- 데이터 읽고 인구 소멸 지역 계산하기
- 지도 시각화를 위한 지역별 ID 만들기
- 카르토그램으로 시각화하기
우리나라 인구수 데이터(출처 KOSIS)에서
지방별 소멸 비율을 조사하고,
카르토그램으로 시각화하여 나타내는 분석을 할 것이다.
지방소멸위험지수는 20~39살 여성 수를 65살 이상 고령인구 수로 나눈 상대 비율로, 가임기 여성이 감소할수록 비율이 낮아진다.
낮음(1.5 이상), 보통(1.0∼1.5), 소멸주의(0.5∼1.0), 위험진입(0.2∼0.5 미만), 고위험(0.2 미만) 등 5단계로 나눈다.
데이터 읽고 인구 소멸 지역 계산하기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
plt.rcParams["axes.unicode_minus"] = False
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
%matplotlib inline
import warnings
warnings.filterwarnings(action="ignore")불필요한 연도 컬럼 삭제, NaN값 삭제하고 채우기
-> fillna를 이용한다. method=pad는 바로 앞 데이터를 가져와 밑에 값들을 채워준다.
(backfill은 뒤의 데이터로 채워줌, 가로 기준으로 하려면 axis=0 설정)
population = pd.read_excel("../data/07_population_raw_data.xlsx", header=1)
population.fillna(method="pad", inplace=True)
population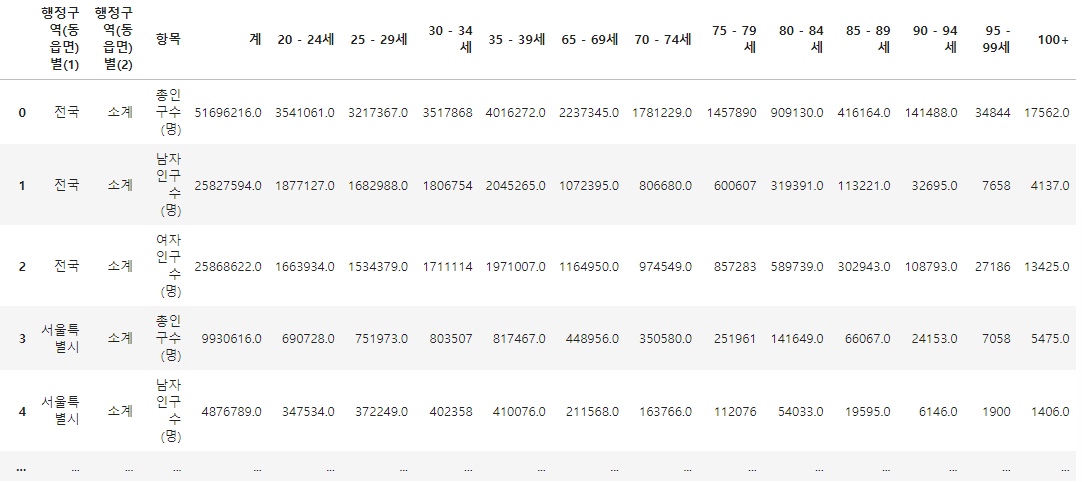
컬럼 이름 변경해주고...
