
최근 챗GPT로 인해 부상한 제로샷(zero-shot), 원샷(one-shot), 퓨샷(few-shot) 러닝 기법은 데이터를 일일이 라벨링하지 않고도 머신러닝 모델을 학습시킬 수 있도록 해줍니다. 해당 포스트는 CV(Computer Vision) 및 NLP(Natural Language Processing)의 관점에서 N-shot learning을 정의하는 것을 목적으로 합니다.
해당 글은 개인적으로 다양한 소스의 글과 영상을 통해 공부하고 작성한 내용입니다. 틀린 내용이 있다면 편하게 댓글로 말씀해주세요 🤗
제로샷·원샷·퓨샷이란?
- Zero-shot learning (ZSL)은 모델이 학습 과정에서
본 적 없는새로운 클래스를 인식할 수 있도록 하는 학습 방법입니다. 이는 모델이 클래스 간의 관계나 속성을 통해 일반화하는 능력을 활용합니다.
➡️ EX) 새로운 클래스에 대한 설명 정보를 입력으로 제공해야 합니다. 이미지 인식에서는 이미지의 특징을 설명하는 텍스트 정보를 사용하여 이전에 본 적이 없던 이미지더라도 해석이 가능하게 됩니다. - One-shot learning (OSL)은 각 클래스에 대해
단 하나의 예시만 제공될 때 모델이 그 클래스를 인식할 수 있도록 하는 학습 방법입니다. 이는 유사도 학습이나 메타 학습 등의 기법을 활용하여 구현됩니다.
➡️ EX) 고양이를 인식하는 딥러닝 모델에게 "스핑크스"라는 새로운 종류의 고양이를 인식하도록 요청한다면, 모델은 이전에 본 적이 없는 스핑크스 고양이 사진 하나만으로도 인식을 수행할 수 있어야 합니다. 이것은 학습 데이터가 매우 제한적인 경우에 유용합니다. - Few-shot learning (FSL)은 ,
극소량의 데이터만을 이용하여 새로운 작업이나 클래스를 빠르게 학습하도록 설계된 알고리즘을 말합니다. 이 방법은 메타 러닝(meta-learning)이나 학습 전략의 최적화 등을 통해 적은 데이터로도 효과적인 일반화(generalization) 능력을 갖추도록 합니다.
➡️ EX) 연구자들이 아주 드문 종류의 식물 사진 몇 장을 확보했다고 할 때, 전통적인 지도학습 모델은 이 식물을 학습하기에 충분한 데이터가 없다는 문제에 직면합니다. 하지만 Few-shot learning을 사용하면, 소수의 이미지만으로도 모델은 새로운 식물 종을 인식하고 분류하는 방법을 학습할 수 있습니다. 이러한 상황에서는 다양한 사전 훈련된 모델과 조합하여 적은 데이터로도 높은 정확도를 달성할 수 있는 전략이 중요하게 작용합니다.
💡 더 자세하게 설명드리기 전에 먼저 복습 차원에서 사전학습과 파인튜닝에 대해서 살펴볼까요?
