
CES 2025 엔비디아 CEO 기조연설
젠슨 황(Jensen Huang)의 CES 2025 기조연설은 엔비디아의 혁신적인 기술과 인공지능(AI)의 미래에 대한 비전을 중심으로 진행되었습니다.
연설은 토큰의 개념에서 시작하여 엔비디아의 기술적 진화, GPU와 AI 융합, 산업 디지털화, 그리고 물리적 AI에 대한 심도 있는 논의를 포함하고 있습니다. 아래는 연설의 주요 내용을 상세히 정리한 내용입니다.
링크 : https://youtu.be/k82RwXqZHY8
- Timeline
- 0:00:00 CES 2025 Keynote Introduction
- 0:09:33 GeForce RTX
- 0:21:48 Blackwell
- 0:36:03 Agentic AI
- 0:47:05 AI PCs
- 0:52:09 Physical AI
- 1:07:38 Autonomous Vehicles
- 1:16:20 Robotics
- 1:21:37 Project DIGITS
- 1:27:20 Closing
1. 인공지능과 토큰의 개념
젠슨 황은 영상을 통해 "토큰(token)"을 인공지능의 핵심 구성 요소로 소개하며, 이를 통해 AI가 세상을 이해하고 창조하는 과정을 설명했습니다.

- 토큰의 역할:
- 언어, 이미지, 비디오를 이해하고 생성.
- 데이터를 지식으로 변환하고, 이미지에 생명을 불어넣음.
- 로봇의 동작을 학습시키고 의학적 혁신을 가능하게 함.
- 위험 예측 및 내부의 위협에 대한 치료법 발견 지원.
- 이를 통해 토큰이 AI 혁신의 기반이 됨을 강조.

2. 엔비디아의 역사와 기술 발전
젠슨 황은 엔비디아의 역사와 GPU의 발전 과정을 소개하며, 회사의 기술적 진화가 AI 혁신에 미친 영향을 설명했습니다.
-
1993년: NV1 출시로 PC에서 게임 콘솔 기능 구현.
-
1999년: 프로그래머블 GPU 발명으로 현대 컴퓨터 그래픽의 기반 마련.

-
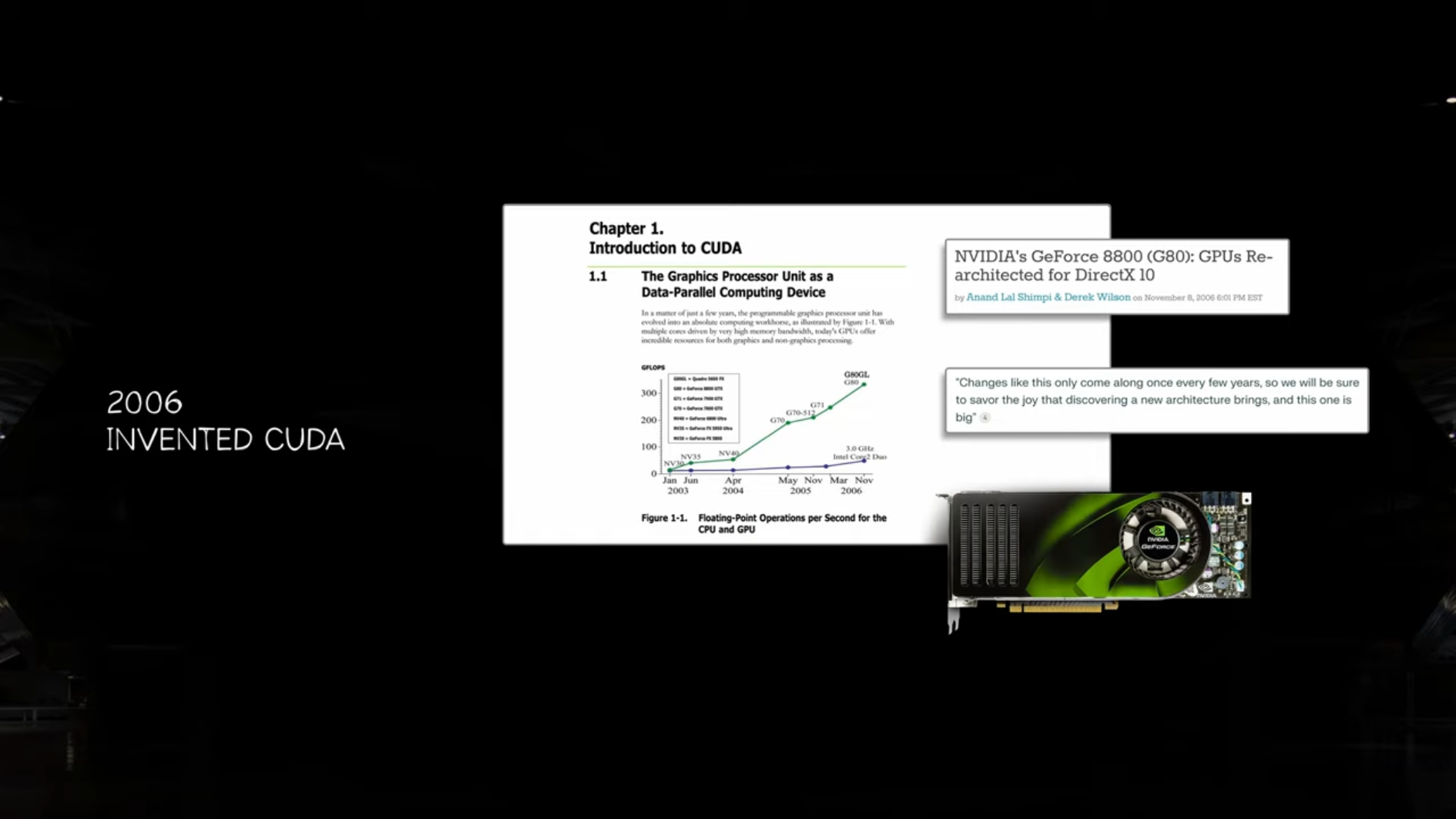
2006년: CUDA 출시로 GPU의 프로그래밍 가능성을 확장, AI 및 과학적 계산에 활용.
-
2012년: AlexNet이 CUDA를 사용하여 딥러닝 혁명을 촉발.

-
2018년: 구글의 Transformer 모델 발표로 AI와 컴퓨팅 전체의 패러다임 전환.
- Transformer는 텍스트, 이미지, 소리뿐 아니라 물리적 데이터까지 이해 및 생성 가능.
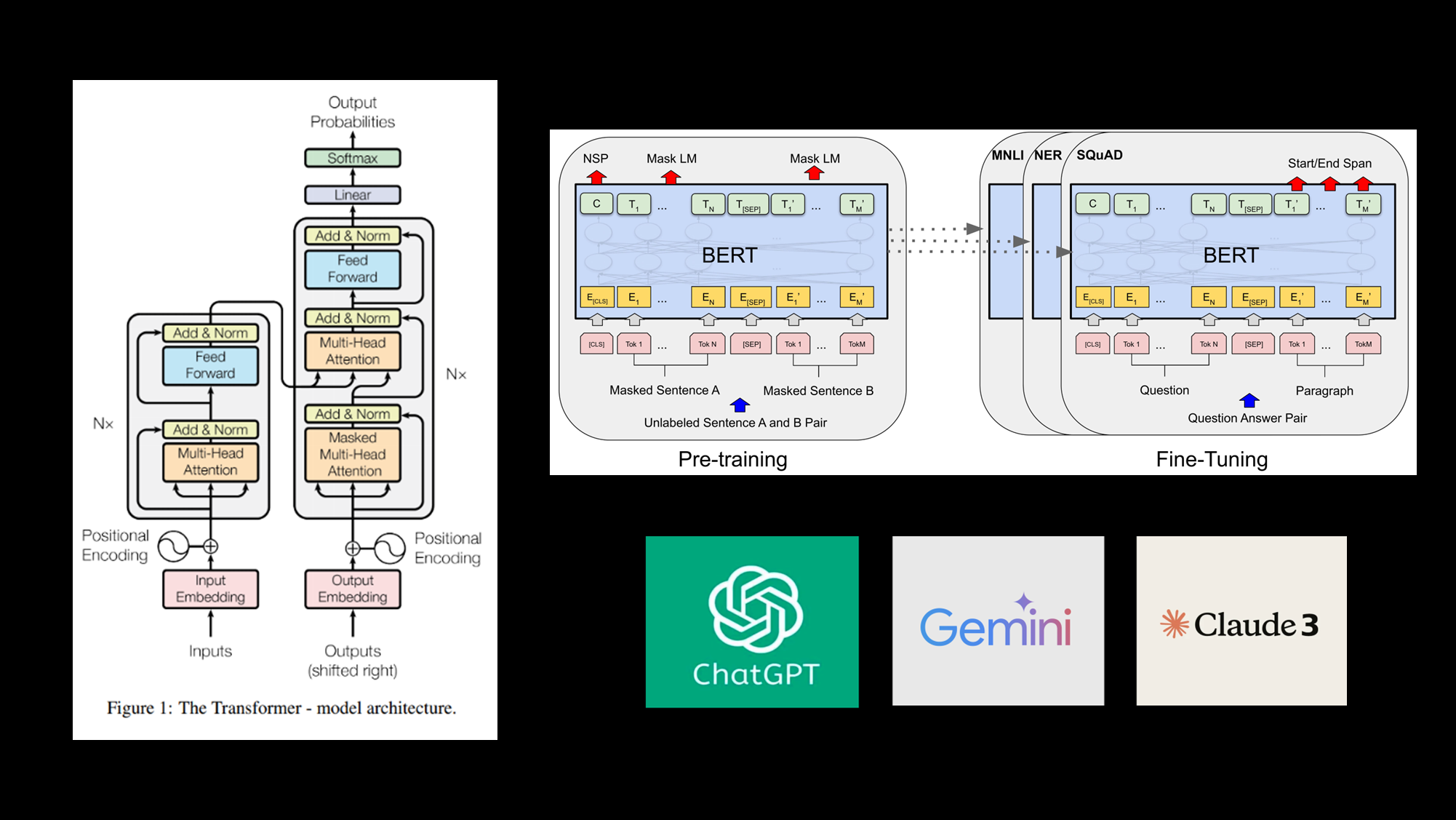
- Transformer는 텍스트, 이미지, 소리뿐 아니라 물리적 데이터까지 이해 및 생성 가능.
3. 새로운 RTX Blackwell 아키텍처
Blackwell 아키텍처 기반 GPU

차세대 GPU 아키텍처
NVIDIA의 Blackwell 아키텍처는 GeForce RTX 50 시리즈에 적용된 차세대 GPU 마이크로아키텍처로, AI 연산과 그래픽 렌더링의 통합에 중점을 둔 설계로 높은 성능과 효율을 제공합니다.

트랜지스터와 연산 성능
Blackwell은 92억 개(92B)의 트랜지스터와 4,000 AI TOPS 이상의 연산 성능을 지원하며, 이전 세대 대비 약 3배의 성능 향상을 달성했습니다. 이로써 AI 워크로드와 고성능 그래픽 처리에서 크게 진화된 퍼포먼스를 제공합니다.

용어정리
- AI TOPS (Tensor Operations Per Second)
- DLSS, 신경망 텍스처 압축 등 AI 기능에 활용
- RT TFLOPS (Ray Tracing Floating Point Operations)
- Ray Tracing, 그림자, 반사 등 실시간 렌더링에 사용
- Shader TFLOPS
- 게임 그래픽스, 3D 렌더링 등 기본 그래픽 작업에 활용
메모리 혁신
GDDR7 메모리를 탑재하여 1.8TB/s의 대역폭을 제공하며, 이전 세대 대비 두 배 이상의 데이터 처리 성능을 보장합니다. 이를 통해 고해상도 렌더링 및 복잡한 그래픽 작업에서 더욱 안정적인 성능을 제공합니다.

