
Inductive Bias
Overview
Inductive Bias란 무엇일까요? 최근 논문들을 보면 그냥 Bias도 아니고 Inductive Bias라는 말이 자주 나오는 것을 확인할 수 있는데요! 오늘은 해당 개념에 대해 정리해보는 시간을 가지려고 합니다. 공부하면서 작성한 글이므로 틀린 개념이 있다면 언제든 피드백 환영합니다.
Bias(편향) and Variance(분산)
이미 해당 포스팅을 읽는 분들은 아시겠지만, 먼저 간단하게 Bias와 Variance의 개념을 짚고 넘어가도록 하겠습니다.
먼저 Error는 다음과 같이 Bias와 Variance로 분해될 수 있습니다.
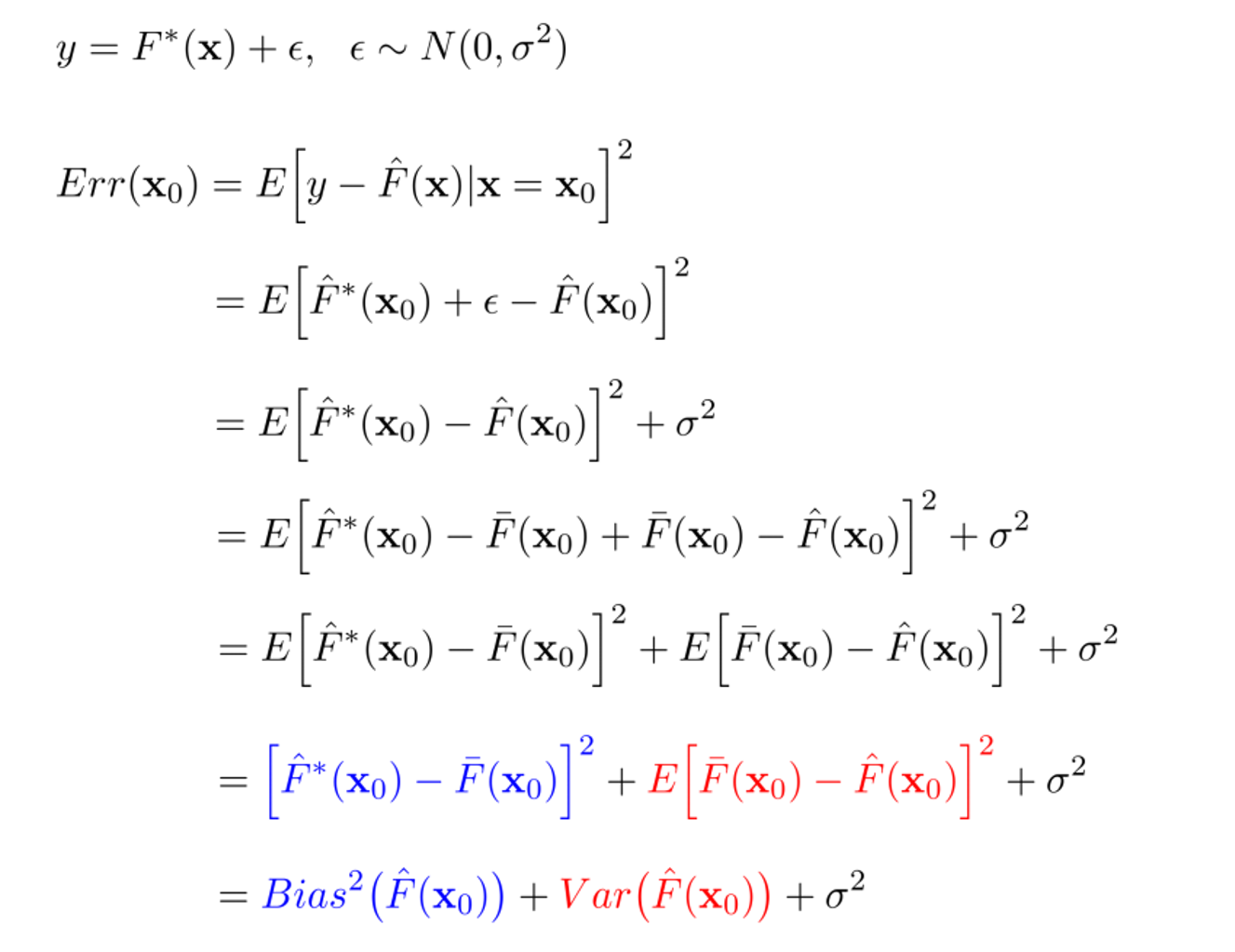
위 수식을 통해 알 수 있는 것은 다음과 같습니다:
-
Bias(의 제곱)은 실제값()과 예측값들의 평균()의 차이를 의미합니다. 낮은 Bias는 평균적으로 우리가 실제값에 근사하게 예측을 수행한다는 것을 의미하며, 높은 Bias는 실제값과 예측값의 평균이 멀리 떨어져있음으로 poor match를 의미합니다. 즉, Bias는 모델의 예측값과 실제값이 얼마나 떨어져있는가를 의미하며, Bias가 크게 되면 과소적합(underfitting)을 야기합니다.
