
TL;DR
NVIDIA는 AI 연산 수요 폭증에 대응하기 위해 Vera Rubin GPU를 양산하고, Cosmos/Alpamayo로 Physical AI 시대를 열며, 반도체부터 제조까지 전 산업에 AI를 통합하는 Full Stack 전략을 추진하고 있습니다.
1️⃣ AI 패러다임의 진화
- Test-Time Scaling: AI가 답변 전에 "생각"하는 시간이 성능 향상의 새로운 축이 됨 (GPT-01 이후)
- Agentic AI: 도구 사용, 계획 수립, 시뮬레이션이 가능한 자율적 AI 시스템 부상
- Open Model: DeepSeek R1이 오픈소스도 Frontier에 도달할 수 있음을 증명, NVIDIA도 자체 오픈 모델 생태계 구축
2️⃣ Physical AI: AI가 물리 세계와 만나다
- AI가 화면을 넘어 물리 세계와 직접 상호작용하려면 중력, 관성, 인과관계 같은 "상식"을 학습해야 함
- 이를 위해 3종류의 컴퓨터 필요: Training(학습), Inference(실행), Simulation(시뮬레이션)
- Cosmos(World Foundation Model)가 합성 데이터를 생성하여 실제 데이터 부족 문제 해결
- Alpamayo: 세계 최초의 "사고하는" 자율주행 AI, Mercedes-Benz CLA에 탑재되어 2026년 출시
3️⃣ Vera Rubin: 차세대 AI 슈퍼컴퓨터
- Moore's Law 둔화로 단일 칩 성능 향상만으로는 AI 수요(모델 10배/년, 토큰 5배/년 증가)를 따라갈 수 없음
- 6개 칩 전면 재설계(Extreme Co-Design): Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, Bluefield-4, Spectrum-X
- 트랜지스터는 1.6배 증가에 불과하지만, 성능은 Inference 5배, Training 3.5배 향상
- 45°C 온수 냉각으로 데이터센터 전력 6% 절감, 전체 시스템 암호화(Confidential Computing) 지원
- 양산 돌입 발표
4️⃣ 산업 생태계 확장
- 엔터프라이즈: Palantir, ServiceNow, Snowflake 등과 Agentic AI 프레임워크 통합
- 반도체/제조: Cadence, Synopsys, Siemens와 파트너십으로 칩 설계부터 제조 라인까지 AI 적용
- 젠슨 황의 비전: "칩이 컴퓨터 안에서 설계되고, 만들어지고, 테스트된 후에야 중력을 경험하게 될 것"

두둥둥장
1. 오프닝: 플랫폼 전환의 시대
젠슨 황은 컴퓨터 산업이 10~15년 주기로 Platform Shift를 경험한다고 설명했습니다.
| 시대 | 플랫폼 |
|---|---|
| 1세대 | Mainframe |
| 2세대 | PC |
| 3세대 | Internet |
| 4세대 | Cloud |
| 5세대 | Mobile |
| 현재 | ? |

그러나 현재는 두 가지 플랫폼 전환이 동시에 일어나고 있습니다:
- AI로의 전환: 애플리케이션이 AI 위에 구축됨
- 컴퓨팅 스택 전체의 재발명: 소프트웨어 개발/실행 방식의 근본적 변화
컴퓨팅 패러다임의 변화
| 기존 | 현재 |
|---|---|
| 소프트웨어를 프로그래밍 | 소프트웨어를 학습(Train) |
| CPU에서 실행 | GPU에서 실행 |
| 사전 컴파일된 애플리케이션 | 매번 실시간으로 생성 (토큰, 픽셀) |
이로 인해 지난 10년간 구축된 약 10조 달러 규모의 컴퓨팅 인프라가 현대화되고 있으며, 매년 수천억 달러의 VC 투자와 100조 달러 규모 산업의 R&D 예산이 AI로 전환되고 있습니다.
2. 2025년 AI 발전 회고

2.1 Scaling Laws의 진화
| 연도 | 이정표 | 의의 |
|---|---|---|
| 2015 | BERT | 실질적 영향력을 가진 최초의 Language Model |
| 2017 | Transformer | 혁신적 아키텍처 등장 |
| 2022 | ChatGPT Moment | AI 가능성에 대한 대중적 각성 |
| 2023 | ChatGPT-o1 | Reasoning + Test-Time Scaling 개념 도입 |
Test-Time Scaling이란?
- Pre-training: 모델이 학습하는 단계
- Post-training: Reinforcement Learning으로 스킬 습득
- Test-Time Scaling: 추론 시점에 "생각(Thinking)"하는 단계
"You think in real time. Each one of these phases of artificial intelligence requires enormous amount of compute."
2.2 Agentic System의 부상 (2024-2025)
2024년부터 Agentic Model이 등장하여 2025년에 폭발적으로 확산되었습니다.
Agentic AI의 핵심 능력:
- Reasoning (추론)
- Research (정보 검색)
- Tool Use (도구 사용)
- Planning (계획 수립)
- Simulation (결과 시뮬레이션)
젠슨 황은 Cursor를 언급하며 "NVIDIA 내부의 소프트웨어 개발 방식을 혁신했다"고 평가했습니다.
2.3 Physical AI의 등장
AI의 종류가 다양화되었습니다:
| AI 유형 | 설명 |
|---|---|
| Large Language Model | 언어 이해 및 생성 |
| Physical AI | 자연 법칙을 이해하고 물리 세계와 상호작용 |
| AI Physics | 물리 법칙 자체를 이해하는 AI |
2.4 Open Model의 약진
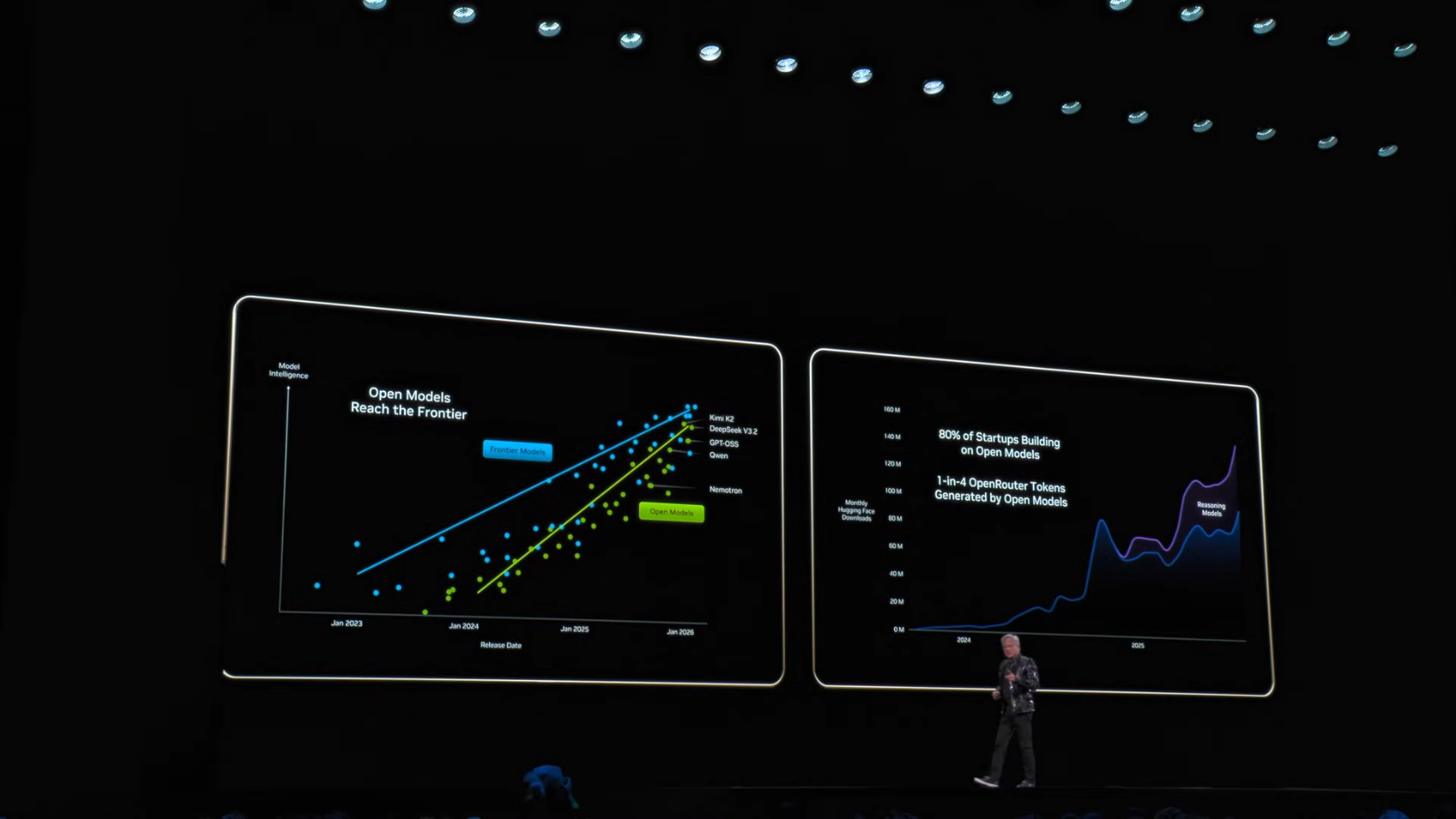
DeepSeek R1의 등장:
- 최초의 오픈소스 Reasoning 시스템
- 전 세계를 놀라게 함
- 오픈 모델도 Frontier에 도달할 수 있음을 증명
"Open models have also reached the frontier... still solidly 6 months behind the frontier models, but every single 6 months a new model is emerging."
오픈 모델 다운로드 수가 폭발적으로 증가한 이유:
- 스타트업의 AI 혁명 참여
- 대기업의 활용
- 연구자/학생의 접근
- 모든 국가가 AI에 참여하고자 함
3. NVIDIA의 오픈 모델 생태계
NVIDIA는 수십억 달러 규모의 DGX Cloud를 자체 운영하며 Frontier AI 모델을 개발하고 있습니다.
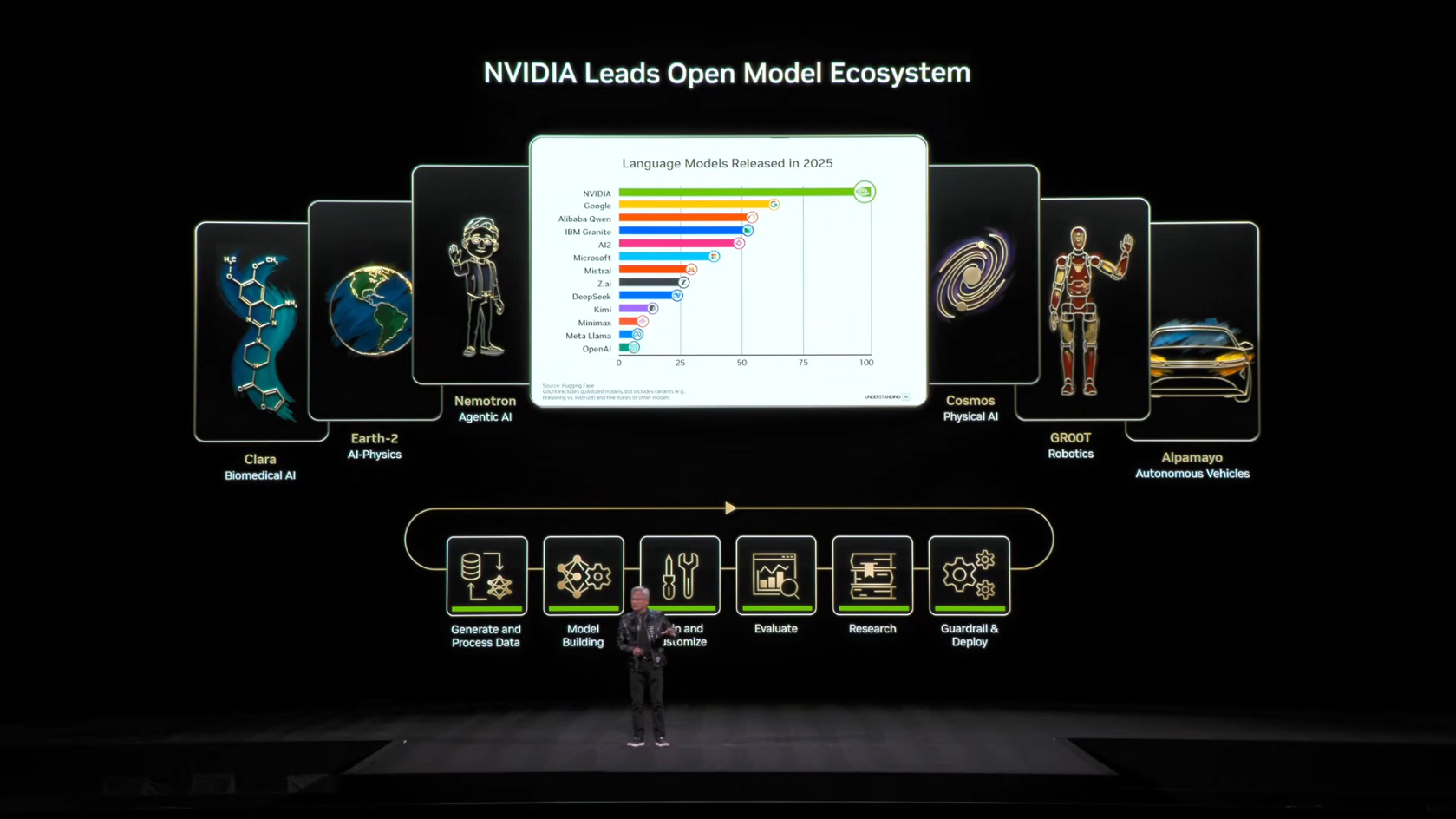
3.1 NVIDIA의 주요 오픈 모델
Agentic AI
- Nemotron — Hybrid Transformer-SSM 기반 Language Model, 빠른 추론 속도와 긴 사고 시간 지원
Physical AI / World Foundation
- Cosmos — 물리 세계의 작동 방식을 이해하는 World Foundation Model (Cosmos Reason, Cosmos Predict, Cosmos Transfer 포함)
Robotics
- Isaac GR00T — 휴머노이드 로봇용 Vision-Language-Action (VLA) 모델, 전신 제어 및 추론 지원
Autonomous Vehicles
- Alpamayo — 세계 최초 Reasoning 기반 자율주행 VLA 모델, End-to-End 학습
Healthcare / Biomedical
- Clara — 의료 영상 분석, 신약 개발 가속화 플랫폼
- Clara La-Proteina — 3D 단백질 구조를 원자 단위로 생성
- Clara CodonFM — RNA 규칙 학습, 치료제 설계 개선
Structural Biology
- OpenFold — 단백질 구조 예측
Cellular Biology
- EVO 2 — 다중 단백질 이해, 세포 표현의 시작
Climate / Weather
- Earth-2 — AI 기반 기후 디지털 트윈 플랫폼
- FourCastNet — 글로벌 대기 역학 예측 AI 모델
- CorrDiff — 생성형 AI 기반 고해상도 다운스케일링 모델 (12.5배 해상도, 1000배 빠름)
3.2 오픈소스 철학
NVIDIA의 접근법:
- 모델 오픈소스
- 학습에 사용된 데이터 오픈소스
- 파생 모델 생성 지원
- Nemo Libraries 제공
(데이터 처리 → 학습 → 평가 → Guardrail → 배포)
3.3 리더보드 성과
NVIDIA 모델들이 다양한 분야에서 리더보드 1위를 기록:
- Intelligence (지능)
- PDF Retriever/Parser (문서 이해)
- Speech Recognition (음성 인식)
- Semantic Search (의미 검색)