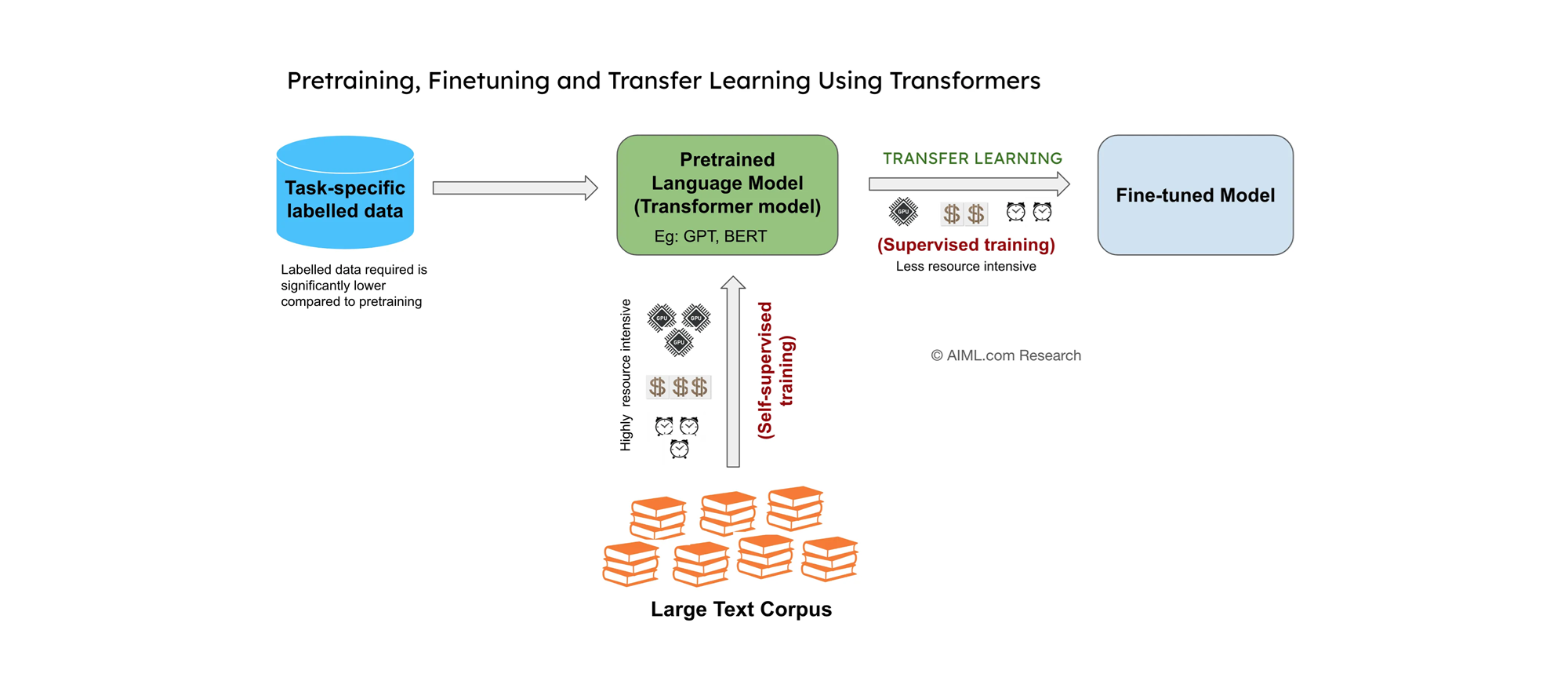
Source: AIML.com Research
-
사전학습 단계에서는 모델이 대규모 데이터셋을 사용하여 광범위한 지식을 학습합니다. 이 과정은 모델에게 일반적인 패턴, 구조, 언어적 특성 등을 이해하게 하는 기반을 마련합니다. LLM 모델의 경우, 위 그림처럼 Large Text Corpus(대용량 텍스트 데이터)를 기반으로 다양한 Task에 대하여 사전학습을 수행하게 됩니다.
-
파인튜닝 단계에서는 사전학습된 모델을 좀 더 특정 태스크나 적은 양의 데이터에 적합하도록 조정합니다. 예를 들어, 금융 도메인 특화 모델, 법률 도메인 특화 모델과 같은 특정 도메인에 초점을 둔 모델이라면 해당 데이터로 모델 파인튜닝을 수행해주면 성능이 향상됩니다.
-
인퍼런스 단계에서는 학습된 모델을 새로운 데이터에 적용하여 예측을 수행합니다.
좀 더 자세한 그림으로 한번 다시 정리해보도록 하겠습니다. 다양한 도메인과 TASK에 대하여 사전학습을 수행하고 난 뒤에, 특정 도메인/Task에 대해서 파인튜닝을 통해 모델 성능을 향상시킬 수 있습니다.
