[강의노트] LangChain Academy : Introduction to LangGraph (Module 1)

랭체인(LangChain)과 랭그래프(LangGraph)는 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 도구들입니다. 위 강의는 LangChain에서 운영하는 LangChain Academy에서 제작한 "Introduction to LangGraph" 강의의 내용을 정리 및 추가 설명한 내용입니다.
- 강의 링크 : https://youtu.be/29XE10U6ooc
- 랭체인 : https://www.langchain.com/
이번 포스트는 "Introduction"과 "Module1"내용을 다룹니다:
목차
- Introduction: 랭체인(LangChain), 그리고 랭그래프(LangGraph)
- Lesson 1: Motivation, Introduction to Langraph
- Lesson 2: Simple Graph
- Lesson 3: LangGraph Studio
- Lesson 4: Chain
- Lesson 5: Router
- Lesson 6: Agent
- Lesson 7: Agent with Memory
- Lesson 8: Deployment
0. Introduction
랭체인(LangChain)
랭체인은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 포괄적인 프레임워크입니다. 이 프레임워크는 LLM과 애플리케이션의 통합을 간소화하기 위해 설계되었으며, 개발자들이 LLM 기반 시스템을 더 쉽고 효율적으로 구축할 수 있도록 돕습니다.

주요 구성 요소
- 데이터 소스 연결: 랭체인은 PDF, 웹 페이지, CSV, 관계형 데이터베이스 등 다양한 외부 데이터 소스와의 연동을 지원합니다. 이를 통해 LLM에 풍부한 컨텍스트를 제공할 수 있습니다.
- 단어 임베딩: 텍스트 데이터를 벡터로 변환하는 과정을 지원합니다. 랭체인은 선택한 LLM에 적합한 임베딩 모델을 자동으로 선택합니다.
- 벡터 데이터베이스: 생성된 임베딩을 저장하고 검색할 수 있는 기능을 제공합니다. 메모리 내 배열부터 Pinecone과 같은 호스팅 벡터 데이터베이스까지 다양한 옵션을 지원합니다.
- 언어 모델 통합: OpenAI, Cohere, AI21 등의 주요 LLM 제공업체와 Hugging Face의 오픈소스 모델을 지원합니다.
- 에이전트: LLM을 사용하여 동적으로 작업 계획을 수립하고 실행할 수 있는 강력한 모듈입니다.
- 메모리: LLM에 단기 및 장기 메모리를 추가하여 대화의 컨텍스트를 유지할 수 있습니다.
- 콜백 시스템: 개발자가 LLM 애플리케이션의 다양한 단계에 연결할 수 있는 기능을 제공합니다.
- 체인: 여러 구성 요소를 연결하여 복잡한 작업 흐름을 구성할 수 있습니다.
랭체인은 이러한 구성 요소들을 통합하여 개발자가 LLM 기반 애플리케이션을 더 쉽게 구축할 수 있도록 돕습니다. 특히, 프롬프트 엔지니어링, API 호출, 결과 해석 등 LLM과의 상호작용에 필요한 다양한 작업을 추상화하여 제공합니다.
랭그래프(LangGraph)
랭그래프는 복잡한 에이전트 시스템을 위한 오케스트레이션 프레임워크입니다. 랭체인보다 더 낮은 수준의 제어를 제공하며, 기업의 고유한 요구사항에 맞는 복잡한 작업을 처리할 수 있는 유연성을 제공합니다.
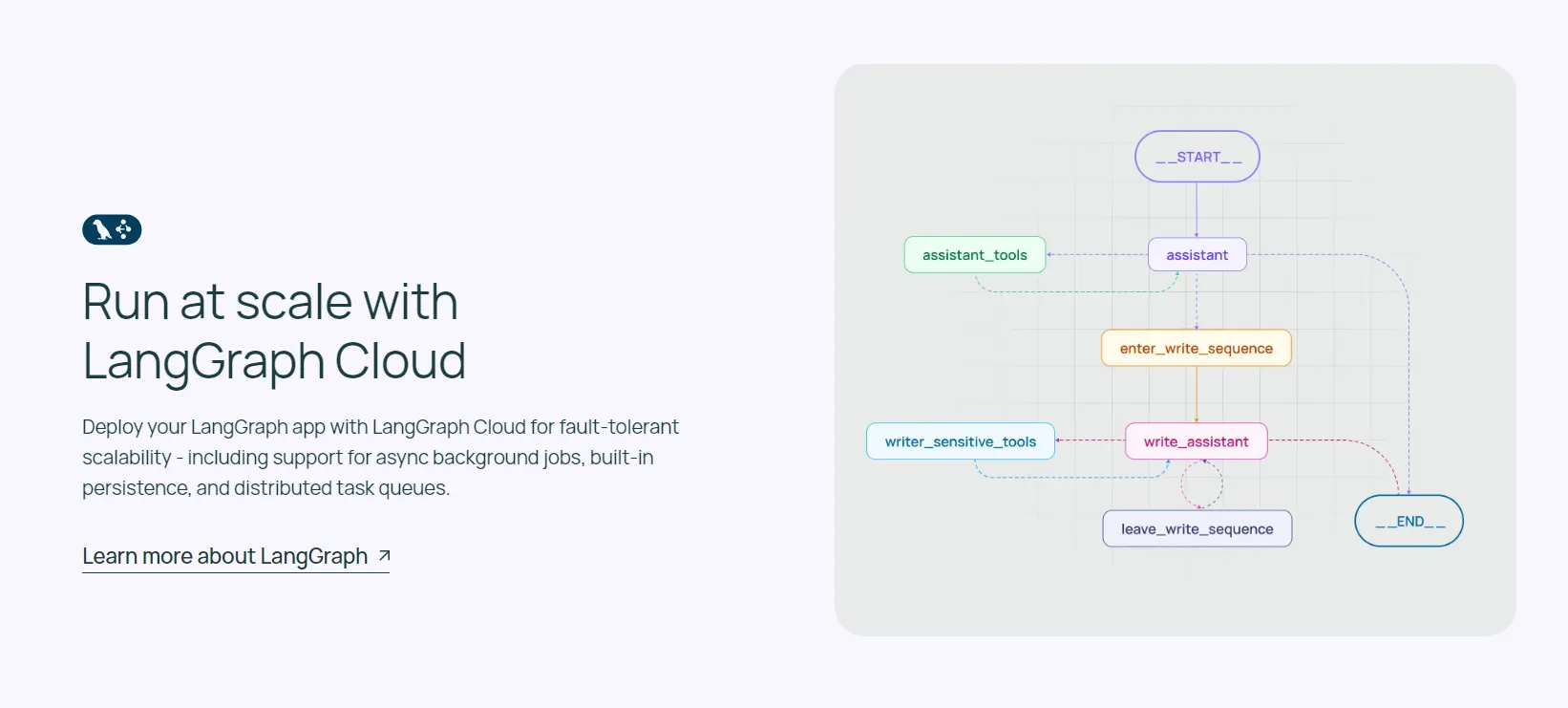
주요 특징
- 세밀한 제어: 랭그래프는 랭체인의 에이전트보다 더 세밀한 수준의 제어를 가능하게 합니다. 이를 통해 개발자는 복잡한 워크플로우를 더 정밀하게 설계하고 구현할 수 있습니다.
- 유연한 프레임워크: 기업의 고유한 요구사항에 맞는 복잡한 작업을 처리할 수 있는 표현력 있는 프레임워크를 제공합니다. 이는 단일한 블랙박스 인지 아키텍처에 제한되지 않고 다양한 접근 방식을 구현할 수 있음을 의미합니다.
- 스트리밍 최적화: 랭그래프는 스트리밍 워크플로우를 염두에 두고 설계되었습니다. 이는 실시간 데이터 처리와 응답이 필요한 애플리케이션에 특히 유용합니다.
- 오픈소스: MIT 라이선스로 제공되는 무료 오픈소스 라이브러리입니다. 이는 개발자들이 자유롭게 사용하고 수정할 수 있음을 의미합니다.
- 랭그래프 클라우드: 랭그래프 애플리케이션의 배포와 확장을 위한 서비스로, 프로토타이핑, 디버깅, 공유를 위한 스튜디오를 제공합니다. 이는 랭그래프 애플리케이션의 개발과 운영을 더욱 효율적으로 만듭니다.
랭그래프는 특히 복잡한 에이전트 시스템을 구축하는 데 적합합니다. 예를 들어, 여러 단계의 의사 결정이 필요한 작업, 다양한 외부 도구와의 상호작용이 필요한 시스템, 또는 동적으로 변화하는 환경에 적응해야 하는 에이전트 등을 구현하는 데 유용합니다.
1. Course Overview
Lesson 1: Motivation, Introduction to Langraph

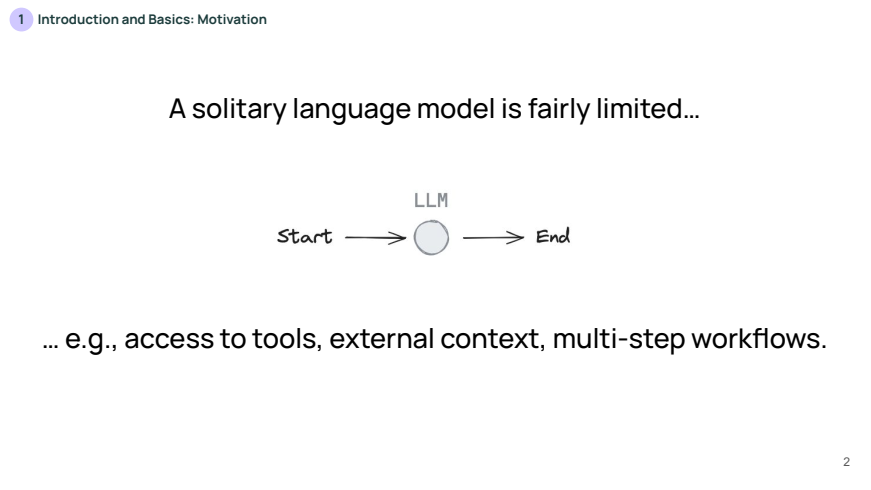
Langraph를 도입한 이유는 단순한 LLM(Language Model) 자체만으로는 한계가 있기 때문입니다. LLM은 외부 도구나 문서 같은 외부 컨텍스트에 접근할 수 없고, 복잡한 멀티스텝 작업을 자체적으로 수행하기 어렵습니다.
그래서 많은 LLM 애플리케이션은 LLM 호출 전후에 여러 단계로 구성된 일련의 작업 흐름을 사용하며, 이를 체인(Chain)이라고 합니다.
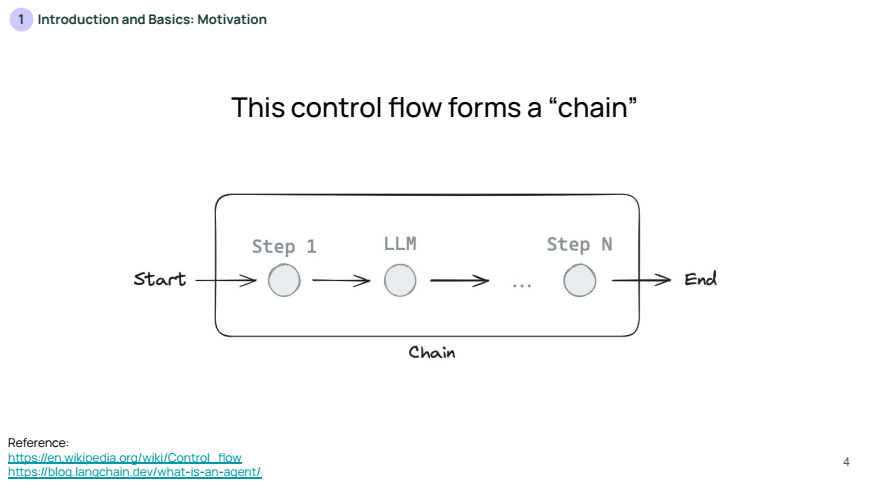
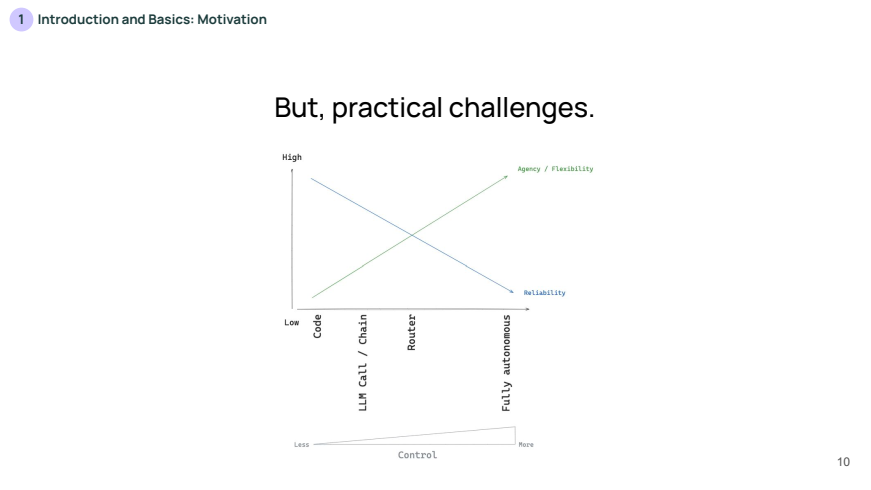
체인은 일정한 흐름을 따르기 때문에 안정적이지만, 때로는 LLM 자체가 문제에 따라 작업 순서를 결정할 수 없다는 단점이 존재하게 됩니다.

