
1. 자연어 처리(NLP) 개요
자연어 처리의 일반적인 순서
-
자연어 처리는 음성을 텍스트로 변환하고, 해당 텍스트를 분석 및 의미를 추출한 뒤, 이를 다시 음성으로 변환하는 과정을 포함합니다. (아래 그림 참고)
-
이 과정은 크게 STT(Speech to Text)와 TTS(Text to Speech)로 나뉩니다.
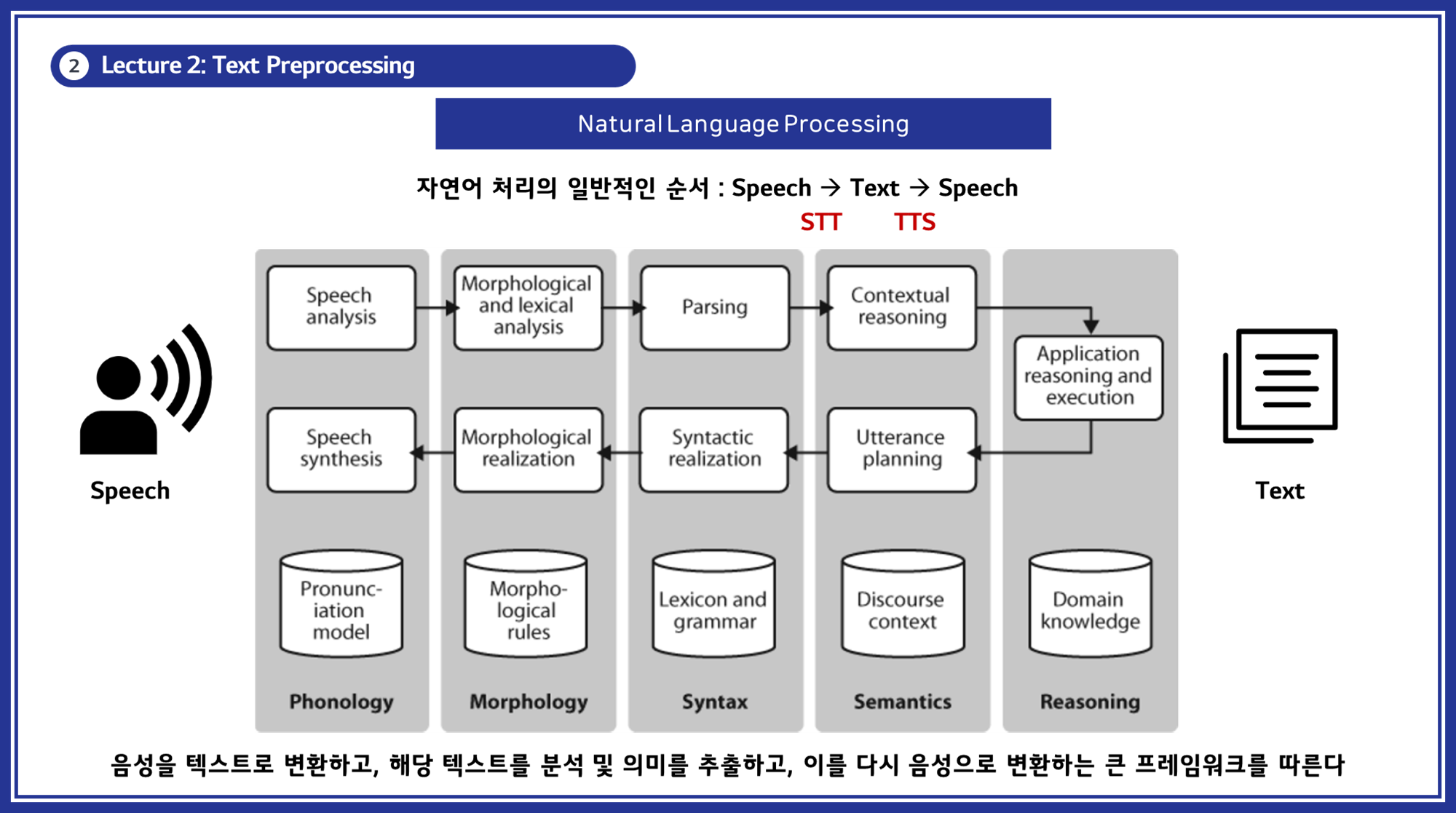
1.1 자연어 처리의 주요 분야
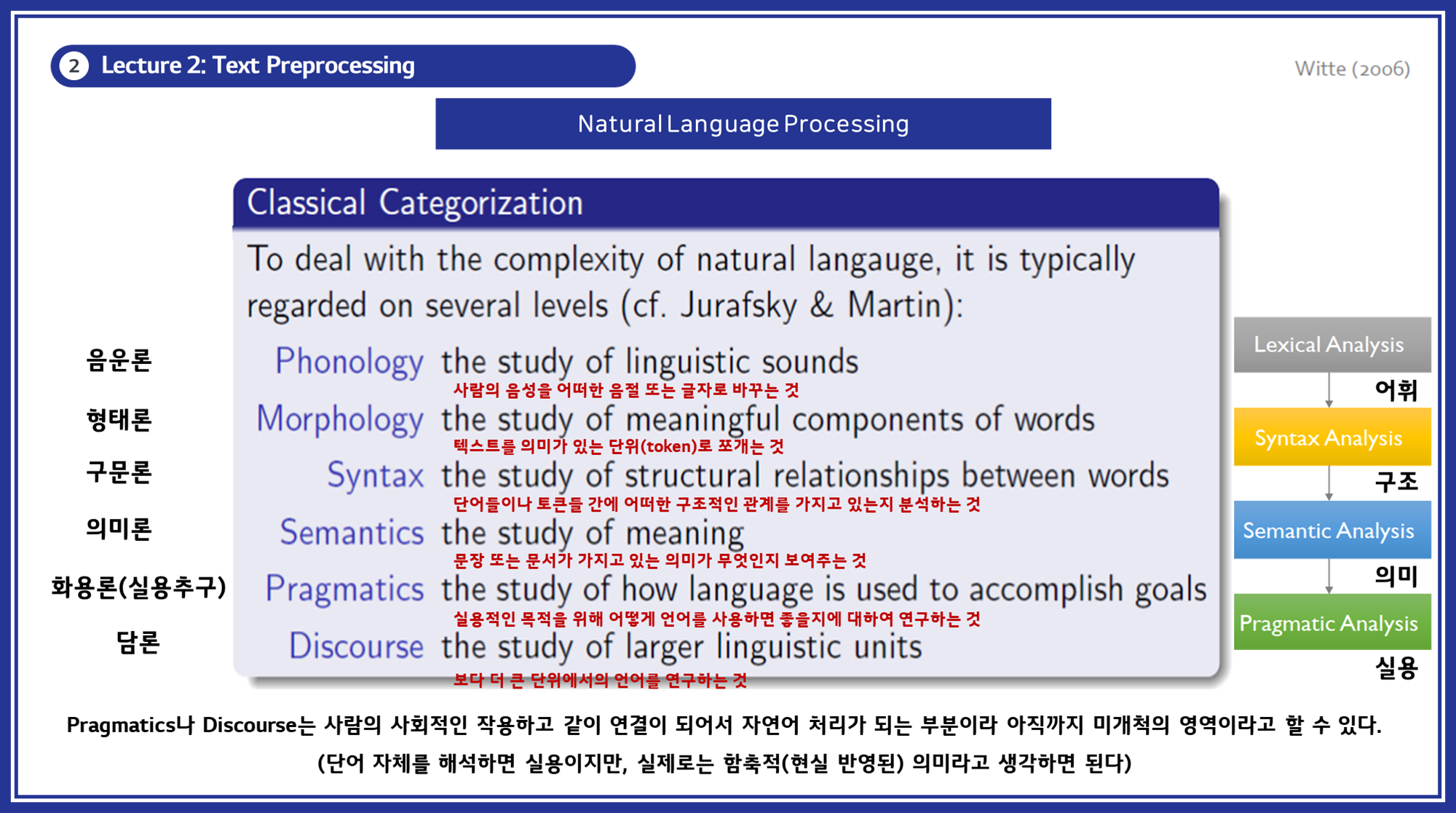
- 음운론, 형태론, 구문론, 의미론, 화용론, 담론과 같은 Classical Categorization은 자연어 처리를 연구하고 응용하는 데 있어서 언어의 각 측면을 분석하고 이해하는 다양한 수준을 기준으로 분류한 것입니다.
- 이러한 분류는 각각의 언어적 현상을 개별적으로 다루고, 각 현상을 처리하는 방법을 연구하는데 중점을 둡니다. 이를 통해 복잡한 자연어를 다양한 층위에서 체계적으로 분석할 수 있습니다.
-
음운론(Phonology):
- 기준: 소리와 관련된 언어적 현상
- 설명: 음운론은 언어의 소리 체계와 음소(phoneme)를 연구합니다. 자연어 처리에서는 음성을 텍스트로 변환하거나, 음성 인식 시스템을 개발할 때 중요한 역할을 합니다.
-
형태론(Morphology):
- 기준: 단어의 구조와 형성
- 설명: 형태론은 단어의 내부 구조를 연구하며, 단어를 의미 있는 단위(morpheme)로 분해하는 작업을 포함합니다. 자연어 처리에서는 형태소 분석(morphological analysis) 및 형태소 기반 토큰화(tokenization)에 활용됩니다.
-
구문론(Syntax):
- 기준: 문장 구조와 문법 규칙
- 설명: 구문론은 단어들이 결합되어 문장을 이루는 규칙을 연구합니다. 자연어 처리에서는 문장 구문 분석(parsing)을 통해 문법적으로 올바른 문장을 분석하고 생성하는 데 사용됩니다.
