자연어 데이터의 특징
테이블 데이터셋의 경우, 각각의 데이터 샘플들이 구성하고 있는 features가 "독립적"이다.
feature들이 독립적이지 않은 케이스는 "이미지"가 있는데
이미지를 구성하는 각 픽셀들은 하나만 가지고도 의미를 가지는 게 아니다.
픽셀들은 다 연관되어 있다.
그리고 translation invariance를 가지고 있다. ->이미지 안에서 물건의 위치가 변해도 물건 자체에 대해서는 변화가 없다
반면 자연어 데이터는,
"나는 사과를 먹었다"
주어, 동사, 목적어가 있기 때문에 translation invariance가 적용되지 않는다.
-> "문장을 구성하고 있는 단어들의 위치가 변해서는 안된다."
-> "단어들간의 관계가 중요하다."
-> 하나의 단어만 바뀌거나 추가되어도 전혀 다른 의미(context)를 가진다.

이것은 다 같은 석상이고 "분류모델"의 경우 정답은 "석상"인데.
결국 이건 피쳐로 이루어진 이미지 데이터셋이잖아
비전 데이터셋은 피쳐가 바뀌는 걸로 영향을 안받음.
근데 자연어인경우, sentiment class라고 칠 때 (긍정/부정)
문장이 길게 있고, 거기에 '안'만 추가해도 "부정"문이 된다.
좋아한다 (긍정) -> 안좋아한다 (부정으로 바뀜)
그럼 "부정" 감성에서 attention해야 하는 텍스트는 "안"이다.
-> 따라서 자연어에선 이런 attention 기법이 특히 중요하다.
<요약>
- GPT를 구성하고 있는 모델은 Transformer에서 가져온 것이다.
- Bert, GPT의 경우 특히 자연어 데이터에 특화된 프레임워크이다.
- 자연어 데이터는 단어와 단어들 사이의 순서와 관계가 중요하다.
- 문장이 갖고 있는 문맥을 알고리즘이 이해할 수 있게 하는 것이 어렵다.
자연어 데이터의 토큰화
토큰화는 어떤 문장이 있으면 그 문장을 "의미 있는 단위"로 쪼개준다는 것이다.
어떻게 쪼갤 것이냐가 문제인데
"Let's do tokenization!"
- Character 단위 -> L,e,t,',s,d,o,t,o,k,e,n,i,z,a,t,i,o,n,!
-> 문장의 시계열 길이가 너무 늘어남
-> 각각의 문자는 의미를 가지고 있지 않음 -> 결국 단어로 표현을 해야 함 - Space 단위 -> Let's, do, tokenization!
-> tokenizaion! 은 느낌표를 포함하고 있는데, 의미가 다르지않냐?
-> word단위는 경우의 수가 너무 많고 , 사전에 없는 단어가 생길 위험이 있음. -> 이모티콘, 신조어 등 rare한 단어 학습 어려움 - punctuation 단위 -> Let, 's, do, tokenizaion, !
<요약>
- hugging face와 같은 대중적인 공유 라이브러리가 존재하기 전까지 연구자들이 각각 토큰화를 임의로 진행했었다.
- 이예 따라서 모델을 다운받아 실행시킬 경우 전혀 다른 결과가 나타남
- 즉 자연어에서의 토큰처리 과정에 대해 아는 것은 매우 중요
자연어 처리 Task
Language model은 하나의 문장을 여러개로 나누고, 나눈 토큰들의 결합분포로 문장에 대해서 확률을 구성한다.
하나의 문장에 대해서 확률적으로 모델링을 한다.
감정분석을 한다면
이 문장이 긍정적인지에 대한 확률을 이야기 한다.
맛있는 사과를 먹었다 <- 맛있는은 긍정이야! 그럼 긍정적인 문장일 확률이 높아지는...

