
Introduction to Text Analytics
Text Analytics는 문서(text)와 같은 비정형 데이터를 분석하여 그 속에 포함된 의미 있는 정보를 추출하는 과정을 의미합니다.- 이는 자연어 처리(Natural Language Processing, NLP) 기술을 활용하여 다양한 형태의 텍스트 데이터를 처리하고 분석함으로써 지식과 통찰을 얻는 것을 목표로 합니다.

Text Analytics의 주요 응용 분야

- Text Analytics는 다양한 응용 분야에서 활용됩니다:
- 정보 추출/요약/시각화: 문서의 주요 정보를 추출하고 이를 요약하거나 시각화하는 작업입니다.
- 제목 추출: 문서의 내용을 기반으로 적절한 제목을 자동으로 생성합니다.
- 스팸 메일 필터링: 스팸 메일을 자동으로 분류하여 사용자에게 전달되지 않도록 합니다.
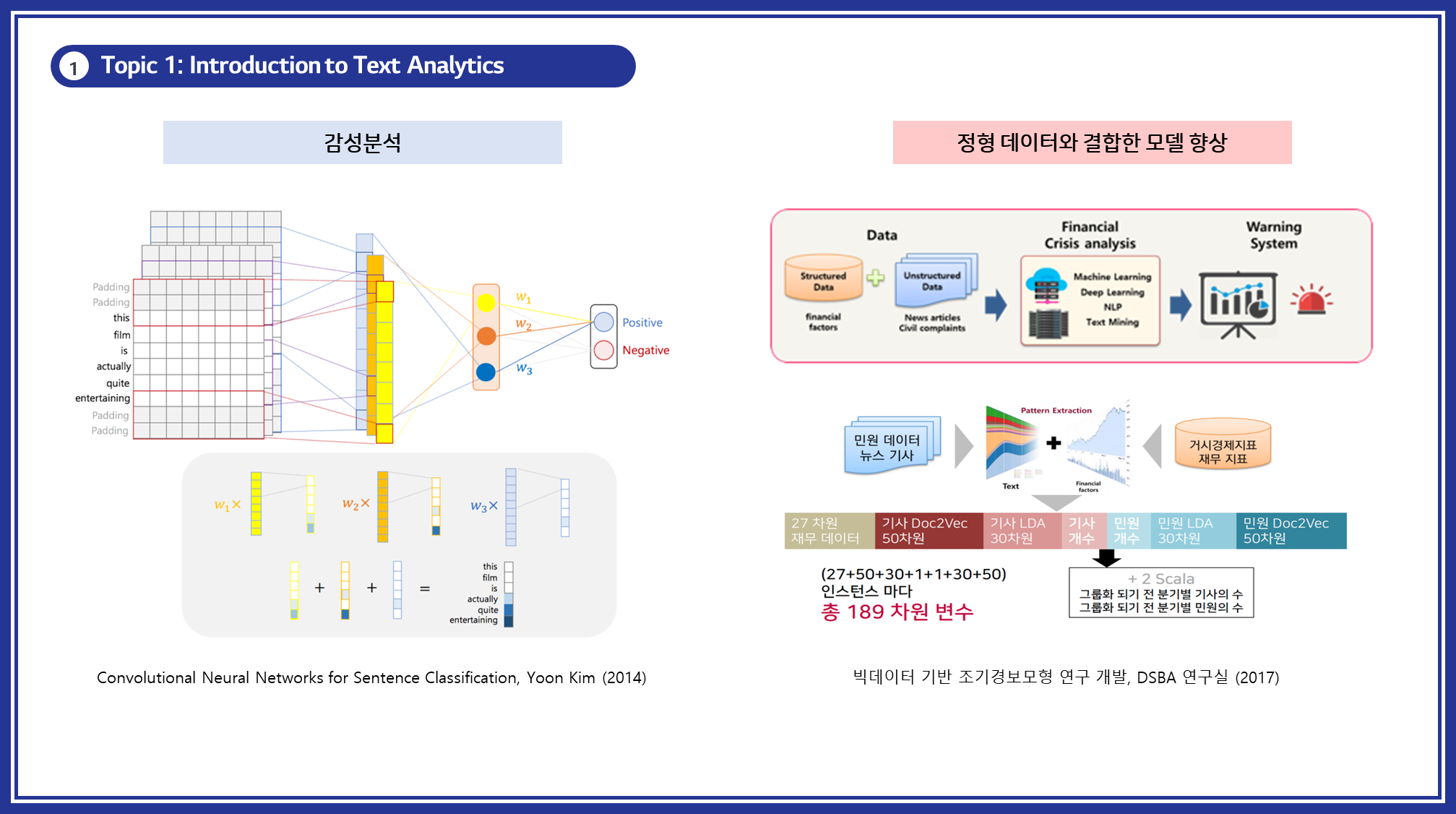
- 감성 분석: 텍스트 데이터에 담긴 감정을 분석하여 긍정적, 부정적, 중립적 감정을 판별합니다.