-
Variance는 예측값들의 평균()으로부터 특정 예측값들()이 어느 정도 퍼져있는 가를 의미합니다. 낮은 Variance는 들어오는 데이터에 따라 예측값이 크게 바뀌지 않는 것을 의미하며, 높은 Variance는 들어오는 데이터에 따라 예측값이 크게 바뀌므로 poor match를 의미합니다. 즉, Variance는 예측 모델의 복잡도라고 해석할 수 있으며, Variance가 큰 모델은 훈련 데이터에 지나치게 적합을 시켜 일반화되지 않는 과대적합(overfitting)을 야기합니다.
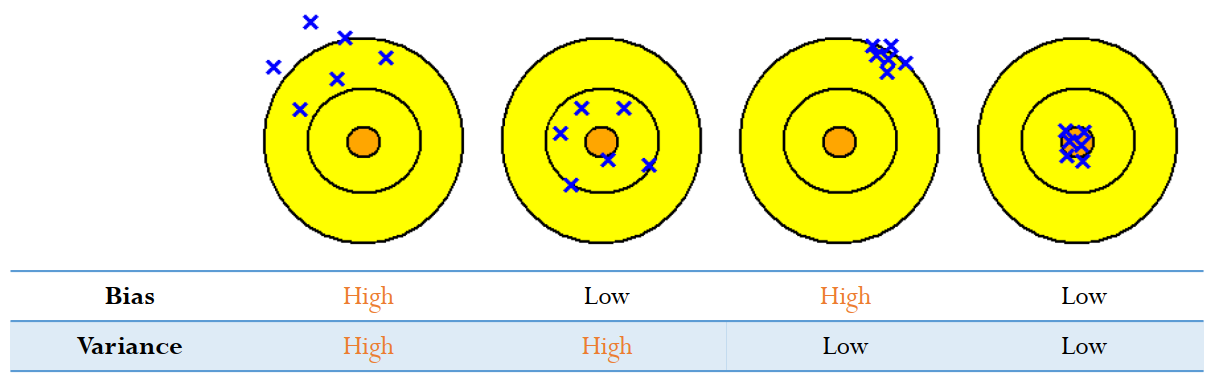
위 그림은 Bias와 Variance를 가장 잘 설명하는 그림(개인적인 생각)으로 가운데 위치한 주황색 원이 우리가 실제로 예측하고자 하는 값(target)이고, 파란색 X들이 모델의 결과(output)라고 생각하시면됩니다. Bias가 낮을수록 실제 정답값에 예측값들이 가깝게 존재하고, Variance가 낮을수록 예측값들의 퍼진 정도가 줄어드는 것을 한 눈에 보실 수 있습니다.
하지만, 현실적으로 낮은 Bias와 낮은 Variance 두 가지를 동시에 만족하는 것은 거의 불가능합니다. 따라서 어느 정도의 tradeoff는 반드시 생길 수 밖에 없으며 이는 bias-variance trade-off 라고 불립니다..
Inductive Bias (귀납편향)
그렇다면 이번 포스팅의 메인 디쉬인 Inductive Bias는 무엇일까요?
일반적으로 모델이 갖는 generalization problem으로는 모델이 brittle(불안정)하다는 것과, spurious(겉으로만 그럴싸한)하다는 것이 있습니다.
- Models are brittle : 데이터의 input이 조금만 바뀌어도 모델의 결과가 망가지게 됩니다.
- Models are spurious : 데이터 본연의 의미를 학습하는 것이 아닌 결과(artifacts)와 편향(biases)를 학습하게 됩니다.
이러한 문제점들을 해결하기 위해 Inductive Bias를 이용하게 됩니다. Wikipedia에서 정의를 빌려오자면, Inductive bias란, 학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인 가정 (additional assumptions)을 의미합니다.
Machine learning에서는 어떤 목표(target)를 예측하기 위해 학습할 수 있는 알고리즘 구축을 목표로 하고, 이를 위해 제한된 수의 입력과 출력 데이터가 주어지게 됩니다. 훈련 데이터를 넘어 다른 데이터에 대해서도 일반화할 수 있는 능력을 가진 모든 기계 학습 알고리즘에는 어떤 유형의 Inductive Bias가 존재하는데, 이는 모델이 목표 함수를 학습하고 훈련 데이터를 넘어 일반화하기 위해 만든 가정입니다.
갑자기 가정이라는 말이 나와서 헷갈리다고요? 편향의 관점으로 다시 정의를 내려보자면 모델이 학습과정에서 본 적이 없는 분포의 데이터를 입력 받았을 때, 해당 데이터에 대한 판단을 내리기 위해 가지고 있는, 학습과정에서 습득된 Bias(편향)이라고 말할 수 있을 것 같습니다.