추가 조사 (분야 - 모델)
| 분야 | 모델명 | 벤치마크/리더보드 |
|---|---|---|
| Intelligence/Reasoning | Nemotron 3 | 코딩, 추론, 수학, 장문맥 |
| PDF/Document Parser | Nemotron Parse | ViDoRe V1, ViDoRe V2 |
| OCR/Document Intelligence | Llama Nemotron Nano VL | OCRBench V2 1위 |
| Speech Recognition | Nemotron Speech (ASR) | ASR 벤치마크 1위, 10x 속도 |
| Semantic Search/Embedding | NV-Embed-v2 | MTEB 1위 (72.31점) |
| Retrieval | NV-Retriever | MTEB Retrieval/BEIR 1위 |
4. Agentic AI의 아키텍처
4.1 Reasoning의 중요성
ChatGPT 초기의 문제점: Hallucination
- 원인: 과거는 기억하지만 현재/미래는 모름
- 해결책: Research 기반 Grounding
Reasoning 능력:
- 연구가 필요한지 판단
- 도구 사용 여부 결정
- 문제를 단계별로 분해
- 각 단계를 조합하여 새로운 문제 해결
"We can encounter a circumstance we've never seen before and break it down into circumstances and knowledge or rules that we know how to do."
4.2 Multi-Model 아키텍처
젠슨 황은 Perplexity를 언급하며 Multi-Model 접근의 혁신성을 강조했습니다.
현대 AI 애플리케이션의 특성:
- Multi-modal: 음성, 이미지, 텍스트, 비디오, 3D, 단백질 등
- Multi-model: 각 작업에 최적의 모델 사용
- Multi-cloud: 다양한 클라우드에 분산
- Hybrid-cloud: Edge + Cloud 조합
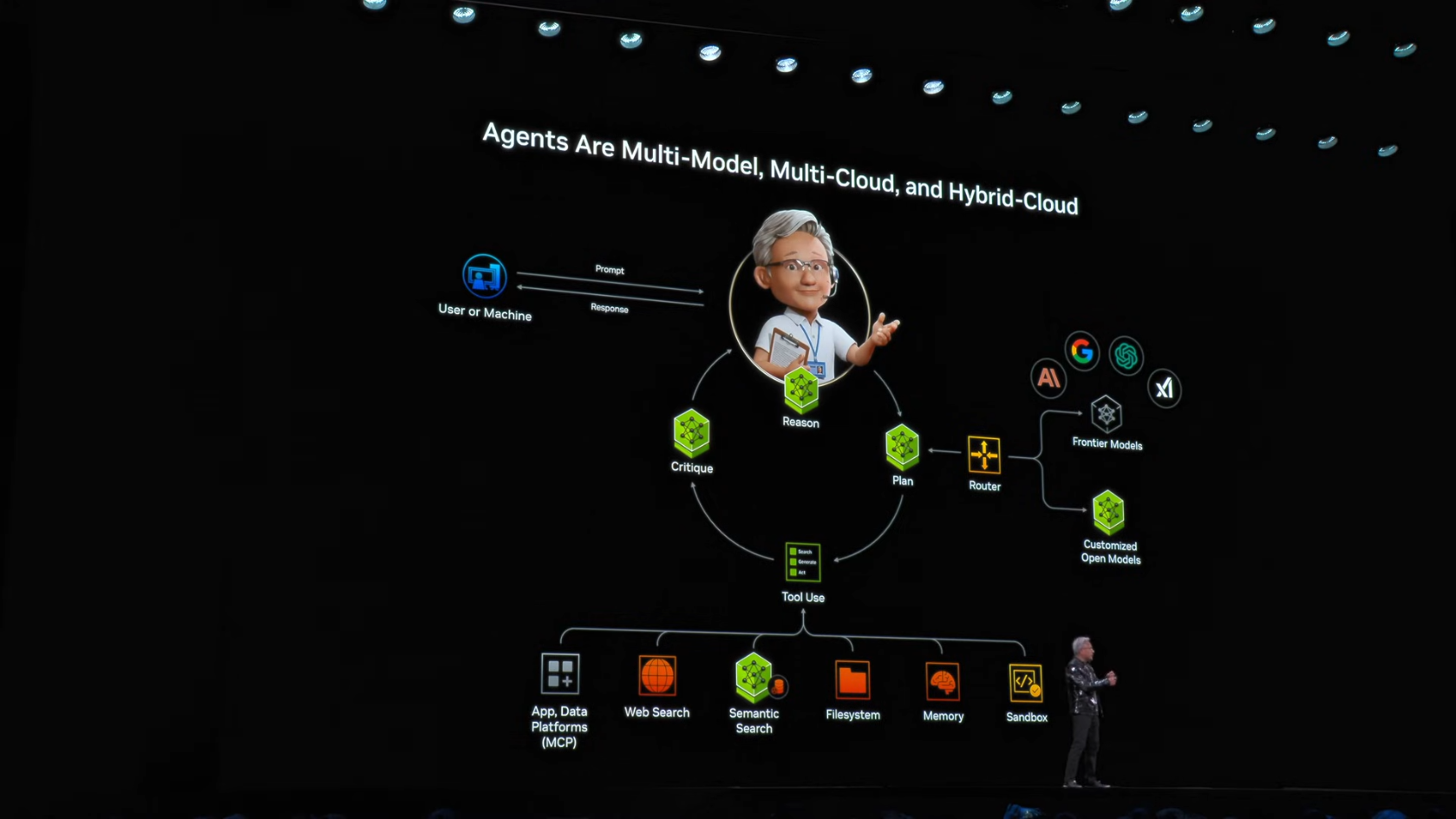
4.3 Agentic AI Framework
기본 구조:
[Frontier Model API] + [Custom Local Model]
↓
[Intent-based Router]
↓
[Tool/File/Agent 접근]핵심 장점:
1. Frontier 유지: 항상 최신 모델 활용
2. Customization: 자사 도메인 전문성 반영
3. Privacy: 민감 데이터는 로컬 처리
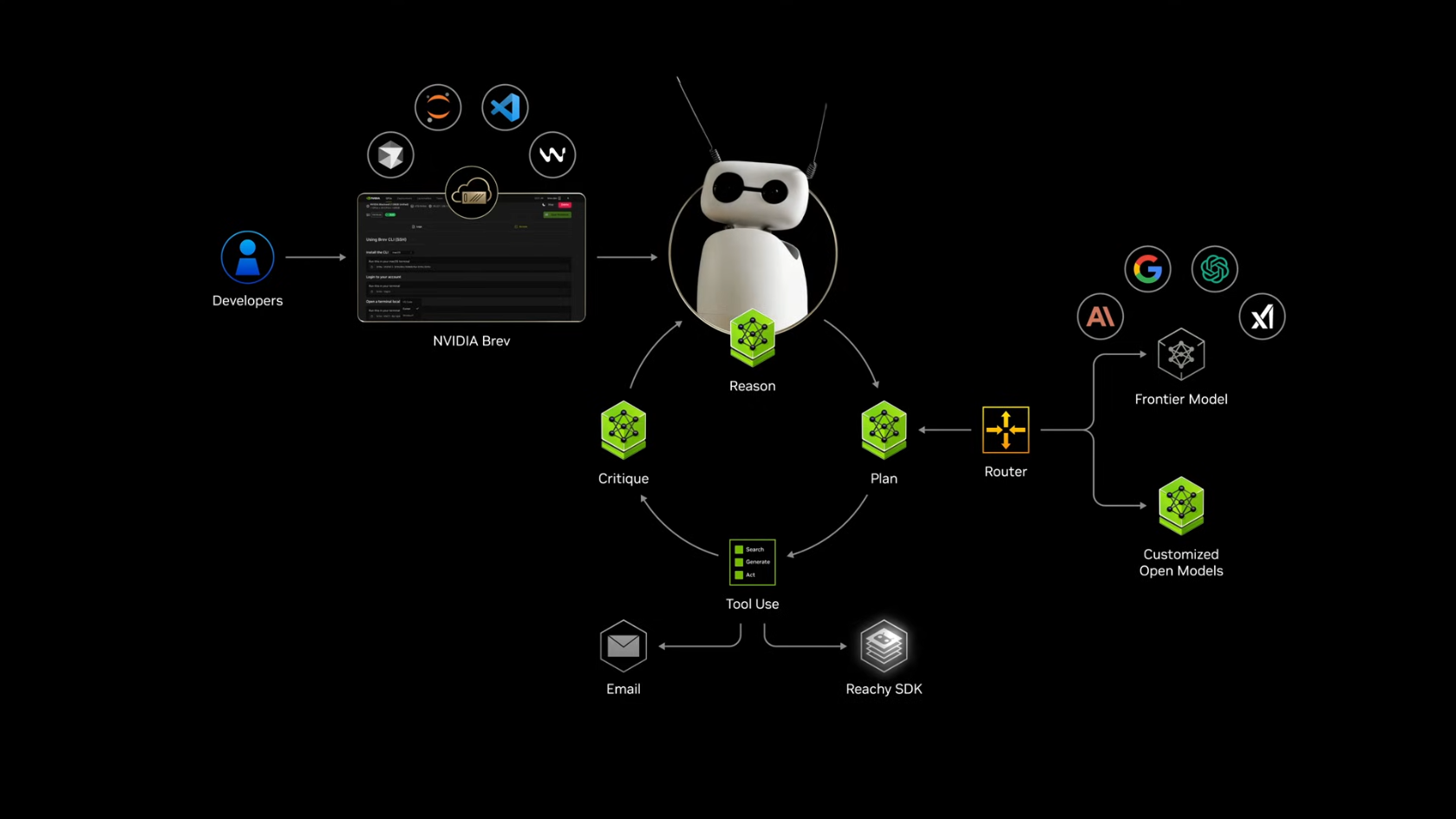
4.4 데모: 개인 AI 비서
젠슨 황은 DGX Spark를 활용한 개인 비서 데모를 시연했습니다 (영상):