- 정형 데이터와 결합한 모델 향상: 비정형 텍스트 데이터를 정형 데이터와 결합하여 모델의 성능을 향상시킵니다.
텍스트 분석의 도전 과제
Text Analytics는 몇 가지 도전 과제에 직면해 있습니다:

- 높은 차원의 문제(High number of Dimensions): 언어의 차원 수가 매우 높아 분석이 복잡해집니다. 예를 들어, 한국어는 약 110만 개의 단어를 포함하고 있습니다.
- 복잡하고 미묘한 관계(Complex and subtle relationships): 단어 간의 복잡한 관계가 존재합니다. 예를 들어, "철수는 영희와 싸웠다"와 "그는 그녀와 말 다툼을 하였다"는 표현은 서로 다른 단어를 사용하지만 동일한 의미를 가집니다.
- 모호성 및 문맥 민감도(Ambiguity and Context sensitivity): 단어의 모호성이 존재합니다. 예를 들어, 애플(Apple)은 문맥에 따라 과일이나 회사 로고를 의미할 수 있습니다.
텍스트 데이터의 구조
텍스트 데이터는 그 구조에 따라 다음과 같이 분류됩니다:
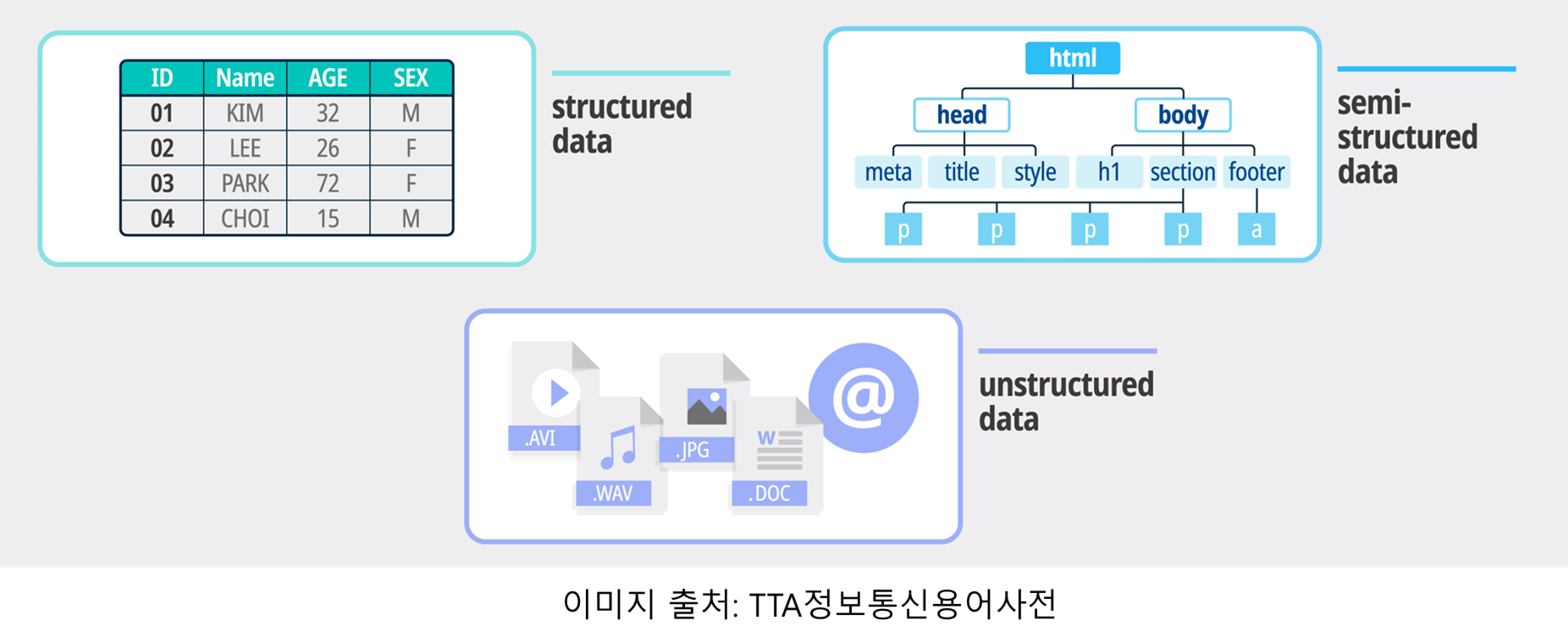
1. Unstructured Data (비구조적 데이터)
-
비구조적 데이터는 명확한 구조적 단서가 없는 데이터로, 텍스트의 형식이나 패턴이 일정하지 않습니다.
