| Porject Page | Arxiv | GitHub |
Preview
-
Cartoon interpolation 논문입니다.
- 첫 프레임과 마지막 프레임을 입력받아 중간 프레임을 생성하여 비디오 클립을 제작합니다.

- 첫 프레임과 마지막 프레임을 입력받아 중간 프레임을 생성하여 비디오 클립을 제작합니다.
-
기존의 T2V 모델을 애니메이션 도메인에 최적화하여 파인튜닝하는 방법 제안합니다.
-
(Reviewer's 💡) 파인튜닝하면서 겪을 수 있는 흔한 문제를 해결하는 연구의 흐름이 괜찮습니다.
Introduction
-
Cartoon video interpolation 태스크입니다.
- 애니메이션의 프레임률을 높이기 위한 연구 분야 (더 부드러운 움직임/모션 가능) 입니다.
-
최근 image-conditioned T2V 모델이 뛰어난 성능을 보이지만, 이 분야에 바로 적용할 수 없는 세 가지 이유는 다음과 같습니다.
-
도메인 gap
: 학습 데이터 주로 (non-cartoon) real 도메인이어서 cartoon 데이터를 잘 대응하지 못합니다. -
압축된 잠재 공간(latent space) 사용함으로 디테일 손실
: 베이스 모델인 LDM(latent diffusion model)의 디코더가 잠재 공간에서 이미지를 복원 과정에서 종종 뭉게지는 현상이 발생합니다.

-
사용자 제어의 어려움
: 텍스트 만으로 원하는 모션을 생성하는 것은 어렵습니다.
-
-
ToonCrafter는 위 세 가지 문제점을 해결하는 방법을 제안합니다.
- 도메인 gap
=> cartoon 도메인의 학습 데이터를 수집하여 파인튜닝합니다. - 압축된 잠재 공간(latent space) 사용함으로 디테일 손실
=> 디테일을 보완할 수 있는 dual-reference 3D 디코더를 제안합니다. - 사용자 제어의 어려움
=> 스케치 condition으로 비디오를 생성할 수 있는 방법을 제안합니다.
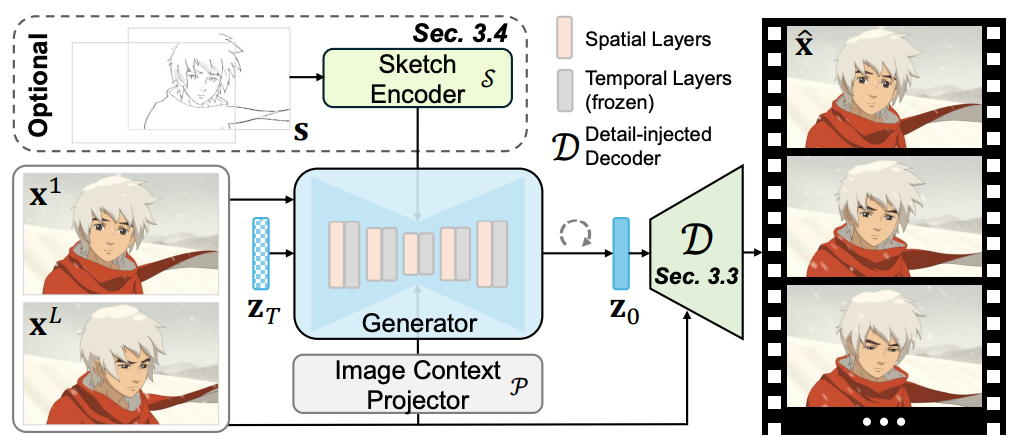
- 도메인 gap
ToonCrafter
- 애니메이션 도메인 파인튜닝 (Toon Rectification Learning)
- 디코더 개선 (Detail Injection and Propagation in Decoding)
- 스케치 조건 추가 (Sketch-based Controllable Generation)
Toon Rectification Learning
- 애니메이션 도메인 파인튜닝
- 데이터셋을 구축, 파인튜닝 기법을 제안
Cartoon Video Dataset Construction
- 학습 데이터셋은 270K 클립, 평가 데이터셋은 1K 클립을 수집
- 수집 & 필터링 과정
- raw 비디오 데이터 수집 (과정 공개 x)
- (사람) 해상도, 물체 기준으로 필터링 => 500h 비디오
- (모델) 정적인 비디오, 텍스트가 너무 많은 데이터 필터링
- (모델) 그림이 아닌 real 도메인 필터링
- (모델) 이미지 캡셔닝 모델로 비디오 설명하는 텍스트 생성
- (모델) 텍스트와 비디오 alignment 필터링
- 구축된 cartoon video 데이터셋은 공개 ❌
Rectification Learning
- DynamiCrafter 기반으로 모델을 파인튜닝
- 수집한 Cartoon video data로 일부 레이어만 파인튜닝
- 전체가 아닌 일부만 파인튜닝하는 이유는 파인튜닝하면서 기존의 능력을 잊어버리는 catastropic forgetting 방지하기 위함
- 멋진 말로 base 모델의 motion prior를 유지하면서 도메인 adaptation
- motion prior를 담당하는 temporal layer를 freezing
- 파인튜닝 모델 : Image-Context projector, Spatial Layers,
Temporal Layers