-
Brev로 DGX Spark를 개인 클라우드로 전환
-
Frontier Model API로 외부 Frontier Model 선언
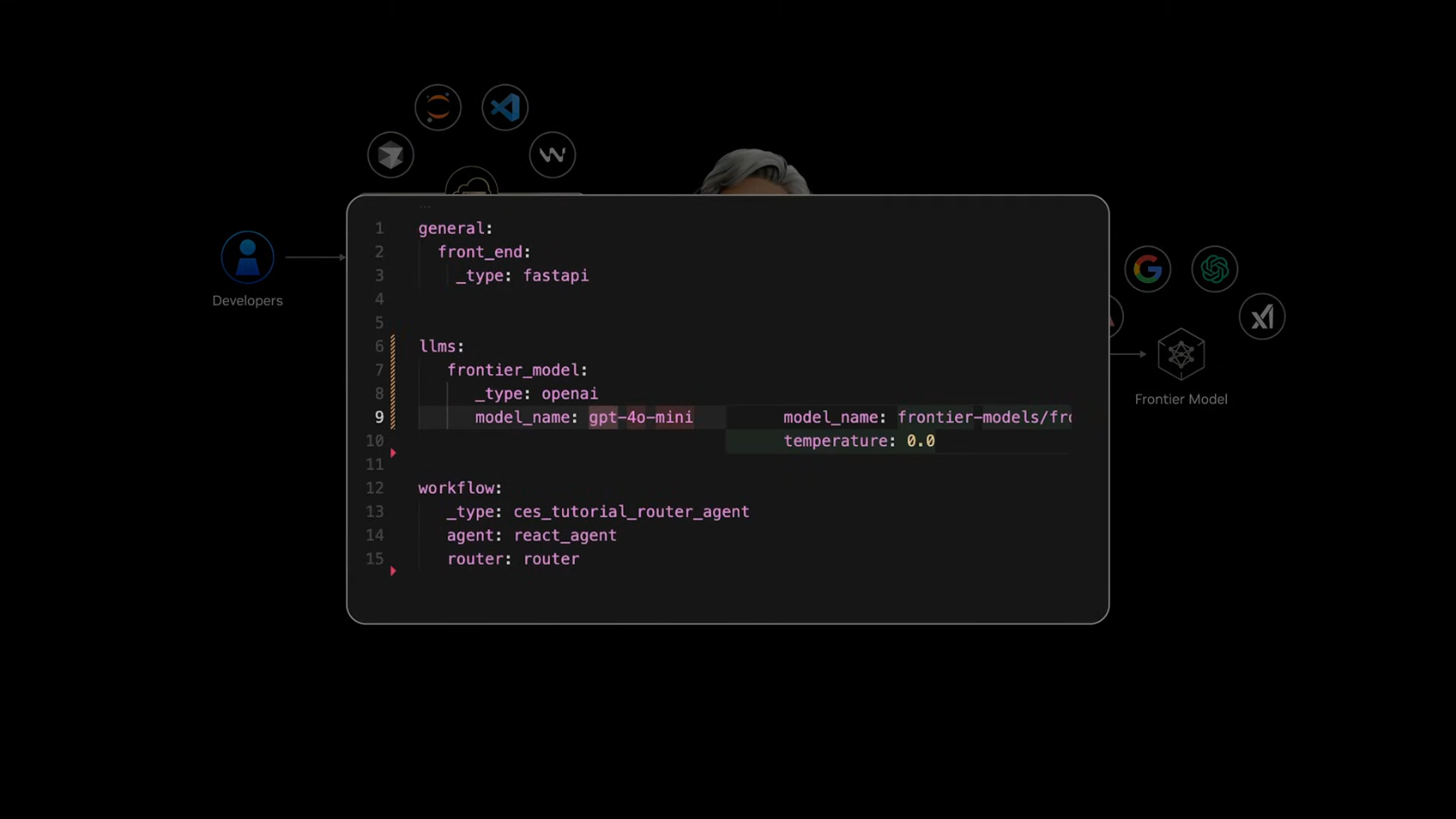
-
Customized Open Models로 로컬 모델 선언
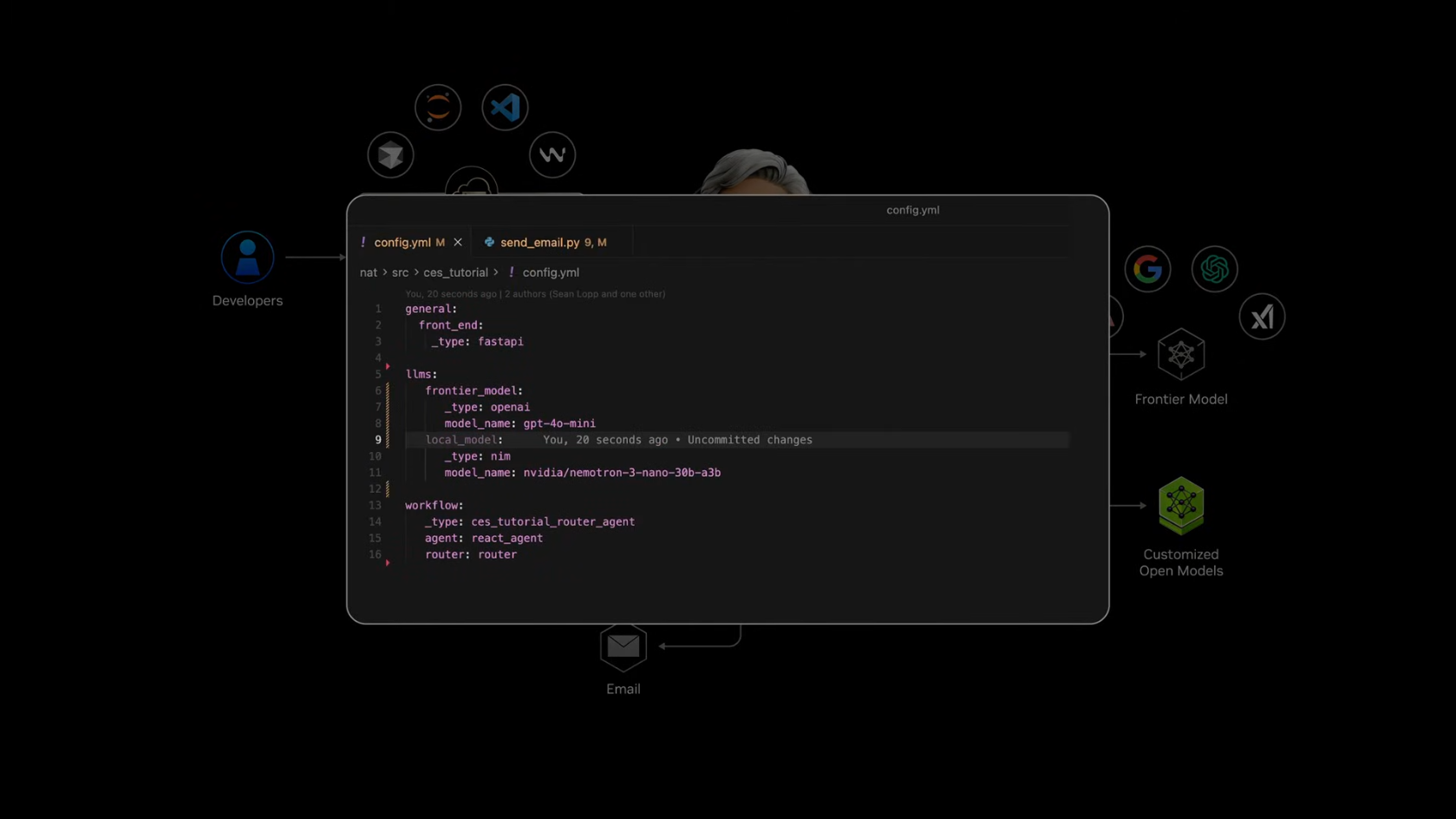
- Intent-based Router로 작업 분배
- 민감한 작업 (이메일 등) → 로컬 오픈 모델 (DGX Spark에서 실행, 데이터 외부 유출 없음)
- 복잡한 추론 작업 → Frontier Model API (Google, OpenAI, Anthropic, xAI)
-
Reachi Mini Robot 제어/연동
-
ElevenLabs 음성 API 연동
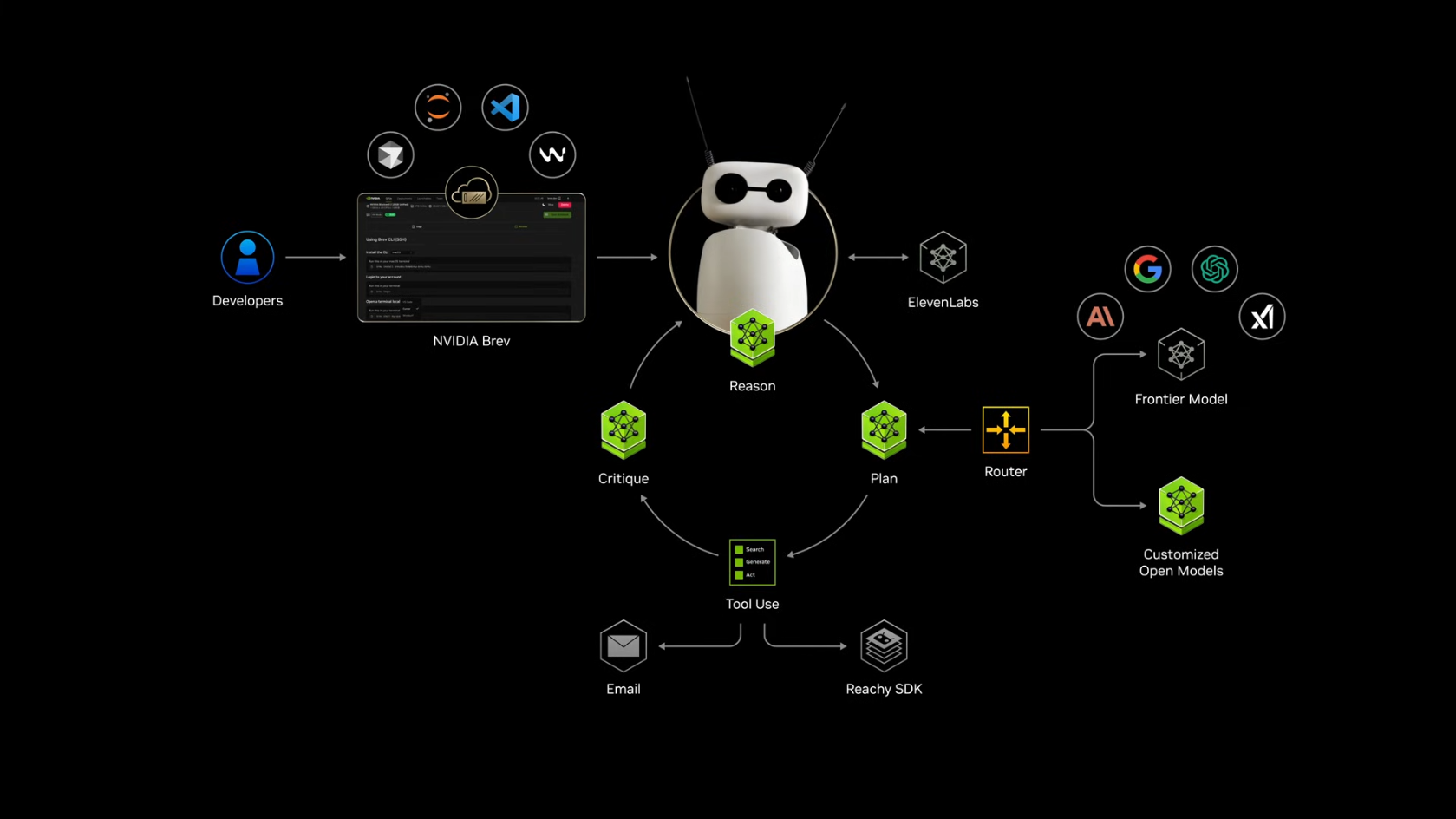
-
이미지 생성 (스케치 → 건축 렌더링)

