
1. kubectl
관리자가 K8S 클러스터를 제어하는 데 사용하는 유틸리티이며 컨트롤 플레인에서 kube-apiserver와 통신하는 데 사용된다.
kubectl로 작업을 수행하려면 다음과 같이 구성해야한다. k8s 클러스터의 위치 및 자격 증명을 예로 들어 클러스터에서 포드 목록을 보려는 관리자를 예로 들어보면, 적절한 자격 증명으로 kubectl을 클러스터에 연결한 후, 관리자는 kubectl get pods명령을 실행할 수 있다.
그러면 , kubectl 은 이를 API 호출로 변환하여 클러스터의 컨트롤 플레인 서버에서 HTTPS를 통해 kube-apiserver로 보낸다.
다음으로 kube-apiserver는 etcd를 쿼리하여 요청을 처리하고 kube-apiserver 는 HTTPS를 통해 kubectl에 결과를 반환한다. 마지막으로 kubectl은 API 응답을 해석하고 터미널(명령 프롬포트)에서 관리자에게 결과를 표시한다.
kubectl을 사용하려면 먼저 클러스터를 구성해야 한다. kubectl 은 .kube라는 홈디렉토리에 숨겨진 디렉토리의 파일에 구성을 저장한다. 구성 파일에는 클러스터 목록과 각 클러스터에 연결하는 데 사용할 자격 증명이 포함되어 있다.
이러한 자격 증명은 GKE의 경우 서비스에서 gcloud 명령어를 통해 이를 제공하고 또한 GKE 클러스터를 kubectl 과 연결하려면 먼저 지정된 클러스터의 사용자 인증 정보를 검색해야 하고, 다른 환경에서 get-credentials gcloud 명령어를 사용하면 된다.
gcloud 도구 및 kubectl 은 모두 Cloud Shell에 기본적으로 설치가 되어있다는 장점이 있으며, gcloud-get-credentials 명령은 구성 정보를 .kube 디렉토리의 config파일에 쓴다.
디버깅 명령어
- describe
kubectl describe [객체]객체에 대한 자세한 정보를 제공하며 포드 내에서 테스트 및 디버그 할 수 있다 - exec
명령 및 애플리케이션을 실행하기 위한exec my-pod-name - logs
Pod 내부에서 일어나느 일을 볼 수 있는 강력한 기능
Pod 내부에서 실행되는 애플리케이션이 작성하는디버깅 메시지,실행에 실패한 컨테이너에 대한 자세한 정보를 찾아야 할 때 특히 유용하다.
2. Cloud Shell에서 Google Kubernetes Engine 클러스터 배포
- Cloud Shell Enabled
GKE 클러스터 배포
Cloud Shell에서 다음 명령을 입력하여 영역 및 클러스터 이름에 대한 환경 변수를 설정
export my_zone=us-central1-a
export my_cluster=standard-cluster-1Kubernetes 클러스터 생성(GKE의 default 클러스터)
gcloud container clusters create $my_cluster --num-nodes 3 --zone $my_zone --enable-ip-alias프로비저닝 되는데 꽤 시간이 소요된다.
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ export my_zone=us-central1-a
export my_cluster=standard-cluster-1
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ gcloud container clusters create $my_cluster --num-nodes 3 --zone $my_zone --enable-ip-alias
Default change: During creation of nodepools or autoscaling configuration changes for cluster versions greater than 1.24.1-gke.800 a default location policy is applied. For Spot and PVM it defaults to ANY, and for all other VM kinds a BALANCED policy is used. To change the default values use the `--location-policy` flag.
Note: The Pod address range limits the maximum size of the cluster. Please refer to https://cloud.google.com/kubernetes-engine/docs/how-to/flexible-pod-cidr to learn how to optimize IP address allocation.
Creating cluster standard-cluster-1 in us-central1-a... Cluster is being health-checked...working... GKE 클러스터 수정
standard-cluster-1 가 4개의 노드를 갖도록 수정
gcloud container clusters resize $my_cluster --zone $my_zone --num-nodes=4GKE 클러스터에 연결
Cloud Shell을 사용하여 GKE 클러스터에 인증한 다음 kubectl 구성 파일을 검사한다 또한 Kubernetes의 인증은 마스터에서 실행되는 kube-APIserver를 통해 외부 클라이언트에서 클러스터와 통신하는 것과 클러스터 내에서 또는 외부에서 통신하는 클러스터 컨테이너에 모두 적용된다.
GKE의 경우 인증은 일반적으로 OAuth2 토큰으로 처리되며 프로젝트 전체에서 Cloud Identity and Access Management 를 통해 관리할 수 있으며 선택적으로 각 클러스터 내에서 정의 및 구성할 수 있는 역할 기반 액세스 제어를 통해 관리할 수 있다.
GKE에서 클러스터 컨테이너는 서비스 계정을 사용하여 외부 리소스를 인증하고 액세스할 수 있다.
현재 사용자의 자격 증명으로 kubeconfig 파일을 생성하고(인증을 허용하기 위해) 특정 클러스터에 대한 엔드포인트 세부 정보를 제공하려면(명령줄 도구를 통해 해당 클러스터와 통신할 수 있도록 하기 위해) 다음 명령을 실행한다.
gcloud container clusters get-credentials $my_cluster --zone $my_zonekubeconfig 파일열어보기
nano ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUVMVENDQXBXZ0F3SUJBZ0lSQVBGbmhsSWN6NGpYSFdMTjAxb1ZEcE13RFFZSktvWklodmNOQVFFTEJRQXcKTHpFdE1Dc0dBMVVFQXhNa1lXSTFNVGt4TXpndFpqUmhZUzA>
server: https://35.223.44.75
name: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
contexts:
- context:
cluster: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
user: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
name: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
current-context: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
kind: Config
preferences: {}
users:
- name: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
user:
exec:
apiVersion: client.authentication.k8s.io/v1beta1
command: gke-gcloud-auth-pluginkubectl 을 사용하여 GKE 클러스터 검사
kubeconfig 파일이 채워지고 활성 컨텍스트가 특정 클러스터로 설정되면 kubectl명령줄 도구를 사용하여 클러스터에 대해 명령을 실행할 수 있고, 대부분의 이러한 명령은 궁극적으로 연결된 작업을 트리거하는 마스터 API 서버에 대해 REST API 호출을 트리거한다.
kubectl config view
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://35.223.44.75
name: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
contexts:
- context:
cluster: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
user: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
name: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
current-context: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
kind: Config
preferences: {}
users:
- name: gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
user:
exec:
apiVersion: client.authentication.k8s.io/v1beta1
args: null
command: gke-gcloud-auth-plugin
env: null
installHint: Install gke-gcloud-auth-plugin for use with kubectl by following
https://cloud.google.com/blog/products/containers-kubernetes/kubectl-auth-changes-in-gke
interactiveMode: IfAvailable
provideClusterInfo: true
kubectl cluster-info
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl cluster-info
Kubernetes control plane is running at https://35.223.44.75
GLBCDefaultBackend is running at https://35.223.44.75/api/v1/namespaces/kube-system/services/default-http-backend:http/proxy
KubeDNS is running at https://35.223.44.75/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
Metrics-server is running at https://35.223.44.75/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
$ kubectl config current-context
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl config current-context
gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
#형식
[gke_ [PROJECT_ID]_us-central 1 -a_standard-cluster- 1]
$ kubectl config get-contexts
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1 gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1 gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1
# 활성 컨텍스트 변경
$ kubectl config use-context gke_${GOOGLE_CLOUD_PROJECT}_us-central1-a_standard-cluster-1
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl config use-context gke_${GOOGLE_CLOUD_PROJECT}_us-central1-a_standard-cluster-1
Switched to context "gke_qwiklabs-gcp-02-25f40659a240_us-central1-a_standard-cluster-1".
# 클러스터 노드 전체의 리소스 사용량을 확인
$ kubectl top nodes
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
gke-standard-cluster-1-default-pool-fe8d27b2-mzjh 106m 11% 911Mi 32%
gke-standard-cluster-1-default-pool-fe8d27b2-nkkm 97m 10% 1102Mi 39%
gke-standard-cluster-1-default-pool-fe8d27b2-svsf 85m 9% 920Mi 32%
gke-standard-cluster-1-default-pool-fe8d27b2-x52s 121m 12% 852Mi 30%
# bash 자동 완성을 활성화
$ source <(kubectl completion bash)
GKE 클러스터에 Pod 배포
kubectl create deployment --image nginx nginx-1
kubectl get pods
# 실습 전체에서 사용할 변수에 Pod 이름을 입력
export my_nginx_pod=nginx-1-779946684f-g7xxc
echo $my_nginx_pod
kubectl describe pod $my_nginx_pod
컨테이너에 파일 푸시
nano ~/test.html
------
<html> <header><title>This is title</title></header>
<body> Hello world </body>
</html>
------
# 파일 옮기기
kubectl cp ~/test.html $my_nginx_pod:/usr/share/nginx/html/test.html테스트를 위해 Pod 외부로 노출시키기
kubectl expose pod $my_nginx_pod --port 80 --type LoadBalancer
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.12.0.1 <none> 443/TCP 39m
nginx-1-779946684f-g7xxc LoadBalancer 10.12.4.169 34.69.152.188 80:30390/TCP 68s
curl http://[EXTERNAL_IP]/test.html
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
kubectl top pods
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl top pods
NAME CPU(cores) MEMORY(bytes)
nginx-1-779946684f-g7xxc 0m 3Mi GKE Pod 검사
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
# 바로가기 링크 등록
ln -s ~/training-data-analyst/courses/ak8s/v1.1 ~/ak8s
cd ~/ak8s/GKE_Shell/
student_03_e94b00dc6527@cloudshell:~/ak8s/GKE_Shell (qwiklabs-gcp-02-25f40659a240)$ ls
new-nginx-pod.yaml test.html
kubectl apply -f ./new-nginx-pod.yaml
셸 디렉션을 사용하여 Pod 에 연결
kubectl exec -it new-nginx /bin/bash
student_03_e94b00dc6527@cloudshell:~/ak8s/GKE_Shell (qwiklabs-gcp-02-25f40659a240)$ kubectl exec -it new-nginx /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@new-nginx:/# apt-get update
apt-get install nano
cd /usr/share/nginx/html
nano test.html
----
<html> <header><title>This is title</title></header>
<body> Hello world </body>
</html>
----
exit
# 포트포워딩
kubectl port-forward new-nginx 10081:80
새 터미널열어 결과 확인

Pod 의 Log 보기
kubectl logs new-nginx -f --timestamps
## 두 번째 Cloud Shell 창으로 돌아가서 curl 명령을 다시 실행하여 Pod에서 일부 트래픽을 생성
student_03_e94b00dc6527@cloudshell:~ (qwiklabs-gcp-02-25f40659a240)$ kubectl logs new-nginx -f --timestamps
2023-07-19T02:47:08.845520523Z /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
2023-07-19T02:47:08.846321386Z /docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
2023-07-19T02:47:08.849594181Z /docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
2023-07-19T02:47:08.856697972Z 10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
2023-07-19T02:47:08.865135864Z 10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
2023-07-19T02:47:08.865560493Z /docker-entrypoint.sh: Sourcing /docker-entrypoint.d/15-local-resolvers.envsh
2023-07-19T02:47:08.865711928Z /docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
2023-07-19T02:47:08.869148060Z /docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
2023-07-19T02:47:08.871004541Z /docker-entrypoint.sh: Configuration complete; ready for start up
2023-07-19T02:47:08.878632642Z 2023/07/19 02:47:08 [notice] 1#1: using the "epoll" event method
2023-07-19T02:47:08.878686924Z 2023/07/19 02:47:08 [notice] 1#1: nginx/1.25.1
2023-07-19T02:47:08.878695624Z 2023/07/19 02:47:08 [notice] 1#1: built by gcc 12.2.0 (Debian 12.2.0-14)
2023-07-19T02:47:08.878703827Z 2023/07/19 02:47:08 [notice] 1#1: OS: Linux 5.15.107+
2023-07-19T02:47:08.878716570Z 2023/07/19 02:47:08 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2023-07-19T02:47:08.878898035Z 2023/07/19 02:47:08 [notice] 1#1: start worker processes
2023-07-19T02:47:08.879130406Z 2023/07/19 02:47:08 [notice] 1#1: start worker process 29
2023-07-19T02:47:08.879401682Z 2023/07/19 02:47:08 [notice] 1#1: start worker process 30
2023-07-19T02:50:07.904750808Z 127.0.0.1 - - [19/Jul/2023:02:50:07 +0000] "GET /test.html HTTP/1.1" 200 88 "-" "curl/7.74.0" "-"
2023-07-19T02:51:45.769672338Z 127.0.0.1 - - [19/Jul/2023:02:51:45 +0000] "GET /test.html HTTP/1.1" 200 88 "-" "curl/7.74.0" "-"
2023-07-19T02:51:47.832076360Z 127.0.0.1 - - [19/Jul/2023:02:51:47 +0000] "GET /test.html HTTP/1.1" 200 88 "-" "curl/7.74.0" "-"
2023-07-19T02:51:52.533044732Z 127.0.0.1 - - [19/Jul/2023:02:51:52 +0000] "GET /test.html HTTP/1.1" 200 88 "-" "curl/7.74.0" "-"
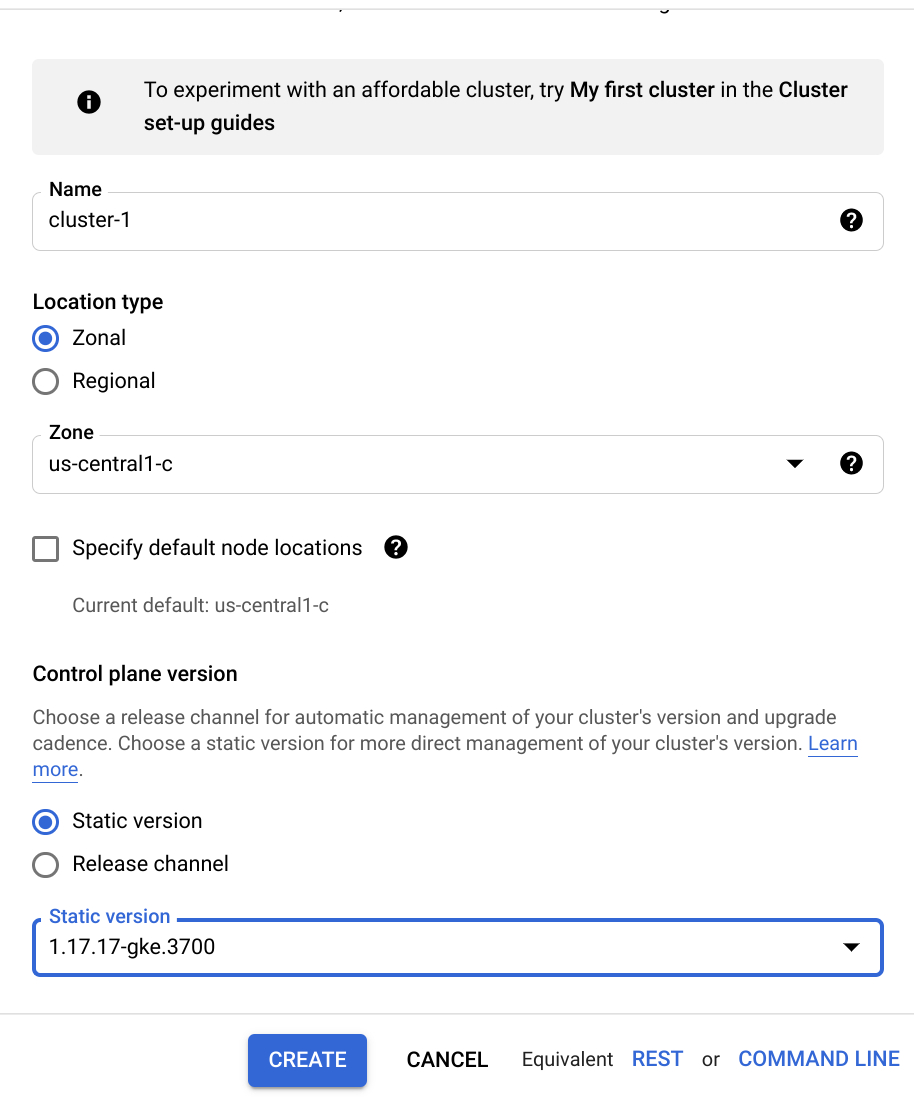
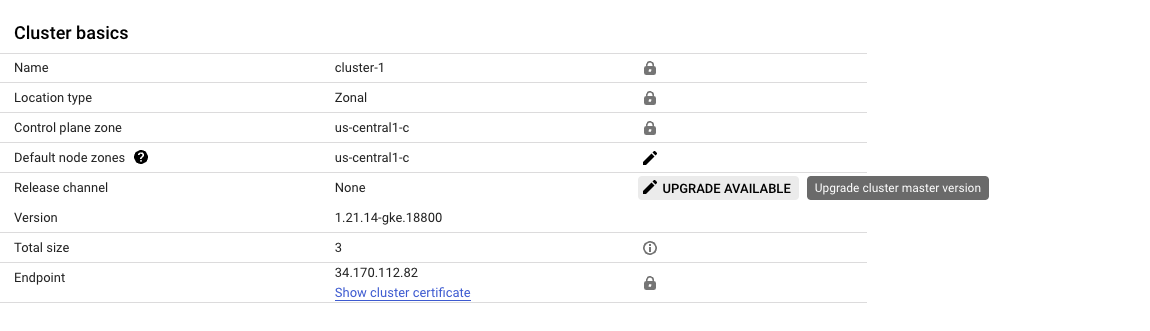
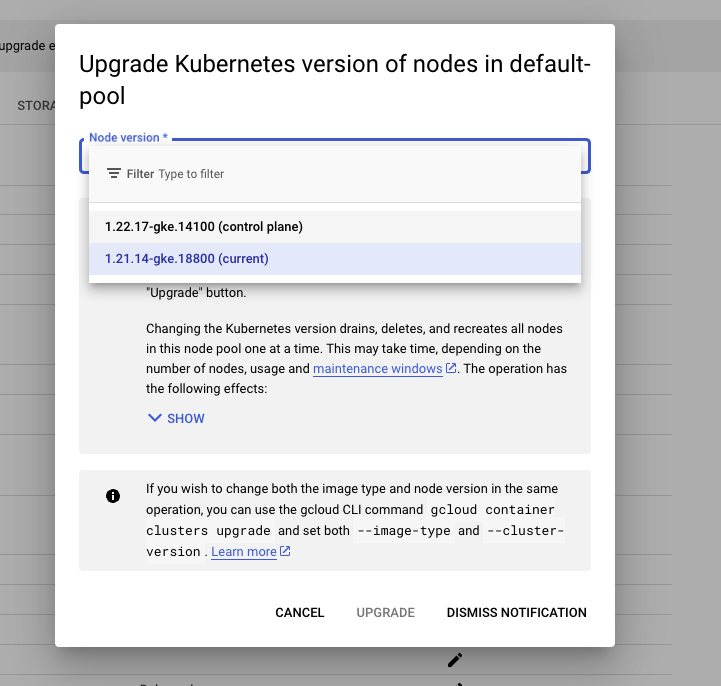
2. GKE 클러스터 업그레이드
콘솔 ➡️ Kubernetes Engine ➡️ 클러스터 ➡️ GKE Standard
- Control Plane Version
- Static Version - 가장 하위 version 선택
- 다른 구성은 Default

