
HTTP 완벽가이드 - 10장. HTTP/2.0
🎨 10.1 HTTP/2.0의 등장 배경
- HTTP/1.1의 한계
- 텍스트 기반 프로토콜로, 요청-응답 구조에 병목이 발생.
- 하나의 TCP 연결에서 하나씩 요청 처리 → 지연(latency) 증가.
- 커넥션을 여러 개 만들어도 브라우저는 개수 제한이 있어 근본적 해결책이 아니었음.
- 성능 개선의 필요성
- 웹페이지 성능 병목 현상을 해결하고자 SPDY와 같은 실험적 프로토콜들이 등장.
- SPDY는 구글이 제안한 프로토콜로, 헤더 압축, 멀티플렉싱, 우선순위, 서버 푸시 등의 기능 포함.
- HTTP/2.0의 탄생
- 2012년, IETF의 HTTP 작업 그룹은 SPDY를 기반으로 HTTP/2.0을 설계하기로 결정.
- 2013년부터 초안이 나오기 시작했고, SPDY의 구조를 거의 그대로 가져옴.
😎 쉽게 이해하기
- HTTP/1.1은 요청과 응답을 한 줄로만 처리했었다. HTTP/1.1은 텍스트 기반이라 사람이 읽기 쉬웠지만, 컴퓨터 입장에서는 느리고 비효율적이었다. → 병렬로 데이터를 보내지 못하고 순차적으로만 처리됨
- 하나의 TCP 연결에서 요청 하나만 처리하다 보니, 많은 이미지나 CSS같은 웹 요소가 있는 웹 사이트는 로딩이 느렸다.
- 브라우저는 동시에 열 수 있는 TCP 연결 수에 제한이 있었다.(보통 6개) 그러다보니 여러 연결을 열어서 처리하는 방식에 한계가 있었다.
- IETF(인터넷 표준을 만드는 조직)에서 SPDY를 바탕으로 HTTP2.0 설계 시작했고, 2012년에 결정되었으며 2013년부터 초안 문서가 나오기 시작했다.
- HTTP/2.0은 SPDY의 장점을 가져오며 표준화된 버전이다.
1. 현재까지 HTTP 버전 흐름
| 버전 | 특징 |
|---|---|
| HTTP/1.0 | 1996년 등장, 요청 하나마다 TCP 연결 새로 만듦 (매우 비효율적) |
| HTTP/1.1 | 1997년 등장, Keep-Alive 도입 → 연결 재사용 가능 |
| HTTP/2.0 | 2015년 등장, 바이너리, 멀티플렉싱, 헤더 압축, 서버 푸시 |
| HTTP/3.0 | 가장 최신 정식 버전 (2022년 RFC 정식 채택), QUIC 기반 |
2. HTTP/3 채택 비율 및 주요 서비스
- 전체 웹사이트 중 약 34%가 HTTP/3를 사용 중이며, HTTP/2 포함해 보면 총 66%가 HTTP/2 또는 HTTP/3를 사용하고 있다.
- HTTP/3를 사용하는 대표 사이트로는 Google, Facebook, YouTube, Instagram, Cloudflare, LinkedIn, Amazon, Bing, Pinterest 등이 존재한다.
3. 한국 서비스 네이버 & 카카오의 HTTP 버전
- 네이버와 카카오는 현재 HTTP/3가 아닌 HTTP/2 기반으로 운영 중인 것으로 알려져 있음.
- HTTP/3 도입 여부에 대한 공식 발표나 기술 문서 등은 확인되지 않음.
- 특히 네이버는 국내 트래픽 중심 구조와 자체 CDN 및 전용 인프라를 갖추고 있어, HTTP/2만으로도 충분한 성능 확보가 가능한 구조임.
- 글로벌 서비스와 달리, 지리적으로 사용자 밀집도가 높고 통신 환경도 안정적이기 때문에 TCP 기반 HTTP/2에서도 병목 없이 빠른 전송이 가능함.
- HTTP/3는 QUIC 기반으로 연결 지연을 줄이고 중간 손실 복원성을 높이는 장점이 있지만, 이는 주로 글로벌 트래픽이나 모바일 네트워크에서 효과가 크기 때문에 네이버처럼 국내 중심의 안정적인 네트워크 환경에서는 체감 성능 차이가 크지 않을 수 있음.