5. 엔터프라이즈 AI 통합
주요 파트너십
NVIDIA AI가 통합된 엔터프라이즈 플랫폼:
| 파트너 | 분야 | 통합 내용 |
|---|---|---|
| Palantir | AI/Data Platform | 전체 플랫폼 가속화 |
| ServiceNow | Enterprise Service | 고객/직원 서비스 |
| Snowflake | Cloud Data | 데이터 플랫폼 |
| Code Rabbit | Developer Tools | AI 코드 리뷰 (NVIDIA 내부 사용) |
| CrowdStrike | Security | AI 위협 탐지 |
| NetApp | Data Platform | Semantic AI + Agentic 시스템 |
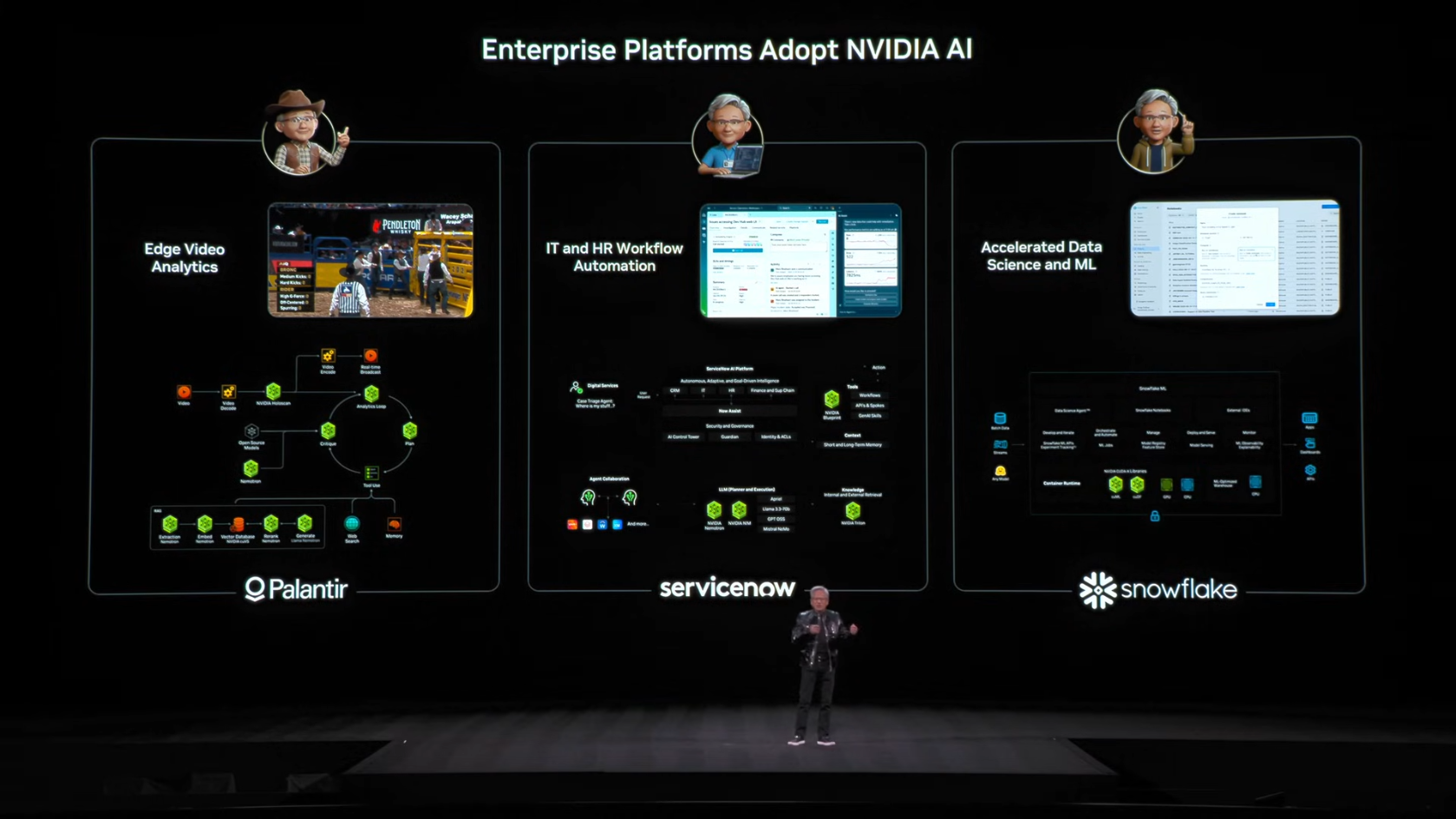
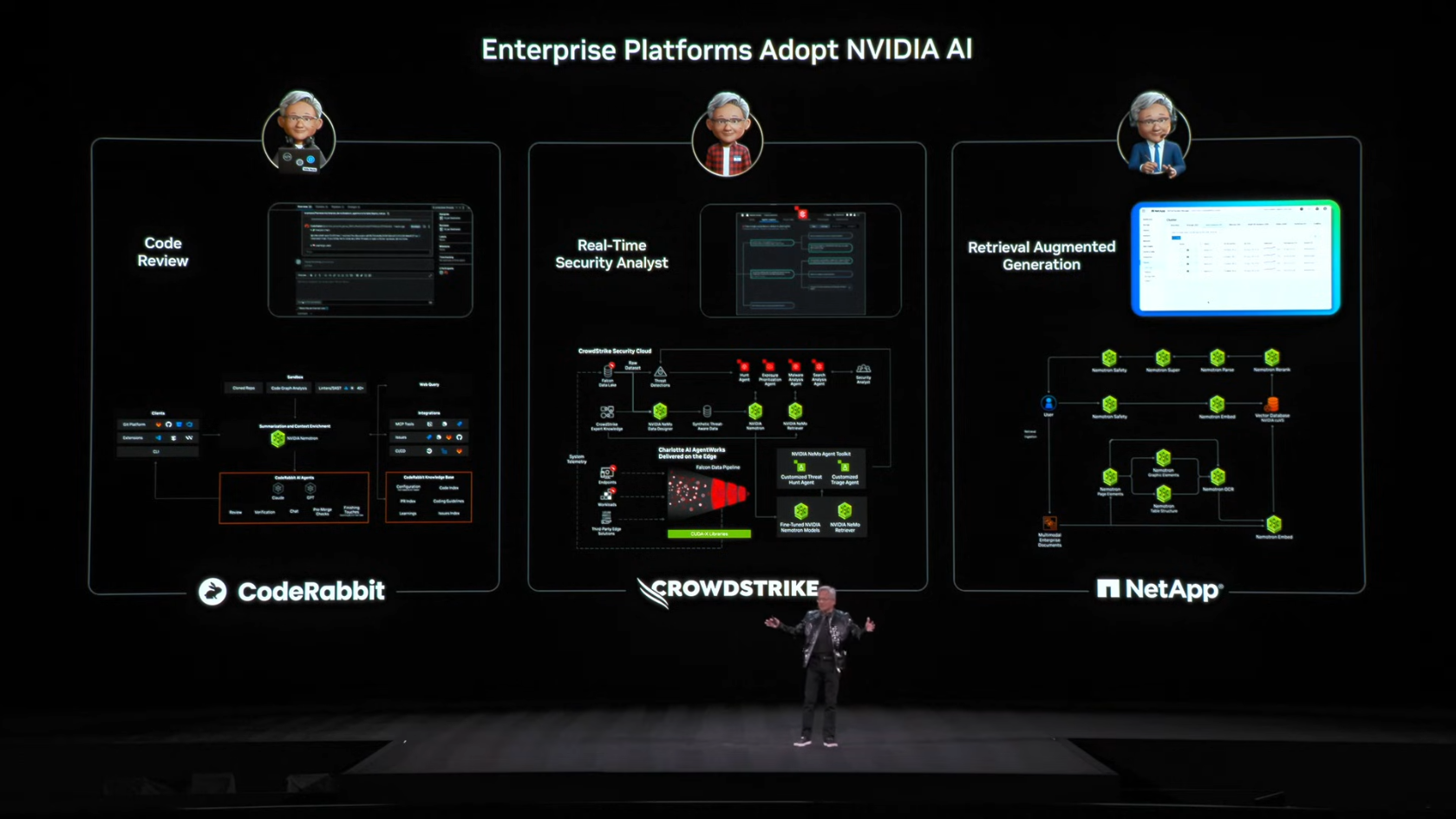
젠슨 황은 이러한 파트너십의 공통점을 강조했습니다. 단순히 AI 기능을 추가하는 것이 아니라, Agentic AI가 플랫폼의 새로운 인터페이스가 된다는 점입니다.
기존에는 사용자가 복잡한 대시보드와 스프레드시트를 직접 조작해야 했지만, 이제는 AI Agent와 자연어로 대화하며 플랫폼을 사용하게 됩니다. 젠슨 황은 이를 "엑셀 칸 채우기에서 사람과 대화하는 방식으로" 바뀌는 것이라고 표현했습니다.
6. Physical AI: 물리 세계와 만나는 AI
젠슨 황은 8년간 Physical AI를 연구해왔다고 밝혔습니다. Physical AI란 화면 속 디지털 세계를 넘어, 로봇이나 자율주행차처럼 실제 물리 세계에서 동작하는 AI를 의미합니다.
6.1 Physical AI가 이해해야 할 것들
ChatGPT 같은 언어 모델은 텍스트를 잘 이해하지만, 물리 세계에 대해서는 아무것도 모릅니다. 젠슨 황은 AI가 물리 세계에서 동작하려면 인간에게는 너무나 당연한 "상식"을 학습해야 한다고 강조했습니다.
예를 들어:
- Object Permanence (객체 영속성): 물체가 시야에서 사라져도 여전히 존재한다는 것
- Causality (인과관계): 물체를 밀면 넘어진다는 것
- Friction & Gravity (마찰과 중력): 물체가 바닥에 붙어있고, 떨어지면 아래로 간다는 것
- Inertia (관성): 무거운 트럭은 급정거가 어렵다는 것
"These ideas are common sense to even a little child. But for AI, it's completely unknown."
어린아이도 본능적으로 아는 이런 개념들을 AI는 전혀 모릅니다. 이것이 Physical AI 개발이 어려운 이유입니다.
6.2 3-Computer 아키텍처
그렇다면 Physical AI를 어떻게 만들 수 있을까요? 젠슨 황은 세 가지 컴퓨터가 필요하다고 설명했습니다.
