[논문 리뷰] In-Context AutoEncoder for Context Compression in a Large Language Model (ICAE)
NLP 논문 리뷰
목록 보기
1/1
※ 이전 연구는 NLP 지식이 쌓인 후 다시 추가하겠습니다... 현재는 방법론 위주로 작성하였습니다.
Introduction
- 이 논문은 LLM의 Long-context 문제를 해결하는 방법을 제안합니다.
(long-context : 긴 입력 텍스트) - 트랜스포머 기반의 LLM 모델들은 self-attention 연산 때문에 긴(long) 입력을 잘 처리하지 못합니다.
(입력 길이에 따라 quadratic()한 연산복잡도) - 이전 연구들은 주로 모델 구조(예.attention)에 변형을 주는 방법으로 연산 속도를 개선시켰지만 성능은 여전히 좋지 못했습니다.
- 이 논문은 **context compression** 관점에서 문제를 해결하고자 합니다.
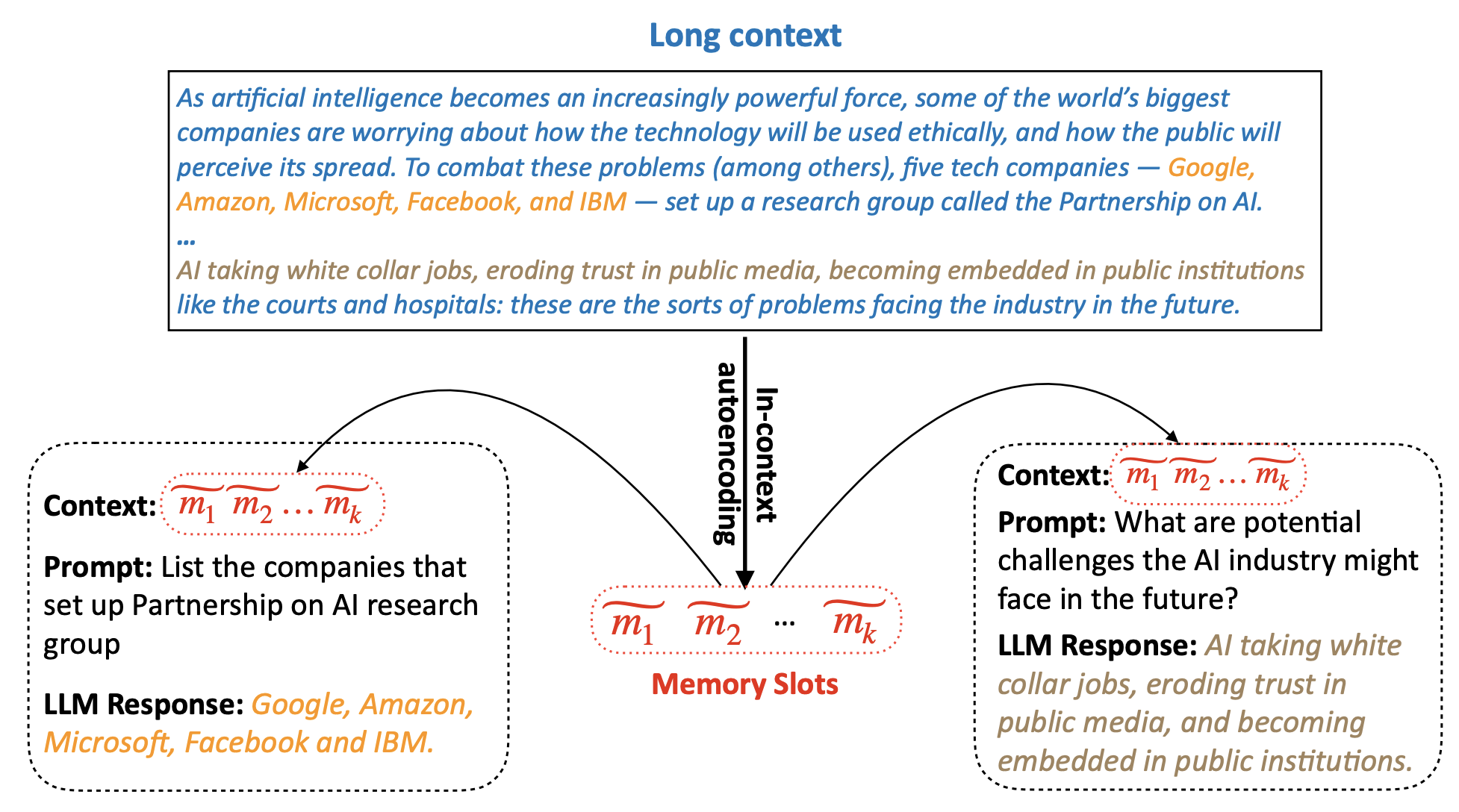
- 즉, long-context를 압축하여 memory라는 feature로 표현하는 방법을 제안합니다.
