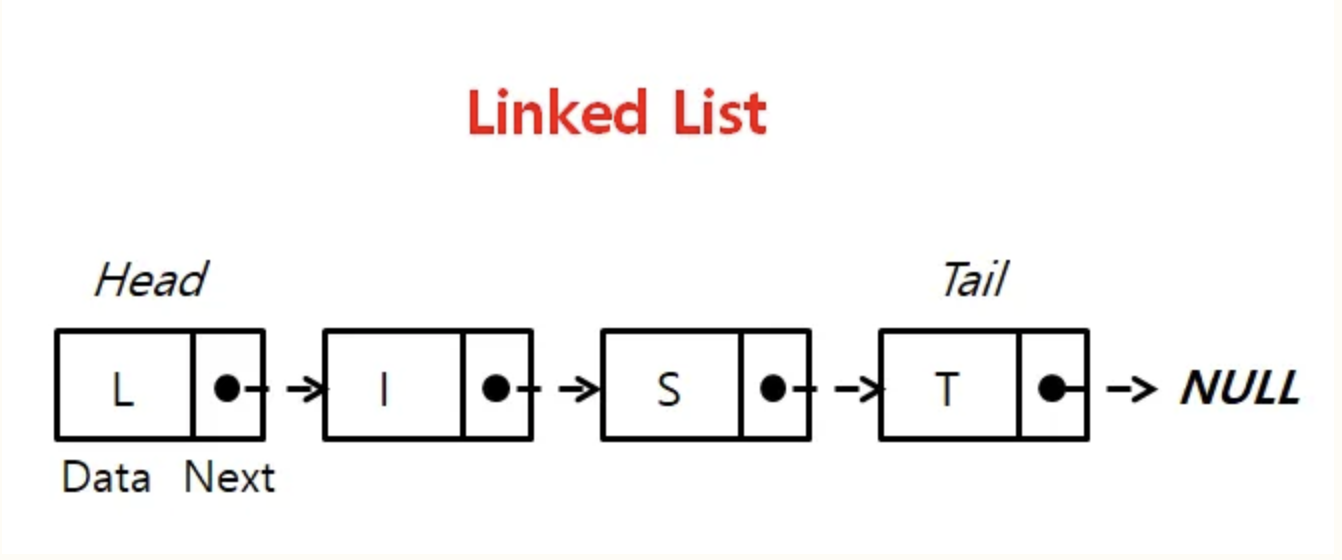
1. 연결리스트란?
- 각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조
2. 연결리스트의 특징
- K번째 원소를 확인 or 변경 => O(K)
- 임의의 위치에 원소 추가 or 제거 => O(1)
=> 배열 대신 연결리스트를 사용하는 이유 - Cache hit rate가 낮지만, 할당이 쉬움
=> 원소들이 메모리 상 연속하지 않기 때문에
3. 연결리스트의 종류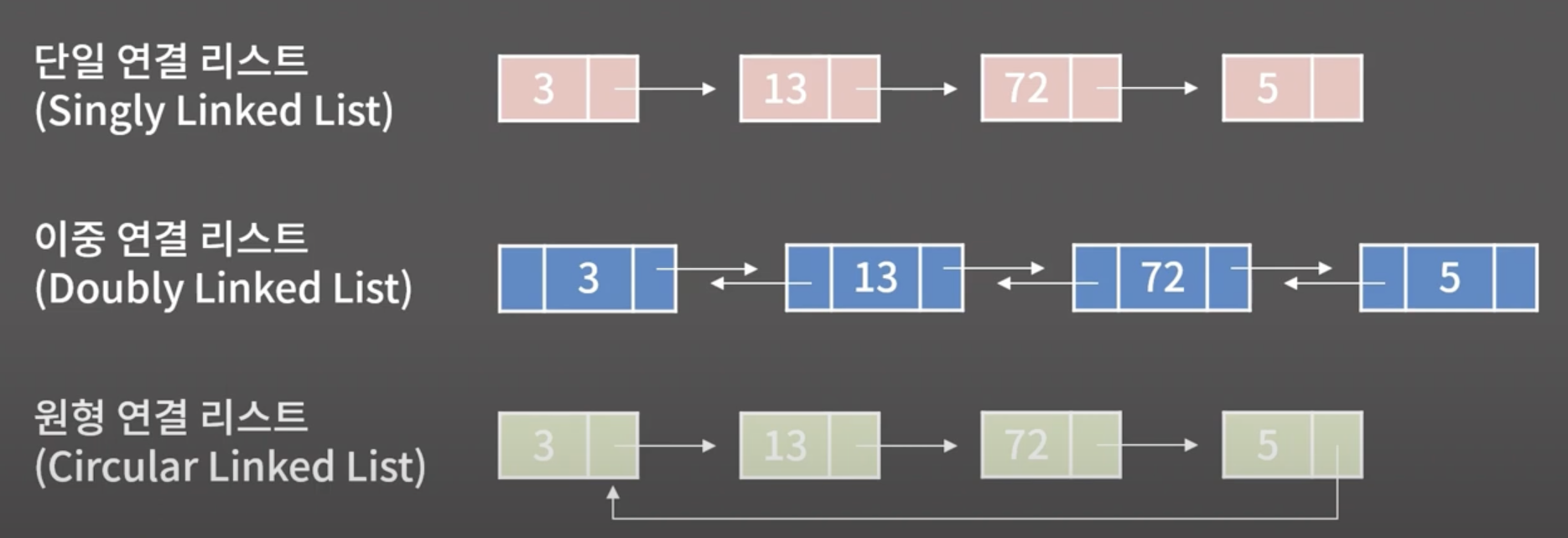
- 단일 연결 리스트: 각 원소가 자신의 다음 원소의 주소를 가지고 있는 리스트
- 이중 연결 리스트: 각 원소가 자신의 다음 + 이전 원소의 주소를 모두 가지고 있는 리스트
=> 메모리를 더 쓴다는 단점이 있다. - 원형 연결 리스트: 단일 연결 리스트 + 마지막 원소가 첫번쨰 원소의 주소를 가지고 있는 리스트
4. 배열 vs 연결리스트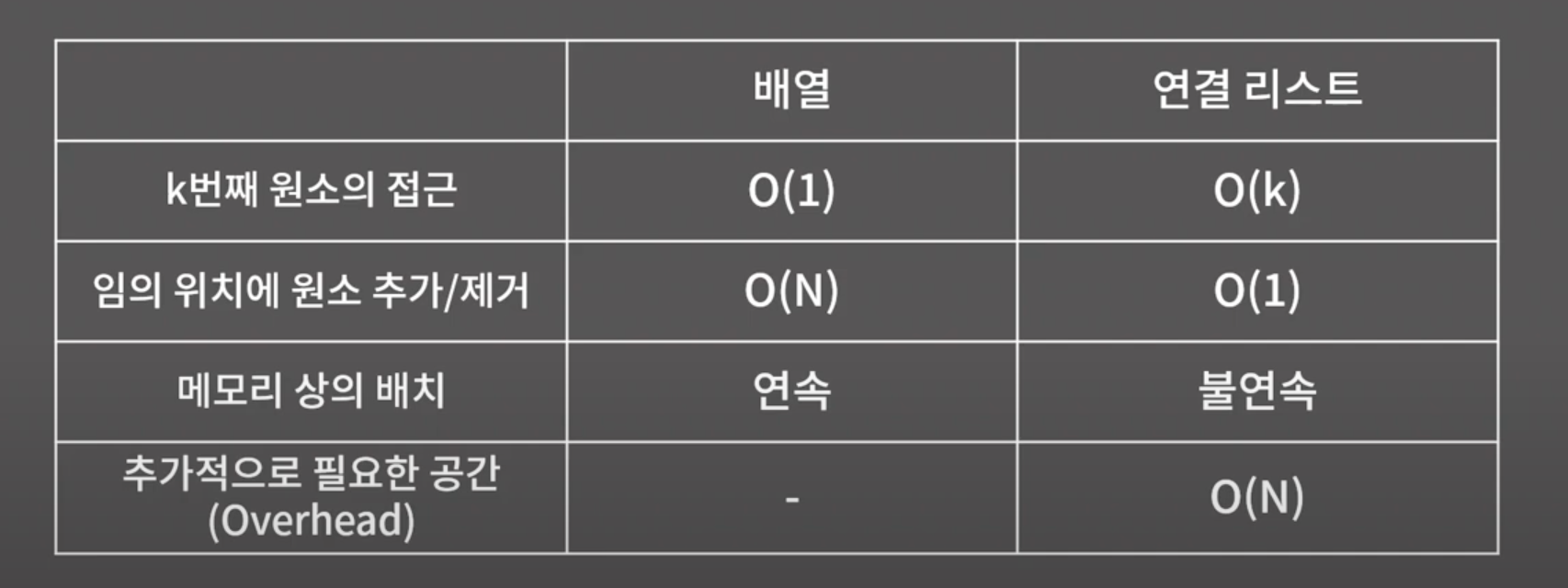
- 연결리스트는 임의 위치에 원소를 추가하거나 삭제할 경우 시간복잡도가 배열보다 훨씬 작기 때문에 이를 중점적으로 볼 필요가 있다.
=> 단, 추가하고 싶은 위치의 주소를 알 경우에만 O(1)이다. - 하지만, 배열과 다르게 다음 원소에 대한 주소값을 추가로 저장해야 하기 때문에, 원소 갯수만큼의 메모리 공간이 추가적으로 필요하다.
5. 연결 리스트를 사용하는 경우
- 원소를 임의의 위치에 추가하거나 제거하는 상황이 많은 경우
- ex) 커서를 왔다갔다 하면서 추가, 삭제하는 메모장같은 텍스트 데이터
6 연결 리스트를 코테에 쓰는 방법
연결리스트 직접 구현
# 노드 정의 & 초기화
class ListNode:
def __init__(self, val=0, next = None):
self.val = val
self.next = next