-
의미론(Semantics):
- 기준: 의미와 해석
- 설명: 의미론은 단어, 구, 문장의 의미를 연구합니다. 자연어 처리에서는 텍스트의 의미를 추출하고, 문맥을 이해하며, 의미 기반 검색 및 질의응답 시스템에 활용됩니다.
-
화용론(Pragmatics):
- 기준: 언어 사용의 맥락과 목적
- 설명: 화용론은 언어가 실제 상황에서 어떻게 사용되는지를 연구합니다. 자연어 처리에서는 대화 시스템, 챗봇 등에서 사용자의 의도를 파악하고 적절한 응답을 생성하는 데 중요합니다.
-
담론(Discourse):
- 기준: 문장 간의 관계와 맥락
- 설명: 담론은 문장들이 결합되어 더 큰 텍스트나 대화를 형성하는 방식을 연구합니다. 자연어 처리에서는 텍스트 요약, 문서 분류, 대화의 일관성 유지 등에 적용됩니다.
1.2 우리는 지금 어느 단계인가?
-
현재 자연어 처리(NLP)의 발전 수준을 평가할 때, 음운론, 형태론, 구문론, 의미론, 화용론, 담론의 6가지 영역에서 각각의 성과를 고려할 수 있습니다.
-
각각의 영역에서 현재 기술이 어느 정도 성숙되었는지 살펴보면 다음과 같습니다:
1. 음운론 (Phonology)
- 음성 인식(Speech Recognition): 매우 높은 정확도로 음성을 텍스트로 변환하는 기술이 개발되었습니다.
- 텍스트 음성 변환(Text-to-Speech): 자연스러운 음성을 생성하는 TTS 기술도 상당히 발전했습니다. DeepMind의 WaveNet과 같은 모델이 그 예입니다.
- 수준: 매우 발전되어 실용화 단계.
- 상용화 예시: Siri, Google Assistant, Amazon Alexa 등의 음성 비서 기능

2. 형태론 (Morphology)
- 형태소 분석(Morphological Analysis): 형태소 분석기와 토크나이저(tokenizer)가 다수 개발되었으며, 한국어, 일본어, 핀란드어 등 형태가 복잡한 언어에서도 높은 성능을 보입니다.
- 수준: 성숙 단계로, 다양한 언어에 대해 높은 정확도를 보임.
- 상용화 예시: Grammarly, Microsoft, 한컴 등의 맞춤법 검사 기능
3. 구문론 (Syntax)
- 구문 분석(Parsing): 구문 분석기는 CFG, PCFG, Dependency Parsing 등 다양한 방식으로 발전되어 왔습니다. 최근에는 BERT, GPT 등 Transformer 기반 모델들이 구문 분석에서도 좋은 성과를 보이고 있습니다.
- 수준: 실용화 단계로, 많은 NLP 응용에서 활용 가능.
- 사용화 예시: Stanford Parser, spaCy, NLTK 라이브러리
🤔Stanford Parser, spaCy, NLTK?
Stanford Parser:
- Stanford 대학에서 개발한 자연어 구문 분석기입니다.
- 다양한 언어(영어, 중국어, 아랍어, 독일어, 프랑스어, 스페인어 등)에 대한 구문 분석을 지원합니다.
- 구성성분 분석(constituency parsing)과 의존 구문 분석(dependency parsing)을 모두 제공합니다.
- PCFG(Probabilistic Context-Free Grammar), Shift-Reduce, Neural Network 기반의 의존 구문 분석기를 포함합니다.
- 오픈 소스로 제공되며, 비상업적 용도로는 무료로 사용할 수 있습니다.
spaCy:
- 산업용 강도의 자연어 처리를 위한 Python 라이브러리입니다.
- 토큰화, 품사 태깅, 개체명 인식, 의존 구문 분석 등 다양한 NLP 작업을 지원합니다.
- 빠른 처리 속도와 높은 정확도로 알려져 있습니다.
- 사전 훈련된 모델을 제공하여 쉽게 사용할 수 있습니다.
- 다국어 지원을 제공합니다.
NLTK (Natural Language Toolkit):
NLTK는 교육과 연구 목적으로 설계되었으며, 다양한 NLP 작업을 지원합니다.
- 토큰화: 문장과 단어 단위로 텍스트를 분할합니다.
- 품사 태깅: 각 단어에 대해 품사 정보를 부여합니다.
- 구문 분석: 구성성분 분석과 의존 구문 분석을 지원합니다.
- 어휘 자원: WordNet과 같은 어휘 자원을 포함하여 단어의 의미를 분석합니다.
- 텍스트 전처리: 불용어 제거, 어간 추출, 표제어 추출 등 다양한 전처리 작업을 지원합니다.
4. 의미론 (Semantics)
- 의미 분석(Semantic Analysis): 단어 임베딩(word embedding), 문장 임베딩 등의 기술이 발전하면서 문장의 의미를 효과적으로 추출할 수 있게 되었습니다. BERT, GPT-3 같은 대형 언어 모델들이 문맥을 이해하고 적절한 응답을 생성하는 능력을 보유하고 있습니다.
- 수준: 매우 발전된 단계로, 실생활 응용에서 활용 중.
- 사용화 예시: Word2Vec, BERT, GPT 등의 언어 모델
5. 화용론 (Pragmatics)
- 대화 시스템(Dialogue Systems): 사용자 의도를 이해하고 적절히 응답하는 챗봇과 대화 에이전트가 활발히 연구되고 있습니다. 실제 상용 제품들도 등장했지만, 아직 완벽하지는 않습니다.
- 맥락 이해(Context Understanding): 상황에 맞는 적절한 언어 사용을 이해하는 데 있어 제한적인 성과를 보이고 있습니다.
- 수준: 발전 중, 상당한 개선 여지 있음
- 사용화 예시: 챗봇, 고객 서비스 자동화 시스템
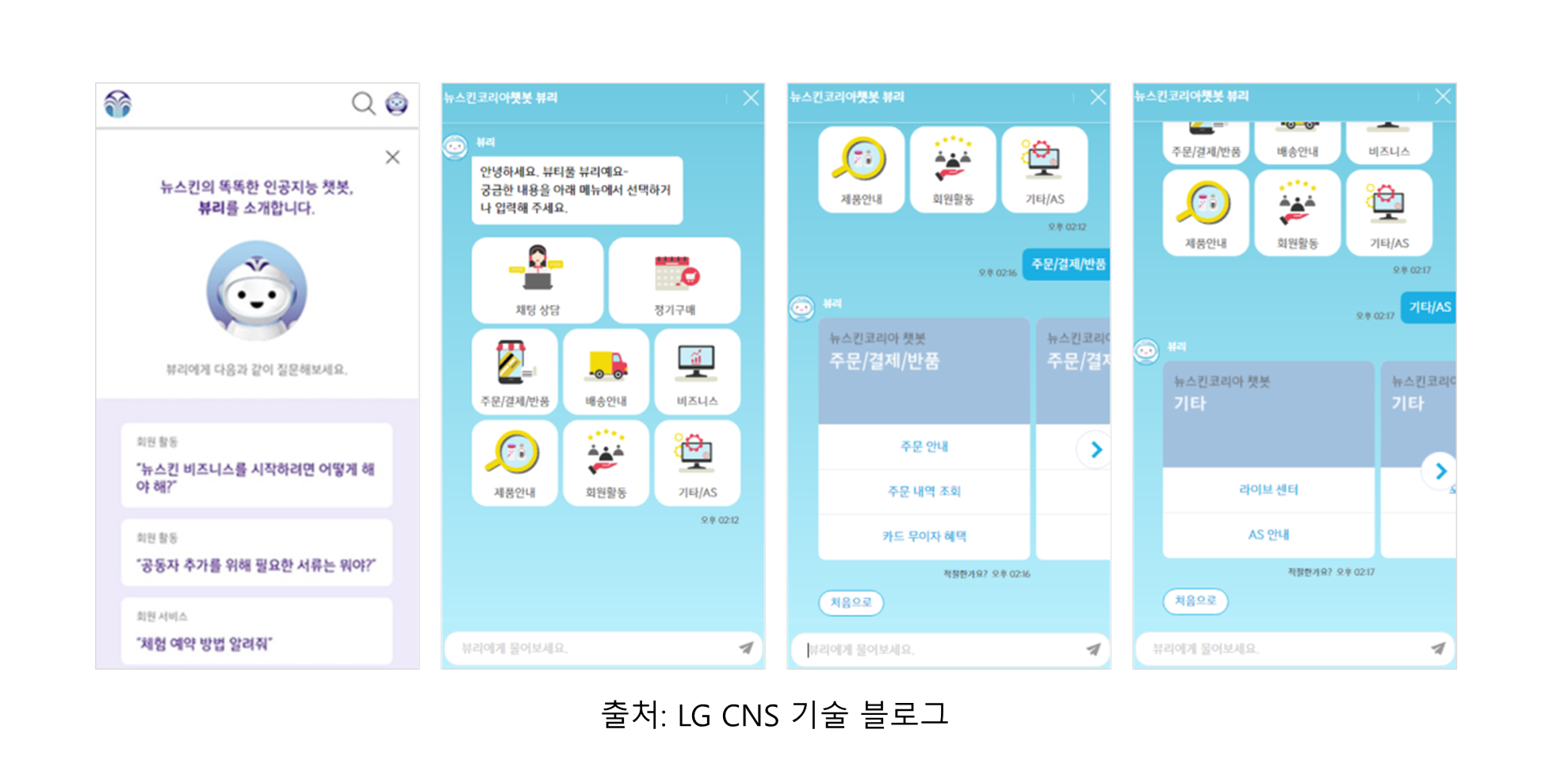
6. 담론 (Discourse)
- 텍스트 일관성(Text Coherence): 긴 문맥을 유지하고 일관성 있는 텍스트를 생성하는 능력이 향상되었습니다. GPT-3와 같은 모델들이 긴 문서 생성에서 좋은 성과를 보이고 있습니다.