Motivation
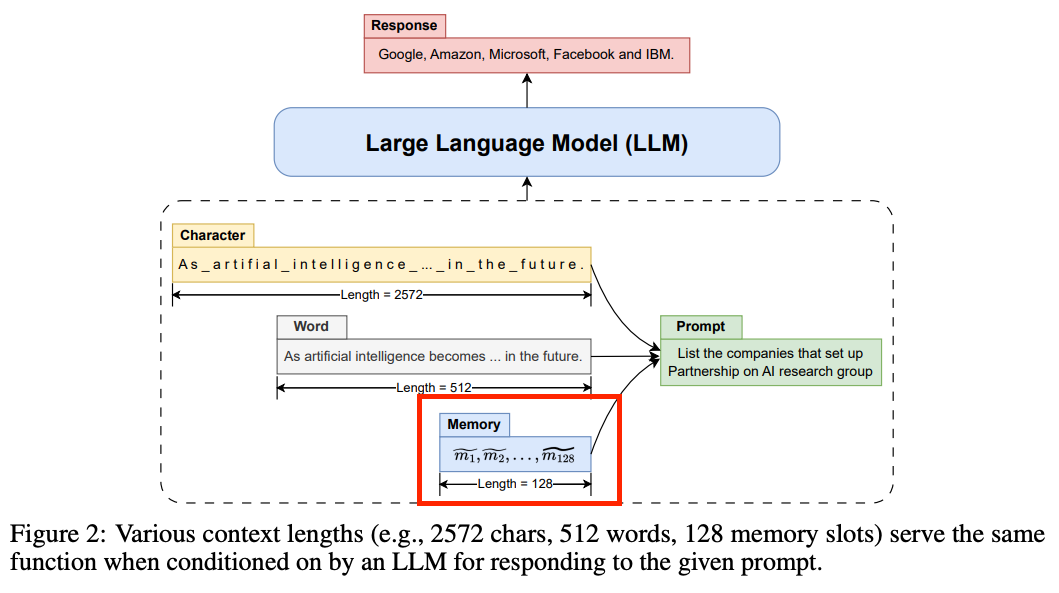
- 같은 정보를 담고 있는 text여도 LLM에서 다른 길이로 표현이 될 수 있습니다.
- 예를 들어, character 단위로 표현하면 2572 토큰, (sub-)word 단위로 표현하면 512 토큰
- 더 짧게 더 compact하게 텍스트를 표현할 수 없을까?가 해당 논문의 motivation입니다.
- 논문은 더 compact한 memory 단위로 long-context 텍스트를 표현합니다.
- memory는 오토인코더를 통해 구합니다.
In-Context AutoEncoder (ICAE)
- 주요 내용 프리뷰
- 오토인코더 구성
: LLM + LoRA를 사용 - 학습 방법
- Pretrain: 오토인코더 학습
- Fine-Tuning: Instruction 데이터로 파인튜닝
- Instruction 데이터셋은 GPT-4로 생성
- 오토인코더 구성
모델 아키텍쳐 & Pretrain 학습
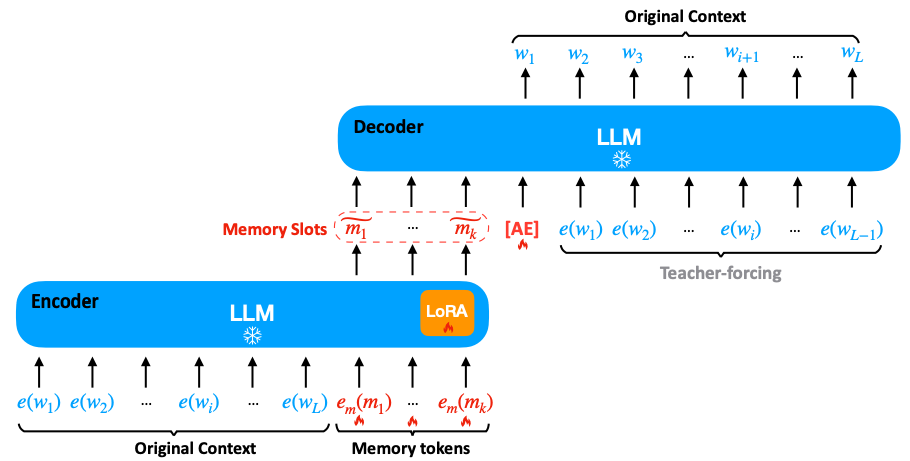
- LLM 자체를 인코더-디코더로써 사용
- 학습된 LLM 자체가 이미 텍스트(feature)를 잘 안다!! 그것을 잘 활용하자!