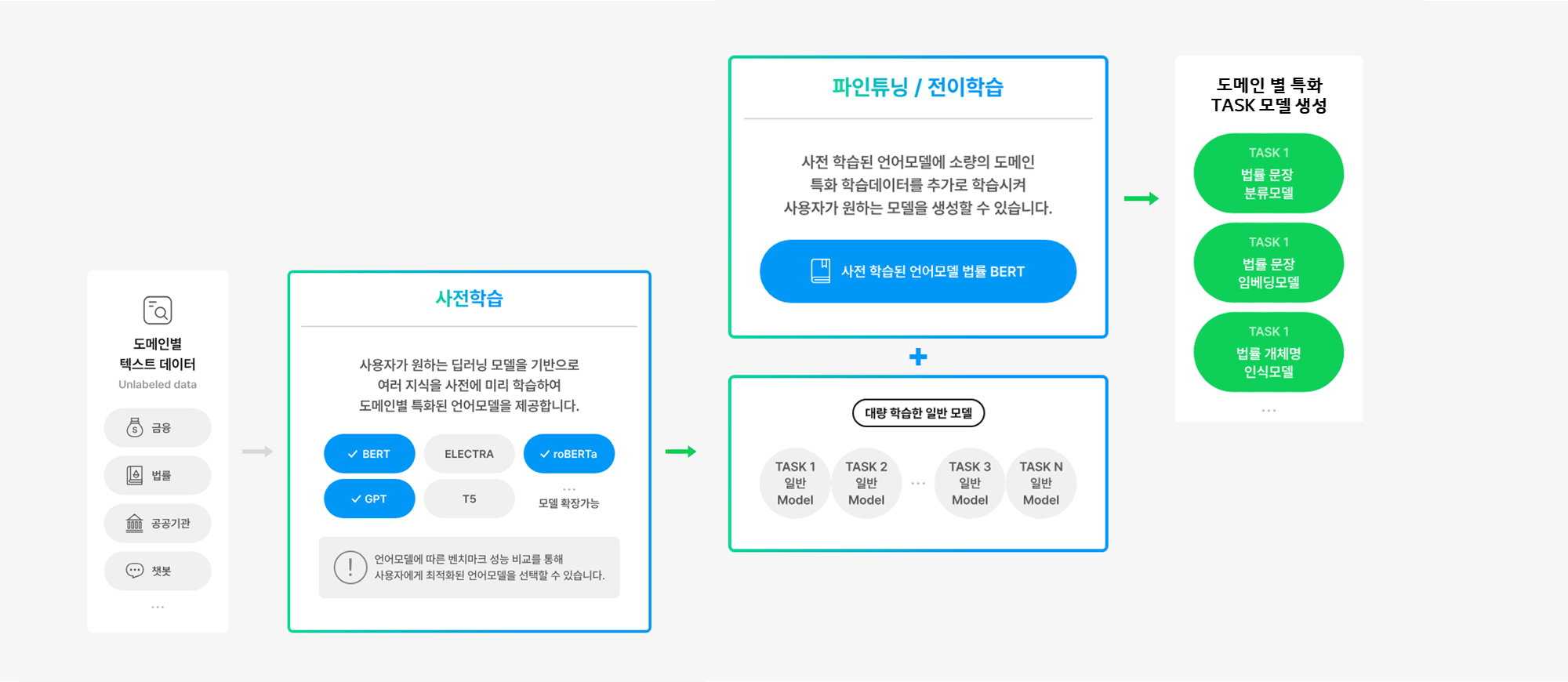
Source: https://www.saltlux.com/
💡 그럼 언제 Few-shot이 쓰이는 거지?🤔
ZSL(Zero-shot Learning), OSL(One-shot Learning), FSL(Few-shot Learning)은 딥러닝 모델의 일반적인 학습 및 적용 단계인 사전학습(pretraining) -> 파인튜닝(finetuning) -> 인퍼런스(inference) 과정에서 주로 파인튜닝 단계와 인퍼런스 단계에서 중요한 역할을 합니다. 이들 방법의 적용과 목적을 각 단계별로 살펴보겠습니다.
사전학습 (Pretraining)
- ZSL, OSL, FSL 자체는 이 단계에서 직접적으로 수행되지 않지만, 사전학습된 모델은 이후의 ZSL, OSL, FSL 적용을 위한 기반을 제공합니다. 특히, 사전학습이 잘 된 모델은 ZSL에서 더 좋은 성능을 보일 가능성이 높습니다.
- 이는 사전학습 과정에서 모델이 다양한 데이터와 상황을 경험하며, 그 과정에서 일반화 능력을 개발하기 때문입니다. 그 결과, 모델은 학습 과정에서 직접적으로 보지 못한 새로운 클래스에 대해서도 유의미한 추론을 할 수 있는 능력을 갖추게 됩니다.
파인튜닝 (Finetuning)
- ZSL은 특별한 경우로, 사전에 본 적 없는 클래스에 대한 인식을 목표로 하기 때문에, 전통적인 파인튜닝보다는 인퍼런스 단계에서 모델이 어떻게 새로운 클래스를 처리할 수 있는지에 더 중점을 둡니다.