population.rename(
columns={
"행정구역(동읍면)별(1)": "광역시도",
"행정구역(동읍면)별(2)": "시도",
"계": "인구수"
}, inplace=True
)
population.tail()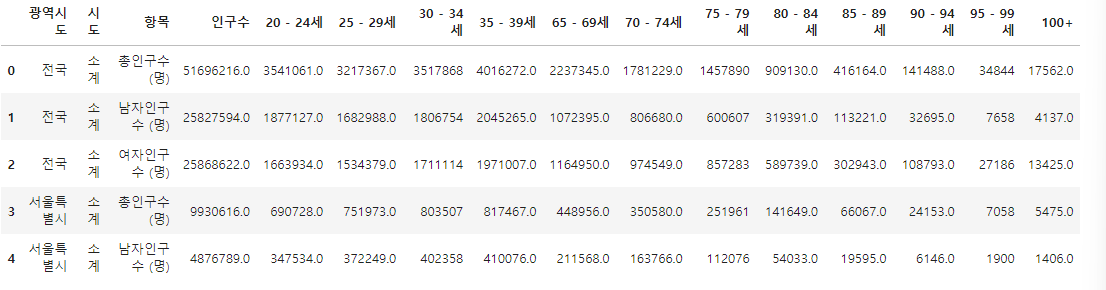
소계 제거 - "소계"가 아닌 애들만 남겨서 저장
population = population[population["시도"] != "소계"]
population.rename(
columns={"항목": "구분"}, inplace=True
)
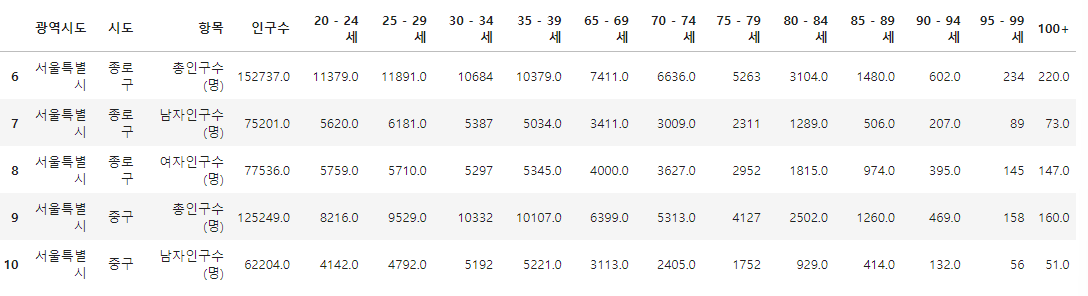
총인구수 (명) <- 이라는 글자를 "합계" 로 바꿔줘
같은 방법으로 남자인구수 (명) -> 남자,
여자인구수 (명) -> 여자 로 바꿔줘
population.loc[population["구분"] == "총인구수 (명)", "구분"] = "합계"
population.loc[population["구분"] == "남자인구수 (명)", "구분"] = "남자"
population.loc[population["구분"] == "여자인구수 (명)", "구분"] = "여자"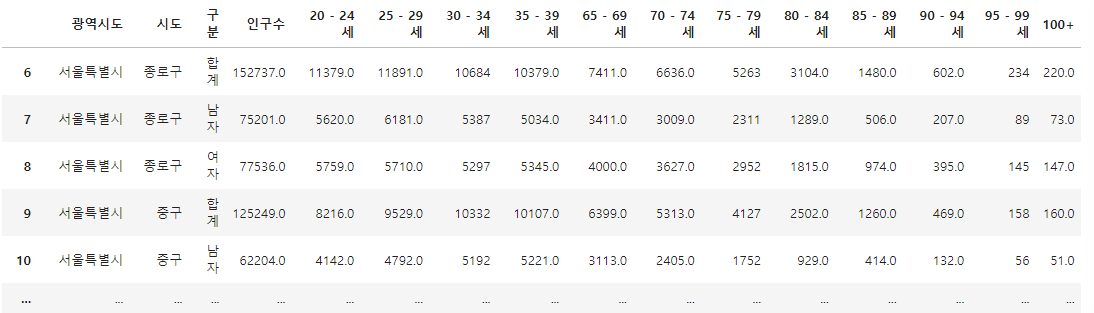
이제 소멸지역을 조사하기 위한 데이터를 생성하자!!
젊은층 / 노년층을 따로 분리하여 합친 컬럼을 만들었다.
population["20-39세"] = (
population["20 - 24세"] + population["25 - 29세"] + population["30 - 34세"] + population["35 - 39세"]
)
population["65세이상"] = (
population["65 - 69세"] + population["70 - 74세"] + population["75 - 79세"] + population["80 - 84세"] +
population["85 - 89세"] + population["90 - 94세"] + population["100+"]
)
population.tail()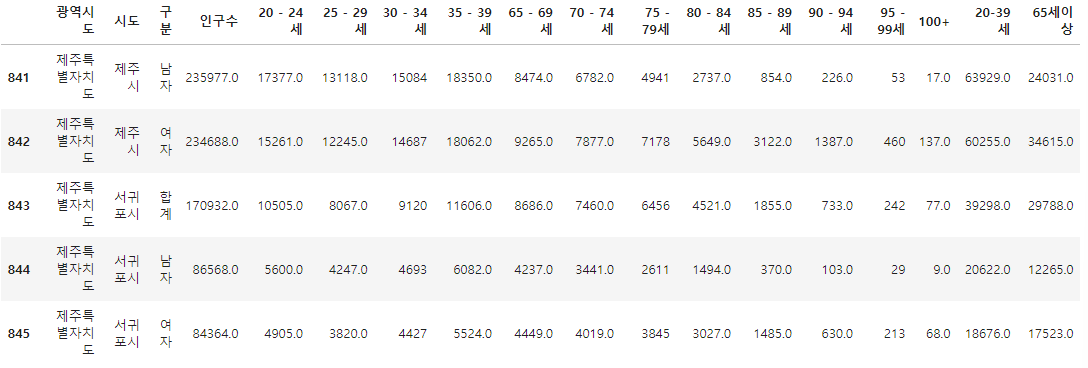
그리고
피벗테이블!!!!