- 담론 분석(Discourse Analysis): 문장 간의 관계를 이해하고, 일관된 대화를 유지하는 데에는 아직 한계가 있습니다.
- 수준: 초기 단계, 많은 개선 필요
- 사용화 예시: 자동 요약 도구, 대화형 AI 시스템
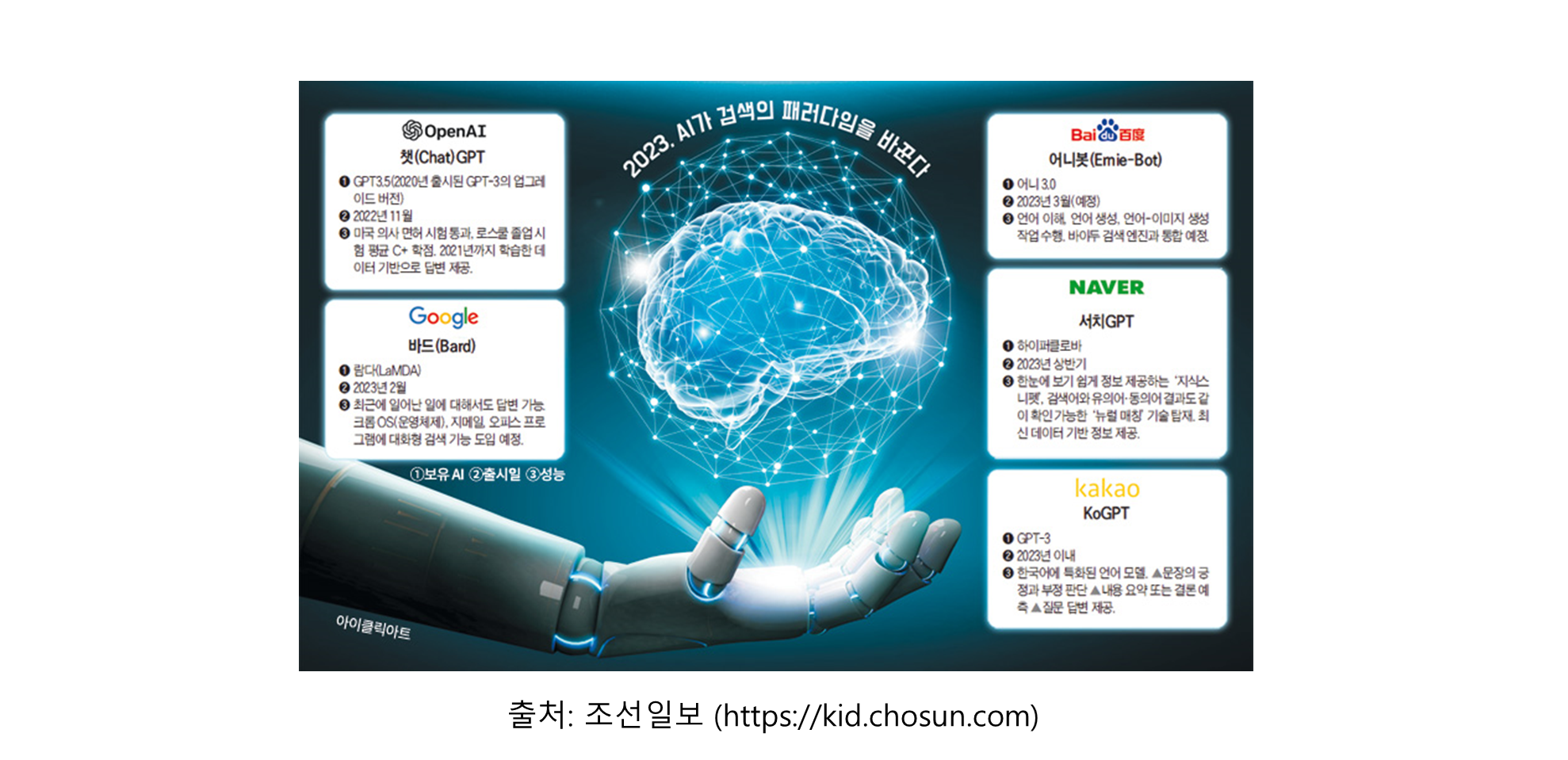
🔎 챗봇 vs 대화형 챗봇, 무엇이 다른가?
챗봇과 대화형 AI의 차이점을 이해하기 위해 두 기술을 비교해 보겠습니다. 이미지를 기반으로 두 기술의 주요 차이점을 정리합니다.
챗봇 (Chatbots) 🗣️
- 기반 기술: 규칙 기반(rule-based) 또는 사전에 정의된 스크립트(predefined scripts)를 사용하여 특정 질의나 명령에 응답합니다.
- 이해 능력: 자연어를 이해하고 생성하는 능력이 제한적이며, 복잡한 대화를 잘 처리하지 못합니다.
- 응답 방식: 특정 입력에 대해 미리 정의된 응답을 제공하는 데 중점을 둡니다.
- 적용 분야: 주로 고객 지원, FAQ, 간단한 정보 제공 등에 사용됩니다.
대화형 AI (Conversational AI) 🎙️
- 기반 기술: 자연어 처리(NLP), 머신 러닝(ML), 인공지능(AI) 등의 다양한 기술을 포함하는 넓은 범위의 기술입니다. 이를 통해 기계가 자연어로 인간과 같은 응답을 이해하고, 처리하며, 생성할 수 있습니다.
- 이해 능력: 더 발전된 기술을 사용하여 문맥, 감정, 언어의 미묘한 차이를 이해하고 처리할 수 있습니다.
- 응답 방식: 상호작용에서 학습하고, 사용자 입력에 따라 적응하며, 더 복잡하고 동적인 대화를 처리할 수 있습니다.
- 적용 분야: 고객 지원, 비즈니스 프로세스 자동화, 개인 비서, 복잡한 질의응답 시스템 등 다양한 분야에서 사용됩니다.

-
현재 NLP 기술의 발전 단계는
4~5 영역에 걸쳐 있으며, 각 영역에서 다음과 같은 특징을 보입니다:-
의미론 (Semantics)영역에서는 상당한 진전을 이루어 실용적인 수준에 도달했지만, 여전히 인간 수준의 이해와 해석에는 미치지 못합니다.- 과제: 복잡한 추론, 상식적 이해, 은유 해석 등에서 여전히 개선이 필요합니다.
-
화용론 (Pragmatics)영역은 의미론보다는 덜 발전했지만, 실제 응용 분야에서 점차 활용되고 있습니다. 특히 대화 시스템과 감정 분석 등에서 유용성을 보이고 있습니다.- 과제: 화자의 의도, 암시적 의미, 사회문화적 맥락 이해 등에서 인간 수준의 이해를 달성하는 것이 목표입니다.
-
담론 (Discourse)영역은 가장 복잡하고 도전적인 영역으로, 현재 초기 연구 단계에 있습니다. 이 영역의 발전은 향후 NLP 기술의 큰 도약을 가져올 것으로 예상됩니다.- 과제: 긴 문맥을 유지하면서 일관성 있는 대화를 이어가는 능력, 복잡한 논리 구조 이해 등이 주요 과제입니다.