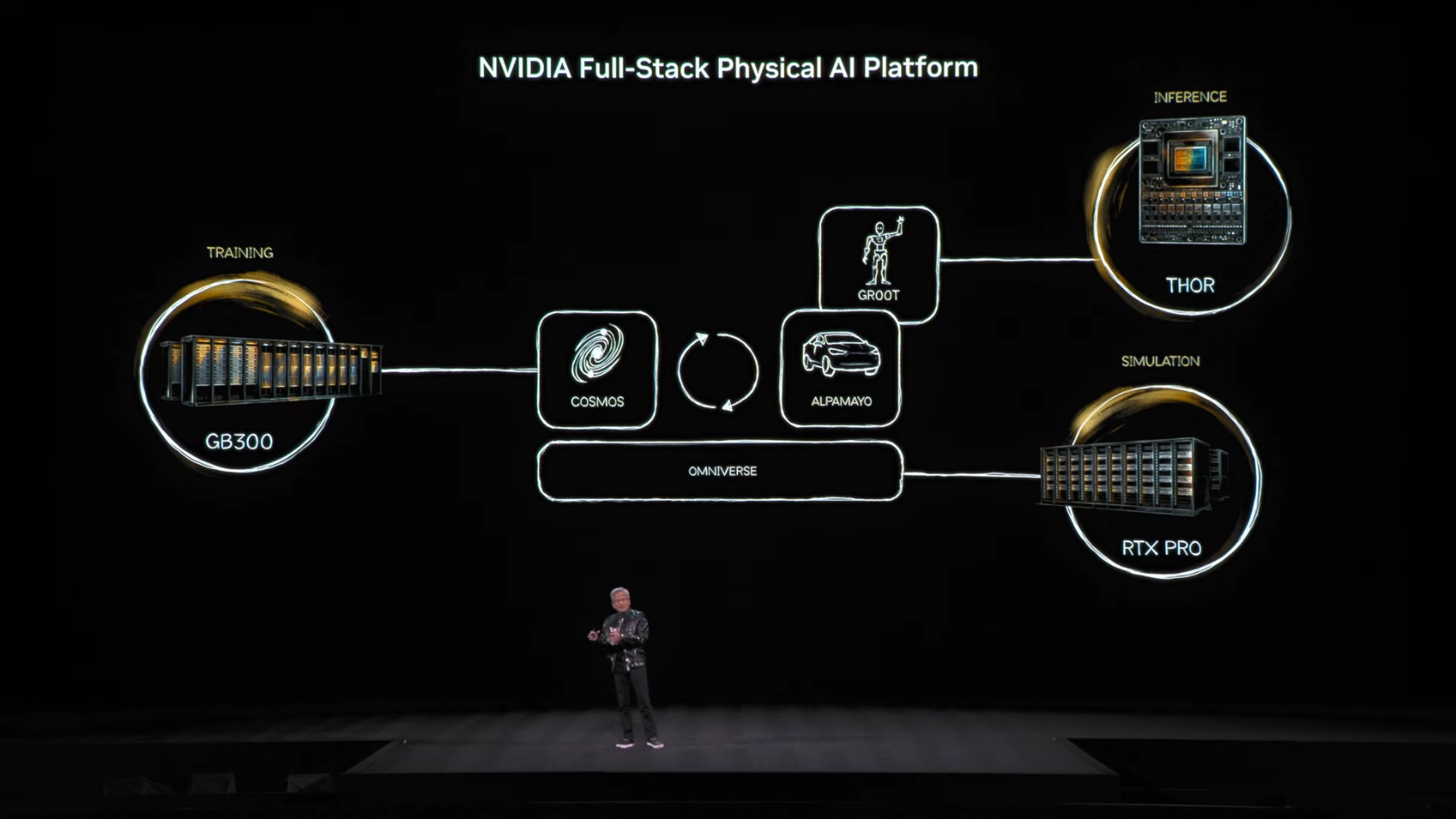
1) Training Computer
- AI 모델을 학습시키는 데이터센터급 슈퍼컴퓨터입니다. DGX SuperPOD 같은 대규모 GPU 클러스터가 여기에 해당합니다.
2) Inference Computer
- 학습된 모델을 실제 로봇이나 차량에서 실행하는 Edge 컴퓨터입니다. NVIDIA Orin, Thor, Jetson 같은 임베디드 AI 칩이 사용됩니다.
3) Simulation Computer
— 여기가 핵심입니다. AI가 물리 세계에서 행동하기 전에 가상 환경에서 먼저 시뮬레이션해볼 수 있는 컴퓨터입니다. NVIDIA Omniverse가 이 역할을 담당합니다.
"How does an AI know that the actions that it's performing is consistent with what it should do if it doesn't have the ability to simulate the response of the physical world back on its actions?"
AI가 자신의 행동 결과를 미리 시뮬레이션할 수 없다면, 어떻게 올바른 행동을 할 수 있을까요? 이것이 NVIDIA가 시뮬레이션 컴퓨터가 필수라고 주장하는 이유입니다.
6.3 핵심 소프트웨어 스택
NVIDIA는 Physical AI를 위한 소프트웨어 스택을 다음과 같이 구성했습니다:
-
Omniverse: 물리 법칙 기반 시뮬레이션 플랫폼, Digital Twin 구축
-
Cosmos: 물리 세계의 작동 방식을 이해하는 World Foundation Model
-
Isaac GR00T: 휴머노이드 로봇용 Vision-Language-Action 모델
-
Alpamayo: 자율주행 AI 모델 (이번 CES에서 발표)
이 스택을 통해 AI는 가상 세계에서 충분히 학습하고, 실제 세계에 배포될 수 있습니다.
7. Cosmos: World Foundation Model
7.1 Cosmos란?
LLM이 언어를 이해하는 모델이라면, Cosmos는 물리 세계를 이해하는 Foundation Model입니다.
젠슨 황은 이를 "World Foundation Model"이라 명명했습니다. ChatGPT가 텍스트로 학습해서 언어의 규칙을 배우듯, Cosmos는 비디오로 학습해서 물리 법칙을 배웁니다.
Cosmos의 학습 데이터:
- 인터넷 규모의 비디오 (2,000만 시간 분량)
- 실제 자율주행 주행 데이터
- 로보틱스 조작 데이터
- Omniverse 3D 시뮬레이션
Cosmos는 이 데이터를 통해 "물체가 떨어지면 아래로 간다", "차가 급회전하면 관성이 작용한다" 같은 물리적 상식을 스스로 학습합니다.
7.2 Cosmos의 핵심 능력
Cosmos가 할 수 있는 것들을 살펴보겠습니다.