Detail Injection and Propagation Decoding
- 입력 이미지 정보를 디코더에 주입하여 디테일을 보완하는 디코더 제안
Dual reference based 3D deocder
- dual-reference : 첫 프레임, 마지막 프레임
- P3D : Pseudo-3D, temporal 정보 추가
- 베이스 모델의 디코더는 T2I의 단순 이미지 생성
- HAR(Hybrid Attention Residual Learning mechanism)
- : 이미지 feature
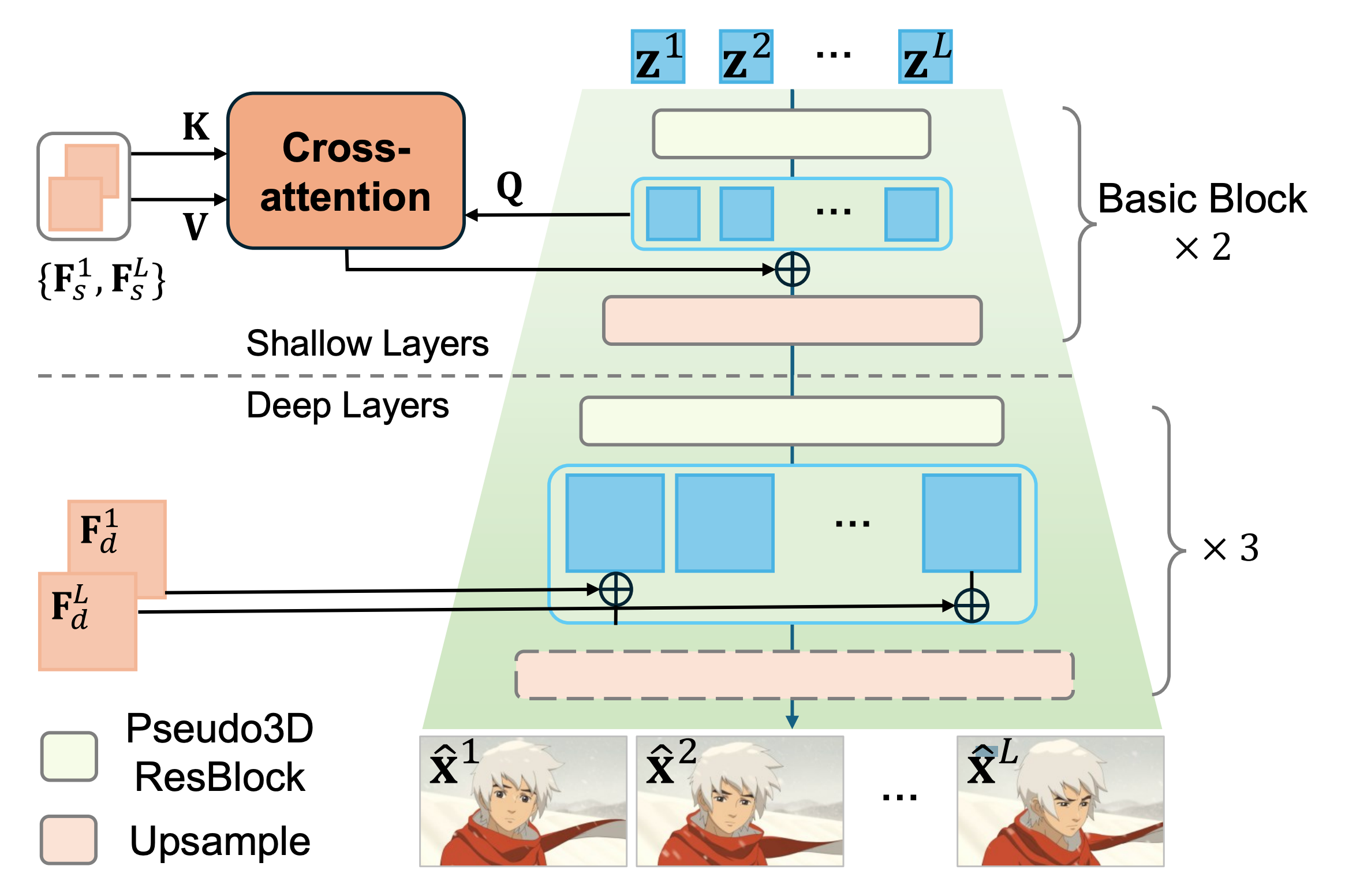
- : 이미지 feature
Sketch-based Controllable Generation
- 유저의 사용성을 높이기 위해 스케치 조건 추가
- ControlNet처럼 학습된 모델에 스케치 조건 모델 학습
- 스케치 조건 모델을 사용하지 않어도 됨