- 따라서, 뒤에 실험에서 나오지만 더 좋은 LLM 사용하면 성능 더 좋아진다
- 토큰을 이어붙이는 In-context 방식으로 인코딩-디코딩 수행
- 오토인코더 구조
- 인코더 : LLM + LoRA ( + memory tokens )
- 디코더 : LLM
- 이 때, LLM은 학습하지 않는다. 추가 LoRA와 임베딩만 학습
- pretrain 학습에는 엄청난 양의 텍스트 데이터 사용
- pretrain 학습 목적 함수는 2 가지가 있음
- AutoEncoding
- Text Continuation
Pretrain : AutoEncoding 학습
- : memory slots이 주어졌을 때 입력 context 복원하도록 memory slots 학습
- 디코더에 special 토큰 [AE] 사용
Pretrain : Text Continuation
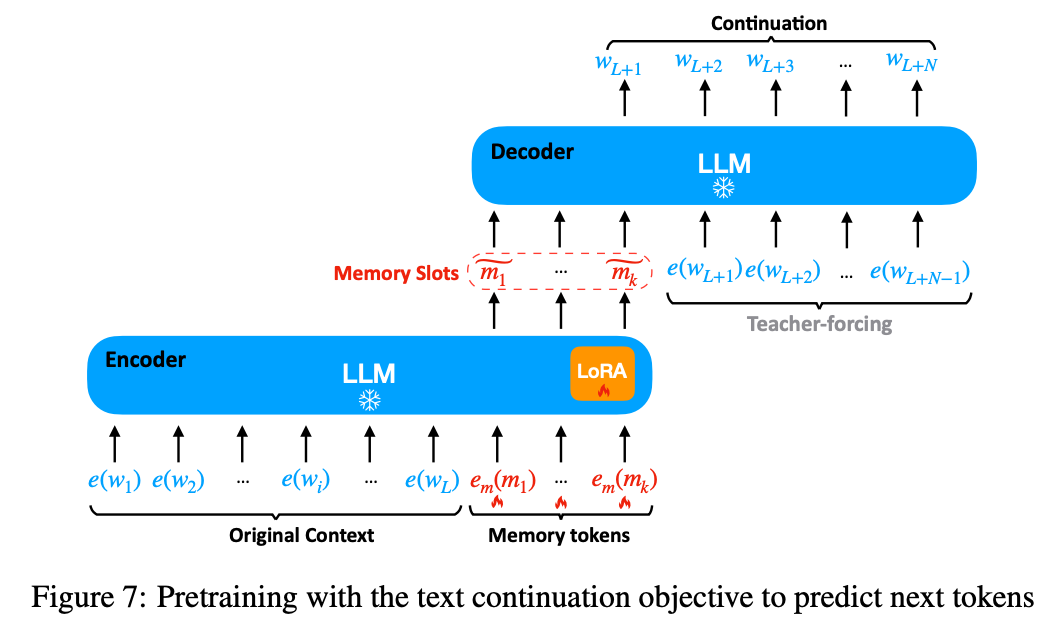
- : (다음 토큰 예측하는) LM 목적 함수와 동일하고 memory slots 학습.
- generalization을 위한 regularization loss
- 추가적인 효과로 기존 LLM의 능력을 잃지 않게 해주는 것 같음
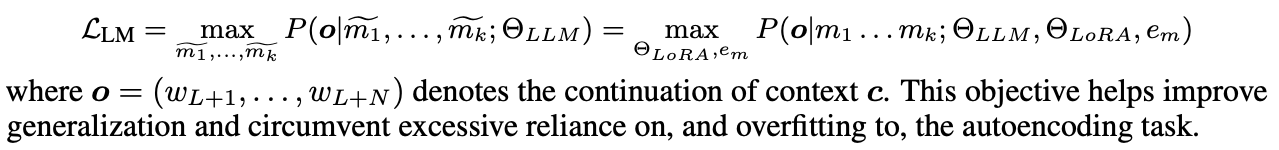