사용 가능한 업그레이드 링크를 클릭하여 업그레이드 마법사를 시작 하여 사용 가능한 가장 최근(가장 높은) 빌드를 선택한 다음 변경 사항 저장
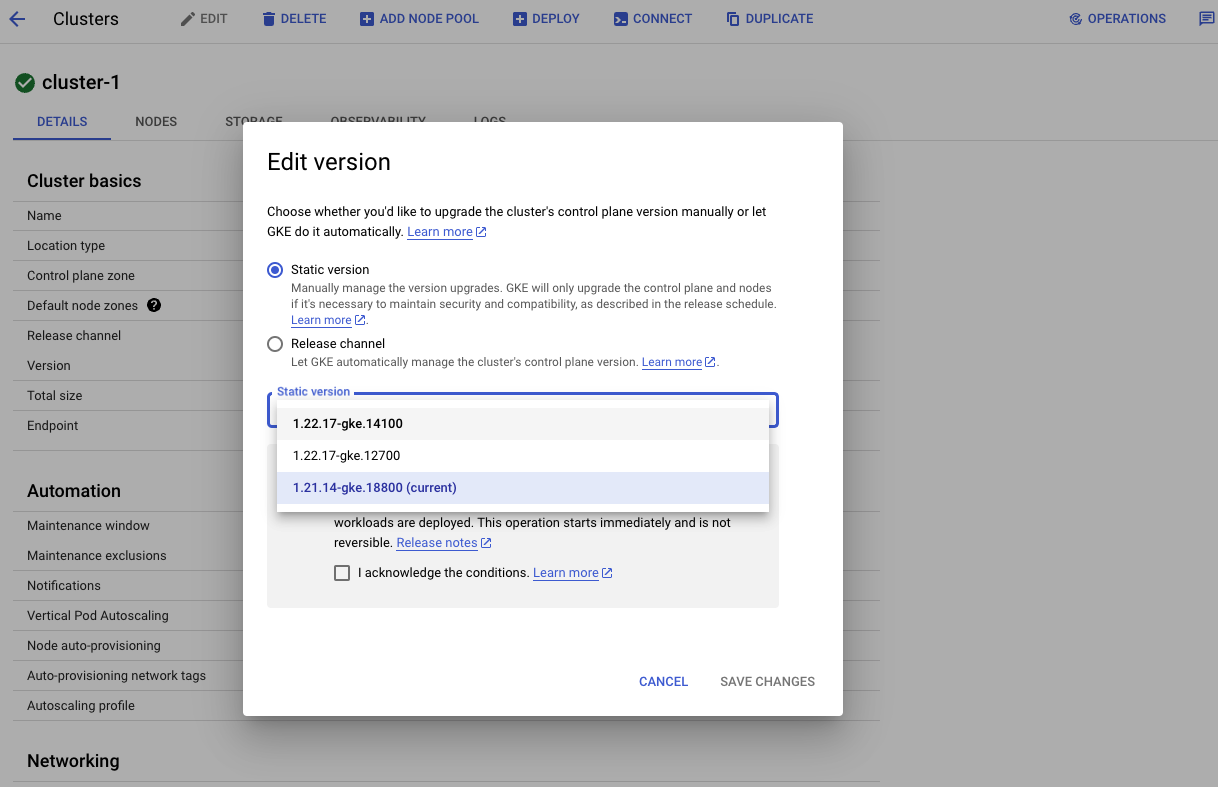
참고: 버전 번호는 major.minor.patch 형식으로 표시됩니다.
예를 들어 버전 1.14.10에서 1 .14.10은 주 버전이고,
1. 14 .10은 부 버전이며 1.14입니다. 10은 패치 버전입니다.
업그레이드하려는 버전이 현재 버전에서 1개 이상의 부 버전인 경우.
이 단계를 단계별로 수행해야 할 수도 있습니다.
예를 들어 먼저 1.14.10 에서 1.15.11 로 업그레이드한 다음
1.15.11 에서 최신 버전( 1.16.9 ) 으로 업그레이드합니다 .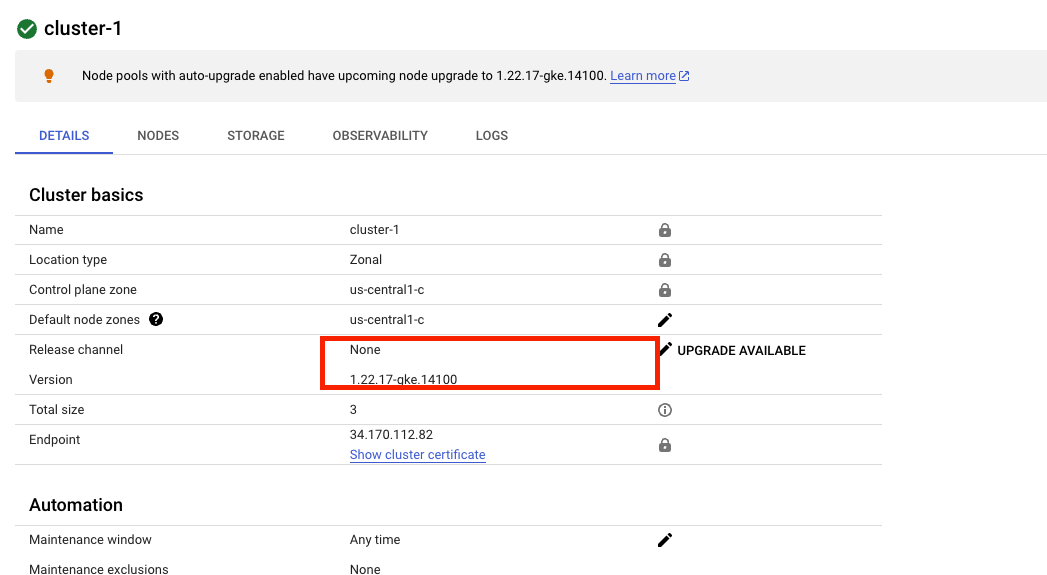
클러스터의 노드 풀 업그레이드

3. 업데이트 및 배포 전략
블루 그린 배포
Recreate 는 새 Pod가 생성되기 전에 기존 Pod를 모두 삭제하는 전략 유형이며, 새 Pod를 생성해야 하고 모든 포드를 즉시 사용할 수는 없기 때문에 이는 고가용성에 분명히 영향을 미친다
예를 들어 애플리케이션 부분 간의 통신 계약이 변경되고 완전히 중단해야 하는 경우에는 어떻게 해야할까? 이러한 상황에서는 지속적인 배포 전략이 적합하지 않다.
모든 복제본을 한 번에 변경해야 하며, 이럴때 Recreate 전략이 권장된다. 요청 및 제한은 Kubernetes가 CPU 메모리와 같은 리소스를 제어하는 데 사용하는 메커니즘이다.
요청은 컨테이너가 확실히 얻을 수 있는 것이며 컨테이너가 리소스를 요청하면 k8s는 해당 리소스를 제공할 수 있는 노드에서만 예약한다. 반면, 제한은 컨테이너가 특정 값을 초과하지 않도록 하는 것이다. 컨테이너는 한도까지만 허용된 다음 제한되며 한도는 요청보다 낮을 수 없다는 점을 기억하는 것이 중요하다
요청 및 제한은 컨테이너별로 적용되며 Pod는 일반적으로 단일 컨테이너를 포함하지만 여러 컨테이너가 있는 Pod 도 많다 따라서 Pod의 각 컨테이너는 고유한 개별 한도 및 요청을 받지만 Pod는 항상 그룹으로 예약 되기 때문에 제한을 추가해아한다.
Pod에 대한 집계를 얻기 위해 각 컨테이너에 대한 요청을 함께 요청하는데 컨테이너가 가질 수 있는 요청 및 제한을 제어하기 위해 컨테이너 수준 및 네임스페이스 수준에서 할당량을 설정할 수 있다.
Pod의 컨테이너에 대한 리소스 요청을 지정하면 Kube-Scheduler는 이 정보를 사용하여 Pod를 배치할 노드를 결정한다. 반대로 컨테이너에 대한리소스 제한을 지정하면 kubelet은 최소한 요청 금액을 예약한다.
블루/그린 배포 전략은 애플리케이션의 새 버전을 개발하고 배포가 업데이트 되는 동안 애플리케이션을 계속 사용할 수 있도록 하려는 경우에 유용하다.
기존에, my-app-v1 의 이미지를 가진 배포가 있고 my-app-v2 로 새 배포의 포드가 준비되면 트래픽을 전환할 수 있다.
여기서 k8s 서비스가 사용되며 서비스를 사용하면 선택한 포드에 대한 네트워크 트래픽 흐름을 관리할 수 있다.
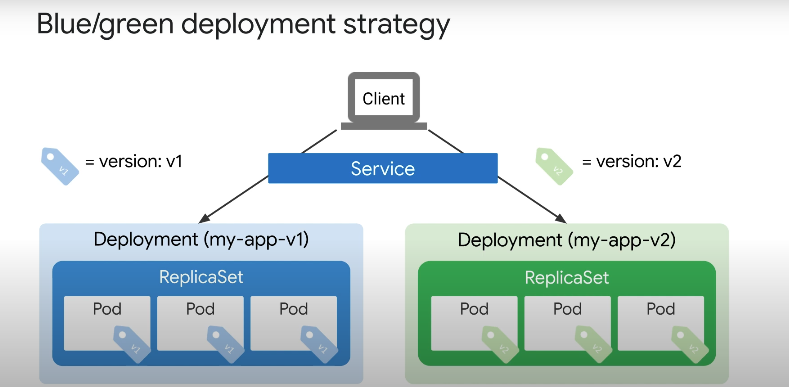

서비스 정의에서 레이블을 기반으로 포드가 선택되며, selector 위의 예시에서 Pod는 my-app 버전 1에 속한다. 이 경우 버전 2로 라벨이 지정된 새 배포가 생성되고 준비되면 서비스의 버전 라벨이 최신으로 변경된다.
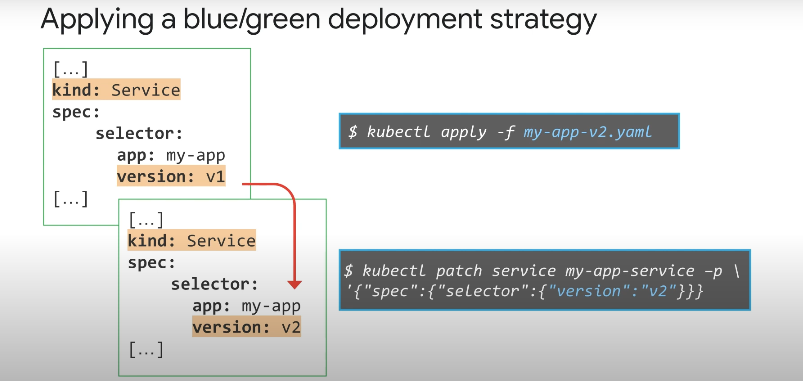
이 경우에는 버전2로 레이블이 지정된 버전이다. 이제 트래픽은 버전1 레이블에 있는 블루 배포 Pod 대신 버전2 레이블이 있는 최신 Pod 집합인 그린 배포로 전달된다.
이제 이전 버전의 블루 배포를 삭제할 수 있으며 블루/그린 배포 전략의 장점은 새로운 롤아웃이 즉시 가능하고 최신 버전을 테스트할 수 있다는 장점이 있다.
전체 사용자에 배포하기 전에 내부적으로 테스트를 위해 별도의 서비스 정의를 사용하기 때문에 리소스 사용량이 두배가 된다는 단점이 있긴하다.
카나리 배포
카나리 배포는 블루/그린 방식을 기반으로 한 또 다른 업데이트 전략이지만 트래픽은 점차 새 버전으로 이동한다는 장점이 있다.
업데이트 중 과도한 리소스 사용 및 롤아웃이 점진적이기 때문에 문제가 애플리케이션의 모든 인스턴스에 영향을 미치기 전에 식별할 수 있다.
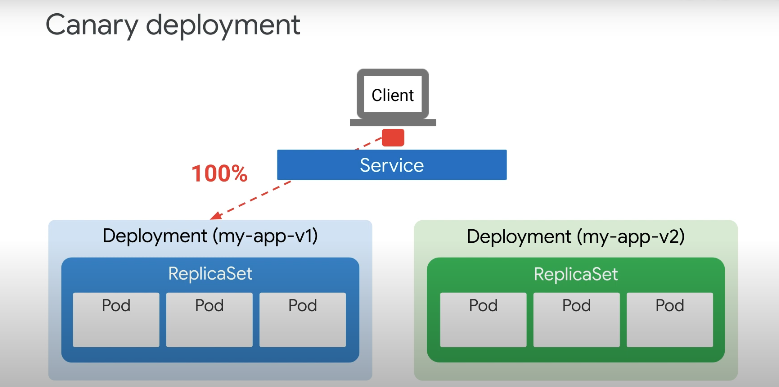
100% 의 트래픽이 처음에 버전 1으로 전달되지만, 카나리아 배포가 시작되면 트래픽의 하위 집합 10% 가 버전 2로 리디렉션 된다.
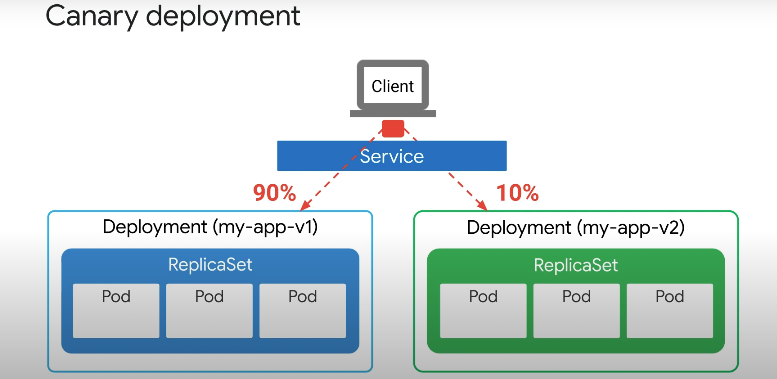
새 버전의 안정성이 확인되면 새 버전으로 라우팅할 수 있다.
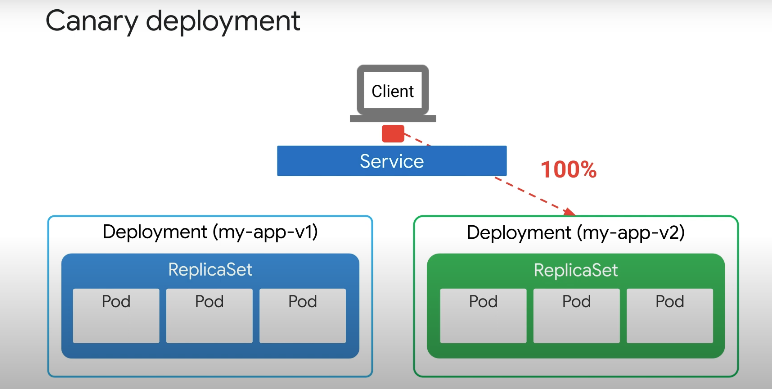
이것이 이루어지는 방법은 무엇일까? 이전에 다룬 블루그린 업데이트 전략에서 앱과 버전 레이블은 모두 서비스에서 선택되었으므로 트래픽은 당연히 서비스에 정의된 버전을 향하여 전송된다.
카나리아 업데이트 전략에서 서비스 Selector는 애플리케이션 레이블만을 기반으로 하며 버전을 지정하지 않는다.

Selector 는 app:my-app 라벨이 있는 모든 Pod를 포함하며 즉, 서비스의 카나리아 업데이트 전략을 사용하면 버전 레이블에 관계없이 트래픽이 모든 포드로 전송된다.

이 설정을 사용허면 서비스가 두 배포에서 Pod로 트래픽을 선택하고 보낼 수 있고, 처음에 배포의 새 버전은 실행 중인 복제본이 없는 상태에서 시작된다.

