[정리] '24년 AI Summit : '라마' 개발 리더가 설명하는 LLM : Small Models 최신 기법 - Soumya Batra
'24년 AI SUMMIT-SEOUL

오전 미팅 일정을 마친 후, Day2 오후 세션에 참석하여 매우 유익한 시간을 보냈습니다. 모든 세션에 참가하지 못한 점은 아쉽지만, 참석한 세션들에서 얻은 내용과 인사이트를 중심으로 이번 시리즈를 구성해 보았습니다.
Track C: LLM & GenAI
- 제목 : '라마' 개발 리더가 설명하는 LLM : Small Models 최신 기법
- 발표자 : Soumya Batra | Meta Tech Lead, Applied Research Scientist

서론
최근 몇 년 동안 대규모 언어 모델(LLM)과 소규모 언어 모델(SLM)의 발전은 인공지능 분야에서 중요한 전환점을 맞이했습니다.
-
LLM(Large Language Models)은 방대한 데이터를 처리할 수 있는 능력을 통해 복잡한 문제를 해결하지만, 높은 계산 비용과 에너지 소비로 인해 한계가 있습니다. -
반면, SLM은 특정 도메인에 집중하여 적은 자원을 활용하면서도 효율적으로 성능을 낼 수 있는 방향으로 발전하고 있습니다.
🔋 LLM to SLM
이러한 변화는 기업과 학계 모두에 중요한 영향을 미치고 있으며, 효율성과 지속 가능성이라는 목표를 강조하고 있습니다.
-
SLM은 특히 환경적, 경제적, 그리고 실용성 측면에서 중요합니다.
- 기존의 대규모 모델은 많은 계산 자원을 요구하여 유지보수와 운영 비용이 높지만, SLM은 이를 극복하며 특정 도메인에 최적화된 효율성을 제공합니다.
- AI 모델의 발전은 단순히 크기를 키우는 것만이 아니라 지속 가능성과 맞춤화라는 측면에서의 혁신을 요구하고 있습니다.
이는 특히 데이터 프라이버시🛡️와 에너지 소비 절감♻️이라는 현대의 주요 요구 사항을 충족시키는 데 있어 중요한 발전입니다.
LLM과 SLM의 정의

이미지 출처 : https://www.digit.in/features/general/slm-vs-llm-why-smaller-gen-ai-models-maybe-better.html
LLM(대규모 언어 모델)은 수십억에서 수천억 개의 매개변수를 가진 모델로, 대량의 데이터를 학습하여 다양한 작업을 수행할 수 있는 범용성을 제공합니다.
- 대표적인 예로
PaLM,Gemini,ChatGPT(GPT-3, GPT-4, GPT-4o)와 같은 모델들이 있습니다. - 이러한 모델은 일반적으로 많은 계산 자원과 강력한 하드웨어를 필요로 하며, 다양한 언어 처리 작업을 지원할 수 있습니다.
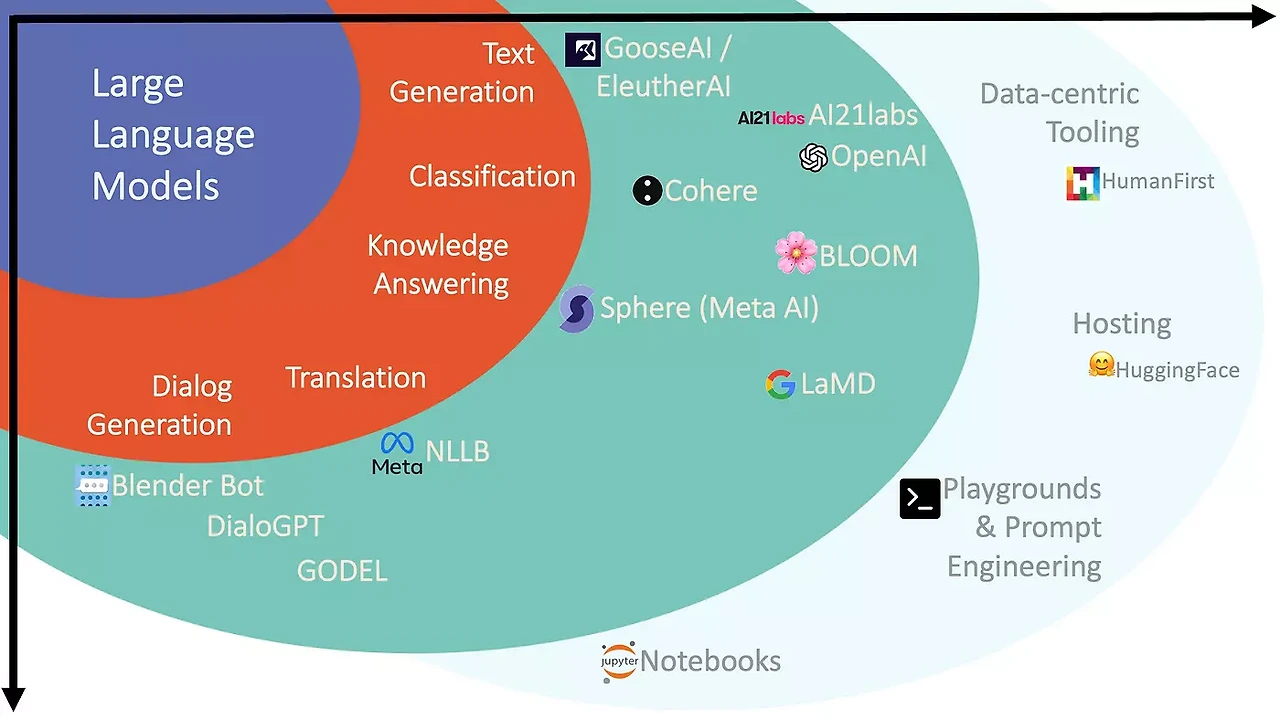
이미지 출처 : https://jaynamm.tistory.com/entry/LLMLarge-Language-Model-이해하기
반면, SLM(소규모 언어 모델)은 (명확한 정의는 없으나) 상대적으로 적은 매개변수를 가진 모델로, 특정 작업에 최적화되어 있으며 효율성과 실행 가능성을 중시합니다.

발표자가 다양한 GPT에게 SLM의 정의를 물어본 장표 ( slide from the talk )
- 이러한 모델은 비교적 적은 자원으로도 높은 성능을 발휘하며, 개인 디바이스나 엣지 컴퓨팅 환경에서 실행될 수 있도록 설계됩니다.
- SLM은 대규모 클라우드 서버에 의존하지 않고도 독립적으로 운영 가능(on-premise)하며, 특히 데이터 프라이버시를 중시하는 환경에서 유용합니다.
SLM의 중요한 특징 중 하나는 도메인 특화입니다.

