
CPU와 GPU
딥러닝과 머신러닝을 학습하거나 작업할 때 GPU를 사용하는 것은 이제 당연하게 여겨집니다. 실제로 아래와 같은 코드로 GPU나 CPU를 손쉽게 선택할 수 있습니다.
import torch
# CUDA 사용 여부 확인
USE_CUDA = torch.cuda.is_available()
print(USE_CUDA)
# device 선언
device = torch.device('cuda:0' if USE_CUDA else 'cpu')하지만, "CPU는 직렬 연산, GPU는 병렬 연산!"이라는 간단한 지식만으로 이 강력한 연산 장치를 제대로 이해할 수 있을까요?
이번 포스팅에서는 CPU와 GPU의 차이점, GPU가 딥러닝에서 강력한 이유, 그리고 GPU 내부의 연산 구조를 깊이 있게 살펴보겠습니다.
CPU와 GPU의 차이점
CPU와 GPU는 둘 다 데이터를 읽어들여 연산처리를 통해 답을 도출하는 기능을 수행하나, 이름과 구조에서 알수 있듯이 중앙 처리 장치(CPU)와 그래픽 처리 장치(GPU)는 역할이 매우 다릅니다.
- 중앙 처리 장치(CPU, Central Processing Unit)
- 그래픽 처리 장치(GPU, Grapical Processing Unit)
CPU·GPU와 같은 프로세서 내부는 크게 연산을 담당하는 산출연산처리장치(ALU, Arithmetic Logic Unit)와 명령어를 해석·실행하는 컨트롤유닛(CU, Control Unit), 각종 데이터를 담아두는 캐시(Cache)로 나뉘게 됩니다. 각각 하나씩 살펴보도록 하겠습니다.
1. CPU란 무엇인가?
CPU(중앙처리장치, Central Processing Unit)는 컴퓨터 시스템의 두뇌 역할을 합니다. 모든 명령을 처리하고, 입력과 출력을 제어하며, 시스템의 다른 부품을 지휘합니다.
- 순차 처리(Sequential Processing): CPU는 입력된 명령을 하나씩 처리하며, 복잡한 작업을 빠르게 해결하도록 설계되었습니다.
- 구성 요소: CPU는 연산을 담당하는 산술논리유닛(ALU), 명령을 제어하는 컨트롤 유닛(CU), 그리고 데이터를 임시 저장하는 캐시(Cache)로 이루어져 있습니다.
- 코어 수와 캐시: 일반적으로 CPU는 소수의 강력한 코어(예: 4~8개)를 가지며, 대용량 캐시를 통해 속도 병목을 최소화합니다.

좀 더 풀어서 설명하자면 아래와 같이 설명할 수 있습니다:
-
CPU는 입출력장치, 기억장치, 연산장치를 비롯한 컴퓨터 리소스를 이용하는 최상위 계층 장치로써, 컴퓨터의 두뇌를 담당합니다. CPU는 컴퓨터 및 운영 체제에 필요한 명령과 처리를 실행하므로 모든 현대 컴퓨팅 시스템에 필수적인 요소입니다.
-
CPU는 명령어가 입력된 순서대로 데이터를 처리하는 순차적인(Sequential) 처리 방식에 특화된 구조를 가지고 있습니다. 이는 한 번에 한 가지의 명령어만 처리한다는 것을 의미하며, 그렇기에 연산을 담당하는 ALU의 개수가 많을 필요가 없게 됩니다. 예를 들어 CPU 제품들 중 Octa-core CPU의 경우에는 코어 당 1개씩, 총 8개의 ALU가 탑재되어 있는 제품입니다.
-
CPU 내부의 절반 이상은 캐시 메모리로 채워져 있습니다. 캐시 메모리는 CPU와 램(RAM)과의 속도차이로 발행하는 병목현상을 막기 위한 장치로써, CPU가 처리할 데이터를 미리 RAM에서 불러와 CPU 내부 캐시 메모리에 임시로 저장해 처리 속도를 높일 수 있게 됩니다. CPU가 단일 명령어를 빠르게 처리할 수 있는 비결도 바로 이 캐시 메모리 때문이라고 할 수 있습니다.
2. GPU란 무엇인가?
GPU(그래픽처리장치, Graphics Processing Unit)는 대규모 병렬 연산을 처리하도록 설계된 연산 장치입니다. 초기에는 주로 그래픽 렌더링에 사용되었으나, 현재는 딥러닝, 과학 연산, 암호화폐 채굴 등 다양한 분야에서 활용되고 있습니다.
- 병렬 처리(Parallel Processing): GPU는 단순 연산을 동시에 수행할 수 있는 수천 개의 코어를 가지고 있어 반복적인 연산에서 CPU보다 훨씬 빠릅니다.
- 구성 요소: GPU는 여러 개의 작은 코어와 병렬 연산을 지원하는 메모리 아키텍처로 구성되어 있습니다.
- 코어 수와 성능: 최신 GPU는 수천 개의 코어를 가지며, 이를 통해 동일한 작업을 병렬로 처리합니다.

💡 여기서 잠깐!
그렇다면 "딥러닝을 학습할때 GPU를 쓰면 무조건 성능이 좋다그러던데 그럼 GPU가 CPU보다 빠르고, 좋은거 아닌가?" 라는 의문점을 품는 이들이 있을 것입니다.