- 따라서 HTTP/3는 필수 도입 요소가 아니며, HTTP/2와 자체 인프라만으로도 충분하다는 업계 분석이 존재함.
- 현재로서는 HTTP/3 도입보다 기존 인프라의 효율적 운영과 안정성 확보에 초점을 두고 있는 것으로 해석됨.
4. 왜 일부 기업들만 HTTP/3 도입 중일까?
- 브라우저와 서버 모두 HTTP/3(QUIC)을 지원해야 사용할 수 있다.
- 대부분의 최신 브라우저는 이미 95% 이상 HTTP/3를 지원하고 있다. (예: Chrome, Firefox, Safari 등)
- Cloudflare, Fastly 등 주요 CDN은 HTTP/3를 기본으로 활성화하거나 쉽게 설정할 수 있도록 제공한다.
5. 그럼 HTTP/3.0은 뭐가 다를까?
1. TCP가 아니라 UDP 기반 프로토콜인 QUIC 사용
- HTTP/1, 2는 전부 TCP 위에서 돌아갔는데, HTTP/3은 TCP 대신 UDP 위에서 돌아가는 QUIC이라는 전송 프로토콜을 사용한다.
2. 왜 QUIC을 쓸까?
- TCP는 느리다. 연결 설정에 3단계(handshake), TLS 암호화에 또 많은 시간이 소요된다.
- 그러나 QUIC은 TLS와 연결 설정을 한 번에 처리하기 때문에 연결 속도 훨씬 빠르다. 중간 장애에도 회복 빠른 장점이 있다.
6. 참고 페이지
Usage Statistics of HTTP/3 for Websites, August 2025
🎨 10.2 HTTP/2.0 개요
- 바이너리 프로토콜
- HTTP/2.0은 텍스트 기반이 아닌 바이너리 프레이밍 계층을 사용함.
- 모든 메시지는 프레임 단위로 나뉘어 전송되고, 프레임은 다시 스트림에 속함.
- 핵심 구조
-
하나의 TCP 연결 안에서 다수의 스트림을 사용해 동시에 여러 요청과 응답을 처리함.
-
이 덕분에 병렬성, 성능, 효율성, 지연 시간 등이 크게 개선됨.
-
😎 쉽게 이해하기
- HTTP/2.0은 텍스트 → 바이너리라는 완전히 새로운 구조를 도입했다.
- 바이너리 프로토콜이란?
- 사람이 읽기에는 어렵지만, 컴퓨터가 훨씬 빠르게 읽고 처리할 수 있는 형식
- HTTP/2.0에서는 “프레임(Frame)이라는 단위로 만들어 전송한다.
- 예시)
- HTTP/1.1에서는 전체 메시지를 텍스트로 주고 받았다면, HTTP/2.0에서는 그 메시지를 쪼개서 작은 조각들(프레임)로 바이너리로 보낸다.
- 프레임(Frame)과 스트림(Stream)
- 프레임은 HTTP/2.0에서 사용하는 가장 작은 데이터 단위를 뜻한다.
- 각 프레임은 무슨 종류의 데이터인지, 어느 요청에 속하는지 등의 정보를 담고 있다.
- 프레임들은 스트림(Stream)이라는 논리적 연결 안에 묶여서 움직인다.
- 여러 스트림을 하나의 TCP 연결 안에서 동시에 처리할 수 있게 된다
→ 멀티플렉싱(Multiplexing)
- 바이너리 구조로 바꿨기 때문에 멀티플렉싱이 가능해진 것이다!
-
바이너리 + 프레임 + 스트림 → 병렬 전송 가능 → 멀티플렉싱
-
바이너리 프로토콜이란?
1. 텍스트 프로토콜 vs 바이너리 프로토콜
| 항목 | 텍스트 기반 (HTTP/1.1) | 바이너리 기반 (HTTP/2.0) |
|---|---|---|
| 구조 | 사람이 읽을 수 있음 (GET /index.html) | 기계가 읽기 쉬움 (01101101...) |
| 처리 속도 | 느림 (해석 필요) | 빠름 (기계가 바로 처리 가능) |
| 유연성 | 형식 오류에 민감 | 포맷이 정해져 있어 안전함 |
| 메시지 단위 | 한 줄씩 구분 | 프레임 단위로 분할 |
2. 예시 비교
HTTP/1.1 (텍스트 기반)
GET /hello HTTP/1.1
Host: example.com
- 이건 사람이 읽기엔 쉬운데, 서버는 이걸 읽고 문자열 파싱(parse)해서 "GET", "Host" 등을 따로 인식해야 함.
