멀티프로세싱과 멀티스레딩을 선택할 때 고려해야 하는 작업의 특성에 대해 더 자세히 설명하겠습니다. 자원 분할 및 할당에 대해서 궁금하신 분을 다음 게시글에서 확인하실 수 있습니다.
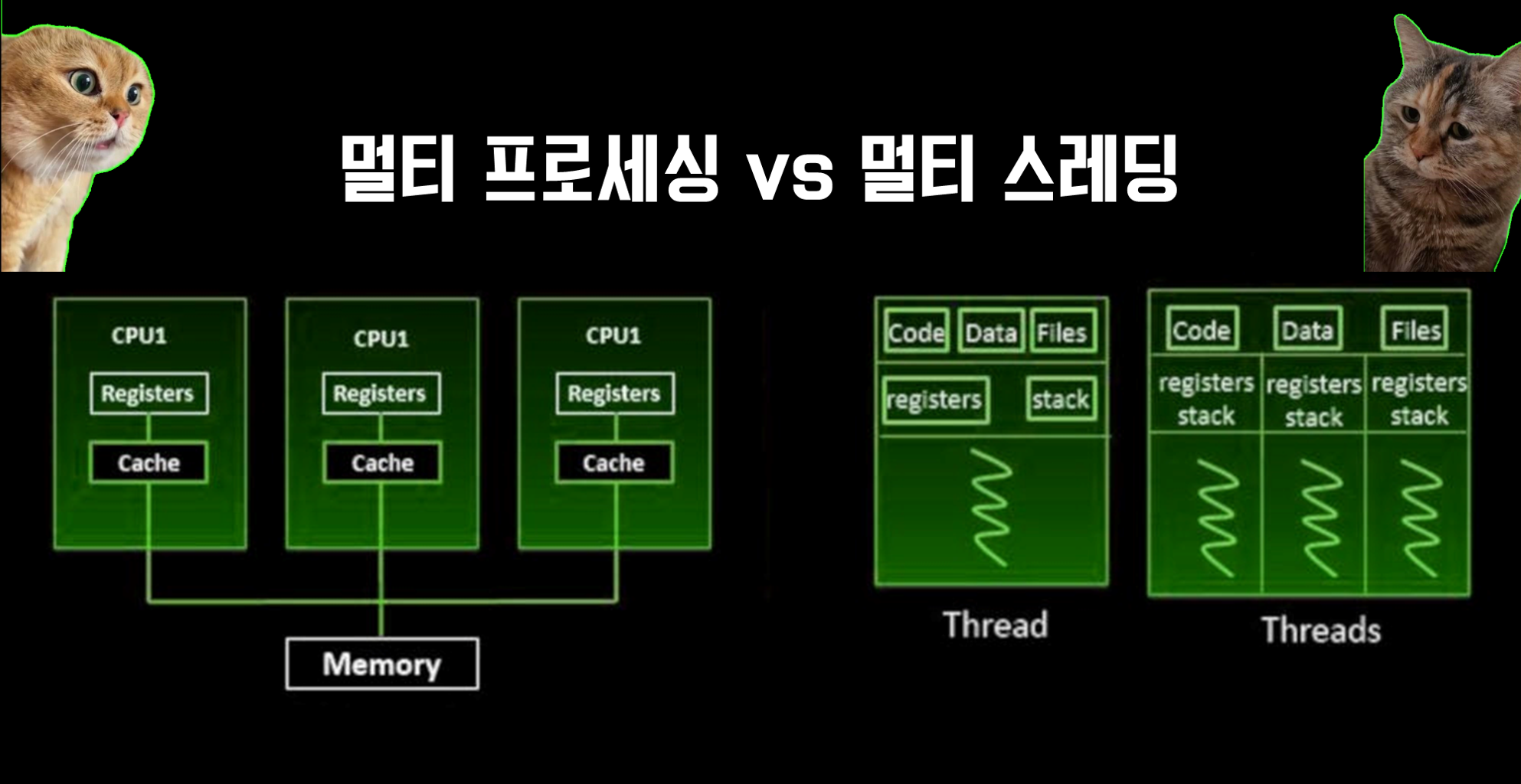
멀티프로세싱(Multiprocessing)
멀티프로세싱은 주로 CPU 집약적인 작업에 적합합니다. 이런 작업은 계산이 많이 필요하고 CPU의 자원을 많이 사용하는 경우인데요. 예로, 데이터 분석, 이미지 처리, 복잡한 수학적 계산 등이 여기에 해당합니다.
멀티프로세싱을 사용하면 각 프로세스가 독립된 메모리 공간을 가지기 때문에, 한 프로세스에서 발생한 문제(예: 메모리 누수)가 다른 프로세스에 영향을 미치지 않습니다. 또한, 멀티코어 CPU를 효율적으로 사용하여 작업을 병렬로 처리할 수 있습니다.