- ❓
일반적으로 범용 컴퓨팅 측면에서,CPU는 GPU보다 훨씬 더 성능이 좋다고 할 수 있습니다. CPU는 GPU에서 발견되는 것보다 더 높은 클럭 속도(aka 주파수)를 가진 더 적은 수의 프로세서 코어 로 설계되어 일련의 작업을 매우 빠르게 완료 할 수 있기 때문입니다.- 🤔
하지만, 딥러닝 학습 측면에서는GPU가 CPU보다 좋다고 할 수 있습니다.
GPU에 대해 더 디테일하게 알아볼까요?
GPU는 CPU에 비해 훨씬 더 많은 수의 코어를 가지고 있으며 애초에 설계도 다른 목적으로 만들어졌습니다. 최초의 GPU는 이름에서 알수 있다시피 그래픽 처리 장치로써, 그래픽 렌더링의 성능을 가속화하도록 설계되었습니다.
CPU와 GPU의 발전을 간단하게 소개를 안 할 수가 없을 것 같은데요. 아주 좋은 설명이 있어서 링크 걸어두겠습니다. (링크 : 그래픽 카드 이야기)
본 영상을 요약하자면, 기존의 CPU는 컴퓨터가 하는 모든 일을 조종/통제해왔습니다. 그러나 점점 기술이 발전하면서 GUI(Graphical User Interface) 등의 다양한 로드가 추가 되었고, 이는 CPU의 성능 저하로 이어져 CPU가 제때 제때 중요한 연산을 못하게 되었습니다.
그러자 이제 개발자들은 간단한 연산들(ex. 그래픽 작업)은 다른 Processing Unit에게 맡기고 기존의 중요한 일을 CPU에게 맡기도록 하자는 아이디어가 나왔고 그것이 바로 GPU의 탄생이 되게 됩니다.
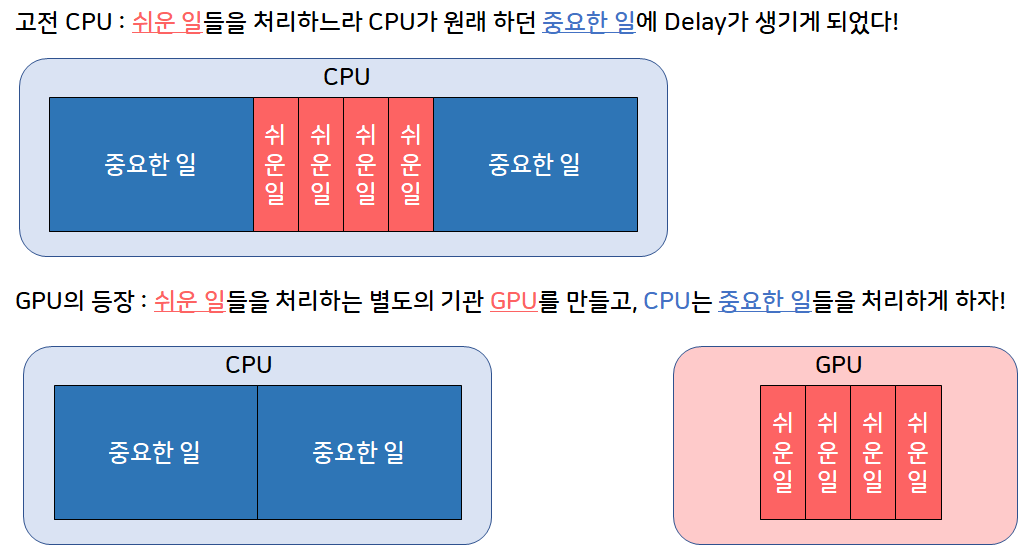
이렇게 CPU의 부담스러운 계산을 GPU가 오프로드해줌으로써 처리 능력을 확보 할 수 있도록함으로써 계속해 발전되어 왔습니다. CPU는 GPU를 포함한 시스템의 나머지 부분에 지침을 제공하는 작업의 두뇌로, GPU는 병렬 처리 아키텍처로 인해 CPU보다 이미지 렌더링에 최적화되어 발전되어 왔습니다. 요약하자면, CPU는 어려운 문제를 푸는데 특화된 소수 정예 싱글코어, 그리고 GPU는 쉬운 문제를 동시에 푸는 데 특화된 인해전술 멀티코어라고 보면 될거 같습니다.
기존의 CPU가 순차적인 처리 방식에 특화되어 있었다면, GPU는 병렬적인(Parallel) 처리 방식에 특화되어 있으며 이로 인해 반복적이고 비슷한 대량의 연산을 수행하는 데에 있어서 속도가 빠릅니다. GPU는 더 작고 보다 전문화된 여러개의 코어로 구성된 프로세서입니다.
여러 개의 코어가 함께 작동하므로, 여러 코어로 나누어 처리할 수 있는 작업의 경우 GPU가 엄청난 성능 이점을 제공합니다. 기존의 CPU가 6-8개의 코어로 구성되어 있다면, GPU는 어떤 GPU인가에 따라 많이 상이하지만 적게는 수백개에서 많게는 수천개의 코어로 구성되어 있습니다.