따라서, 작업 순서를 결정할 수 있는 에이전트(Agent)가 필요로 하게 됩니다. 에이전트는 LLM이 주도하는 작업 흐름이며, 이때 LLM은 작업 단계를 스스로 선택합니다.
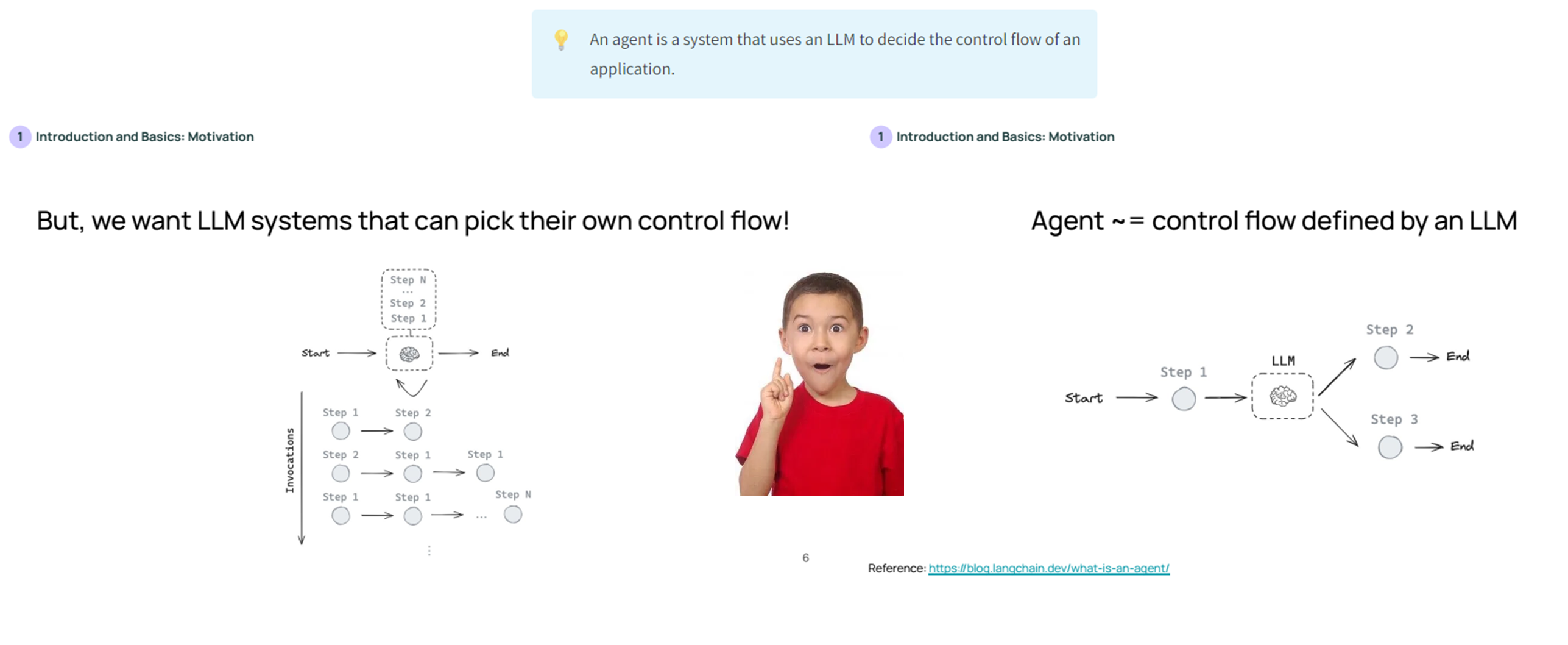
제어 수준이 높아질수록 에이전트는 더 많은 자율성을 가지게 되어 다양한 상황에 대해 더 유연하게 대처할 수 있습니다.
- 예를 들어, LLM(대형 언어 모델)이 자신의 워크플로우를 스스로 결정할 수 있게 하면, 복잡한 문제에 대해 더 적절한 결정을 내릴 수 있는 가능성이 높아집니다.
하지만, 제어 수준이 높아지면 예측 가능성이 줄어들고, 각 단계에서 발생할 수 있는 변동성이나 오류가 증가할 수 있습니다. 이는 시스템의 안정성에 영향을 미치며, 특히 자동화된 의사결정에서 발생할 수 있는 오류 가능성이 높아질 수 있습니다.
🔎 "제어 수준이 높아진다"는 의미는 시스템, 특히 LLM(대형 언어 모델)이 수행하는 작업에서 더 많은 자율성을 부여받는 것을 뜻합니다. 여기서 '제어'는 워크플로우의 흐름을 결정하는 권한을 말하며, 제어 수준이 높아질수록 LLM이나 에이전트가 더 많은 결정과 작업 순서를 스스로 선택할 수 있게 됩니다.
제어 수준 낮음: LLM이 주어진 입력을 받아서 고정된 절차에 따라 순차적으로 도구를 호출하거나 응답을 생성. 예를 들어, 사용자가 질문을 하면 LLM이 항상 ① 검색 ② 문서 요약 ③ 응답 생성이라는 고정된 순서로 작업을 수행.제어 수준 높음: LLM이 문제의 복잡성이나 상황에 따라 어떤 도구를 호출할지, 몇 단계의 작업을 수행할지, 또는 새로운 단계를 생성할지를 스스로 판단. 예를 들어, 사용자의 질문에 따라 ① 검색이 필요 없다고 판단하거나 ② 새로운 도구 호출 단계를 추가하는 등 변동적인 워크플로우를 적용.
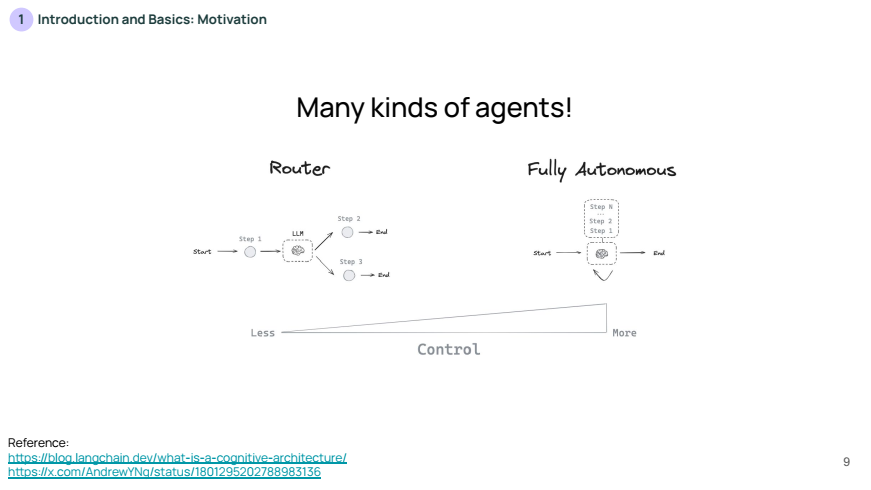
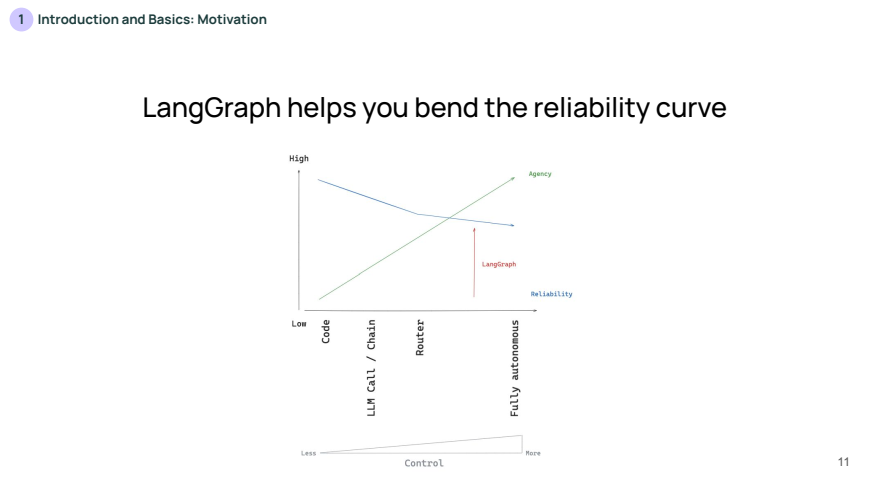
Langraph는 LLM의 제어 수준을 높이면서도 안정성을 유지할 수 있도록 돕는 도구입니다. Langraph는 그래프 기반으로 구성되며, 각 노드(Node)는 특정 작업을 의미하고 엣지(Edge)는 노드 간의 연결을 나타냅니다.
Langraph의 주요 Intuition과 관련하여 아래 내용을 소개합니다:
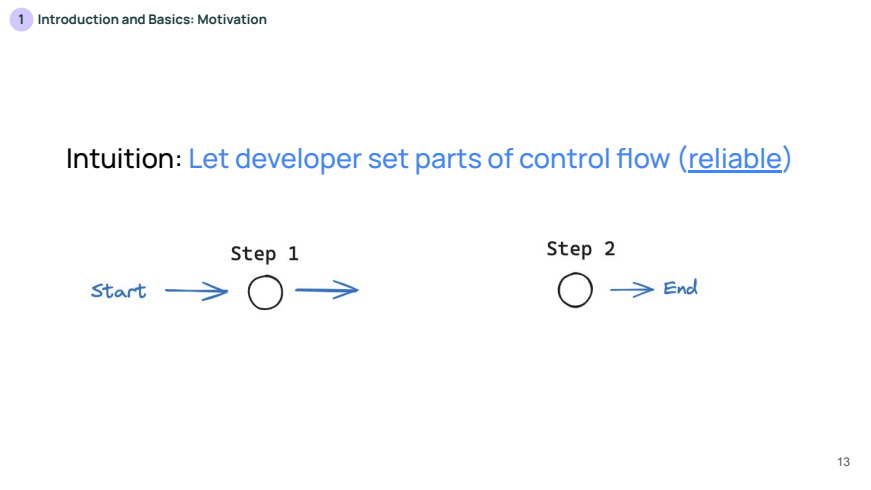
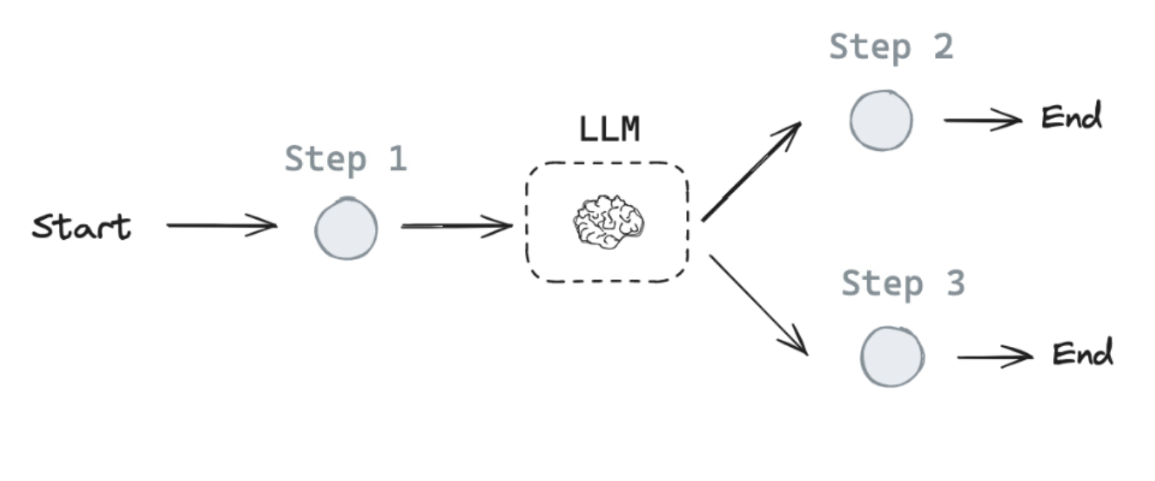
위 슬라이드는 개발자가 제어 플로우의 일부를 고정하는 개념을 설명합니다. 개발자가 작업 흐름의 일부 단계를 명확하게 설정하면, 해당 워크플로우는 항상 동일한 방식으로 수행되므로 신뢰성(reliable)이 보장됩니다.
- 예를 들어, 시작(Start)에서 첫 번째 단계(Step 1), 두 번째 단계(Step 2)로 이어지는 고정된 흐름이 있습니다. 이는 항상 같은 순서로 작업이 진행되어 예측 가능성이 높습니다.
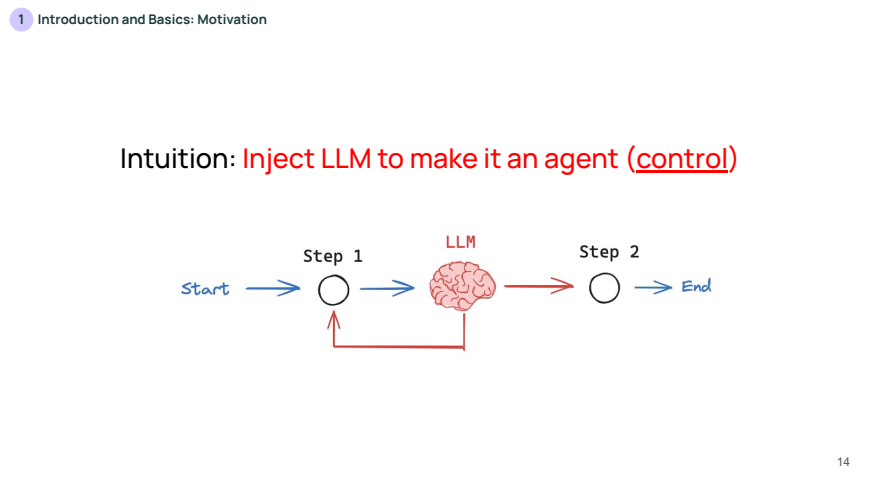
위 슬라이드는 LLM(대형 언어 모델)을 주입하여 에이전트로 전환하는 개념을 설명합니다. 여기서 LLM은 고정된 흐름 대신, 특정 시점에서 스스로 판단하여 흐름을 변경(control)할 수 있습니다.