Instruction Fine-Tuning
-
단순 복원이 아니라 학습된 memory가 다양한 task에 사용될 수 있어야함
-
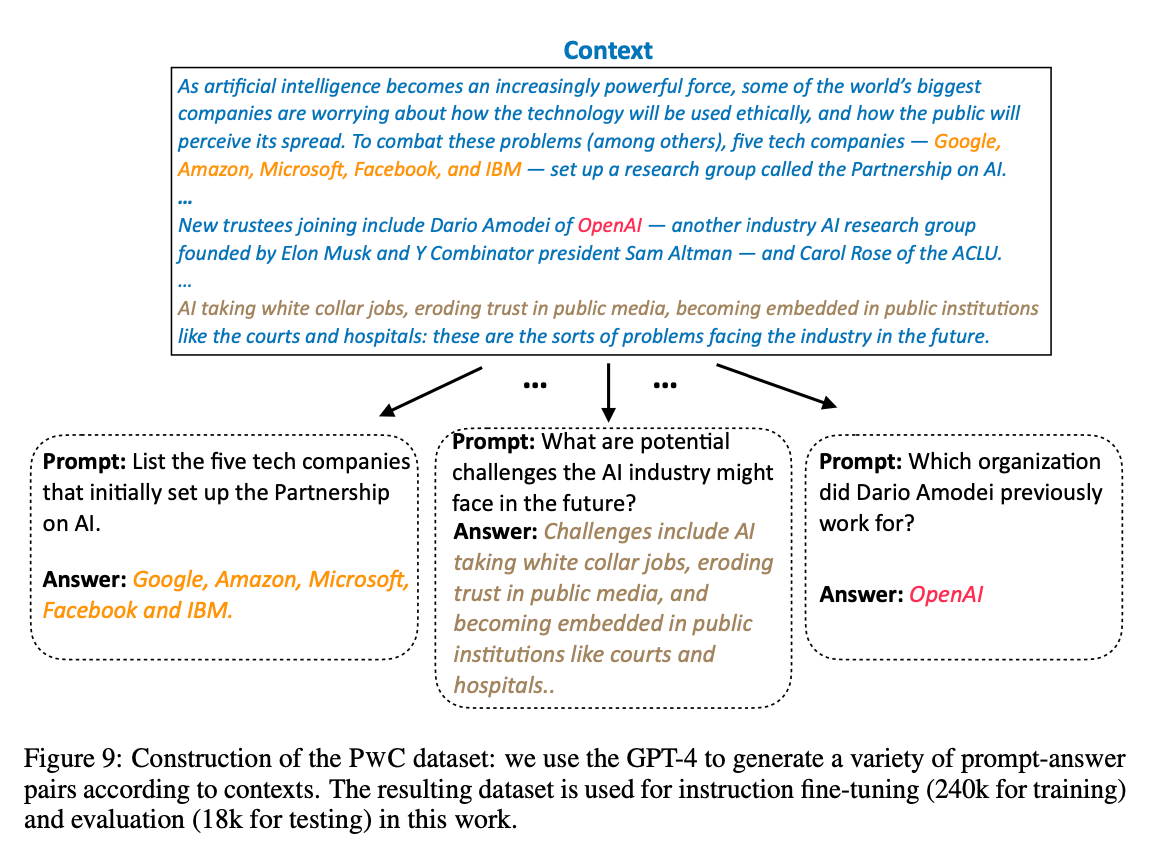
PwC(Prompt-with-Context) dataset으로 파인튜닝
- 논문에서 새로 만든 Instruction 데이터셋
- (context, prompt, response)로 구성됨
- context는 The Pile 데이터셋에서 샘플링, prompt-response는 GPT4로 생성
-
: context와 (instruction) prompt 주어졌을 때 response 생성하도록 memory slots 학습

Experiment
Setting
- pretrain에는 The Pile 데이터셋 사용
- The Pile: An 800gb dataset of diverse text for language modeling
- fine-tuning에는 PwC(Prompt-with-Context) 데이터셋 사용
- 240k samples for training, 18k for testing
- 허깅페이스 datasets에 공개됨
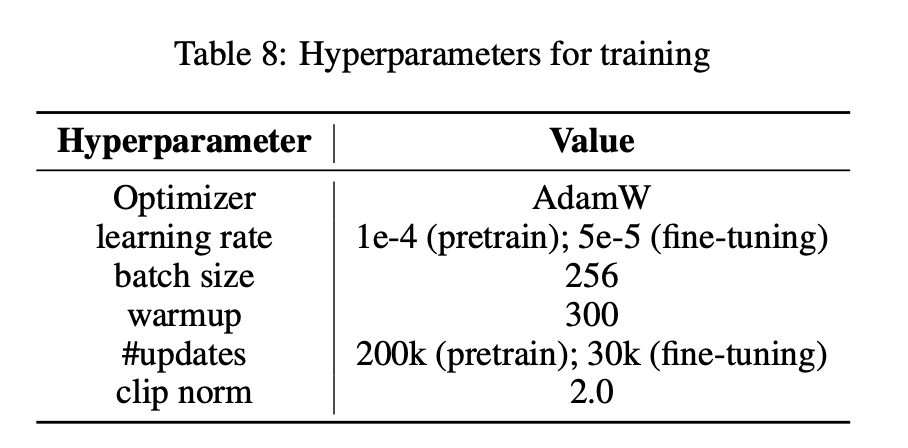