- OSL과 FSL은 이 단계에서 큰 역할을 합니다. 적은 양의 데이터로 모델을 조정하여 특정 태스크에 대한 모델의 성능을 최적화할 수 있습니다. 이는 특히 소수의 예시만을 사용하여 모델이 특정 클래스를 인식하도록 하는 데 중요합니다.
인퍼런스 (Inference)
- ZSL, OSL, FSL은 이 단계에서 핵심적인 역할을 합니다. 모델이 본 적 없는 데이터나 소수의 예시를 기반으로 분류, 인식, 예측 등의 태스크를 수행하는 능력이 이 단계에서 평가됩니다.
📖 요약하자면, ZSL은 주로 인퍼런스 단계에서 본 적 없는 클래스를 처리하는 모델의 능력을 나타내며, OSL과 FSL은 파인튜닝 단계에서 모델을 특정 태스크에 최적화하는 데 중요한 역할을 하고, 인퍼런스 단계에서도 그 성능이 평가됩니다. 이러한 방법들은 모델이 제한된 정보로부터 학습하고, 적응하며, 예측하는 능력을 극대화하는 데 도움을 줍니다.
Supervised vs Few-shot Learning
지금까지 ZSL, OSL, FSL의 개념과 어느 단계(step)에서 사용되는지 살펴봤는데요. 이쯤 되면 이런 궁금증이 생기실 것 같습니다.
🤔그렇다면 일반적인 Supervised Learning(지도학습)과 Few-shot Learning(퓨샷러닝)은 학습 면에서 어떤 차이가 있을까?
지도 학습(Supervised Learning)은 레이블이 지정된 대규모의 훈련 데이터를 사용하여 모델을 훈련시키는 기계 학습의 한 형태입니다. 이 과정에서 모델은 입력 데이터에서 출력 레이블을 예측하는 방법을 학습합니다. 훈련 데이터는 다양한 특징(feature)을 포함하고 있으며, 각 샘플은 특정 레이블과 연관되어 있습니다. 일단 모델이 충분한 데이터로 훈련되고 나면, 새로운, 전에 본 적 없는 데이터에 대한 예측을 할 수 있게 됩니다. (하지만, 이러한 예측은 훈련 중에 모델이 학습한 클래스 내에서 이루어집니다.)
반면에, Few-shot Learning은 지도 학습의 한 형태이지만, 매우 적은 수의 훈련 샘플로부터 학습(또는 검증)하는 데 중점을 둡니다. 이 방법론은 모델이 새롭고 알려지지 않은 클래스의 데이터에 대해 예측을 수행할 수 있게 하기 위해 설계되었습니다. Few-shot Learning 시나리오에서는 지원 세트(Support Set)가 제공되며, 이는 각 클래스의 몇 가지 예시만을 포함합니다. 그 후, 쿼리 샘플(Query Sample)이 주어지면 모델은 지원 세트를 기반으로 이 샘플이 어떤 클래스에 속하는지 예측해야 합니다. 여기서 중요한 점은 쿼리 샘플이 훈련 과정에서 본 적 없는 새로운 클래스에서 온 것일 수 있다는 것입니다.
이는 아래 그림으로 직관적으로 설명이 가능할 것 같습니다. 좌측의 그림(Supervised Learning)에서는 실제 학습 데이터셋에 있던 클래스인 Husky를 분류하고 있는 것을 볼 수 있습니다. 반면에 우측의 그림(Few-Shot Learning)에서는 실제 학습 데이터셋에는 Rabbit이 없고 이를 분류하고자 하는 것을 볼 수 있습니다.