- LLM이 컨트롤을 가져가는 시점에서 보다 유연하게 동작하지만, 신뢰성이 떨어질 가능성도 있습니다. 이 슬라이드는 시작부터 LLM이 개입하여 워크플로우의 일부를 동적으로 조정할 수 있는 구조를 보여줍니다.
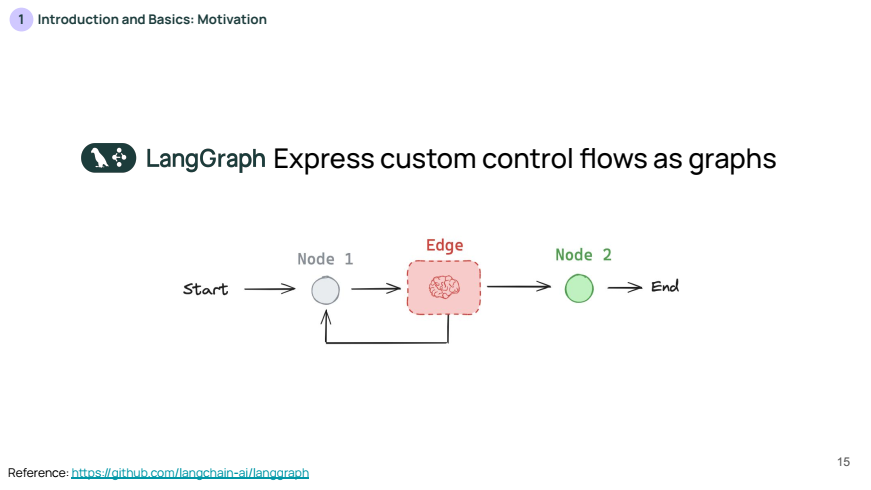
위 슬라이드는 커스텀 제어 흐름을 그래프 형태로 표현하는 LangGraph의 구조를 나타냅니다. 각 단계(Node)는 작업을 나타내고, 엣지(Edge)는 노드 간의 연결을 의미합니다.
- 여기서 LLM은 엣지에 위치하여 각 단계를 결정하며, 이를 통해 유연한 흐름 제어가 가능해집니다. LangGraph는 이러한 구조를 시각화하고 관리할 수 있는 도구입니다.
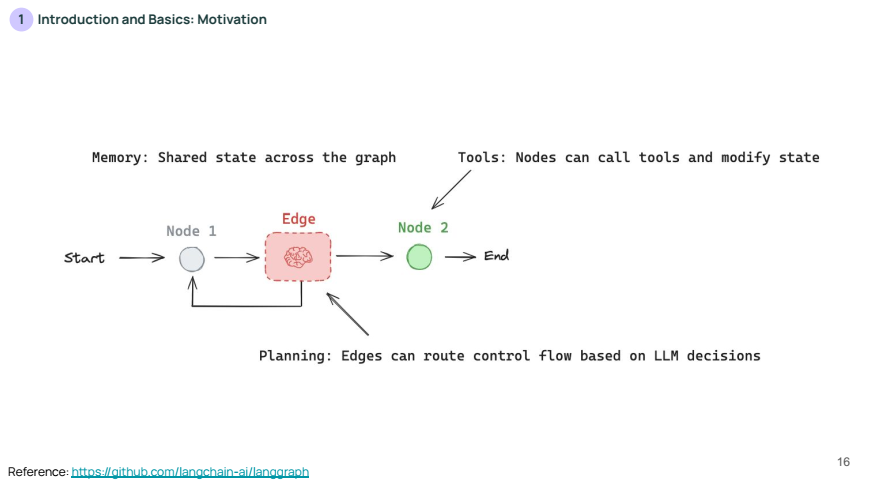
위 슬라이드는 LangGraph의 세 가지 중요한 개념을 설명합니다:
- Memory (메모리): 그래프 전반에 걸쳐
공유되는 상태를 의미합니다.- 즉, 상태가 계속 유지되어 그래프가 진행될 때 이를 참조할 수 있습니다.
- Tools (도구): 각 노드가 외부 도구를 호출하고 상태를 수정할 수 있는 기능을 의미합니다.
- Planning (계획): 엣지는 LLM의 결정에 따라 제어 플로우를 조정할 수 있습니다.
- 이를 통해 워크플로우를 더욱 정교하게 관리할 수 있습니다.
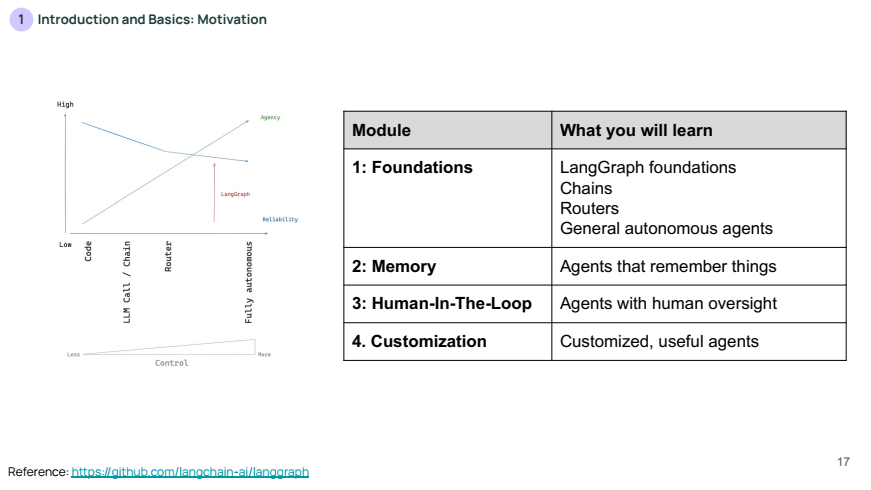
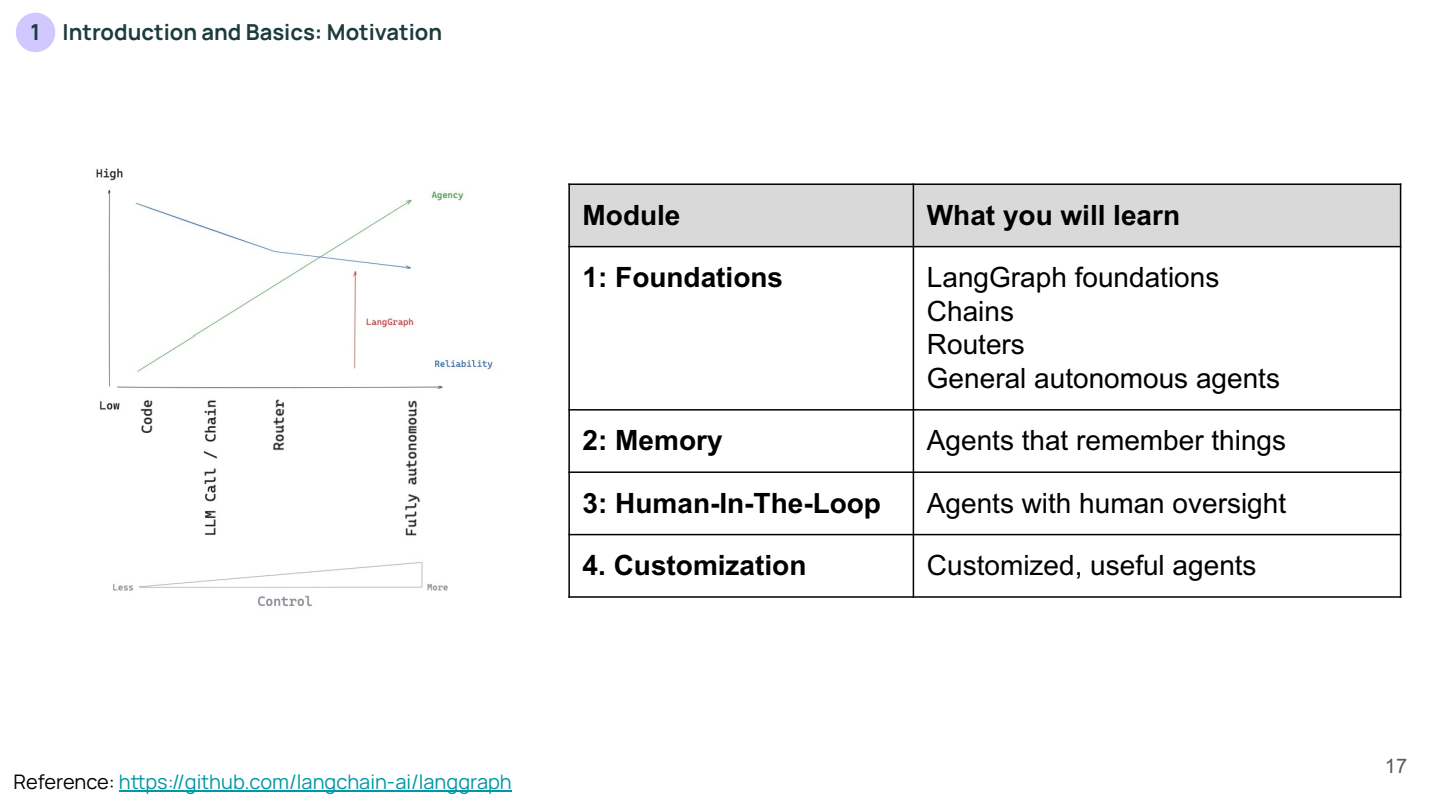
위 슬라이드는 이후 LangGraph의 각 모듈에서 배울 내용을 개요로 설명합니다:
- Foundations: LangGraph의 기초, 체인, 라우터, 그리고 일반적인 자율 에이전트 구축.
- Memory: 메모리 기능을 활용하여 상태를 기억하는 에이전트.
- Human-In-The-Loop: 사람이 개입하여 에이전트를 감독하는 기능.
- Customization: 맞춤형 에이전트를 구축하는 방법.
Lesson 2: Simple Graph
Langraph의 기본 구성 요소인 그래프(Graph)를 이해하는 간단한 예제를 소개합니다.
그래프에는 노드(Node)와 엣지(Edge)가 존재합니다.
- 각 노드는 특정 작업(예: 도구 호출, 데이터 검색 등)을 수행합니다.
- 각 엣지는 노드 간의 작업 흐름을 연결하는 역할을 합니다.
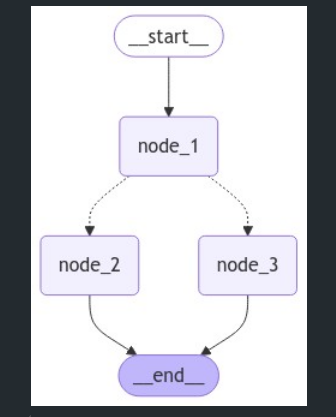
간단한 그래프 예시에서는 시작(Start)에서 노드 1로 가고, 노드 1에서 조건에 따라 노드 2 또는 노드 3으로 이동한 후 종료합니다. 이때 조건부 엣지(Conditional Edge)를 사용해 LLM의 결정에 따라 노드 2나 노드 3 중 하나로 분기할 수 있습니다.
주요 개념:
- 상태(State): 각 노드는 그래프 상태를 받아 작업을 수행하고, 상태를 업데이트합니다.
- 조건부 엣지(Conditional Edge): 특정 조건에 따라 다음 노드를 선택합니다.
코드 실습
TypedDict로 State을 정의합니다.TypedDict는 Python 3.8부터 도입된 기능으로, 딕셔너리의 구조를 타입 힌트로 명시할 수 있게 해줍니다.- 이는 주로 Type Hinting의 일환으로 사용되며, 딕셔너리 내에서 사용되는 키와 값의 타입을 정의할 수 있습니다.
- 이를 통해 코드의 가독성을 높이고, IDE 또는 타입 체커(myPy 등)를 이용하여 코드의 타입 오류를 미리 잡아낼 수 있습니다.
# STATE 정의
from typing_extensions import TypedDict
class State(TypedDict):
graph_state: str- 위 코드에서 State라는 이름의 TypedDict가 정의되어 있습니다.
- 이 구조체는 graph_state라는 키를 가지고, 해당 키의 값은 str 타입이어야 한다는 것을 명시합니다.
# NODE 정의
def node_1(state):
print("---Node 1---")
return {"graph_state": state['graph_state'] +" I am"}
def node_2(state):
print("---Node 2---")
return {"graph_state": state['graph_state'] +" happy!"}
def node_3(state):
print("---Node 3---")
return {"graph_state": state['graph_state'] +" sad!"}
- 이 함수는 state라는 변수를 받아, 그 안의 graph_state 키에 접근한 후, 해당 값을 변경하여 반환합니다.
- 여기서
state['graph_state']가 문자열임이 보장되므로, 문자열 결합(+) 연산이 가능합니다.
# EDGE 정의
import random
from typing import Literal
def decide_mood(state) -> Literal["node_2", "node_3"]:
# Often, we will use state to decide on the next node to visit
user_input = state['graph_state']
# Here, let's just do a 50 / 50 split between nodes 2, 3
if random.random() < 0.5:
# 50% of the time, we return Node 2
return "node_2"
# 50% of the time, we return Node 3
return "node_3"- 이 함수는 상태(state)를 입력받아, 상태에 따라 다음에 어느 노드로 이동할지를 엣지를 결정하는 로직입니다.