- LLM으로 LlaMa 사용
- LoRA는 LLM multi-head attention의 query, value projections에 사용, LoRA rank는 128
- memory slot 길이 k=128
- ICAE는 LLM의 약 1% 파라미터 추가됨
- 8 개의 A100 GPUs(80GB)으로 학습, bf16 사용
Pretrain된 ICAE 성능 평가
오토인코더의 복원 능력 평가
- metric
- BLEU score
- Exact-Match (EM) score :
- Cross Entropy Loss
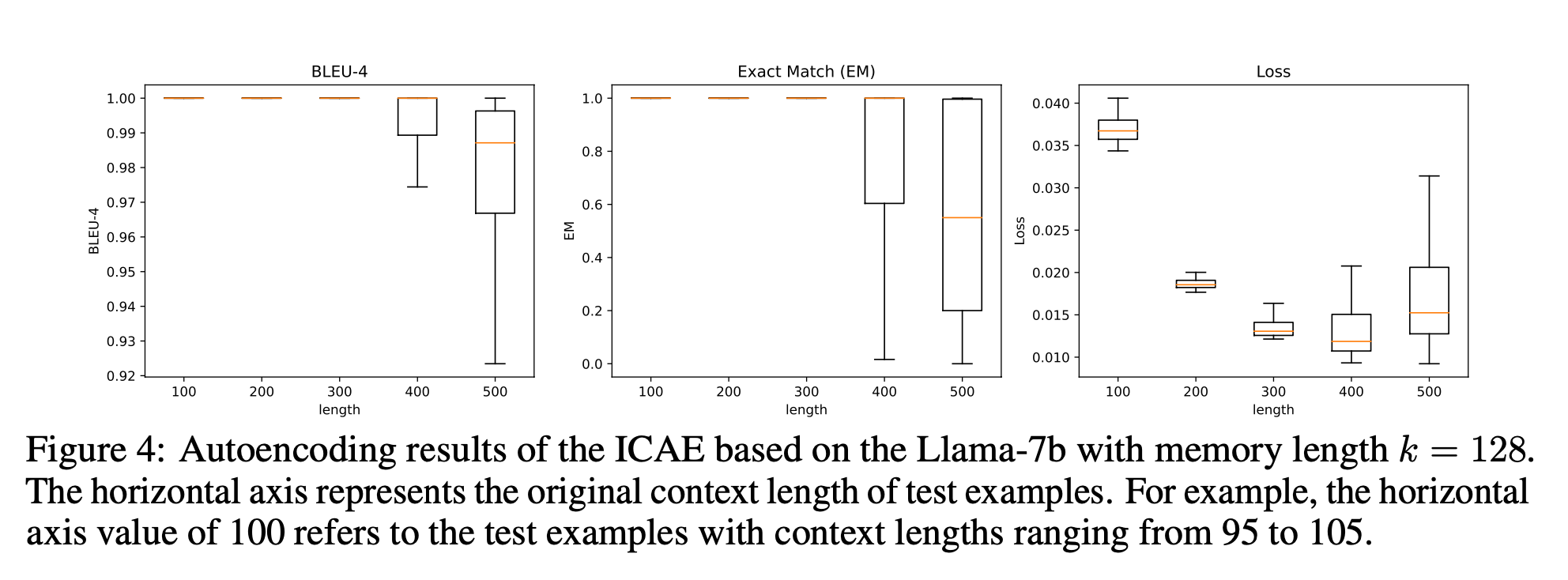
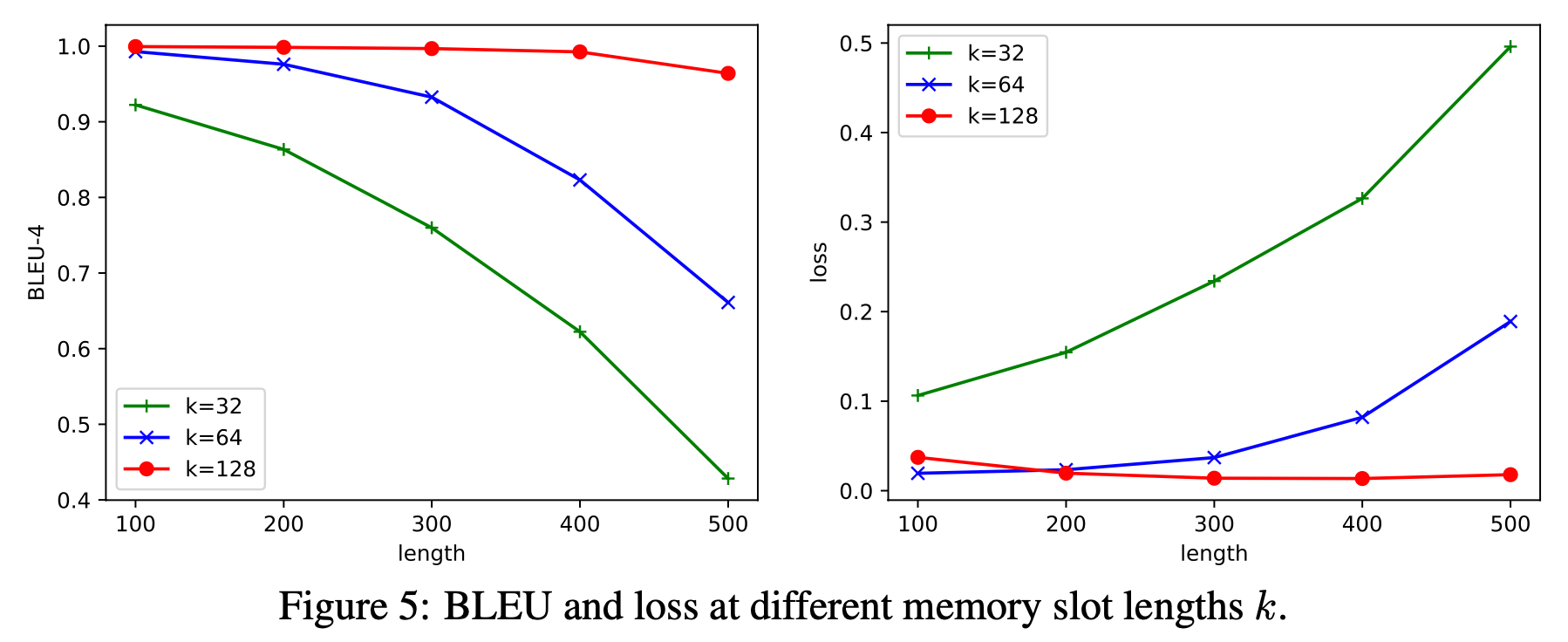
- 입력 토큰 길이에 따른 성능 비교
- 300까지는 거의 완전 복구
- 500의 경우 BLEU median이 0.98, EM이 0.6 (500*0.6=300토큰)
- memory slot 길이 k에 따른 성능 비교
- k가 작을수록 성능 하락
- 4배 이상 압축하는 것은 다소 어렵다.
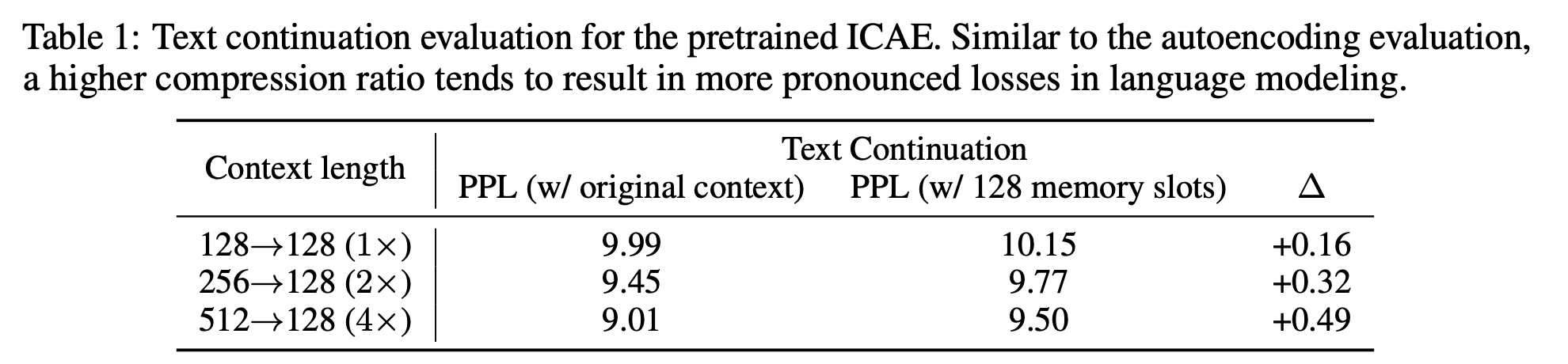
Text continuation 평가
- 압축률이 클수록 손실이 크다.