발표자 SLM의 정의 장표 ( slide from the talk )
SLM은 특정 사용 의도(usage intent)에 따라 정의되는 언어 모델입니다. 여기서 사용 의도는 주로 모델이 어떤 작업을 수행할지, 어떤 도메인에 특화되어 있는지에 따라 달라집니다.
SLM의 주요 특징
-
컴팩트함 (Compact)
- 사용자 디바이스(최대 몇 개의 GPU)에 적합한 크기.
- 대규모 서버 환경 없이도 동작 가능.
-
자원 효율성 (Resource Efficient)
- 메모리와 계산량이 적게 소모됨.
- 하드웨어 요구 사항이 낮아 더 폭넓은 환경에서 활용 가능.
-
LLM과 유사한 성능 (Almost as performant as equivalent LLMs)
- 특정 작업에 대해 대규모 언어 모델(LLM)과 유사한 성능 제공.
-
특정 작업 특화 (On Specific Tasks)
- 의료, 법률과 같은 특정 도메인에 최적화.
- 일반적인 작업보다는 도메인 특화 작업에 탁월.
활용 예시
- 의료 기록 분석: SLM은 의료 데이터를 이해하고 요약하는 데 사용될 수 있습니다.
- 법률 문서 처리: 계약서 또는 법률 문서를 자동으로 처리하고 주요 정보를 추출.
- 산업별 애플리케이션: 특정 기업 내 고객 지원 데이터 분석 또는 운영 데이터 요약.
SLM은 특정한 도메인과 작업에 초점을 맞추어 설계되었기 때문에, 대규모 언어 모델에 비해 효율적이고, 빠르며, 자원 절약적이라는 점에서 다양한 산업에서 실용적으로 활용되고 있습니다.
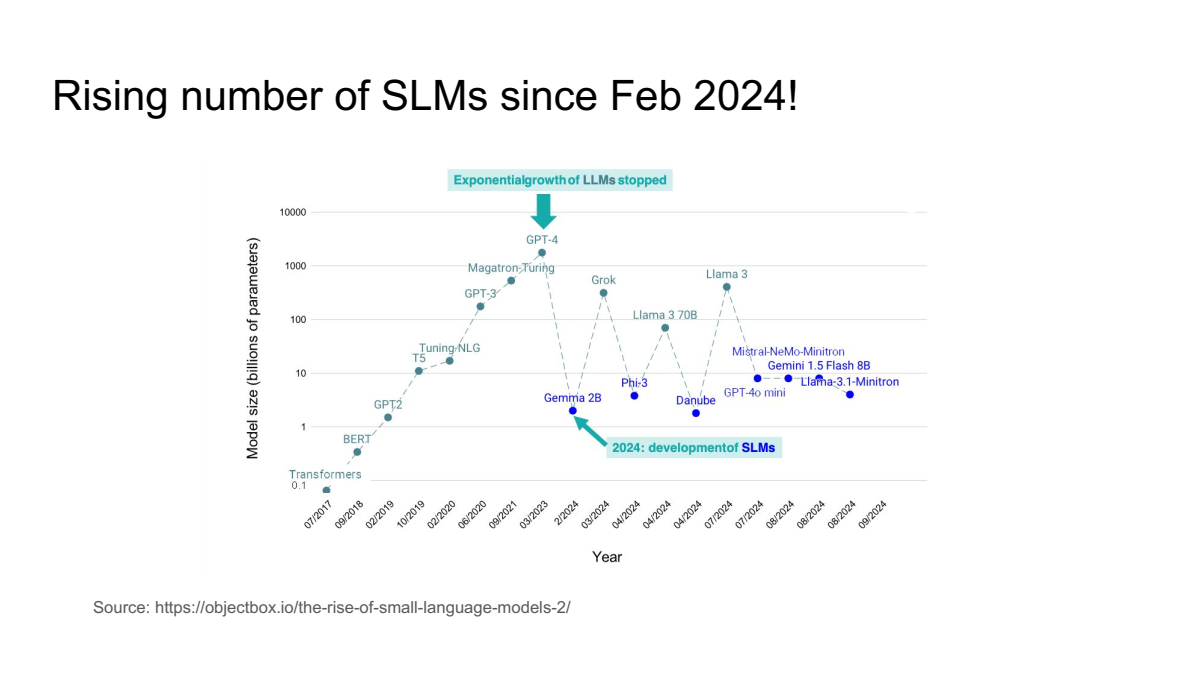
발표자 SLM 모델 증가 장표 ( slide from the talk )
SLM(Small Language Model)의 개발이 2024년 2월 이후 급격히 증가하고 있습니다. 이는 대규모 언어 모델(LLM) 개발이 정체를 보이기 시작하면서, 보다 효율적이고 특정 작업에 최적화된 SLM이 주목받게 된 결과입니다.
SLM은 파라미터 수가 적으면서도 특정 도메인이나 작업에서 높은 성능을 발휘할 수 있도록 설계됩니다. 예를 들어, Gemini 2B, Danube, GPT-4o Mini, Llama-3.1-Minitron과 같은 새로운 SLM은 제한된 자원을 활용하여 높은 성능을 보여주며, 이러한 모델들이 다양한 산업에서 도입되고 있습니다.
SLM의 증가는 대규모 데이터와 고성능 하드웨어가 필요했던 기존 LLM의 한계를 보완하며, 특정 목적을 위한 맞춤형 AI 솔루션 개발에 새로운 가능성을 열고 있습니다. 2024년 이후, SLM의 활용은 더욱 확산될 것으로 예상됩니다.
(정리) LLM과 SLM의 차이 테이블
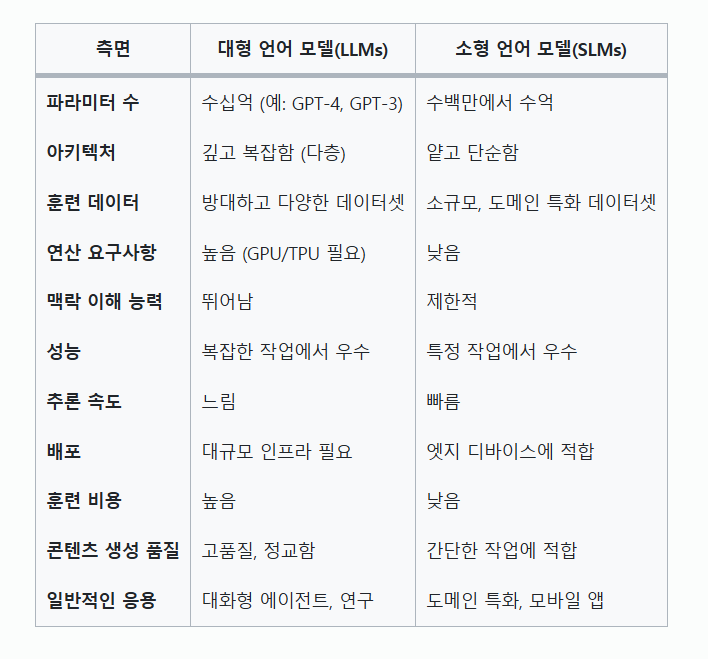
SLM이 주목받는 이유
-
SLM의 수요가 증가하는 주요 이유

-
프라이버시 (Privacy)
- SLM은 로컬 환경에서 실행될 수 있어, 데이터를 외부 서버로 전송할 필요가 없습니다.
- 이는 민감한 데이터 처리나 보안이 중요한 분야에서 매우 유리합니다.
-
비용 절감 (Cost)
- 대규모 모델에 비해 학습과 추론에 필요한 자원이 적기 때문에 비용 효율적입니다.
- 특히 중소규모 기업이나 자원이 제한된 환경에서도 활용 가능성이 높습니다.
-
효율성 (Efficiency)
- SLM은 경량화된 구조 덕분에 실행 속도가 빠르고 특정 작업에 최적화되기 쉽습니다.
- 데이터 센터에서의 에너지 소비를 줄일 수 있어 지속 가능성을 추구하는 산업에 적합합니다.
- 실시간 처리와 같은 고속 응용 분야에서 높은 성능을 발휘합니다.
-
맞춤화 (Customization)
- 특정 도메인에 특화된 데이터와 작업에 맞게 조정하기 용이합니다.
- 이는 의료, 법률, 고객 서비스 등 다양한 산업에서 SLM이 널리 활용되는 이유 중 하나입니다.
-
-
점점 커지는 SLM 시장
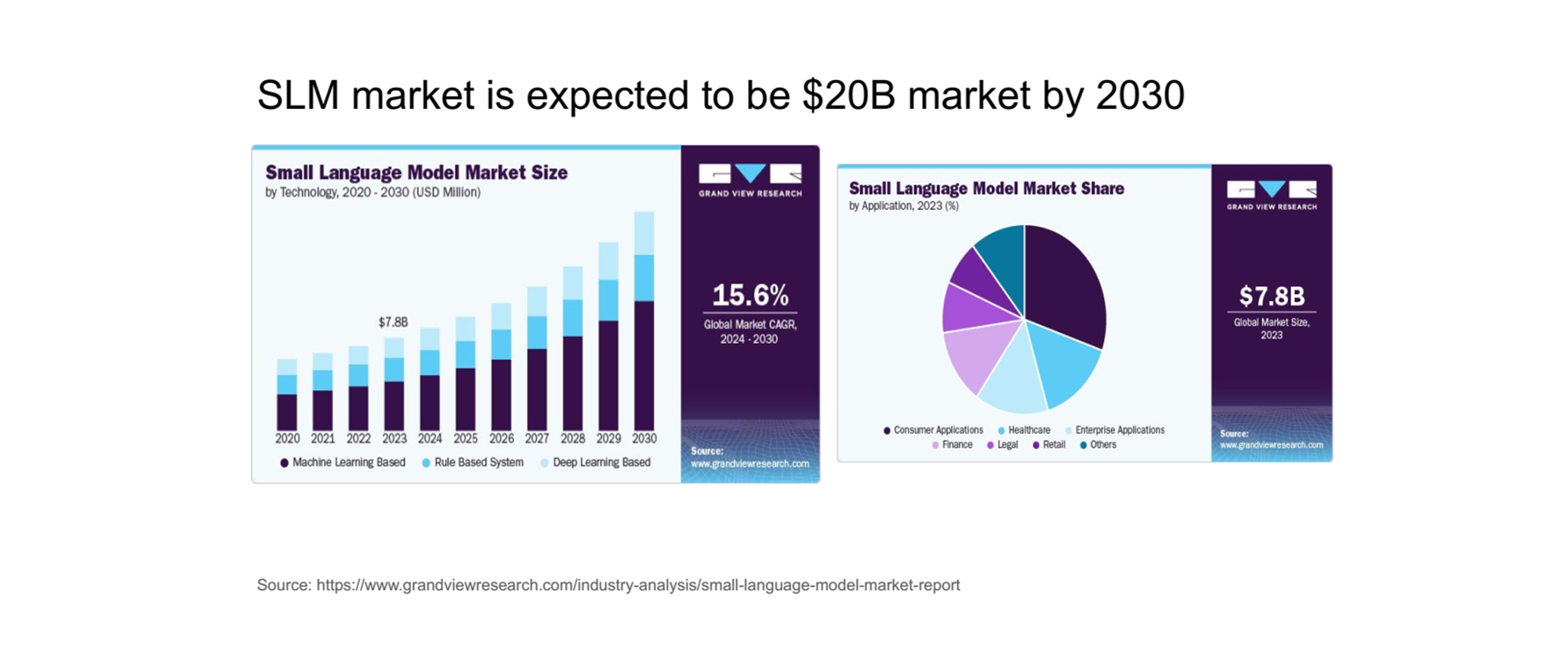
-
좌측 그래프
- SLM(Small Language Model) 시장은 빠르게 확장되고 있으며, 2030년까지 200억 달러(약 20조 원) 규모에 이를 것으로 예상됩니다.
- 현재 2023년 기준으로 시장 규모는 약 78억 달러(7.8B USD)에 달하며, 연평균 성장률(CAGR)은 15.6%로 예측되고 있습니다.
📟 (참고) 만약 해당 액수 계산이 구체적으로 궁금하다면 아래 연평균 성장률(CAGR) 공식을 통해 다음과 같이 계산할 수 있습니다:

-
우측 그래프
- 시장 점유율 분포를 보면, 소비자 애플리케이션(Consumer Applications), 헬스케어(Healthcare), 기업용 애플리케이션(Enterprise Applications) 등이 주요 사용 사례로 나타나고 있습니다.
- 특히 소매(Retail)와 법률(Legal) 분야에서도 도입이 활발합니다.
-
- 엣지 배포 가능성

- SLM은 엣지 디바이스나 온프레미스 환경에서 실행 가능하며, 네트워크 제약 환경에서 유리합니다.
- 이러한 특징은 데이터 프라이버시를 보장하면서 독립적으로 작동할 수 있습니다.
- SLM은 엣지 디바이스나 온프레미스 환경에서 실행 가능하며, 네트워크 제약 환경에서 유리합니다.
- 지속 가능성 (Sustainability)
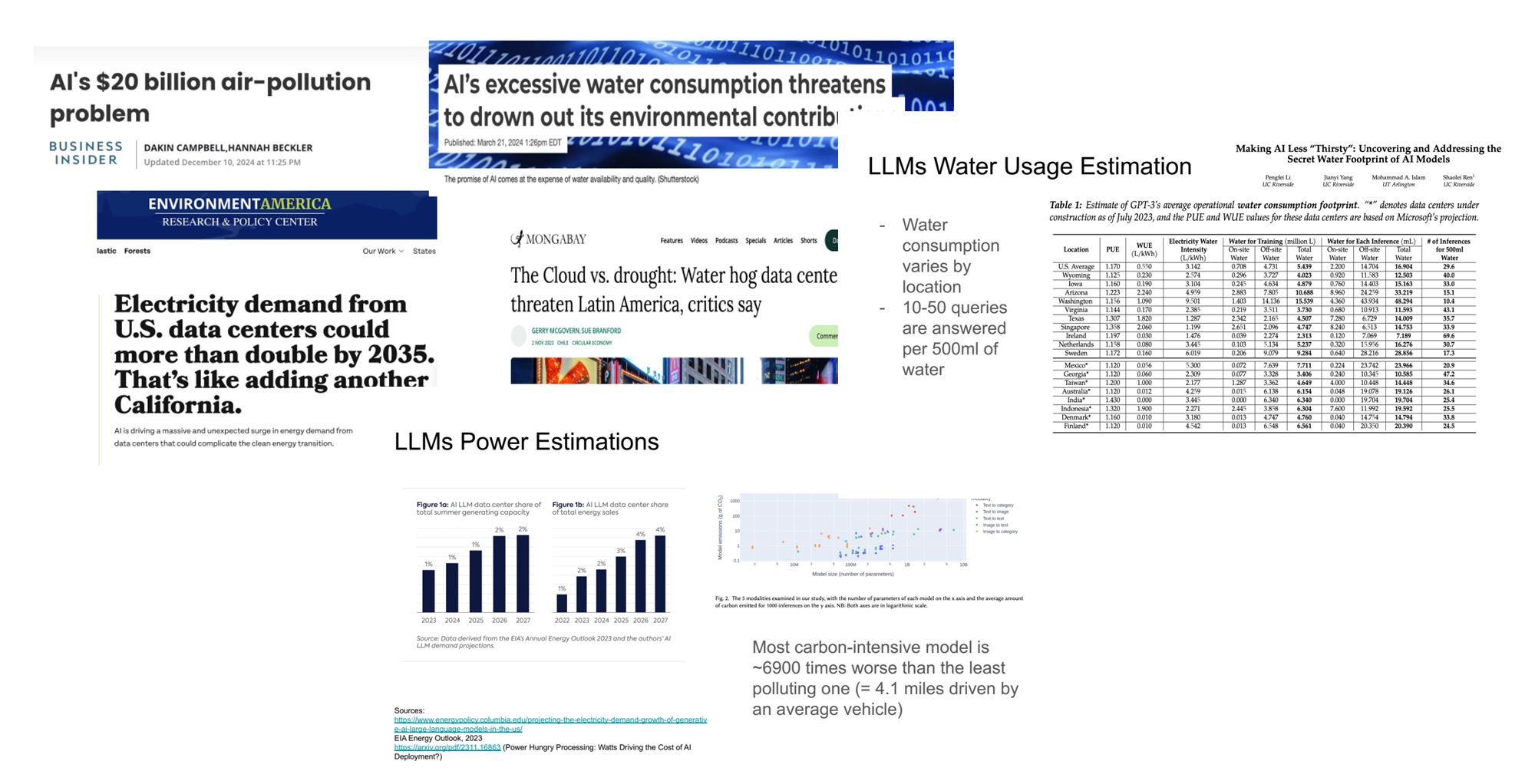
- LLM은 에너지 소비와 탄소 배출에서 약 7,000배 더 많은 자원을 필요로 합니다.
- 데이터 센터의 에너지 소비는 전체 소비량의 2%를 차지하며, 2년 내 두 배로 증가할 것으로 예상됩니다.
- SLM은 이러한 문제를 해결할 수 있는 현실적인 대안입니다.
- 에너지 소비 절감 외에도, SLM은 환경 영향을 최소화하는 방향으로 연구되고 있습니다.
- LLM은 에너지 소비와 탄소 배출에서 약 7,000배 더 많은 자원을 필요로 합니다.
SLM 만드는 방법
본 발표에서 SLM을 만드는 방법에 대해서 소개합니다. 2가지 접근법이 있다고 이야기하는데요.
- LLM을 압축시켜서 SLM을 만드는 LLM Compression Technique를 소개합니다. (LLM 압축 기법)
- 처음부터 SLM을 설계하고 구축하는 방법을 소개합니다. (모델의 처음부터 구축)

1. LLM 압축 기법
기존 모델의 효율성을 최적화하는 방법으로, 주로 다음과 같은 기술이 사용됩니다:
- 지식 증류(Knowledge Distillation): 지식 증류(Knowledge Distillation)는 대규모 교사(Teacher) 모델의 출력을 통해 학습 데이터의 패턴, 관계 및 일반화된 지식을 학생(Student) 모델에 전달하는 딥러닝 최적화 기법입니다.
- 이 과정에서 학생 모델은 교사 모델의 예측 확률 분포를 모방하여 학습하며, 이를 통해 더 작은 모델(학생 모델)이 교사 모델의 복잡한 지식과 성능을 효과적으로 계승합니다.
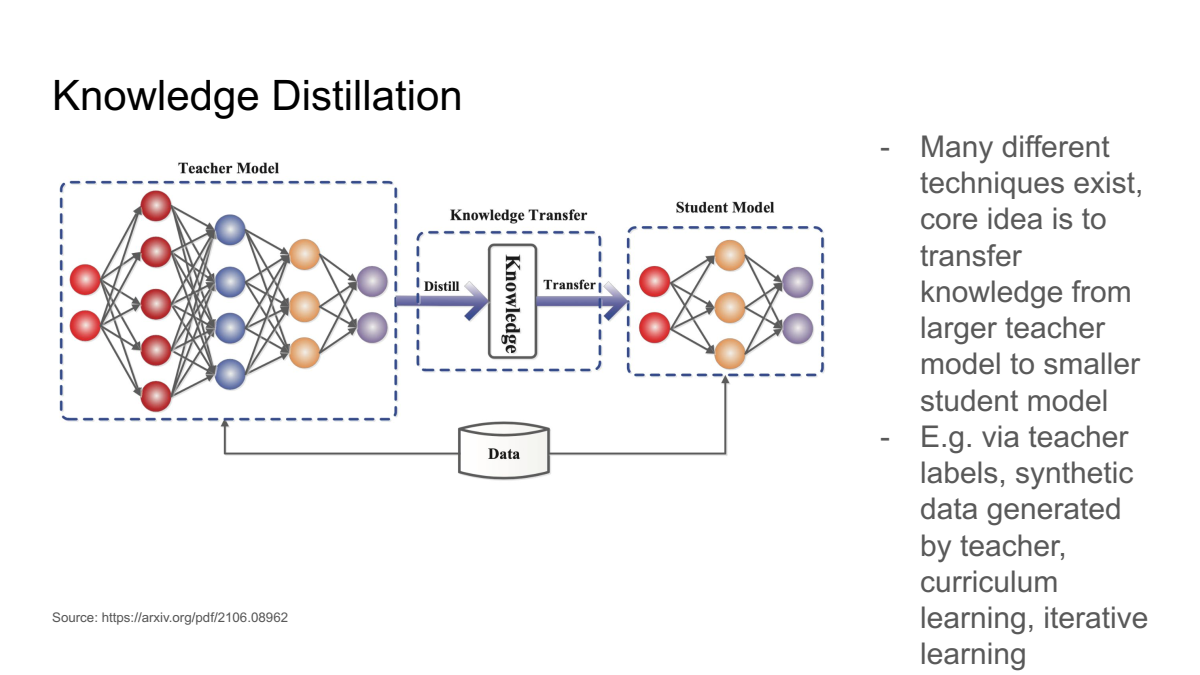
📁 지식 증류(Knowledge Distillation) 기반 연구 예시
- 논문: DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- 대규모 '교사' 모델의 지식을 더 작은 '학생' 모델에 전달하여 성능을 유지하면서도 모델의 크기를 줄이는 방법입니다.
- 예를 들어, DistilBERT는 지식 증류(Knowledge Distillation)를 사용하여 BERT 모델의 크기를 약 40% 줄이면서도 성능의 97%를 유지하는 데 성공했습니다.
이미지 출처 : https://zilliz.com/learn/distilbert-distilled-version-of-bert
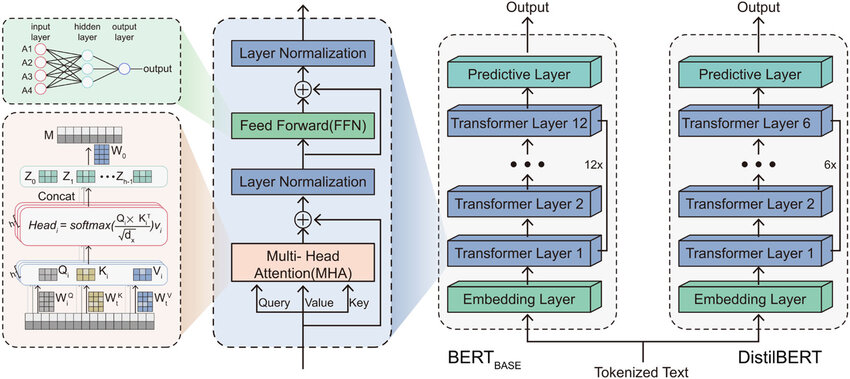
- 프루닝(Pruning): 프루닝(Pruning)은 모델의 파라미터 또는 뉴런 연결 중 중요도가 낮은 부분을 제거하여, 계산 효율성을 높이고 모델을 경량화하는 딥러닝 최적화 기법입니다.
- 중요도가 낮다고 간주되는 가중치(weight)나 뉴런을 제거함으로써 메모리 사용량과 계산 비용을 줄입니다.
- 모델의 구조를 변경하지 않고도 동일한 결과를 유지하거나, 최소한의 성능 손실만 발생하도록 설계합니다.
📁 프루닝(Pruning) 기반 연구 예시
- 논문: Structured Pruning of BERT-based Question Answering Models
- 모델의 중요하지 않은 파라미터나 뉴런 연결을 제거하여 모델의 크기를 줄이고 계산 효율성을 높이는 기법입니다.
- 예를 들어, 논문 "Structured Pruning of BERT-based Question Answering Models"에서는 BERT 기반 질문 응답 모델에 구조적 프루닝(Structured Pruning)을 적용하여 모델의 효율성을 향상시키는 방법을 제안하고 있습니다.
이미지 출처 : https://arxiv.org/pdf/1910.06360 (논문 원문)