- 입력: state는 TypedDict로 정의된 딕셔너리이며, graph_state라는 키에 문자열을 저장합니다.
- 기능: random.random()을 사용하여 50% 확률로 "node_2" 혹은 "node_3"을 반환합니다.
- 리턴값: "node_2" 또는 "node_3"이라는 문자열을 반환하여, 어떤 노드로 이동할지 결정합니다.
# GRAPH 정의
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_conditional_edges("node_1", decide_mood)
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
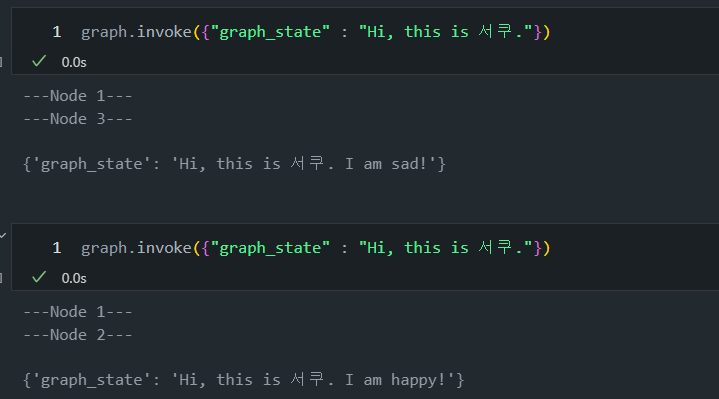
display(Image(graph.get_graph().draw_mermaid_png()))- 아래 과정을 통해 상태와 조건에 따라 흐름을 결정하는 상태 전이 그래프가 완성됩니다.
- 그래프가
START에서 시작하여node_1로 이동합니다. node_1에서decide_mood 함수가 호출되어,무작위로 node_2 또는 node_3로 이동합니다.node_2또는node_3에 도달하면 그래프가종료(END)됩니다.
- 그래프가
- 랜덤 값이므로 돌릴 때마다 다르게 값이 나오는 것을 확인할 수 있습니다:
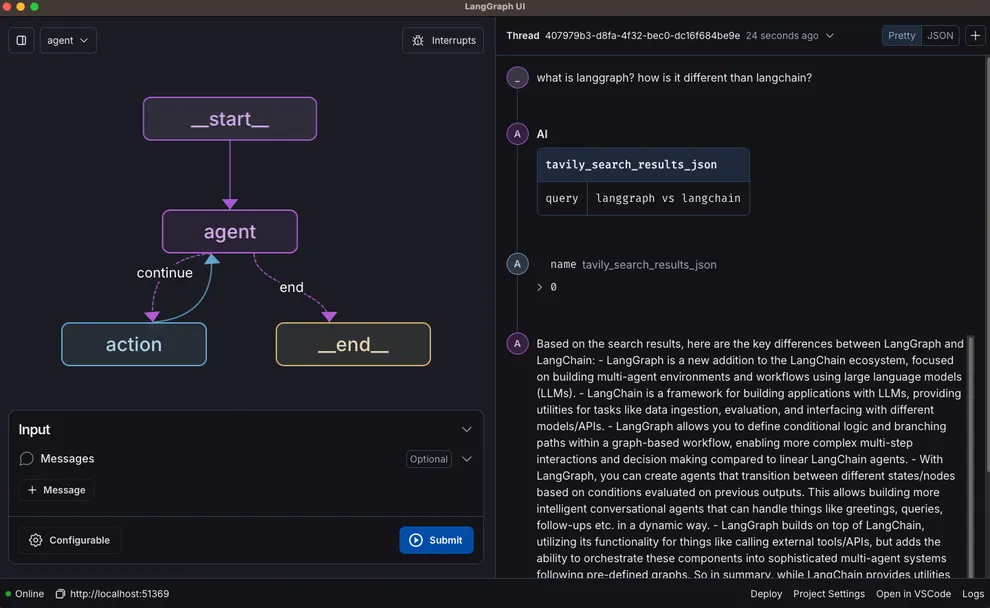
Lesson 3: LangGraph Studio
Langraph Studio는 시각적으로 그래프를 구축하고 디버깅할 수 있는 통합 개발 환경(IDE)입니다. Studio를 사용하면 에이전트를 시각적으로 디버깅하고, 각 노드에서 상태가 어떻게 변화하는지 쉽게 추적할 수 있습니다.
-
이미지 출처 : https://blog.langchain.dev/langgraph-studio-the-first-agent-ide/
-
랭스튜디오 깃허브 : https://github.com/langchain-ai/langgraph-studio
Studio에서는 상태를 직접 입력하고 각 노드의 실행 결과를 확인할 수 있으며, 이전 실행 기록을 스레드(Thread)로 관리할 수 있어 디버깅이 수월합니다.
Studio는 Docker를 백그라운드에서 실행하여 쉽게 로컬 환경에서 실행할 수 있으며, Studio에서 작성한 그래프는 Langraph API와 연결되어 클라우드에서도 실행할 수 있습니다.
저는 맥북 유저가 아니라 아직 사용이 불가하기 때문에 LangGraph Studio 부분들은 제외하고 진행하겠습니다.
Lesson 4: Chain
🔷 chat models & messages
chat models는 대화 내에서 다양한 역할을 나타내는 'messages' 기능을 사용할 수 있습니다.
- LangChain은 여러 메시지 유형(message types)을 지원합니다:
- HumanMessage: 사용자의 메시지
- AIMessage: 채팅 모델의 응답 메시지
- SystemMessage: 채팅 모델의 행동을 지시하는 메시지
- ToolMessage: 도구 호출의 결과를 나타내는 메시지
각 메시지는 다음 요소로 구성될 수 있습니다:
- content: 메시지 내용
- name: 메시지 작성자 (선택사항)
- response_metadata: 메타데이터 딕셔너리 (선택사항, 주로 AIMessage에서 모델 제공자가 채움)
아래 예시 코드를 통해 다양한 메시지 유형으로 대화 목록을 만들 수 있습니다.
from pprint import pprint
from langchain_core.messages import AIMessage, HumanMessage
messages = [AIMessage(content=f"So you said you were researching ocean mammals?", name="GPT")]
messages.append(HumanMessage(content=f"Yes, that's right.",name="HUMAN"))
messages.append(AIMessage(content=f"Great, what would you like to learn about.", name="GPT"))
messages.append(HumanMessage(content=f"I want to learn about the best place to see Orcas in the US.", name="HUMAN"))
for m in messages:
m.pretty_print()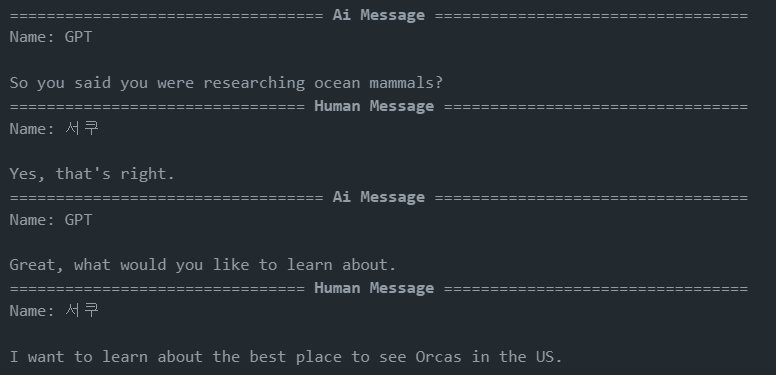
이러한 메시지와 채팅 모델을 활용하면 대화형 AI 애플리케이션을 더 효과적으로 구축할 수 있습니다.
- LangChain에서는 다양한 채팅 모델을 선택할 수 있으며, 아래 예시들은 OpenAI 모델을 사용한 예시입니다.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
result = llm.invoke(messages)
type(result)아까 제가 마지막으로 말한거에 이어서 AIMessage가 답변하는 것을 볼 수 있습니다.
그럼 "I want to learn about the best place to see Orcas in the US", 해석하면 "미국에서 범고래를 가장 잘 볼 수 있는 곳에 대해 배우고 싶습니다."라고 물어봤을때 AI는 뭐라고 답변했는지 볼까요?
result.content답변을 가져와서 보면,
"Orcas, also known as killer whales, are fascinating creatures, and there are several great places in the United States where you can observe them in their natural habitat. Here are some of the best locations:\n\n1. **San Juan Islands, Washington**: This is one of the most famous spots for orca watching. The waters around the San Juan Islands are home to several pods of resident orcas, particularly during the summer months. You can take boat tours from Friday Harbor or other nearby locations...오! 제대로 답변을 잘 수행한 것을 확인할 수 있습니다.
그리고 result.response_metadata를 수행해보면 해당 답변의 상세 정보를 살펴볼 수 있습니다.

🔷 tools
도구(tools)는 모델이 외부 시스템과 상호작용할 때 유용합니다. (Tools are useful whenever you want a model to interact with external systems.)
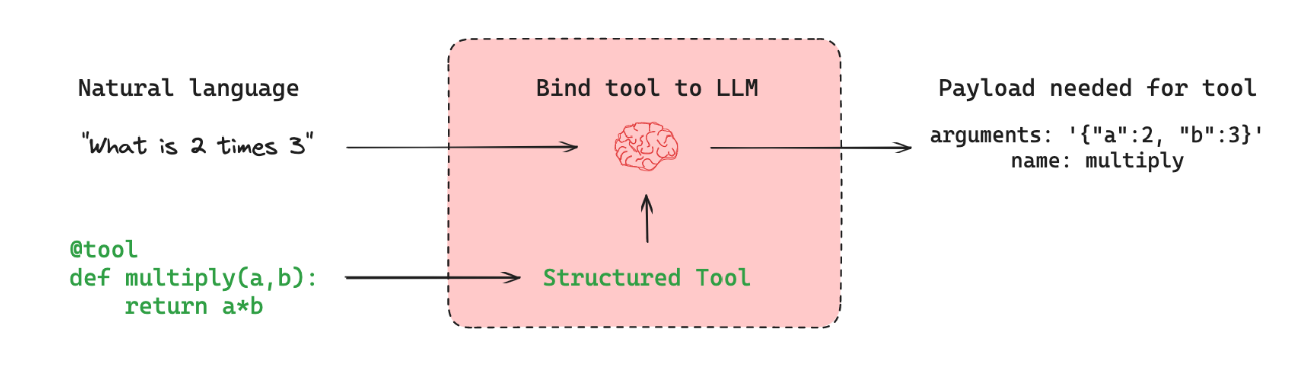
Tool의 주요 역할
-
페이로드 생성: LLM은 사용자의 자연어 입력을 해석하여 특정 도구(함수)를 실행하는 데 필요한 정확한 인자(페이로드)를 생성합니다.✔ 페이로드란?
컴퓨터 네트워크에서, 데이터 패킷에서 실제 전송하고자 하는 데이터 부분을 의미합니다. -
함수 실행 준비: 생성된 페이로드는 바인딩된 함수의 매개변수에 맞는 형식으로 구성됩니다. -
인터페이스 제공: Tool은 LLM과 실제 실행될 함수 사이의 인터페이스 역할을 합니다. LLM이 이해한 사용자의 의도를 실제 실행 가능한 형태로 변환합니다. -
유연성 확보: 다양한 외부 시스템, API, 또는 함수들을 LLM에 쉽게 연결할 수 있게 해줍니다. -
정확성 향상: 사용자의 의도를 정확하게 해석하여 적절한 함수를 호출하고, 필요한 인자를 정확히 제공함으로써 원하는 결과를 얻을 수 있게 합니다.
Tool의 작동 방식
- 모델은 사용자의 자연어 입력을 기반으로 도구를 호출할지 결정합니다.
- 모델은 도구의 스키마에 맞는 출력을 반환합니다.
- 도구를 정의하는 것 자체는 무료지만, 도구를 실제로 사용할 때 연관된 서비스나 API 호출에 따른 비용이 발생할 수 있습니다.
- 개발자는 이러한 잠재적 비용을 고려하여 도구를 설계하고 사용해야 합니다
LangChain의 Tool 호출 인터페이스
- 많은 LLM 제공업체가 도구 호출을 지원하며, LangChain에서는 간단한 도구 호출 인터페이스를 제공합니다.
- Python 함수를
ChatModel.bind_tools(function)에 전달하기만 하면 됩니다. 이를 통해 모델은 해당 함수를 도구로 인식하고 사용할 수 있게 됩니다.
예시 1
-
LLM(Large Language Model)이 도구(tool)를 사용할 때의 과정을 좀 더 상세히 설명하면 다음과 같습니다:
-
사용자가 자연어로 요청을 합니다.
-
LLM은 이 자연어 요청을 이해하고, 어떤 도구를 사용해야 할지 결정합니다.
-
LLM은 선택한 도구를 실행하기 위해 필요한 정확한 인자(arguments)를 생성합니다. 이 인자들이 바로 '페이로드'입니다.
-
이 페이로드(인자들)는 도구 함수의 매개변수에 맞는 형식으로 구성됩니다.
-
생성된 페이로드를 사용하여 도구 함수가 실행됩니다.
def get_weather(city: str, date: str): # 날씨 정보를 반환하는 함수 pass # 사용자 입력: "내일 서울의 날씨는 어때?" # LLM이 생성한 페이로드 payload = { "city": "서울", "date": "2024-10-16" # 내일 날짜 } # 이 페이로드를 사용하여 get_weather 함수 호출 result = get_weather(**payload)위와 같은 과정을 통해 LLM은 자연어 명령을 구조화된 함수 호출로 변환할 수 있게 됩니다. 이는 LLM이 다양한 외부 시스템이나 API와 효과적으로 상호작용할 수 있게 해주는 강력한 기능입니다.