이러한 딱딱한 개념이 아닌 조금 더 비유적인 표현을 가지고 예시를 들어보겠습니다. 우리가 흔히 말하는 머신러닝/딥러닝을 input과 output의 데이터가 주어지면, 주어진 데이터에 맞는 함수를 가방에서 찾는 것이라고 비유해 보겠습니다. Inductive Bias는 우리가 함수를 찾는 가방의 크기에 반비례(가정의 강도와는 비례)되는 개념으로 보시면 될 것 같습니다. 실제로 거의 모든 함수를 표현할 수 있는 MLP(Multi-Linear Perceptron)의 경우 엄청 큰 가방이라고 생각하면되고, CNN(Convolutional Neural-Net)의 경우 전자보다는 작은 가방이라고 생각하면 될 것 같습니다.
몇 가지 Inductive Bias를 예로 들어보겠습니다.
-
Translation invariance: 어떠한 사물이 들어 있는 이미지를 제공해줄 때 사물의 위치가 바뀌어도 해당 사물을 인식할 수 있습니다. -
Translation Equivariance: 어떠한 사물이 들어 있는 이미지를 제공해줄 때 사물의 위치가 바뀌면 CNN과 같은 연산의 activation 위치 또한 바뀌게 됩니다. -
Maximum conditional independence: 가설이 베이지안 프레임워크에 캐스팅될 수 있다면 조건부 독립성을 극대화합니다. -
Minimum cross-validation error: 가설 중에서 선택하려고 할 때 교차 검증 오차가 가장 낮은 가설을 선택합니다. -
Maximum margin: 두 클래스 사이에 경계를 그릴 때 경계 너비를 최대화합니다. -
Minimum description length: 가설을 구성할 때 가설의 설명 길이를 최소화합니다. 이는 더 간단한 가설은 더 사실일 가능성이 높다는 가정을 기반으로 하고 있습니다. -
Minimum features: 특정 피쳐가 유용하다는 근거가 없는 한 삭제해야 합니다. -
Nearest neighbors: 특징 공간에 있는 작은 이웃의 경우 대부분이 동일한 클래스에 속한다고 가정합니다.
딥러닝에서의 Inductive Bias
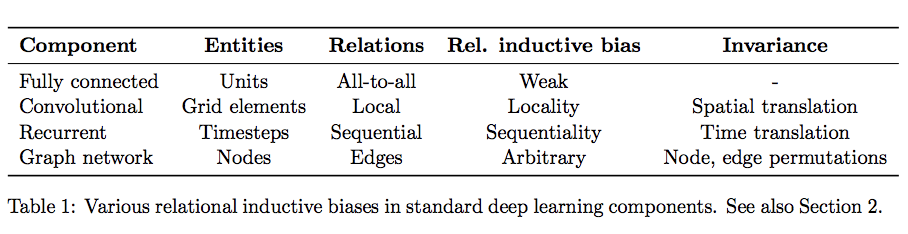
딥러닝의 관점에서 Inductive Bias를 이야기해보자면, 딥러닝에서 우리가 흔히 쌓는 레이어의 구성은 일종의 Relational Inductive Bias(관계 귀납적 편향), 즉 hierarchical processing(계층적 처리)를 제공합니다. 딥러닝 레이어의 종류에 따라 추가적인 관계 유도 편향을 부과되며 이는 아래 표를 참고하면 될 것 같습니다.
Conclusion
Inductive Bias가 강할수록, Sample Efficiency가 좋아지긴 하나 그만큼 가정이 강하게 들어간 것임으로 좋게 볼 수만은 없습니다. 이는 앞에서 소개한 bias-variance tradeoff와 유사한 개념으로 보시면 될 것 같습니다.
많은 현대의 딥러닝 방법은 최소한의 선행 표현 및 계산 가정을 강조하는 "End-to-End" 설계 철학을 따르며, 이러한 트렌드가 왜 대부분의 딥러닝 기법들이 데이터 집약적(Data-Intensive)인지를 설명합니다.
반면에, 몇몇 딥러닝 아키텍처(Eg. Graph Network)에 더 강한 관계 Inductive Bias를 만드는 것에 대한 많은 연구들이 존재합니다.
출처
본 포스팅은 아래 사이트들을 참고하여 작성되었습니다.
- https://www.facebook.com/groups/TensorFlowKR/permalink/1485375795136807/
- https://stats.stackexchange.com/questions/208936/what-is-translation-invariance-in-computer-vision-and-convolutional-neural-netwo/208949#208949
- https://stackoverflow.com/questions/35655267/what-is-inductive-bias-in-machine-learning
- https://www.youtube.com/watch?v=cHiG0Ucv6Ck
- https://www.youtube.com/watch?v=mZwszY3kQBg
- https://en.wikipedia.org/wiki/Inductive_bias

5개의 댓글

안녕하세요, 포스팅에 사용하신 이미지와 일부 정리 내용들을 혹시 스터디 활동에서 정리겸 작성하는 위키독스 문서에 사용 가능할까요?(영리목적이 없고, 출처를 기재해 놓겠습니다!)

안녕하세요 MLP Mixer 발표 영상을 보다가 inductive bias가 궁금해서 검색했는데, 같은 분이 쓰신 글이었네요 ㅋㅋㅋ 정말 잘 배워갑니다!