시간이 지남에 따라 새 버전이 확장되면 배포의 이전 버전이 축소되고 결국 삭제될 수 있다. 카나리아 업데이트 전략을 사용하면 사용자 하위 집합이 새버전으로 안내되며 이를 통해 새 버전을 사용할 때 오류 및 성능 문제를 모니터링 하고 신속하게 롤백할 수 있다.
문제가 발생할 경우 전체 사용자 기반에 미치는 영향을 최소화 하지만, 배포의 전체 롤 아웃은 느린 프로세스일 수 있으며 istio 같은 도구가 필요할 수 있다.
A/B 테스트
변형 구현을 사용하여 가설을 테스트한다. A/B 테스트는 데이터에서 파생된 결과를 기반으로 비즈니스 결정을 내리는 데 사용된다.
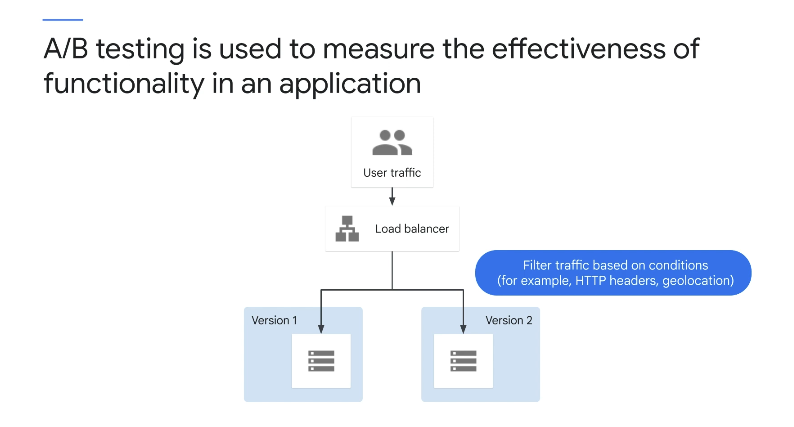
A/B 테스트를 수행할 때 여기의 예와 같이 라우팅 규칙에 따라 사용자 하위 집합을 새로운 기능으로 라우팅하며, 라우팅 규칙에는 종종 브라우저와 같은 요소가 포함됩니다.
버전, 사용자 에이전트, 지리적 위치 및 운영 체제 버전을 측정하고 비교한 후 더 나은 결과를 가져온 버전으로 프로덕션 환경을 업데이트한다. A/B 테스트는 측정에 가장 적합하다.
이전에 논의된 배포 패턴의 사용 사례는 새 소프트웨어를 안전하게 릴리스하고 예측 가능하게 롤백하는 데 중점을 두고, A/B 테스트에서는 새로운 기능에 대한 대상 고객을 제어하고 모니터링한다.
카나리아 테스트와 같은 순차적 실험 기술은 테스트 초기 단계에서 잠재적으로 고객을 열악한 애플리케이션 버전에 노출시킬 수 있다.
쉐도우 테스트
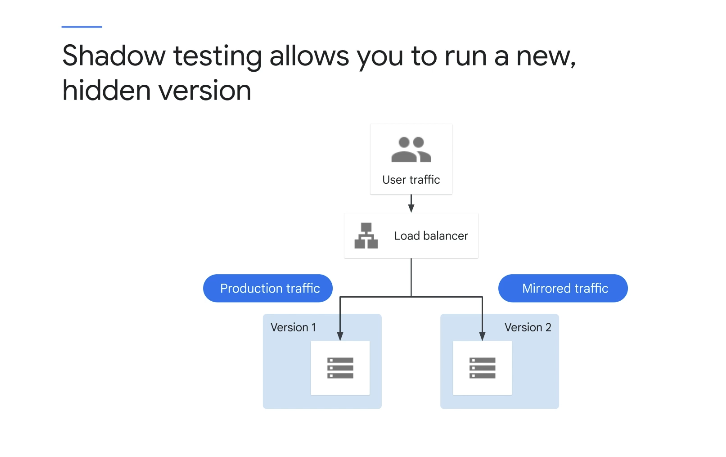
섀도 테스트를 사용하면 현재 버전과 함께 새 버전을 배포하고 실행할 수 있지만 표시된 다이어그램과 같이 새 버전이 사용자에게 표시되지 않는다.
들어오는 요청은 미러링되어 테스트 환경에서 재생되며, 이 프로세스는 실시간으로 또는 이전에 캡처한 프로덕션 트래픽을 복사한 후 비동기적으로 발생할 수 있다.
새로 배포된 서비스에 대해 재생되며, 섀도우 테스트가 기존 프로덕션 환경이나 사용자 상태를 변경할 수 있는 부작용을 유발하지 않도록 해야 한다
쉐도우 테스트에는 많은 장점이 있다. 트래픽이 복제되기 때문에 섀도우 데이터를 처리하는 버그 및 서비스는 프로덕션에 영향을 미치지 않고 Diffy와 같은 도구와 함께 사용하면 트래픽 섀도잉을 통해 라이브 프로덕션 트래픽에 대한 서비스 동작을 측정할 수 있다.
이 기능을 사용하면 응용 프로그램 버전 간의 오류, 예외, 성능 및 결과 패리티를 테스트할 수 있으며, 배포 위험이 줄어들 수 있다.
트래픽 섀도잉은 일반적으로 카나리아 테스트와 같은 다른 접근 방식과 결합되며, 트래픽 섀도잉을 사용하여 새 기능을 테스트한 후 시간이 지남에 따라 점점 더 많은 사용자에게 기능을 점진적으로 릴리스하여 사용자 경험을 테스트할 수 있다.
또한, 애플리케이션이 안정성 및 성능 요구 사항을 충족할 때까지 전체 롤아웃이 발생하지 않는다.
4. 배포전략 테스트
➡️ Cloud Shell Enabled
1. 배포 매니페스트 생성 및 클러스터에 배포
Cloud Shell에서 다음 명령을 입력하여 영역 및 클러스터 이름에 대한 환경 변수를 설정
export my_zone=us-central1-a
export my_cluster=standard-cluster-1Cloud Shell에서 kubectl 탭 완성을 구성
source <(kubectl completion bash)Cloud Shell에서 다음 명령을 사용하여 kubectl 명령줄 도구에 대한 클러스터 액세스를 구성
gcloud container clusters get-credentials $my_cluster --zone $my_zone리포지토리를 랩 Cloud Shell에 복제
git clone https://github.com/GoogleCloudPlatform/training-data-analyst작업 디렉토리에 대한 바로 가기로 소프트 링크 만들기
ln -s ~/training-data-analyst/courses/ak8s/v1.1 ~/ak8s
cd ~/ak8s/Deployments/cat nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
kubectl apply -f ./nginx-deployment.yaml
student_02_3b1582a73cf8@cloudshell:~/ak8s/Deployments (qwiklabs-gcp-03-495abc05d03f)$ kubectl apply -f ./nginx-deployment.yaml
deployment.apps/nginx-deployment created
student_02_3b1582a73cf8@cloudshell:~/ak8s/Deployments (qwiklabs-gcp-03-495abc05d03f)$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 11s2. Pod 수를 수동으로 확장 및 축소
➡️ Console 이용 ➡️ 워크로드 ➡️ Actions ➡️ Scale ➡️ Edit replicas
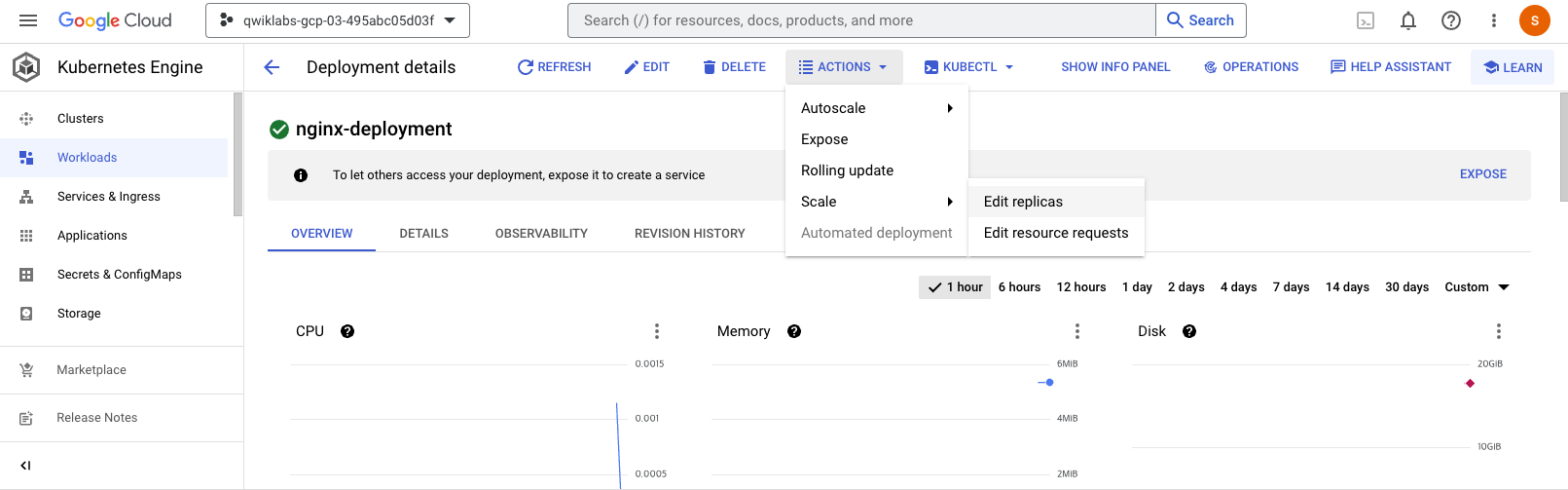
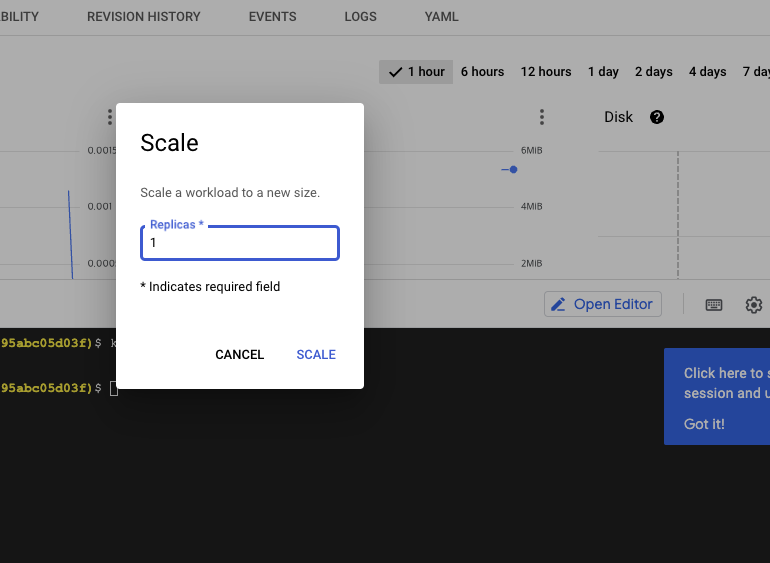
student_02_3b1582a73cf8@cloudshell:~/ak8s/Deployments (qwiklabs-gcp-03-495abc05d03f)$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 1/1 1 1 3m16s3. 배포 롤아웃 및 배포 롤백 트리거
배포 롤아웃 트리거
배포에서 nginx 버전을 업데이트
kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1 --record롤아웃 상태를 보려면 다음 명령을 실행
kubectl rollout status deployment.v1.apps/nginx-deployment배포의 롤아웃 기록 보기
kubectl rollout history deployment nginx-deployment
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1
2 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1 --record=true배포 롤백 트리거
개체 롤아웃을 롤백하려면 kubectl rollout undo명령을 사용하면 된다.
kubectl rollout undo deployments nginx-deployment업데이트된 배포 기록 보기
kubectl rollout history deployment nginx-deployment
최신 배포 개정의 세부 정보 보기
kubectl rollout history deployment/nginx-deployment --revision=3
student_02_3b1582a73cf8@cloudshell:~/ak8s/Deployments (qwiklabs-gcp-03-495abc05d03f)$ kubectl rollout history deployment/nginx-deployment --revision=3
deployment.apps/nginx-deployment with revision #3
Pod Template:
Labels: app=nginx
pod-template-hash=57c68fcd95
Containers:
nginx:
Image: nginx:1.7.9
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
4. 매니페스트에서 서비스 유형 정의
이 서비스는 레이블이 있는 컨테이너의 TCP 포트 60000에서 포트 80으로 인바운드 트래픽을 분산하도록 구성한다.
service-nginx.yaml
--------
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
type: LoadBalancer
selector:
app: nginx
ports:
- protocol: TCP
port: 60000
targetPort: 80
--------
kubectl apply -f ./service-nginx.yaml
kubectl get service nginx
student_02_3b1582a73cf8@cloudshell:~/ak8s/Deployments (qwiklabs-gcp-03-495abc05d03f)$ kubectl get service nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx LoadBalancer 10.15.251.227 35.238.107.130 60000:30988/TCP 63s
5. 카나리아 배포 수행
nginx-canary.yaml제공되는 매니페스트 파일은 기본 배포보다 최신 버전의 nginx를 실행하는 단일 포드를 배포한다.
nginx-canary.yaml
-------
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-canary
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
track: canary
Version: 1.9.1
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
-------
이전 작업에서 배포한 nginx 서비스의 매니페스트는 레이블 선택기를 사용하여 레이블이 있는 Pod를 대상으로 지정한다.(app: nginx)
일반 배포와 이 새로운 카나리아 배포에는 모두 app: nginx 레이블이 있다. 인바운드 연결은 서비스에 의해 일반 배포 포드와 카나리아 배포 포드 모두에 배포되며, Canary 배포에는 일반 배포보다 복제본(Pod)이 적으므로 일반 배포보다 적은 수의 사용자가 사용할 수 있다는 장점이 있다.
$ kubectl apply -f nginx-canary.yaml
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-canary 1/1 1 1 7s
nginx-deployment 3/3 3 3 19mCloud Shell로 다시 전환하고 기본 배포를 복제본 0개로 축소
kubectl scale --replicas=0 deployment nginx-deployment
student_02_3b1582a73cf8@cloudshell:~/ak8s/Deployments (qwiklabs-gcp-03-495abc05d03f)$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-canary 1/1 1 1 106s
nginx-deployment 0/0 0 0 20m외부 LoadBalancer 서비스 IP에 연결된 브라우저 탭으로 다시 전환하고 페이지를 새로 고침 해도, Welcome to nginx서비스가 자동으로 카나리아 배포에 트래픽을 분산하고 있음을 보여주는 표준 페이지가 계속 표시되어야 한다.
5. Job & CronJob
5-1. Job
Job은 배포와 같은 Kubernetes 객체이며, Job은 하나 이상의 포드를 생성하고 특정 작업을 안정적으로 실행한다.
가장 간단한 형태로 Job은 하나의 Pod를 생성하고 해당 Pod 내에서 작업 완료를 추적하며, 작업이 완료되면 포드를 종료하고 작업이 성공적으로 완료되었음을 보고한다.
단일 독립형 포드를 사용하여 일부 비디오 파일을 트랜스코딩하는 시나리오를 고려한다면 포드가 실행 중인 노드가 갑자기 종료되면 어떻게 될까 수행 중이던 작업은 손실될 수 밖에 없다.
어떤 이유로든 포드가 종료되면 다시 시작되지 않는다. 작업은 이러한 유형의 실패를 처리하는 메커니즘을 제공한다.
다른 쿠버네티스 컨트롤러와 달리 작업은 원하는 상태가 아니라 완료될 때까지 작업을 관리하며, 작업의 바람직한 상태는 완료입니다.
시나리오 하나를 예로 들어보자 사용자가 변환 또는 코드 변환을 위해 비디오 파일을 웹 서버에 업로드한다는 시나리오이다.
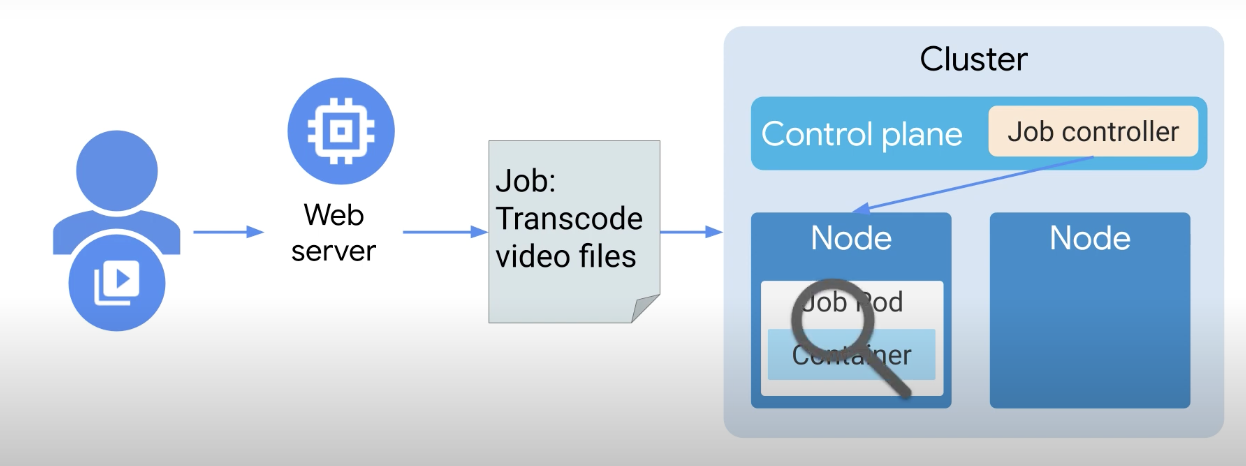
웹 서버는 트랜스코딩 작업을 위한 작업 개체 매니페스트를 생성했으며 클러스터에 작업이 생성되었다. 여기서 Job controller는 노드의 작업에 대한 Pod 스케치이다.
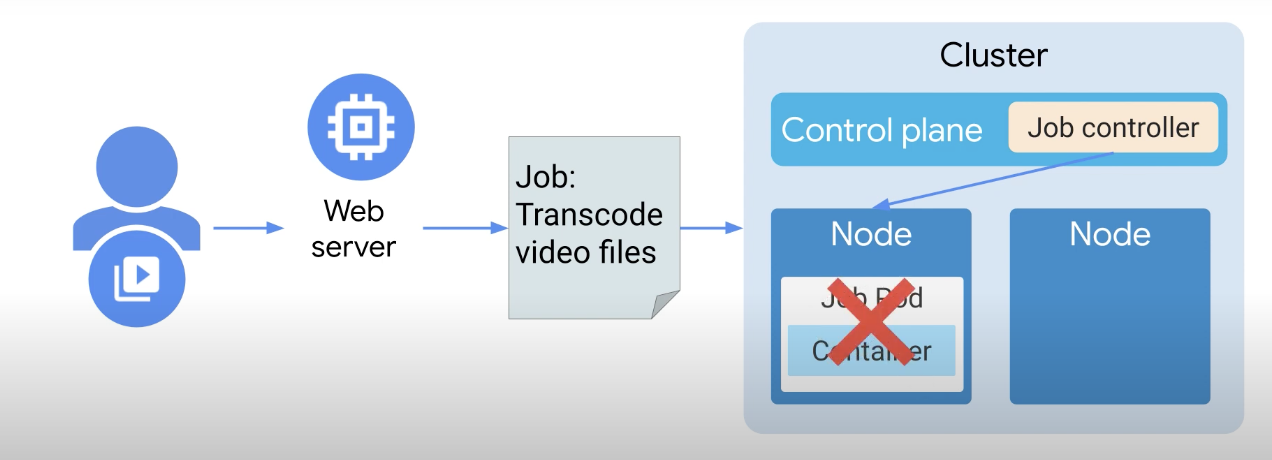
작업 컨트롤러는 포드를 모니터링하는데, 노드 장애가 발생하고 Pod가 손실되면 작업 컨트롤러는 작업이 완료되지 않았음을 인식하고 작업 컨트롤러가 일정을 변경한다.
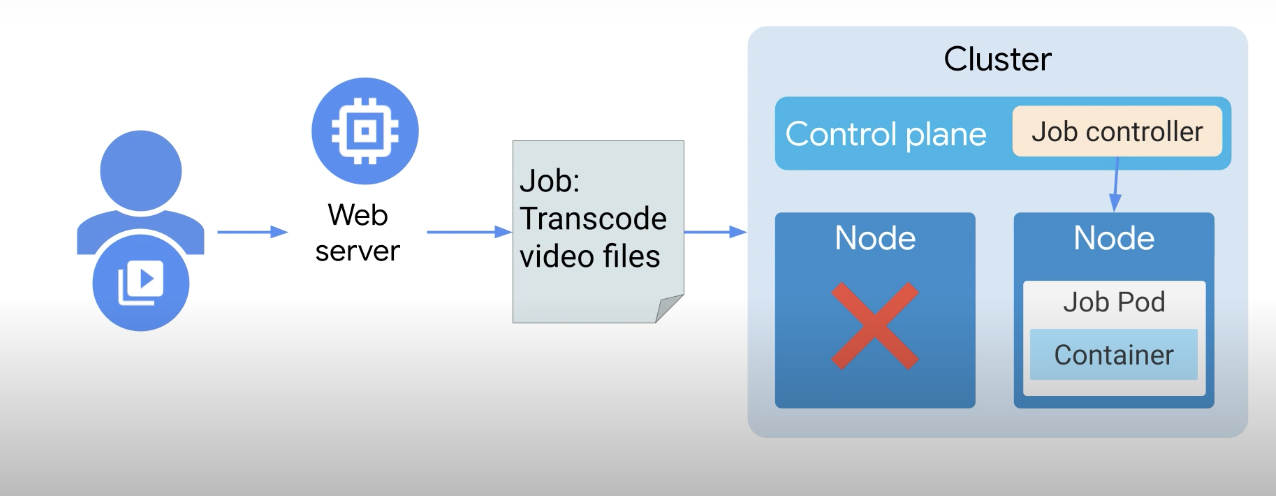
다른 노드에서 실행할 작업 Pod로 변경하고 작업 컨트롤러는 작업이 완료될 때까지 포드를 계속 모니터링하며, 작업이 완료되면 작업 컨트롤러가 기존의 Node 안의 Pod를 삭제한다.
완료된 Job 및 이와 관련된 Pod Job을 정의하는 두 가지 주요 방법이 있다 비 병렬 및 병렬 이며 비병렬 작업은 한 번에 하나의 포드만 생성한다.