-> "광역시도", "시도" 를 인덱스로 잡고, columns는 구분, 그 안의 데이터는 인구수, 젋은층, 노년층
pop = pd.pivot_table(
data=population,
index=["광역시도", "시도"],
columns=["구분"],
values=["인구수", "20-39세", "65세이상"]
)
pop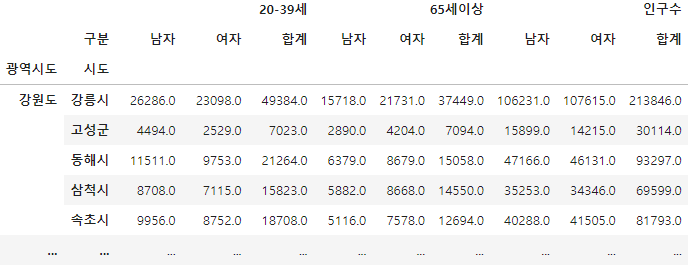
소멸 비율 컬럼을 추가하자!!
소멸 위기 지역이냐 아니냐?<- T/F로 구분지어주는 컬럼 생성
소멸비율이 1.0보다 작으면 소멸 위기 지역이다.
pop["소멸비율"] = pop["20-39세", "여자"] / (pop["65세이상", "합계"] / 2)
pop["소멸위기지역"] = pop["소멸비율"] < 1.0
pop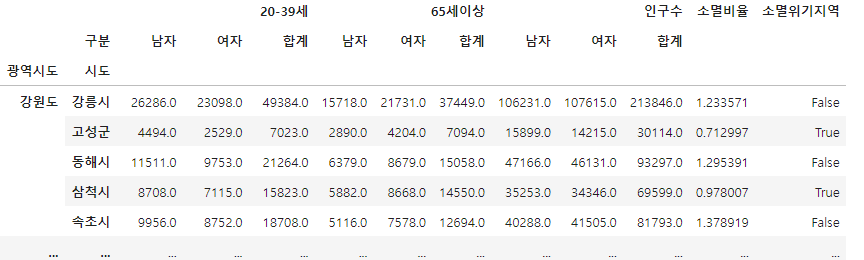
리셋인덱스 해주고,
컬럼명 재정렬 해주었다.
pop.reset_index(inplace=True)
tmp_columns = [
pop.columns.get_level_values(0)[n] + pop.columns.get_level_values(1)[n]
for n in range(0, len(pop.columns.get_level_values(0)))
]
tmp_columns
pop.columns = tmp_columns
pop.head()
지도 시각화를 위한 지역별 ID 만들기
빈 리스트를 만들듯이
지역 이름을 none으로 채워주고,
si_name = [None] * len(pop)
si_nametmp_gu_dict = {
"수원": ["장안구", "권선구", "팔달구", "영통구"],
"성남": ["수정구", "중원구", "분당구"],
"안양": ["만안구", "동안구"],
"안산": ["상록구", "단원구"],
"고양": ["덕양구", "일산동구", "일산서구"],
"용인": ["처인구", "기흥구", "수지구"],
"청주": ["상당구", "서원구", "흥덕구", "청원구"],
"천안": ["동남구", "서북구"],
"전주": ["완산구", "덕진구"],
"포항": ["남구", "북구"],
"창원": ["의창구", "성산구", "진해구", "마산합포구", "마산회원구"],
"부천": ["오정구", "원미구", "소사구"],
}고유한 ID를 만들어야 하는데,
"남양주" <- 이런 지역명은 고유하다.
하지만 "중구" <- 이런 애들은 중복되는 값들이 많다...
그렇다면 "서울 중구" 이런 식으로 표시를 하는 반복문을 만들어야 한다.