-
이러한 데이터는 분석하기 어렵지만, 자연어 처리(NLP) 기술을 통해 의미를 추출할 수 있습니다.
-
예시로는 다음이 있습니다:
- 문자 메시지
- 소설
- 블로그 글
- 소셜 미디어 게시물
2. Weakly Structured Data (약간 구조적 데이터)
-
약간 구조적 데이터는 일부 구조적 단서를 포함하고 있지만, 여전히 비구조적 요소가 많습니다.
-
이러한 데이터는 특정 형식을 따르지만, 그 형식이 완전히 일관되지는 않습니다.
-
예시로는 다음이 있습니다:
- 뉴스 기사
- 법률 문서
- 연구 논문
- 제품 리뷰
3. Semi-Structured Data (반구조적 데이터)
-
반구조적 데이터는 명확한 구조적 단서를 많이 포함하고 있으며, 특정 형식을 따릅니다. 이러한 데이터는 구조화된 정보와 비구조화된 정보를 모두 포함할 수 있습니다.
-
예시로는 다음이 있습니다:
- HTML
- XML
- 이메일
- JSON 파일
Text Mining의 유형
Text Mining은 여러 가지 유형으로 나뉩니다:
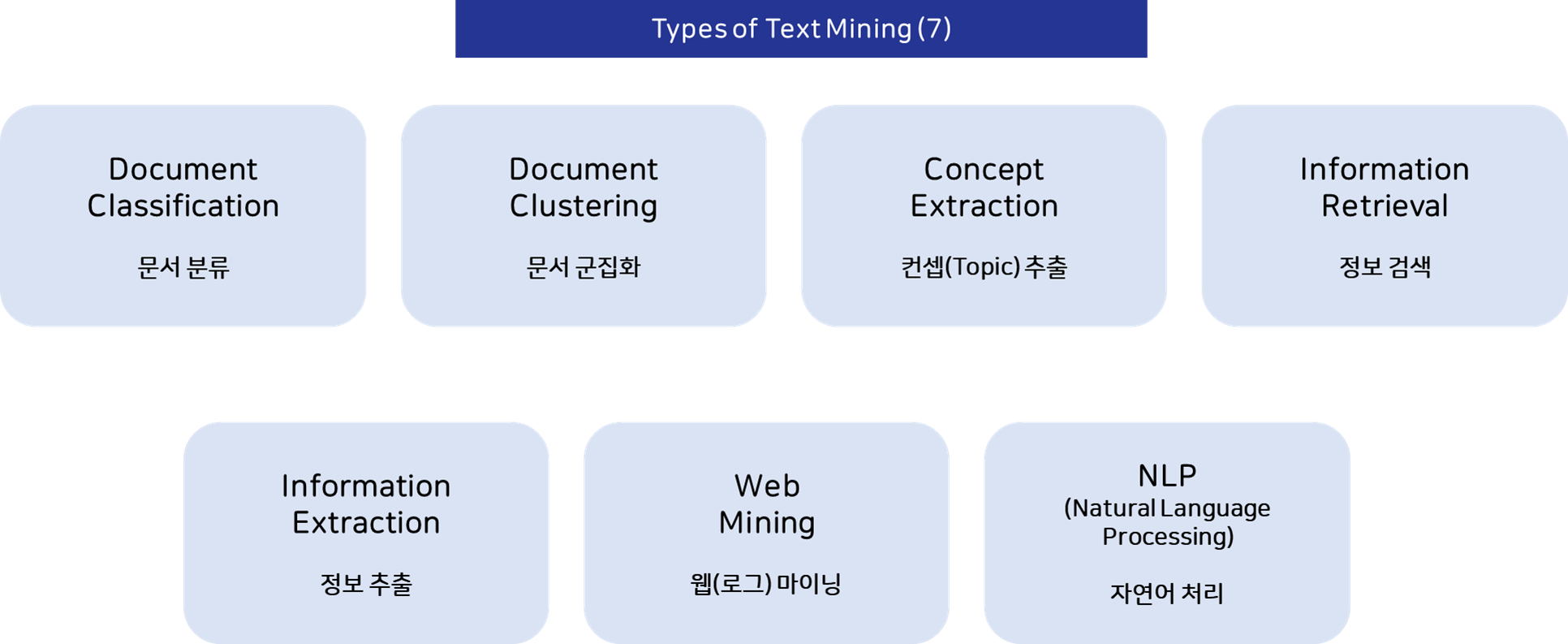
- 문서 분류(Document Classification): 문서를 미리 정의된 카테고리로 분류합니다.