- 참고: 발표 이후 SK와 삼성의 GDDR7 관련 논란이 있었습니다. 이 포스트에서는 해당 이슈를 다루지는 않지만, 궁금하신 분들을 위해 참고로 관련 기사 링크를 공유합니다. 😊
DLSS 4와 AI 활용
- 엔비디아의 DLSS(Deep Learning Super Sampling)는 인공지능을 활용하여 게임의 그래픽 성능과 화질을 향상시키는 기술입니다.
- 이 기술은 게임을 낮은 해상도로 렌더링한 후, AI를 통해 고해상도로 업스케일링하여 프레임 레이트를 높이고, 이미지 품질을 개선합니다.
- DLSS를 활성화하면 더 나은 화질과 더 높은 FPS를 기대할 수 있습니다. 일부 기능의 사용 가능 여부는 RTX 세대에 따라 달라지므로 사용 중인 NVIDIA GPU RTX에 따라 달라집니다.

💌 이전 DLSS Versions 정리
DLSS는 Subpixel Deformation(하위 픽셀 변형)을 통해 이전 이미지의 데이터를 사용하여 미세한 디테일을 생성하고 신호 처리 과정에서 발생하는 신호 왜곡 현상, 에일리어싱 현상을 줄이는 TAAU(템포럴 안티 에일리어싱 업샘플링)를 실행하는 것입니다. (이미지 출처 : https://www.nvidia.com/en-us/geforce/news/dlss3-ai-powered-neural-graphics-innovations/)
- DLSS 2.0 💻
- 특징:
- 저해상도 원시 입력, 모션 벡터, 노출/밝기 정보를 사용.
- 텐서 코어를 활용해 일반화된 AI 학습 모델 사용.
- 대부분의 게임과 호환 가능.
- 장점:
- 시간적 아티팩트를 억제하며, 디테일을 잘 복원.
- 기존 TAAU보다 선명한 이미지를 생성 가능.
- 게임마다 별도의 학습 없이 바로 적용 가능.
- 제한사항:
- 완벽한 템포럴 솔루션이 아니며, 일부 아티팩트(예: 고스트 현상)가 여전히 발생.
- DLSS 3.0 💻
- 특징:
- 광학 흐름 가속기를 활용한 모션 보간 기능 도입.
- 두 개의 연속된 이미지를 사용해 중간 프레임을 생성하여 부드러운 움직임 구현.
- 모든 새 이미지 렌더링 시 추가 이미지 생성 가능.
- 시스템 지연 시간을 줄이기 위해 NVIDIA Reflex 통합.
- 장점:
- 네이티브 렌더링 대비 시스템 지연 시간 최대 2배 감소.
- 새로운 광학 흐름 알고리즘으로 프레임 속도를 효과적으로 두 배 증가.
- 제한사항:
- RTX 40 시리즈 이상에서만 사용 가능.
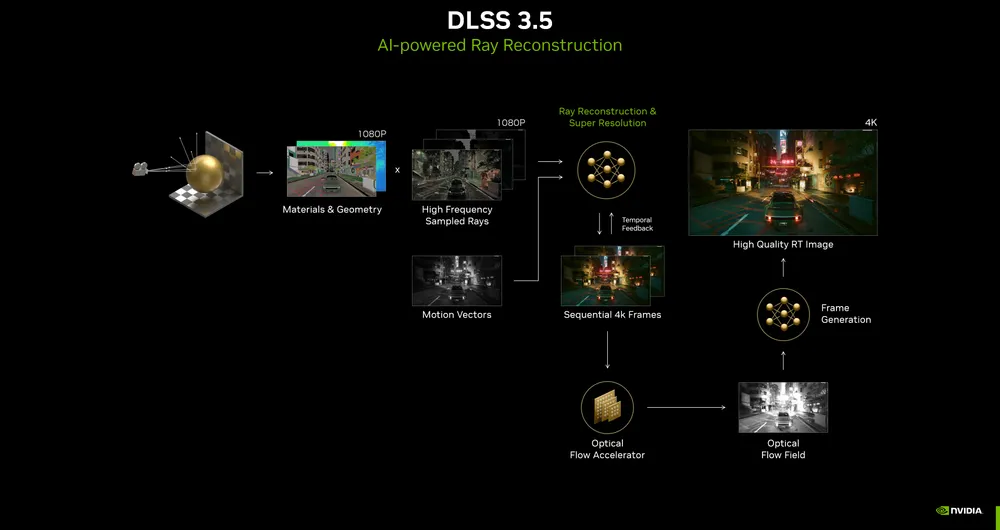
- DLSS 3.5 💻
- 특징:
- 광선 재구성 기능(Ray Reconstruction) 도입.
- 여러 노이즈 제거 알고리즘을 단일 AI 모델로 대체.
- 버전 3.0 대비 5배 더 큰 데이터 세트로 학습된 모델 활용.
- 장점:
- 고품질 광선 추적(Ray Tracing)을 위한 디테일 복원과 이미지 개선.
- 다양한 알고리즘 통합으로 효율적이고 일관된 결과 제공.
- 적용 가능 GPU:
- RTX 40 시리즈 외에도 이전 RTX GPU에서도 사용 가능.

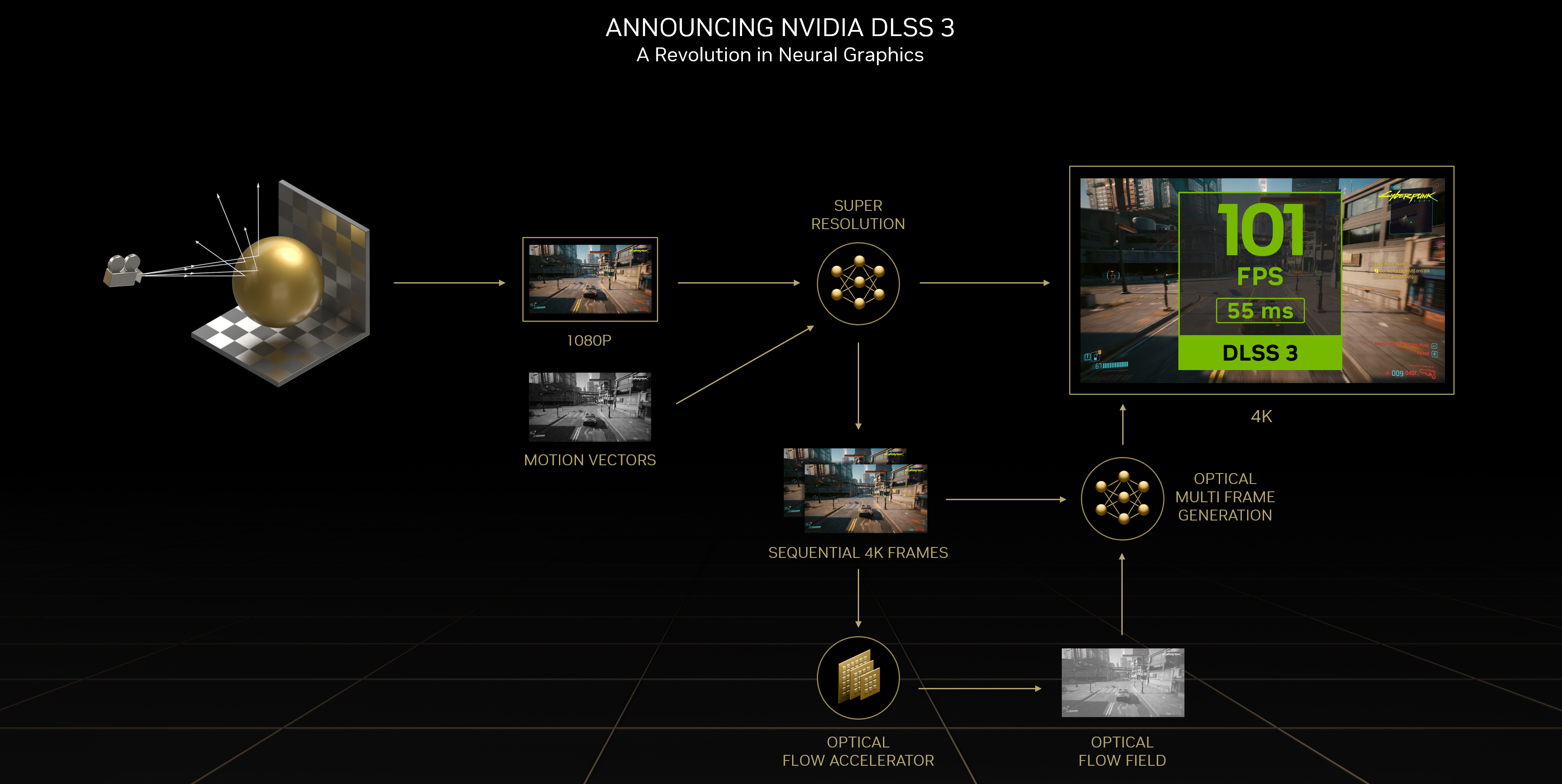
차세대 DLSS, DLSS Multi Frame Generation의 프레임 페이싱 요구 사항을 지원하기 위해 Blackwell 아키텍처는 향상된 하드웨어 플립 미터링 기능으로 구축되어 원활한 고품질 경험에 필요한 속도와 정확성을 제공합니다.
-
AI 기반 DLSS 4(Deep Learning Super Sampling):
최신 버전인 DLSS 4는 멀티 프레임 생성(Multi Frame Generation) 기능을 도입하여 기존 렌더링된 한 프레임당 최대 3개의 추가 프레임을 AI로 생성합니다. 이를 통해 최대 8배의 성능 향상을 이루며, 4K 해상도에서도 240fps의 완벽한 레이 트레이싱 게임 경험을 제공합니다. -
업스케일링 및 효율성:
DLSS 4는 낮은 해상도로 렌더링된 이미지를 AI를 통해 고해상도로 업스케일링하여 프레임 레이트를 크게 개선합니다. 렌더링해야 할 픽셀 수를 약 6%로 줄이며, AI가 나머지를 생성하여 리소스 효율을 극대화합니다. -
지원 게임:
Cyberpunk 2077, Alan Wake 2를 포함한 75개 이상의 게임과 애플리케이션에서 DLSS 4를 지원합니다.

AI와 GPU의 융합
-
AI 연산 통합:
Blackwell GPU는 셰이더 코어와 텐서 코어를 활용하여 뉴럴 네트워크 연산을 지원하며, 복잡한 AI 알고리즘과 그래픽 렌더링을 실시간으로 처리할 수 있는 성능을 제공합니다. -
Neural Compression 기술:
Blackwell은 Neural Texture Compression과 Neural Material Shading 기술을 통해 고품질 텍스처와 머티리얼을 효율적으로 생성 및 압축합니다. 이러한 기술은 그래픽 디테일과 현실감을 극대화하며, 그래픽 리소스를 절약하는 데 기여합니다.
GeForce RTX 50 시리즈 주요 모델
-
NVIDIA의 차세대 GPU 라인업으로, 고성능 AI 연산 및 그래픽 렌더링을 지원하는 Blackwell 아키텍처를 기반으로 설계되었습니다.
- 출시 일정: 2024년 1월부터 순차적으로 출시될 예정.
- RTX 5090: 최고의 AI 및 그래픽 성능을 제공하며, 하이엔드 사용자를 위한 선택지로 자리 잡을 전망.