확률적 모델링을 이용해서
나는 ( ) 먹었다.
( ) 안에 위치하게 될 단어들이 어떤 확률일지를 예측
사과일 경우 0보다 크고, 식탁일 경우 0이다! 라는 확률을 알 수 있다.
문제상황에 따라서 맞는 모델을 찾는 것이다.
자연어 처리 metric
-> BLEU, Rouge, METEOR
BLEU metrics를 가장 많이 쓴다. 기계어 번역에서 많이 쓰는데,
예를 들어 일반적인 머신러닝 task 에서 분류모델을 다룬다 하면
input이 들어오면 모델을 거처 추론을 하는 시스템
근데 기계어번역은 결과가 똑같지 않을 확률이 굉장히 높아.
-> 정량적인 분석이 힘들다. (어폐가 있을 수도)
어떠한 문장에 대해서 번역이 된 것/생성된 문장에
길이에 먼저 independent한지를 따진다.
I ate apple이 정답이라 쳐봐
번역이 나온 문장이 I 어쩌고오오오오 ate 어쩌고오오오 apple 어쩌고오오오옹
그럼 I, ate, apple 있으니까 똑같지 않냐 -> X
BLEU -> based on n-gram based precision
예를 들어 단어들을 3개씩 봐서, 3개 중에 번역된 게 몇개가 맞았는지...
a, the 이런 개 막 다섯개 뱉음 -> the the the apple 이런 건 이상한 문장이니까 마이너스를 주고
그래서 자연어처리는 human based measures가 많다.
사람한테 시켜서 뭐가 더 그럴듯해보이니????
-> 번역, 감정분석 이런 건 정량적인 확인이 힘들다. 너무 애매모호한 부분!
기존 연구
기존 연구들의 특징:
어떠한 문장을 분류하거나 혹은 이 문장을 내포하고 있는 어떤 벡터로 표현하고 싶다.
문장의 문맥을 하나의 벡터로 표현하기 위해서 인코딩을 한다.
문맥을 알아내는 Enbcoder를 학습했다면 다양한 task에 적용이 가능
"나는 사과를 좋아한다"라는 문장 자체를 인코딩한다. (인코딩 과정: 토크나이저 과정을 통한 토큰 만들기 -> 나는, 사과를, 좋아한다. 로 쪼개고 -> 나는 을 숫자로, 사과를 을 숫자로... -> 나는 사과를 좋아한다 라는 벡터가 최종적으로 n차원의 context vector로 나온다)
-> 감정분석, 기계어번역, QA 에 적용
Recurrent neural networks (RNNs)
-> input이 순서대로 들어오면 그 인풋을 받아 모델이 아웃풋을 내뱉는데
두가지 방향으로 내뱉는다. 순차적으로 아웃풋을 내뱉는 모양.
-> 문장은 순서를 가지고 있으니, 문장의 처음부터 끝까지 순서대로 입력을 받아서 최종적으로 벡터를 생성하자!
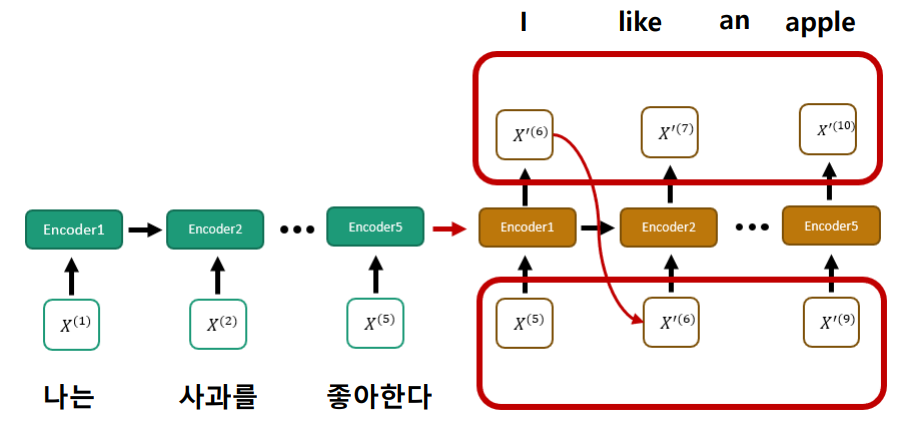
그렇다면
문장의 단어들이 순서를 가지고 있는 거 알겠어.
하지만 중요한 단어들이 처음 부분에 있다면 정보를 잃어 버리지 않을까?
-> 각각의 단어에 대해서 "Attention"을 줄 수 있으면 좋겠다!!!
"나는 사과를 좋아한다" -> "I like an apple"
I를 번역할 때는 "나는"에 attention,
Apple을 번역할 때는 "사과"에 집중해야 한다.

-> 기존 연구들이 고려한 자연어 데이터의 순차적인 특성만으로는 부족하기 때문에
문장마다의 중요도를 계산하여 Attention 모듈을 생각해 내었다.