1) Text-to-World Generation
- 3D 씬을 텍스트로 설명하면 물리 법칙에 맞는 비디오를 생성합니다. 예를 들어 "비 오는 밤, 교차로에서 트럭이 좌회전한다"고 입력하면, 빗물 반사, 헤드라이트 산란, 타이어 마찰까지 고려한 영상이 만들어집니다.
2) Video-to-World Prediction
- 단일 이미지나 짧은 비디오를 입력하면 "다음에 무슨 일이 일어날지" 예측합니다. 자율주행차 앞에 보행자가 보이면, 그 보행자가 어떤 경로로 이동할지 여러 가능성을 시뮬레이션합니다.
3) Edge Case Reasoning
- 실제로 거의 발생하지 않는 위험 상황(갑자기 튀어나오는 동물, 역주행 차량 등)을 생성하고 분석합니다. 이런 Edge Case는 실제 데이터로 수집하기 거의 불가능합니다.
4) Closed-loop Simulation
- AI가 행동을 취하면 → 세계가 반응하고 → 그 반응을 보고 AI가 다시 행동하는 상호작용 시뮬레이션이 가능합니다. 로봇이 물건을 집으면 물건이 움직이고, 그 움직임을 보고 로봇이 다음 동작을 결정합니다.

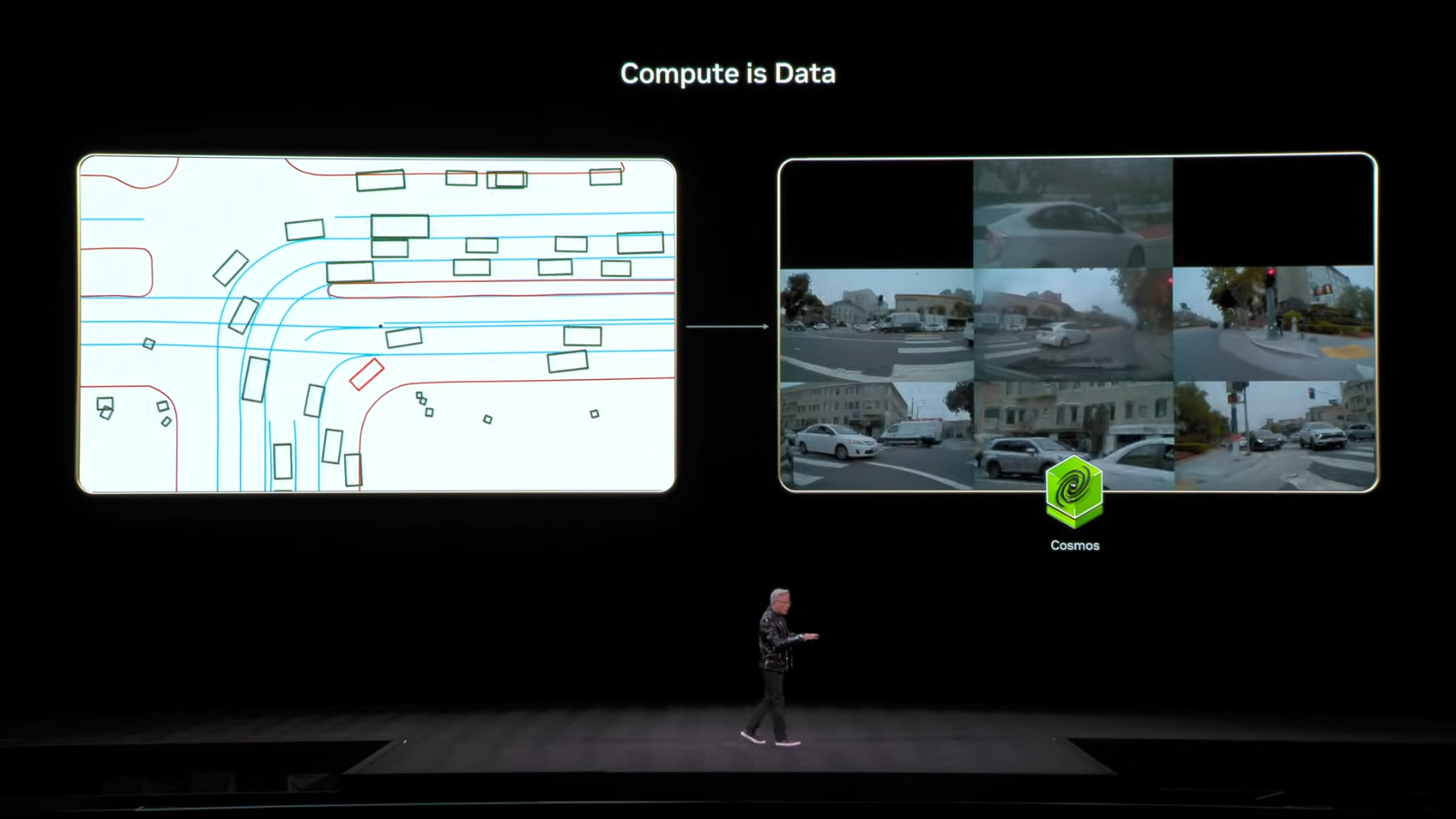
7.3 합성 데이터 생성: Compute를 Data로 전환
Physical AI 개발의 가장 큰 병목은 데이터 부족입니다.
자율주행차를 학습시키려면 수십억 마일의 주행 데이터가 필요하지만, 실제로 그만큼 운전해서 데이터를 모으는 것은 불가능합니다. 특히 사고 상황 같은 위험한 Edge Case는 실제로 수집할 수도 없습니다.
"The challenge is clear. The physical world is diverse and unpredictable. Collecting real world training data is slow and costly and it's never enough. The answer is synthetic data."
젠슨 황의 해결책은 합성 데이터(Synthetic Data)입니다. Cosmos를 사용하면 컴퓨팅 파워를 데이터로 전환할 수 있습니다.
워크플로우 예시:
Traffic Simulator (차량 궤적, 신호등 상태)
↓
Cosmos
↓
물리적으로 타당한 360° Surround Video
(날씨, 조명, 반사, 그림자 모두 포함)간단한 시뮬레이터 출력을 Cosmos에 넣으면, 실제 카메라로 촬영한 것 같은 고품질 영상이 생성됩니다. 이 영상으로 자율주행 AI를 학습시키면, 실제 주행 없이도 다양한 상황을 경험할 수 있습니다.
8. Alpamayo: 자율주행 AI
8.1 Alpamayo 소개
Alpamayo는 NVIDIA가 발표한 세계 최초의 Thinking/Reasoning Autonomous Vehicle AI입니다.
기존 자율주행 AI가 "어떻게 운전할지"만 결정했다면, Alpamayo는 "왜 그렇게 운전하는지"까지 설명할 수 있습니다. 마치 운전 강사가 "저 보행자가 횡단보도로 향하고 있으니 속도를 줄여야 해"라고 말하듯, Alpamayo도 자신의 판단 근거를 실시간으로 출력합니다.
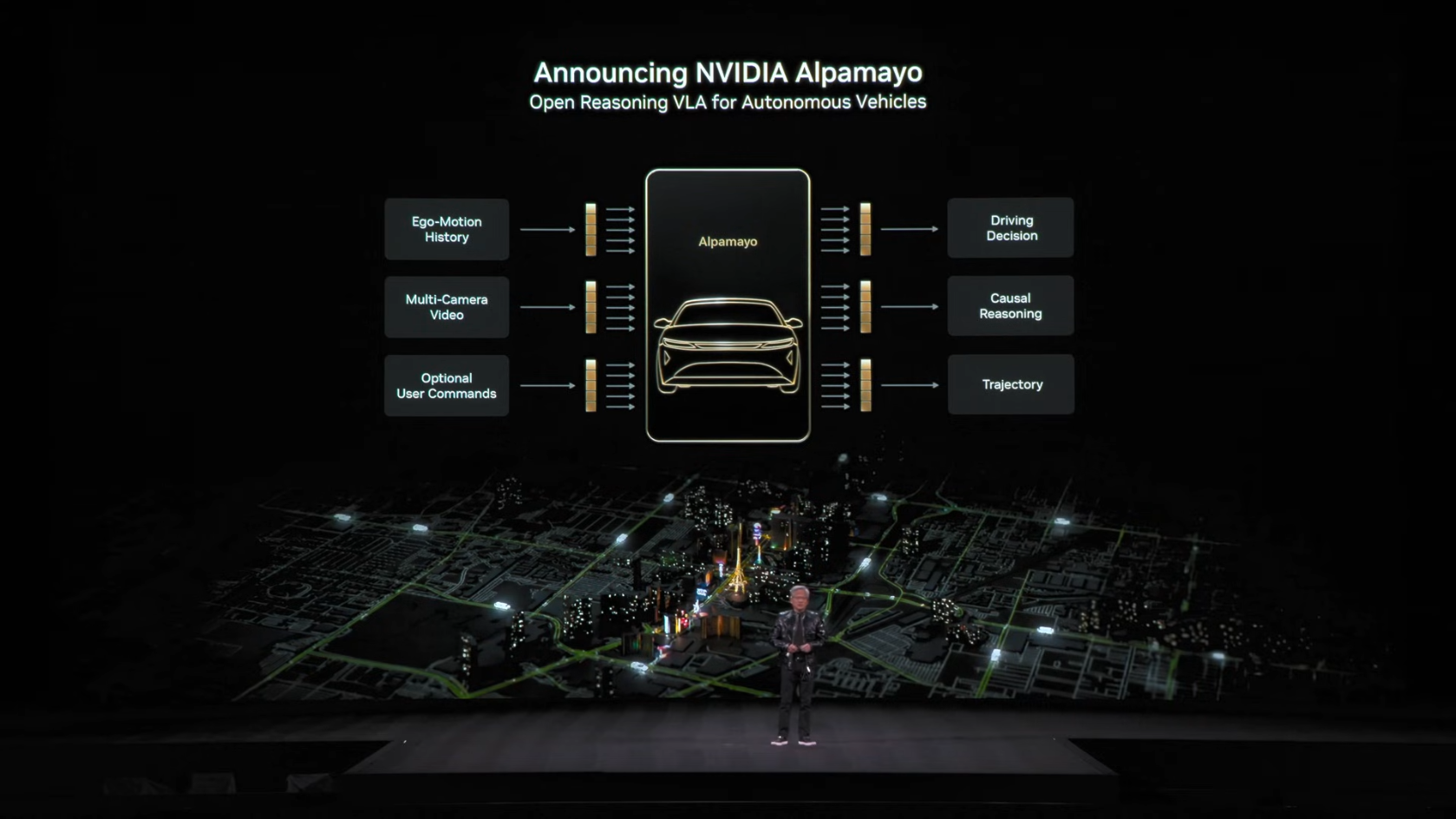
8.2 핵심 특징
1) End-to-End 학습
전통적인 자율주행 시스템은 인지(Perception) → 판단(Planning) → 제어(Control)가 분리된 파이프라인 구조입니다. 각 모듈을 따로 개발하고 연결해야 합니다.
Alpamayo는 이와 달리 카메라 영상을 입력받아 조향/가속/제동을 직접 출력하는 End-to-End 구조입니다. 중간 단계 없이 "보는 것"에서 "행동"으로 바로 연결됩니다.
2) Human Demonstration 학습
Alpamayo는 인간 운전자의 주행 데이터를 보고 배웁니다. 숙련된 운전자가 다양한 상황에서 어떻게 반응하는지 관찰하고, 그 패턴을 학습합니다.
3) Cosmos 합성 데이터 활용
앞서 소개한 Cosmos로 생성한 합성 주행 시나리오를 학습에 활용합니다. 실제로 경험하기 어려운 위험 상황(갑작스러운 장애물, 악천후, 역주행 차량 등)도 합성 데이터로 충분히 학습할 수 있습니다.
4) Reasoning 출력
Alpamayo의 가장 독특한 특징입니다. 단순히 "좌회전한다"가 아니라 "전방 신호가 녹색이고, 반대편 차량이 멈춰있으며, 보행자가 없으므로 좌회전한다"처럼 판단 근거를 자연어로 설명합니다.
8.3 Long-tail 문제 해결
자율주행의 가장 어려운 문제 중 하나가 Long-tail 문제입니다.
일반적인 주행 상황(직진, 차선 변경, 신호 대기)은 데이터도 많고 처리하기 쉽습니다. 하지만 드물게 발생하는 예외 상황(도로 위 떨어진 화물, 갑자기 뛰어드는 동물, 공사 중 임시 신호체계)은 데이터가 거의 없고, 이런 상황이 무한히 다양합니다. 이것이 "Long-tail"입니다 — 빈도 그래프의 긴 꼬리 부분에 해당하는 수많은 희귀 상황들.
"It's impossible for us to simply collect every single possible scenario... However, it is very likely that every scenario if decomposed into a whole bunch of other smaller scenarios are quite normal for you to understand."
젠슨 황의 핵심 통찰은 이렇습니다: 아무리 드문 시나리오라도 익숙한 하위 문제들로 분해하면 처리할 수 있다는 것입니다.
예를 들어 "공사장 옆 비포장 도로에서 역주행 자전거를 피하는 상황"은 처음 보는 시나리오일 수 있습니다. 하지만 이를 분해하면:
- 비포장 도로 주행 (학습된 패턴)
- 장애물 회피 (학습된 패턴)
- 자전거 궤적 예측 (학습된 패턴)
...의 조합이 됩니다. Alpamayo는 Reasoning 능력으로 이런 분해와 조합을 수행합니다.
8.4 데모
젠슨 황은 실제 Alpamayo 주행 영상을 공개했습니다.