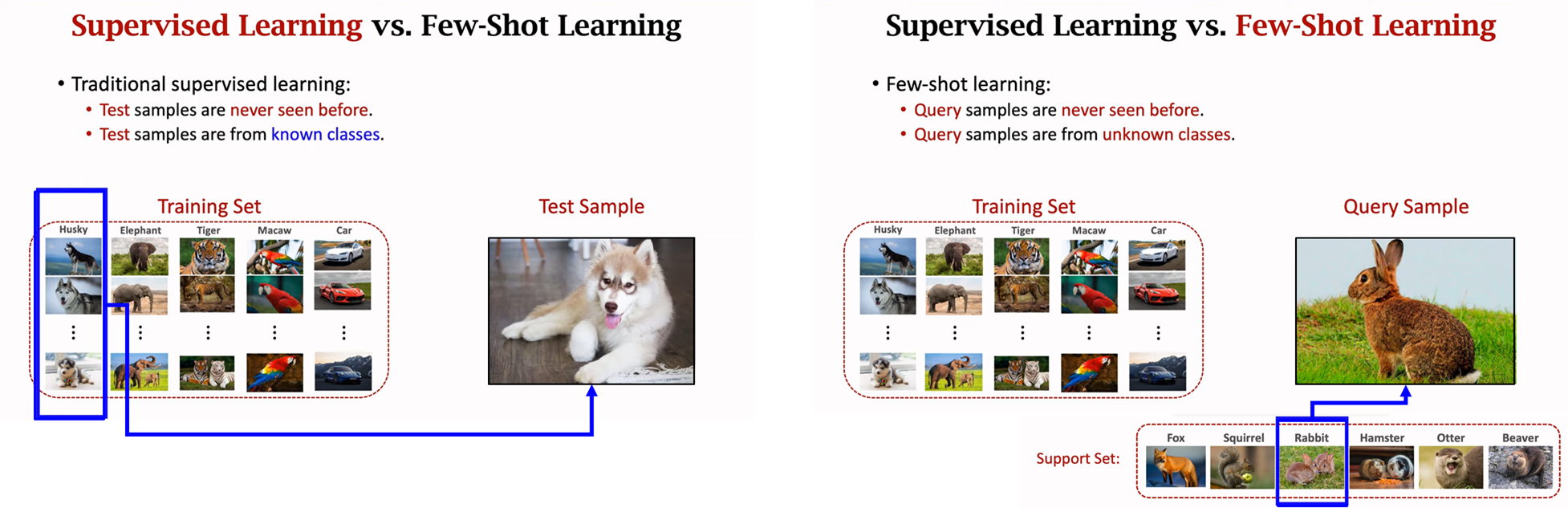
Source: Youtube Lecture Slide(Shusen Wang)
컴퓨터 비전(CV)에서의 퓨샷러닝
정의
컴퓨터 비전에서 ZSL, OSL, FSL은 이미지 분류, 객체 인식 등의 태스크에서 활용되며, 모델이 적은 예시나 본 적 없는 예시를 기반으로 객체를 인식하거나 분류할 수 있게 합니다.
예시
- ZSL: 모델이 사전에 정의된 속성을 통해 새로운 객체를 인식하는 경우, 예를 들어, '유모차'를 '바퀴가 네 개 있고 아기를 태울 수 있는' 속성을 통해 인식합니다.
- OSL: 특정 동물의 한 장의 사진을 학습하여, 다른 사진 속 같은 동물을 인식합니다.
- FSL: 새 종류를 몇 장의 사진만 보고 분류하는 경우입니다.
학습 방법 및 데이터셋 구성
데이터셋 구성 예시:
- Zero-Shot Learning: 데이터셋은 이미지와 그 이미지가 속한 클래스의 설명(예: 속성, 관계)을 포함합니다. 예를 들어, '유모차' 클래스에는 '바퀴가 4개', '아기를 태울 수 있는' 같은 속성이 레이블로 달릴 수 있습니다.
- One-Shot Learning: 각 클래스에서 하나의 이미지만 제공됩니다. 예를 들어, '고양이' 클래스에 대해 하나의 고양이 이미지를 학습 데이터로 사용합니다.
- Few-Shot Learning: 소수의 이미지(보통 2~5개)를 각 클래스별로 제공합니다. '강아지' 클래스에 대해 5개의 다양한 강아지 이미지가 학습 데이터셋에 포함됩니다.
학습 방법:
- ZSL에서는 모델이 이미지 속성과 클래스 간의 관계를 학습하여, 본 적 없는 클래스의 이미지를 인식할 수 있습니다.
- OSL과 FSL에서는 유사도 측정, 메타 학습, 데이터 증강 등을 활용해 제한된 예시로부터 클래스를 학습합니다.