😵 새 RTX 5070 시리즈는 RTX 4090시리즈의 Performance라고 ㄷㄷ

RTX 5070 Laptop

- 가격: $1,299부터 시작.
- 성능: RTX 4090급 성능을 노트북에서도 구현.
- 기술: AI 기반 DLSS를 통해 전력 효율과 휴대성을 극대화.

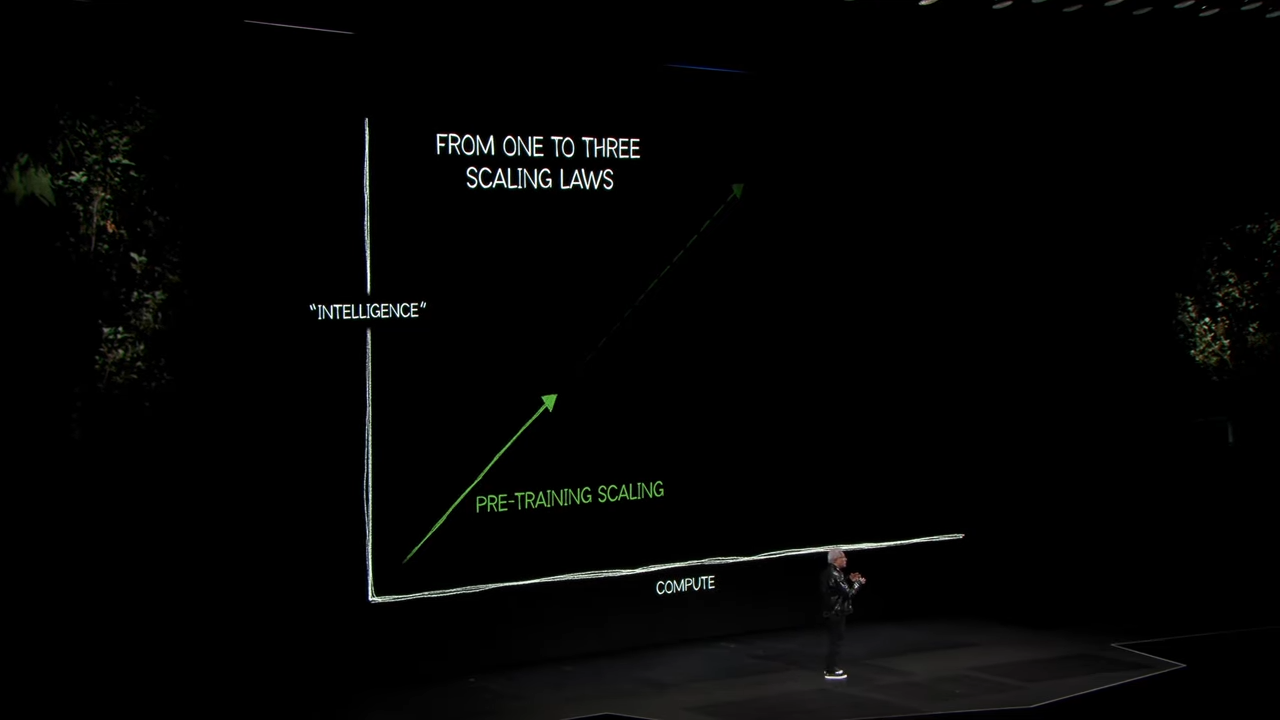
4. 인공지능의 확장과 스케일링 법칙
젠슨 황은 AI 발전을 위한 세 가지 주요 스케일링 법칙을 설명했습니다.
-
프리트레이닝(Pre-training):
- 대규모 데이터를 학습하여 모델 생성.
- 텍스트, 이미지, 소리를 포함한 다양한 데이터 형태 처리 가능.
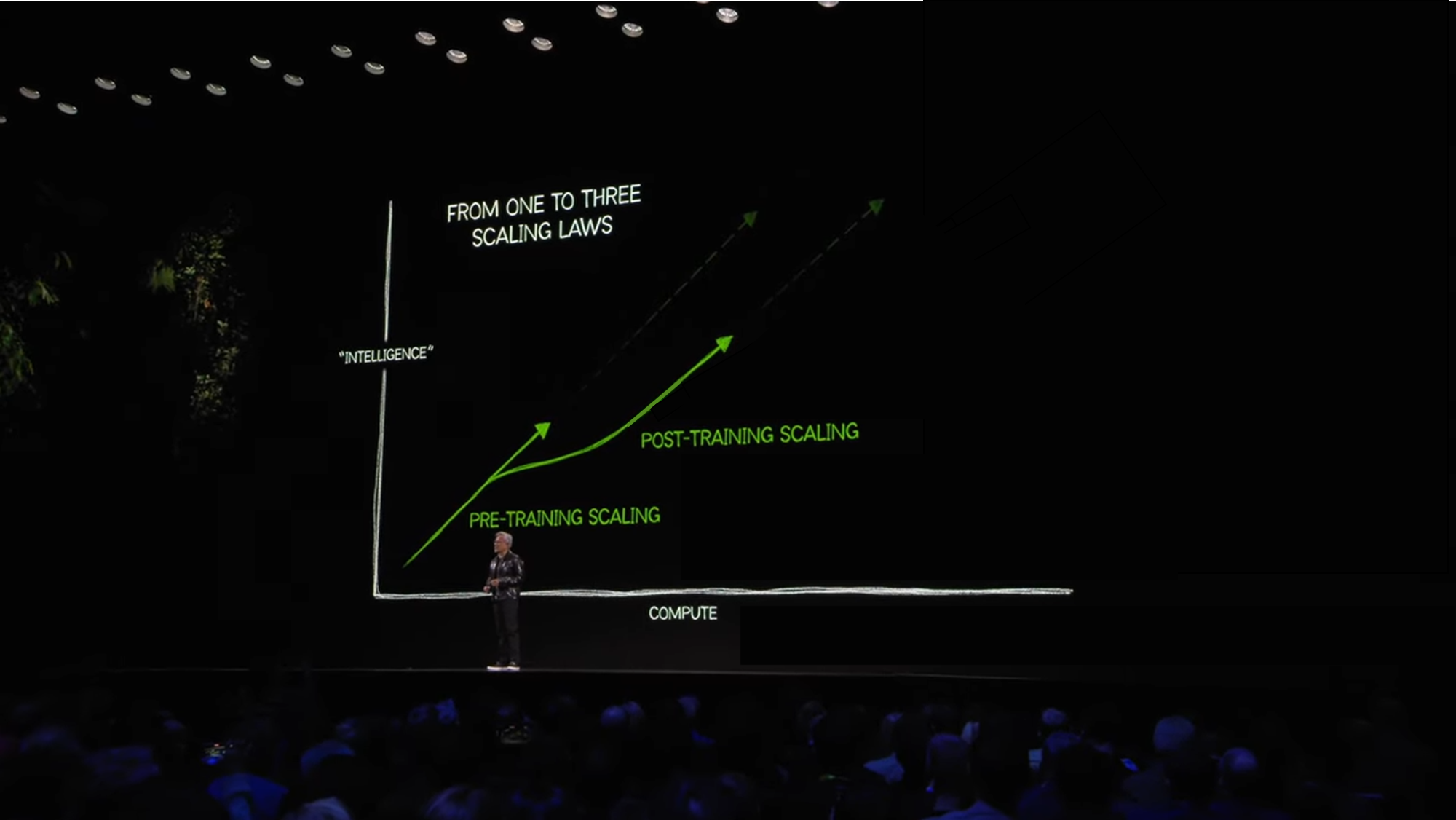
-
포스트트레이닝(Post-training):
- 강화 학습(RLHF, 인간 피드백 강화학습)과 인간 피드백을 통해 특정 도메인에서 성능을 세분화하고 정교화.
- 예: 인공 데이터 생성, 수학 문제 해결 능력 향상.
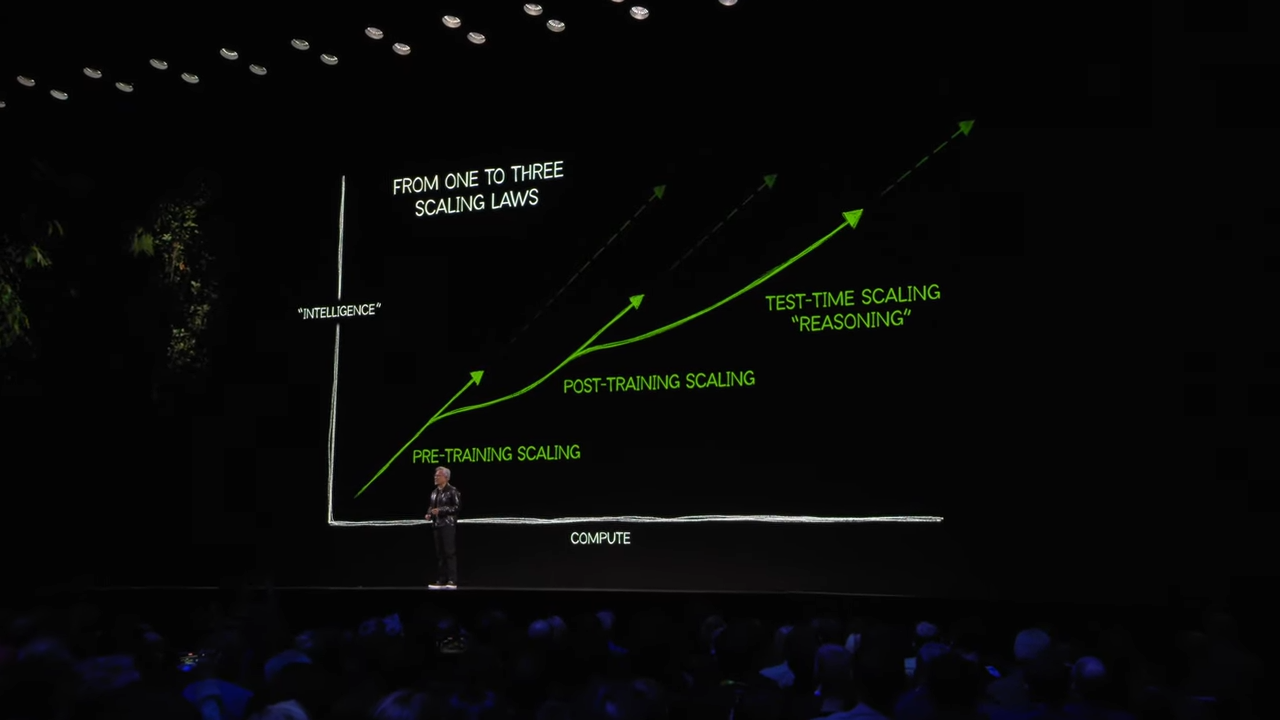
-
테스트타임 스케일링(Test-time Scaling):
- AI가 실시간으로 문제 해결에 필요한 자원을 동적으로 할당.
- 문제를 단계별로 나누고 여러 아이디어를 생성 및 평가.
- 예. Agentic AI, 사고(Reasoning) -> 추론 연산량 폭발적 증가
5. NVLink와 데이터 센터용 Blackwell 아키텍처
NVLink 기술과 데이터 센터 연결
- NVLink 72는 NVIDIA의 고속 GPU 연결 기술로, Blackwell GPU 72개를 하나로 연결하여 1.4 ExaFLOPS(AI 연산 성능)을 제공합니다.
- 이를 통해 대규모 AI 모델 학습 및 추론에 필요한 방대한 연산량을 처리할 수 있습니다.