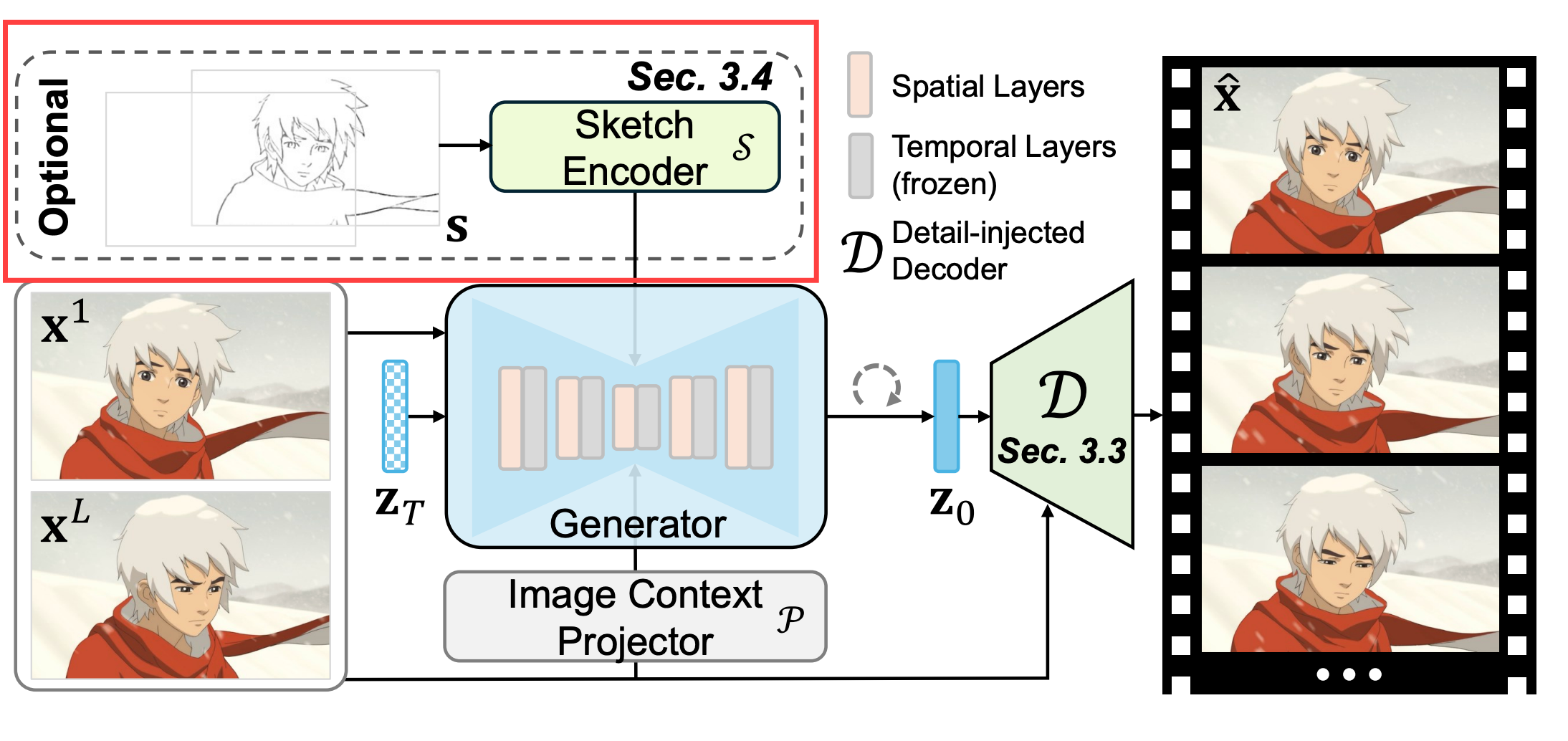
- 스케치 조건 모델을 사용하지 않어도 됨
- 스케치 조건 모델은 프레임 별 독립적으로 학습
- 모든 프레임마다 스케치 조건 없어도 됨 (sparse sketch ✅)
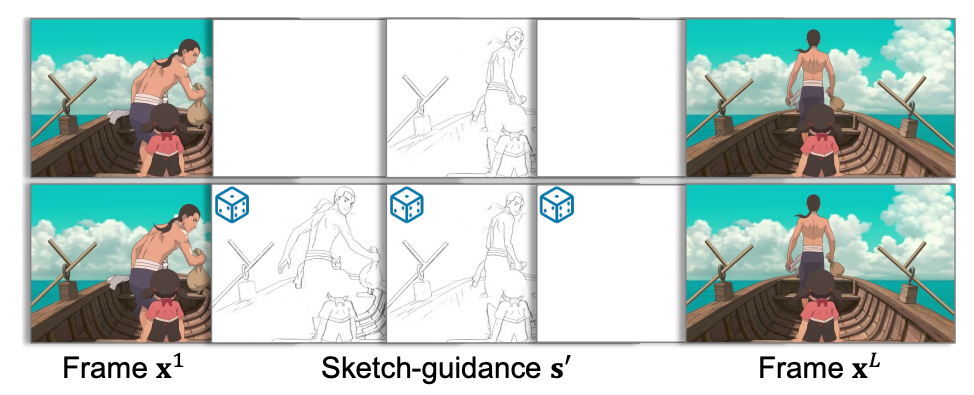
- 모든 프레임마다 스케치 조건 없어도 됨 (sparse sketch ✅)
Experiments
- DynamiCrafter의 512x320을 베이스 모델로 사용
- 학습 하이퍼파라미터
- 비디오 생성 모델 : 50K steps, lr=, batch size 32
- 디코더 : 60K steps, lr=, batch size 16
- 스케치 조건 모델: 50K steps, lr=, batch size 32
- (Reviewer's 💡) 정량적 결과는 생략하고 정성적 결과만 보겠습니다!
Application
- animation interpolation