class LinkedList:
def __init__(self):
self.head = None
# 맨 마지막 원소 추가
def append(self,value):
new_Node = ListNode(val)
# 맨 처음 노드일 경우
if self.head is None:
self.head = new_Node
else:
curr = self.head
# 맨 마지막까지 조회 후 추가
while curr.next != None:
curr = curr.next
curr.next = new_Node
# 특정 idx 값 가져오기 (조회 + 값 가져오기)
def get(self, idx):
curr = self.head
for i in range(idx):
curr = curr.next
return curr.value
# 특정 위치에 값 추가
def insert(self, idx,val):
# 새로운 노드 추가
new_Node = ListNode(val)
curr = self.head
for i in range(idx-1):
curr = curr.next
new_Node.next = curr.next
curr.next = new_Node
# 특정 위치 값 삭제
def remove(self, idx):
curr = self.head
target = self.head
for i in range(idx-1):
target = target.next
for j in range(idx):
curr = curr.next
target.next = curr.next- 위는 연결리스트와 그의 기능등을 깡으로 구현한 코드이다.
- 사실 코테 측면에서는 코드가 너무 길기 떄문에, 잘 사용하진 않지만, 각 기능에 맞춰서 구현을 진행하였다.
- 핵심은 head와 next를 통해서 현재 노드와 다음노드를 잘 지정해주면 된다.
⌘ 파이썬은 List와 deque가 존재하기 때문에 연결리스트를 잘 사용하지는 않는다.

매일매일 차근차근 나아가보는 개발일기