- NVIDIA의 NVLink 72 시스템은 72개의 Blackwell GPU를 연결하여 하나의 거대한 칩처럼 작동하도록 설계되었습니다.
- 이 구조는 1.4 ExaFLOPS의 AI 연산 성능과 14TB의 HBM 메모리, 1.2PB/s 메모리 대역폭을 제공하며, 현재 세계에서 가장 강력한 데이터 센터 솔루션 중 하나로 자리 잡고 있습니다.

💬 NVLink 72의 하드웨어 특징
- 구성:
- 36개의 Grace CPU
- 72개의 Blackwell GPU
- 576개의 메모리 칩, 총 14TB의 HBM 메모리
- 1.2PB/s의 메모리 대역폭
- 물리적 규모:
- 무게 1.5톤, 약 60만 개의 부품
- 2마일(약 3.2km)의 구리 케이블로 연결
- 전 세계 45개 공장에서 생산 및 조립.

포토타임 가지신 젠슨 황 CEO님 ㅋㅋㅋ (aka Captin NVIDIA)
"하나의 거대한 칩"의 비유
-
위에서 말한 것처럼 NVLink 72는 "전체 시스템이 하나의 거대한 칩처럼 작동하도록 설계"되었으며, 이를 통해 대규모 AI 모델 학습 및 추론에 필요한 연산 성능과 확장성을 극대화할 수 있습니다.
-
만약 실제로 이러한 크기의 칩을 단일로 제작한다면 생산 수율과 제조 공정의 어려움이 커지지만, NVIDIA는 NVLink와 HBM 메모리를 활용하여 이를 여러 GPU와 메모리를 결합한 하나의 모듈처럼 구성했습니다.
💬 NVLink 72 기술적 구현의 특징
- NVLink Spine 구조
- GPU 간 초고속 데이터 전송을 위한 중앙 연결 구조
- 모든 GPU가 마치 단일 칩처럼 작동하도록 설계
- 대규모 AI 모델 학습과 추론에 최적화
- 시스템 통합
- 여러 GPU와 메모리를 하나의 통합 시스템으로 구성
- 단일 칩 제작의 한계를 분산 시스템으로 해결
- 고속 데이터 전송과 처리를 위한 최적화된 설계
- 확장성과 성능
- 대규모 AI 워크로드 처리에 최적화
- GPU 간 지연 시간 최소화
- 시스템 전체가 단일 칩처럼 효율적으로 작동
6. 엔비디아의 AI 에코시스템
NVIDIA는 Agentic AI의 강력한 기능과 소프트웨어 스택을 통해 다양한 AI 활용 사례를 지원하고 있습니다.

1. Agentic AI 개념
- Agentic AI는 여러 AI 모델이 협력하여 복잡한 문제를 단계별로 해결할 수 있도록 지원합니다.
- 단계적 접근: 명령 → 풀이 → 추론 → API/툴 호출 → 결과 도출.
- Test-time Scaling을 활용해 필요할 때 연산량을 유연하게 확장하여 더 나은 결과를 도출합니다.
2. NVIDIA의 소프트웨어 스택
NVIDIA가 제공하고자 하는 핵심은 엔터프라이즈 및 AI 활용 환경에서의 "Agentic AI" 생태계 구축입니다.
이를 위해 NVIDIA는 다음과 같은 요소를 제공하고 통합하고자 합니다 (3가지) :
- NVIDIA NIM (AI Microservices)
- NVIDIA NeMo
- Llama Nemotron

1) NVIDIA NIM (AI Microservices):
- AI 기능을 마이크로서비스 형태로 제공하여 언어, 시각, 음성, 애니메이션, 디지털 바이올로지 데이터를 처리합니다.
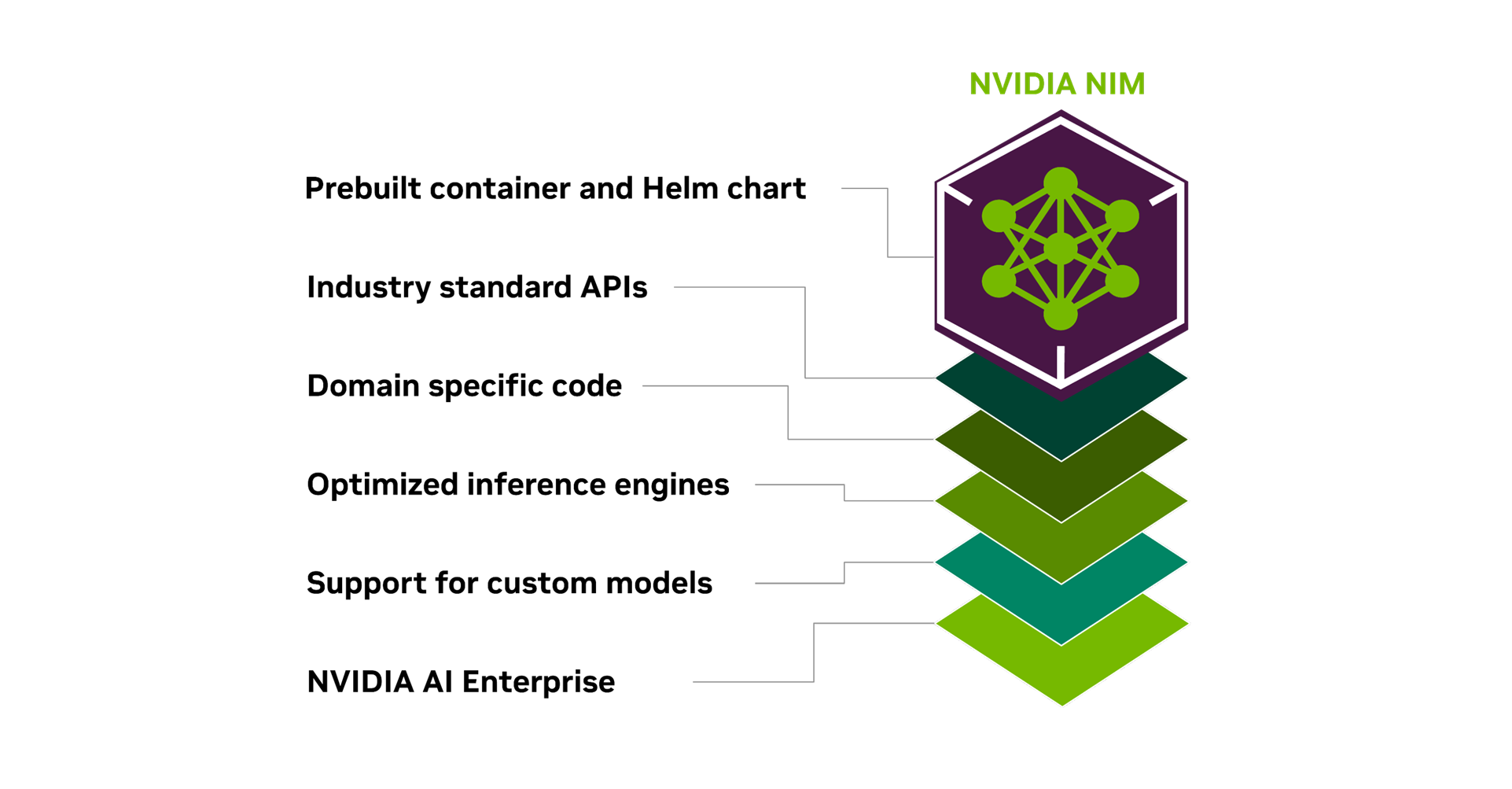
- 특징:
- 컨테이너 형태로 배포되어 클라우드와 온프레미스에서 동일한 환경에서 실행 가능.
- 140개 이상의 사전 학습된 모델 포함, 사용자 맞춤형 통합 가능.
- 주요 활용 분야:
- 정보 검색
- AI 안전성(AI Safety)
- 디지털 휴먼(Digital Human) 생성
- 생물학적 시뮬레이션 및 시각적 콘텐츠 생성
2) NVIDIA NeMo:
- 기업 맞춤형 AI 에이전트(디지털 직원)를 온보딩, 훈련, 검증, 가드레일 설정까지 지원하는 플랫폼입니다.
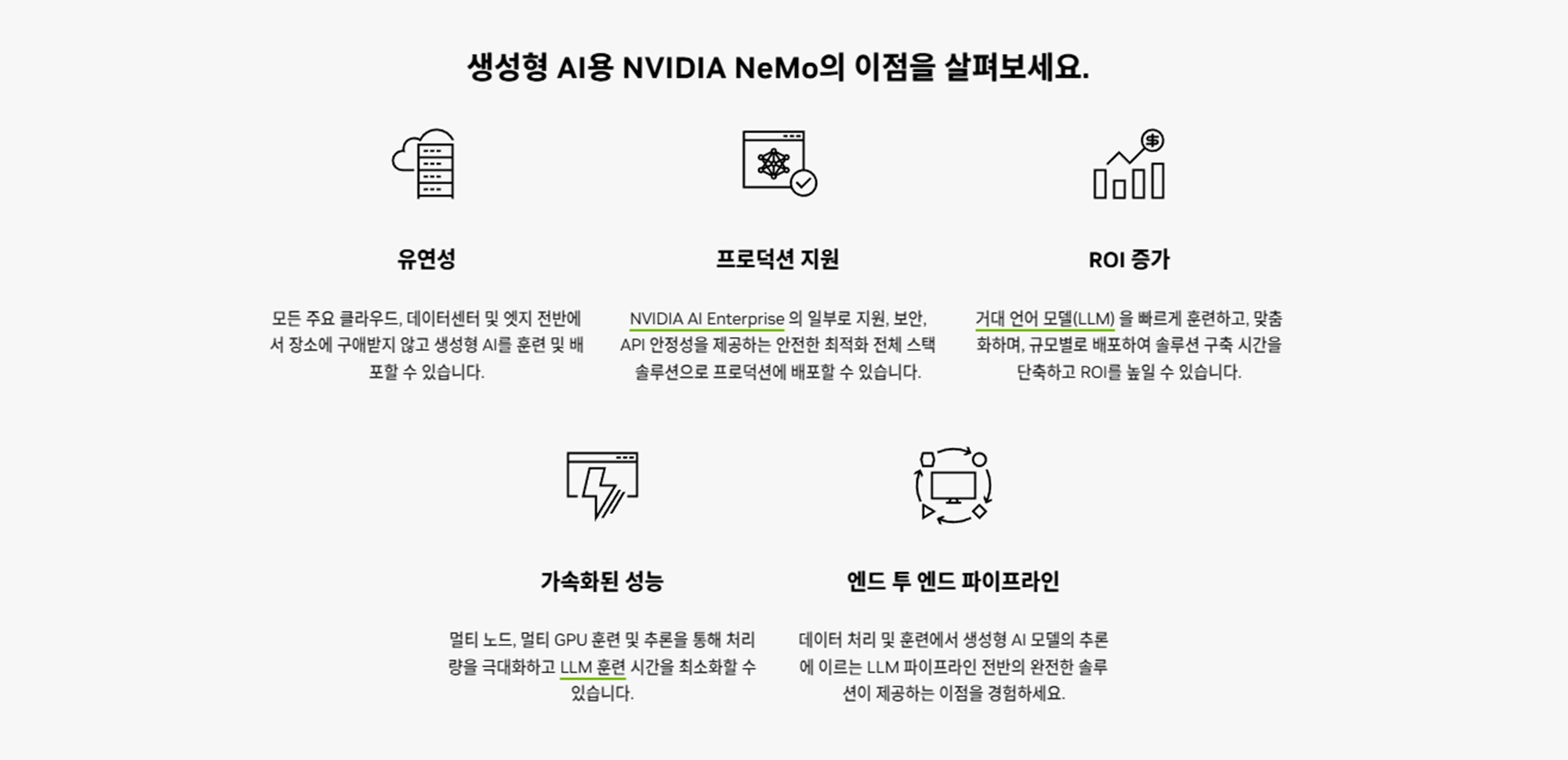
- 세부 기능:
- 기업 고유의 언어, 프로세스, 정책을 반영한 세분화 및 미세 조정.
- 복잡한 비즈니스 업무 프로세스를 자동화 및 최적화.
3) NVIDIA AI Blueprints:
- NVIDIA AI Blueprints는 Agentic AI를 보다 쉽게 배포하고 활용할 수 있도록 설계된 템플릿입니다.
- 다양한 AI 애플리케이션의 베스트 프랙티스를 포함.
- 빠른 개발과 배포를 가능하게 하여 기업의 AI 도입 장벽을 낮춤.