- 문서 군집화(Document Clustering): 유사한 문서들을 그룹화합니다.
- 주제 추출(Concept Extraction): 문서에서 주요 주제를 추출합니다.
- 정보 검색(Information Retrieval): 사용자 질의에 맞는 문서를 검색합니다.
- 정보 추출(Information Extraction): 문서에서 특정 정보를 추출합니다.
- 웹 마이닝(Web Mining): 웹 로그 데이터를 분석합니다.
- 자연어 처리(NLP): 언어의 구조를 분석하고 이해합니다.
하지만, 특정 Task가 어느 한 영역에만 존재한다고는 할 수 없습니다. 예를 들어 GPT나 챗봇은 주로 자연어 처리(NLP) 영역에 속하지만, 정보 검색, 정보 추출, 문서 분류, 주제 추출, 문서 군집화 등 다양한 Text Analytics 기술을 활용하여 사용자에게 유용한 정보를 제공하고 상호작용합니다. 이러한 기술들은 함께 작동하여 챗봇이 더 스마트하고 효율적으로 사용자와 소통할 수 있도록 합니다.
-
자연어 처리(Natural Language Processing, NLP):
- GPT(Generative Pre-trained Transformer)와 같은 언어 모델은 NLP의 핵심 기술을 사용하여 인간 언어를 이해하고 생성합니다. 이는 텍스트의 구조를 분석하고 문법 규칙을 이해하며 문맥을 파악하여 자연스러운 언어 생성이 가능하도록 합니다.
-
정보 검색(Information Retrieval):
- GPT 기반 챗봇은 사용자 질의에 맞는 적절한 정보를 검색하여 응답을 생성할 수 있습니다. 이는 사용자가 질문을 했을 때 관련 정보를 찾고 이를 바탕으로 답변을 제공하는 기능을 포함합니다.
-
정보 추출(Information Extraction):
- 챗봇은 문서나 대화에서 특정 정보를 추출하여 사용자에게 제공합니다. 예를 들어, 사용자가 특정 데이터나 정보를 요청하면, 챗봇은 해당 정보를 추출하여 답변합니다.
-
문서 분류(Document Classification):
- GPT 모델은 문서를 다양한 카테고리로 분류하는 데 사용될 수 있습니다. 예를 들어, 고객 서비스 챗봇은 사용자의 질문을 분석하여 기술 지원, 청구 관련 질문 등으로 분류하고 이에 맞는 답변을 제공할 수 있습니다.
-
주제 추출(Concept Extraction):
- GPT 모델은 텍스트에서 주요 주제를 추출할 수 있습니다. 예를 들어, 긴 문서를 요약하거나 대화의 주요 주제를 파악하여 그에 맞는 응답을 생성할 수 있습니다.
-
문서 군집화(Document Clustering):
- 챗봇은 유사한 문서를 그룹화하여 사용자에게 추천하거나 관련 정보를 제공할 수 있습니다. 이는 사용자가 특정 주제에 대해 질문할 때, 관련 문서를 그룹화하여 제공하는 데 유용합니다.
텍스트 분석의 단계
Text Analytics는 다음과 같은 단계로 이루어집니다:

- 정의 및 데이터 수집(Define & Collect): 분석할 목표를 정의하고 텍스트 데이터를 수집합니다.
- 전처리 및 변환(Preprocess & Transform): 데이터를 전처리하여 분석 가능한 형태로 변환합니다.
- 특징 선택 및 추출(Select & Extract Features): 분석에 필요한 중요한 특징을 선택하고 추출합니다.
- 알고리즘 학습 및 평가(Algorithm Learning & Evaluation): 적절한 알고리즘을 학습시키고 평가합니다.
다음 포스트에서는 텍스트 분석 단계에 대해서 자세하게 살펴보겠습니다.