물론 성공적으로 종료되지 않으면 해당 포드가 다시 생성되며, 이러한 작업은 포드가 성공적으로 종료되거나 완료 횟수가 정의된 경우 필요한 완료 횟수에 도달하면 완료된다.
병렬 작업은 병렬 처리 값이 정의된 작업으로, 여러 포드가 해당 작업에서 동시에 작동하도록 예약된다. 만약, 완료 횟수도 정의되어 있는 경우 두 번 이상 완료해야 하는 작업에 사용되고 Kubernetes는 성공적으로 종료된 Pod의 수가 완료 횟수에 도달하면 병렬 작업이 완료된 것으로 간주한다.
작업 대기열을 처리하기 위한 두 번째 유형의 병렬 작업도 정의할 수 있는데 이에 대해서는 나중에 살펴보겠다.
5-2. 비 병렬 작업
간단한 비병렬 작업을 생성하는 방법부터 살펴보자.
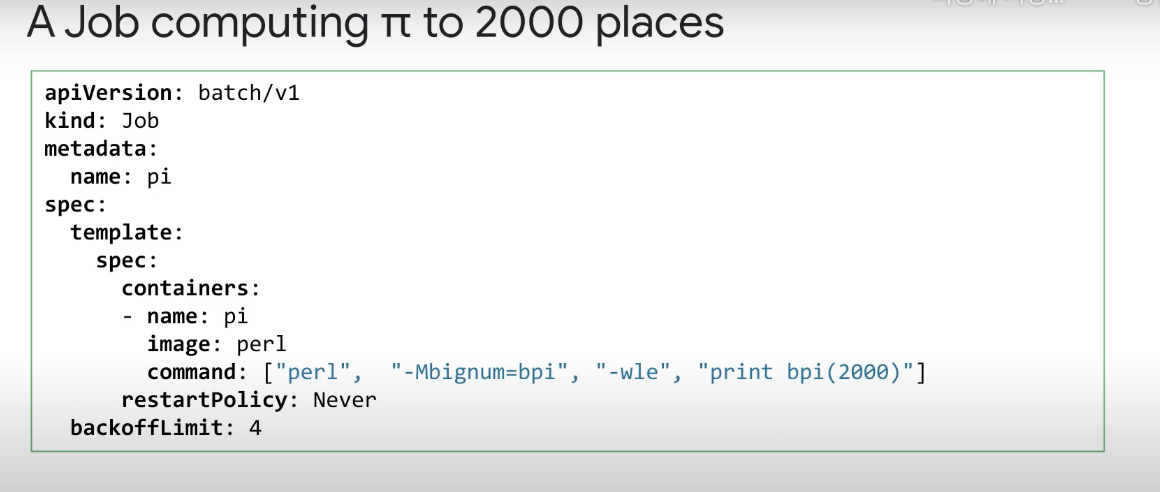
다음은 Pi를 소수점 이하 2,000자리까지 계산하는 작업의 예시 인데, 작업 개체는 해당 kind를 통해 지정된다. Job spec 내에는 Pod template이 있으며, Pod 사양이 있는 곳이다.
여기서 restartPolicy는 never로 설정됐는데, 컨테이너와 Pod가 어떤 이유로든 실패하면 전체 Pod가 실패하고 작업 컨트롤러는 새 포드를 시작하여 이 포드 실패에 응답하는 옵션이다.
작업에 사용할 수 있는 다른 restartPolicy 옵션은 restartPolicy를 OnFailure로 설정하는 것인데, 이 경우 Pod는 노드에 남아 있지만 컨테이너는 다시 시작된다.
또한, 애플리케이션 실패가 가능하거나 예상되는 경우 backoffLimit 필드를 사용할 수 있다. BackoffLimit은 작업이 완전히 실패한 것으로 간주되기 전에 재시도하는 옵션이며 기본값은 6이다. 이를 통해 재시작 루프에 갇히게 될 작업을 중단할 수 있다는 장점이 있다. 루프 내에서는 실패한 Pod가 다시 시작된다.
포드가 네번 계속 실패하면, Job은 주어진 backoffLimit 초과로 인해 실패한다. backoffLimit에 도달하기 전에 포드가 성공하면 카운터가 재설정된다.
5-3. 병렬 작업
병렬 작업 유형은 동일한 작업에서 동시에 작동하는 여러 포드를 생성하며, 병렬 작업 유형은 spec.parallelism 값을 설정하여 지정된다.
1보다 큰 작업, 앞서 언급했듯이 두 가지 유형의 병렬 작업이 있다. 하나는 고정된 작업 완료 횟수를 가지며 다른 하나는 작업 대기열을 처리한다.
고정 완료 횟수와 함께 병렬 작업에 대해 동시에 여러 포드를 시작하려는 경우 병렬 처리와 함께 완료를 추가할 수 있다. 작업 컨트롤러는 최대 수의 병렬 처리 값으로 지정된 동시에 포드는 완료 횟수에 도달할 때까지 포드를 계속 다시 시작한다.

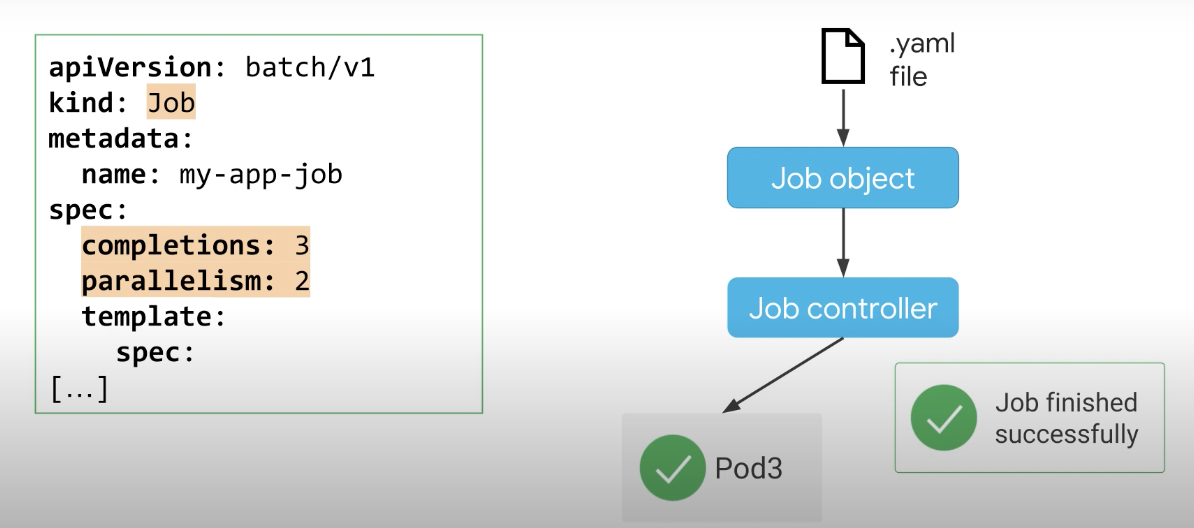
이 예에서 컨트롤러는 최대 2개의 포드를 병렬로 시작한다. 3개의 Pod가 성공적으로 종료될 때까지 작업을 처리하며 컨트롤러는 다음 포드를 시작하기 전에 실행 중인 포드 중 하나가 성공적으로 완료될 때까지 기다린다. 작업 컨트롤러는 성공적인 완료를 계속해서 추적한다.
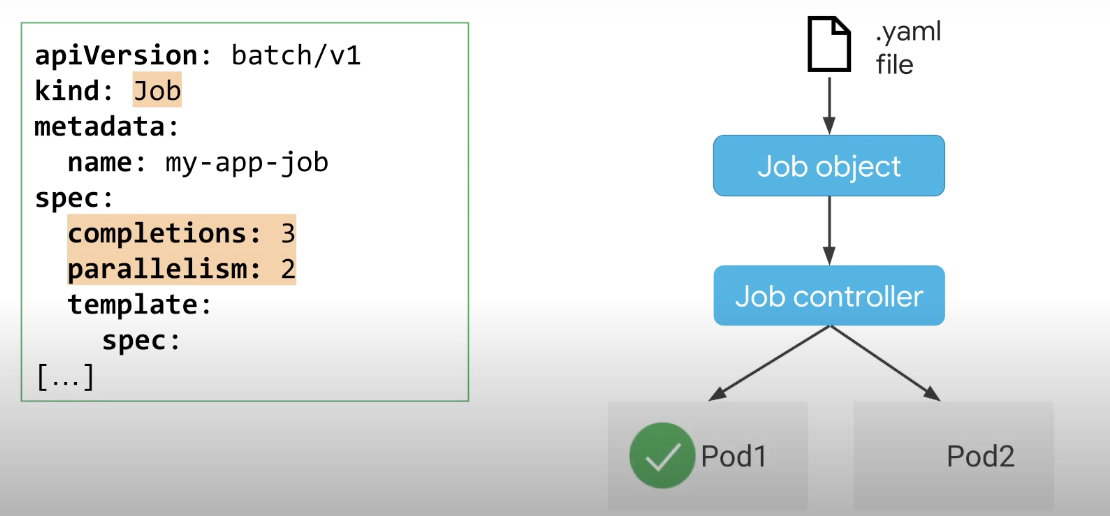
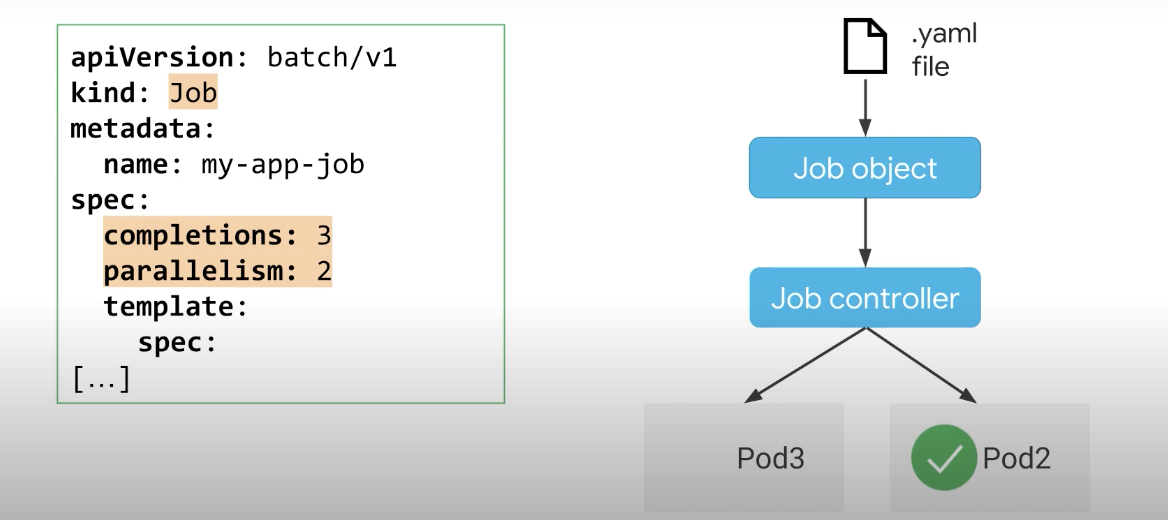
지정된 완료 횟수에 도달하면 작업이 완료된 것으로 간주되며, 남은 완료 수가 병렬 처리 값보다 적으면 컨트롤러는 남은 포드가 충분하므로 새 포드를 예약하지 않는다.
작업자 대기열이 있는 병렬 작업은 무엇일까? 작업자 대기열 병렬 작업에서 각 포드는 대기열의 여러 항목에 대해 작업하고 더 이상 항목이 없으면 종료된다. 이것들은 작업자이기 때문에 Pod 자체는 작업 대기열이 비어 있고 작업 컨트롤러가 작업 대기열에 대해 알지 못하는 시기를 감지한다.
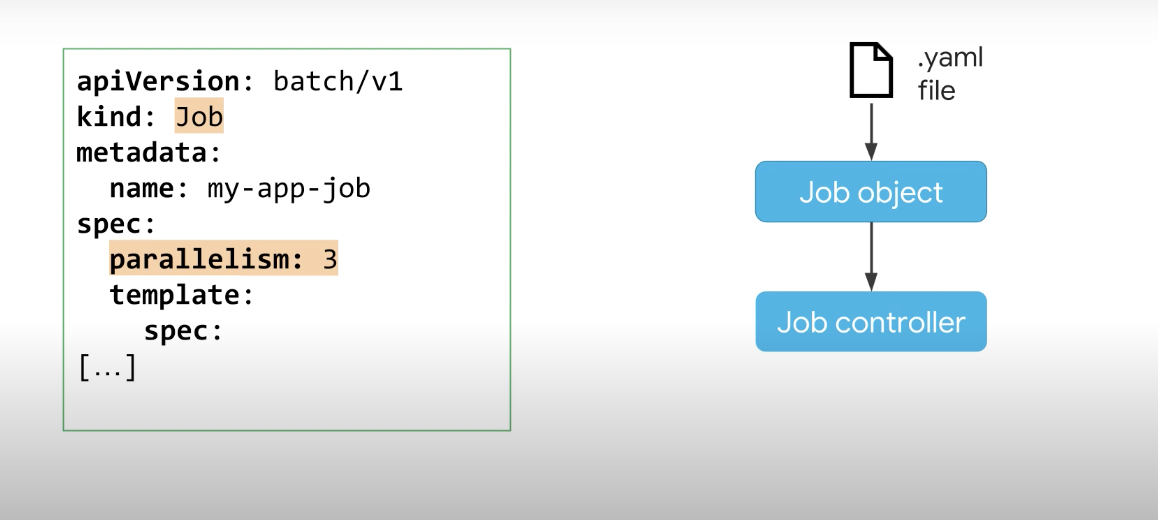
컨트롤러는 작업자가 종료하여 작업을 마쳤을 때 신호를 보내는 것에 의존하며, 병렬 처리 값을 지정하고 spec.completions를 설정하지 않은 상태로 두어 작업자 대기열을 처리하는 병렬 작업을 생성한다.
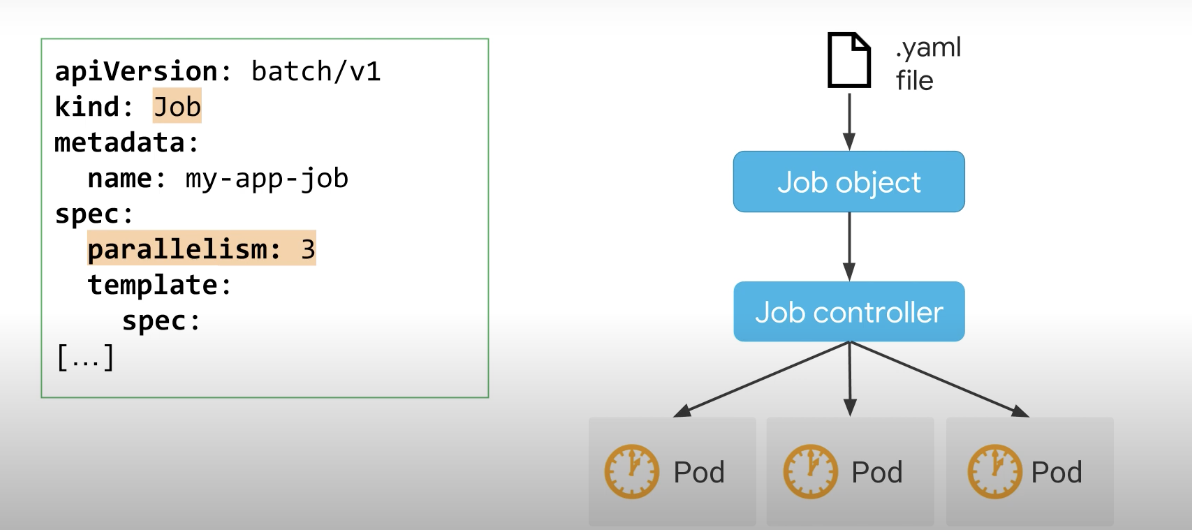
병렬 처리가 3으로 설정된 경우 작업 컨트롤러는 3개의 포드를 동시에 시작한다.
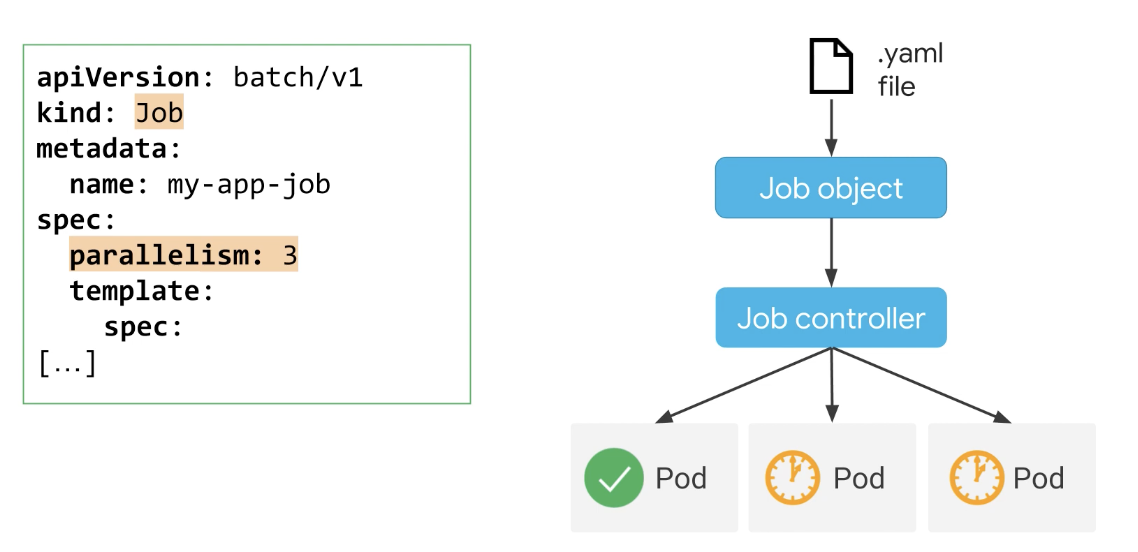
작업은 이 세 개의 포드 중 하나라도 완료되는 즉시 모든 작업이 완료된 것으로 간주한다.