(1) 일반 시 이름과 세종시, 광역시도의 일반 구 정리
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
si_name[idx] = row["시도"][:-1]
elif row["광역시도"] == "세종특별자치시":
si_name[idx] = "세종"
else:
if len(row["시도"]) == 2:
si_name[idx] = row["광역시도"][:2] + " " + row["시도"]
else:
si_name[idx] = row["광역시도"][:2] + " " + row["시도"][:-1](2) 행정구
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
for keys, values in tmp_gu_dict.items():
if row["시도"] in values:
if len(row["시도"]) == 2:
si_name[idx] = keys + " " + row["시도"]
elif row["시도"] in ["마산합포구", "마산회원구"]:
si_name[idx] = keys + " " + row["시도"][2:-1]
else:
si_name[idx] = keys + " " + row["시도"][:-1](3) 고성군
for idx, row in pop.iterrows():
if row["광역시도"][-3:] not in ["광역시", "특별시", "자치시"]:
if row["시도"][:-1] == "고성" and row["광역시도"] == "강원도":
si_name[idx] = "고성(강원)"
elif row["시도"][:-1] == "고성" and row["광역시도"] == "경상남도":
si_name[idx] = "고성(경남)"pop["ID"] = si_name
pop청년층 여자 데이터와, 노년층 합계 데이터만 있으면 되기 때문에 필요 없는 컬럼 날리기!
del pop["20-39세남자"]
del pop["65세이상남자"]
del pop["65세이상여자"]pop.head()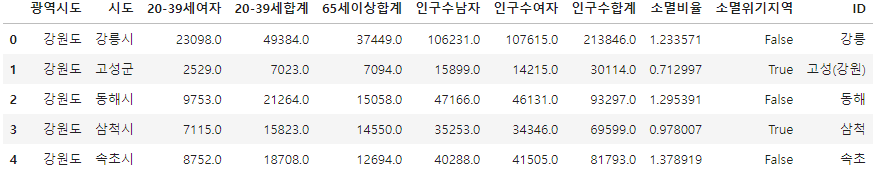
완성!!
카르토그램으로 시각화하기
교수님이 한땀한땀 만드신 지도 모양 엑셀 파일을 읽어온다! -> 데이터가 없는 칸은 NaN
draw_korea_raw = pd.read_excel("../data/07_draw_korea_raw.xlsx")
draw_korea_raw지도 그리기 작업으로는
우선 경계선을 설정해주고, 지명 문구를 표시해준다.
0번 인덱스에 값이 있는 애들, 1번 인덱스에 값이 있는 애들,,,
이거를 데이터프레임으로 만들어주고 저장:
draw_korea_raw_stacked = pd.DataFrame(draw_korea_raw.stack())
draw_korea_raw_stackedNaN을 제외한, 값이 있는 애들만 출력한 거고
reset_index 해준다.
draw_korea_raw_stacked.reset_index(inplace=True)
draw_korea_raw_stacked
컬럼명 바꾸고, 다시 저장.
draw_korea_raw_stacked.rename(
columns={
"level_0" : "y",
"level_1" : "x",
0 : "ID"
}, inplace=True
)
draw_korea_raw_stacked
draw_korea = draw_korea_raw_stacked
엑셀에서는 색깔로 구분되어 있지만, 데이터프레임에서 표현해주기 위해서 경계선을 하나하나 그려주자 (x, y좌표)
교수님의 엄청난 노력과 노가다가 담겨 있는 부분...!!
BORDER_LINES = [
[(5, 1), (5, 2), (7, 2), (7, 3), (11, 3), (11, 0)], # 인천 경계선
[(5, 4), (5, 5), (2, 5), (2, 7), (4, 7), (4, 9), (7, 9), (9, 7), (9, 5), (10, 5), (10, 4), (5, 4)], # 서울
[(1, 7), (1, 8), (3, 8), (3, 10), (10, 10), (10, 7), (12, 7), (12, 6), (11, 6), (11, 5), (12, 5), (12, 4), (11, 4), (11, 3)], # 경기도
[(8, 10), (8, 11), (6, 11), (6, 12)], # 강원도
[(12, 5), (13, 5), (13, 4), (14, 4), (14, 5), (15, 5), (15, 4), (16, 4), (16, 2)], # 충청북도
[(16, 4), (17, 4), (17, 5), (16, 5), (16, 6), (19, 6), (19, 5), (20, 5), (20, 4), (21, 4), (21, 3), (19, 3), (19, 1)], # 전라북도
[(13, 5), (13, 6), (16, 6)],
[(13, 5), (14, 5)], # 대전시 # 세종시
[(21, 2), (21, 3), (22, 3), (22, 4), (24, 4), (24, 2), (21, 2)], # 광주
[(20, 5), (21, 5), (21, 6), (23, 6)], # 전라남도
[(10, 8), (12, 8), (12, 9), (14, 9), (14, 8), (16, 8), (16, 6)], # 충청북도
[(14, 9), (14, 11), (14, 12), (13, 12), (13, 13)], # 경상북도
[(15, 8), (17, 8), (17, 10), (16, 10), (16, 11), (14, 11)], # 대구
[(17, 9), (18, 9), (18, 8), (19, 8), (19, 9), (20, 9), (20, 10), (21, 10)], # 부산
[(16, 11), (16, 13)],
[(27, 5), (27, 6), (25, 6)]
]지도 위에 글씨를 잘 배치하기 위해서,
공백 기준 split을 했는데 길이가 2다: 서울(한줄 띄고)은평 <- 이런 식으로 해야겠다.