- 양자화(Quantization): 모델의 파라미터를 낮은 비트 정밀도(예: 32-bit → 8-bit 또는 4-bit)로 변환하여 메모리 사용량을 줄이고 계산 비용을 절감하는 방법입니다.
- 이는 모델의 성능을 유지하면서도 하드웨어에서의 실행 효율성을 극대화합니다.
- 양자화는 특히 모바일 디바이스 및 엣지 컴퓨팅 환경에서의 딥러닝 모델 적용에 유용합니다.
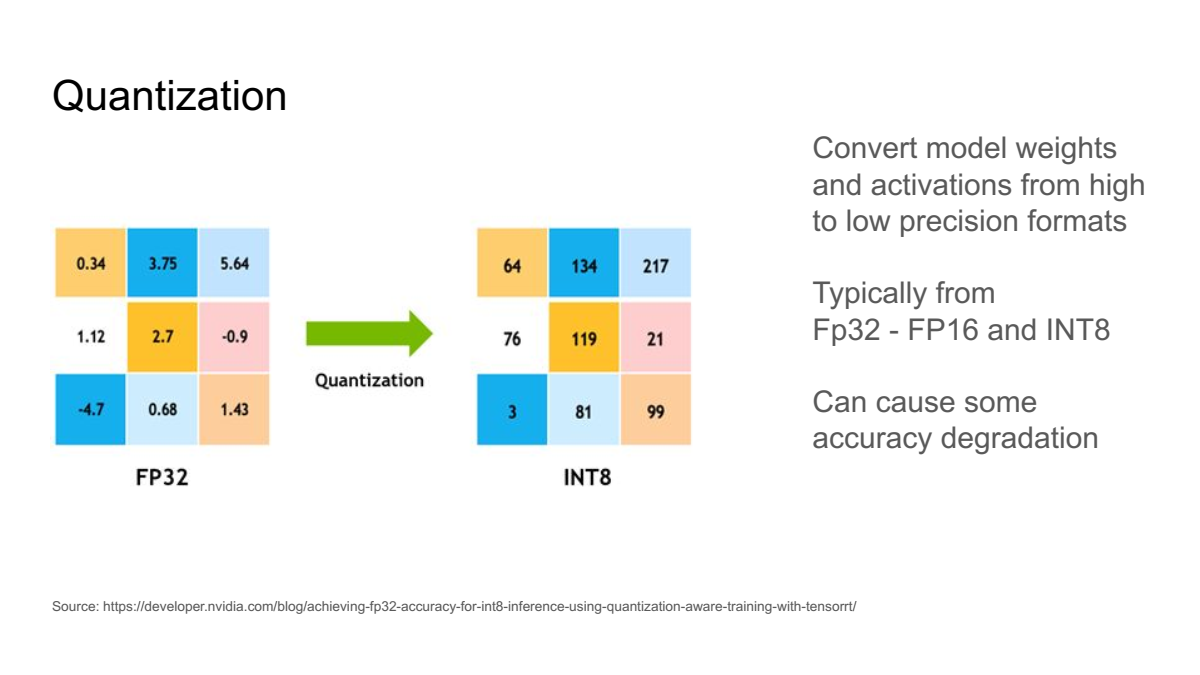
📁 양자화(Quantization) 기반 연구 예시
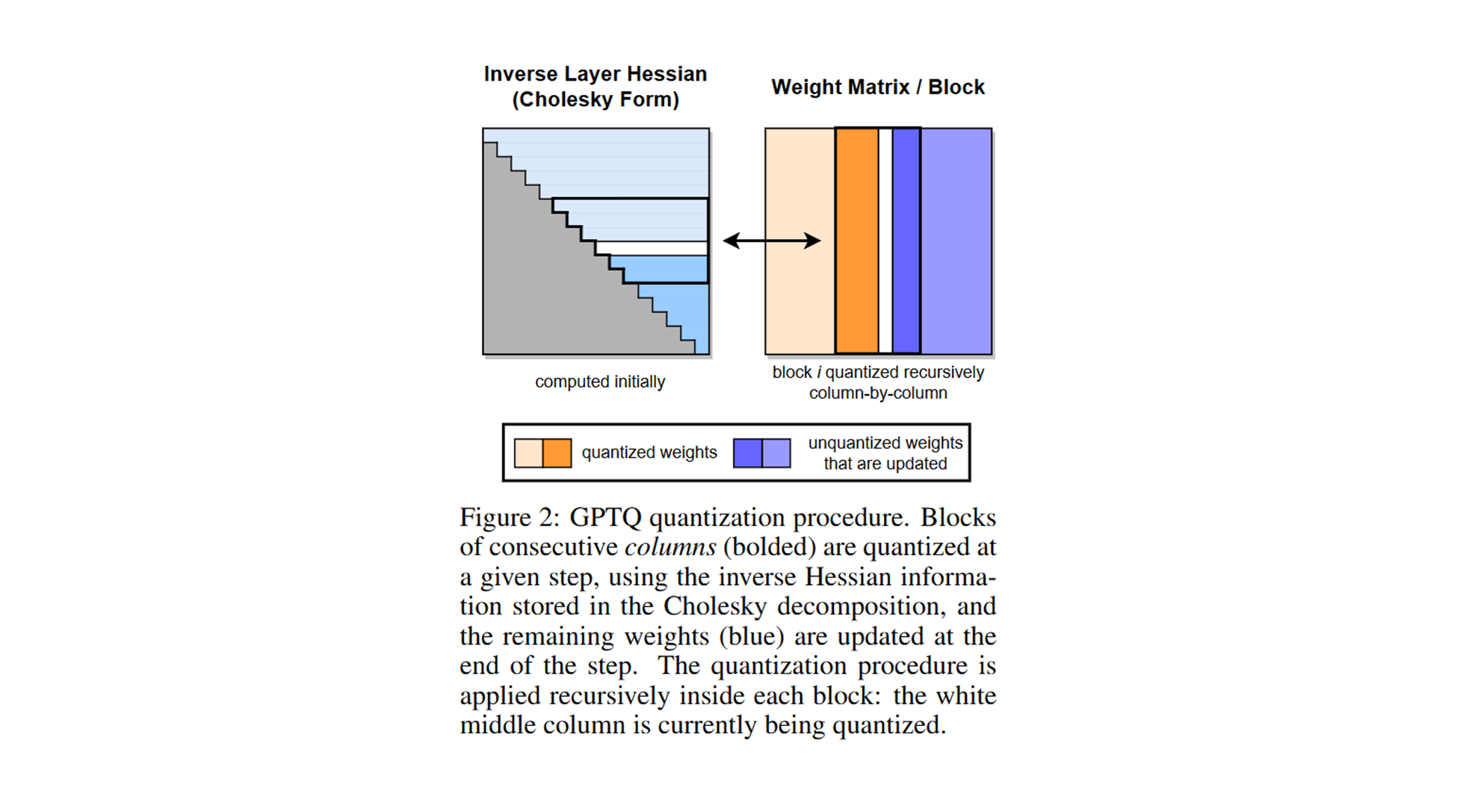
- 논문: GPTQ (Generative Pre-trained Transformer Quantization)
- GPT-3와 같은 대규모 모델은 뛰어난 성능을 제공하지만, 추론 시에도 엄청난 계산 리소스와 메모리가 필요합니다.
- 이를 해결하기 위해, 후처리 양자화(post-training quantization)를 통해 모델을 3비트 또는 4비트로 압축하면서 성능 손실을 최소화하는 방법을 제안합니다.
이미지 출처 : https://arxiv.org/pdf/1910.06360 (논문 원문)
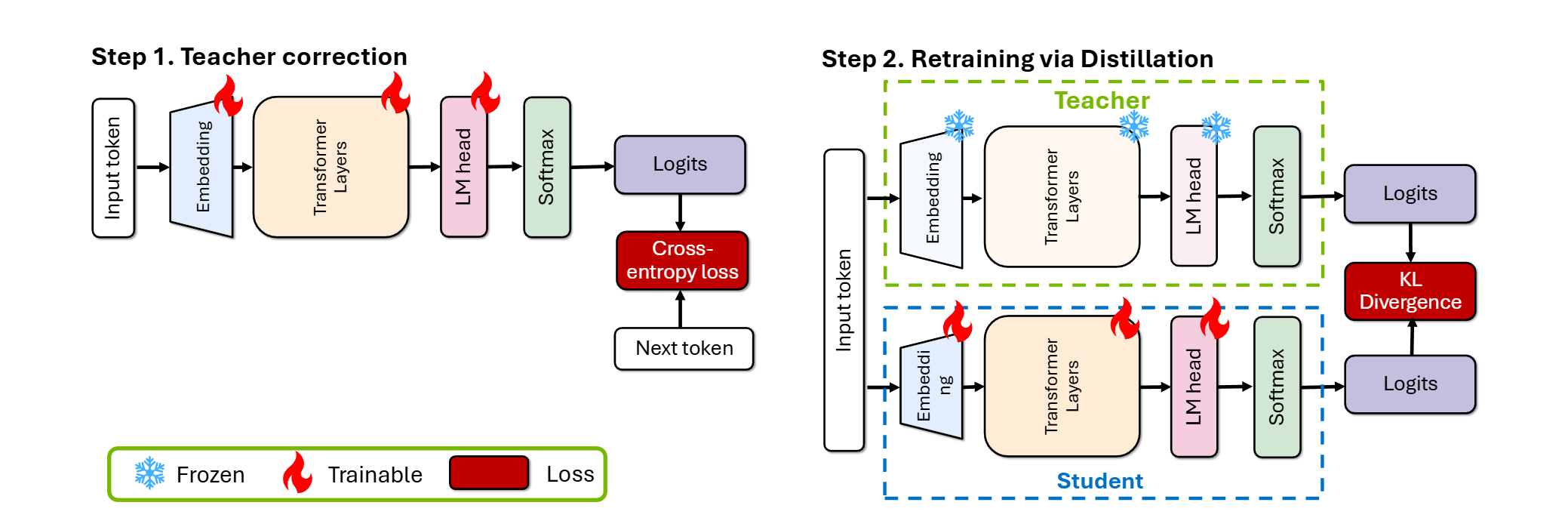
Pruning + Knowledge Distillation