- sktech interpoation

- colorization

Ablation study
Rectification Learning

1. base 모델 : 애니메이션 도메인 생성 x
2. 모든 레이어ICP + UNet(spatial+temporal) 파인튜닝 : 움직임이 덜 자연스러움
3. temporal 레이어 사용하지 않고 ICP + UNet 파인튜닝 : 움직임이 자연스럽지 않음
4. (Ours) temporal 레이어를 사용하되 학습시키지 않고 ICP + UNet spatial 파인튜닝 : 가장 애니메이션 도메인이면서, 움직임이 자연스러움
5. ICP만 파인튜닝 : 생성 퀄리티 낮음
Dual reference based 3D decoder

- 요소 설명
- P3D : temporal 정보 반영
- HAR : 첫프레임, 마지막 프레임 정보 사용
- 저자가 제안한 디코더가 디테일을 상당히 보완
Sketch guidance

- 요소 설명
- ZeroGate : frame-dependent sketch 조건 모델
- (Ours)FrameIn.Enc. : frame-independent sketch 조건 모델
- w/o sketch : 스케치 조건 사용하지 않음
- 스케치 조건을 사용하지 않으면 첫 프레임과 마지막 프레임과 유사한 interpolation만 가능
- ZeroGate는 스케치 조건이 없는 프레임을 잘 생성하지 못함
- 제안한 frame에 독립적으로 학습된 sketch 조건 모델이 활용도가 높음
Limitation
- 콘텐츠 잘 파악하지 못함, 텍스트 반영 잘 되지 않음
- (Reviewer's 💡) 데이터셋 텍스트 만들 때 이미지 캡셔닝 모델 써서 motion을 잘 표현했을지 의문...

- (Reviewer's 💡) 데이터셋 텍스트 만들 때 이미지 캡셔닝 모델 써서 motion을 잘 표현했을지 의문...
Reviewer's Comments 💡
- 파인튜닝을 위한 데이터 구축 과정을 세세하게 설명해서 좋음, but 데이터 공개하지 않아 아쉬움. 아마 저작권 문제 있지 않을까...?
- 디테일 뭉게지는 이슈를 기존에는 주로 Super Resolution으로 해결하는데, 이 논문에서는 태스크에 맞게 consistency를 더 잘 유지하면서 디테일을 개선하는 방법으로 디코더 구조를 제안하고 학습하는 게 좋아보임
- 실제 데모 테스트해봤을 때 텍스트 반영은 거의 잘 되지 않고, 학습할 때 프롬프트 개선하면 성능이 개선될 것이라 생각됨