영상에서는 One-shot, no hands — 즉 운전자가 핸들에서 손을 떼고 개입 없이 주행하는 모습이 시연되었습니다. 화면에는 Alpamayo의 실시간 Reasoning 출력이 함께 표시되어, AI가 왜 그런 결정을 내렸는지 확인할 수 있었습니다.
8.5 안전 아키텍처: Dual Stack
자율주행에서 가장 중요한 것은 안전입니다. NVIDIA는 이중 안전 구조(Dual Stack)를 채택했습니다.
"All safety systems should have diversity and redundancy."
Alpamayo Stack:
- End-to-End 학습 기반으로, 뛰어난 주행 스킬과 유연한 상황 대응이 장점입니다. 하지만 신경망 특성상 왜 그런 결정을 내렸는지 완벽히 추적하기 어려울 수 있습니다.

Classical AV Stack:
- NVIDIA가 6~7년간 개발해온 전통적 자율주행 스택입니다. 규칙 기반으로 동작하여 모든 결정을 완벽히 추적(trace)할 수 있습니다.
Policy & Safety Evaluator:
- 두 스택의 출력을 비교하고, 상황에 따라 어떤 스택의 결정을 따를지 선택합니다. 둘의 결정이 충돌하면 더 안전한 쪽을 선택합니다.
이 구조의 핵심은 다양성(Diversity)과 중복성(Redundancy)입니다. 한 시스템이 실패해도 다른 시스템이 백업하고, 서로 다른 방식으로 동작하기 때문에 같은 실수를 동시에 할 가능성이 낮습니다.
8.6 Mercedes-Benz 파트너십
Alpa-mayo의 첫 상용화 파트너는 Mercedes-Benz입니다.
Mercedes-Benz CLA는 NCAP에서 "세계에서 가장 안전한 자동차" 등급을 받은 차량입니다. 여기에 NVIDIA의 자율주행 기술이 탑재됩니다.
프로세서 로드맵:
- 현재: Dual NVIDIA Orin
- 차세대: Dual NVIDIA Thor (Orin 대비 대폭 성능 향상)
출시 일정:
- 2026년 Q1: 미국 출시
- 2026년 Q2: 유럽 출시
- 2026년 Q3~Q4: 아시아 출시
8.7 오픈소스 공개
놀랍게도 젠슨 황은 Alpamayo를 오픈소스로 공개한다고 발표했습니다.
"Alpamayo today is open sourced... This incredible body of work took several thousand people."
수천 명의 엔지니어가 수년간 개발한 자율주행 AI를 공개하는 것은 이례적인 결정입니다. NVIDIA가 자율주행 생태계 전체를 키우려는 전략으로 보입니다 — 더 많은 기업이 NVIDIA 플랫폼 위에서 자율주행을 개발하도록 유도하는 것입니다.
9. 로보틱스의 미래
9.1 로봇 데모
젠슨 황은 기조연설 무대에 작은 로봇들을 직접 초대했습니다. 이 로봇들은 NVIDIA의 엣지 AI 플랫폼인 Jetson 컴퓨터를 탑재하고 있으며, Omniverse 환경(Isaac Sim, Isaac Lab)에서 시뮬레이션 기반 강화학습을 통해 훈련되었습니다.
실제 물리 세계에 배치되기 전에 디지털 환경에서 수백만 번의 시행착오를 거쳤기 때문에, 현실 세계에서도 안정적으로 동작할 수 있습니다. Physical AI의 구체적인 결과물을 무대에서 직접 시연한 것입니다.

9.2 로봇 파트너 생태계
젠슨 황은 NVIDIA가 협력하고 있는 다양한 로봇 기업들을 소개했습니다.
휴머노이드 및 모바일 로봇 분야에서는 Neurobot, Aubot, Agibot, LG, Agility, Boston Dynamics 등이 NVIDIA 플랫폼을 활용하고 있습니다. 산업용 로봇 분야에서는 대형 건설장비의 Caterpillar, 배달 로봇 Surf Robot(Uber Eats 배달에 사용), 수술 로봇, Frana 매니퓰레이터, Universal Robotics 등이 파트너로 참여하고 있습니다.
"This is the next chapter... but it's not just about the robots in the end."
젠슨 황의 이 발언은 로봇 그 자체가 목표가 아니라, 로봇을 가능하게 하는 Physical AI 생태계 전체가 NVIDIA의 다음 성장 동력이라는 점을 강조한 것입니다. 로봇은 Physical AI가 현실 세계에 나타나는 하나의 형태일 뿐입니다.

10. 산업 파트너십: EDA & Manufacturing
10.1 반도체 설계 도구 혁신
Physical AI와 AI Physics 기술은 로봇과 자율주행에만 적용되는 것이 아닙니다. 반도체 설계 산업도 이 기술들로 혁신되고 있습니다.
반도체 설계 분야의 양대 산맥인 Cadence와 Synopsys가 NVIDIA와 협력합니다. Cadence는 Physical Design과 Emulation 분야에서, Synopsys는 Logic Design과 IP 분야에서 각각 CUDA-X와 Physical AI를 통합하고 있습니다. 이를 통해 칩 설계 시뮬레이션이 가속되고, AI 기반 최적화가 가능해집니다.
"In the future, we're going to design your chips inside Cadence and inside Synopsys. We're going to design your systems and emulate the whole thing and simulate everything inside these tools."
미래에는 칩 설계부터 시스템 설계, 전체 에뮬레이션까지 모두 이 도구들 안에서 이루어진다는 비전입니다.

10.2 Siemens 파트너십 (신규 발표)
이번 CES에서 새롭게 발표된 파트너십은 Siemens와의 협력입니다.
Siemens는 거의 200년 역사를 가진 세계적인 산업 기술 기업입니다. 이번 협력을 통해 Siemens의 도구들에 CUDA-X, Physical AI, Agentic AI (Nemo, Nemotron), 그리고 Omniverse가 통합됩니다.