Nvidia의 논문 "LLM Pruning and Distillation in Practice: The Minitron Approach"는 대규모 언어 모델(LLM)의 효율적인 압축을 위해 가지치기(pruning)와 지식 증류(knowledge distillation)를 결합한 Minitron 방법론을 제시합니다.
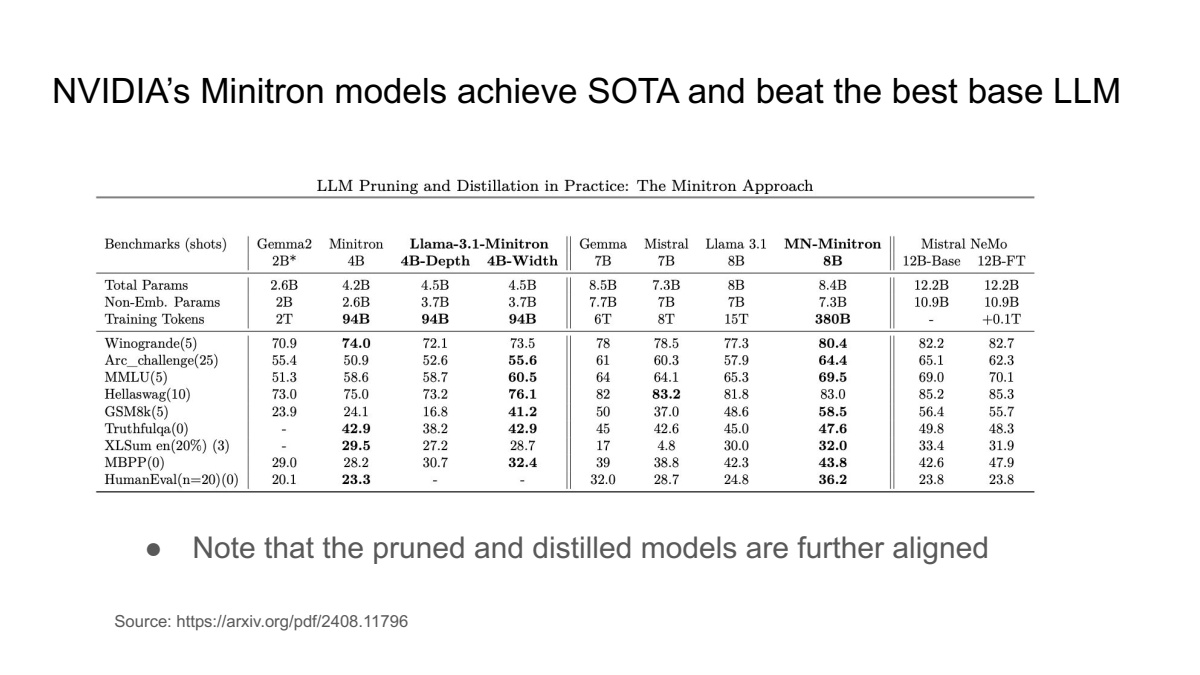
아래 표는 NVIDIA의 Minitron 모델이 기존의 대규모 언어 모델(LLM)들과 비교하여 다양한 벤치마크에서 우수한 성능(State-of-the-Art, SOTA)을 달성했음을 나타냅니다.
LLM의 발전속도는 빠르지만, SLM도 격차를 좁히고 있다
이 그래프는 SLM의 효율적인 발전 속도를 강조하며, 특정 주기마다 성능이 LLM에 근접하거나 따라잡을 가능성을 시사합니다.
- 이를 통해 SLM이 LLM의 대체재로서 활용될 수 있는 잠재력이 있음을 보여줍니다.
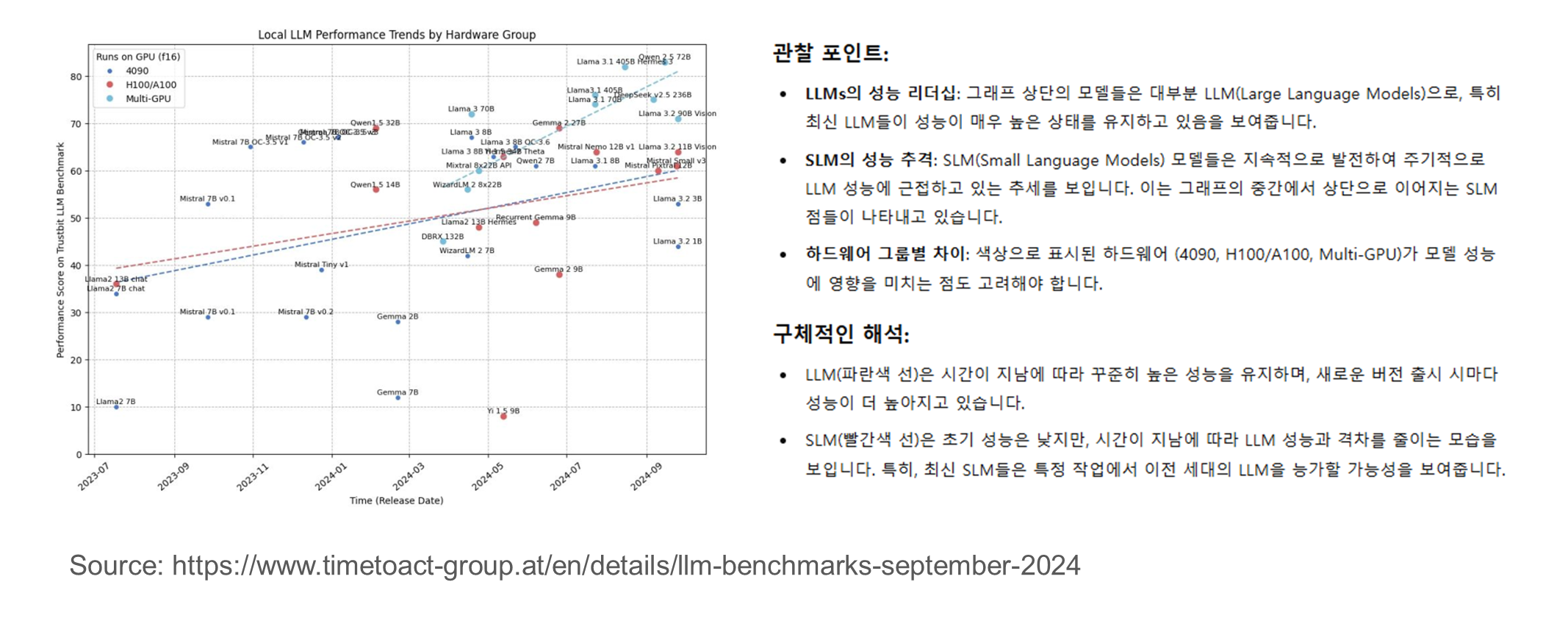
- 추가적으로, SLM의 성장 속도와 개발 주기를 더 분석하면 SLM이 LLM의 비용 대비 효율적인 선택지가 되는 영역을 구체적으로 확인할 수 있을 것입니다.