작업을 성공적으로 완료하면 어느 시점에서 포드 중 하나가 성공적으로 종료되고, 나머지 포드에서 실행 중인 애플리케이션은 이 완료 상태를 감지하고 완료되어 나머지 포드가 스스로 종료된다. 결과적으로 작업을 성공적으로 종료하는 하나의 포드는 성공적으로 완료된 것으로 간주된다.
Pod 실패를 제한하는 한 가지 방법은 앞에서 설명한 backoffLimit를 사용하는 것인데 또 다른 옵션은 activeDeadlineSeconds 설정을 사용하는 것이다. 이것은 작업이 완료될 활성 기한을 설정할 수 있다. 기한 카운트는 작업이 시작될 때 시작되며, 기한에 도달하면 '기한 초과' 이유로 작업과 모든 포드가 종료된다. ActiveDeadlineSeconds는 backoffLimit보다 우선 이다.
5-4. CronJob
Cron 형식은 날짜를 지정하는 데 사용되는 일반적으로 채택되는 구문이며, 작업을 실행하고 반복해야 하는 시간이다. 공백으로 구분된 필드와 실행할 명령으로 구성된 일반 문자열로 정의할 수 있다.

별표는 가능한 값의 전체 범위를 나타낸다. 예: 매분,매 시간 등 모든 필드에는 1,3,7과 같이 쉼표로 구분된 값 목록 또는 두 개의 정수가 하이픈으로 구분된 값 범위가 포함될 수 있다.
예를 들어, 1-5. 별표 또는 값 범위 뒤에 슬래시 문자를 사용하여 값 사이에 특정 간격으로 값이 계속해서 반복되도록 지정할 수 있다.

CronJob은 정의된 일정에 따라 반복 가능한 방식으로 작업을 생성하는 Kubernetes 개체이며, CronJob은 프로세스 예약을 위한 표준 Unix/Linux 메커니즘인 cron의 이름을 따서 명명되었기 때문에 이렇게 불린다.
일정 필드는 CronJob을 지정하기 위해 Unix/Linux 표준 형식의 시간을 허용하고 예시에서는 CronJob 사양에 따라 1분마다 실행되도록 cron 일정이 설정되어 있는 예시이다.
JobTemplate은 Job에 대한 이전 단원에서 설명한 것처럼 Job 사양을 정의한 것이다.
이 매니페스트에 정의된 작업이 1분마다 시작되도록 예약된 경우 예약된 시간까지 작업이 시작되지 않으면 어떻게 될까? 기본적으로 CronJob은 작업이 마지막으로 예약된 이후 실행에 실패한 횟수를 확인한다.
실패 횟수가 100을 초과하면 오류가 기록되고 작업이 예약되지 않으며, 이렇게 하면 시간이 지남에 따라 실패한 시도가 끝없이 누적되는 CronJob의 오류를 방지할 수 있다는 장점이 있다.

이 동작은 startingDeadlineSeconds 값을 사용하여 제어할 수 있다. 작업이 마지막으로 성공적으로 실행된 이후 실패한 실행 시도 횟수를 확인하는 대신 이러한 속성을 정의할 수 있다.
실패한 시도 횟수를 합산할 시간 창을 정의하고 이는 컨트롤러가 검사하는 창을 변경한다. 이제 작업이 마지막으로 예약된 시간을 되돌아보는 대신 startingDeadlineSeconds가 설정되면 창은 지금 이전의 startingDeadlineSeconds에서 시작된다.
작업이 예약되는 빈도와 정의된 작업을 완료하는 데 걸리는 시간에 따라 CronJob이 둘 이상의 작업을 동시에 실행하게 할 수 있다.
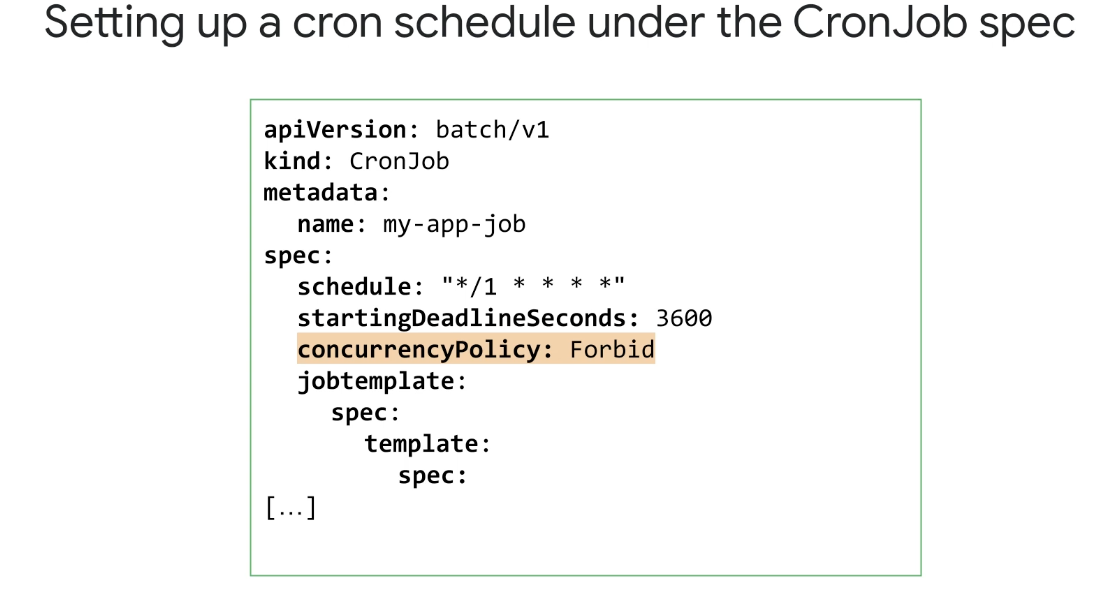
concurrencyPolicy 값을 사용하여 Allow, Forbid 또는 Replace 값으로 동시 실행이 허용되는지 여부를 정의할 수 있다. Forbid의 경우 기존 Job이 완료되지 않으면 CronJob이 종료되지 않는다.
replace를 사용하면 기존 작업이 새 작업으로 대체된다. 이 정책은 동일한 CronJob을 사용하여 생성된 작업에만 적용됩니다. 다른 CronJob 및 작업은 영향을 받거나 고려되지 않는다.

suspend 속성을 True로 설정하여 CronJob의 개별 작업 실행을 중지할 수 있다. 이것이 설정되면 모든 새 작업 실행이 일시 중지되고 일시 중단된 실행은 여전히 축적된 작업으로 계산된다.
히스토리에 보존할 성공 및 실패한 작업 수에 대한 제한은 'successfulJobsHistoryLimit' 및 'failedJobsHistoryLimit' 필드로 구성됩니다. CronJob은 작업 자체와 동일한 방식으로 작동한다.
6. CronJob 실습
➡️ Google Cloud Shell 활성화
6-1. 작업 매니페스트 정의 및 배포
➡️ 이전에 클러스터에 접근했던 방법과 동일
export my_zone=us-central1-a
export my_cluster=standard-cluster-1
source <(kubectl completion bash)
gcloud container clusters get-credentials $my_cluster --zone $my_zone
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
ln -s ~/training-data-analyst/courses/ak8s/v1.1 ~/ak8s
cd ~/ak8s/Jobs_CronJobs작업 생성 및 실행
이 작업은 Pi 값을 2,000자리까지 계산한 다음 결과를 인쇄
$ cat example-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
# Unique key of the Job instance
name: example-job
spec:
template:
metadata:
name: example-job
spec:
containers:
- name: pi
image: perl:5.34
command: ["perl"]
args: ["-Mbignum=bpi", "-wle", "print bpi(2000)"]
# Do not restart containers after they exit
restartPolicy: Never
$ kubectl apply -f example-job.yaml
student_01_6525729cc917@cloudshell:~/ak8s/Jobs_CronJobs (qwiklabs-gcp-03-8bb0c960aa22)$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
example-job 0/1 36s 37s
student_01_6525729cc917@cloudshell:~/ak8s/Jobs_CronJobs (qwiklabs-gcp-03-8bb0c960aa22)$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
example-job 1/1 36s 40s
$ kubectl describe job example-job
Name: example-job
Namespace: default
Selector: controller-uid=7e48d234-c60b-40e7-8405-18cd121b2158
Labels: controller-uid=7e48d234-c60b-40e7-8405-18cd121b2158
job-name=example-job
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Wed, 19 Jul 2023 09:12:13 +0000
Completed At: Wed, 19 Jul 2023 09:12:49 +0000
Duration: 36s
Pods Statuses: 0 Active (0 Ready) / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=7e48d234-c60b-40e7-8405-18cd121b2158
job-name=example-job
Containers:
pi:
Image: perl:5.34
Port: <none>
Host Port: <none>
Command:
perl
Args:
-Mbignum=bpi
-wle
print bpi(2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 68s job-controller Created pod: example-job-mjw78
Normal Completed 33s job-controller Job completed
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-job-mjw78 0/1 Completed 0 2m2s작업이 완료되면 작업이 포드 생성을 중지하지만, 작업 API 개체는 완료될 때 제거되지 않으므로 해당 상태를 볼 수 있다. 작업에 의해 생성된 포드는 삭제되지 않지만 종료되며Pod 보관을 통해 로그를 보고 상호 작용할 수 있다는 장점이 있다.
$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
example-job 1/1 36s 3m28s작업을 실행한 포드에서 로그 파일을 검색하려면 다음 명령어를 실행하며. [POD-NAME]을 마지막 작업에서 기록한 노드 이름으로 바꿔야 함
$ kubectl logs example-job-mjw78
3.1415926535897932384626433832795028841971693993751058209749445... 많음
# Job delete
$ kubectl delete job example-job
job.batch "example-job" deleted
$ kubectl get pods
No resources found in default namespace.6-2. CronJob 매니페스트 정의 및 배포
이 CronJob은 시간, 날짜 및 "Hello, World!"를 인쇄하는 새 컨테이너를 매분 배포한다.
$ cat example-cronjob.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo "Hello, World!"
restartPolicy: OnFailure
cron 형식
참고:schedule CronJob은 Unix 표준 형식의 시간을 허용하는 필수 필드를 사용합니다 crontab.
모든 CronJob 시간은 UTC 기준입니다.
첫 번째 값은 분(0에서 59 사이)을 나타냅니다.
두 번째 값은 시간(0에서 23 사이)을 나타냅니다.
세 번째 값은 일을 나타냅니다(1에서 31 사이).
네 번째 값은 월(1에서 12 사이)을 나타냅니다.
다섯 번째 값은 요일(0에서 6 사이)을 나타냅니다.
이 schedule필드는 * 및 ?도 허용합니다. 와일드카드 값으로. /와 범위를 결합하면 작업이 일정한 간격으로 반복되어야 함을 지정합니다. 예에서 는 */1 * * * *작업이 매월 매일 매분 반복되어야 함을 나타냅니다.$ kubectl apply -f example-cronjob.yaml
cronjob.batch/hello created
$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 1 0s 65s
$ kubectl describe job hello
Name: hello-28162641
Namespace: default
Selector: controller-uid=5daa9cd5-f12b-44c0-84bd-3ef355a704a9
Labels: controller-uid=5daa9cd5-f12b-44c0-84bd-3ef355a704a9
job-name=hello-28162641
Annotations: batch.kubernetes.io/job-tracking:
Controlled By: CronJob/hello
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Wed, 19 Jul 2023 09:21:00 +0000
Completed At: Wed, 19 Jul 2023 09:21:05 +0000
Duration: 5s
Pods Statuses: 0 Active (0 Ready) / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=5daa9cd5-f12b-44c0-84bd-3ef355a704a9
job-name=hello-28162641
Containers:
hello:
Image: busybox
Port: <none>
Host Port: <none>
Args:
/bin/sh
-c
date; echo "Hello, World!"
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 102s job-controller Created pod: hello-28162641-zb7s9
Normal Completed 97s job-controller Job completed
Name: hello-28162642
Namespace: default
Selector: controller-uid=17368eab-2678-4340-b025-c2b63b3276f0
Labels: controller-uid=17368eab-2678-4340-b025-c2b63b3276f0
job-name=hello-28162642
Annotations: batch.kubernetes.io/job-tracking:
Controlled By: CronJob/hello
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Wed, 19 Jul 2023 09:22:00 +0000
Completed At: Wed, 19 Jul 2023 09:22:04 +0000
Duration: 4s
Pods Statuses: 0 Active (0 Ready) / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=17368eab-2678-4340-b025-c2b63b3276f0
job-name=hello-28162642
Containers:
hello:
Image: busybox
Port: <none>
Host Port: <none>
Args:
/bin/sh
-c
date; echo "Hello, World!"
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 42s job-controller Created pod: hello-28162642-trs6p
Normal Completed 38s job-controller Job completed
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-28162641-zb7s9 0/1 Completed 0 2m23s
hello-28162642-trs6p 0/1 Completed 0 83s
hello-28162643-c4psp 0/1 Completed 0 23s
$ kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
hello-28162641-zb7s9 0/1 Completed 0 2m54s
hello-28162642-trs6p 0/1 Completed 0 114s
hello-28162643-c4psp 0/1 Completed 0 54s
hello-28162644-dqzpf 0/1 Pending 0 0s
hello-28162644-dqzpf 0/1 Pending 0 0s
hello-28162644-dqzpf 0/1 ContainerCreating 0 0s
hello-28162644-dqzpf 0/1 Completed 0 2s
hello-28162644-dqzpf 0/1 Completed 0 4s
hello-28162644-dqzpf 0/1 Completed 0 5s
hello-28162641-zb7s9 0/1 Terminating 0 3m5s
hello-28162641-zb7s9 0/1 Terminating 0 3m5s
$ kubectl logs hello-28162642-trs6p
Wed Jul 19 09:22:01 UTC 2023
Hello, World!
$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
hello-28162643 1/1 4s 2m38s
hello-28162644 1/1 5s 98s
hello-28162645 1/1 5s 38s기본적으로 Kubernetes는 마지막 3개의 성공한 작업과 마지막으로 실패한 작업만 유지되도록 작업 기록 제한을 설정하므로 이 목록에는 4개의 작업 중 가장 최근 3개의 작업만 포함된다.
작업 정리 및 삭제
$ kubectl delete cronjob hello
$ kubectl get jobs
-> no Resources7. Cluster 스케일링
7-1 Scale Down
실행 중인 기존 노드에 배포하는 데 몇 초 밖에 걸리지 않을 수 있지만 오토스케일러가 추가한 새 노드를 사용하려면 몇 분이 걸릴 수 있다.
노드를 추가하는 것은 더 많은 비용을 지출한다는 것을 의미하고 클러스터 조정은 드물게 발생해야 하는 대략적인 작업으로 생각하고 배포를 통한 포드 조정은 세분화된 작업으로 생각해야 한다.
이것은 자주 일어나야 하는 일이며, 두 종류의 확장을 함께 사용하여 지출의 균형을 맞출 수 있다. GKE 클러스터 오토스케일링 프로세스는 노드를 축소할 수도 있다. 자동 확장 처리가 축소를 관리하는 방법을 살펴보자.
-
Cluster Autoscaler는 보류 중인 확장 이벤트가 없도록 합니다. 축소 프로세스 중에 확장 이벤트가 발생하면 축소가 실행되지 않는다. -
노드를 안전하게 삭제할 수 있는지 확인해야하며, 노드에 다음 조건 중 하나를 충족하는 포드가 포함되어 있으면 노드를 삭제할 수 없다.
- ReplicaSet, 작업 상태 저장 세트 등. 로컬 스토리지가 있는 포드, 다른 노드에 서 실행되지 않도록 하는 제약 조건 규칙에 의해 제한되는 포드 등
노드 삭제를 방지하기 위해 명시적으로 설정할 수 있는 기본값이 아닌 설정이 많이 있다. "False"로 설정된 safe-to-evict 주석이 있는 포드

