BLEU Score
제가 처음으로 소개해드릴 논문은 BLEU입니다. 저도 이번 발표를 준비하면서 처음 접한 내용인데, 개념이 크게 어렵지도 않고 흥미로워서 개인적으로 즐겁게 준비했던 것 같아요 :)
해당 논문의 전체 제목은 BLEU : a Method for Automatic Evaluation of Machine Translation으로, 기계 번역의 성능 평가 지표라고 보시면 될 것 같습니다. 그럼 지금부터 BLEU Score에 대한 내용을 소개해드리도록 하겠습니다.
1. Introduction
우선 설명 중간에 표현 상의 편의로 MT, HT라고 쓰는 일이 종종 있을텐데 다음과 같이 받아들여주시면 되겠습니다.
MT : 기계 번역 (machine translation)
HT : 사람이 진행한 번역 (human traslation)
사실 논문에서는 MT만 줄임말로 사용했는데 편의상 인간번역도 HT로 작성하도록 하겠습니다
우선 기계 번역의 성능 평가는 적절성(adequacy), 충실성(fidelity), 유창성(fluency)에 중점을 두고 있습니다. 그러나 사람이 진행하는 MT evaluation은 비용과 시간이 많이 들기 때문에, 빠르고 언어에 상관없으며 human evaluation에 상응하는 평가 방법이 필요하다는 것을 바탕으로 하여 BLEU가 등장했습니다.
이 때의 견해로는 사람이 번역한 것과 유사할수록 더 성능이 좋은 기계번역이라고 봅니다. 따라서 기계 번역의 quality를 판단하려면 하나 이상의 reference human translations와의 거리(근접성)을 측정할 수 있는 수치적 측도가 필요한데, 이를 위해서는 두 가지가 요구됩니다.
- 수치적인 ‘translation closeness’ 측도
- 퀄리티 좋은 human reference translation corpus
2.The Baseline BLEU Metric
그럼 앞에서 설명했듯 HT와 가까울수록 MT에게 좋은 점수를 주는 척도를 만든다는 것을 기본 가정으로 BLEU의 baseline을 생각해보도록 하겠습니다. 가장 간단한 방법으로 얼마나 reference (good HT)와 비슷한지를 측정하는 방법이 있을 수 있습니다. 예시를 통해 설명해보도록 하겠습니다.
Example 1.
Candidate 1 : It is a guide to action which ensures that the military always obeys the commands of the party.
Candidate 2 : It is to insure the troops forever hearing the activity guidebook that party direct.
두 Candidate 문장은 쉽게 평가 성능을 확인하고 싶은 MT 문장들이라고 보면 됩니다. 두 문장 모두 같은 내용을 담고 있지만 문장의 질적 측면에서 Candidate 1이 더 명확한 문장이라고 합니다. 사람이 번역한 reference와의 비교를 통해 더 확실히 알아볼 수 있습니다.
Example 1.
Reference 1 : It is a guide to action that ensures that the military will forever heed Party commands.
Reference 2 : It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference 3 : It is the practical guide for the army always to heed the directions of the party.
위의 Reference 문장들은 사람이 직접 번역한, 소위 말하자면 '번역의 질이 좋은 문장들'이라고 보시면 되겠습니다. Reference들과 비교하면 Candidate 1은 세 reference들과 겹치는 단어와 구절이 많은데 비해 Candidate 2는 그렇지 않음을 확인할 수 있습니다.
프로그램은 이처럼 n-gram matches를 비교해서 Candidate 1에게 더 높은 rank를 부여하는데, BLEU의 기본적인 프로그래밍 태스크도 이 작업을 베이스로 합니다. Candidate의 n-gram을 Reference의 n-gram과 비교하고, 일치하는것의 수를 카운트하면 됩니다. 즉, 다음과 같이 계산할 수 있습니다.
따라서, Example 1.에서 Candidate 1과 2의 Standard Unigram Precision은 각각 17/18, 8/14입니다.
이를 Standard n-gram precision이라고 부르겠습니다. 그러나 이 계산법에서는 다음과 같은 문제점이 발생합니다.
2.1 Modified n-gram precision
Example 2.
Candidate : the the the the the the the.
Reference 1: The cat is on the mat.
Reference 2: There is a cat on the mat.
해당 태스크를 Example 2에 적용하면 문제가 발생합니다. Candidate translation은 엉망인데 unigram match를 헤아려보면 Candidate 내의 유니그램(the)이 모두 Reference에 속하게 되어 Candidate가 완벽한 정밀도를 가지게 된다는 결론이 나오게 됩니다. Candidate의 단어가 중복되어 등장했기 때문인데, 이를 방지하기 위해 match를 셀 때 Reference의 단어는 일치하는 Candidate 단어가 식별된 후에 소진된다는 아이디어로의 확장이 자연스럽습니다. 이것이 modified unigram precision입니다.
이 modified unigram precision의 개념을 구현하기 위해 clipping이라는 방법을 사용하는데, 그 수식은 다음과 같습니다.