-
뿐만 아니라 작은 사이즈의 모델(SLM)이 특정한 작업(task-specific)에 최적화될 경우, 더 큰 모델(LLM)과 비교하여 경쟁력 있는 성능을 발휘할 수 있다고 이야기 합니다.
- Llama 3.3 70B 모델은 텍스트 처리에 특화된 instruction-tuned 모델로, 이를 통해 같은 크기의 Llama 3.1 70B 모델보다 성능이 우수함을 보여줍니다.
- 텍스트 전용 작업(text-only applications)에 한정할 경우, 더 큰 모델인 Llama 3.2 90B 또는 Llama 3.1 405B에 근접하거나 유사한 성능을 발휘할 수 있음이 강조되고 있습니다.
2. 처음부터 SLM 구축하는 팁
- 고품질 데이터 수집 및 전처리

💡 아래 두 논문, "Textbooks Are All You Need"와 "Textbooks Are All You Need II: phi-1.5 기술 보고서"는 고품질 데이터의 중요성을 강조하며, 소형 언어 모델의 성능을 극대화하는 방법을 탐구합니다.
- 각 논문의 주요 기여와 핵심 포인트는 다음과 같습니다:
- Textbooks Are All You Need 1
- phi-1 모델 개발: 1.3억 개의 매개변수를 가진 Transformer 기반 모델인 phi-1을 소개하였으며, 이는 HumanEval에서 50.6%, MBPP에서 55.5%의 pass@1 정확도를 달성하였습니다.
- 데이터 품질의 중요성 강조: 모델 크기와 데이터 양을 줄이면서도 고품질 데이터를 활용하여 기존의 대규모 모델과 유사하거나 더 나은 성능을 달성할 수 있음을 입증하였습니다.
- Textbooks Are All You Need 2
- phi-1.5 모델 개발: 1.3억 개의 매개변수를 가진 phi-1.5 모델을 소개하였으며, 이는 자연어 처리 작업에서 5배 큰 모델과 유사한 성능을 보였고, 초등학교 수학 및 기본 코딩과 같은 복잡한 추론 작업에서는 대부분의 비최신 LLM을 능가하였습니다.
- 모델의 특성 관찰: phi-1.5는 '단계별 사고' 능력, 기본적인 인컨텍스트 학습 등 더 큰 LLM에서 관찰되는 특성을 보여주었으며, 환각 및 유해하거나 편향된 생성의 가능성도 나타났습니다.
- Chinchilla Scaling Laws를 넘어서 훈련
잠깐! Chinchilla Scaling Laws에 대해서 알아보고 갑시다!
-
배경 설명
- Scaling Laws for Neural Language Models
🧐 OpenAI의 2020년도 연구 "Scaling Laws for Neural Language Models"는 모델의 파라미터 수와 데이터 크기를 증가시키면 성능이 향상되지만, 한쪽만 증가시킬 경우에는 성능 향상에 한계가 있음을 지적하였습니다.

모델 크기,데이터 크기,계산 자원의 증가가 모델 성능 향상에 중요한 영향을 미친다는 것을 6가지 주요 법칙으로 정리합니다.- 거듭제곱 법칙 (Power Laws):
- 모델 성능은 모델 크기, 데이터셋 크기, 훈련에 사용되는 컴퓨트 양 등 주요 요소에 대해 거듭제곱 법칙으로 나타납니다. 각 요소는 성능에 비례하여 영향을 미칩니다.
- 과적합의 보편성 (Universality of Overfitting):
- 성능은 모델 크기(N)와 데이터셋 크기(D)를 함께 증가시킬 때 향상되지만, 한쪽만 증가할 경우 점진적으로 성능 저하가 발생하므로 N과 D의 적절한 비율을 유지하는 것이 중요합니다.
- 훈련 곡선의 보편성 (Universality of Training):
- 훈련 곡선은 예측 가능하며, 모델 크기와 관계없이 매개변수가 유사한 경향을 나타냅니다. 초기 훈련 데이터를 통해 추후 손실 값을 예측할 수 있는 가능성을 제공합니다.
- 샘플 효율성 (Sample Efficiency):
- 큰 모델은 더 샘플 효율적이며, 동일한 성능에 도달하기 위해 적은 데이터 포인트와 적은 최적화 단계를 요구합니다.
- 최적의 배치 크기 (Optimal Batch Size):
- 훈련 모델의 최적 배치 크기는 손실과 밀접한 관계가 있으며, 가장 큰 모델을 사용할 때 수렴하기 위해 약 100만에서 200만 토큰이 이상적이라는 점이 제안됩니다.
- 컴퓨트 효율적인 훈련 (Compute-Efficient Training):
- 고정된 컴퓨트 예산 내에서 훈련을 진행할 때, 매우 큰 모델을 훈련하고 수렴 전에 중단하는 것이 최적의 성능을 달성하는 데 더 효과적이라는 주장이 있습니다.
- Training Compute-Optimal Large Language Models
🧐 Google의 2022년도 연구 "Training Compute-Optimal Large Language Models", Chinchilla 연구는 주어진 계산 자원 내에서 모델 크기와 학습 데이터 크기를 어떻게 최적화할 것인지에 초점을 맞추었습니다.

- 이 연구는 모델 크기와 학습 데이터 크기를 동일한 비율로 증가시키는 것이 최적의 성능을 달성하는 데 중요하다는 것을 발견하였습니다.
- 이를 통해, 기존의 대규모 모델들이 과소학습(undertrained) 상태였음을 지적하며, 모델 크기와 데이터 크기의 균형이 중요하다는 새로운 관점을 제시하였습니다.
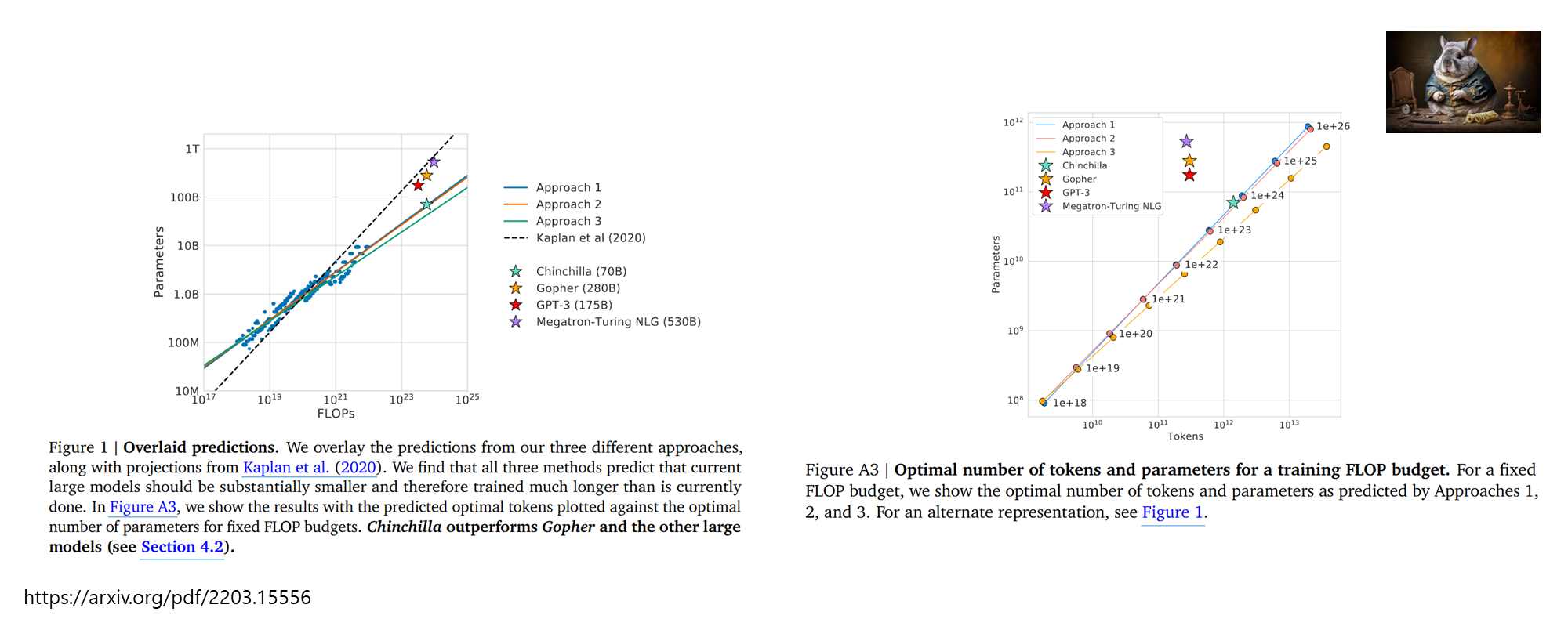
- 이를 통해, 기존의 대규모 모델들이 과소학습(undertrained) 상태였음을 지적하며, 모델 크기와 데이터 크기의 균형이 중요하다는 새로운 관점을 제시하였습니다.
- 논문의 Figure 1과 Figure A3는 현재의 대규모 언어 모델들이 과소학습(undertrained) 상태에 있음을 시각적으로 보여줍니다. 각 그래프의 의미를 자세히 살펴보겠습니다.
- Figure 1: Overlaid predictions
- 이 그래프는 세 가지 접근법(Approach 1, 2, 3)의 예측 결과와 Kaplan et al. (2020)의 예측을 함께 보여줍니다. X축은 FLOPs(연산량)을, Y축은 모델 파라미터 수를 나타냅니다.
- 현재 모델들의 위치: GPT-3(175B), Gopher(280B), Megatron-Turing NLG(530B) 등의 모델은 그래프 상단에 위치해 있습니다. 이는 모델 크기는 크지만, 주어진 연산 예산 내에서 최적의 성능을 내기에는 학습 데이터가 부족함을 시사합니다.
- 예측된 최적 지점: 세 가지 접근법 모두 현재 모델들보다 작은 파라미터 수를 가지며, 더 많은 학습 데이터를 사용하는 것이 최적임을 보여줍니다. 이는 모델 크기와 학습 데이터 크기를 균형 있게 증가시켜야 함을 의미합니다.
- Figure A3: Optimal number of tokens and parameters for a training FLOP budget
- 이 그래프는 고정된 연산 예산(FLOP budget) 하에서 최적의 파라미터 수와 학습 토큰 수를 나타냅니다. X축은 모델 파라미터 수, Y축은 학습 토큰 수를 나타냅니다.
- 최적의 조합: 세 가지 접근법 모두 모델 파라미터 수와 학습 토큰 수가 비례 관계에 있음을 보여줍니다. 이는 주어진 연산 예산 내에서 모델 크기와 학습 데이터 크기를 동일한 비율로 증가시키는 것이 최적임을 의미합니다.
- 현재 모델들의 위치: 현재의 대규모 모델들은 이 최적선에서 벗어나 있으며, 모델 크기에 비해 학습 데이터가 부족함을 시사합니다.
📌 따라서! 🐿️ Chinchilla Optimum(최적화 법칙) 또는 Chinchilla Point(지점)은 모델의 파라미터 크기와 학습 데이터 크기 간의 최적 균형을 제안하는 기준이라고 정의할 수 있습니다.
-
SLM은 대형 모델에 비해 파라미터 수가 적어 복잡한 패턴 학습에 제한이 있을 수 있습니다. 그러나 Chinchilla Scaling Laws에 따라 모델 크기에 비례하여 충분한 양의 고품질 데이터를 제공하면, 모델의 일반화 능력과 성능을 향상시킬 수 있습니다.
- 특히, Qwen2.5와 같이 모델 크기에 비해 더 많은 데이터를 활용하는 전략은 SLM의 한계를 극복하는 데 효과적입니다. 이는 SLM이 성능을 끌어올리기 위해 추가 데이터 학습이 얼마나 중요한지를 강조합니다.