🦾 Llama Nemotron 모델:
- Meta의 Llama 3.1 기반으로 엔터프라이즈 환경에 최적화된 언어 모델 라인업을 제공합니다.
- 다양한 크기의 모델:
Nano(소형): 빠른 응답성과 저지연성을 필요로 하는 PC 및 엣지 장치에 적합.Super(중형): 성능과 효율성을 모두 만족하는 모델.Ultra(대형): 데이터 센터 수준의 높은 정확도와 처리 성능을 위한 모델.- 특징:
- 멀티 리더보드 1위 수준의 성능 제공.
- 기업 환경에 최적화된 파인튜닝 및 효율적 배포 지원.

💻 NVIDIA의 에코시스템과 파트너십
- NVIDIA는 다양한 산업과 IT 생태계에서 Agentic AI의 확산과 실질적인 활용을 위해 폭넓은 파트너십을 구축하고 있습니다.
- 이를 통해 기업과 조직이 AI 기반의 도구와 플랫폼을 더 쉽게 통합하고 활용할 수 있도록 돕고 있습니다.

3. AI on Windows (WSL2)
NVIDIA의 발표에서 Windows WSL2(Windows Subsystem for Linux 2) 기반으로 AI를 실행하고 활용하는 방법에 대해 설명하며, 이를 통해 Windows PC가 차세대 AI 플랫폼으로 자리 잡는 비전을 제시했습니다.
(참고) WSL(Windows Subsystem for Linux)은 Windows에서 Linux 환경을 실행할 수 있게 해주는 Microsoft의 핵심 기술입니다.
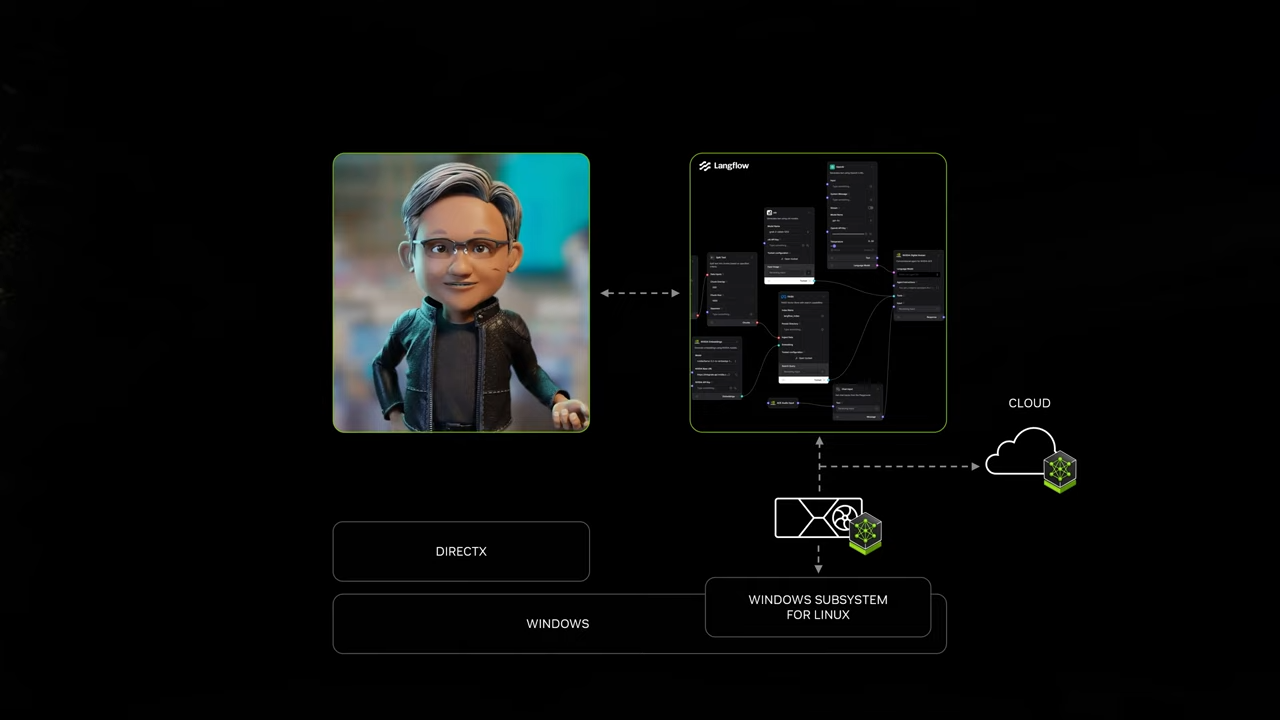
3.1. Windows WSL2와 NVIDIA AI 스택 통합
- CUDA 지원:
- WSL2는 NVIDIA CUDA를 기본적으로 지원하여, NVIDIA의 모든 AI 소프트웨어 스택(NVIDIA NIM, NeMo, AI Blueprints)을 실행할 수 있도록 최적화되었습니다.
- 클라우드 네이티브 환경 지원:
- PC(Windows)에서도 클라우드 네이티브 방식의 AI 애플리케이션 실행 가능.
- 쿠버네티스(Kubernetes) 및 클라우드 네이티브 API를 활용하여 AI 모델을 로컬 및 클라우드에서 원활히 배포 및 실행.
3.2. AI PC 시대를 위한 준비
- AI API의 확장:
- 과거 멀티미디어 API(3D, 사운드, 비디오)에 더해, AI API가 PC 환경에서 중요한 역할을 할 것으로 예상.
- Generative AI API: 텍스트, 그래픽, 사운드 등 생성형 AI를 위한 API 지원.
- PC OEM 파트너십:
- NVIDIA는 전 세계 주요 PC 제조사와 협력하여 RTX 50 시리즈 + WSL2 + NVIDIA AI 스택이 결합된 AI PC를 제공할 예정.
- 수백만 대의 Windows PC를 AI에 적합하도록 준비하고, 이를 통해 AI를 더욱 대중화할 계획.
7. 물리적 AI (Physical AI)와 'Cosmos' 플랫폼
Physical AI 개념
- Physical AI는 텍스트 기반의 입력 대신, 센서 데이터(예: 자율주행 차량이나 로봇의 센서 데이터)와 행동(Action) 토큰을 활용하여 물리적 세계와 상호작용할 수 있는 AI 시스템을 의미합니다.
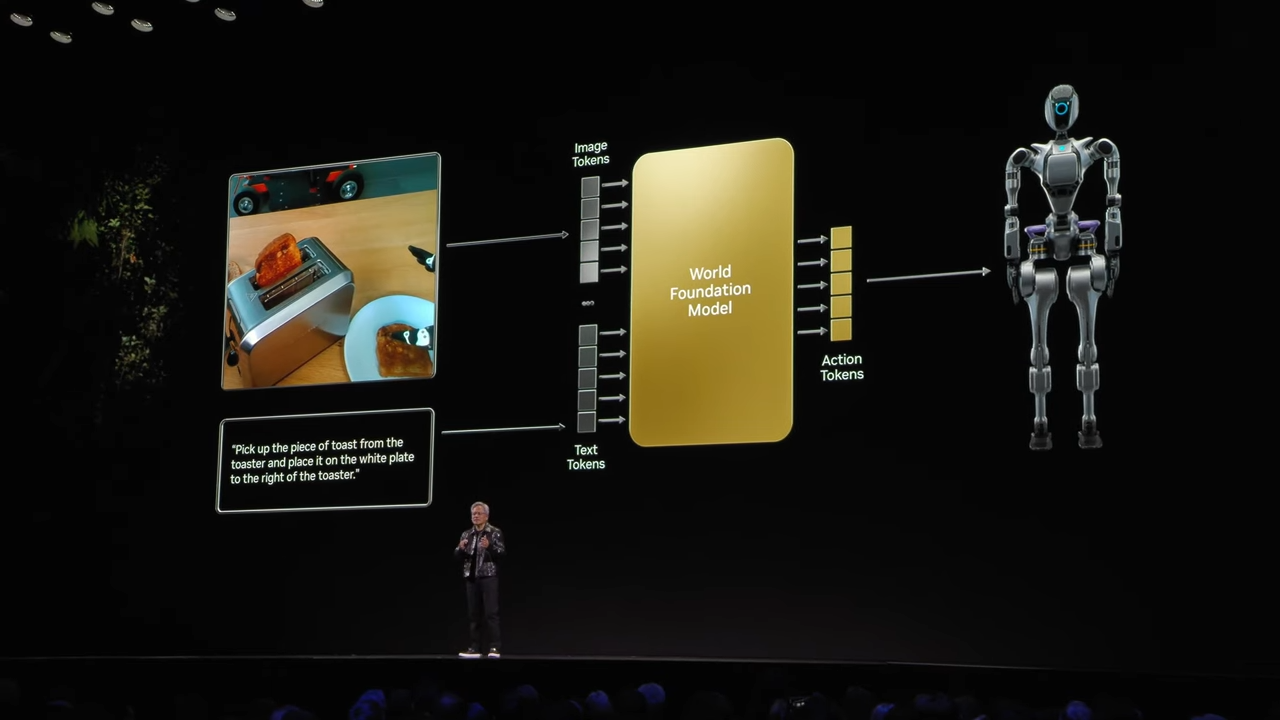
-
입력(Input):
- 로봇, 자율주행 차량 등에서 생성된 센서 데이터 및 행동 데이터.
- 기존 텍스트 기반 입력과 달리 물리적 세계의 데이터를 직접 활용.
-
출력(Output):
- 로봇과 같은 물리적 시스템이 수행할 구체적 행동(Action) 토큰을 생성.
- 예: "토스터에서 빵을 꺼내 접시에 올려놔" 같은 물리적 명령 수행.
-
(Preliminaries, 사전 조건) 물리 세계의 이해:
- AI가 중력, 마찰, 관성 같은 물리 법칙을 이해하고, 이를 기반으로 현실적이고 예측 가능한 동작을 수행.
- 객체 영속성(Object Permanence): 물체가 시야에서 사라져도 존재한다고 인식.
- 원인과 결과: 물체를 밀거나 떨어뜨릴 때 발생할 수 있는 결과를 예측.
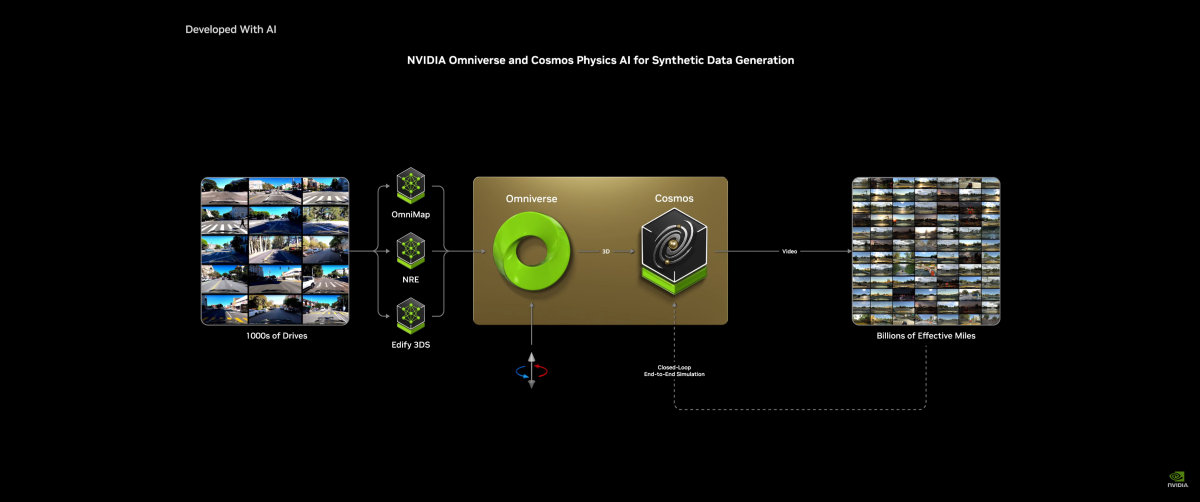
'Cosmos': 세계 기반 모델 (World Foundation Model)