-
예시 2
-
파이썬 multiply함수 args를 맞춰주는 llm을 binding직접 시켜보도록 하겠습니다.
def multiply(a: int, b: int) -> int: """Multiply a and b. Args: a: first int b: second int """ return a * b llm_with_tools = gpt4o_chat.bind_tools([multiply]) llm_with_tools.bind_tools([multiply]) llm_with_tools.kwargs -
일단 위 함수로 binding을 시켰고요.
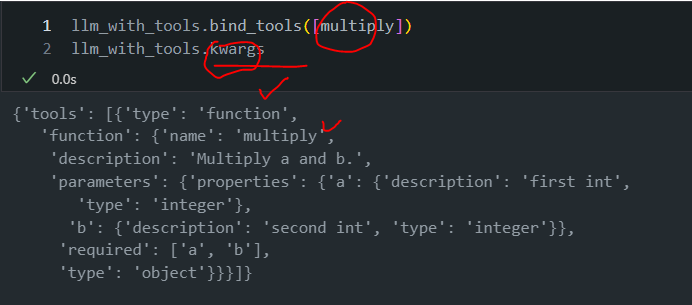
-
아래 그림과 같이 "What is 2 multiplied by 3", "2 곱하기 3은 무엇인가요?"라고 묻는 자연어를 넣어주면 알아서 argument가 들어가는 것을 볼 수 있습니다.
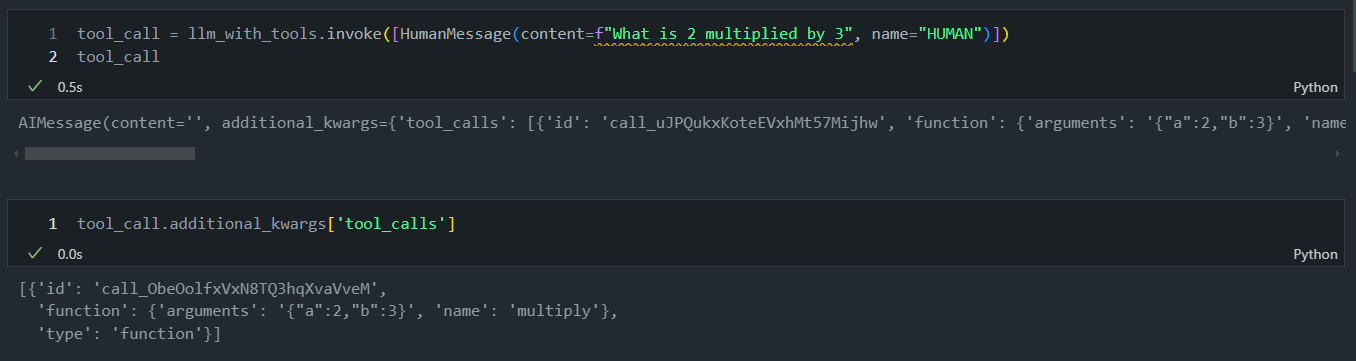
-
GPT-4o라서 그런지 한글로 해도 잘 작동하는 군요!

-
참고로 여기서 나온 답변을 좀 더 자세하게 살펴보면, AiMessage안에 Contents가 공란인 것을 볼 수 있습니다.
-
LangChain에서 Tool의 답변(invoke 결과)은 일반적으로 다음과 같이 처리됩니다:
- Tool의 실행 결과는 기본적으로 AIMessage의 content 필드에 들어갑니다.
- 그러나 Tool의 실행 결과에 추가적인 메타데이터나 구조화된 정보가 포함되어 있다면, 이는 additional_kwargs 딕셔너리에 저장됩니다.
- 특히 OpenAI의 함수 호출(function calling) 기능을 사용할 때, Tool의 결과는 주로 additional_kwargs 내의 function_call 키에 저장됩니다.
-
만약에 내가 tool이랑 전혀 상관없는 소리를 하면 LLM이 tool을 호출하지 않고 정상적으로 content를 호출하는 것을 볼 수 있습니다.
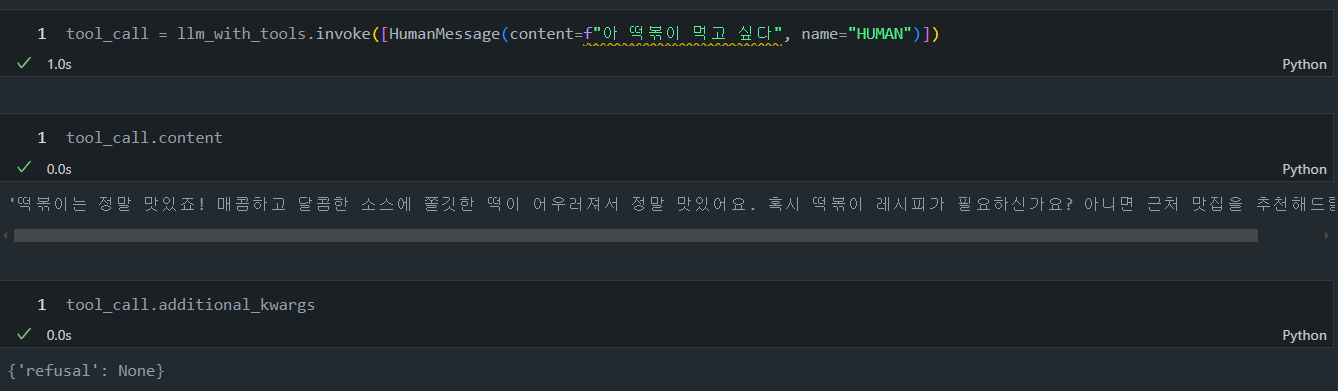
그럼 이제 기억으로 다시 이전 챕터 "Lesson 2: Simple Graph"로 기억을 되짚어서 가봅시다!
- 여기서 우리는 그래프의
State를 PythonTypeDict사용한 타입 힌팅 객체로 정의했었는데요.

- 이는 코드 작성 시
IDE나 타입 체커에게 힌트를 제공하지만,실제 파이썬 런타임에는 영향을 주지 않습니다.
- 이는 코드 작성 시
- 그리고 실제로
builder = StateGraph(State)에서State는 타입 정보를 제공합니다. 이는 그래프가 어떤 형태의 상태를 다룰지 명시하는 역할을 합니다.

- 실행 시, 각각의 노드 함수(예로, node_1 함수)는 딕셔너리 형태의 객체를 받아 처리합니다. 이 객체가 State 타입과 일치하는지는 런타임에 확인되지 않습니다.
자! 그러면 마찬가지로 LLM에서의 메세지를 State로 활용할 수 있습니다.
from typing_extensions import TypedDict
from langchain_core.messages import AnyMessage
class MessagesState(TypedDict):
messages: list[AnyMessage]-
MessagesState: 메세지들 역시 대화 상태를 나타내는 MessagesState(TypedDict 형태)로 나타내볼 수 있겠죠? messages 키 하나만 가지며, 이는메시지 객체(HumanMessage, AIMessage 등)의 리스트입니다.- 일반적인
TypedDict와 관련된 문제부터 살펴보겠습니다. 예를 들어,TypedDict로 상태를 정의하면 각 노드가 상태를 업데이트할 때 덮어쓰기(override)가 기본 동작으로 수행됩니다.- 이는 상태의 이전 값이 완전히 대체되기 때문에, 새 값으로 덮어씌워져 이전 메시지들이 사라지게 되는 문제를 일으킵니다.
- 일반적인
-
채팅 애플리케이션에서는 일반적으로 이전 메시지들을 유지하면서 새 메시지를 추가하고자 합니다.
- 하지만 이 코드에서는 각 노드가 실행될 때마다 전체 메시지 리스트가 덮어씌워집니다.
-
이러한 문제 때문에, 단순한 TypedDict 정의만으로는 효과적인 메시지 상태 관리가 어렵습니다. TypedDict를 단순히 사용하면, 각 노드에서 반환된 새로운 값이 이전 상태를 덮어씌우게 됩니다.
- 물론 이전처럼
+나append함수를 사용해서 문자열을 정보를 누적해줄 수 있지만, LangGraph에서는 별도로 리듀서 함수라는 기능을 제공하고 있습니다. - LangGraph에서는 리듀서 함수(예:
add_messages)를 사용하여 상태를 덮어쓰는 대신 새로운 데이터를 기존 상태에 추가할 수 있도록 만듭니다. MessagesState는 미리 정의된 상태 구조와add_messages리듀서를 포함하고 있기 때문에, 메시지 상태 관리에 최적화되어 있습니다.
- 물론 이전처럼
from langgraph.graph import MessagesState
class MessagesState(MessagesState):
# Add any keys needed beyond messages, which is pre-built
pass
# Initial state
initial_messages = [AIMessage(content="Hello! How can I assist you?", name="Model"),
HumanMessage(content="I'm looking for information on marine biology.", name="HUMAN")
]
# New message to add
new_message = AIMessage(content="Sure, I can help with that. What specifically are you interested in?", name="Model")
# Test
add_messages(initial_messages , new_message)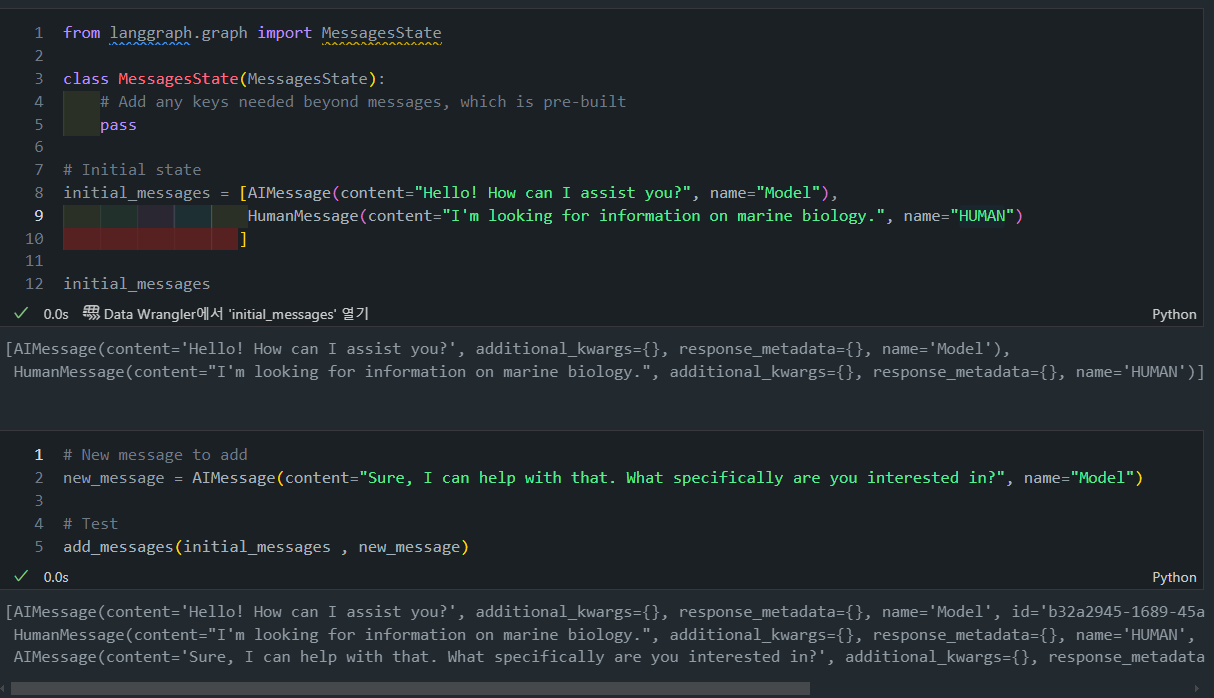
그럼 이제 그래프로 한번 시각화해보겠습니다. 해당 그래프는 단순하게 위에서 정의해둔 tool_calling_llm을 호출하고 이를 시각화한 코드입니다.
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# Node
def tool_calling_llm(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("tool_calling_llm", tool_calling_llm)
builder.add_edge(START, "tool_calling_llm")
builder.add_edge("tool_calling_llm", END)
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))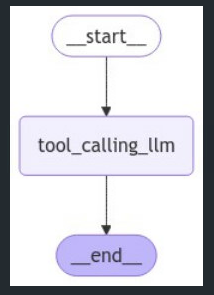
만든 그래프가 제대로 작동하는 것을 확인할 수 있습니다.