- 특히, Qwen2.5와 같이 모델 크기에 비해 더 많은 데이터를 활용하는 전략은 SLM의 한계를 극복하는 데 효과적입니다. 이는 SLM이 성능을 끌어올리기 위해 추가 데이터 학습이 얼마나 중요한지를 강조합니다.
- (참고) 실제로 추가적으로 자료 조사를 수행해보니까 SLM에 Chinchilla Scaling Laws를 넘어선 추가 데이터 학습을 수행한 SLM 학습을 시키는 모델들이 있는 것을 확인할 수 있었습니다.
- Mamba와 Phi-2는 모두 소형 언어 모델(SLM)에 속하며, 이들의 학습 비율을 보면 200:1로 over-trained 영역에 있는 것을 확인할 수 있습니다.
이미지 출처 : https://lifearchitect.ai/chinchilla/
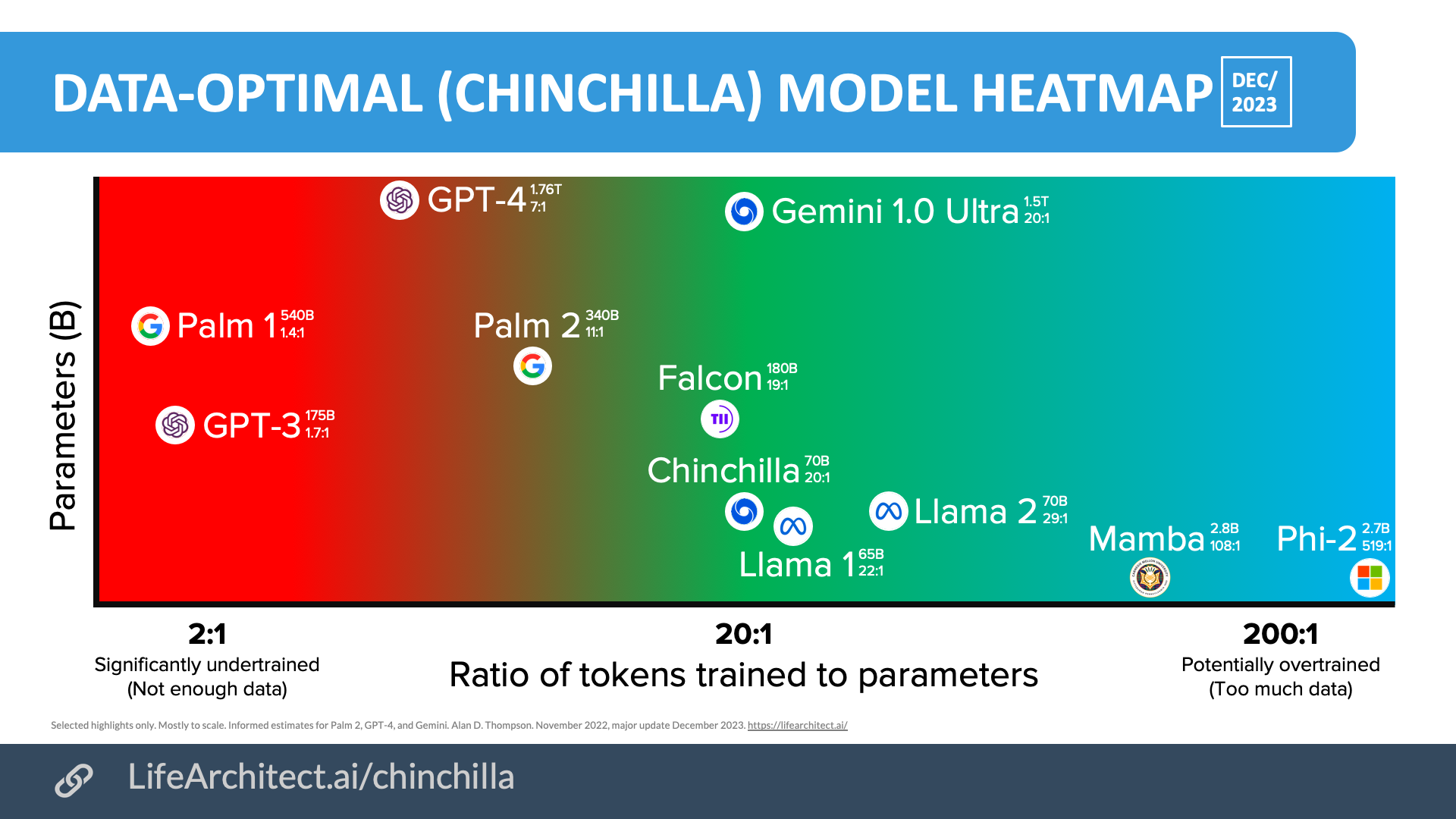
SLM이 어떻게 LLM을 따라잡을 수 있는가

-
Generative AI(GenAI) 연구는 처음에 SLM으로 시작되었습니다.
- 이후 LLM이 도입되었지만, 실험 결과 큰 모델이 항상 작은 모델보다 더 나은 것은 아니며, 작은 모델을 작업(task)에 맞게 파인튜닝하면 더 나은 결과를 낼 수 있음이 밝혀졌습니다.
-
현재의 LLM조차도 전 세계의 지식을 충분히 포함할 수 없는, 압축된 상태의 모델입니다.
- 이는 우리가 알고 있는 모든 정보를 담기에는 LLM도 제한적이라는 것을 뜻합니다.
- 얼마나 더 훈련 및 효율성을 개선하는 가에 따라서, SLM이 특정 작업에 더 잘 작동할 수 있습니다.
-
모델 크기와 데이터 양이 성능에 미치는 관계는 여전히 유효합니다.
- SLM이라도 적절한 데이터 크기와 훈련 자원을 투입하면 LLM에 근접한 성능을 낼 수 있습니다.
(결론) 현재의 LLM은 지식을 저장하는 방식이나 계산 효율성 측면에서 비효율적이라는 것을 의미합니다.
LLM의 문제점
발표자는 현재의 LLM(Large Language Models)이 "무차별적인 brute force 방식"으로 작동하고 있다는 점을 강조합니다