NVIDIA의 Cosmos는 물리적 AI(Physical AI)를 위해 개발된 세계 기반 모델 플랫폼으로, 물리적 세계의 데이터를 시뮬레이션하고 이를 AI 학습 및 테스트에 활용할 수 있도록 설계되었습니다. Cosmos는 AI 모델의 성능과 물리적 환경의 상호작용을 극대화하는 데 초점을 맞추고 있으며, 물리 세계에서 데이터 수집의 높은 비용 문제를 해결하기 위해 합성 데이터 생성과 실시간 토큰 생성을 지원합니다.
Cosmos 모델의 주요 특징
-
WFM (World Foundation Model):
- 텍스트, 이미지, 비디오를 입력받아 물리적으로 일관된 시뮬레이션 데이터를 생성.
- 2000만 시간 분량의 비디오 데이터를 학습하여 중력, 마찰, 관성 등 물리적 법칙과 환경 조건을 이해.
- AI가 객체 영속성(Object Permanence) 및 물리적 행동 패턴을 학습할 수 있도록 지원.

-
고급 합성 데이터 생성:
- Cosmos는 현실적인 환경 조건(조명, 날씨, 시간대 등)을 고려한 고품질 시뮬레이션 데이터를 생성.
- 자율주행, 로봇공학 등에서 중요한 엣지 케이스(극단적인 시나리오) 데이터를 효율적으로 생성.

-
실시간 생성 및 다중 센서 뷰:
- 실시간 토큰 생성을 통해 AI 모델이 여러 미래 시나리오를 시뮬레이션하고 최적의 경로를 선택하도록 지원.
- 다양한 센서 데이터를 통합하여 멀티 센서 뷰 기반의 데이터 생성.

-
Comos 내부 World Foundation Models:
- Auto-regressive Model:
- 실시간 물리적 데이터 생성에 사용.
- 연속적인 데이터 생성이 필요한 경우 활용.
- Auto-regressive Model:
- Diffusion-based Model:
- 고품질 이미지와 영상을 생성하여 물리적 세계의 디테일한 표현 가능.
- Video Tokenizer:
- 이미지와 비디오를 텍스트 토큰화하여 물리적 행동의 의미를 명확히 전달.
- Video Processing & Curation Pipeline:
- 페타바이트급의 대규모 비디오 데이터를 처리하기 위한 고속 파이프라인 활용.
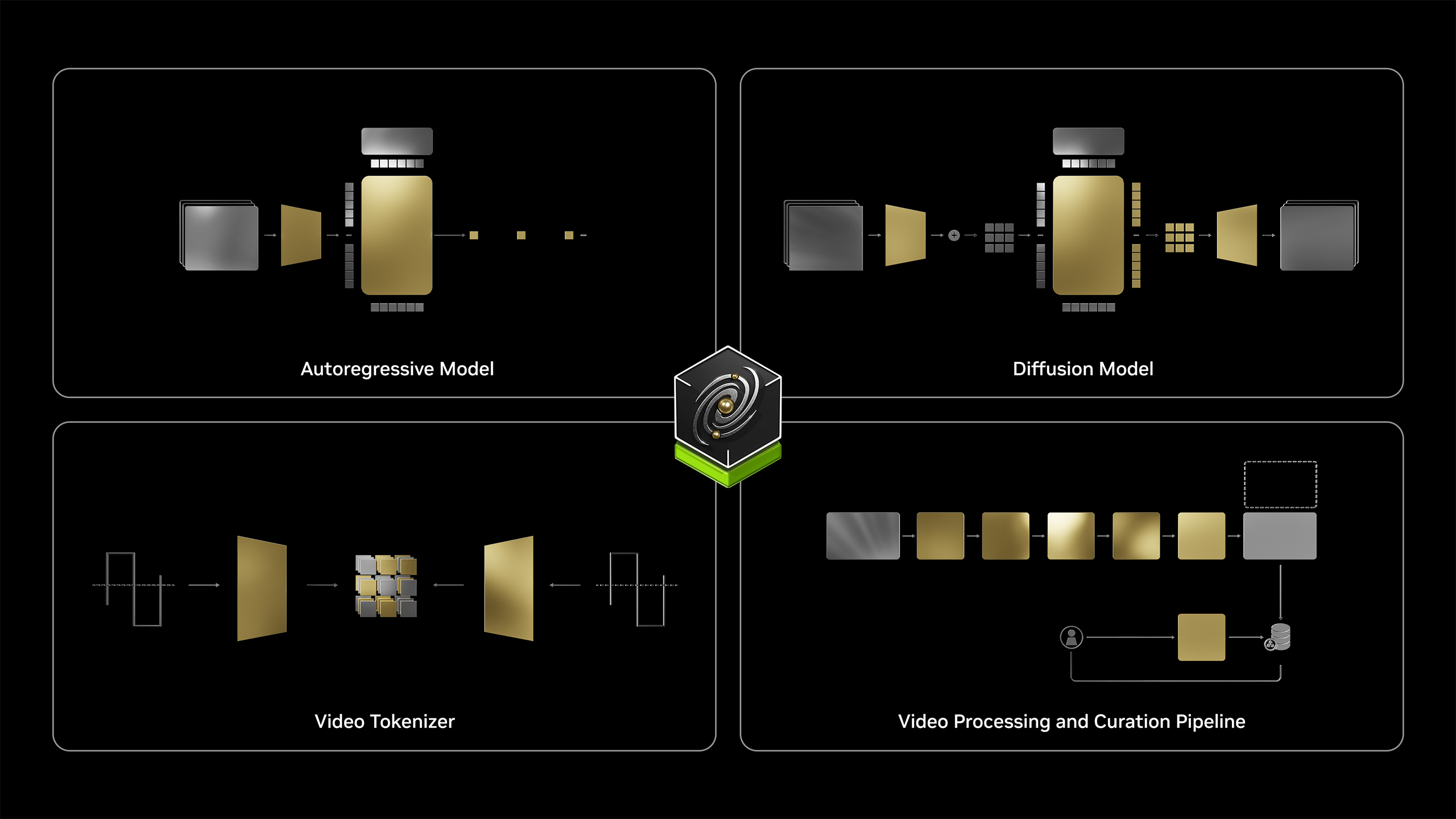
- 페타바이트급의 대규모 비디오 데이터를 처리하기 위한 고속 파이프라인 활용.
Omniverse와 Cosmos의 결합
-
Omniverse:
-
NVIDIA의 실시간 3D 시뮬레이션 엔진인 Omniverse와 Cosmos를 결합하여, 가상 환경에서 물리적 세계의 정확한 시뮬레이션을 가능하게 합니다.

-
Ground Truth 데이터 생성:
- Cosmos는 AI 모델에 필요한 고품질의 그라운드 트루스 데이터를 생성하여 로봇 및 AI 시스템의 정확도를 향상.

-
-
멀티버스 시뮬레이션:
- Cosmos와 Omniverse는 다양한 시나리오에서 AI를 검증할 수 있는 Multiverse Playground를 제공합니다.
- 로봇의 물리적 행동을 디지털로 시뮬레이션하며 실제 환경에 적용하기 전 검증 및 최적화 가능.

8. 로봇틱스, 디지털 트윈 및 자율 주행
젠슨황은 NVIDIA Robotics 3 Computer Solution을 제시합니다.
- 이 솔루션은 NVIDIA의
DGX,Omniverse with Cosmos,AGX세 가지 컴퓨팅 플랫폼을 활용하여, AI 모델 학습부터 시뮬레이션 및 배포까지 포괄적인 프로세스를 지원합니다.
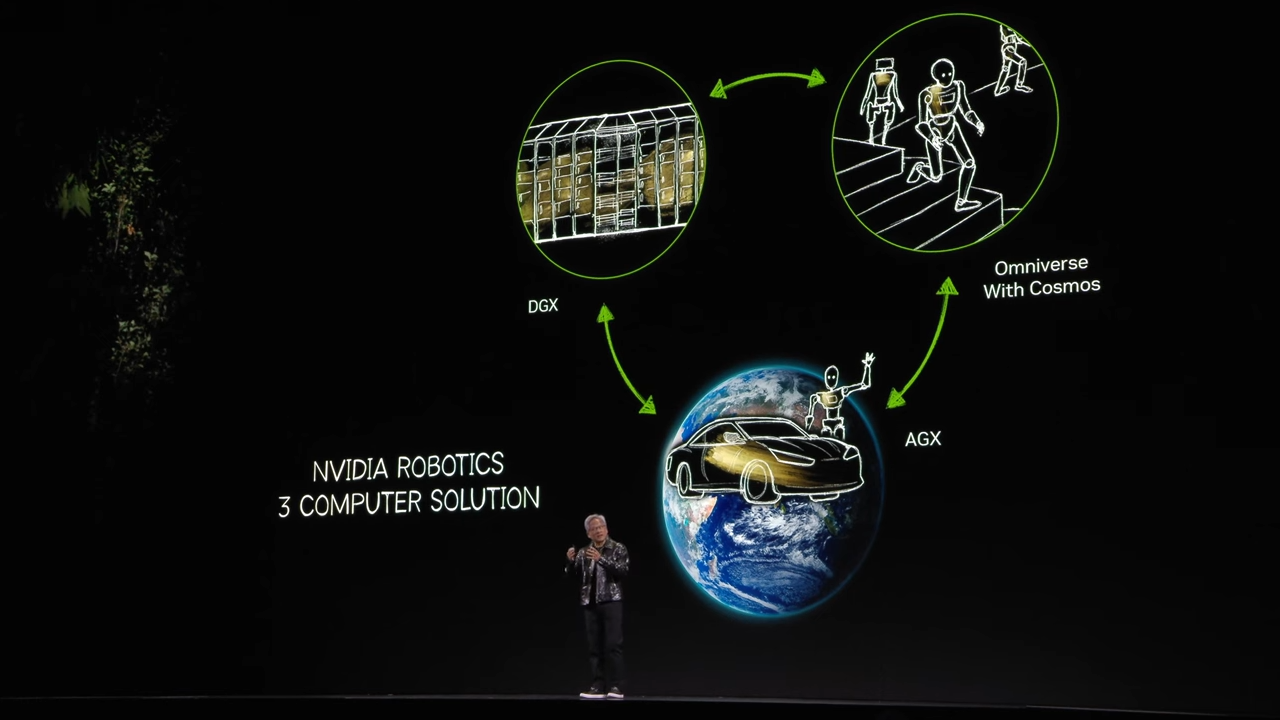
- DGX (데이터 센터 컴퓨팅):
- 목적: AI 모델 훈련.
- 기능: NVIDIA DGX 시스템은 대규모 데이터세트를 활용해 AI 모델을 훈련합니다.
- 역할:
- 물리적 세계의 데이터를 기반으로 학습된 AI 모델을 생성.
- 데이터센터 환경에서 모델 훈련과 파인튜닝을 수행.