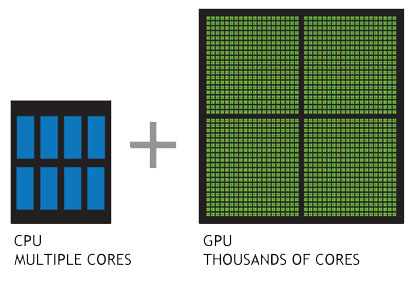
Source : https://kr.nvidia.com/object/what-is-gpu-computing-kr.html
우리가 딥러닝을 생각해보면 대부분이 벡터나 행렬 연산으로 이루어져있다고 해도 과언이 아닌데요. 이러한 잘 나누어지는 계산, 즉 병렬성이 극대화된 계산은 GPU가 이미 해오던 연산으로, GPU를 딥러닝 연산에 사용하게 됨으써 CPU보다 더 빠르고 최적화된 연산을 수행하게 됬다고 보시면 될 것 같습니다.
비교: CPU와 GPU의 설계 철학
-
CPU는 전문가, GPU는 작업 분담형 공장
CPU는 복잡하고 다양한 작업을 고속으로 처리할 수 있는 만능 전문가와 같습니다. 반면 GPU는 많은 일꾼이 한 가지 작업을 나누어 수행하는 공장과 같아 대량의 데이터를 효율적으로 처리합니다. -
CPU vs GPU 아키텍처 비교
| 특징 | CPU | GPU |
|---|---|---|
| 주요 역할 | 범용 처리(운영체제, 애플리케이션 등) | 병렬 연산(그래픽, 딥러닝 등) |
| 코어 수 | 소수(4~8개) | 다수(수백~수천 개) |
| 처리 속도 | 고속 싱글 연산 | 다량의 연산을 병렬 처리 |
| 메모리 구조 | 대용량 캐시 | 고대역폭 메모리 |
| 연산 최적화 | 순차 연산 | 병렬 연산 |
실험해봅시다!
다음은 속도 비교를 위해 간단하게 코드로 연산 및 처리 속도를 비교해 본 것인요.
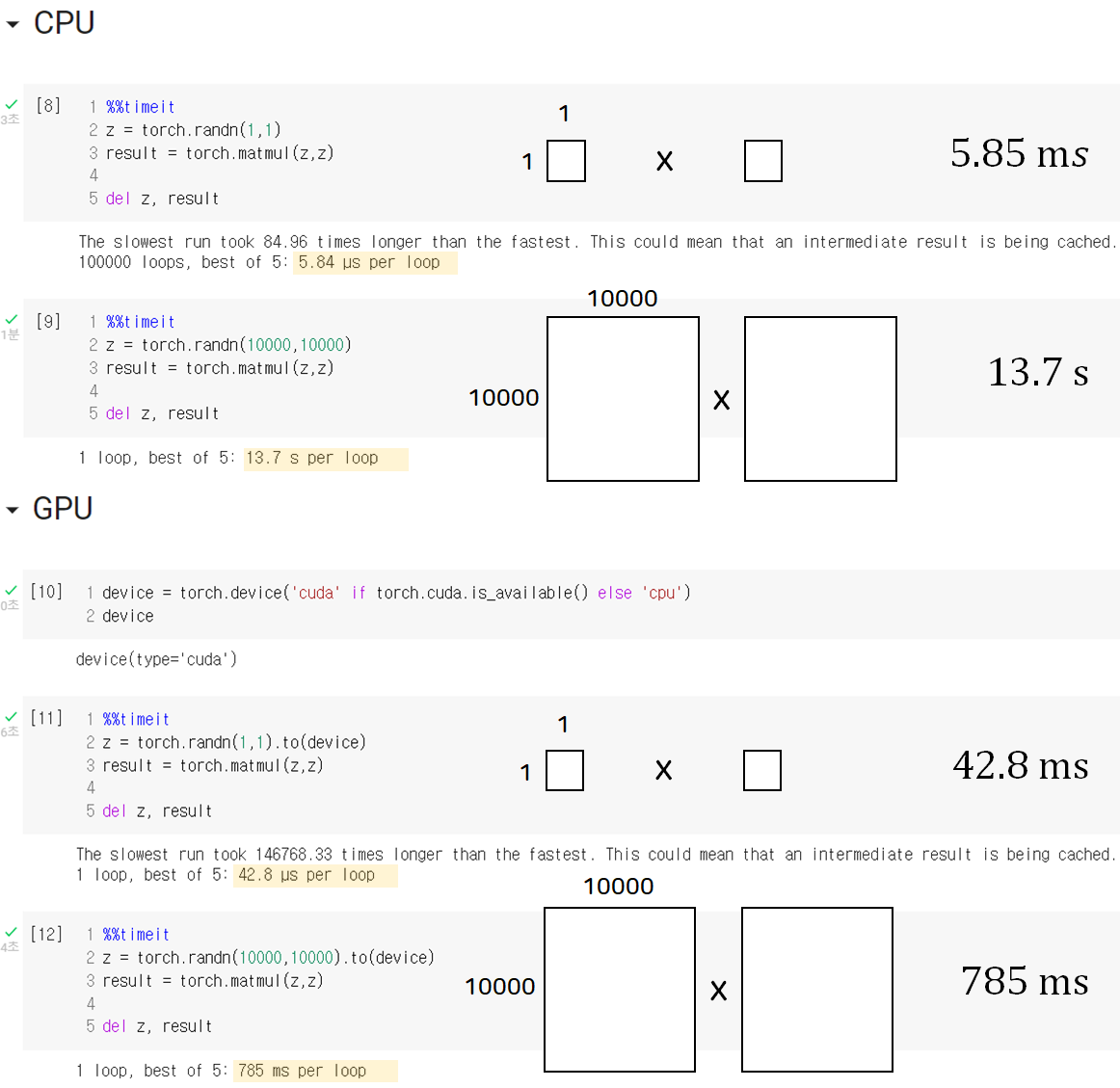
단순한 상수 연산을 수행할 때 각각 CPU는 5.84ms, GPU는 42.8ms가 나온 것을 통해 우리는 CPU가 하나의 연산을 수행함에 있어서 더 우수한 것을 볼 수 있습니다.