-
훈련 데이터의 품질 문제
- Pre-trained models are getting trained with noisy data:
- 현재 LLM은 대규모의 데이터를 학습하고 있지만, 이 데이터에는 많은 노이즈(불필요하거나 부정확한 정보)가 포함되어 있습니다.
- 노이즈는 모델의 성능을 제한하며, 학습 효율성을 떨어뜨립니다.
- 이는 모델이 반드시 필요한 정보만 학습하도록 데이터를 정제하는 작업이 부족함을 시사합니다.
- Pre-trained models are getting trained with noisy data:
-
비효율적인 지식 저장
- Knowledge is stored in a highly non-optimized way:
- 현재 LLM은 비효율적인 방식으로 지식을 저장하고 있습니다.
- 슬라이드는 모든 LLM이 파라미터당 약 2비트(bits)의 정보를 저장할 수 있다고 가정합니다.
- 7B(7 billion parameters) 모델만으로도 전 세계의 위키(Wikipedia)와 교과서 텍스트 지식을 학습하기에 충분하다고 주장합니다.
- 이는 더 작은 모델에서도 동일한 작업을 더 효율적으로 수행할 수 있음을 암시합니다.
- Knowledge is stored in a highly non-optimized way:
-
중복되거나 불필요한 연결
- Redundant/unnecessary connections:
- Interpretability Research에 따르면, LLM은 필요 이상의 중복된 연결을 포함하며, 이는 모델의 효율성을 떨어뜨립니다.
- LLM이 여러 개의 작은 회로(circuit)를 인코딩하는 경향이 있다는 점이 발견되었습니다. 이는 최적화가 부족함을 보여줍니다.
- Redundant/unnecessary connections:
-
새로운 학습 알고리즘 및 아키텍처의 가능성
- Possibly more efficient learning algorithms are yet to be discovered/proven:
- 현재 사용되는 Transformer 아키텍처가 최적의 학습 방법이 아닐 가능성을 제기합니다.
- SSM(State Space Models)와 RNN 기반 모델과 같은 더 효율적인 구조가 연구되고 있으며, 이는 LLM의 비효율성을 해결할 가능성이 있습니다.
- 또한, 행렬 곱셈(matrix multiplication)을 최적화하는 아키텍처가 성능 향상을 제공할 수 있습니다.
- Possibly more efficient learning algorithms are yet to be discovered/proven:
Research Frontiers
-
Rethinking Model Architectures
- Linear Models:
- SSM(State Space Models) 및 RNN 기반 모델과 같은 경량화된 모델 아키텍처 탐색.
- Sparse Attention 및 Reversible Networks를 통한 계산 효율성 증대.
- Linear Models:
-
Rethinking Hardware
- Non-von Neumann Architectures:
- 양자 컴퓨팅(Quantum Computing)과 신경형 컴퓨팅(Neuromorphic Computing)과 같은 새로운 하드웨어 기술 적용 가능성.
- 전력 효율성과 모델 성능을 동시에 향상시키기 위한 지속 가능한 컴퓨팅 기술 연구.
- Non-von Neumann Architectures:
✔️ Non-von Neumann Architectures이란?
- Non-von Neumann Architectures는 전통적인 폰 노이만 구조(Von Neumann Architecture)의 한계를 극복하기 위해 제안된 컴퓨팅 아키텍처입니다.
- 폰 노이만 구조는 컴퓨터의 메모리와 프로세서가 분리되어 있으며, 데이터를 메모리에서 프로세서로 전송하는 방식으로 동작합니다.
- 하지만 이 구조는 다음과 같은 문제를 가지고 있습니다.
- 폰 노이만 병목 현상(Von Neumann Bottleneck)
- 메모리와 프로세서 간의 데이터 전송 속도가 컴퓨터 성능의 주요 제한 요소가 됩니다.
- 처리할 데이터가 커질수록 병목 현상이 심화되어 에너지 소모와 연산 속도가 비효율적입니다.
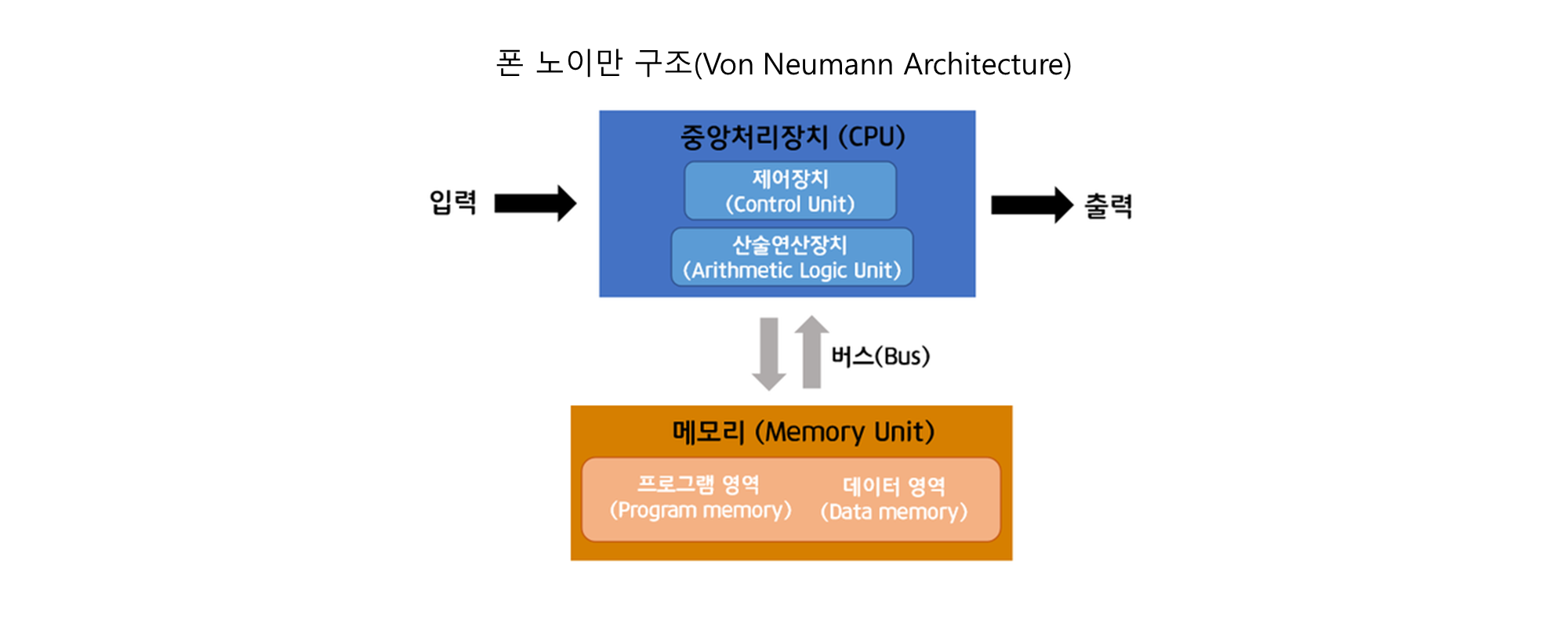
✔️ Non-von Neumann Architectures의 특징
- Non-von Neumann 구조는 이러한 문제를 해결하기 위해 제안된 대안적인 컴퓨팅 아키텍처로, 대표적으로 다음과 같은 기술들이 포함됩니다:
- (1) Neuromorphic Computing (신경형 컴퓨팅)
- (2) Quantum Computing (양자 컴퓨팅)
- (3) Processing-in-Memory (PIM, 메모리 내 연산)
- (4) Heterogeneous Architectures (이종 컴퓨팅 아키텍처)
- Interpretability Research
- 모델의 내부 구조를 더 깊이 이해하기 위한 해석 가능성 연구.
"The more we understand what’s going under the hood, the more we can
learn how best to train models" ("모델 내부에서 어떤 일이 일어나는지 이해할수록, 모델을 최적으로 훈련시키는 방법을 더 잘 배울 수 있다.")
- 모델의 내부 구조를 더 깊이 이해하기 위한 해석 가능성 연구.
결론
SLM(Small Language Model)은 효율성, 실용성, 지속 가능성이라는 현대 AI의 핵심 요구를 충족하며, 특정 도메인에 특화된 해결책으로 자리잡고 있습니다. 에너지 소비와 탄소 배출의 감소, 더 낮은 계산 비용으로도 높은 성능을 발휘할 수 있는 가능성은 기업과 연구자들에게 실질적인 혜택을 제공합니다.
또한, SLM은 LLM(Large Language Model)이 해결하지 못한 문제들을 보완하며, 데이터 프라이버시와 엣지 컴퓨팅과 같은 실질적인 요구를 충족합니다. 이는 더 이상 AI 연구가 단순히 모델 크기를 키우는 방향이 아니라, 특정 문제를 효율적으로 해결할 수 있는 맞춤형 솔루션을 탐구해야 함을 시사합니다.
앞으로의 연구와 혁신은 SLM과 LLM의 공존과 상호 보완에 집중해야 합니다. LLM은 여전히 범용적이고 복잡한 문제를 해결하는 데 강점을 가지며, SLM은 도메인 특화와 경량화된 환경에서 그 장점을 발휘할 것입니다. 이러한 균형은 AI의 지속 가능성과 확장 가능성을 동시에 실현하는 핵심 전략이 될 것입니다.
특히, LLM과 SLM 간의 차별화된 역할을 인정하면서도, 양자의 장점을 결합해 더 나은 모델 설계를 도모하는 연구가 이어질 것으로 보입니다. 이를 통해 AI는 단순히 더 큰 모델이 아니라, 특정한 요구에 맞춘 최적화된 형태로 진화해 갈 것입니다.
결국, SLM은 데이터와 컴퓨팅 자원이 제한된 상황에서도 강력한 AI 기능을 제공할 수 있는 새로운 가능성을 열며, AI의 대중화와 실용화를 촉진할 중요한 축이 될 것입니다. 이를 기반으로, AI는 더 많은 사람들에게 다가갈 수 있는 혁신적 도구로 발전하게 될 것입니다.
읽어주셔서 감사합니다 :)