복구 예제

- 복구를 제대로 못한 부분을 보면 그럴 듯 하다
The results prove -> The experimental evidence proves
- Insight
: memorization 위해서 모델이 자기 지식을 바탕으로 스스로 특정 부분을 강조/무시
=> 지식이 없으면? rote memorization! (기계적 기억)

=> 지식이 많은 모델은 적은 노력으로 외울 수 있다
=> stronger LLM일수록 압축 더 잘한다
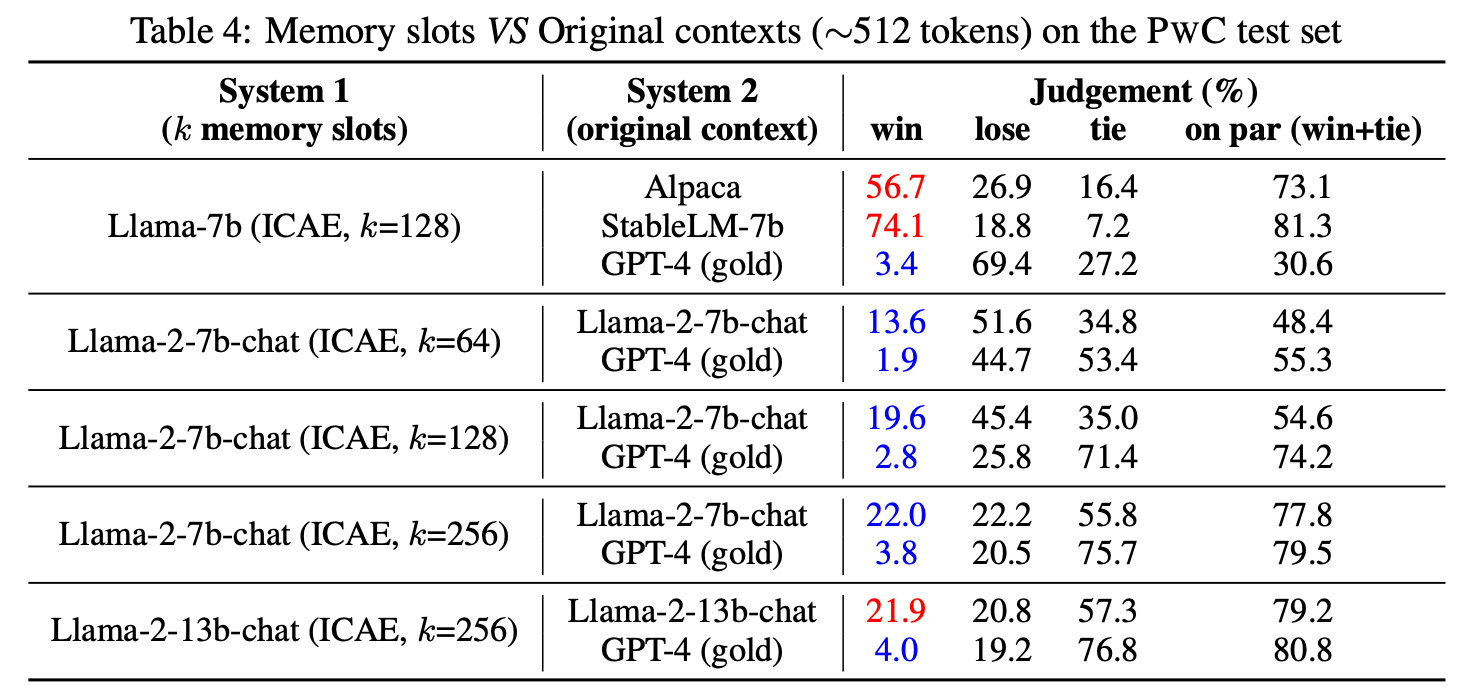
Fine-tuning된 ICAE 성능 평가
- PwC 테스트셋 사용
- GPT4에게 어느 모델의 결과가 더 좋냐고 물어봄
- 저자는 on par(win+tie)를 주 성능 지표로 사용함
LLM 비교
- Llama-7b의 ICAE는 GPT-4와 on par 비교했을 때 처참한데, 모델을 Llama-2-7b-chat으로 바꾸면 75%까지 올라감 (k=128 기준)
- Llama-2-7b-chat의 ICAE는 Llama-2-7b-chat보다 약간 성능이 떨어지지만 더 큰 모델(Llama-2-13b-chat)을 사용했을 때는 오히려 성능 향상이 있음. 이는 insight와 동일함.