즉, 일치하는 unigram을 카운트할때, 해당 unigram이 하나의 Reference에 존재하는 최대 카운트를 초과하면 더 이상 세지 않는다고 보면 됩니다.
이 클리핑 개념을 바탕으로 Reference에 대한 Candidate의 modified unigram precision을 계산하는 방법은 다음과 같습니다.
- Candidate의 단어가 각각의 Reference에 몇 개 등장하는지 센다.
- 최대 Reference 카운트에 맞춰 Candidate의 unigram들을 clipping한다.
- clipping한 값들을 모두 더하고 Candidate의 unigram의 총 카운트로 나눈다.
따라서 Example 2에서의 modified unigram precision은 2/7입니다.
이 개념을 그대로 n-gram으로 확장시킨 것이 modified n-gram precision입니다. Example 2에 대한 modified bigram precision의 결과는 0이 됨을 확인할 수 있습니다.
그렇다면 이 modified n-gram precision으로 HT와 MT의 성능을 구분할 수 있는지 확인해보도록 하겠습니다.
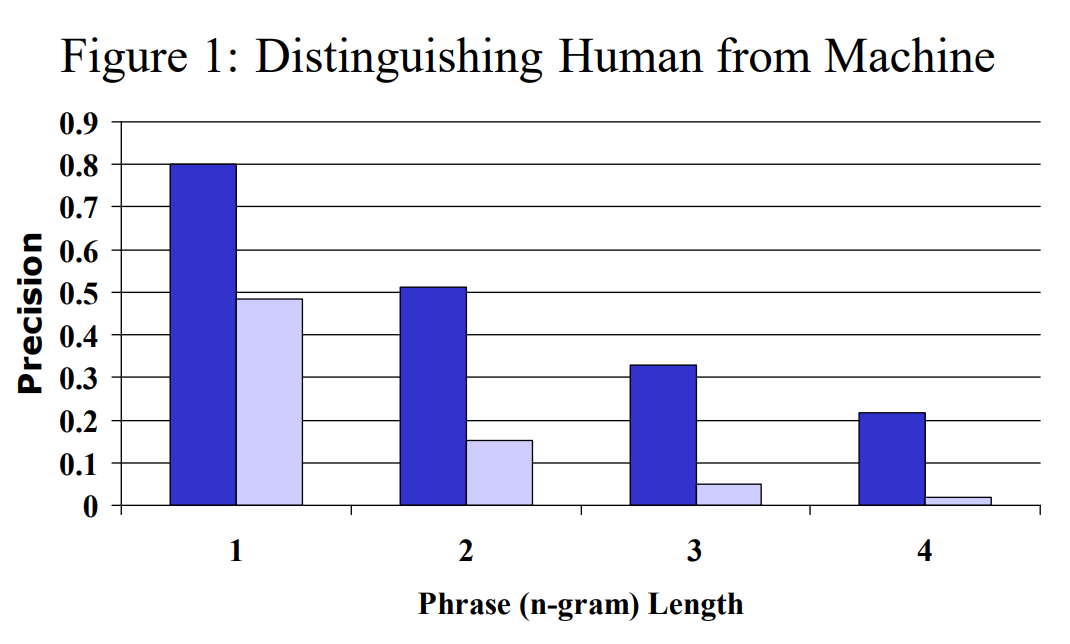
이 그래프는 4개의 reference translation과 127개의 source sentence들로 계산한 (good)human translation과 (poor)machine translation의 modified n-gram precision 평균을 나타낸 것입니다. 짙은 파란색이 HT, 연한 파란색이 MT의 precision을 의미합니다. 모든 n-gram precision에서 그 차이가 명확하게 드러나기 때문에 특정 하나의 n-gram precision만 사용해도 bad translation과 good translation을 잘 구분할 수 있음을 알 수 있습니다.
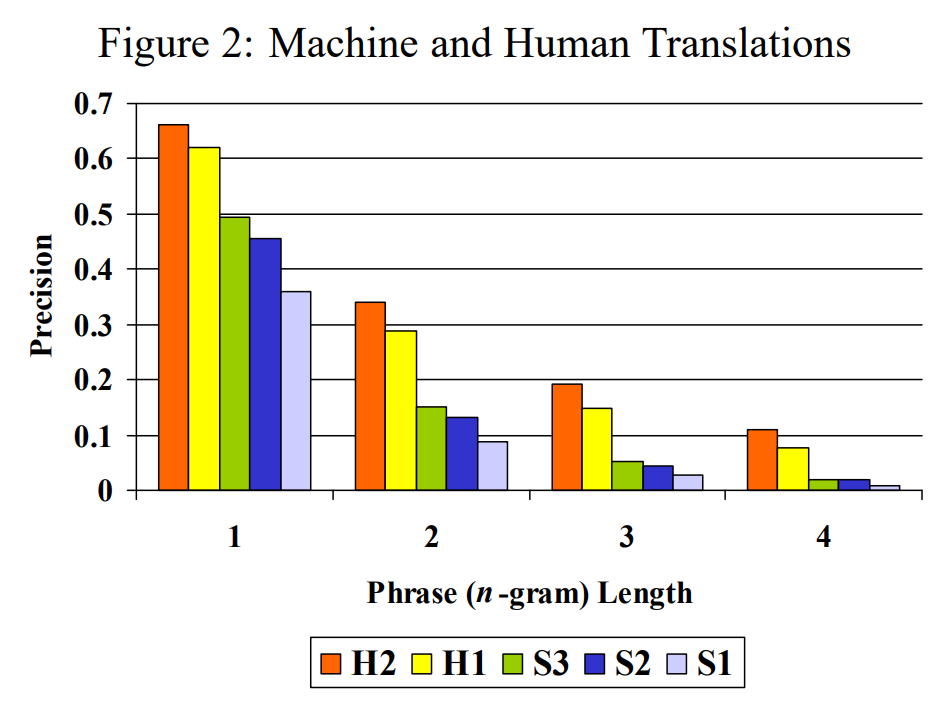
그런데 사실 성능 평가는 이렇게 누가 봐도 확연한 차이를 띄는걸 구분하기보다는 퀄리티가 비슷한 번역문들, 혹은 human translation 사이의 성능을 구분할 수 있어야 유용합니다.