검증 방법
검증은 학습 데이터셋에서 본 적 없는 새로운 이미지나 클래스를 얼마나 잘 분류하는지를 평가합니다. 검증 데이터셋은 다양한 소스에서 가져온 새로운 이미지로 구성됩니다.
자연어처리(NLP)에서의 퓨샷러닝
정의
NLP에서 이러한 학습 방식은 텍스트 분류, 기계 번역, 질의 응답 등에 적용됩니다. 모델은 사전 학습된 지식을 활용하거나 제한된 데이터로부터 특정 태스크를 수행합니다.
예시
- ZSL: 모델이 특정 주제에 대한 질문에 대답하는 경우, 예를 들어, 사전에 학습되지 않은 새로운 주제에 대한 질문입니다.
- OSL: 한 가지 스타일의 텍스트 예시를 보고 그 스타일로 글을 쓰는 경우입니다.
- FSL: 몇 가지 예시 문장을 통해 새로운 주제에 대해 글을 쓰는 경우입니다.
학습 방법 및 데이터셋 구성
데이터셋 구성 예시:
- Zero-Shot Learning: 학습 데이터셋은 다양한 주제의 텍스트를 포함하며, 모델은 이를 통해 일반화된 언어 이해를 학습합니다. 예를 들어, 주제에 대한 기사나 블로그 포스트가 사용될 수 있습니다.
- One-Shot Learning: 각 클래스에 대해 하나의 텍스트 예시만 제공됩니다. 예를 들어, '긍정적인 리뷰' 클래스에 대한 하나의 긍정 리뷰 예시가 제공됩니다.
- Few-Shot Learning: 각 클래스별로 소수의 텍스트 예시를 제공합니다. '부정적인 리뷰' 클래스에 대해 5개의 다양한 부정 리뷰가 학습 데이터로 사용됩니다.
학습 방법:
- ZSL에서는 모델이 텍스트의 주제나 감정 등을 이해하고, 본 적 없는 새로운 태스크에 이를 적용할 수 있어야 합니다.
- OSL과 FSL에서는 프롬프팅, 데이터 증강, 메타 학습을 통해 제한된 데이터로부터 태스크를 학습합니다.
검증 방법
검증은 모델이 학습 과정에서 본 적 없는 새로운 문제에 얼마나 잘 대응하는지를 평가합니다. 검증 데이터셋은 다양한 주제나 스타일의 텍스트로 구성됩니다.
CV vs LLM Few-shot Learning
공통점
두 분야 모두 ZSL, OSL, FSL을 사용하여 제한된 데이터로부터 모델의 일반화 및 적응 능력을 개선합니다. 또한, 사전 학습된 모델과 메타 학습 기법이 중요한 역할을 합니다.
💡 메타 학습 기법이란?
메타 학습(Meta-learning)기법은 "학습을 학습하는" 방식으로, 모델이 다양한 태스크에서 빠르게 학습하고 적응하는 방법을 배우는 학습 접근 방식입니다. 이 기법의 핵심 아이디어는 모델이 새로운 작업이나 소량의 데이터로부터 효율적으로 학습하는 법을 학습함으로써, 본 적 없는 태스크에 대해 빠르게 적응하고 예측을 수행할 수 있도록 하는 것입니다. 메타 학습은 특히 Zero-shot Learning (ZSL), One-shot Learning (OSL), 그리고 Few-shot Learning (FSL)과 같이 데이터가 제한적인 상황에서 모델의 성능을 개선하는 데 유용합니다.
차이점
CV와 NLP는 다루는 데이터의 형태(이미지 vs. 텍스트)와 관련 태스크에서 차이를 보입니다. NLP는 프롬프팅이 자주 사용되며, 이는 사전 학습된 언어 모델을 활용해 새로운 태스크에 적응하는 방법입니다. 반면, CV에서는 이미지의 속성이나 유사도를 기반으로 학습하는 경우가 많습니다.
예시) CV 유사도 기반 Training
📺 컴퓨터 비전(CV)에서 유사도 기반 학습은 주로 이미지 간의 시각적 유사성을 평가하는 데 사용됩니다. 예를 들어, Siamese 네트워크는 두 이미지가 같은 클래스에 속하는지 여부를 판별하기 위해 훈련됩니다. 이 과정에서, 네트워크는 두 이미지의 특징을 추출하고, 이 특징 벡터 간의 거리 또는 유사도를 계산합니다.