- Omniverse with Cosmos (시뮬레이션 및 테스트 환경):
- 목적: 물리적 AI와 로봇의 동작 시뮬레이션.
- 기능:
- NVIDIA Omniverse와 Cosmos 플랫폼을 결합하여 물리적 시뮬레이션 데이터를 생성.
- 현실 세계와 유사한 조건에서 AI 모델을 검증하고 최적화.
- 활용:
- 로봇과 자율주행차의 행동을 예측하고 성능을 테스트.
- 조명, 날씨, 지형 등 다양한 환경 조건을 시뮬레이션.
- AGX (엣지 컴퓨팅):
- 목적: 실시간 AI 추론 및 배포.
- 기능:
- NVIDIA AGX는 차량이나 로봇에 직접 탑재되어 AI 모델을 실행.
- 현장에서 실시간 데이터 처리 및 의사결정을 지원.
- 활용:
- 자율주행차의 센서 데이터 처리 및 실시간 경로 계획.
- 로봇 공학에서의 복잡한 작업 수행.
🔀 솔루션 워크플로우
- DGX → Omniverse with Cosmos:
- 훈련된 AI 모델을 Omniverse 및 Cosmos 환경에서 시뮬레이션하여 성능 검증.
- 다양한 시나리오를 테스트하고 모델의 안정성을 높임.
- Omniverse with Cosmos → AGX:
- 시뮬레이션에서 검증된 AI 모델을 엣지 디바이스로 배포.
- 차량, 로봇 등의 실제 환경에서 AI 모델이 실시간으로 동작.
💡 사례 소개 : KION & Accenture: 디지털 트윈을 활용한 창고 관리 혁신 사례
KION과Accenture는 NVIDIA와 협력하여 창고 관리 및 물류 운영을 혁신하기 위한 디지털 트윈 솔루션을 개발했습니다.- 이 솔루션은 NVIDIA의 Omniverse와 Cosmos 플랫폼을 활용하여 창고 환경을 디지털로 복제하고, 다양한 시뮬레이션 및 최적화를 통해 운영 효율성을 극대화하는 것을 목표로 했습니다.
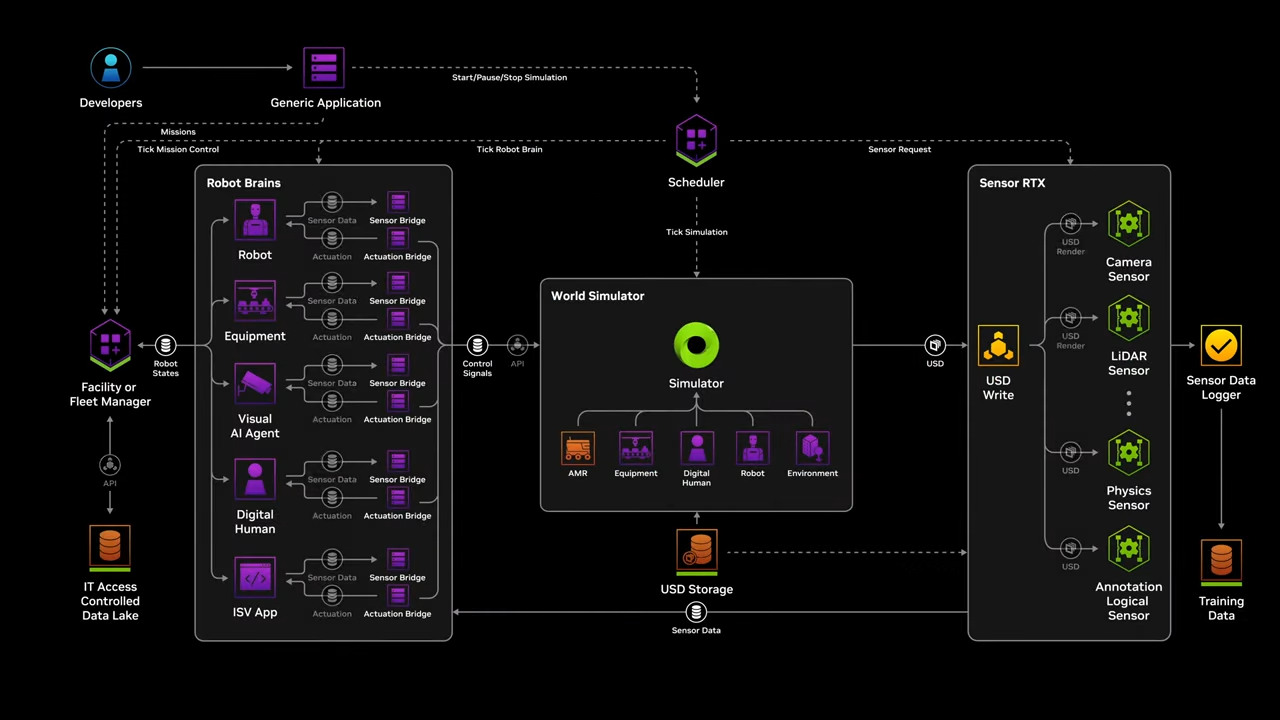
- KION과 Accenture는 디지털 트윈을 통해 다양한 산업 시나리오에 솔루션을 확장할 예정이며, 이를 통해 더 많은 공장과 창고에서 스마트 팩토리를 구현하고자 합니다.
🔍 (심화) 디지털 트윈 구축 과정
- (1) Omniverse를 활용한 창고 환경의 디지털화
- CAD, 포인트 클라우드 데이터, 생성된 3D 데이터를 기반으로 창고의 실제 환경을 디지털로 복제.
- 창고 내부의 로봇, 물류 흐름, 선반 배치 등을 디지털 트윈 모델로 구현.
- (2) Cosmos를 통한 시뮬레이션 및 최적화
- Cosmos 플랫폼에서 다양한 물리적 환경과 물류 시나리오를 시뮬레이션.
- 날씨, 수요 변동, 경로 최적화와 같은 실제 상황의 변화에 따른 시뮬레이션 수행.
- 예측 가능한 물류 문제를 식별하고 최적화된 운영 방안을 도출.
- (3) 운영 효율성 분석
- 작업자의 동선, 로봇 경로, 물류 흐름 등을 분석하여 효율성을 높이는 시뮬레이션 실행.
- KPI(핵심 성과 지표) 측정을 통해 잠재적인 병목 현상을 제거하고 생산성을 향상.

자율주행차 산업

⚡ Thor 프로세서: 범용 로봇 프로세서
- NVIDIA의 Thor 프로세서는 자율주행차와 범용 로봇의 핵심 프로세서로 설계되었습니다. 이는 차량과 로봇에 필요한 방대한 센서 데이터를 처리하고 AI 기반 의사결정을 수행할 수 있도록 강력한 성능과 효율성을 제공합니다.

주요 특징:
- 성능:
- Orin 대비 20배 향상된 성능.
- 통합 설계:
- CPU와 GPU가 통합되어 단일 칩으로 높은 컴퓨팅 효율성 제공.
- 센서 데이터 처리:
- 12개의 카메라, 9개의 레이더, 1개의 LiDAR, 12개의 초음파 센서를 포함한 센서 데이터 처리 가능.
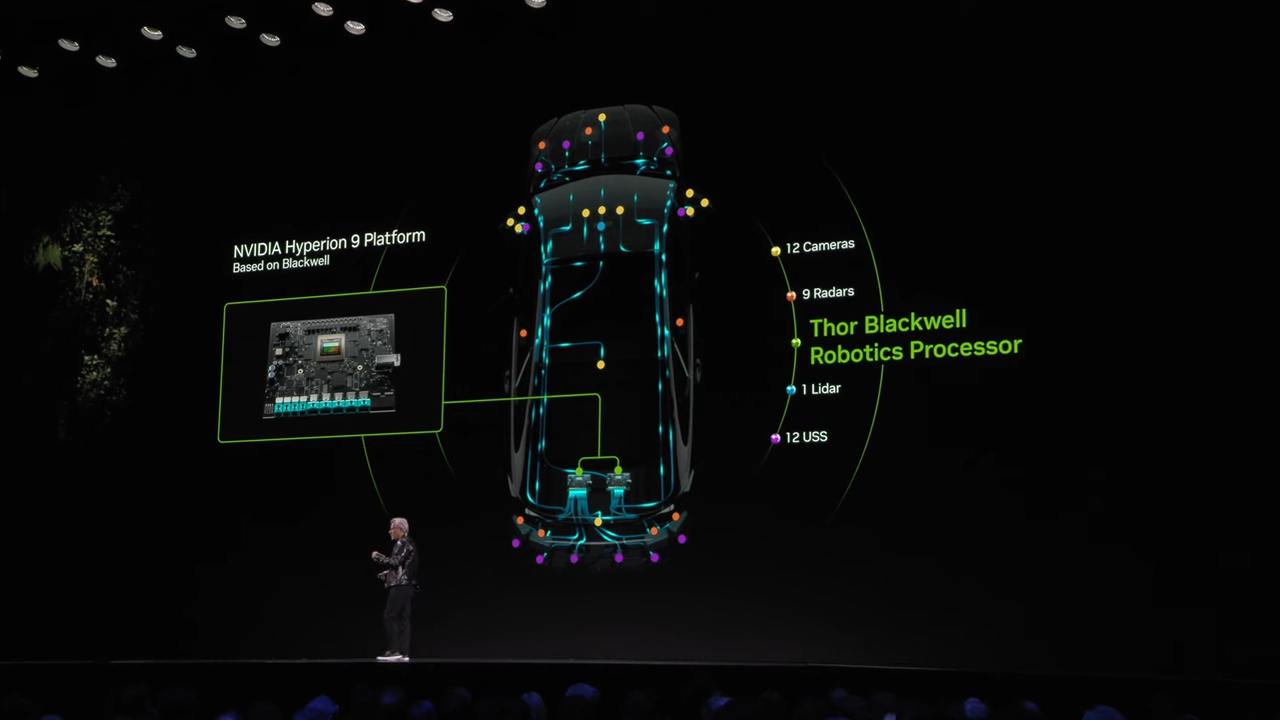
- 12개의 카메라, 9개의 레이더, 1개의 LiDAR, 12개의 초음파 센서를 포함한 센서 데이터 처리 가능.
- AI 모델 학습 및 추론:
- Transformer 모델을 활용해 실시간 경로 예측 및 복잡한 의사결정을 지원.
- 안전성:
- ISO 26262 ASIL-D 인증을 획득하여 차량 및 로봇의 안전 기준 충족.

- ISO 26262 ASIL-D 인증을 획득하여 차량 및 로봇의 안전 기준 충족.
활용 분야:
- 자율주행차: NVIDIA Drive Hyperion 9 플랫폼에서 핵심 컴퓨팅 역할 수행.
- 범용 로봇: 제조 및 물류 로봇, 서비스 로봇의 주요 AI 프로세서로 활용.