pretrain의 영향 비교
- GPT에게 토큰 summary한 것보다 ICAE로 압축한 메모리 사용하는 것이 성능이 좋음
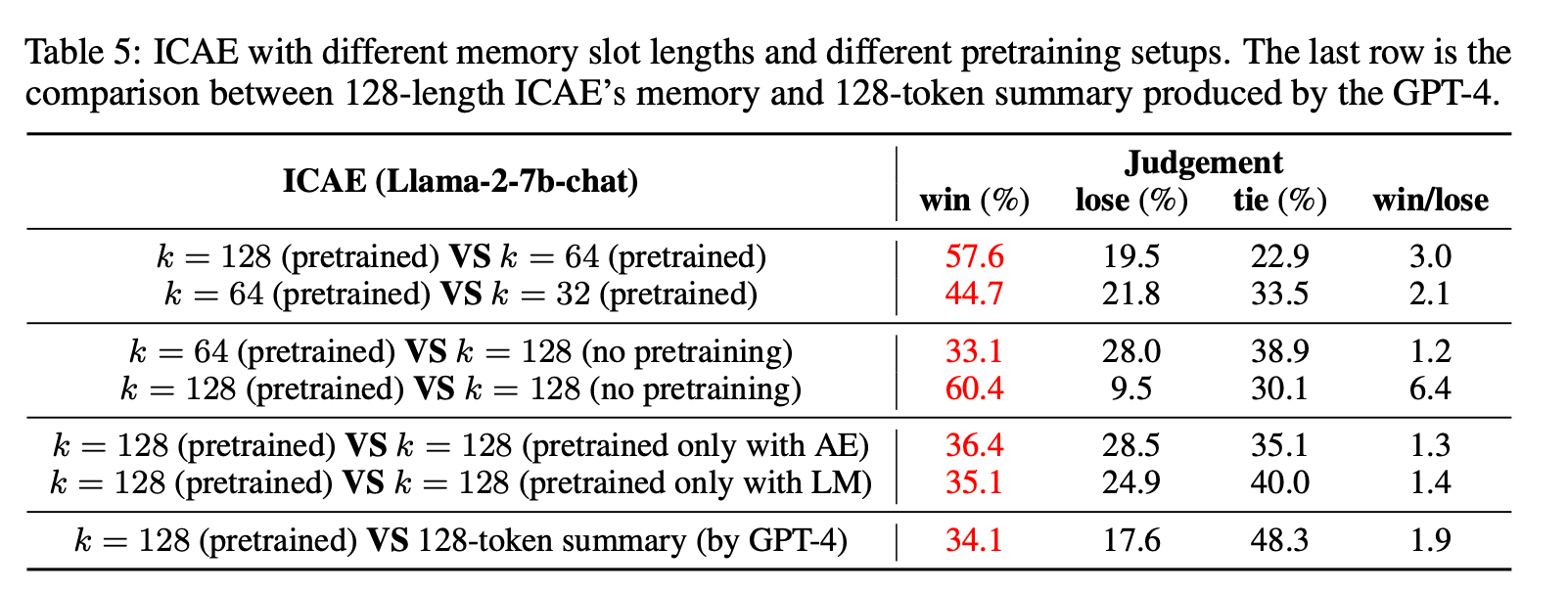
- pretrained vs non-pretrained 예제
- 30년인데 non-pretrained에서는 3년이라고 함

- 30년인데 non-pretrained에서는 3년이라고 함
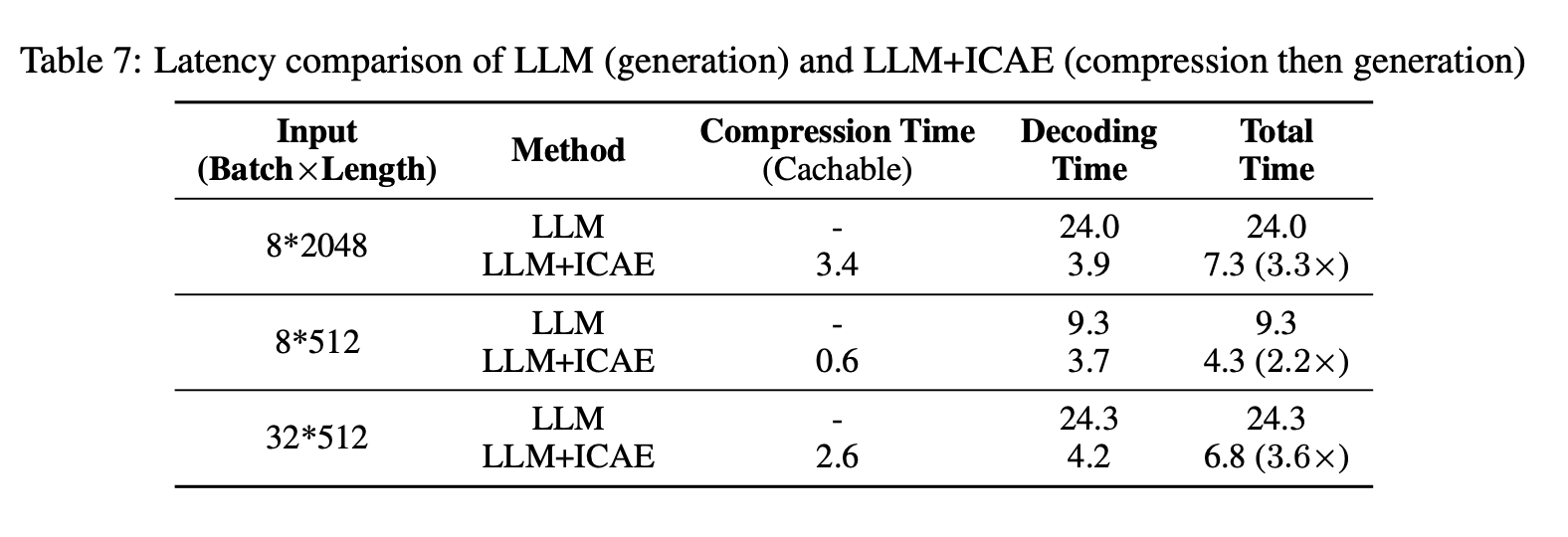
Latency
- 약 3 배 정도 빨라짐
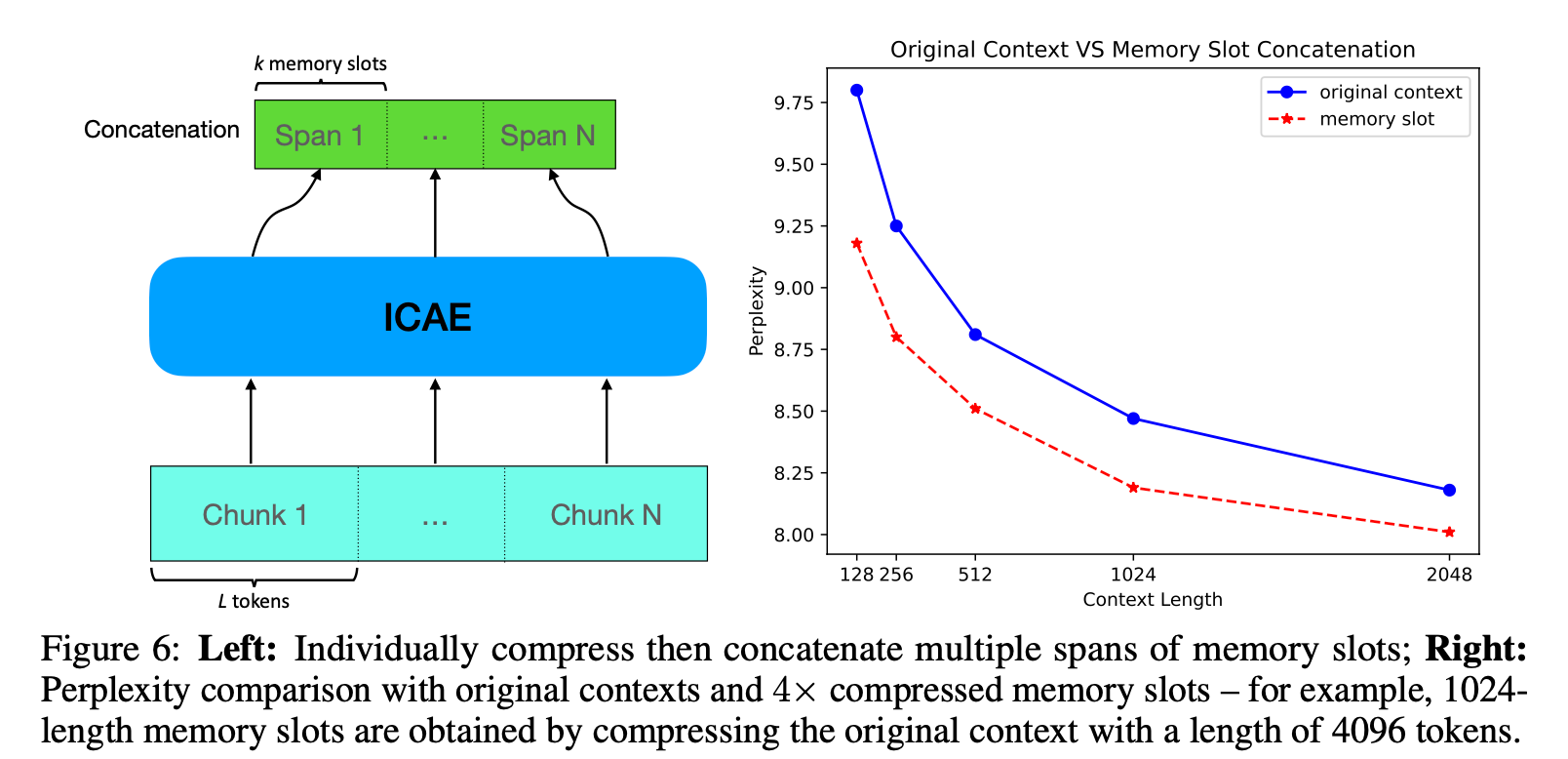
Multiple Spans of Memory Slots
- 512토큰 보다 많은 입력은 토큰 chunk를 내고 concat해서 사용
- 소량의 multiple span concatenation samples 학습 필요- ?? fill in the middle ??
enabling the model to work with concatenated spans of memory slots, as OpenAI’s work (Bavarian et al., 2022) on introducing the “fill in the middle” ability for the GPT.