HTTP/2.0 (바이너리 기반)
00001001 01000000 ...- 위 요청은 바이너리로 정해진 포맷의 프레임으로 변환돼서 전송된다.
- 이진수 기반이라 사람이 보기엔 알아볼 수 없지만, 서버는 정확히 어느 부분이 요청이고, 어느 부분이 헤더인지 구조적으로 빠르게 인식 가능하다.
- 즉, 처리 속도와 효율성은 텍스트보다 바이너리가 훨씬 우수함.
🎨 10.3 HTTP/1.1과의 주요 차이점
📌 10.3.1 프레임 구조
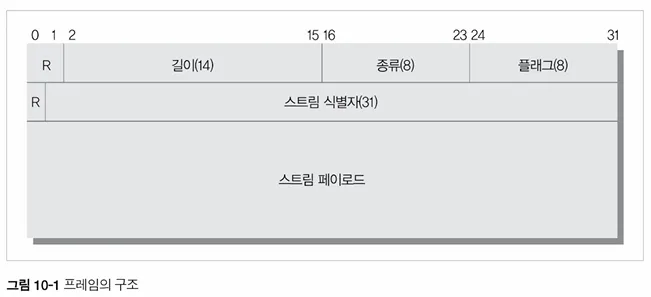
- 모든 메시지는 프레임에 담아 전송.
- 프레임은 헤더(8바이트) + 페이로드로 구성.
- 총 10가지 이상의 프레임 타입 존재:
DATA,HEADERS,PRIORITY,RST_STREAM,SETTINGS,PUSH_PROMISE,PING,GOAWAY,WINDOW_UPDATE,CONTINUATION.
📌 10.3.2 스트림과 멀티플렉싱
- HTTP/2.0은 하나의 TCP 연결 내에서 여러 스트림을 통해 동시에 요청 처리 가능.
- 각 스트림은 고유 식별자(31비트)를 가지며, 양방향 독립적으로 통신.
- 멀티플렉싱 덕분에 헤드 오브 라인 블로킹(Head-of-line blocking) 문제를 완화.
📌 10.3.3 헤더 압축 (HPACK)
- HTTP/1.1은 헤더를 매 요청마다 전송해서 비효율적이고 느렸음.
- HTTP/2.0은 HPACK이라는 전용 압축 방식 도입.
- 정적 테이블과 동적 테이블을 활용하여 반복되는 헤더를 줄임.
- 압축 상태를 공유하는 context 기반으로 작동.
- 압축 오류 발생 시
COMPRESSION_ERROR반환.
📌 10.3.4 서버 푸시 (Server Push)
- 클라이언트가 요청하지 않은 리소스를 서버가 미리 전송 가능.
PUSH_PROMISE프레임을 사용하여 예상되는 리소스를 사전 푸시.- 단, 남용 시 오히려 성능 저하나 리소스 낭비 가능성 존재.
😎 쉽게 이해하기
1. 프레임 구조
- 이 구조 덕분에, 데이터 조각 하나하나를 정확히 구분하고 통신할 수 있음
- 프레임 단위 전송 구조 덕분에 HTTP/2는 구조적으로 유연하고 병렬 처리가 가능하다.
- 프레임 타입 예시
-
DATA: 실제 요청/응답 본문 데이터 -
HEADERS: 요청/응답 헤더 -
SETTINGS: 연결 설정 정보 -
PING: 연결 확인 -
PUSH_PROMISE: 서버 푸시용필드 설명 길이 (14비트) 페이로드 길이 종류 (8비트) 프레임 타입 (예: DATA, HEADERS 등) 플래그 (8비트) 해당 프레임의 속성 지정 스트림 식별자 (31비트) 이 프레임이 어떤 스트림에 속하는지 표시 페이로드 실제 데이터 (헤더/본문 등)
-
2. HTTP/1.1의 문제와 HTTP/2.0의 해결책
- HTTP/1.1의 경우, 헤더는 매번 반복돼서 전송됐다. (예:
User-Agent,Accept,Host등) - HTTP/2.0은 HPACK이라는 압축 알고리즘 사용한다.