🌳 NVIDIA Isaac Groot: 로봇 학습 및 개발의 핵심 플랫폼
- Isaac Groot는 물리적 AI 기반 로봇의 학습과 개발을 지원하기 위한 NVIDIA의 포괄적 플랫폼입니다.
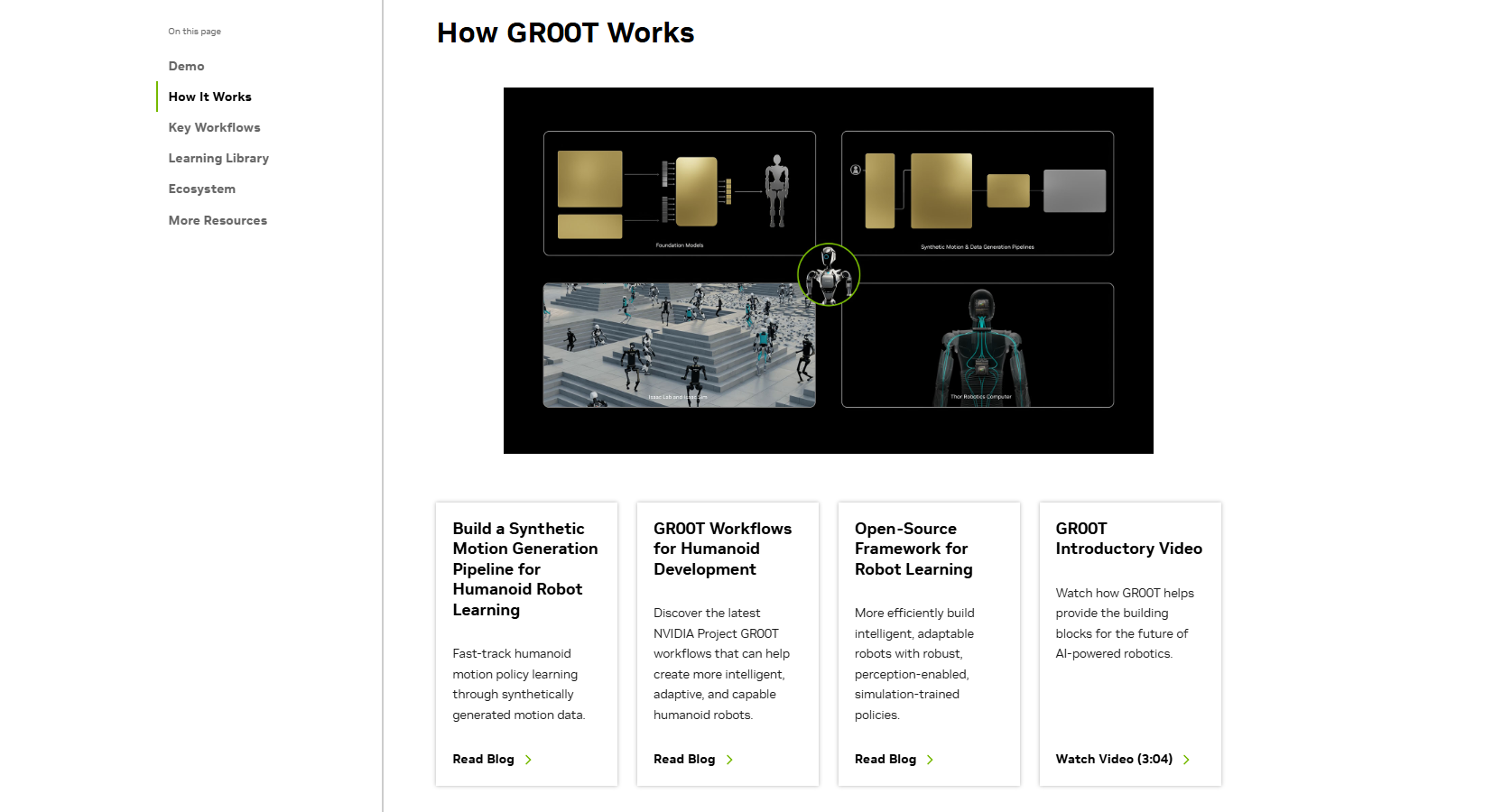
주요 기능:
-
로봇 데이터 증강:
- 소수의 인간 시연 데이터를 기반으로 대규모 합성 데이터를 생성.
- Omniverse와 Cosmos를 활용해 물리적으로 기반이 된 시뮬레이션 데이터를 제공.
- 다양한 환경과 시나리오에서 테스트 가능.
-
시뮬레이션 기반 학습:
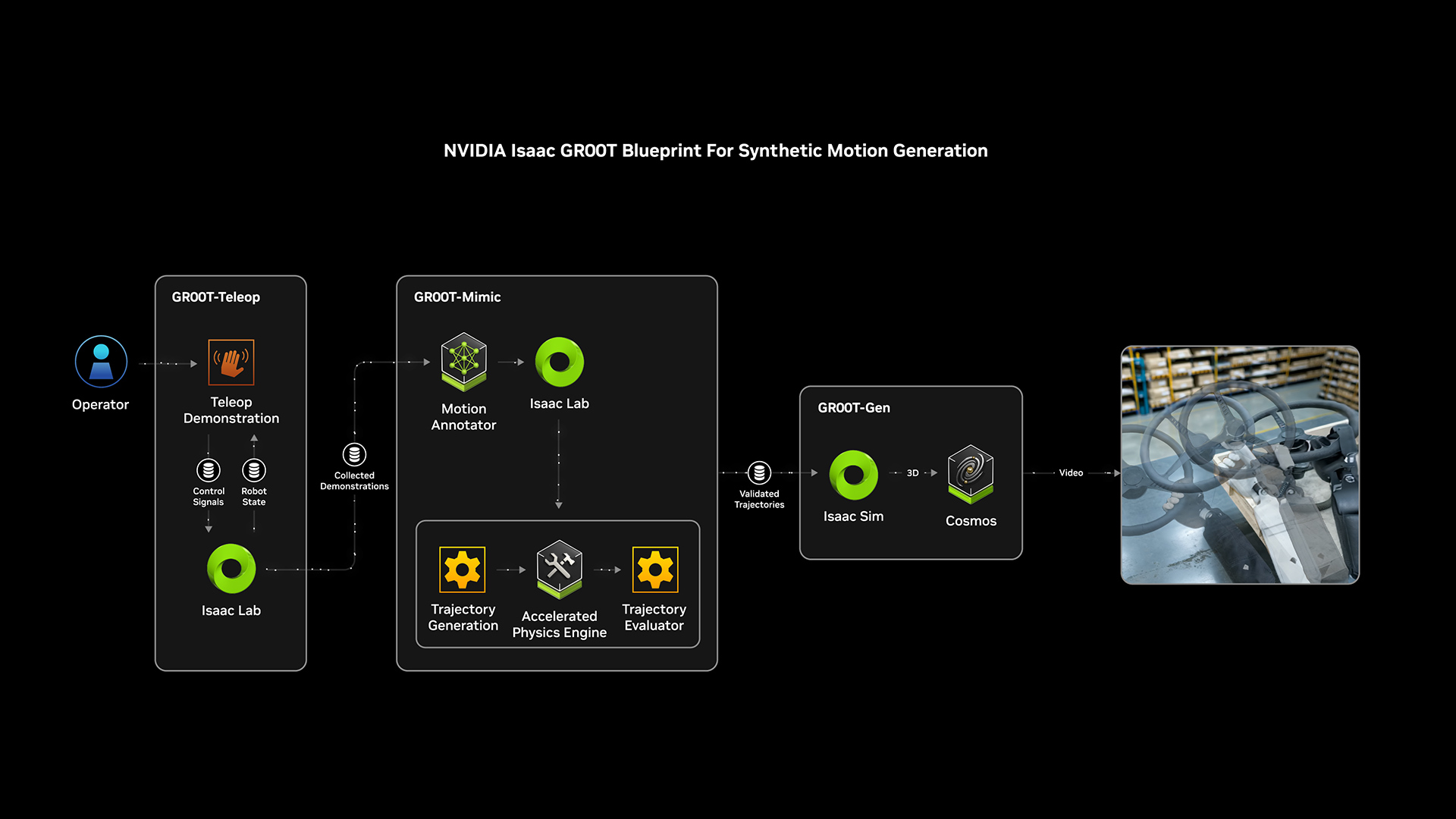
- Groot Teleop: VR을 활용해 디지털 트윈 환경에서 로봇 조작 데이터를 수집.
- Groot Mimic: 수집된 데이터를 기반으로 대규모 합성 데이터 생성.
- Groot Gen: 도메인 랜덤화 및 3D 확장을 통해 다양한 환경을 학습.
-
소프트웨어 검증:
- Omniverse와 Cosmos 기반의 멀티버스 시뮬레이션 엔진을 통해 로봇 정책을 학습.
- 소프트웨어-인-루프 테스트를 통해 실제 환경에서 검증 전에 정확도를 확인.
9. 새로운 AI 컴퓨터 – DGX와 Project Digits
🌐 DGX의 혁신

- NVIDIA의 DGX는 AI와 고성능 컴퓨팅(HPC)을 위한 최적의 플랫폼으로, 연구소 및 기업의 AI 프로젝트에 강력한 기반을 제공.
- 최신 Blackwell GPU와 Grace CPU의 조합으로, 데이터 중심 애플리케이션 및 AI 모델 학습·추론을 지원.
- 1 PFLOP FP4 AI 연산 성능으로 대규모 AI 작업을 처리.
- 20개의 ARM 코어를 통해 고성능 컴퓨팅 환경을 제공하며, AI와 데이터 중심 워크로드에 최적화.
🌐 소형 AI 슈퍼컴퓨터 ‘Digits’ (프로젝트명)

- 개인 및 중소형 기업을 겨냥한 소형 AI 컴퓨터로, 데스크톱 수준에서 고성능 AI 작업을 가능하게 설계.
- Blackwell GPU와 Grace CPU를 단일 SoC로 통합하여 크기를 획기적으로 줄임.
- NVIDIA의 모든 AI 스택(CUDA, Triton, Nemo 등)을 완벽히 지원.
- 책상 위에 놓을 수 있는 크기와 에너지 효율성을 갖추어, 일반 개발자와 중소기업의 AI 활용 장벽을 낮춤.
주요 사양 및 기능
- 128GB DDR5X 메모리: 고속 데이터 전송과 에너지 효율성 제공.
- Coherent Cache: GPU와 CPU 간 데이터 전송 최적화 및 병목현상 최소화.
- ConnectX 통합: 네트워크 및 데이터 처리 성능 강화.
- 확장성:
- NVLink와 ConnectX를 활용해 다수의 'Digits'를 클러스터로 묶어 대규모 연산 수행 가능.
- 클라우드 방식으로 데이터센터와 연결하여 HPC 환경에서 사용 가능.
활용 목표
- 2024년 5월 출시 예정으로, AI 연구소, 중소기업, 일반 개발자들이 손쉽게 접근 가능한 AI 슈퍼컴퓨터 생태계 구축.
- 데이터 분석, AI 모델 학습 및 추론, 시뮬레이션 작업에 최적화된 플랫폼으로 자리잡을 전망.
결론
엔비디아는 GPU 기술의 혁신에서 시작해 AI, 자율주행, 로봇 공학, 디지털 트윈 등 다양한 첨단 분야로의 확장을 통해 기술 리더십을 공고히 하고 있습니다. CES 2025에서 발표된 내용은 엔비디아가 AI와 물리적 세계의 융합, 디지털 트윈 기술, 자율주행, 로봇 공학 등에서 대규모 변화를 주도하며 미래를 설계하고자 하는 명확한 비전을 제시했습니다.
특히, Blackwell 아키텍처와 Cosmos 플랫폼, 그리고 Agentic AI와 같은 새로운 기술들은 AI 생태계 전반에 걸쳐 더욱 강력하고 실질적인 활용 사례를 제공할 것으로 기대됩니다. 엔비디아의 이번 발표는 단순한 기술 소개를 넘어, AI 기반의 미래를 구체화하고 실현하려는 의지를 보여준 자리였습니다.
다음 Keynote들도 이어서 정리해보겠습니다 💌