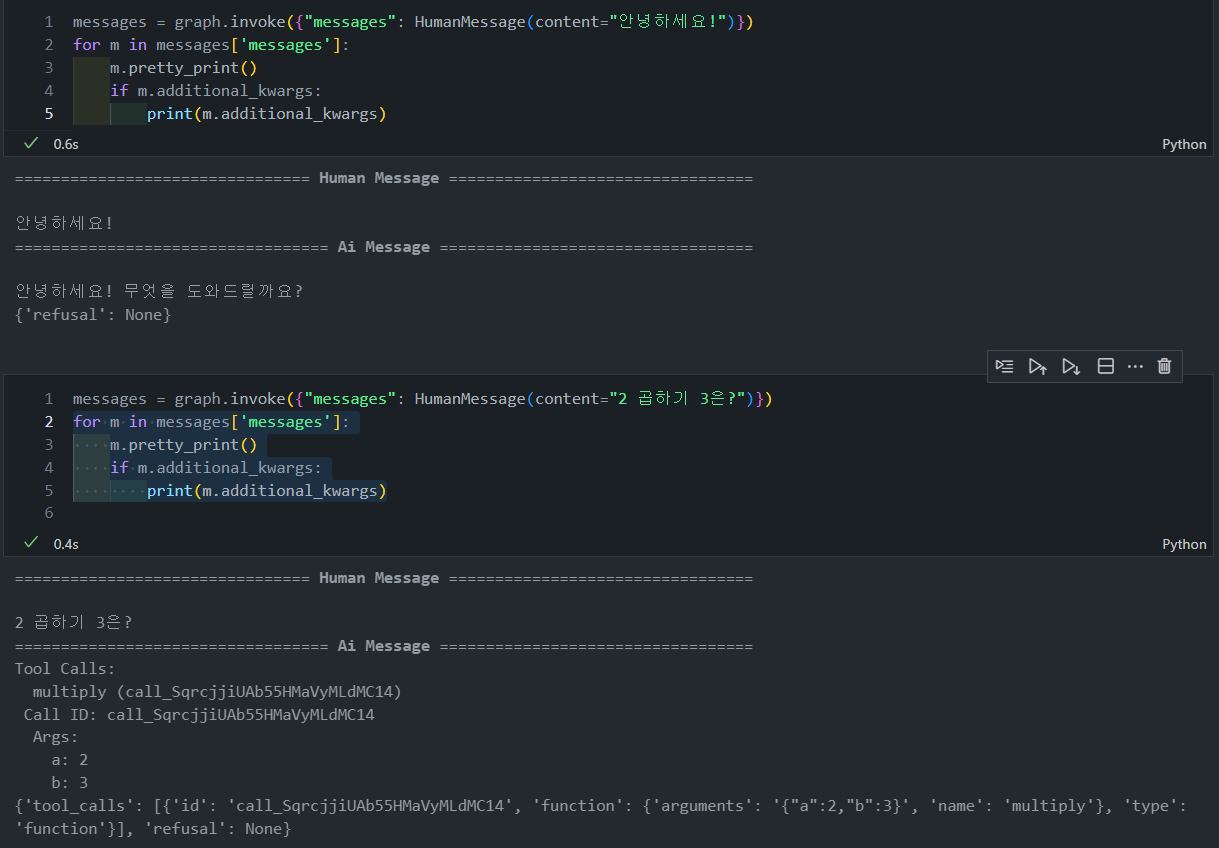
아래처럼 코드를 조금 변경하면 이어서 대화를 수행해볼 수 있습니다.
# Node
def tool_calling_llm(state: MessagesState):
# LLM 호출을 통해 새로운 메시지를 얻음
new_message = llm_with_tools.invoke(state["messages"])
# 기존 messages에 새 메시지를 추가
updated_messages = add_messages(state["messages"], new_message)
return {"messages": updated_messages}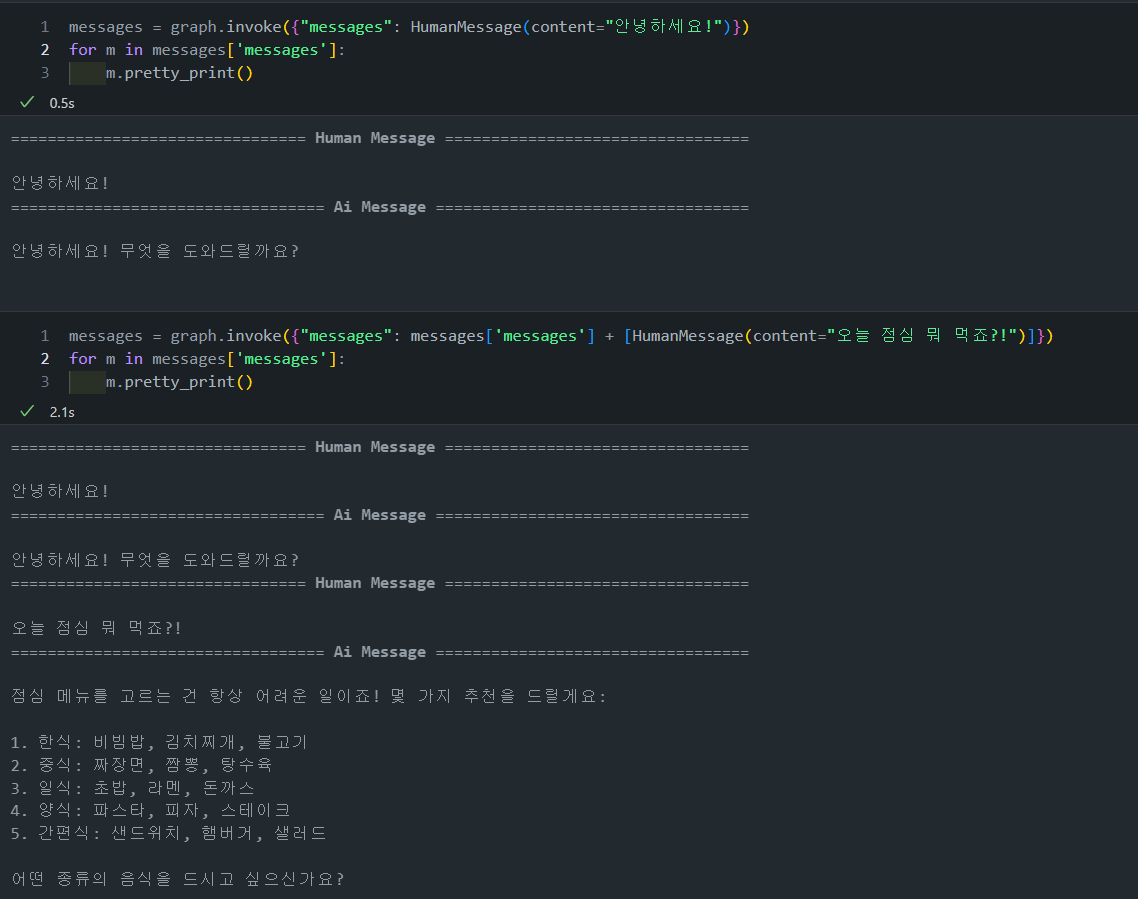
Lesson 5: Router
Router는 LLM이 자연어 응답 또는 도구 호출 중 하나를 선택하는 구조입니다.
- 사용자의 입력을 받아, LLM이 직접 응답할지 도구를 호출할지 결정하는 기본적인 에이전트 구조를 만듭니다.
Router의 핵심:
-
LLM은 입력에 따라 두 가지 경로 중 하나를 선택합니다.
-
도구 호출이 필요하면 도구 노드로 이동하고, 그렇지 않으면 응답을 바로 반환합니다.
-
Conditional Edge를 사용해 LLM의 출력에 따라 도구 호출 경로를 선택하거나 종료합니다.
-
langgraph.prebuilt의ToolNode와tools_condition은 LangGraph에서 제공하는 유용한 기능입니다. 각각의 역할과 기능을 설명해드리겠습니다:-
ToolNode:
- 목적: 여러 도구(tools)를 하나의 노드로 묶어 실행하는 기능을 제공합니다.
- 사용 방법:
ToolNode([tool1, tool2, ...])형태로 초기화합니다. - 기능:
- 주어진 도구 목록을 받아 실행할 수 있는 노드를 생성합니다.
- 상태에서 도구 호출 정보를 읽고, 해당 도구를 실행합니다.
- 도구 실행 결과를 상태에 추가합니다.
- 장점:
- 여러 도구를 쉽게 통합할 수 있습니다.
- 도구 실행 로직을 자동으로 처리합니다.
-
tools_condition:
- 목적: LLM의 출력이 도구 호출인지 아닌지를 판단하는 조건부 라우팅 함수입니다.
- 사용 방법:
add_conditional_edges()메서드의 조건 함수로 사용됩니다. - 기능:
- LLM의 최신 메시지를 검사하여 도구 호출 여부를 판단합니다.
- 도구 호출이면 'tools' 노드로 라우팅합니다.
- 도구 호출이 아니면 END 노드로 라우팅합니다.
- 장점:
- 도구 호출 여부에 따른 자동 라우팅을 제공합니다.
- 복잡한 조건 로직을 간단하게 구현할 수 있습니다.
-
(참고) tools_condition함수 snippet
from typing import (Any,Literal,Union) from langchain_core.messages import AnyMessage # Route the graph def tools_condition( state: Union[list[AnyMessage], dict[str, Any], BaseModel], ) -> Literal["tools", "__end__"]: if isinstance(state, list): ai_message = state[-1] elif isinstance(state, dict) and (messages := state.get("messages", [])): ai_message = messages[-1] elif messages := getattr(state, "messages", []): ai_message = messages[-1] else: raise ValueError(f"No messages found in input state to tool_edge: {state}") if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0: return "tools" return "__end__"
예시 코드
- 예시 코드를 한번 살펴보겠습니다:
- 사용자 입력이 들어오면
tool_calling_llm노드가 실행됩니다.
- 첫 번째 인자 "tool_calling_llm"은 출발 노드를 지정합니다.
- LLM이 응답을 생성합니다.
tools_condition함수가 LLM의 응답을 분석합니다.
- 두 번째 인자
tools_condition은 라우팅 함수입니다. - 도구 호출이면 tools 노드로 이동(tools 노드로 라우팅)하여 도구를 실행한 후 종료합니다.
- 일반 응답이면 바로 종료됩니다. (END 노드로 라우팅)
- 사용자 입력이 들어오면
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
from langgraph.graph import MessagesState
from langgraph.prebuilt import ToolNode
from langgraph.prebuilt import tools_condition
# Node
def tool_calling_llm(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# Build graph
builder = StateGraph(MessagesState)
# Define Nodes
builder.add_node("tool_calling_llm", tool_calling_llm)
builder.add_node("tools", ToolNode([multiply]))
# Define Edges
builder.add_edge(START, "tool_calling_llm")
builder.add_conditional_edges(
"tool_calling_llm",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
builder.add_edge("tools", END)
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))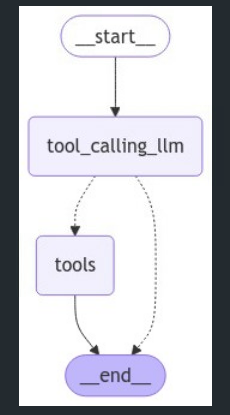
🤗
tools_condition이 tools 노드로 연결되는 로직은 tools_condition 함수 내부에 구현되어 있으며, add_conditional_edges 메서드를 통해 그래프에 적용됩니다.
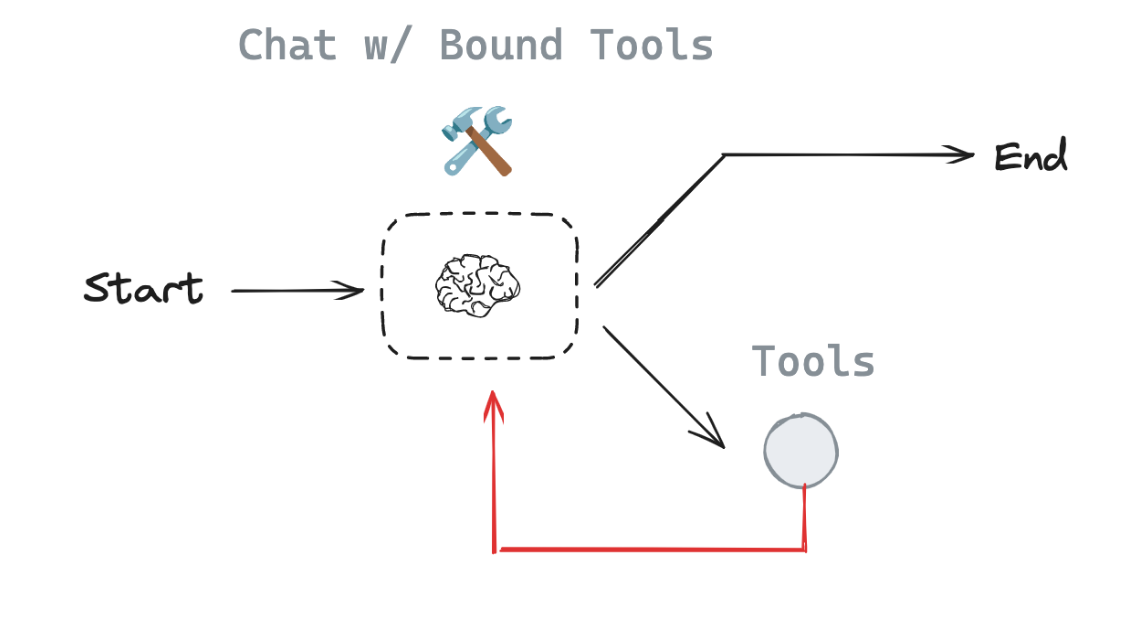
Lesson 6: Agent
이전에 구현한 라우터는 사용자 입력에 따라 도구 호출 여부를 결정했습니다. 조건부 엣지(add_conditional_edges)를 사용하여 도구 호출 노드나 종료로 라우팅했습니다.
이번 챕터에서는 Router를 확장하여 에이전트(Agent)를 구성할 수 있습니다. 에이전트는 Router와 비슷하지만, 도구 호출 결과를 다시 LLM에게 전달하고, LLM이 그 결과를 바탕으로 추가적인 결정을 내리도록 구성할 수 있습니다.
-
이를 React 에이전트(반응형 에이전트)라고 하며,
세 가지 단계로 나뉩니다.- Act: LLM이 도구를 호출하는 단계.
- Observe: 도구 호출 결과를 LLM에게 전달하는 단계.
- Reason: LLM이 도구 결과를 바탕으로 추가적인 결정을 내리는 단계.
-
이 방식은 여러 번의 도구 호출을 필요로 하는 복잡한 작업을 처리할 수 있으며, LLM이 결과를 기반으로 추가 작업을 수행할 수 있는 유연성을 제공합니다.