적용 범위는 광범위합니다. 반도체 설계 자동화(EDA), 컴퓨터 지원 엔지니어링(CAE), Digital Twin 도구 및 플랫폼 전반에 걸쳐 NVIDIA 기술이 녹아들어갑니다.
"For nearly two centuries, Siemens has built the world's industries. And now it is reinventing it for the age of AI."
10.3 비전: 완전한 디지털 제조
젠슨 황은 무대 위의 로봇들에게 직접 말하듯 미래 비전을 설명했습니다.
그의 비전은 명확합니다. 칩을 컴퓨터 안에서 설계하고, 제조 라인도 컴퓨터 안에서 설계하고, 모든 것을 컴퓨터 안에서 테스트하고 평가한 후에야 비로소 중력을 경험한다는 것입니다. "중력을 경험한다"는 표현은 실제 물리 세계에 제품이 나온다는 의미입니다.
"You're going to be designed in a computer. You're going to be made in a computer. You're going to be tested and evaluated in a computer long before you have to spend any time dealing with gravity."
Digital Twin과 시뮬레이션이 제조업의 기본이 되는 미래를 그린 것입니다.
11. Vera Rubin: 차세대 AI 슈퍼컴퓨터
11.1 명명의 의미
Vera Rubin은 미국의 천문학자 이름에서 따왔습니다.
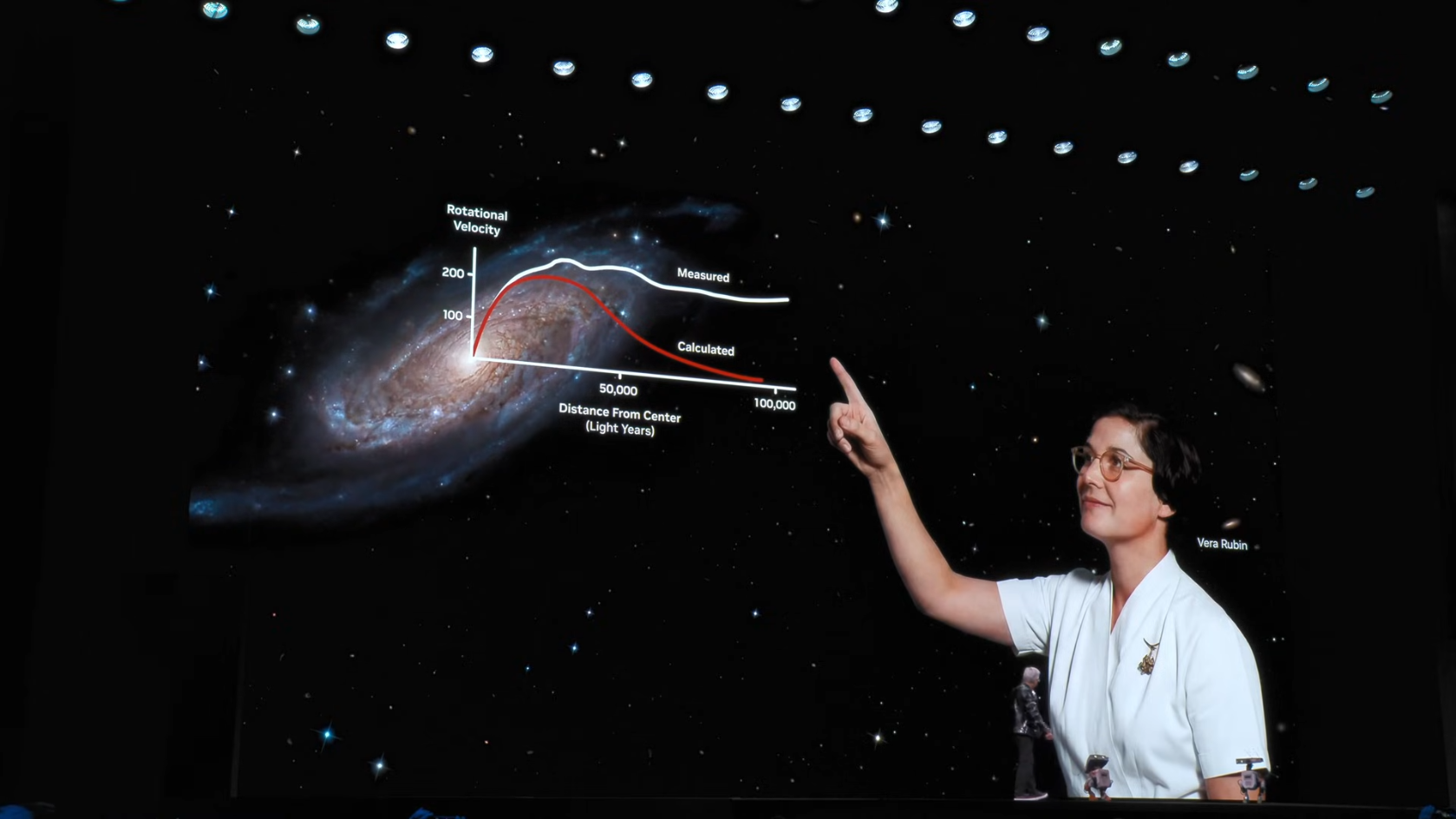
그녀는 은하 외곽 별들의 회전 속도를 관측하던 중 기존 뉴턴 물리학으로는 설명할 수 없는 현상을 발견했습니다. 은하 외곽의 별들이 예상보다 훨씬 빠르게 회전하고 있었고, 이는 우리가 볼 수 없는 어떤 물질이 존재한다는 증거였습니다. 이것이 암흑물질(Dark Matter)의 존재를 실증적으로 발견한 첫 사례입니다.
NVIDIA가 이 이름을 선택한 것은 Vera Rubin이 기존 패러다임을 뒤흔든 과학자였기 때문일 것입니다.
11.2 왜 Vera Rubin이 필요한가?
젠슨 황은 AI 연산 수요가 세 가지 요인에 의해 동시에 폭발적으로 증가하고 있다고 설명했습니다.
-
첫째, AI 모델의 크기가 매년 약 10배씩 커지고 있습니다. 더 크고 더 정교한 모델이 계속 등장합니다.
-
둘째, Test-Time Scaling의 등장으로 추론 시 생성하는 토큰 수가 매년 약 5배씩 증가하고 있습니다. o1, o3 같은 Reasoning 모델은 답변 하나에 수천 개의 토큰을 내부적으로 생성합니다.
-
셋째, 경쟁 심화로 토큰당 비용이 매년 1/10로 떨어지고 있습니다. 비용이 떨어지면 사용량이 늘어나고, 총 연산 수요는 오히려 증가합니다.
"All of these things are simultaneously happening at the same time. And so we decided that we have to advance the state-of-the-art of computation every single year. Not one year left behind."
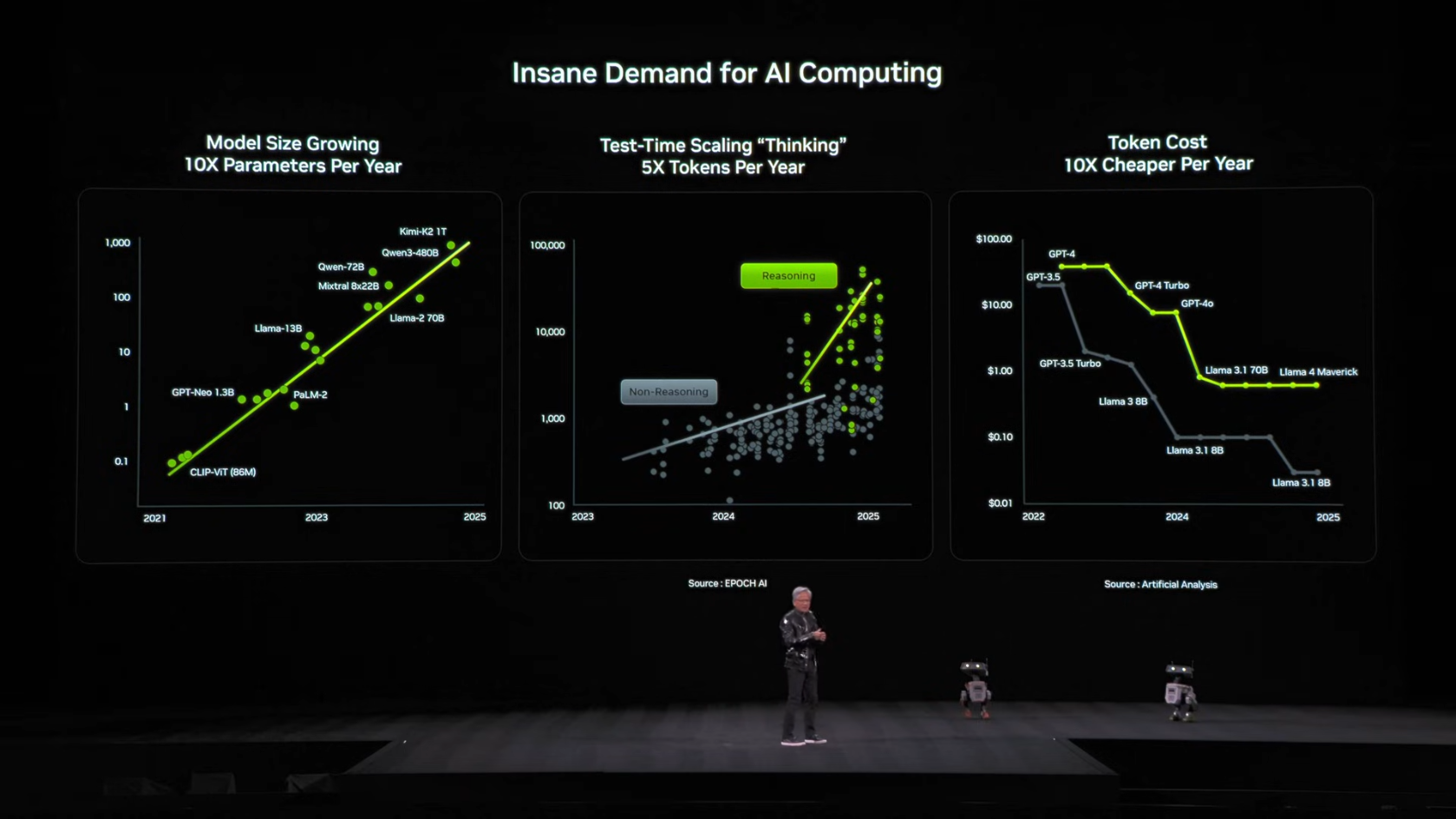
이 세 가지가 동시에 일어나기 때문에, NVIDIA는 매년 연산 기술을 혁신해야 한다고 결론 내렸습니다.
11.3 제품 로드맵
NVIDIA의 데이터센터 GPU 로드맵을 보면 속도가 놀랍습니다.
약 1.5년 전 GB200 출하가 시작되었고, 현재는 GB300이 풀스케일 양산 중입니다. 그리고 오늘 발표에서 Vera Rubin의 풀스케일 양산 돌입을 선언했습니다. 거의 1년 단위로 새로운 세대가 양산에 들어가는 셈입니다.
11.4 Extreme Co-Design: 6개 칩 동시 재설계
NVIDIA 내부에는 오랫동안 "한 세대에 1~2개 칩만 변경한다"는 규칙이 있었습니다. 복잡성을 관리하고 리스크를 줄이기 위해서입니다.
하지만 Vera Rubin에서는 이 규칙을 깼습니다. 6개 칩 모두를 동시에 재설계했습니다.
이유는 명확합니다. Moore's Law가 둔화되면서 트랜지스터 수 증가만으로는 세대당 10배 성능 향상이 불가능해졌습니다. 개별 칩의 점진적 개선으로는 AI 수요 증가 속도를 따라잡을 수 없습니다. 따라서 Extreme Co-Design — 칩, 패키징, 네트워크, 소프트웨어 스택 전체를 동시에 혁신하는 접근법이 필수가 되었습니다.
"It is impossible to keep up with those kind of rates... unless we deployed aggressive extreme code design, basically innovating across all of the chips across the entire stack all at the same time."
11.5 6개의 핵심 칩

1. Vera CPU
가장 먼저 소개된 컴포넌트입니다. NVIDIA가 직접 설계한 서버용 CPU로, 이전 세대 대비 2배의 성능을 제공합니다.
- 88개 코어, 176 스레드 구성
- Spatial Multi-threading 방식 적용으로 각 스레드가 풀 성능 발휘
- 전력 제한 환경에서 경쟁 CPU 대비 와트당 성능 2배

2. Rubin GPU
Vera CPU 바로 다음에 소개되었습니다. Vera와 Rubin은 처음부터 양방향 coherent 데이터 공유를 위해 Co-Design되었다고 강조했습니다.
- Blackwell 대비 FP 성능 5배 향상
- 트랜지스터 수는 1.6배 증가에 그침 (아키텍처 혁신의 결과)
- NV FP4 Tensor Core: 단순한 4비트 연산이 아닌 적응형 정밀도 프로세서
- Transformer 각 레이어에서 필요한 정밀도를 하드웨어 레벨에서 동적 조절
- 소프트웨어로는 불가능한 실시간 정밀도 적응

3. Vera Rubin Compute Board / Compute Tray
개별 칩은 아니지만 시스템 구성 단위로 소개되었습니다.
- Compute Board: Vera CPU 1개 + Rubin GPU 2개 + 17,000개 부품
- Compute Tray: Bluefield-4 DPU 1개 + ConnectX-9 NIC 8개 + Vera CPU 2개 + Rubin GPU 4개
- 케이블, 호스, 팬 없이 완전히 재설계됨

4. ConnectX-9
Scale-out 대역폭을 담당하는 네트워크 인터페이스입니다.
- GPU당 1.6Tbps의 Scale-out 대역폭 제공
- 랙 간 통신(East-West 네트워크) 담당

5. Bluefield-4 DPU
스토리지와 보안을 오프로드하여 컴퓨팅 자원이 AI에만 집중할 수 있게 합니다.
- North-South 트래픽에서 가상화, 보안, 네트워킹 기능 처리
- KV Cache 컨텍스트 메모리 관리 역할 추가 (Vera Rubin의 새로운 기능)

6. NVLink Switch (6세대)
GPU 간 내부 통신을 담당합니다.
- "전 세계 인터넷보다 많은 데이터" 이동 가능
- 18개 Compute Node 연결, 최대 72개 Rubin GPU가 하나로 동작

7. Spectrum-X Ethernet Photonics Switch
데이터센터 스케일의 네트워크 연결을 담당합니다.
- 세계 최초로 Co-packaged Optics 적용 이더넷 스위치
- 512개 레인, 각 200Gbps 속도
- 수천 개 랙을 AI Factory로 Scale-out

12. 클로징
12.1 NVIDIA의 현재
"We mentioned that we build chips, but as you know, NVIDIA builds entire systems now."
젠슨 황은 클로징에서 NVIDIA의 정체성을 다시 정의했습니다. NVIDIA는 더 이상 칩 회사가 아닙니다. Full Stack을 구축하는 회사입니다.
이 Full Stack은 Chips(Vera, Rubin, NVLink, ConnectX, Bluefield, Spectrum-X)에서 시작해 Infrastructure(NVL72, Pod, 냉각 시스템)로 이어지고, Models(Cosmos, Nemotron, Llama 최적화)과 Applications(자율주행, 로보틱스, 디지털 제조)까지 확장됩니다.
12.2 핵심 메시지
"AI is a full stack. We're reinventing AI across everything from chips to infrastructure to models to applications. And our job is to create the entire stack so that all of you could create incredible applications for the rest of the world."
AI는 단일 기술이 아니라 전체 스택입니다. NVIDIA는 칩부터 인프라, 모델, 애플리케이션까지 AI의 모든 층위를 재발명하고 있습니다. 그리고 NVIDIA의 역할은 이 전체 스택을 만들어서, 전 세계의 개발자들이 놀라운 애플리케이션을 만들 수 있게 하는 것입니다.
읽어주셔서 감사합니다!

이번 CES에 관심있는 내용이 많았는데, 깔끔하게 정리해주셔서 감사합니다!