만약 이름이 "고성"이면 고성으로 나오게 하고!
이것도저것도 아니면, 그냥 출력해라 ~
annotate <- matplotlib에서 주석 다는 기능이다. 글자를 표시하기 위함
def plot_text_simple(draw_korea):
for idx, row in draw_korea.iterrows():
if len(row["ID"].split()) == 2:
dispname = "{}\n{}".format(row["ID"].split()[0], row["ID"].split()[1])
elif row["ID"][:2] == "고성":
dispname = "고성"
else:
dispname = row["ID"]
if len(dispname.splitlines()[-1]) >= 3: # 세글자보다 크다 = 길이가 넘 기니까 글자 크기를 줄이기
fontsize, linespacing = 9.5, 1.5
else:
fontsize, linespacing = 11, 1.2
plt.annotate(
dispname,
(row["x"] + 0.5, row["y"] + 0.5),
weight="bold",
fontsize=fontsize,
linespacing=linespacing,
ha="center", # 수평 정렬
va="center" # 수직 정렬
)
def simpleDraw(draw_korea):
plt.figure(figsize=(8, 11))
plot_text_simple(draw_korea)
for path in BORDER_LINES:
ys, xs = zip(*path) # zip함수
plt.plot(xs, ys, c="black", lw=1.5)
plt.gca().invert_yaxis()
plt.axis("off")
plt.tight_layout() # 이런 식으로 좀 글자 배치를 예쁘게 하기 위한 기능을 찾아라
plt.show()simpleDraw(draw_korea)
우왕.. ㅎㅎ
검증 작업도 배웠다!
set(집합)기능을 이용해서 차집합을 구했을 때, 차집합이 없어야 정상!
set(draw_korea["ID"].unique()) - set(pop["ID"].unique())-> set()
정상임.
순서를 바꿔보면 .. 있다
set(pop["ID"].unique()) - set(draw_korea["ID"].unique())-> {'고양', '부천', '성남', '수원', '안산', '안양', '용인', '전주', '창원', '천안', '청주', '포항'}
이러면 안되는 거라, 이 데이터들을 지워준다.
리스트로 형변환하고, for문으로 하나씩 뽑아와서 하나씩 drop
tmp_list = list(set(pop["ID"].unique()) - set(draw_korea["ID"].unique()))
for tmp in tmp_list:
pop = pop.drop(pop[pop["ID"] == tmp].index)
set(pop["ID"].unique()) - set(draw_korea["ID"].unique())-> set()
merge!!
pop = pd.merge(pop, draw_korea, how="left", on="ID")각 ID에 해당하는 좌표값을 가져왔다
이 데이터프레임을 이용해서 카르토그램 시각화!!
그림을 그리기 위한 데이터를 계산하는 함수
- 색상을 만들 때, 최소값을 흰색으로 하는 기능
- 받는 인자로는 blockedMap: 인구현황 (pop데이터)
- targetData: 그리고 싶은 컬럼
흰 도화지 위에
"색으로 의미를 주는 것이다"
색깔이 진하면 인구가 많은 곳...<- 이런 식으로 의미를 주는 것을 함수로 만들어서 한번에 일괄적으로 적용하는 과정이다.