-
전반적으로, NLP 기술은 이 세 영역에서 지속적으로 발전하고 있지만, 인간 수준의 언어 이해와 생성을 위해서는 아직 많은 연구와 혁신이 필요한 상태입니다. (=> 지금도 활발하게 연구가 진행되고 있습니다)
2. NLP의 어려움과 역사
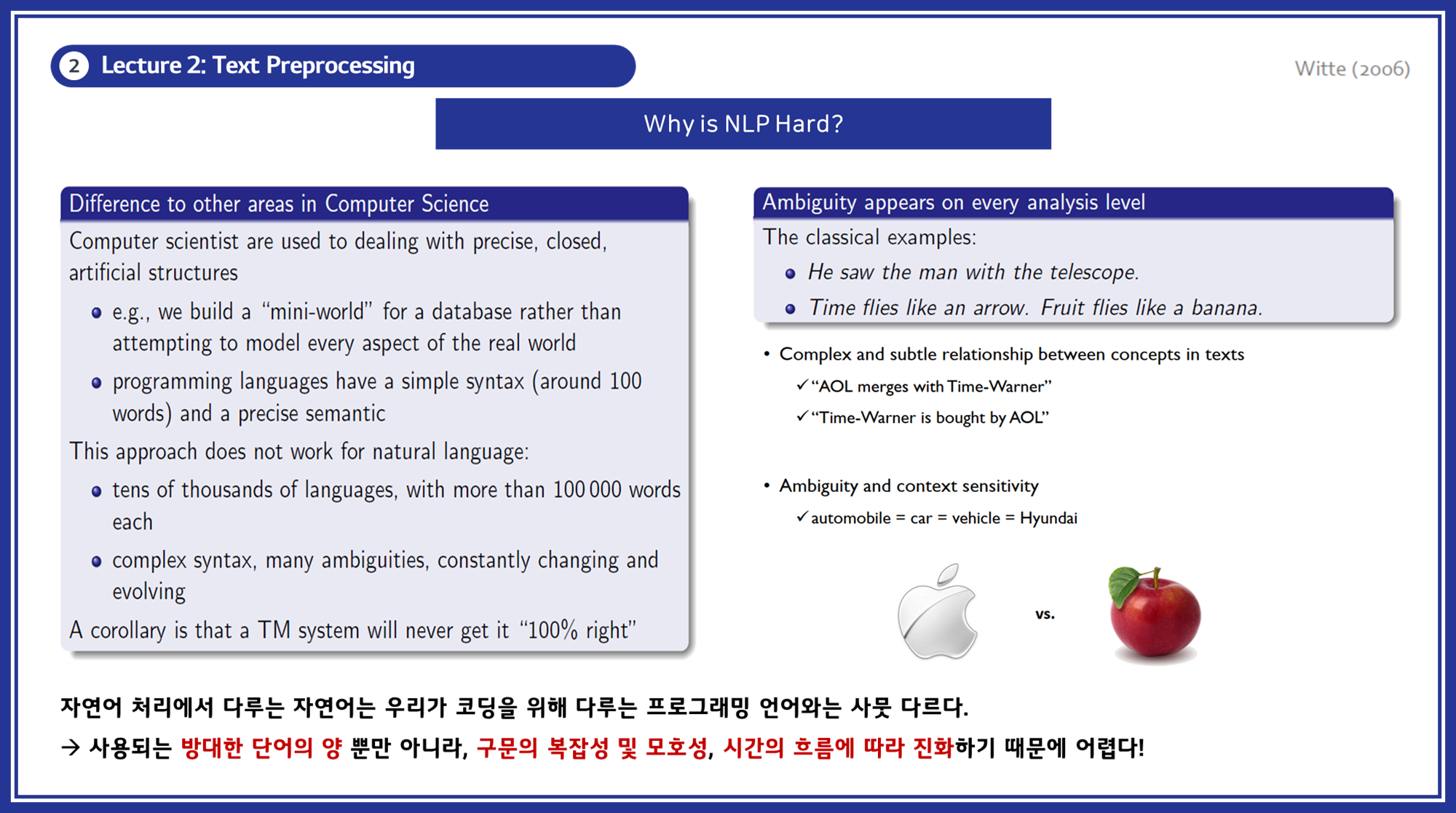
- 왜 NLP가 어려운가? : 자연어는 프로그래밍 언어와 달리 방대한 단어의 양, 복잡한 구문, 모호성 등으로 인해 다루기 어렵습니다. 사용되는 방대한 단어의 양 뿐만 아니라, 구문의 복잡성 및 모호성, 시간의 흐름에 따라 진화하기 때문에 초기 NLP연구에 어려움이 존재했습니다.
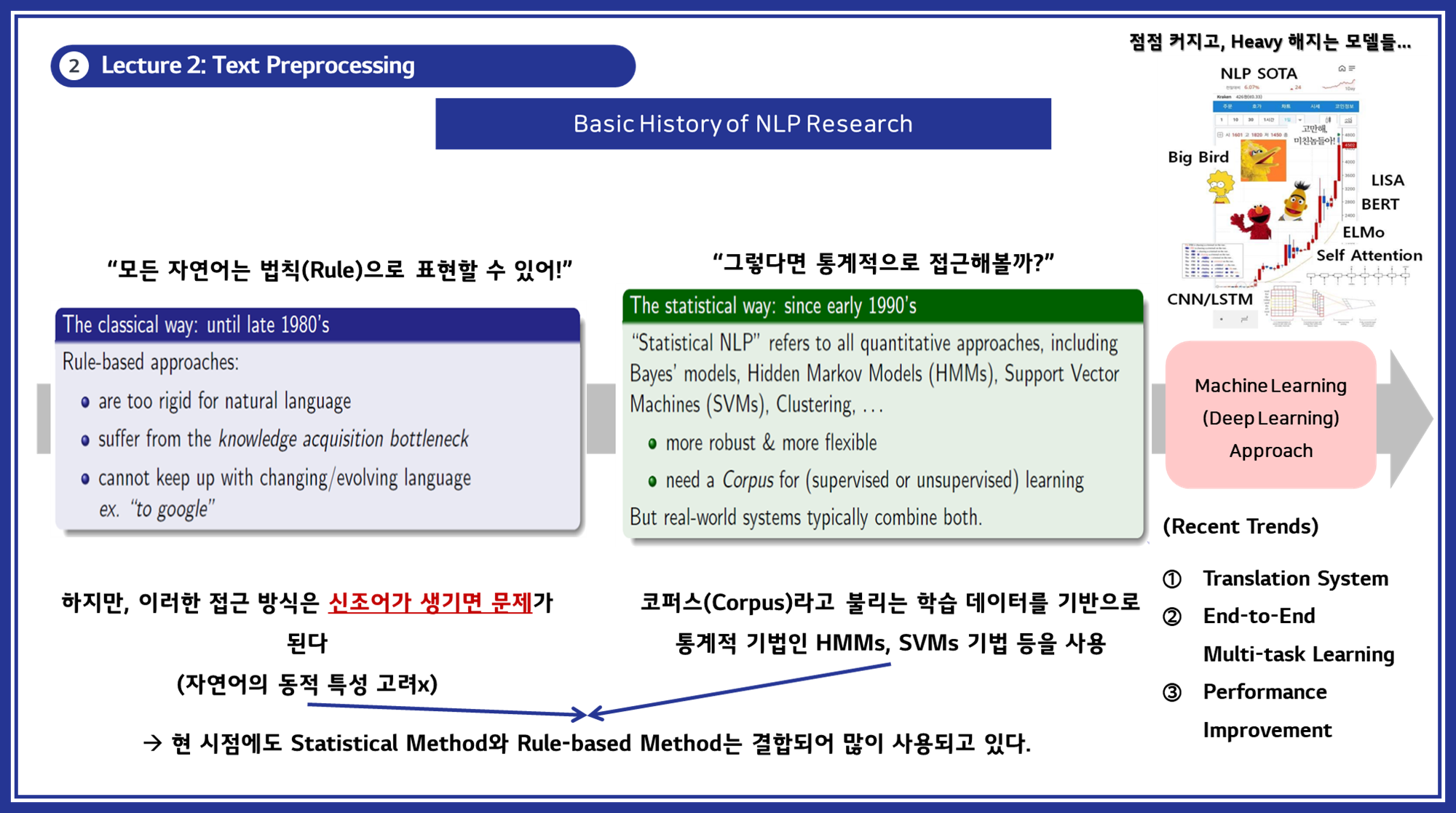
- NLP 연구의 역사 : 초기에는 규칙 기반 접근법이 주로 사용되었지만, 자연어의 동적 특성을 고려하지 못하는 단점이 있었습니다. 현재는 통계적 방법과 규칙 기반 방법을 결합하여 사용하며, 머신 러닝 및 딥 러닝 기반 접근법이 주류를 이루고 있습니다.
3. Lexical Analysis
3.1. 토큰화 (Tokenization)
토큰화는 텍스트를 작은 의미 단위로 분할하는 과정입니다. 이러한 단위는 단어, 구, 심지어는 개별 문자일 수도 있습니다. 예를 들어, "Hello, world!"라는 문장은 ["Hello", ",", "world", "!"]로 분할될 수 있습니다. 토큰화는 텍스트의 구조를 이해하고 각 단어가 어떻게 사용되는지를 분석하는 데 필수적입니다.
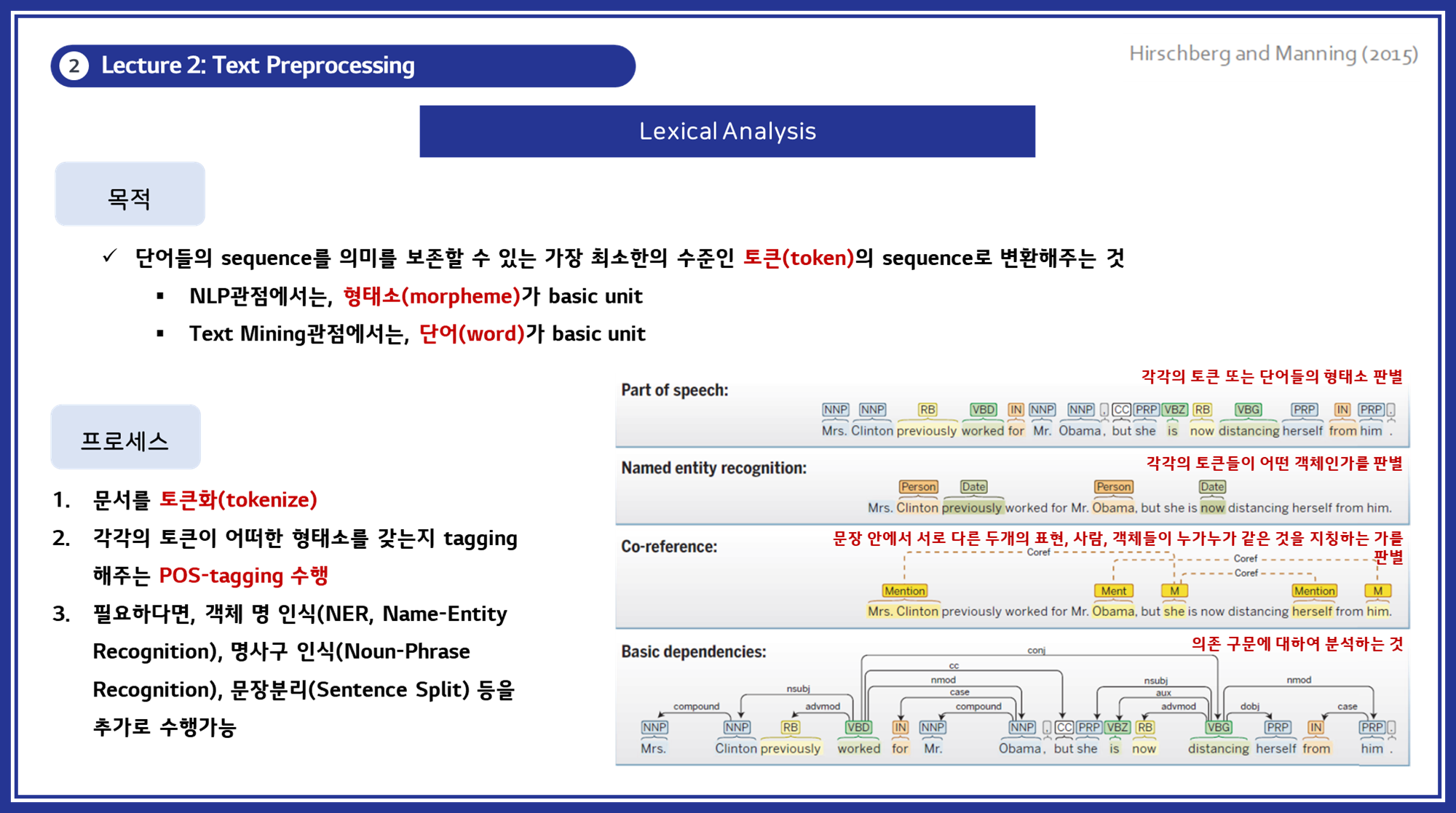
토큰화에는 여러 가지 방법이 있습니다:
- 공백 기반 토큰화: 공백을 기준으로 단어를 분리합니다.
