
아스키코드, 유니코드 등은 컴퓨터가 이해할 수 있는 0과 1로 다양한 문자를 표현하는 방법이다. 이에 대해 알아보자.
문자 집합과 인코딩
- 컴퓨터가 인식하고 표현할 수 있는 문자 모음을 문자집합 이라고 한다.
- 문자를 그대로 컴퓨터가 읽을 수 없기 때문에 문자를 0과 1로 변환하는 과정을 문자 인코딩 이라고 한다.
- 인코딩의 반대, 0과 1로 이루어진 문자 코드를 문자로 변환하는 과정을 문자 디코딩이라고 한다.
아스키코드
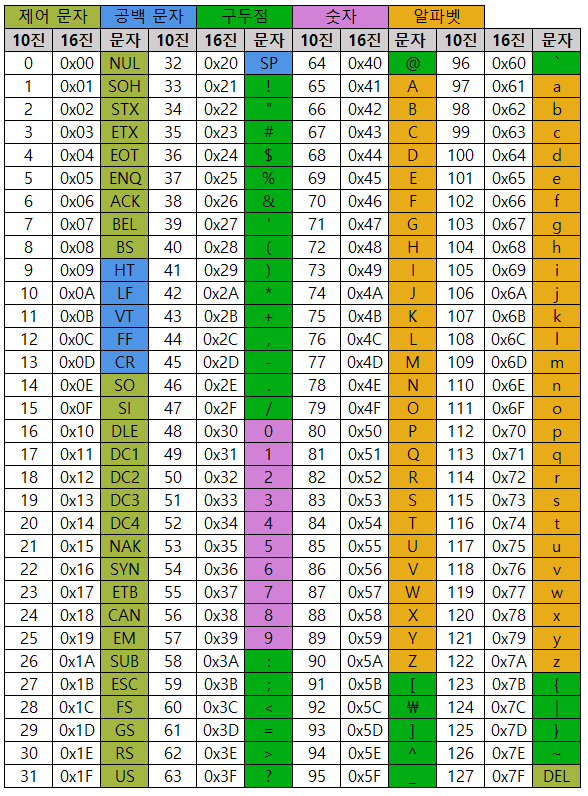
- 아스키는 초창기 문자 집합 중 하나로, 영어 알파벳과 아라비아 숫자, 그리고 일부 특수 무자를 포함한다 아스키 문자 집합에 속한 문자를 아스키 문자라고 하며 각각 7비트로 표현되는데, 7비트로 표현할 수 있는 정보의 가짓수는 27이며, 총 128개의 문자를 표현할 수 있다.
- 아래의 표를 보면 알 수 있듯, 아스키 문자들은 0부터 127까지 총 128개의 숫자 중 하나의 고유한 수에 일대일로 대응된다. 아스키 문자에 대응된 고유한 수를 아스키코드라고 한다.
EUC-KR
- 한글은 각 음절 하나하나가 초성, 중성, 종성의 집합으로 이루어져있다. 그래서 한글 인코딩에는 두 가지 방식, 완성형(한글 완성형 인코딩)과 조합형(한글 조합형 인코딩)이 존재한다.
- 완성형 인코딩은 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식이다.
ex. '가' = 1, '나' = 2, '다' = 3 - 조합형 인코딩은 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열을 할당하여 그것들의 조합을 ㅗ하나의 글자 코드를 완성하는 인코딩 방식이다.
ex. 강 = ㄱ + ㅏ + ㅇ = (예시) 0010 + 0011 + 001 0011
유니코드와 UTF-8
- 모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식으로 등장한 것이 유니코드 문자집합이다.
- UTF-8, UTF-16, UTF-32는 유니코드 문자의 인코딩 방식이다.
- 유니코드는 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합이며, 문자 인코딩 세계에서 매우 중요한 역할을 한다.
- UTF-8은 통상 1바이트부터 4바이트까지 인코딩 결과를 만들어낸다.
- UTF-8로 인코딩한 결과가 몇 바이트가 될지는 유니코드 문자에 부여된 값의 범위에 다라 결정된다.
-
유니코드 문자에 부여된 값의 범위가 0부터 007F(16)까지는 1바이트로 표현
-
유니코드 문자에 부여된 값의 범위가 0080(16)부터 07FF까지는 2바이트로 표현
-
유니코드 문자에 부여된 값의 범위가 0800(16)부터 FFFF(16)까지는 3바이트로 표현
-
유니코드 문자에 부여된 값의 범위가 10000(16)부터 10FFFF(16)까지는 4바이트로 표현된다.
ex. 한글 = 한(=D55C(16)) + 글(=AE00(16)), 두 글자 모두 0800(16)~FFFF(16)사이에 있으므로 3바이트로 표현될 것이다.
-

꾸준함의 가치를 믿는 개발자