포드를 제거할 수 없음을 자동 확장 처리에 알리는 포드 수준이며, 결과적으로 클러스터가 축소될 때 실행 중인 노드는 삭제 대상으로 선택되지 않습니다.
또한, 포드 중단 예산이 제한된 포드는 노드 삭제를 방지할 수도 있다. 포드 중단 예산을 정의하여 해당 컨트롤러 레플리카 수를 지정할 수도 있다.
예를 들어 3개의 복제본이 있고 포드 중단 예산이 2로 설정된 배포에서 한 번에 하나의 복제본만 제거하거나 중단할 수 있다.
노드 수준에서 노드 축소 비활성화 주석이 "True"로 설정되면 해당 노드는 축소 작업에서 항상 제외된다. 스케일 업이 필요하지 않은 경우, 클러스터 오토스케일러는 불필요한 노드를 확인하며 이는 10초마다 수행된다.
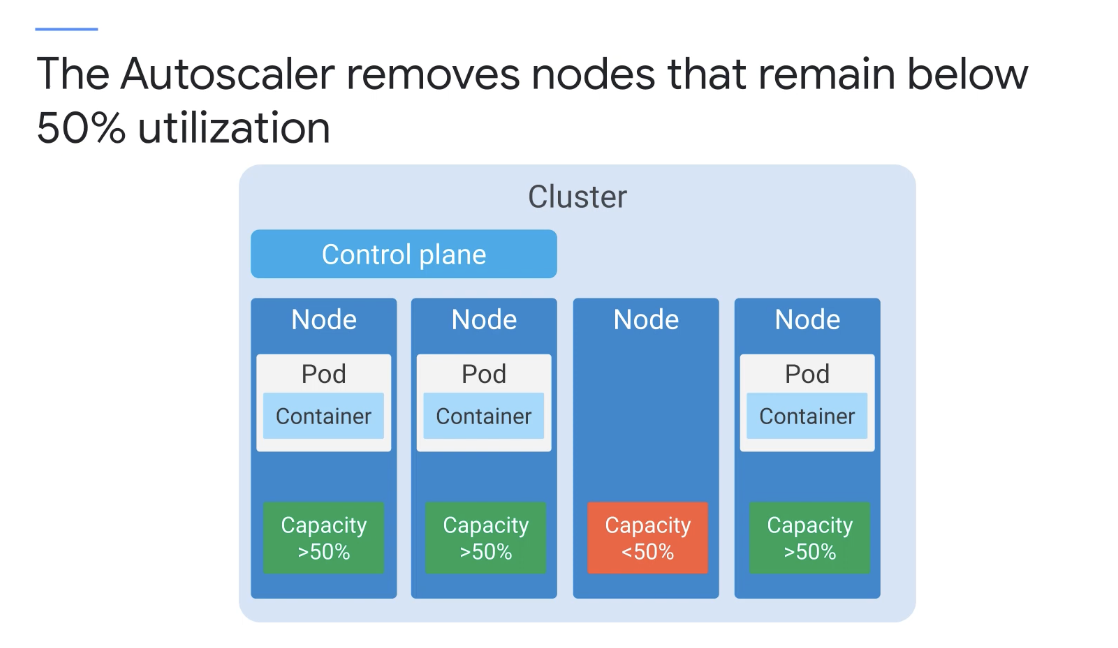
아래의 조건이 모두 충족되면 노드 제거가 고려될 수 있다.
-
CPU와 메모리의 합계가 노드 할당 가능 용량의 50% 미만인 경우
-
노드에서 실행 중인 모든 포드는 다른 노드로 제거할 수 있으며 클러스터가 그렇지 않은 경우 축소 비활성화된 주석이 있는 경우 클러스터 자동 크기 조정기는 불필요한 노드를 10분 이상 모니터링하고 필요하지 않은 경우 노드를 종료한다.
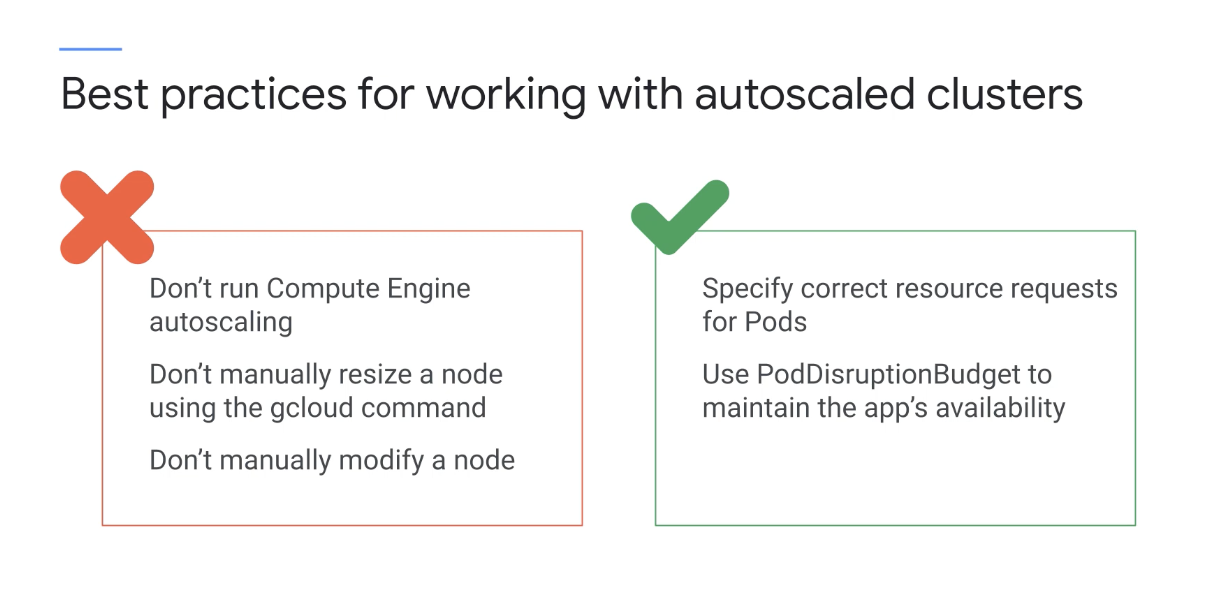
몇 가지 모범 사례
자동 확장된 클러스터로 작업하기 위한 것이고, 먼저 이러한 노드에서 관리형 인스턴스 그룹에 대해 Compute Engine 자동 확장을 실행하면 안된다.
GKE 자동 확장 처리는 Compute Engine 자동 확장과 별개이고 노드 풀 크기를 수동으로 조정하지 말자.
Cluster Autoscaler가 사용 설정된 경우 gcloud 명령어로 인해 클러스터가 불안정해지고 클러스터의 노드 풀 크기가 잘못될 수 있다. 자동 확장된 노드를 수동으로 수정하지 말자
노드 풀의 모든 노드는 용량, 레이블 및 시스템 부분이 동일해야 하며. 또한 kubectl을 사용하여 직접 노드 중 하나의 레이블을 변경하면 변경 사항이 적용되지 않는다.
포드에 대한 올바른 리소스를 지정하면 Pod가 Cluster Autoscaler와 효과적으로 작동할 수 있다.
Pod의 리소스 요구 사항을 모르는 경우 테스트 부하에서 측정하면 된다.
마지막으로 포드 중단 예산을 사용하자. 컨트롤러에 속한 포드는 안전하게 종료되고 재배치될 수 있으며 애플리케이션이 이러한 중단을 허용할 수 없는 경우, 포드 중단 예산을 사용하여 애플리케이션의 가용성을 유지하자
7-2. Node Pool

-
클러스터에는 하나 이상의 노드 풀이 포함하며 노드 풀 크기는 최소 및 최대 크기를 지정하여 설정할 수 있다.
-
클러스터의 일부 노드 풀을 0으로 축소할 수 있으나, 전체 클러스터 크기는 절대 0으로 확장할 수 없다.
-
시스템 Pod를 실행하려면 클러스터 내에 하나 이상의 노드가 필요하다.
클러스터 자동 확장 처리는 최대 15000개의 노드에서 각각 110개의 Pod를 실행하는 테스트를 거쳤으나, 그러나 총 Compute Engine 인스턴스 수에 대한 표준 Google Cloud 할당량 한도가 적용된다는 점!
기본 할당량을 늘리지 않으면 결국 중단이 발생하고 할당량 한도를 올릴 때까지 새 VM이 시작되지 않는다.
몇가지 gcloud auto-scaling 명령어
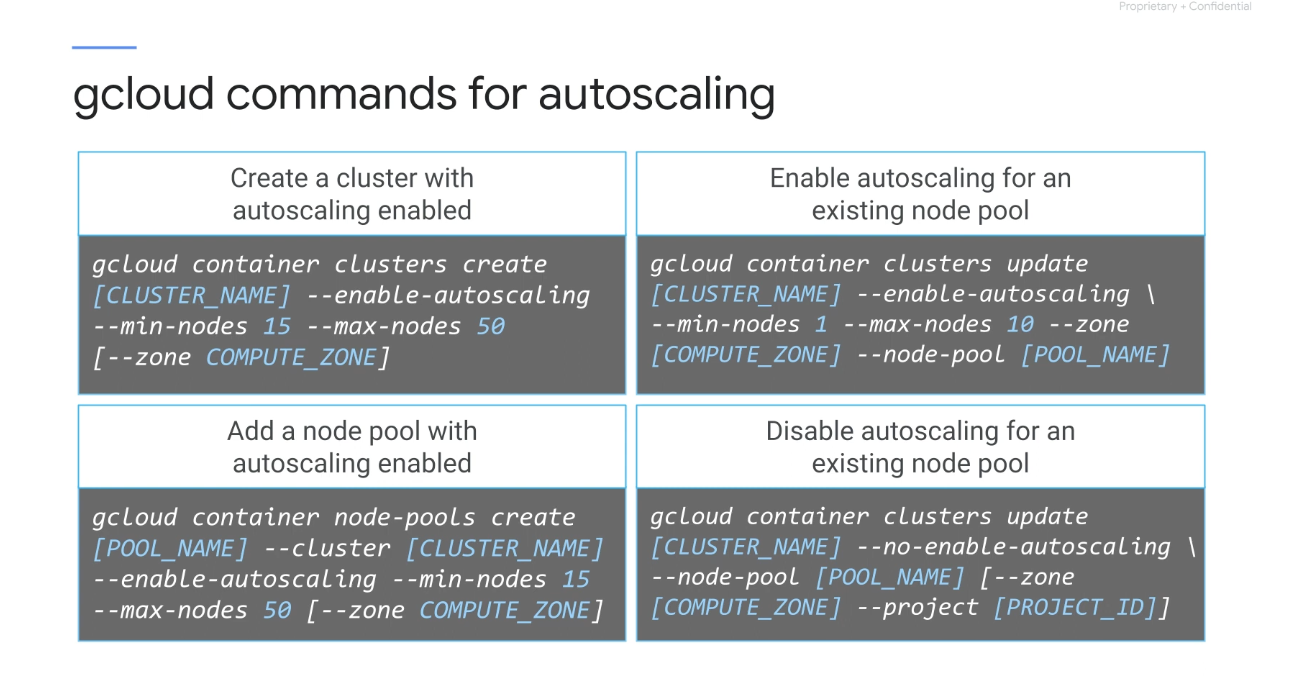
-
기본 풀에 대해 자동 크기 조정이 활성화된 클러스터를 시작할 수 있다.
-
자동 확장이 활성화된 새 풀을 추가하거나 기존 노드 풀에 대해 자동 확장을 활성화할 수 있다.
-
기존 노드 풀에 대해 자동 확장을 비활성화할 수도 있다.
-
자동 크기 조정이 비활성화된 경우 노드 풀 크기는 클러스터의 현재 노드 풀 크기로 고정된다.
7-3 Pod 배치
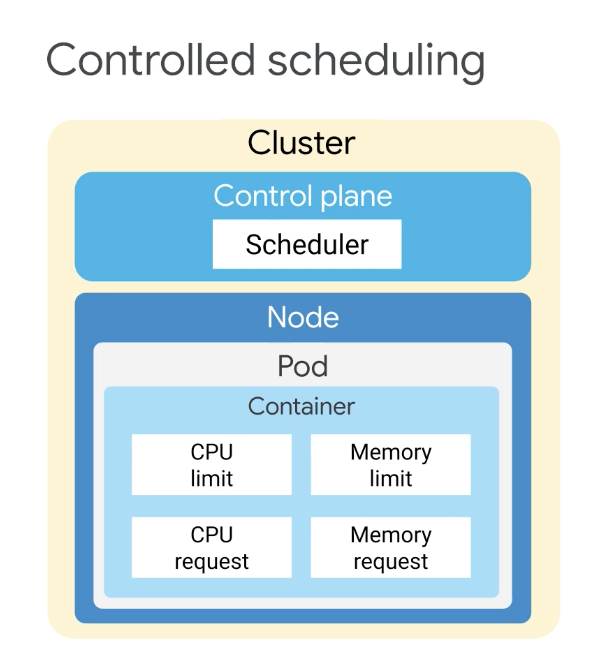
Kubernetes에서 Pod 배치는 노드의 레이블 및 taint와 배포 사양의 노드 선호도규칙 및 허용 오차로 제어할 수 있다.
포드를 지정할 때 각 컨테이너에 필요한 CPU 및 RAM 양을 선택적으로 지정할 수 있다. 컨테이너에 리소스 요청이 지정된 경우 스케줄러는 포드를 배치할 노드에 대해 더 나은 결정을 내린다.
컨테이너에 제한이 지정되어 있으면 노드의 리소스 경합을 지정된 방식으로 처리할 수 있으며, 포드는 각 컨테이너의 리소스 요청과 한도를 합산하고 설정한다.
스케줄러는 포드 내의 컨테이너에서 설정한 리소스 요청 및 제한을 기반으로 노드에 포드를 할당한다. 또한, 스케줄러는 Pod의 요청된 제한이 노드 용량 내에 있는지 확인하고 포드를 노드 전체에 자동으로 분산시킬 수 있다. 이러한 노드는 서로 다른 컴퓨팅 영역에 걸쳐 설정할 수 있다.
노드가 시작되면 kubelet은 영역 정보와 함께 레이블을 노드에 자동으로 추가한다. Kubernetes는 단일 영역 클러스터의 노드 간에 복제 컨트롤러 또는 서비스의 Pod를 자동으로 분산한다.
실패의 영향을 줄이기 위해, 다중 구역 클러스터를 사용하면 구역 장애의 영향을 줄이기 위해 이 확산 동작이 구역 전체로 확장되는데. 특정 유형의 특정 노드의 애플리케이션이라던지!
예를 들어 SSD가 있는 노드에서 웹 서버를 실행하려는 경우 Pod가 특정 노드에서 실행되려면 해당 노드는 Pod의 nodeSelector 필드 아래에 있는 모든 레이블과 일치해야 한다.

nodeSelector는 하나 이상의 레이블을 지정하는 포드 사양 필드이고, 노드 레이블은 자동으로 할당될 수 있다.
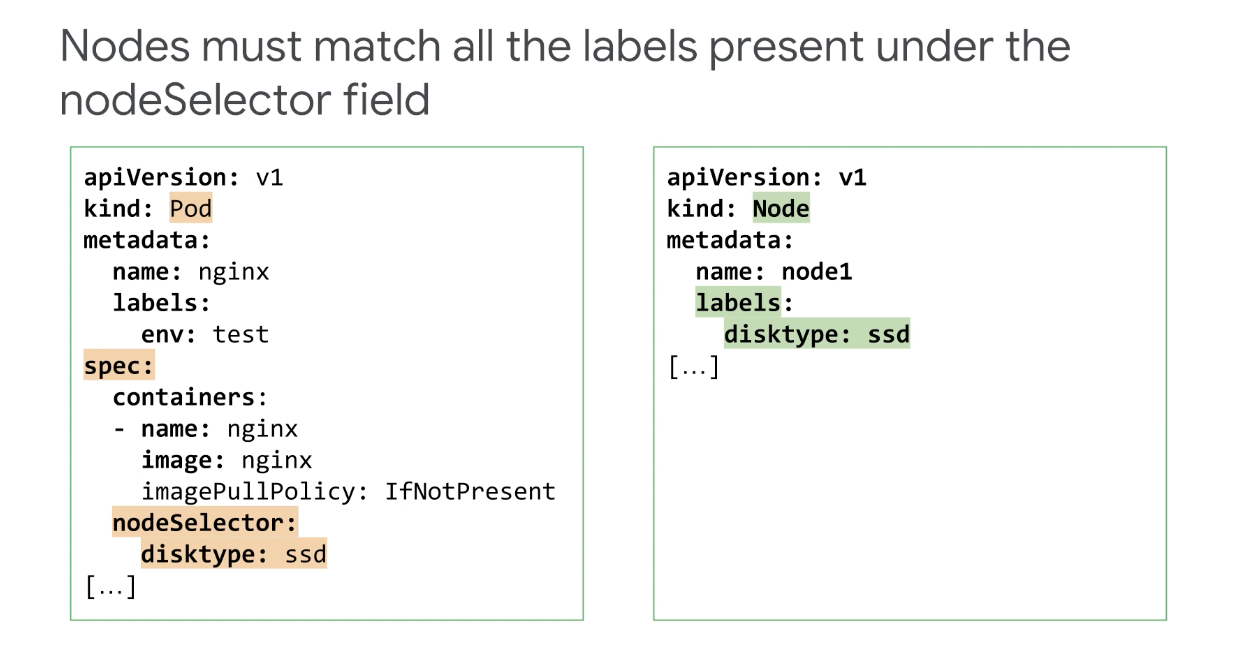
예를 들어 라벨 kubernetes.io/hostname은 GKE에서 자동으로 생성되거나 특정 기준을 충족하는 노드를 식별하기 위해 직접 라벨을 추가해야 할 수 있다.
예를 들어 이 포드는 노드가 AMD 또는 Intel 64비트 플랫폼에서 실행 중임을 나타내는 GKE 라벨이 붙은 노드에서 노드 레이블이 변경되면 실행 중인 포드는 영향을 받지 않으며. 노드 셀렉터는 포드 예약 중에만 사용된다.