반면에 10000 by 10000 행렬연산을 수행하는 데 있어서는 CPU는 13.7s, GPU는 785ms인 것을 통해 GPU가 병렬 연산을 하는데 있어서 더 빠른 것을 직접적으로 확인해 볼 수 있습니다.
GPU의 실전 응용
- GPU는 아래 용도로 쓰일 수 있습니다:
-
딥러닝 학습: 딥러닝 모델은 수십억 개의 파라미터를 학습하기 위해 GPU의 병렬 연산을 활용합니다. GPU의 텐서 코어는 이러한 학습 작업을 빠르고 효율적으로 수행합니다. -
그래픽 렌더링: GPU는 3D 그래픽에서 모델 변환, 조명 계산, 텍스처 매핑 등 여러 작업을 동시에 처리합니다. 이를 통해 실시간으로 고품질 그래픽을 렌더링할 수 있습니다. -
암호화폐 채굴: GPU는 병렬로 수많은 해시 연산을 수행하여 비트코인과 같은 암호화폐 채굴 작업에 사용됩니다. SHA-256 해싱 알고리즘을 반복적으로 실행하여 빠르게 결과를 도출합니다.
GPU 내부 구조 살펴보기
- 참고 영상 : https://youtu.be/h9Z4oGN89MU
최신 GPU의 내부는 수많은 기술적 혁신과 병렬 연산의 비밀이 담긴 복잡한 설계를 가지고 있습니다.
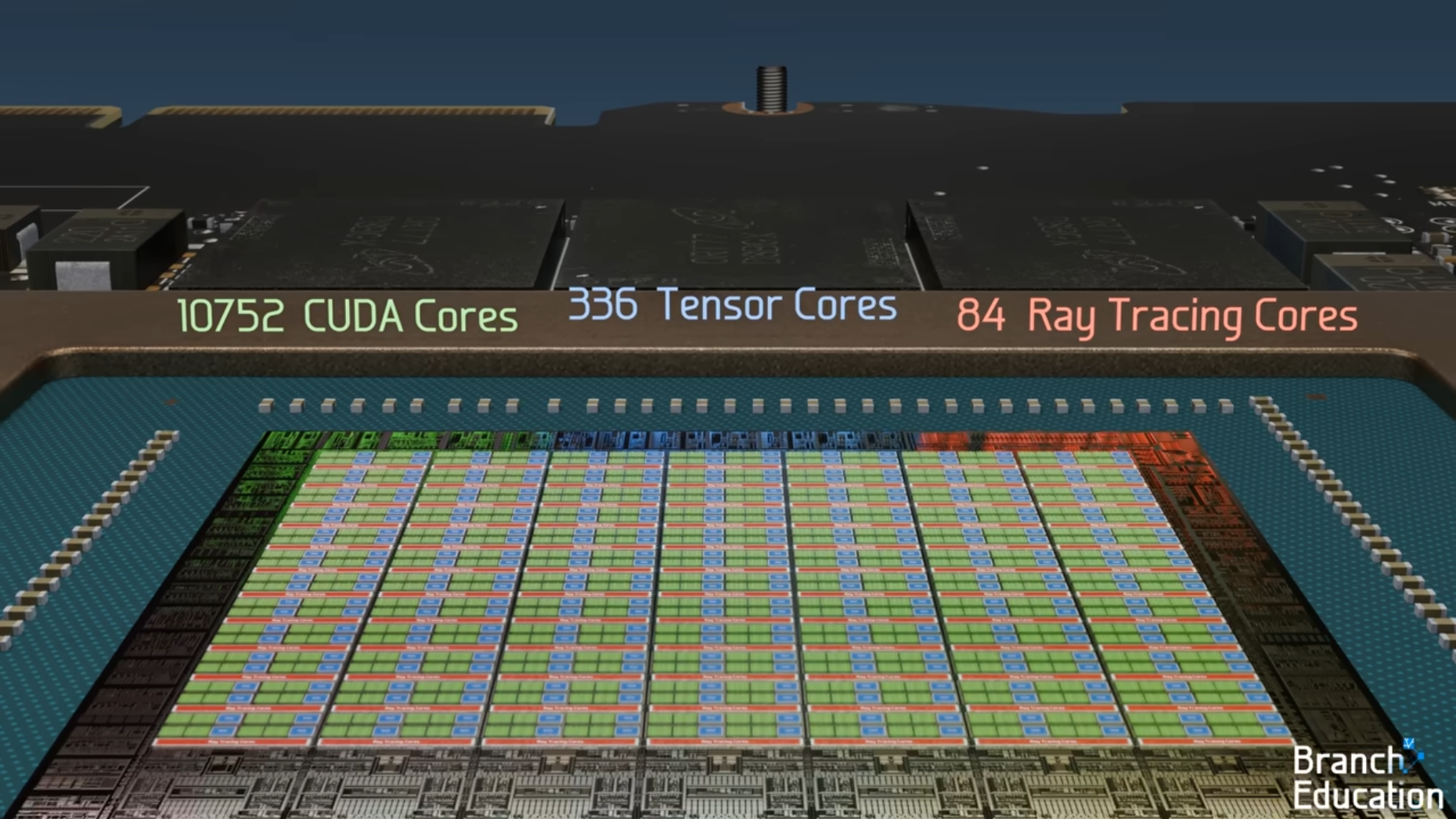
출처: How do Graphics Cards Work? Exploring GPU Architecture(링크)
NVIDIA RTX 3090 GPU를 기준으로 하여 세부적으로 살펴보겠습니다. 일단 GPU는 아래 3가지 코어로 구성이 되어 있습니다.