- 구두점 기반 토큰화: 구두점도 별도의 토큰으로 처리합니다.
- 어절 기반 토큰화: 언어적 의미를 고려하여 어절 단위로 분리합니다. (한국어와 같은 언어에서 특히 중요합니다)
코드 예시
from nltk.tokenize import word_tokenize
sentence = "Hello, world! Welcome to NLP."
tokens = word_tokenize(sentence)
print(tokens)출력: ['Hello', ',', 'world', '!', 'Welcome', 'to', 'NLP', '.']
3.2. 형태소 분석 (Morphological Analysis)
형태소 분석은 단어의 내부 구조를 분석하고 변환하는 과정입니다. 이는 단순히 단어를 분리하는 토큰화 단계보다 더 깊은 분석을 포함합니다. 형태소 분석은 주로 두 가지 주요 작업으로 나뉩니다:
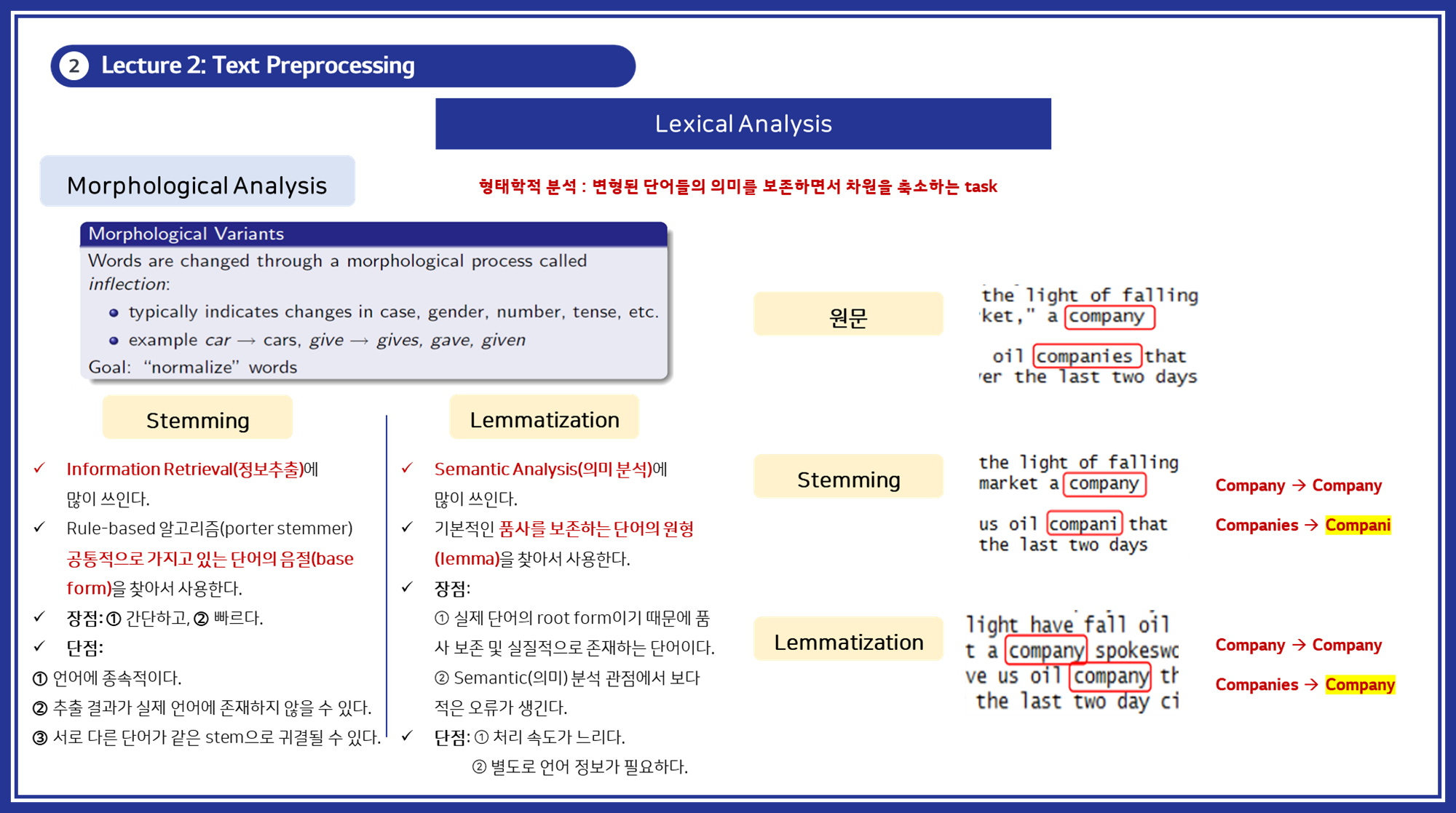
-
형태소(Morpheme) 식별: 단어를 구성하는 최소 의미 단위인 형태소를 식별합니다. 형태소는 자립 형태소(독립적으로 사용될 수 있는 단어)와 의존 형태소(다른 형태소와 결합되어야 의미를 갖는 단어)로 나뉩니다.
- 예시: "unhappiness"는 "un-", "happy", "-ness"의 세 가지 형태소로 구성됩니다.
-
형태소 변형(Morphological Inflection): 단어가 문법적 형태를 나타내기 위해 변형되는 과정을 분석합니다. 이는 다음 두 가지 방법으로 수행됩니다:
- Stemming: 단어의 어간(Stem)을 추출합니다. 이는 단어의 변형된 형태들을 동일하게 인식하기 위한 방법입니다. 예를 들어, "running", "runner", "ran"은 모두 "run"으로 변환될 수 있습니다. Stemming은 규칙 기반 알고리즘을 주로 사용하며, 단어의 일부분을 제거하는 방식으로 구현됩니다.
- 예시: Porter Stemmer, Snowball Stemmer
- Lemmatization: 단어의 기본 형태(Lemma)를 찾아내는 과정입니다. 이는 어휘 형태소 분석을 포함하여 단어의 품사 정보를 고려합니다. 예를 들어, "running"은 "run"으로, "better"는 "good"으로 변환될 수 있습니다. Lemmatization은 언어적 지식(사전)을 바탕으로 단어를 변환합니다.
- 예시: WordNet Lemmatizer
- Stemming: 단어의 어간(Stem)을 추출합니다. 이는 단어의 변형된 형태들을 동일하게 인식하기 위한 방법입니다. 예를 들어, "running", "runner", "ran"은 모두 "run"으로 변환될 수 있습니다. Stemming은 규칙 기반 알고리즘을 주로 사용하며, 단어의 일부분을 제거하는 방식으로 구현됩니다.
코드 예시
from nltk.stem import PorterStemmer, WordNetLemmatizer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
word1 = "running"
word2 = "better"
print(stemmer.stem(word1)) # 출력: run
print(lemmatizer.lemmatize(word1, pos='v')) # 출력: run
print(lemmatizer.lemmatize(word2, pos='a')) # 출력: good출력:
run
run
good3.3. 문장 분할 (Sentence Splitting)
문장 분할은 텍스트를 개별 문장으로 분리하는 과정입니다. 이는 구두점이나 문장의 구조를 기준으로 이루어집니다. 문장 분할은 텍스트 분석의 단위를 명확히 하는 데 중요합니다.