이를 위해 원어(중국어)와 대상어(영어)에 모두 능통하지 않은 사람에 의해 HT를 얻고(H1), 비교를 위해 영어 원어민에게도 HT를 얻었습니다.(H2) 또한 세 가지 시스템에 의한 기계 번역도 얻었습니다. (S1, S2, S3) modified n-gram precision을 계산해 나온 결과를 보면 H2 > H1 > S3 > S2 > S1 순으로 퀄리티가 좋다는 결론이 나왔고, 이는 이후에 사람들이 직접 번역문을 평가한 결과와 같은 순서였습니다.
그런데 n-gram size에 따라 precision이 다르게 나오는데 이를 통합해서 어떻게 표현할 수 있을까요? n-gram size에 따라 precision이 급수적으로 변화하기 때문에 BLEU에서는 가중치를 부여한 로그 기하평균을 이용해서 modified n-gram precisions를 통합합니다. 따라서 지금까지의 BLEU 식을 종합하면 다음과 같습니다.
p_n : modified n-gram precision
N : n-gram에서 사용할 n의 최대 숫자. N이 4라면 p1,p2,p3,p4를 사용한다.
w_n : 가중치
2.2 Sentence length
Example 3.
Candidate: of the
Reference 1: It is a guide to action that ensures that the military will forever heed Party commands.
Reference 2 : It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference 3: It is the practical guide for the army always to heed the directions of the party.
이제 BLEU 식이 거의 완성되었는데, 아직 한가지 약점이 존재합니다. 해당 예제에서, Candidate 문장의 길이가 너무 짧기 때문에 modified unigram precision과 modified bigram precision은 각각 2/2, 1/1로 1이 되게 됩니다. 따라서 너무 짧은 Candidate에 대해서는 페널티를 주게 되는데, 이를 Brevity Penalty라고 합니다.
Brevity Penalty는 앞서 세운 BLEU식에 페널티 BP를 곱해서 사용합니다. 따라서 최종 BLEU식은 다음과 같이 도출할 수 있게 됩니다.

3. Human Evaluation
BLEU의 목적은 빠르고 자동화되면서도, 사람이 평가하는 것과 유사한 결과를 내는 평가 점수 척도를 만드는 것이었습니다. 따라서 BLEU를 통해 도출된 결과가 사람 평가의 결과와 유사한지 다음의 그래프들을 통해 비교해보며 BLEU 논문 리뷰를 마치도록 하겠습니다.
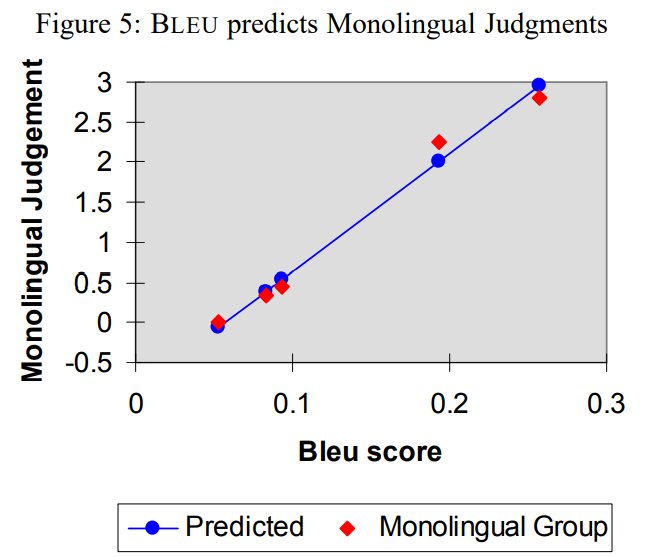

4. 참고
https://wikidocs.net/31695 : 친절한 설명 + 간단한 파이썬 구현
https://www.nltk.org/_modules/nltk/translate/bleu_score.html : bleu를 계산할 수 있는 nltk 패키지
https://misconstructed.tistory.com/53?category=878789