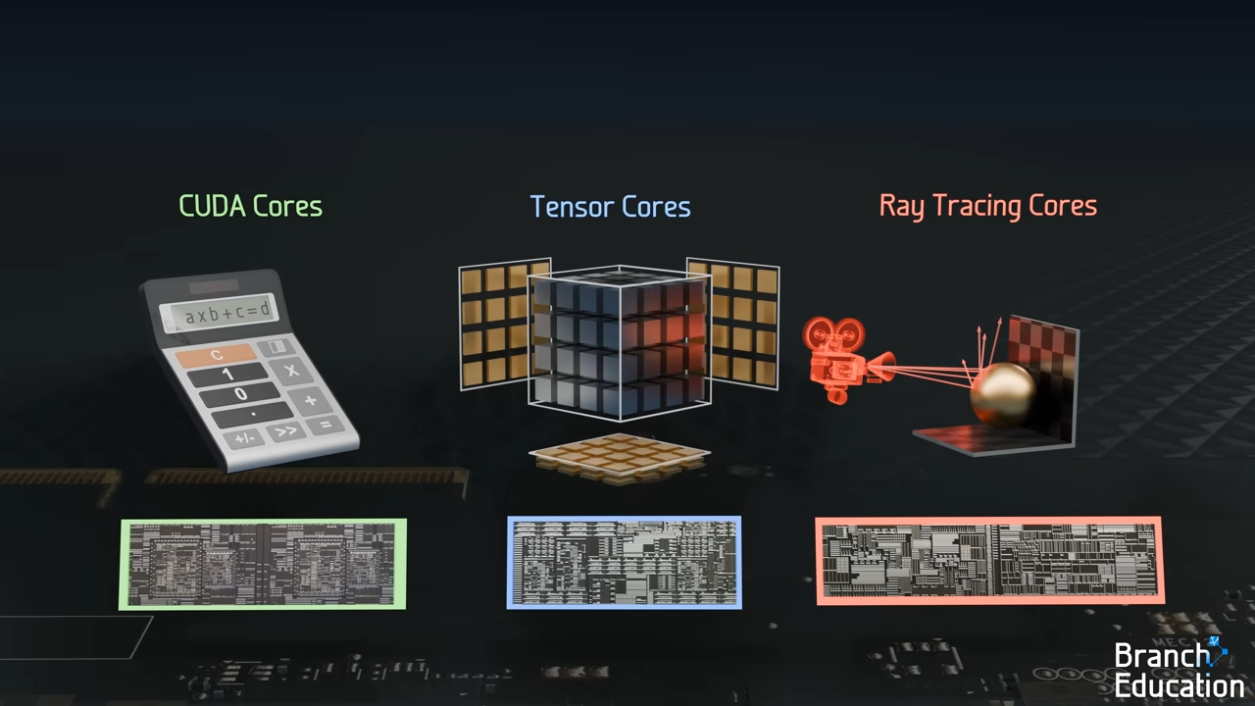
출처: How do Graphics Cards Work? Exploring GPU Architecture(링크)
- CUDA Cores
- Tensor Cores
- Ray Tracing Cores
1. 코어와 병렬 처리
CUDA 코어는 GPU의 기본 구성 요소입니다. RTX 3090에는 10,496개의 CUDA 코어가 있으며, 이 코어들은 간단한 산술 연산(덧셈, 곱셈 등)을 수행합니다.