코드 예시
from langgraph.graph import START, StateGraph
from langgraph.prebuilt import tools_condition
from langgraph.prebuilt import ToolNode
from IPython.display import Image, display
# Graph
builder = StateGraph(MessagesState)
# Define nodes: these do the work
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
builder.add_edge("tools", "assistant")
react_graph = builder.compile()
# Show
display(Image(react_graph.get_graph(xray=True).draw_mermaid_png()))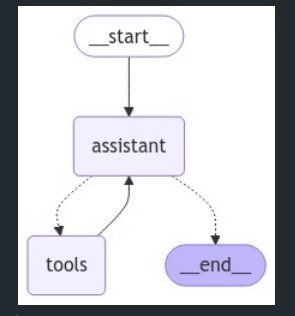
- Assistant 노드가 실행된 후, tools_condition이 도구 호출 여부를 확인합니다.
- 도구 호출이면 Tools 노드로 이동하고, 그 결과를 다시 Assistant에 전달합니다.
- 이 루프는 모델이 도구 호출을 중단할 때까지 계속됩니다.
- 모델이 직접 응답하면 그래프가 종료됩니다.
아래는 해당 코드를 실행한 결과입니다:
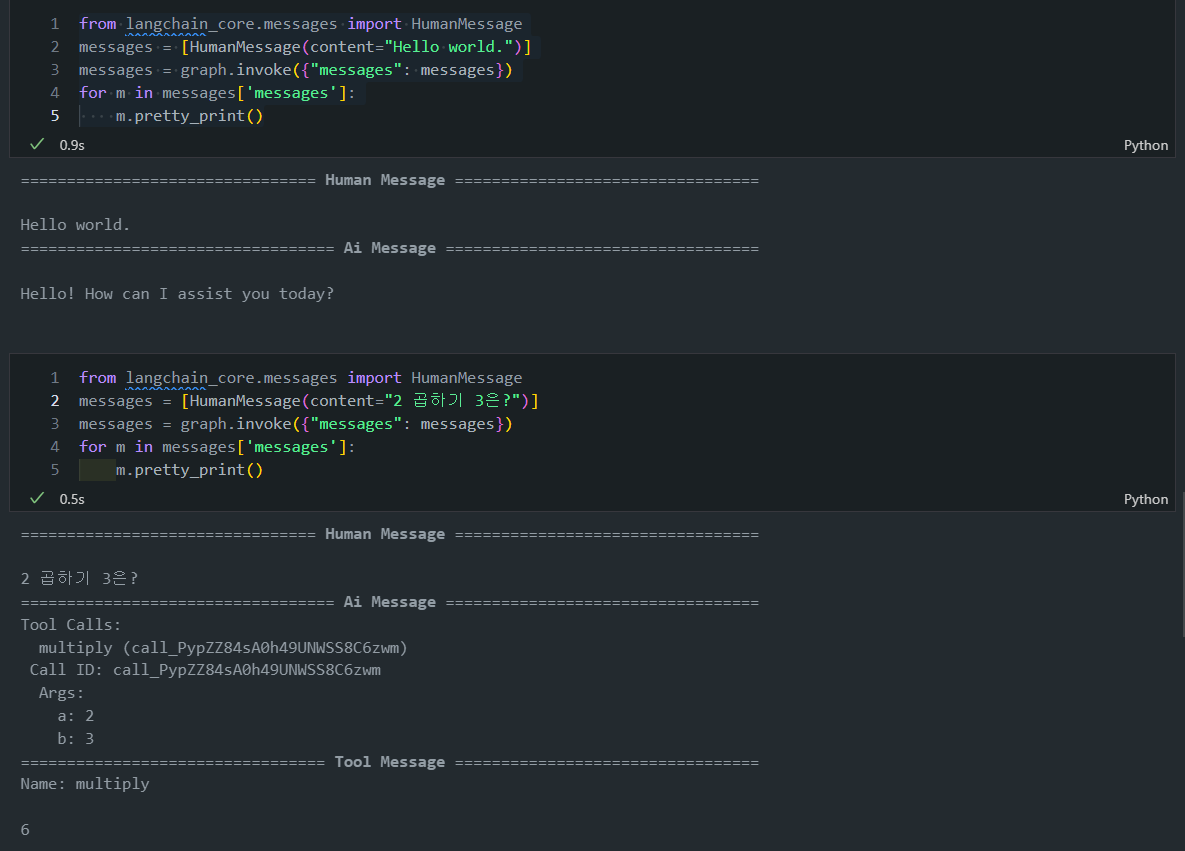
messages = [HumanMessage(content="3과 4를 더합니다. 출력에 2를 곱합니다. 출력을 5로 나눕니다")]
messages = react_graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()- 그래프는 START 노드에서 시작하여 정의된 노드들을 순차적으로 또는 조건에 따라 실행합니다.
- 아래 그림을 보면 Assistant 노드가 실행된 후, tools_condition가 도구를 여러번 호출하고 있는 것을 확인할 수 있습니다.
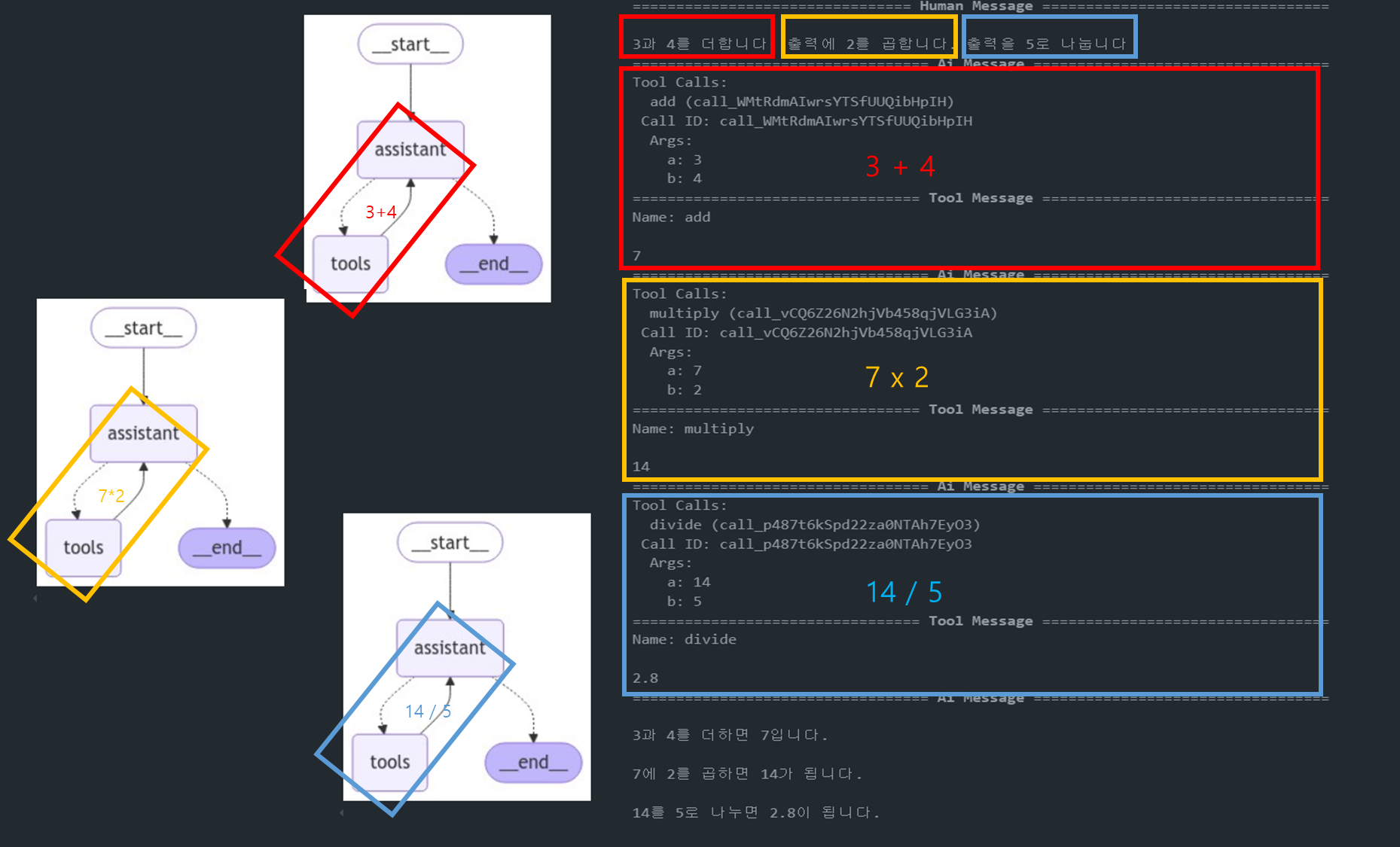
아래는 LangSmith 결과인데 이를 보면 실제로도 Assitant가 Tool을 호출해서 실행하고 있는 것을 직접 확인해볼 수도 있습니다.
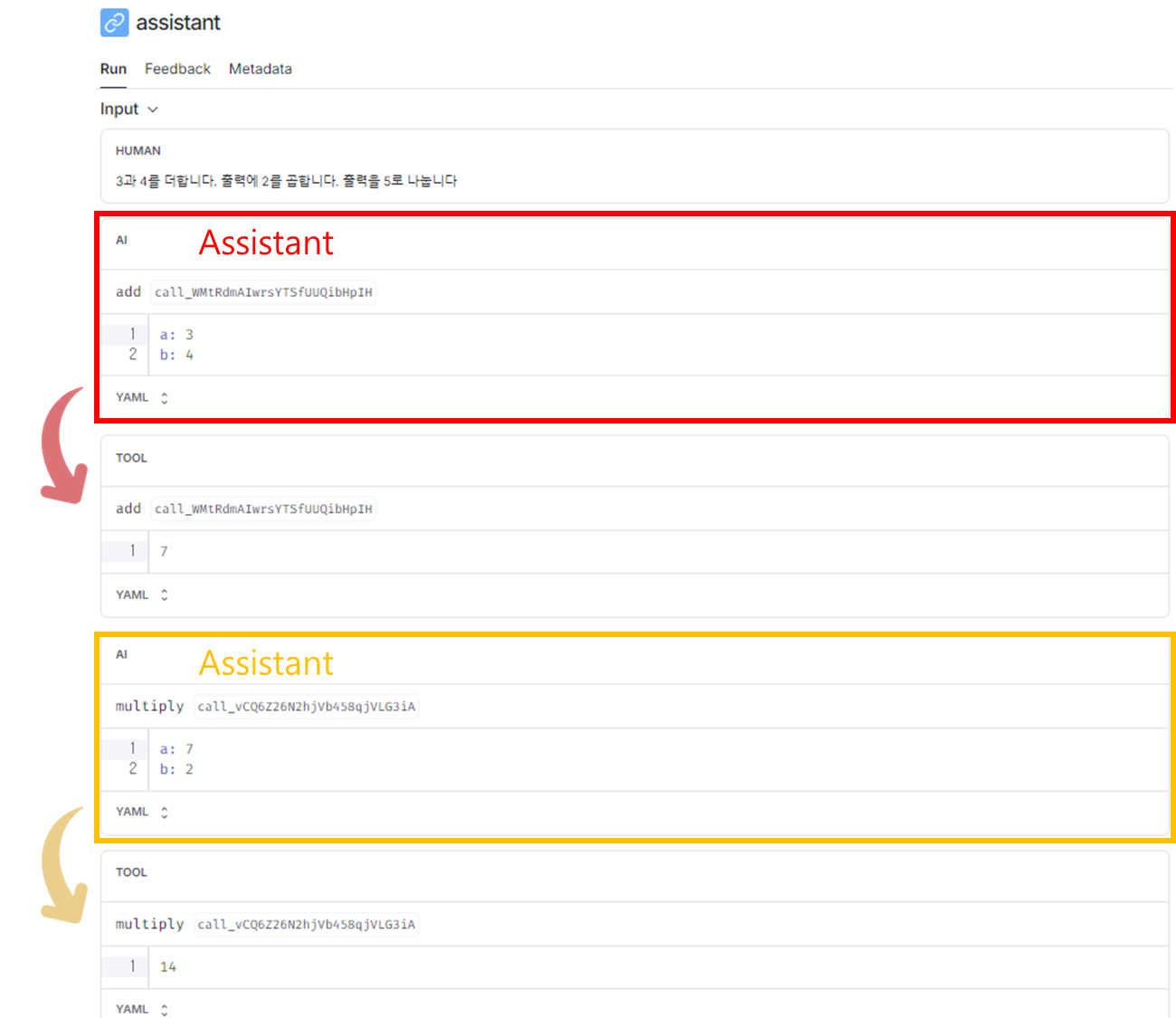
Lesson 7: Agent with Memory
앞에 Lesson6에 이어서 살펴보면 이렇게 각각 서로 다른 주피터 Cell에서 실행을 하게되면 다른 Cell에서 얘기했던 내용을 기억하지 못하고 새롭게 대화를 이어나가는 것을 볼 수 있습니다.