- 정적 테이블: 표준 헤더를 미리 정의
- 동적 테이블: 세션 중에 자주 쓰는 헤더를 저장해서 재사용
- 상태 정보를 공유하는 압축 context 기반
3. HTTP/2.0의 장점
- 데이터 크기 줄음 → 전송 속도 향상
- 반복 헤더 제거 → 리소스 절감
- 오류 발생 시
COMPRESSION_ERROR발생
4. 오류 발생 시 COMPRESSION_ERROR 발생은 왜 장점일까?
- HTTP/2.0은 헤더 압축을 위해 HPACK이라는 알고리즘을 사용한다.
- HPACK은 압축 효율을 높이기 위해 서버와 클라이언트가 공유하는 압축 상태(context)를 유지한다.
- 하지만 네트워크가 끊기거나, 클라이언트/서버 중 하나가 압축 테이블 상태가 어긋났을 때 문제가 생길 수 있다. → 이 때
COMPRESSION_ERROR이 필요! - 명확하게 “압축 오류”라고 알려주고 안전하게 동작을 중단할 수 있게 해주는 구조이기 때문이다.
COMPRESSION_ERROR덕분에 오류 상황을 명확하게 구분- 클라이언트나 서버가 즉시 연결을 종료하거나, 재시도할 수 있다.
- 디버깅이나 보안 분석 시 빠르게 추적 가능
⇒ 의미 있는 실패를 주기 때문에 신뢰성과 보안 측면에서 아주 큰 장점으로 작용한다.
5. HTTP/1.1 vs HTTP/2: 서버 푸시(Server Push)의 차이
- HTTP/1.1: 클라이언트 주도(Client-Initiated Model)
- 클라이언트가 먼저 요청해야만 서버가 응답할 수 있다.
- 서버는 절대 먼저 데이터를 보낼 수 없다.
- HTTP/2: 서버 푸시(Server Push) 기능 도입
- 서버가 먼저 리소스를 ‘예상해서’ 미리 전송할 수 있다.
- 클라이언트가
index.html을 요청하면, 서버는 이 HTML은style.css랑app.js도 필요하겠네! → 클라이언트가 요청하지 않아도 자동으로 CSS와 JS를 미리 보내는 구조
- 어떻게 가능할까?
PUSH_PROMISE프레임을 사용해서 예고한 뒤 전송하는 구조
- 표로 보기
항목 HTTP/1.1 HTTP/2 요청 흐름 클라이언트가 먼저 요청해야 응답 가능 서버가 클라이언트보다 먼저 응답 가능 서버 푸시 불가능 가능 ( PUSH_PROMISE)전송 방식 요청 1 → 응답 1 요청 1 → 응답 1 + 푸시 리소스 다수 장점 안정적이나 비효율적 병렬 전송, 리소스 예측 가능 단점 느림 푸시 남용 시 오히려 캐시 충돌이나 낭비 발생 가능
6. 왜 "남용 시 문제가 될 수 있다"고 할까?
- 이미 브라우저 캐시에 있는 리소스를 또 푸시하면? → 네트워크 낭비, 시간 낭비
- 클라이언트가 원하지 않는 리소스를 보내면? → 트래픽과 처리 리소스 낭비
- 그래서 HTTP/3에서는 서버 푸시 기능을 오히려 제거하는 방향으로 논의됨
🎨 10.4 알려진 보안 이슈
📌 10.4.1 중계자 캡슐화 공격 (Intermediary Encapsulation Attacks)
- HTTP/2.0과 HTTP/1.1이 혼용될 때, 메시지 변환 과정에서 보안 취약점 발생 가능.
- 중간 프록시나 게이트웨이에서 헤더를 잘못 해석해 오류 또는 정보 유출 가능성 있음.
📌 10.4.2 장기 커넥션 유지로 인한 개인정보 노출
- HTTP/2.0은 연결을 오래 유지함으로써, 쿠키나 사용자 정보 노출 위험이 증가할 수 있음.