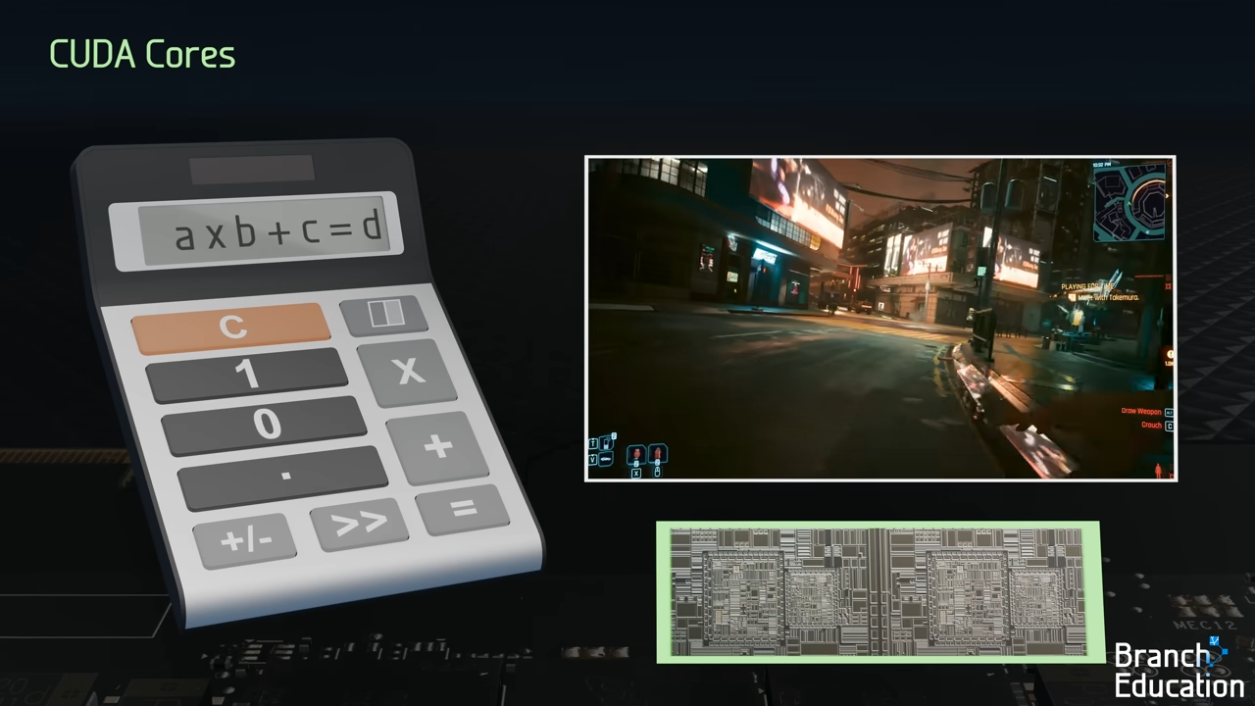
출처: How do Graphics Cards Work? Exploring GPU Architecture(링크)
-
CUDA 코어란? (범용 병렬 연산 유닛)
-
기본 개념: CUDA 코어는 GPU의 가장 기본적인 연산 유닛으로, 일반적인 산술 연산(덧셈, 곱셈 등)을 병렬로 처리합니다.
-
작동 방식: 모든 CUDA 코어는 하나의 명령어를 받아 각 데이터를 독립적으로 계산합니다.
- 예를 들어, 3D 그래픽에서 물체의 각 점(vertex)을 이동시키기 위해 ((x+dx, y+dy, z+dz)$ 연산을 병렬로 수행합니다.
-
특징: 범용적으로 동작하며, 게임 그래픽 렌더링, 데이터 병렬 처리 등 다양한 작업에 사용됩니다.
-
-
쉽게 이해하기: 다수의 일꾼이 각자 독립적으로 일하는 공장.
-
병렬 처리와 SIMD(Single Instruction Multiple Data)
- GPU는 SIMD 아키텍처를 통해 동작합니다. 하나의 명령어를 여러 데이터에 동시에 적용하는 방식으로 작동합니다.
- 예를 들어, 3D 그래픽에서 물체의 모든 점(vertex)을 특정 위치로 이동시키는 연산에서 GPU는 모든 점에 대해 동일한 계산을 병렬로 수행합니다.
-
병렬 처리 예시
- 3D 모델의 각 점의 좌표(x, y, z)를 이동시키기 위해 를 계산하는 것을 예로 들 수 있습니다.
- 수천 개의 점을 동시에 처리할 수 있어 CPU보다 훨씬 빠르게 결과를 생성할 수 있습니다.
-
GPU의 코어 배치
- CUDA 코어는
SM, Streaming Multiprocessor라는 그룹으로 묶입니다. SM은 여러 코어를 포함하며, 각 SM 내에서 스레드(threads)가 병렬로 실행됩니다.
- CUDA 코어는

출처: How do Graphics Cards Work? Exploring GPU Architecture(링크)
NVIDIA의 GA102 GPU 아키텍처는 RTX 3080, 3090, 3080 Ti, 3090 Ti에 사용되며, 동일한 설계를 기반으로 제작되었습니다.
- 그러나 이들이 다른 성능을 제공하는 이유는 제조 공정과 칩의 결함 처리 방식에 있습니다.😮😮
-
-
모든 카드가 동일한 GA102 아키텍처를 사용하지만, 제조 과정에서 발생하는 미세한 결함(패터닝 오류, 먼지 입자 등)을 처리하기 위해 설계된 코어 중 일부를 비활성화합니다.
- 예를 들어, 결함이 있는 스트리밍 멀티프로세서(SM)를 비활성화하고 나머지 정상적으로 작동하는 코어만 활성화합니다.

출처: How do Graphics Cards Work? Exploring GPU Architecture(링크)
-
GPU 칩은 테스트를 통해 코어 수와 성능에 따라 분류(binning)됩니다.
-
RTX 3090 Ti는 완벽한 칩으로 모든 10,752개의 쿠다 코어를 활성화하며, RTX 3080은 8,704개의 쿠다 코어만 활성화된 결함 버전입니다.
-
아래는 이를 정리한 테이블입니다:
모델 활성화된 쿠다 코어 수 비활성화된 SM 수 비고 RTX 3090 Ti 10,752 0 완벽한 칩 RTX 3090 10,496 2 일부 결함 처리 RTX 3080 Ti 10,240 4 중간 성능 RTX 3080 8,704 16 더 많은 결함 처리
2. 텐서 코어와 AI 가속
텐서 코어(Tensor Core)는 딥러닝과 같은 고성능 계산 작업에 특화된 GPU의 연산 장치입니다.