- ?? fill in the middle ??
- ICAE 성능이 original context보다 더 좋음
- 사실 같은 1024 토큰이지만 ICAE는 4배 압축했기 때문에 4096 토큰 정보를 포함
- 약간의 성능 저하로 메모리 절약 가능
Conclusion
- LLM을 사용하여 context를 압축하는 ICAE 제안
- 연산량을 줄였고, 메모리 효율적
- LLM이 memorization 수행하는 방식에 대한 insight 제공
- PwC 데이터셋 공개
Reviewer's Summary
- 같은 입력일 때는 압축안한 것이 성능 좋음
- 단, 엄청 긴 길이 일때는 압축한 것이 좋음
- 같은 길이일 때는 압축한 것이 성능 좋음
- multi-span이 좋아보이는 데 왜 강조를 안했지?
- PwC 데이터셋 만드는 것도 일이었을텐데 contribution이라 안하고 그냥 넘어감
- contribution이라고 하는 insight 부분은 너무 주관적, 큰 모델 쓰면 잘된다를 설명하기 위해 넣은 듯
- 예전 attention 처음 나왔을 때의 느낌이 든다. 그 기계 번역에서 c 벡터로 압축하는...
- rote memorization 이란 단어 좋은 듯! 모델이 그냥 외워버려~