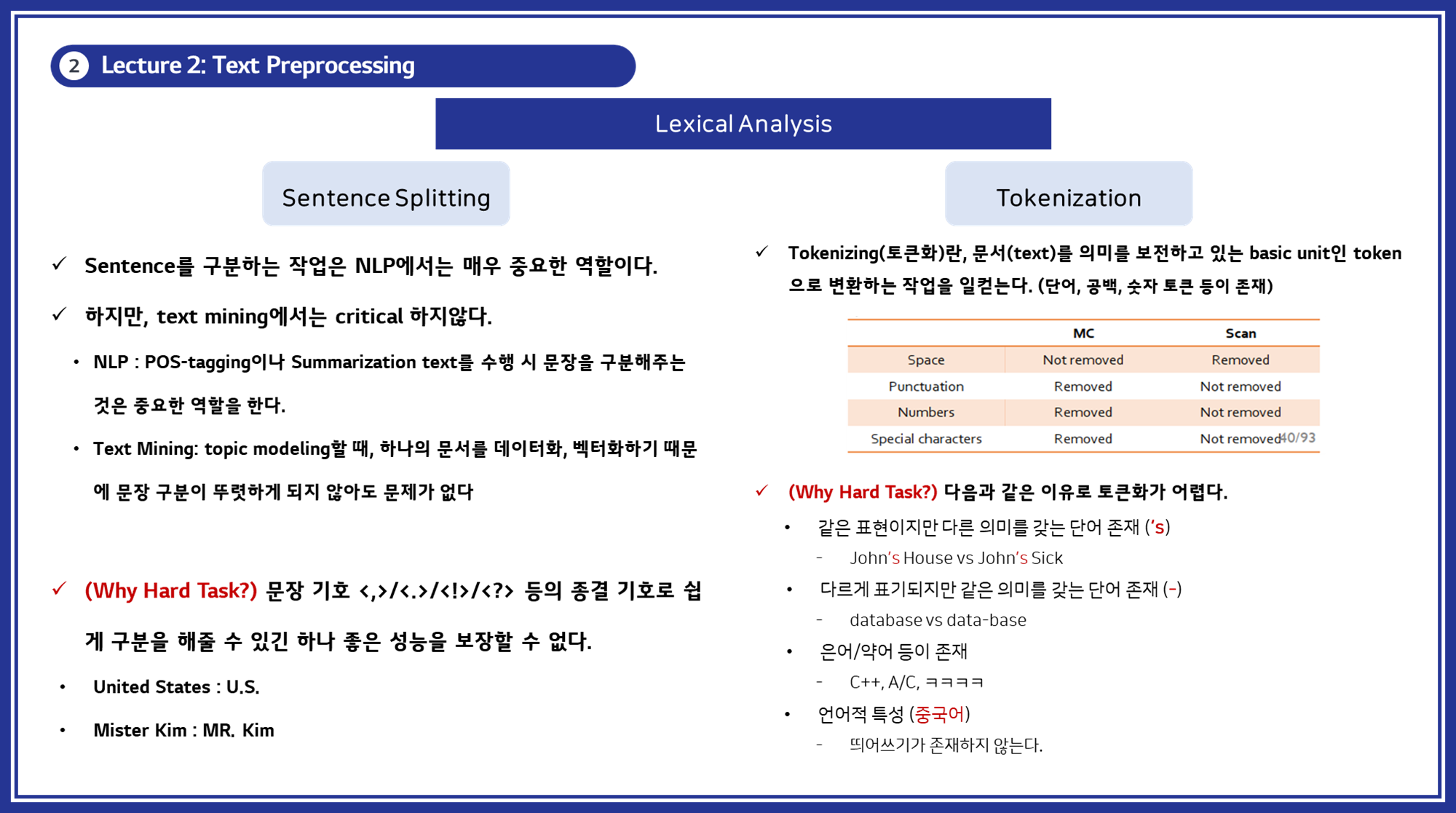
코드 예시
from nltk.tokenize import sent_tokenize
text = "Hello world! How are you doing? NLP is interesting."
sentences = sent_tokenize(text)
print(sentences)출력: ['Hello world!', 'How are you doing?', 'NLP is interesting.']
3.4. 품사 태깅 (Part-of-Speech Tagging)
품사 태깅은 문장에서 각 단어에 해당하는 품사를 할당하는 과정입니다. 이는 문장의 구문 구조를 이해하고, 단어 간의 관계를 파악하는 데 도움을 줍니다.
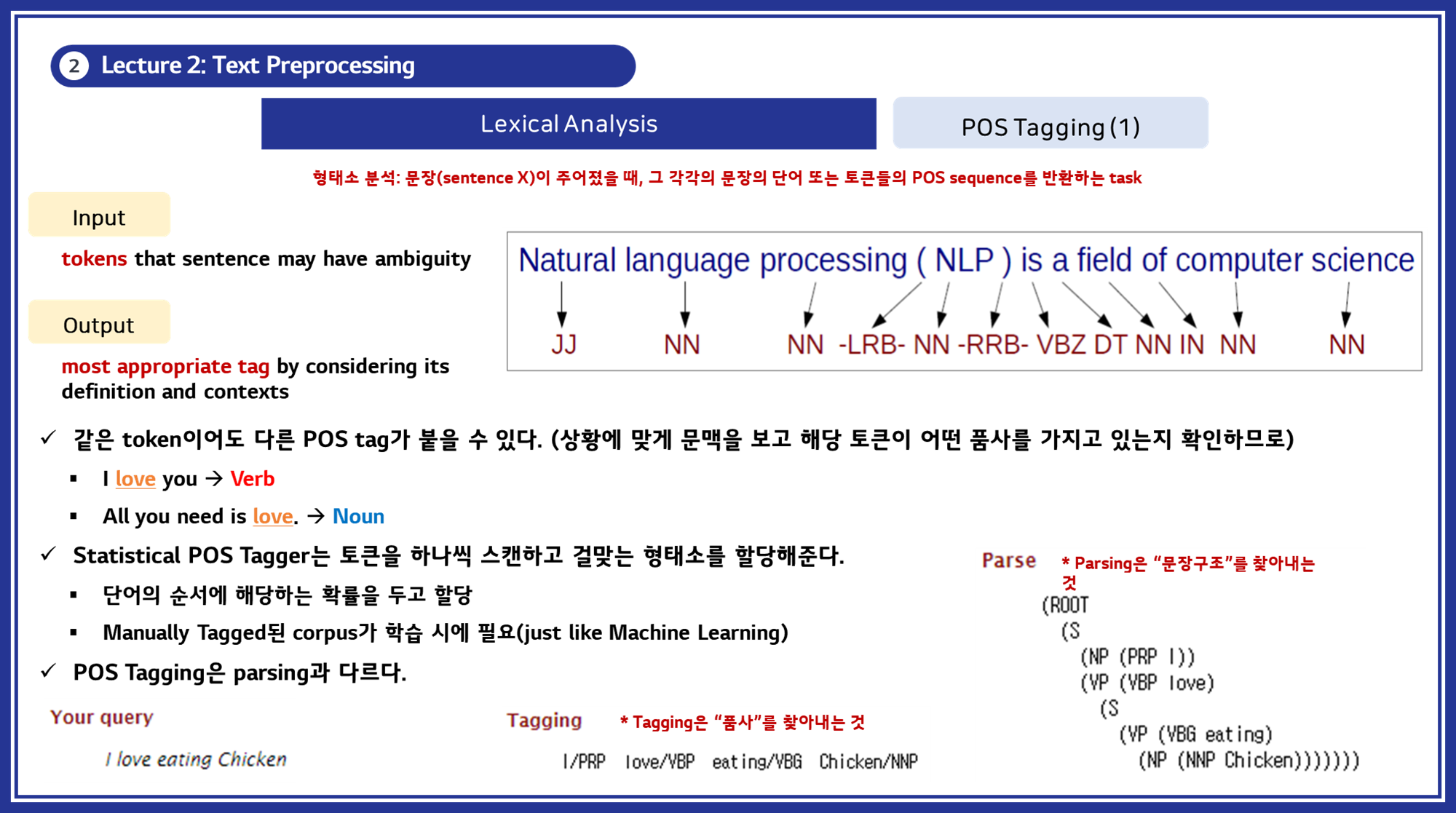
품사 태깅은 주로 다음과 같은 알고리즘을 사용합니다:
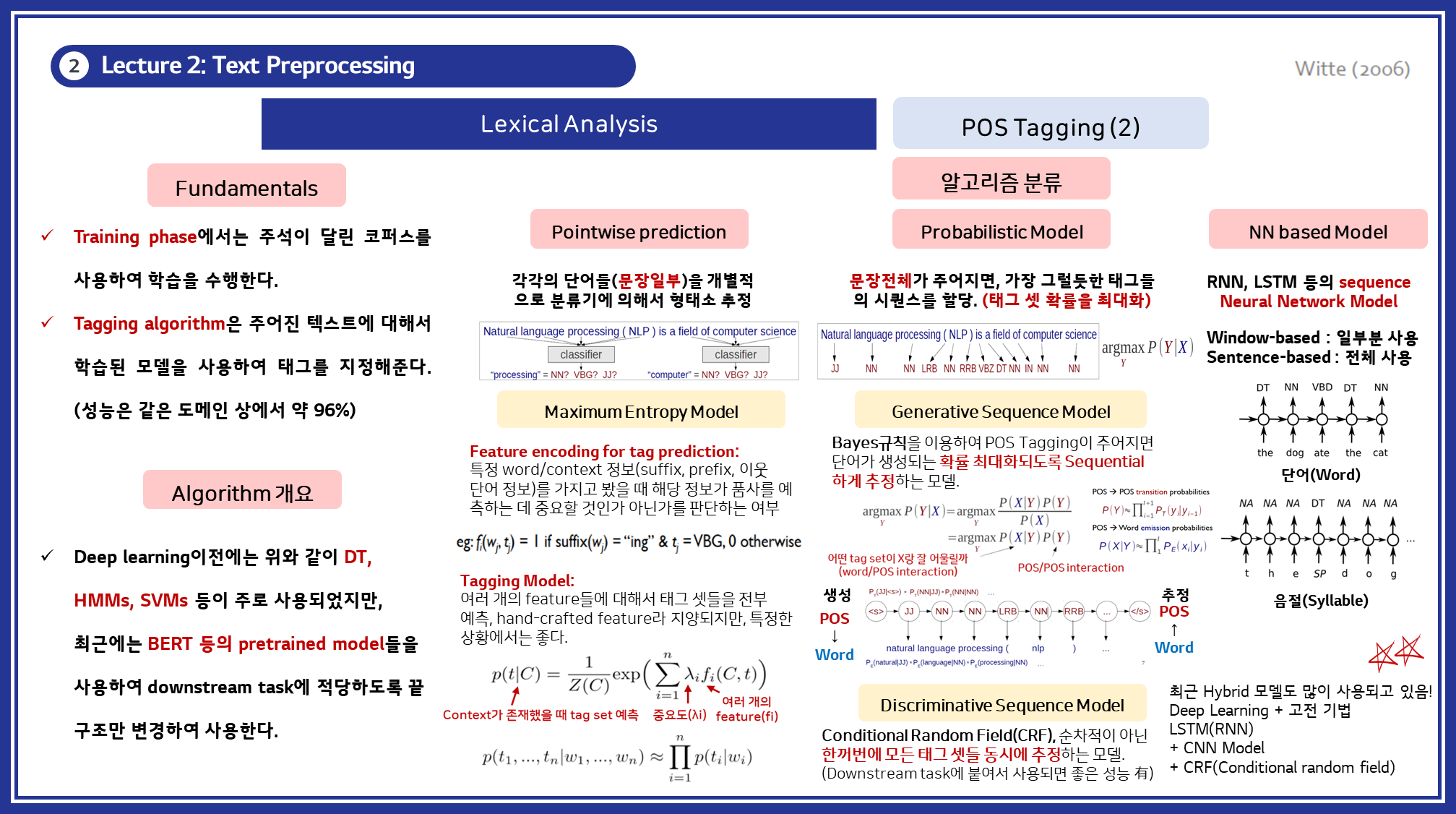
- 규칙 기반 태깅(Rule-Based Tagging): 정해진 문법 규칙을 이용하여 단어의 품사를 결정합니다.