- 텐서 코어는 행렬 연산(Matrix Math)을 빠르게 처리하여 신경망의 학습 속도를 크게 높입니다.
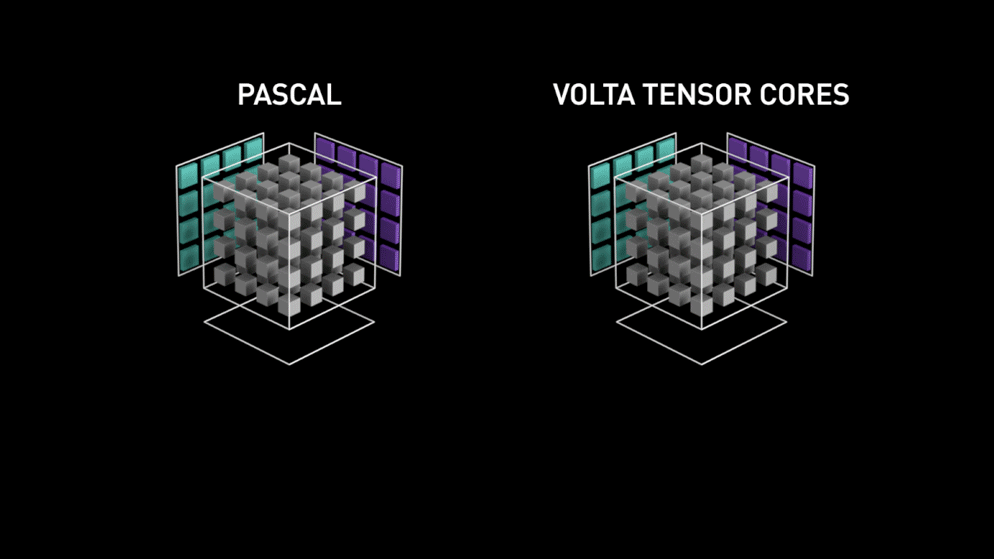
출처: Nvidia 공식 사이트 (Nvidia.com)
- (왼쪽) 행렬 내의 각 요소를 개별적으로 계산하는 파스칼 아키텍처, (오른쪽) 전체 작업을 한 번에 끝내는 볼타 텐서 아키텍처
-
Tensor 코어란? (딥러닝 가속기)
-
기본 개념: Tensor 코어는 GPU에서 딥러닝 연산을 가속하기 위해 설계된 유닛으로, 대규모 행렬 연산(Matrix Multiplication)에 특화되어 있습니다.
-
작동 방식: 하나의 연산 주기에서 와 같은 복잡한 행렬 연산을 수행합니다.
- FP16(16-bit 부동소수점)을 사용하여 연산 효율을 극대화합니다.
-
특징:
- 한 번에 4x4 또는 8x8 행렬을 병렬로 계산하여, 딥러닝 모델의 학습 속도를 비약적으로 높입니다.
- 딥러닝에서 자주 쓰이는 CNN(Convolutional Neural Network) 또는 Transformer 모델에 최적화.
-
-
쉽게 이해하기: AI 학습을 위한 전문 작업반. 행렬 연산이라는 큰 작업을 맡아 GPU 전체의 효율을 극대화합니다.

출처: How do Graphics Cards Work? Exploring GPU Architecture(링크)
-
GPU와 AI
- 딥러닝 모델은 수천 개의 행렬 곱셈과 같은 연산으로 구성됩니다.
- GPU의 텐서 코어는 이러한 연산을 병렬로 처리하여 AI 모델의 학습 속도를 CPU 대비 10 ~ 100배 이상 높일 수 있습니다.
-
활용 사례
- 자연어 처리 모델(예: ChatGPT)
- 이미지 생성 모델(예: Stable Diffusion)
- 음성 인식 및 생성 모델

출처: Nvidia 공식 사이트 (Nvidia.com)
3. 레이 트레이싱 코어
레이 트레이싱 코어는 빛의 반사, 굴절, 그림자 생성 등을 물리적으로 정확하게 계산하여 3D 환경에서 매우 사실적인 이미지를 생성합니다.
-
레이 트레이싱이란?
- 레이 트레이싱은 광선이 물체와 상호작용하는 방식을 시뮬레이션하여 현실감 있는 그래픽을 생성하는 기술입니다.
- 예를 들어, 빛이 유리잔을 통과하면서 굴절되고 주변 물체에 반사되는 효과를 GPU가 실시간으로 계산합니다.
-
Ray Tracing 코어란? (사실적인 그래픽 생성기)
-
기본 개념: Ray Tracing 코어는 GPU에서 광선(ray)과 물체 간의 상호작용(반사, 굴절, 그림자 등)을 물리적으로 정확하게 계산하는 유닛입니다.
-
작동 방식: 빛의 경로를 시뮬레이션하여 광선이 물체에 부딪힐 때 반사되거나 굴절되는 효과를 실시간으로 계산합니다.
- 각 광선과 물체의 교차점을 찾아내고, 이를 기반으로 화면에 표시되는 이미지를 생성합니다.
-
특징:
- 사실적이고 생동감 있는 그래픽을 실시간으로 렌더링 가능.
- Cyberpunk 2077 같은 고품질 게임이나 영화 제작에서 주로 사용.
-
-
쉽게 이해하기: 3D 그래픽의 빛 전문 디자이너. 화면에 빛이 반사되는 모습을 자연스럽게 만들어 줍니다.