- 연결을 지속하면서 브라우저 사용자 식별 가능성이 존재.
😎 쉽게 이해하기
1. 중계자 캡슐화 공격 (Intermediary Encapsulation Attacks)의 중계자란?
- 우리가 웹 요청을 보낼 때, 사이 사이 다양한 중간 장치가 존재한다.
- 프록시 서버, 게이트웨이, 로드 밸런스 등
- 이 중간 장치들은 보통 HTTP/1.1 기반으로 만들어졌다.
2. 그래서 뭐가 문제일까?
- 클라이언트와 서버는 HTTP/2.0로 통신하고 있는데 중간 장비가 HTTP/1.1로 메시지를 해석할 가능성 → 잘못된 요청 전달, 의도치 않은 헤더 노출, 악성 요청이 우회되어 전달될 우려가 있음 → 이것을 캡슐화 오류 라고 부른다.
3. 장기 커넥션 유지로 인한 개인정보 노출과 HTTP/2.0
- HTTP/1.1은 보통 요청 → 응답 → 연결 끊음의 구조로 오래 연결을 유지하지 않는다.
- HTTP/2.0은 TCP 연결을 아주 오래 유지한다. 하나의 연결로 여러 요청을 처리하기 때문이다.
- 연결을 오래 유지하기 때문에 같은 사용자라는 정보가 계속 남아있을 수 있다.
- 서버나 중간자(통신사, 공용 와이파이 등)입장에서는 쿠키, IP, TLS세션 등과 조합되면 사용자 추적 가능성이 증가하게 된다.
- 공격자가 중간에서 암호화는 풀지 못하더라도, 같은 연결을 10분째 쓰는 사용자가 누구인지, 패턴이나 메타데이터(길이, 주기)만 보고도 추론이 가능하기 때문이다.
- HTTP/2.0은 성능이 뛰어나지만, 이전 버전과 혼용되는 환경이나 장시간 연결을 유지하는 구조 때문에 의도치않은 보안 취약점이 발생할 수 있다.
4. HTTP/3.0 버전은 달라졌을까?
- HTTP/3.0은 전송 계층만 TCP → QUIC으로 바뀌었지, HTTP 레벨 구조는 HTTP/2.0와 거의 동일하다.
- 스트림 구조 존재 / 연결 유지 시간 김 / 멀티플렉싱 방식 동일
- 그러므로 장기 연결을 통해 사용자 식별 가능 → 개인 정보 노출의 문제는 여전히 유효하다.
- 그러나, HTTP/3.0은 완화 장치가 존재한다.
- QUIC에서는 IP가 바뀌어도 연결 유지가 가능하도록 설계되어 있어 사용자의 연결 안정성은 높이고, 추적 가능성은 줄이려고 하기 때문이다.
- TCP에서는 IP = 연결 식별자였기 때문에 IP가 바뀌면 사용자가 바뀌었다 생각하거나 역으로 추적에 사용 가능했으나, QUIC에서는 IP 대신 연결 ID로 추적하기 때문에 추적당할 가능성을 줄이고 익명성을 높일 수 있다.
- 서버 입장에서는 IP가 바뀌어도 연결 유지가 가능하기 때문에 안정적이다.
- 공격자(중간자)는 IP를 보고 다른 연결로 착각할 수 있으며, 연결 ID는 암호화되어 외부에 노출되지 않는다.
- 연결 ID는 바꿀 수 있으므로 클라이언트가 원할 때 ID를 재생성(rekeying)해서 더 이상 예전 연결과의 연관성을 추적할 수 없게 할 수 있다.
- 표로 보기
항목 HTTP/2 HTTP/3 전송 방식 TCP QUIC (UDP 기반) 커넥션 재설정 불완전 (TCP는 IP+Port 기준) QUIC은 연결 ID(Connection ID)로 재식별 허용 주소 노출 동일 IP+포트 → 식별 위험 연결 ID 재할당 가능 → IP 바뀌어도 추적 방지
🎨 10.5 참고 문서
- HTTP/2.0 공식 스펙: http://http2.github.io/http2-spec/
- 헤더 압축 스펙: https://tools.ietf.org/html/draft-ietf-httpbis-header-compression-04

꾸준함의 가치를 믿는 개발자