- 통계적 태깅(Statistical Tagging): 코퍼스 데이터를 이용하여 품사를 확률적으로 예측합니다. HMM(Hidden Markov Model)이나 Maximum Entropy 모델이 사용됩니다.
- 기계 학습 기반 태깅(Machine Learning-Based Tagging): 지도 학습을 통해 품사를 예측합니다. SVM, Decision Tree, 그리고 최근에는 신경망 모델(Neural Networks)을 사용합니다.
- 예시: CRF(Conditional Random Fields), Bi-LSTM
코드 예시
import nltk
nltk.download('averaged_perceptron_tagger')
sentence = "I love eating chicken."
tokens = word_tokenize(sentence)
pos_tags = nltk.pos_tag(tokens)
print(pos_tags)출력: [('I', 'PRP'), ('love', 'VBP'), ('eating', 'VBG'), ('chicken', 'NN')]
4. Named Entity Recognition (NER)
- 객체명 인식 (Named Entity Recognition, NER) : 객체명 인식은 문장에서 특정 요소를 미리 정의된 카테고리(예: 사람, 장소, 조직, 날짜 등)로 분류하는 작업입니다. 이는 텍스트 데이터에서 중요한 정보를 추출하는 데 사용됩니다.
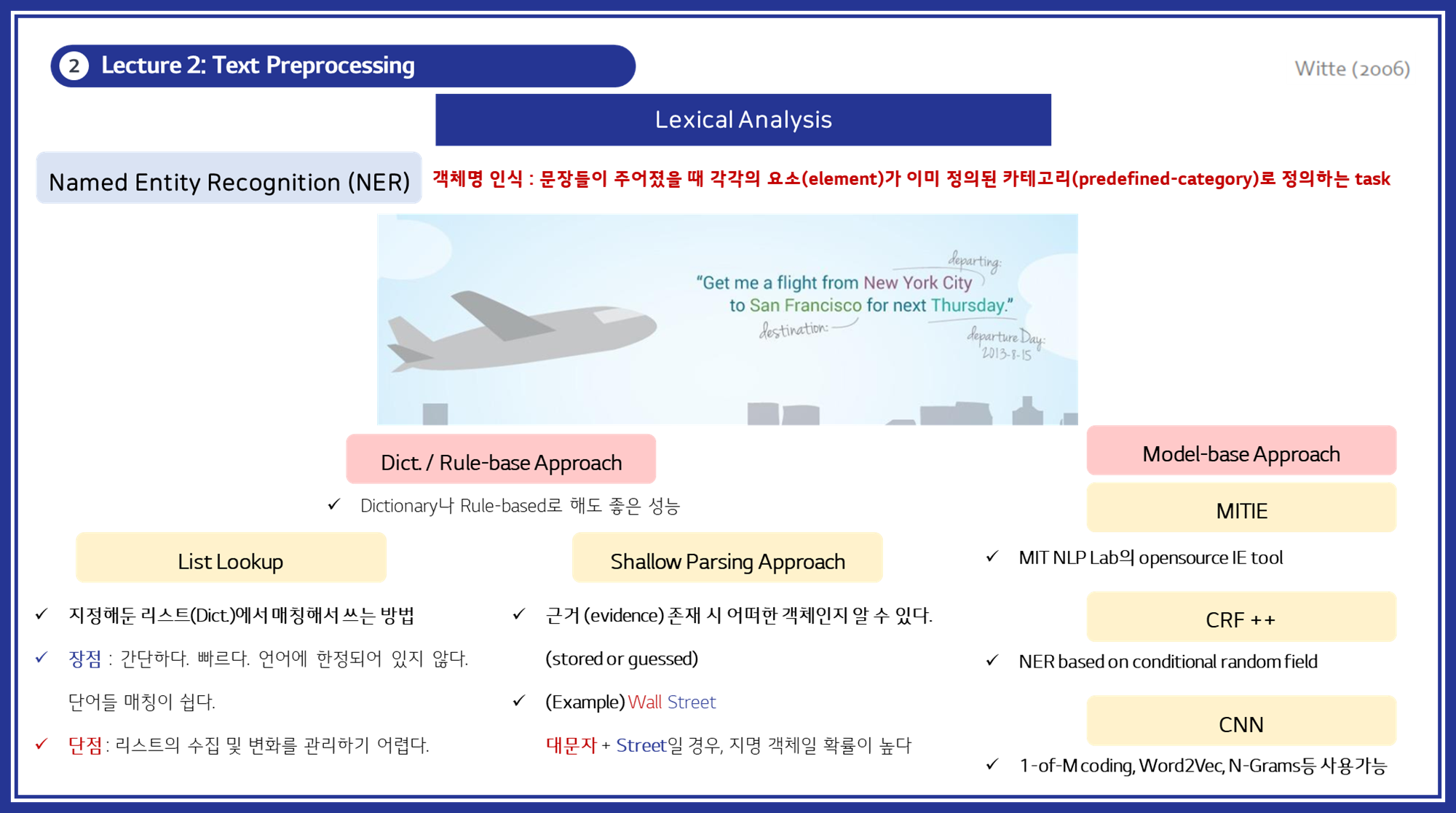
접근 방법
1. 사전 기반 접근법 (Dictionary / Rule-based Approach)
- List Lookup: 사전에 정의된 리스트를 사용하여 텍스트에서 해당 단어를 검색합니다.
- 장점: 간단하고 빠르며, 특정 언어에 특화된 처리가 가능합니다.
- 단점: 리스트의 크기와 유지 관리가 어렵고, 새로운 단어나 변화에 민감합니다.
- Shallow Parsing Approach: 근거 있는 증거(evidence)를 기반으로 텍스트에서 객체를 추출합니다.
- 예시: "Wall Street"에서 "Street"과 같은 단어를 통해 지명을 인식합니다.
- 모델 기반 접근법 (Model-based Approach)
- CRF (Conditional Random Fields): 문맥을 고려하여 단어의 카테고리를 예측합니다.
- 신경망 기반 모델 (Neural Network-based Models): RNN, CNN 등을 사용하여 문맥 정보를 학습합니다.
- 장점: 문맥을 잘 반영하여 높은 정확도를 보입니다.
- 단점: 많은 학습 데이터와 계산 자원이 필요합니다.
코드 예시
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Barack Obama was born in Hawaii.")
for ent in doc.ents:
print(ent.text, ent.label_)출력: Barack Obama PERSON, Hawaii GPE
5. Syntax Analysis (구문 분석)
구문 분석 (Syntax Analysis) : 구문 분석은 문장에서 단어들이 어떻게 구조적으로 연결되어 있는지를 분석하는 작업입니다. 이는 문장의 문법적 구조를 이해하고 각 단어의 관계를 파악하는 데 중요합니다.
5.1. Parsing

- Top-down Parsing: 문장의 시작부터 문법 규칙을 적용하여 구조를 분석합니다.
- Bottom-up Parsing: 단어부터 시작하여 문법 규칙을 역으로 적용하여 구조를 분석합니다.