예시: 아래 그림에서, 모델은 사물 사진 두 장을 입력으로 받습니다. Siamese 네트워크는 두 사물에서 특징 벡터를 추출하고, 이 두 사물이 같은가의 여부를 판별하기 위해 특징 벡터 간의 유사도를 계산합니다. 학습 과정에서 네트워크는 다양한 사물 이미지 쌍을 사용하여, 유사도를 정확하게 측정하는 방법을 배웁니다.
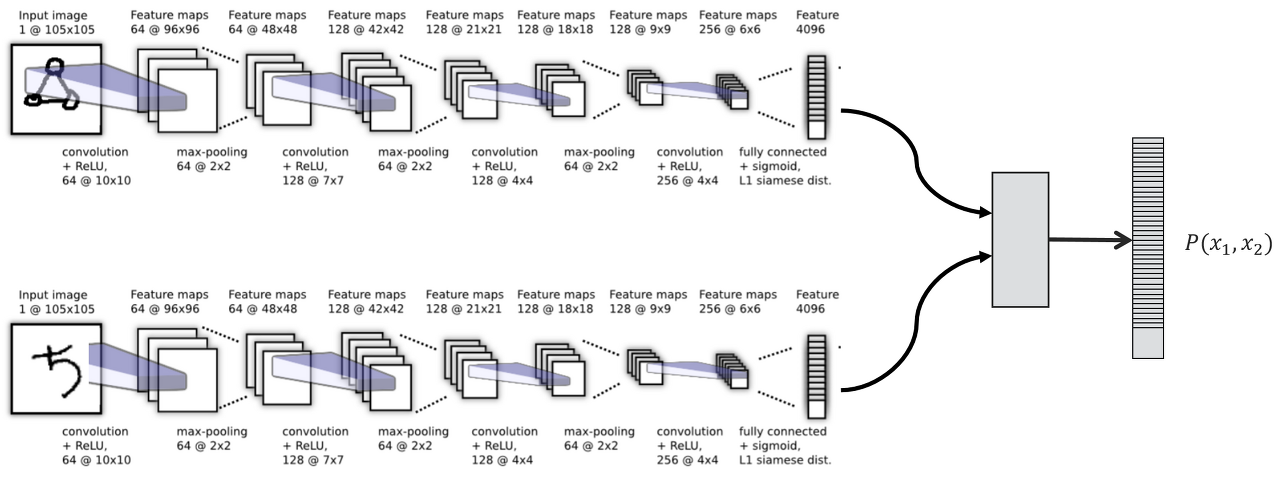
Source: Siamese Neural Networks for One-shot Image Recognition (논문)
예시) NLP 프롬프팅 기반 Inference
🗣️ 자연어 처리(NLP)에서 프롬프팅은 사전 학습된 언어 모델을 새로운 태스크에 적응시키는 강력한 방법으로 사용됩니다. 프롬프트는 모델에게 특정 작업을 수행하도록 지시하는 텍스트 조각입니다.
예시: GPT-3와 같은 대규모 언어 모델을 사용하는 질문-답변 시스템에서, 시스템은 "베를린은 어느 나라의 수도입니까?"와 같은 질문에 대한 답변을 생성하기 위해 프롬프트를 사용합니다. 프롬프트는 질문 형식으로 구성되며, 모델은 이를 바탕으로 관련 지식을 활용하여 "베를린은 독일의 수도입니다."와 같은 답변을 생성합니다.
이때 프롬프팅 방식으로 Zero-shot, One-shot, Few-shot 기법을 통해 모델이 직접적으로 학습하지 않은 태스크에 대해서도 유용한 답변을 생성할 수 있도록 합니다. 이는 기존의 Transfer Learning과 다른 방식입니다.

Source: Language Models are Few-Shot Learners (논문)
이것으로 제로샷(zero-shot), 원샷(one-shot), 퓨샷(few-shot)의 개념에 대해서 살펴보고, 각각 컴퓨터 비전(CV), 자연어 처리(NLP) 관점에서 비교해보는 시간을 가졌습니다.
여러분의 의견은 어떤가요? 컴퓨터 비전(CV)과 자연어 처리(NLP)에서의 Few-shot Learning이 동일하다고 느껴지시나요? 의견을 아래 댓글로 남겨주세요 🤔