출처: How do Graphics Cards Work? Exploring GPU Architecture(링크)
- 응용 분야
- 실시간 그래픽(게임: Cyberpunk 2077, Minecraft RTX)
- 3D 렌더링 및 애니메이션
- 영화 및 광고 제작
요약
아래는 CUDA 코어, Tensor 코어, 그리고 Ray Tracing 코어의 차이를 한 표에 정리하고, 각각의 개념을 한줄로 정리한 내용입니다..
| 특징 | CUDA 코어(CUDA Core) | Tensor 코어(Tensor Core) | Ray Tracing 코어(Ray Tracing Core) |
|---|---|---|---|
| 역할 | 범용 병렬 연산 처리 | 행렬 연산 및 딥러닝 가속화 | 실시간 빛 추적 계산으로 사실적 그래픽 생성 |
| 연산 유형 | 스칼라 연산 (단일 값의 덧셈, 곱셈 등) | 행렬 연산 (다중 값의 곱셈 및 덧셈) | 광선-물체 교차 및 빛의 반사, 굴절 계산 |
| 작동 방식 | 한 번에 한 개의 숫자 연산 처리 | 한 번에 4x4 또는 8x8 행렬 계산 | 복잡한 광학 연산을 병렬로 처리 |
| 연산 성능 | 범용적으로 동작, 대규모 연산에서 효율적 | 딥러닝 학습에서 초고속 성능 제공 | 사실적인 빛의 반사 및 그림자 표현 가능 |
| 활용 분야 | 그래픽 렌더링, 기본 병렬 연산 | 딥러닝 학습 및 추론, AI 모델 | 실시간 그래픽, 3D 애니메이션, 영화 제작 |
| 데이터 정밀도 | FP32(32-bit 부동소수점), INT32 | FP16(16-bit 부동소수점), INT8 | 광학 모델 기반 연산 |
| 효율성 | 단순 연산에서 강력 | 대규모 병렬 연산에서 극도로 효율적 | 그래픽 사실성 극대화, 병렬 처리 효율적 |
- CUDA 코어: 게임이나 애플리케이션에서 반복적인 연산을 수행하며, 그래픽과 데이터 처리를 담당.
- Tensor 코어: AI와 딥러닝 작업에서 대규모 데이터 학습과 추론을 가속.
- Ray Tracing 코어: 사실적인 조명과 그림자를 생성하여 몰입감을 더함.
GPU의 병렬 연산: 딥러닝에서의 활용
GPU는 벡터 및 행렬 연산을 병렬로 처리하며, 이는 딥러닝 모델의 학습과 추론에 이상적입니다.
- 벡터 연산의 병렬화
딥러닝의 많은 계산은 벡터(숫자의 일렬 배열)로 수행됩니다. GPU는 벡터의 각 요소를 개별 코어에 할당하여 병렬 연산을 수행합니다.
- 예시:
, 일 때, .
이 계산에서 GPU는 각 코어가 A와 B의 한 요소를 동시에 처리합니다.
- 행렬 곱셈의 병렬화
딥러닝 모델의 핵심 연산인 행렬 곱셈도 GPU의 병렬 처리 덕분에 효율적으로 수행됩니다.
-
예시:
두 행렬 와 를 곱하여 행렬 를 계산한다고 가정합시다. GPU는 행렬 의 각 요소를 병렬로 계산합니다.
행렬 곱셈 공식:
각 값은 독립적으로 계산 가능하므로, GPU의 코어가 각 계산을 병렬로 수행합니다. -
딥러닝에서의 응용
- 뉴런 간의 가중치 계산
- 데이터의 전방 전파(Forward Propagation)
- 역전파(Back Propagation) 및 그래디언트 계산
GPU 아키텍처의 유연성: SIMD에서 SIMT로
전통적인 GPU는 SIMD(Single Instruction Multiple Data) 구조를 사용했으나, 최신 GPU는 더 유연한 SIMT(Single Instruction Multiple Threads) 구조로 발전했습니다.
-
SIMD vs SIMT
- SIMD(Single Instruction Multiple Data): 하나의 명령어를 여러 데이터에 동시에 적용.
- 모든 스레드가 동일한 속도로 진행해야 함.
- SIMT(Single Instruction Multiple Threads): 스레드 간 동기화 없이 독립적으로 명령어를 실행할 수 있음.
- 조건문 등으로 인한 분기(branch)를 처리하기에 적합.
- SIMD(Single Instruction Multiple Data): 하나의 명령어를 여러 데이터에 동시에 적용.
-
SIMT의 장점
- 코드 유연성 증가: 조건문 처리가 가능.
- 계산 효율성 향상: 병렬 연산 성능 극대화.
결론
GPU는 병렬 연산에 특화된 구조와 수많은 코어를 통해 CPU보다 대규모 연산에서 훨씬 뛰어난 성능을 발휘합니다. 딥러닝, 그래픽 렌더링, 암호화폐 채굴 등 다양한 응용 분야에서 GPU는 없어서는 안 될 존재입니다.
GPU의 내부 구조와 작동 방식을 이해하면 딥러닝 모델을 최적화하거나 하드웨어를 선택하는 데 큰 도움을 받을 수 있습니다.

이상으로 오늘 포스팅 마치도록 하겠습니다 ^~^
긴 글 읽어주셔서 감사합니다!