5.2. 모호성 (Ambiguity)
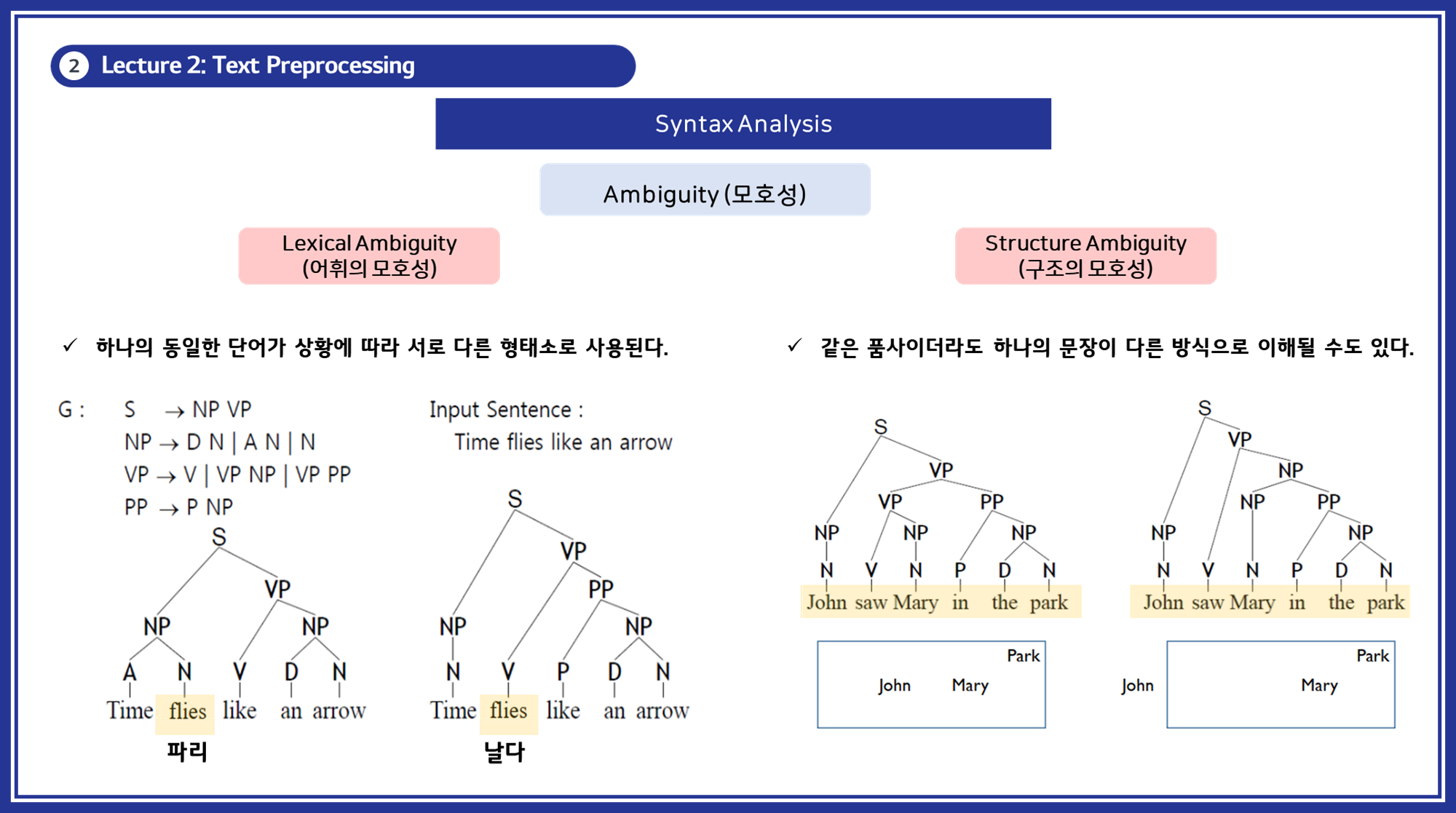
구문 분석에서 중요한 문제는 모호성을 해결하는 것입니다.
- 구조의 모호성 (Structural Ambiguity): 같은 문장이 여러 방식으로 해석될 수 있습니다.
- 예시: "John saw Mary in the park." (존이 공원에서 메리를 봤다 / 존이 메리를 봤는데, 메리는 공원에 있다)
- 어휘의 모호성 (Lexical Ambiguity): 같은 단어가 상황에 따라 다른 형태소로 사용될 수 있습니다.
- 예시: "Time flies like an arrow." (시간은 화살처럼 날아간다 / 파리는 화살을 좋아한다)
코드 예시
import nltk
sentence = "John saw the man with a telescope."
grammar = nltk.CFG.fromstring("""
S -> NP VP
VP -> V NP | VP PP
PP -> P NP
V -> "saw"
NP -> "John" | "man" | "telescope" | Det N | NP PP
Det -> "a" | "the"
N -> "man" | "telescope"
P -> "with"
""")
parser = nltk.ChartParser(grammar)
for tree in parser.parse(sentence.split()):
print(tree)6. 언어 모델링 (Language Modeling)
확률적 언어 모델 (Probabilistic Language Modeling) : 언어 모델링은 주어진 문장이 실제 문법적으로 타당한지 평가하는 모델입니다. 이는 문장의 문법적 구조와 단어 간의 관계를 이해하는 데 사용됩니다.
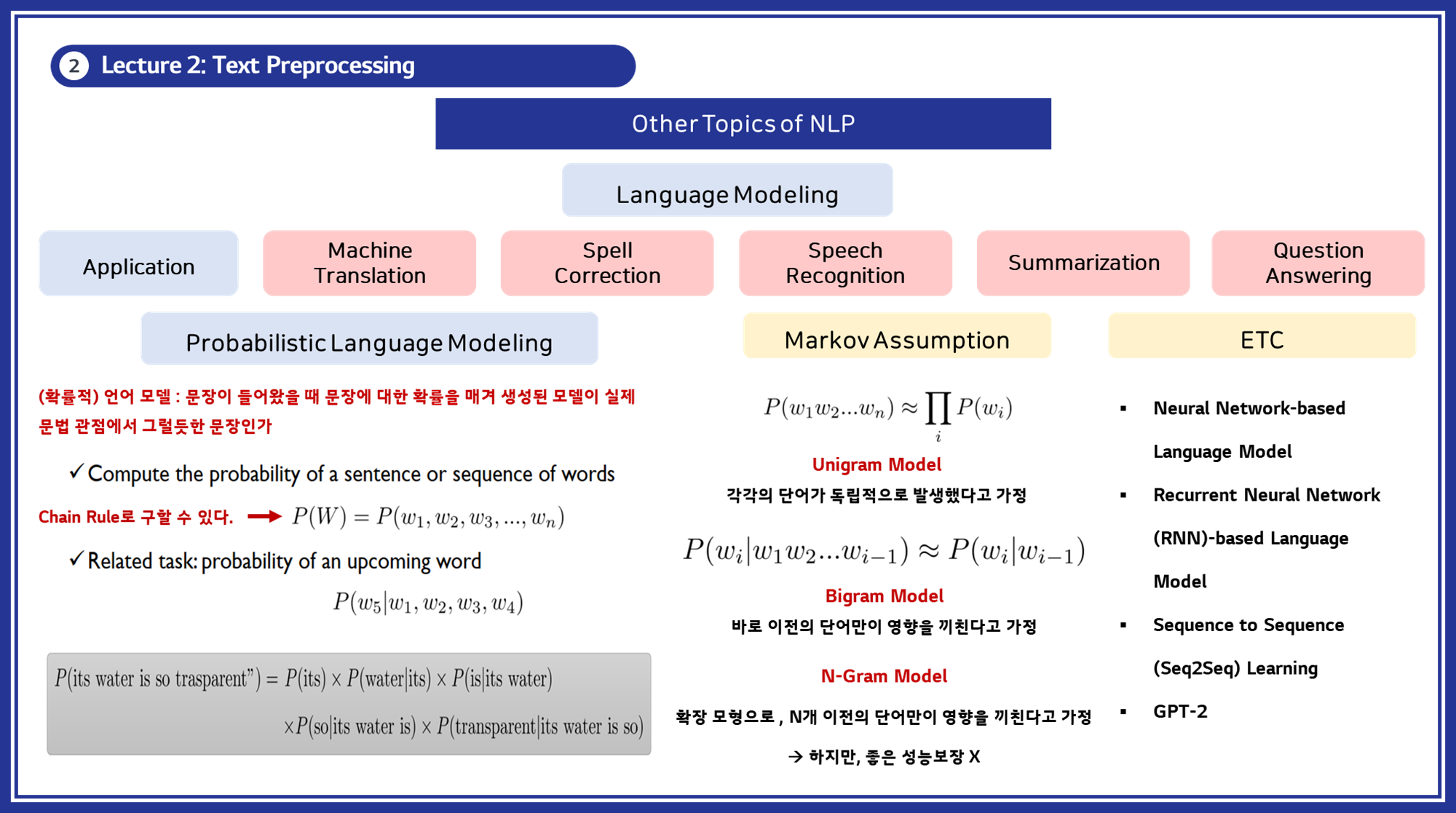
접근 방법
1. N-그램 모델 (N-gram Models)
- 단어의 연속적인 패턴을 분석하여 다음 단어의 확률을 예측합니다.
- Unigram: 단어 하나의 확률
- Bigram: 두 단어의 연속 확률
- Trigram: 세 단어의 연속 확률
- 신경망 기반 모델 (Neural Network-based Models)
- RNN, LSTM, Transformer와 같은 모델을 사용하여 문맥 정보를 학습합니다.
- BERT, GPT-2: 사전 학습된 대규모 언어 모델로, 문맥을 잘 반영하여 높은 성능을 보입니다.
응용 분야
- 기계 번역 (Machine Translation)
- 철자 교정 (Spell Correction)
- 음성 인식 (Speech Recognition)
- 요약 (Summarization)
- 질의 응답 시스템 (Question Answering)
코드 예시
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
input_text = "Natural language processing is"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=50, num_return_sequences=1)
print(tokenizer.decode(output[0], skip_special_tokens=True))