7-4. 선호도 및 반선호도

NodeSelector와 마찬가지로 노드 선호도를 사용하면 레이블을 기반으로 포드를 예약할 수 있는 노드를 제한할 수 있지만 기능은 더 표현력이 있으며 레이블에 대해 제한하는 데 사용할 수 있다.
두 노드 및 노드에서 실행 중인 다른 Pod의 NodeSelector 요구 사항이 충족되지 않으면 Pod가 예약되지 않는 NodeSelector와 달리, 선호도 및 반선호도 기본 설정을 정의할 수 있다.
기본 설정이 충족되지 않으면 포드가 실행되는 것을 막지 않는 사실은 엄격한 요구 사항 과 소프트한 기본 설정을 지정할 수 있다고 생각하면 된다.

친화력과 반친화성은 'requiredDuringSchedulingIgnoredDuringExecution' 및 'preferredDuringSchedulingIgnoredDuringExecution' 규칙으로 표시된다.
키워드에는 'IgnoredDuringExecution' 문자열이 포함되어 있어 라벨이 변경되더라도 이미 실행 중인 Pod는 영향을 받지 않는다는 점을 상기시켜 준다. 여기에 표시된 'requiredDuringScheduling' 규칙은 NodeSelector와 유사한 엄격한 요구 사항이며 Pod가 예약되기 위해 충족되어야 한다.
이 엄격한 요구 사항 예에서 Pod는 키가 accelerator-type이고 값이 GPU 또는 TPU인 레이블이 있는 노드에서만 실행할 수 있다는 점이다. 이러한 레이블은 이전에 컴퓨팅 노드에 추가되어 있어야 한다.
여기서 단일 nodeSelectorTerms가 사용된다. 여러 nodeSelectorTerms를 사용할 수 있지만 예약에는 하나만 필요하다. 예제에서는 하나의 matchExpression만 언급되지만, 여러 matchExpression을 추가할 수 있다.
노드는 각 nodeSelector에 나열된 모든 matchExpressions를 충족해야 한다. 논리적으로 이들은 부울 AND를 사용하여 결합되며, In 연산자를 사용하면 여러 값을 가질 수 있지만 일치하는 데는 하나만 필요하다.
여기에 단일 키에 대해 두 개의 값이 기록되어 있는데, 논리적으로 In 연산자는 부울 OR 역할을 하기 때문에 문제는 없다.
NotIn, Exists, DoesNotExist, 보다 큰 경우 Gt, 보다 작은 경우 Lt와 같은 다양한 연산자를 사용할 수 있다.
예를 들어 이 예제에서 NotIn 연산자가 사용된 다면 노드 반선호도 규칙을 구성하게 된다.

'preferredDuringSchedulingIgnoredDuringExecution'을 지정하면 소프트 기본 설정 규칙이 생성된다. 가중치의 값 범위는 1~100 이며, 가장 약한 기본 설정 수준을 100으로 설정하면 가장 높은 기본 설정이 된다.
이 예에서 부드러운 기본 설정에는 1로 설정된 가중치도 부여된다. 엄격한 요구 사항이 아닌 소프트 기본 설정으로 만드는 것은 '필수' 키워드 대신 '선호'라는 단어를 사용하는 것이며, 스케줄러가 이러한 기본 설정을 평가할 때 Pod가 예약될 수 있는 각 노드는 총 가중치 점수를 받는다.
리소스 요청, 리소스 제한 및 'requiredDuringSchedulingIgnoredDuringExecution'과 같은 기타 nodeAffinity 규칙과 같은 충족하는 모든 요구 사항을 기반으로 한다. 'preferredDuringSchedulingIgnoredDuringExecution'의 가중치도 이 총점에 추가될 수 있고 그런 다음 스케줄러는 총 점수가 가장 높은 노드에 포드를 할당한다.
가중치는 기본 설정의 강도를 정의하며 팟 간 어피니티 및 안티어피니티 기능은 노드 어피니티 개념을 확장한다.

노드 자체의 라벨만 아니라 노드에서 이미 실행 중인 포드 라벨을 기반으로 하는 규칙을 포함한다. 필요하거나 다른 포드와 동일한 노드에서 실행하는 것을 선호하는 포드는
podAffinity 규칙으로 구성해야 하고, 다른 포드와 동일한 노드에서 예약해서는 안되거나 예약되어서는 안 되는 포드는 podAntiAffinity 규칙으로 구성할 수 있다. 이것은 몇 가지를 추가하여 노드 선호도와 유사함은 사실이다.
추가 필드, 이 경우 이 포드는 라벨이 key: 값인 app: webserver인 포드와 동일한 노드에서 예약되지 않는 것을 강력히 선호한다. 이것은 강력하지만 여전히 부드러운 선호도인 점!
podAntiAffinity 규칙은 가능한 가장 높은 값인 100을 갖지만, 규칙은 여전히 preferredDuringScheduling이다.
topologyKeys를 사용하면 특정 노드보다 더 높은 수준에서 선호도 및 비선호도 규칙을 지정할 수도 있다.

예를 들어 Pod가 동일한 노드가 아니라 동일한 영역에 함께 배치되지 않도록 하려면 topologyKey를 정의하여 podAntiAffinity 규칙이 영역 토폴로지 수준에서 적용될 수 있다.
topologyKey를 사용하여 노드, 영역 및 지역과 같은 토폴로지 도메인을 지정할 수 있으며, 여기에 표시된 Pod에는 topologyKey가 설정된 podAntiAffinity 규칙이 있으므로 동일한 영역에서 예약되지 않는 것을 선호한다.
key: 및 app 값: webserver로 이미 하나의 Pod를 실행 중이다.
7-5. 포드 어피니티와 안티어피니티를 결합한 예시
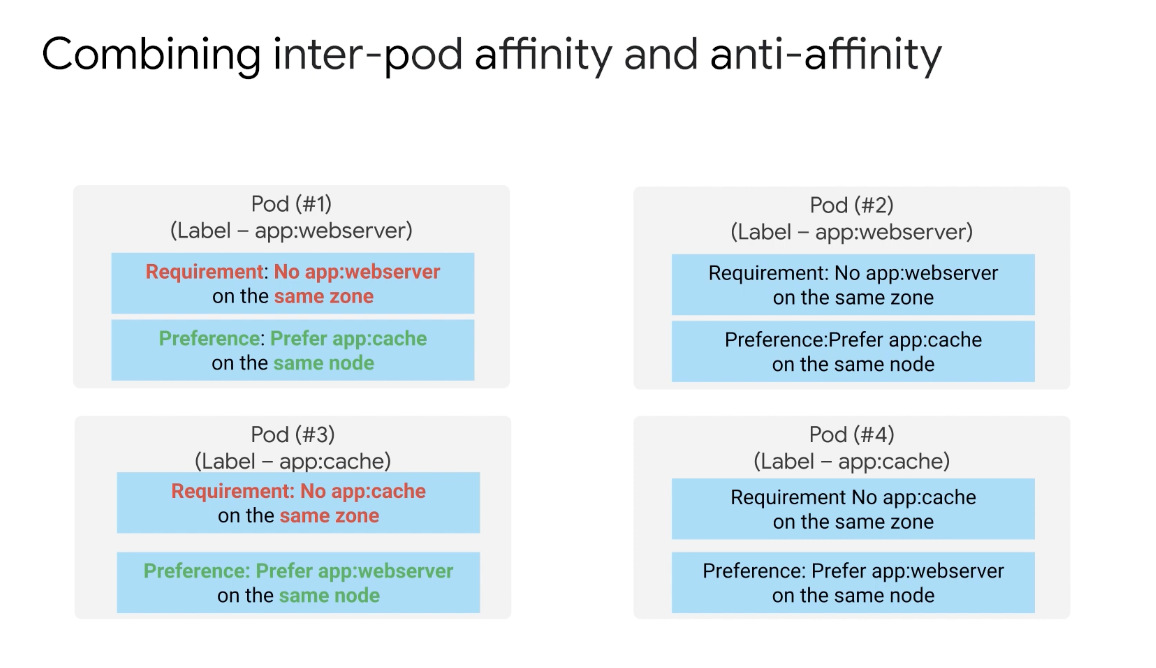
레이블이 app:webserver인 Pod #1에는 엄격한 제한과 소프트 제한이 모두 있다. 이 포드에서 엄격한 제한에는 다른 포드가 app:webserver 레이블이 있는 서버는 동일한 영역에서 허용되지 않는 반면에 소프트 제한에는 동일한 노드에 app:cache 레이블이 있는 다른 포드가 있는 것을 선호하는 친화성이 있다.
그러나 캐시 포드는 웹 서버와 동일한 노드에서 예약되는 것을 선호하지만, 여러 캐시 포드가 동일한 영역에 배포되는 것을 방지하는 엄격한 제한이 있다.
결과적으로 배포에는 영역 수준에서 서로 반발하고 노드 수준에서 캐시 Pod를 끌어들이는 두 개의 웹 서버 포드가 있다. 두 캐시 포드는 또한 영역 수준에서 서로를 밀어내고 있다.
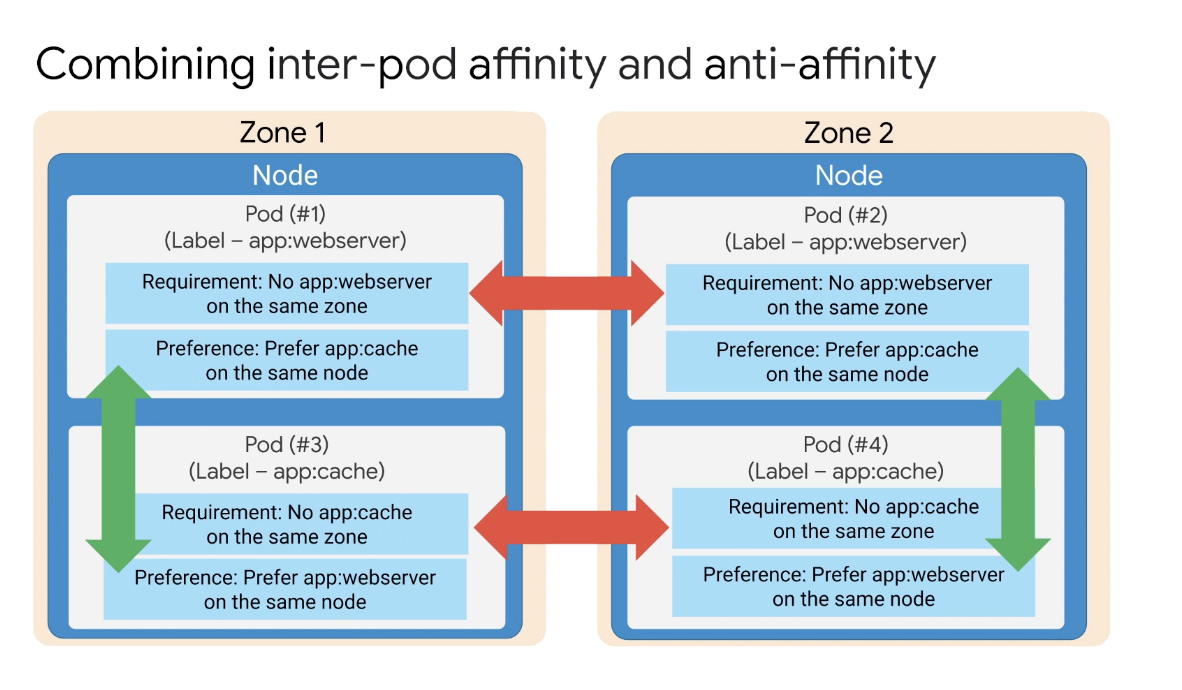
예제를 통해 작업해 보자면 포드 1은 이미 영역 1의 노드에서 실행 중이며 이제 포드 2가 예약되는데 포드 1과 2는 엄격한 제한에 따라 서로 밀어낸다. 따라서 포드 2는 다른 영역 2 및 다른 노드에서 실행되도록 예약된다.
포드 3에는 웹 서버 포드와 동일한 노드에서 실행되는 소프트 제한 기본 설정이 있으므로 포드 1 또는 포드 2와 동일한 노드에서 예약할 수 있다.
여기서는 Pod 1과 함께 실행하도록 예약함을 볼 수 있고 마지막으로 Pod 4를 예약해야 하는데 엄격한 제한이 있는 포드 3에서 격리되지만 포드 2와 함께 다른 영역에서 실행할 수 있다.
또한 소프트 제한에는 다른 노드가 아닌 웹 서버 포드와 동일한 노드에서 실행되는 기본 설정이 있다.
이를 통해 서로 다른 토폴로지에서 Pod를 같은 위치에 배치하기 위한 선호도 규칙을 지정할 수 있다. 결국 계층을 관리하고 토폴로지 계층에 걸쳐 Pod의 배포를 제어하는 셈이다.
7-6. Taints & Tolerations
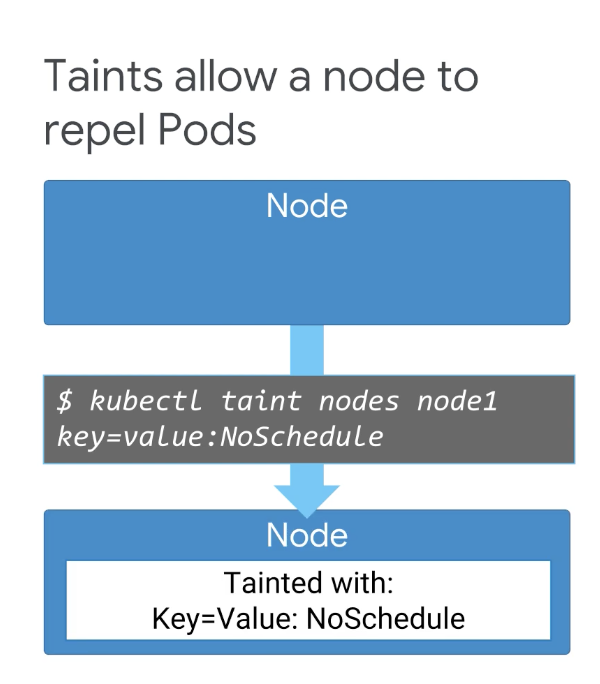
앞서 노드 어피니티는 포드를 끌어당기고 반어피니티는 포드를 밀어낸다는 것을 알았다. taint를 사용하여 Pod가 특정 노드에서 예약되지 않도록 할 수도 있는데, ❗️그러면 taint와 선호도 설정이 모두 필요한 이유가 무엇일까
당연히 선택권이 있으면 더 많은 관리 유연성을 얻을 수 있기 때문이다. Pod에서 NodeSelector, 선호도 및 반선호도 규칙을 구성하지만, 반대로 노드에서 taint를 구성하면 클러스터의 모든 Pod에 적용된다는 점은 짐작해볼 수 있다.
우리는 가장 경제적으로 표현할 수 있는 메커니즘을 사용해야 한다. 노드를 오염시키려면 kubectl taint 명령을 사용하면 된다. taint에는 value와 taint 효과가 있는 key가 있다.
NoSchedule 효과가 있는 이 오염은 모든 Pod가 이 특정 노드에서 예약되지 않도록 제한한다. 노드에 여러 taint를 적용할 수 있으며, 이 경우 Pod를 사용할 수 없다.


그러면 예약되고 실행 중인 모든 포드가 제거되지 않을까? 그렇다면 여기서 노드를 어떻게 예약할 수 있을까? Toleration이 이를 가능하게 한다. Toleration은 포드에 적용된다.
Toleration은 Pod가 예약되지 않거나 노드에서 계속 실행되는 것을 방지하는 taint의 영향에 Pod가 대응할 수 있도록 하는 메커니즘이다.
toleration 필드는 키, 값, 효과 및 연산자로 구성된다. Pod의 toleration은 toleration의 키와 taint가 동일한 경우 taint와 일치한다.
효과는 동일(No 스케줄)하며 연산자는 값을 수락한다. Operator 필드는 약간의 유연성을 허용합니다. 여기에 표시된 것처럼 연산자 필드가 같음인 경우 값도 같아야 한다.
7-7. 클러스터에 Software 가져오기
이전 모듈에서는 Cloud Build와 같은 도구를 사용하여 소프트웨어를 컨테이너로 패키징하는 방법에 대해 설명했고, Container Registry를 사용하여 프라이빗 컨테이너 이미지를 저장할 수 있으며 Kubernetes는 가져올 수 있다.
이러한 이미지를 레지스트리에서 가져와 포드에서 실행하지만, 안정적이고 유용하게 실행되도록 하는 배포 패턴과 서비스를 정의하는 것은 사용자에게 달려 있다. 고유한 YAML 매니페스트를 만들고 소스 제어에서 직접 유지 관리하는 작업말이다.
사용자에게 YAML 파일을 작성하는 것은 그리 재미있는 일이 아닐 수 있다.
그리고 인기 있는 오픈 소스 소프트웨어를 Kubernetes 클러스터에 배포하기 위한 최상의 패턴을 다른 사람들은 이미 가지고 있지 않을까?