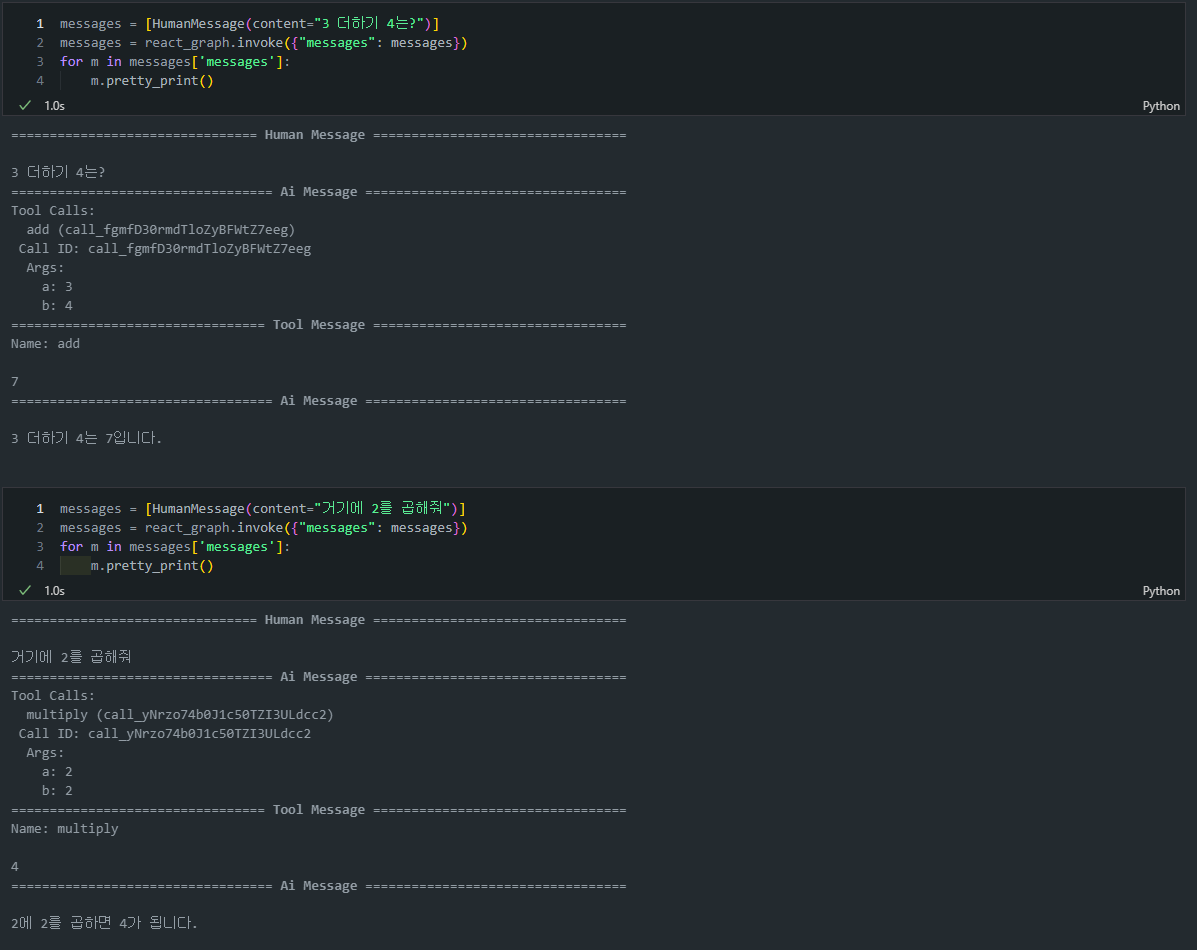
이는 바로 기억(메모리)를 하지 못하기 때문인데요.
- 에이전트에 메모리를 추가하면 상태를 유지하고, 이전에 처리한 정보를 기억하여 더 복잡한 상호작용을 처리할 수 있습니다.
- Langraph는 체크포인터(Checkpointer)를 사용해 그래프의 상태를 각 단계마다 저장하고, 이를 기반으로 이후에 상태를 복원하여 작업을 이어나갈 수 있습니다.
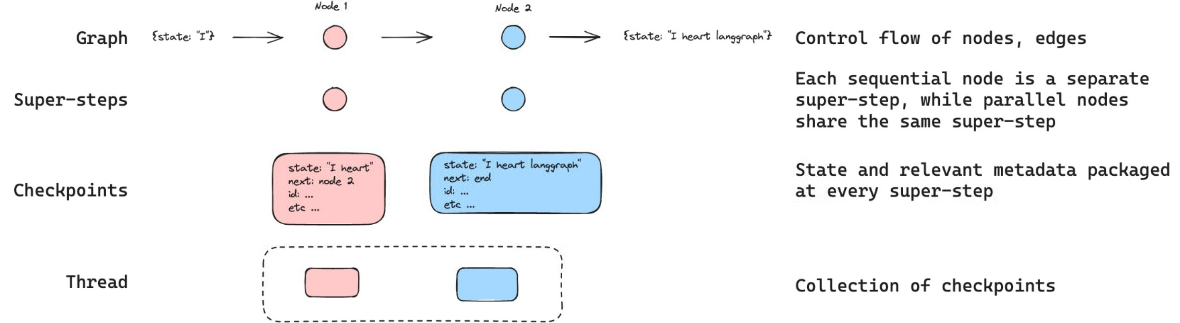
주요 용어 정리:
MemorySaver:- LangGraph에서 제공하는 인메모리 체크포인터 구현입니다.
- 그래프의 상태를 메모리에 저장하고 관리합니다.
- 간단하고 빠른 상태 관리를 위해 사용됩니다.
Checkpointer (체크포인터):- 그래프 실행 중 각 단계에서 상태를 저장하는 메커니즘입니다.
- 여러 스레드의 상태를 관리합니다.
Thread (스레드):- 그래프 실행의 독립적인 인스턴스를 나타냅니다.
- 각 스레드는 별도의 대화 세션이나 작업 흐름을 의미합니다.
Thread ID (스레드 ID):- 각 스레드를 고유하게 식별하는 식별자입니다.
- 사용자가 정의하며, 보통 사용자 ID나 세션 ID 등을 사용합니다.
이 방식은 LLM이 한 번에 여러 작업을 처리하는 상황에서 매우 유용하며, 상태 간의 일관성을 유지할 수 있습니다.
스레드 ID와 체크포인트의 연관성:
- 각 스레드는 고유한 ID를 가집니다.
- 체크포인터는 이 스레드 ID를 사용하여 각 스레드의 상태를 개별적으로 저장하고 관리합니다.
- 스레드 ID를 통해 특정 대화나 작업의 상태를 저장하고 불러올 수 있습니다.
사용 방법:
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph
memory = MemorySaver()
graph = StateGraph(...).compile(checkpointer=memory)
# 스레드 1의 상태 저장
result1 = graph.invoke(input_data, config={"configurable": {"thread_id": "user1"}})
# 스레드 2의 상태 저장
result2 = graph.invoke(input_data, config={"configurable": {"thread_id": "user2"}})
# 스레드 1의 상태 불러오기
state1 = graph.get_state({"configurable": {"thread_id": "user1"}})- 이렇게
thread_id를 사용하여 각 대화나 작업의 상태를 독립적으로 관리할 수 있습니다. checkpointer는 이thread_id를 키로 사용하여 각 스레드의 상태를 저장하고 검색할 수 있습니다.
코드 예시
1. config에 thread_id 정의 후 message invoke
-
메모리를 사용할 때는 thread_id를 지정해야 합니다.
-
이 thread_id는 그래프 상태의 컬렉션을 저장합니다.
# Specify a thread config = {"configurable": {"thread_id": "1"}} # Specify an input messages = [HumanMessage(content="Add 3 and 4.")] # Run messages = react_graph_memory.invoke({"messages": messages}, config) for m in messages['messages']: m.pretty_print()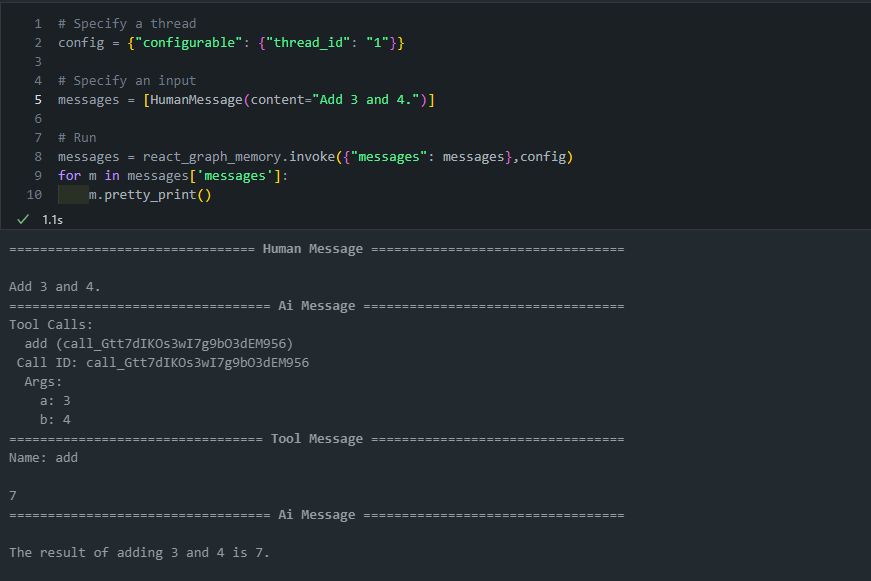
- checkpointer는 그래프의 모든 단계에서 상태를 기록합니다.
- 이 체크포인트들은 스레드에 저장됩니다.
- 나중에 thread_id를 사용하여 해당 스레드에 접근할 수 있습니다.
- 해당
config를 물고 다음 invoke를 수행하면 memory가 유지되는 것을 확인할 수 있습니다.messages = [HumanMessage(content="Multiply that by 2.")] messages = react_graph_memory.invoke({"messages": messages}, config) for m in messages['messages']: m.pretty_print()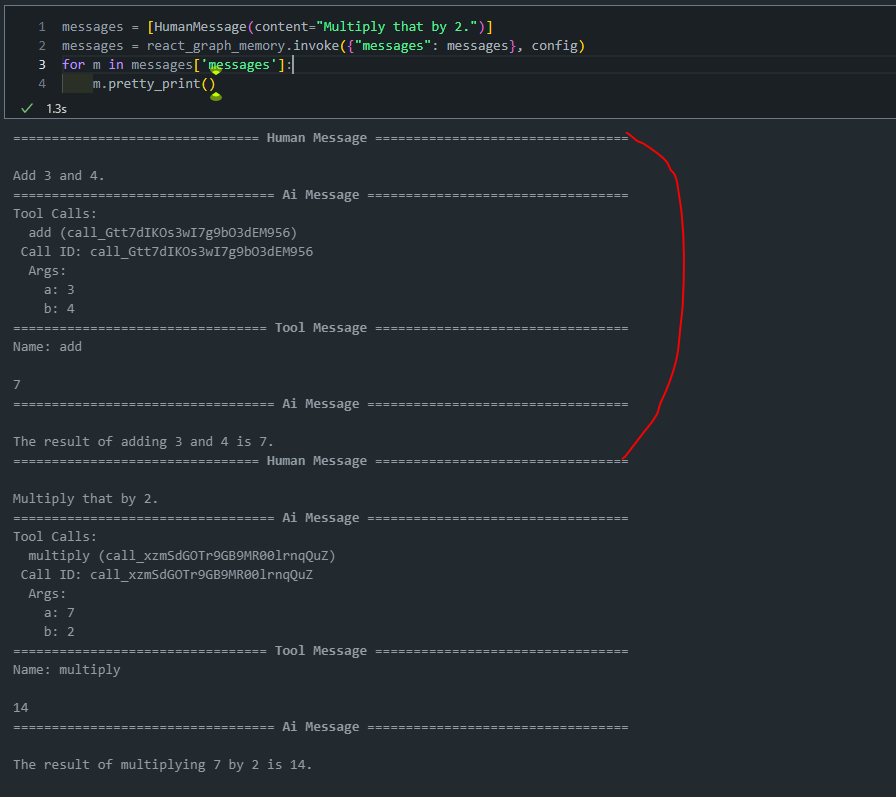
Lesson 8: Deployment
Langraph로 만든 에이전트는 Langraph Cloud를 통해 쉽게 배포할 수 있습니다. GitHub 저장소와 연결하면 자동으로 배포할 수 있으며, 배포된 에이전트는 API를 통해 접근할 수 있습니다. 저는 유료 사용자가 아니라서 별도의 실습은 수행하지 않았습니다.
-
LangGraph:- Python과 JavaScript 라이브러리
- 에이전트 워크플로우 생성 가능
-
LangGraph API:- 그래프 코드를 번들로 제공
- 비동기 작업 관리를 위한 태스크 큐 제공
- 상호작용 간 상태 유지를 위한 지속성 제공
-
LangGraph Cloud:- LangGraph API의 호스팅 서비스
- GitHub 저장소에서 그래프 배포 가능
- 배포된 그래프에 대한 모니터링 및 추적 제공
- 각 배포에 대해 고유 URL 제공
-
LangGraph Studio:- LangGraph 애플리케이션을 위한 통합 개발 환경(IDE)
- API를 백엔드로 사용하여 실시간 테스트 및 그래프 탐색 가능
- 로컬 또는 클라우드 배포로 실행 가능
-
LangGraph SDK:- LangGraph 그래프와 프로그래밍 방식으로 상호작용하기 위한 Python 라이브러리
- 로컬 또는 클라우드에서 제공되는 그래프 작업을 위한 일관된 인터페이스 제공
- 클라이언트 생성, 어시스턴트 접근, 스레드 관리, 실행 등 가능
-
로컬 테스팅:- LangGraph Studio에서 로컬로 제공되는 그래프에 쉽게 연결 가능
- Studio UI의 왼쪽 하단에 제공되는 URL을 통해 연결
이 구조를 통해 LangGraph는 에이전트 워크플로우의 개발, 테스트, 배포, 관리를 위한 종합적인 환경을 제공합니다. 개발자는 로컬에서 그래프를 만들고 테스트한 후, 클라우드에 쉽게 배포하고 모니터링할 수 있습니다.
다음 Module은 2번째 모듈 State and Memory 관련 내용입니다.
다음 글에서 뵙겠습니다 🤗

면접때문에 랭그래프 공식문서 번역기 가지고도 잘 이해못하면서 읽다가 써주신 글 보니 이해가 확 되네요 ㅠㅠ 감사합니다