멀티프로세싱 예시 코드 설명
from multiprocessing import Pool
import pandas as pd
def process_file(file_name):
# 대용량 파일 처리 로직
data = pd.read_csv(file_name)
# 복잡한 데이터 처리 작업 수행
processed_data = data # 이 부분은 예시로 대체
return processed_data
if __name__ == '__main__':
files = ['file1.csv', 'file2.csv', 'file3.csv'] # 처리할 파일 목록
with Pool(processes=3) as pool:
results = pool.map(process_file, files)Pool객체를 사용하여 멀티프로세싱 풀을 생성합니다. 이 풀은 여러 프로세스를 관리하며, 각 프로세스에 작업을 할당합니다.process_file함수는 각 파일을 처리하는 로직을 담고 있습니다. 여기서는 예시로 pandas를 사용하여 CSV 파일을 읽어들이는 것으로 나타냈습니다.pool.map메소드를 통해 파일 목록에 대해process_file함수를 병렬로 실행합니다. 각 프로세스는 파일 목록 중 하나를 받아 독립적으로 처리합니다.
위에서 사용한 pool.map 대신 start와 join을 사용하고도 동일하게 멀티프로세싱을 수행할 수 있습니다.
from multiprocessing import Process
import pandas as pd
def process_file(file_name):
# 대용량 파일 처리 로직
print(f"Processing {file_name}")
data = pd.read_csv(file_name)
# 복잡한 데이터 처리 작업 수행
processed_data = data # 이 부분은 예시로 대체
# 처리된 데이터 반환 대신 파일 이름과 처리 완료 출력
print(f"Finished processing {file_name}")
return processed_data
if __name__ == '__main__':
files = ['file1.csv', 'file2.csv', 'file3.csv'] # 처리할 파일 목록
processes = []
# 각 파일에 대해 별도의 프로세스 생성 및 시작
for file_name in files:
process = Process(target=process_file, args=(file_name,))
processes.append(process)
process.start()
# 모든 프로세스의 완료를 기다림
for process in processes:
process.join()
print("All processing complete.").start()메서드를 호출하여 각 프로세스를 시작합니다. 이는 각 파일 처리 작업을 병렬로 실행하게 만듭니다..join()메서드를 사용하여 메인 프로세스가 모든 자식 프로세스의 실행이 완료될 때까지 기다리게 합니다. 이는 모든 데이터 처리 작업이 완료될 때까지 프로그램의 종료를 지연시킵니다.
멀티스레딩(Multithreading)
멀티스레딩은 주로 I/O 바운드 작업에 적합합니다. 이런 작업은 대량의 입출력, 예를 들어, 파일 읽기/쓰기, 네트워크 통신 등을 필요로 하는 경우입니다. 이 경우, 프로그램은 대부분의 시간을 데이터를 읽거나 쓰기를 기다리며 보내게 되는데, 이때 CPU는 많은 시간 동안 아무 일도 하지 않게 됩니다.
멀티스레딩을 사용하면, 한 스레드가 I/O 작업으로 대기 상태일 때 다른 스레드가 CPU를 사용하여 작업을 계속 진행할 수 있습니다. 이를 통해 프로그램의 전체 실행 시간을 줄일 수 있습니다.
멀티스레딩 예시 코드 설명
import threading
import requests
def fetch_data(url):
# 웹사이트에서 데이터를 요청하고 처리하는 로직
response = requests.get(url)
data = response.text # 이 부분은 예시로 대체
return data
urls = ['http://example.com/data1', 'http://example.com/data2', 'http://example.com/data3'] # 데이터를 수집할 웹사이트 주소 목록
threads = []
for url in urls:
thread = threading.Thread(target=fetch_data, args=(url,))
threads.append(thread)
thread.start()
for thread in
threads:
thread.join()- 여기서는
threading.Thread를 사용하여 각 URL에 대한 데이터 수집 작업을 별도의 스레드로 실행합니다. fetch_data함수는 주어진 URL에서 데이터를 요청하고, 응답을 받아오는 역할을 합니다.- 각 스레드는 독립적으로 웹사이트에 요청을 보내고 응답을 기다립니다. 이 과정에서 I/O 작업이 진행되는 동안, 다른 스레드는 CPU를 활용할 수 있습니다.
thread.join()은 메인 스레드가 모든 스레드의 작업이 끝날 때까지 기다리도록 합니다.
멀티프로세싱과 멀티스레딩의 선택은 작업의 특성에 따라 달라집니다. CPU 사용이 많은 작업에는 멀티프로세싱을, I/O 작업이 많은 경우에는 멀티스레딩을 사용하는 것이 좋습니다.

Q1. 파이썬에서는 GIL로 인해 멀티쓰레딩을 사용해도, 실제로는 멀티 쓰레드로 동작하지 않는걸로 알고 있는데 그 부분에 대해서는 어떻게 생각하시나요?
Q2. 멀티 프로세싱 에서 map()으로 실행을 하게 되면 동기적으로 실행되어서 실제로 병렬처리가 아니라 순차적으로 처리되기에 작업 소요시간은 동일할 것으로 보이는데 이부분에 대해서는 어떻게 생각하시는지?