따라서 이 문제는 Helm이 해결해줄 수 있다. apt-get 및 yum은 Linux용 패키지 관리자처럼, Helm을 사용하면 개발자는 Chart라는 패키지로 Kubernetes 개체를 구성할 수 있다.
차트를 쉽게 생성, 버전 관리, 공유 및 게시할 수 있으며, 차트는 복잡한 애플리케이션의 배포를 관리한다.
차트를 매개변수화된 YAML 템플릿으로 생각할 수 있으며, Helm 차트는 작동하는 데 필요한 매개변수를 알고 있다.
예를 들어 필요한 각 구성 요소의 인스턴스 수와 리소스 제약 조건들 즉, Helm 차트 개발자는 이러한 매개변수를 정의하고 유용한 기본값도 제공한다.
Helm 차트를 설치할 때 Helm은 사용자가 제공한 매개변수를 채우고 클러스터에 대한 차트의 특정 인스턴스 릴리스. 새 차트를 개발하고 차트 리포지토리를 관리할 수 있는 명령줄 클라이언트(helm이라고도 함)이 있다.
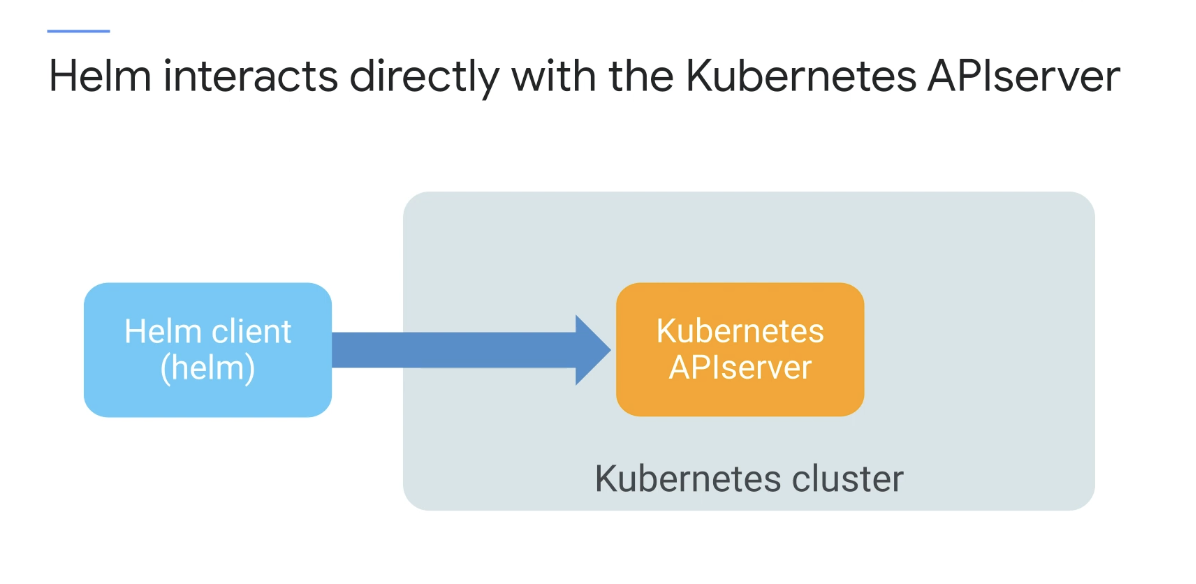
Helm은 Kubernetes API 서버와 직접 상호 작용하여 Kubernetes 리소스를 설치, 업그레이드, 쿼리 및 제거한다.
Helm을 사용하면 작업을 줄이고 오류 위험을 줄이면서 Kubernetes 클러스터에 오픈 소스 소프트웨어를 배포할 수 있다는 강력한 기능이 있다.
그러나, 여전히 Helm 자체를 관리해야 하며 사용하려는 도구를 찾아야 한다 더 간단한 것이 있다면?
Google Cloud Marketplace는 바로 사용할 수 있는 개발 스택, 솔루션, 서비스를 제공한다고 한다.
결국 GCP 홍보!
8. 포드 자동 확장 및 NodePool 구성 실습
➡️ Cloud Shell Enabled
Google Kubernetes Engine(GKE)에서 애플리케이션을 설정한 다음 HorizontalPodAutoscaler를 사용하여 웹 애플리케이션을 자동 확장하고 다양한 유형의 여러 노드 풀로 작업하고 taint 및 toleration을 적용하여 기본 노드 풀과 관련하여 Pod의 일정을 제어해보자.
클러스터에 연결
export my_zone=us-central1-a
export my_cluster=standard-cluster-1
source <(kubectl completion bash)
gcloud container clusters get-credentials $my_cluster --zone $my_zone8-1. GKE 클러스터에 샘플 웹 애플리케이션 배포
git clone https://github.com/GoogleCloudPlatform/training-data-analyst
ln -s ~/training-data-analyst/courses/ak8s/v1.1 ~/ak8s
cd ~/ak8s/Autoscaling/
-------------
$ cat web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 1
selector:
matchLabels:
run: web
template:
metadata:
labels:
run: web
spec:
containers:
- image: gcr.io/google-samples/hello-app:1.0
name: web
ports:
- containerPort: 8080
protocol: TCP
resources:
# You must specify requests for CPU to autoscale
# based on CPU utilization
requests:
cpu: "250m"
-------------
$ kubectl create -f web.yaml --save-config
deployment.apps/web created
$ kubectl expose deployment web --target-port=8080 --type=NodePort
service/web exposed
$ kubectl get service web
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web NodePort 10.15.242.129 <none> 8080:32077/TCP 22s8-2. 클러스터에서 자동 크기 조정 구성
$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
web 1/1 1 1 2m38s자동 크기 조정을 위해 샘플 애플리케이션을 구성하려면(그리고 CPU 사용률 목표가 1%인 상태에서 최대 복제본 수를 4개로, 최소 복제본 수를 1개로 설정하려면) 다음 명령을 실행하면 된다.
$ kubectl autoscale deployment web --max 4 --min 1 --cpu-percent 1
horizontalpodautoscaler.autoscaling/web autoscaled
$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
web 1/1 1 1 10m8-3. HorizontalPodAutoscaler 개체 검사
kubectl autoscale 이전 작업에서 사용한 명령은 크기 조정 대상이라는 지정된 리소스를 대상으로 하는 개체를 만들고 필요 HorizontalPodAutoscaler에 따라 크기를 조정한다.
자동 크기 조정기는 자동 크기 조정기를 만들 때 지정하는 평균 CPU 사용률과 일치하도록 크기 조정 대상의 복제본 수를 주기적으로 조정한다.
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web 0%/1% 1 4 1 9m33s
$ kubectl describe horizontalpodautoscaler web
Name: web
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Wed, 19 Jul 2023 12:41:20 +0000
Reference: Deployment/web
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (0) / 1%
Min replicas: 1
Max replicas: 4
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 10m horizontal-pod-autoscaler No recommendation
$ kubectl get horizontalpodautoscaler web -o yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: "2023-07-19T12:41:20Z"
name: web
namespace: default
resourceVersion: "185556"
uid: e54245b5-2a49-4853-92a9-efe265f99501
spec:
maxReplicas: 4
metrics:
- resource:
name: cpu
target:
averageUtilization: 1
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web
status:
conditions:
- lastTransitionTime: "2023-07-19T12:52:23Z"
message: recommended size matches current size
reason: ReadyForNewScale
status: "True"
type: AbleToScale
- lastTransitionTime: "2023-07-19T12:41:43Z"
message: the HPA was able to successfully calculate a replica count from cpu resource
utilization (percentage of request)
reason: ValidMetricFound
status: "True"
type: ScalingActive
- lastTransitionTime: "2023-07-19T12:41:37Z"
message: the desired count is within the acceptable range
reason: DesiredWithinRange
status: "False"
type: ScalingLimited
currentMetrics:
- resource:
current:
averageUtilization: 0
averageValue: 1m
name: cpu
type: Resource
currentReplicas: 1
desiredReplicas: 1
8-4. 자동 크기 조정 구성 테스트
웹 애플리케이션을 강제로 확장하려면 웹 애플리케이션에 과도한 로드를 생성해야 한다. 샘플 애플리케이션 웹 서버에 대해 HTTP 쿼리의 무한 루프를 실행하는 네 개의 컨테이너 배포를 정의하는 구성 파일을 만들 수 있다.
loadgen.yaml - 제공된 파일을 사용하여 loadgen 애플리케이션을 배포하여 웹 애플리케이션에 로드를 생성해보자
$ cat loadgen.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: loadgen
spec:
replicas: 4
selector:
matchLabels:
app: loadgen
template:
metadata:
labels:
app: loadgen
spec:
containers:
- name: loadgen
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- while true; do wget -q -O- http://web:8080; done
$ kubectl apply -f loadgen.yaml
deployment.apps/loadgen created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
loadgen-665b67d8f9-8zpr8 1/1 Running 0 25s
loadgen-665b67d8f9-chtd5 1/1 Running 0 25s
loadgen-665b67d8f9-fgqgd 1/1 Running 0 25s
loadgen-665b67d8f9-htb5g 1/1 Running 0 25s
web-794565cfb9-hljm6 1/1 Running 0 18m
$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
loadgen 4/4 4 4 46s
web 1/1 1 1 18m
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web 96%/1% 1 4 4 15m
자동 크기 조정기는 웹 배포를 4개의 복제본으로 늘렸음을 볼 수 있다. REPLICAS = 4
# 로드 중지
$ kubectl scale deployment loadgen --replicas 0
deployment.apps/loadgen scaled
$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
loadgen 0/0 0 0 2m46s
web 4/4 4 4 20m
자동 확장 처리를 배포할 때 구성한 복제본 1개의 최소값으로 웹 애플리케이션이 축소되었는지 확인해보자 - 수 분 소요
8-5. 노드 풀 관리
선점형 인스턴스를 사용하여 새 노드 풀을 만든 다음 선점형 노드에서만 실행되도록 웹 배포를 제한해보자
3개의 선점형 VM 인스턴스가 있는 새 노드 풀을 배포하려면 다음 명령어를 실행
$ gcloud container node-pools create "temp-pool-1" --cluster=$my_cluster --zone=$my_zone --num-nodes "2" --node-labels=temp=true --preemptibleDefault change: During creation of nodepools or autoscaling configuration changes for cluster versions greater than 1.24.1-gke.800 a default location policy is applied. For Spot and PVM it defaults to ANY, and for all other VM kinds a BALANCED policy is used. To change the default values use the `--location-policy` flag.Creating node pool temp-pool-1...working.. Creating node pool temp-pool-1...done.
Created [https://container.googleapis.com/v1/projects/qwiklabs-gcp-04-a37d634e5f03/zones/us-central1-a/clusters/standard-cluster-1/nodePools/temp-pool-1].
NAME: temp-pool-1
MACHINE_TYPE: e2-medium
DISK_SIZE_GB: 100
NODE_VERSION: 1.26.5-gke.1200
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-standard-cluster-1-temp-pool-1-567f5a20-hs37 Ready <none> 41s v1.26.5-gke.1200
gke-standard-cluster-1-temp-pool-1-567f5a20-q3t5 Ready <none> 42s v1.26.5-gke.1200
gke-standard-cluster-standard-cluster-12bfe733-967z Ready <none> 6h48m v1.26.5-gke.1200
gke-standard-cluster-standard-cluster-12bfe733-h41g Ready <none> 6h48m v1.26.5-gke.1200
temp=true노드 풀을 만들 때 레이블을 설정했기 때문에 추가한 모든 노드에는 레이블이 있다. 이 레이블을 사용하면 이러한 노드를 쉽게 찾고 구성할 수 있다
$ kubectl get nodes -l temp=true
NAME STATUS ROLES AGE VERSION
gke-standard-cluster-1-temp-pool-1-567f5a20-hs37 Ready <none> 2m2s v1.26.5-gke.1200
gke-standard-cluster-1-temp-pool-1-567f5a20-q3t5 Ready <none> 2m3s v1.26.5-gke.12008-6 taint 및 toleration으로 스케줄링 제어
스케줄러가 임시 노드에서 Pod를 실행하지 않도록 하려면 임시 풀의 각 노드에 taint를 추가한다. Taint는 Pod가 특정 노드에서 실행될 수 있는지 여부를 결정하는 효과(예: NoExecute)가 있는 키-값 쌍으로 구현되며, taint의 키-값을 허용하도록 구성된 노드만 이러한 노드에서 실행되도록 예약된다.
새로 생성된 각 노드에 taint를 추가하려면 다음 명령을 실행할 수 있으며, temp=true레이블을 사용하여 이 변경 사항을 모든 새 노드에 동시에 적용 할 수 있다.
$ kubectl taint node -l temp=true nodetype=preemptible:NoExecute
node/gke-standard-cluster-1-temp-pool-1-567f5a20-hs37 tainted
node/gke-standard-cluster-1-temp-pool-1-567f5a20-q3t5 tainted이러한 오염된 노드에서 애플리케이션 포드를 실행하려면 배포 구성에 tolerations 키를 추가해야 한다.
파일을 편집하여 web.yaml템플릿 spec섹션에 다음 키를 추가
tolerations:
- key: "nodetype"
operator: Equal
value: "preemptible"
--------
$ cat web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 1
selector:
matchLabels:
run: web
template:
metadata:
labels:
run: web
spec:
tolerations:
- key: "nodetype"
operator: Equal
value: "preemptible"
containers:
- image: gcr.io/google-samples/hello-app:1.0
name: web
ports:
- containerPort: 8080
protocol: TCP
resources:
# You must specify requests for CPU to autoscale
# based on CPU utilization
requests:
cpu: "250m"새 노드 풀을 사용하도록 웹 배포를 강제하려면 템플릿의 spec섹션에 nodeSelector 키를 추가한다. 이것은 방금 추가한 tolerations 키와 유사하다.
nodeSelector:
temp: "true"
------
$ cat web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 1
selector:
matchLabels:
run: web
template:
metadata:
labels:
run: web
spec:
tolerations:
- key: "nodetype"
operator: Equal
value: "preemptible"
nodeSelector:
temp: "true"
containers:
- image: gcr.io/google-samples/hello-app:1.0
name: web
ports:
- containerPort: 8080
protocol: TCP
resources:
# You must specify requests for CPU to autoscale
# based on CPU utilization
requests:
cpu: "250m"
$ kubectl apply -f web.yaml
deployment.apps/web configured
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
web-79796588bb-9kbv4 1/1 Running 0 21s변경 사항을 확인하려면 다음 명령을 사용하여 실행 중인 웹 포드를 검사해보자
Node-Selectors: temp=true
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
nodetype=preemptible
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 93s default-scheduler Successfully assigned default/web-79796588bb-9kbv4 to gke-standard-cluster-1-temp-pool-1-567f5a20-hs37
Normal Pulling 92s kubelet Pulling image "gcr.io/google-samples/hello-app:1.0"
Normal Pulled 91s kubelet Successfully pulled image "gcr.io/google-samples/hello-app:1.0" in 1.165564533s (1.165581954s including waiting)
Normal Created 91s kubelet Created container web
Normal Started 91s kubelet Started container web출력은 포드가 새로운 선점형 노드에서 taint 값을 허용하므로 해당 노드에서 실행하도록 예약할 수 있음을 확인할 수 있다.
웹 애플리케이션만 직접 확장할 수 있지만 loadgen 앱을 사용하면 웹 및 loadgen 애플리케이션에 적용되는 다양한 taint, toleration 및 nodeSelector 설정이 예약된 노드에 어떤 영향을 미치는지 확인할 수 있다. loadgen 앱을 사용해보자
$ kubectl scale deployment loadgen --replicas 4
deployment.apps/loadgen scaledloadgen 앱이 default-pool노드에서만 실행되고 웹 앱이 선점형 노드에서만 실행되고 있음을 보여준다.
taint 설정은 포드가 선점형 노드에서 실행되지 않도록 하여 loadgen 애플리케이션이 기본 풀에서만 실행되도록 한다. toleration 설정은 웹 애플리케이션이 선점형 노드에서 실행되도록 허용하고 nodeSelector는 웹 애플리케이션 포드가 해당 노드에서 실행되도록 강제할 수 있다.
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loadgen-665b67d8f9-427cm 1/1 Running 0 2m1s 10.12.1.14 gke-standard-cluster-standard-cluster-12bfe733-967z <none> <none>
loadgen-665b67d8f9-fx22v 1/1 Running 0 2m1s 10.12.1.13 gke-standard-cluster-standard-cluster-12bfe733-967z <none> <none>
loadgen-665b67d8f9-skmbc 1/1 Running 0 2m1s 10.12.2.11 gke-standard-cluster-standard-cluster-12bfe733-h41g <none> <none>
loadgen-665b67d8f9-zmszt 1/1 Running 0 2m1s 10.12.2.12 gke-standard-cluster-standard-cluster-12bfe733-h41g <none> <none>
web-79796588bb-86ct9 1/1 Running 0 91s 10.12.4.3 gke-standard-cluster-1-temp-pool-1-567f5a20-hs37 <none> <none>
web-79796588bb-9kbv4 1/1 Running 0 6m18s 10.12.4.2 gke-standard-cluster-1-temp-pool-1-567f5a20-hs37 <none> <none>
web-79796588bb-wrfl7 1/1 Running 0 91s 10.12.3.2 gke-standard-cluster-1-temp-pool-1-567f5a20-q3t5 <none> <none>
web-79796588bb-zlnrb 1/1 Running 0 91s 10.12.3.3 gke-standard-cluster-1-temp-pool-1-567f5a20-q3t5 <none> <none>