def get_data_info(targetData, blockedMap):
whitelabelmin = (
max(blockedMap[targetData]) - min(blockedMap[targetData])
) * 0.25 + min(blockedMap[targetData])
vmin = min(blockedMap[targetData])
vmax = max(blockedMap[targetData])
mapdata = blockedMap.pivot_table(index="y", columns="x", values=targetData)
return mapdata, vmax, vmin, whitelabelmindef get_data_info_for_zero_center(targetData, blockedMap):
whitelabelmin = 5
tmp_max = max(
[np.abs(min(blockedMap[targetData])), np.abs(max(blockedMap[targetData]))]
)
vmin, vmax = -tmp_max, tmp_max
mapdata = blockedMap.pivot_table(index="y", columns="x", values=targetData)
return mapdata, vmax, vmin, whitelabelmin위에서 연습으로 만들었던 코드를 가져와주고,
targetData, blockedMap, whitelabelmin을 인자로 받는다.
def plot_text(targetData, blockedMap, whitelabelmin):
for idx, row in blockedMap.iterrows():
if len(row["ID"].split()) == 2:
dispname = "{}\n{}".format(row["ID"].split()[0], row["ID"].split()[1])
elif row["ID"][:2] == "고성":
dispname = "고성"
else:
dispname = row["ID"]
if len(dispname.splitlines()[-1]) >= 3:
fontsize, linespacing = 9.5, 1.5
else:
fontsize, linespacing = 11, 1.2
annocolor = "white" if np.abs(row[targetData]) > whitelabelmin else "black" # 색깔 지정
plt.annotate(
dispname,
(row["x"] + 0.5, row["y"] + 0.5),
weight="bold",
color=annocolor,
fontsize=fontsize,
linespacing=linespacing,
ha="center", # 수평 정렬
va="center" # 수직 정렬
)def drawKorea(targetData, blockedMap, cmapname, zeroCenter=False):
if zeroCenter:
masked_mapdata, vmax, vmin, whitelabelmin = get_data_info_for_zero_center(targetData, blockedMap)
if not zeroCenter:
masked_mapdata, vmax, vmin, whitelabelmin = get_data_info(targetData, blockedMap)
plt.figure(figsize=(8, 11))
plt.pcolor(masked_mapdata, vmin=vmin, vmax=vmax, cmap=cmapname, edgecolor="#aaaaaa", linewidth=0.5)
plot_text(targetData, blockedMap, whitelabelmin)
for path in BORDER_LINES:
ys, xs = zip(*path)
plt.plot(xs, ys, c="black", lw=1.5)
plt.gca().invert_yaxis()
plt.axis("off")
plt.tight_layout()
cb = plt.colorbar(shrink=0.1, aspect=10)
cb.set_label(targetData)
plt.show()drawKorea("인구수합계", pop, "Blues")
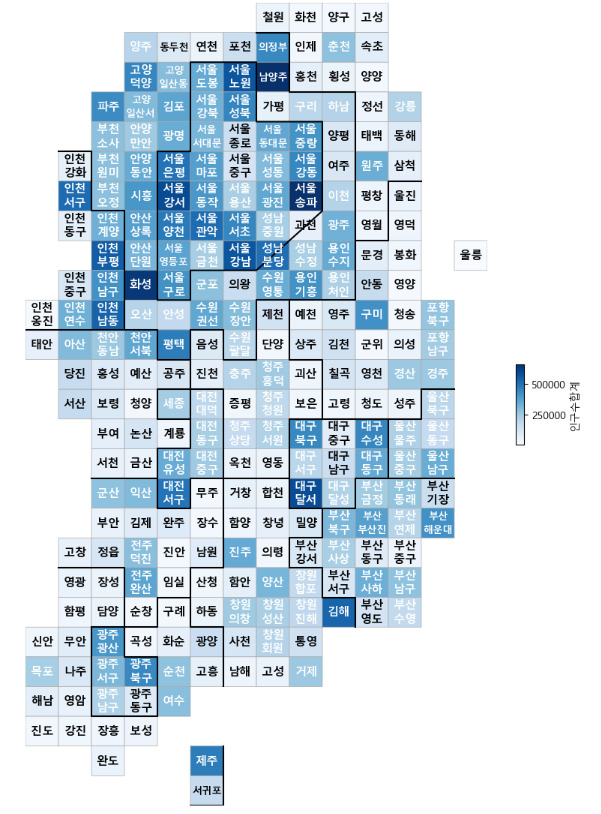
이렇게 인구수 합계 정보를 지역별로 관찰할 수 있는 카르토그램이 만들어졌다.
이제, 소멸위기지역 정보를 가지고 시각화해보자.
소멸위기지역의 t/f를 con 변수에 담고, true면 1 false면 0 -> drawKorea 함수에 전달
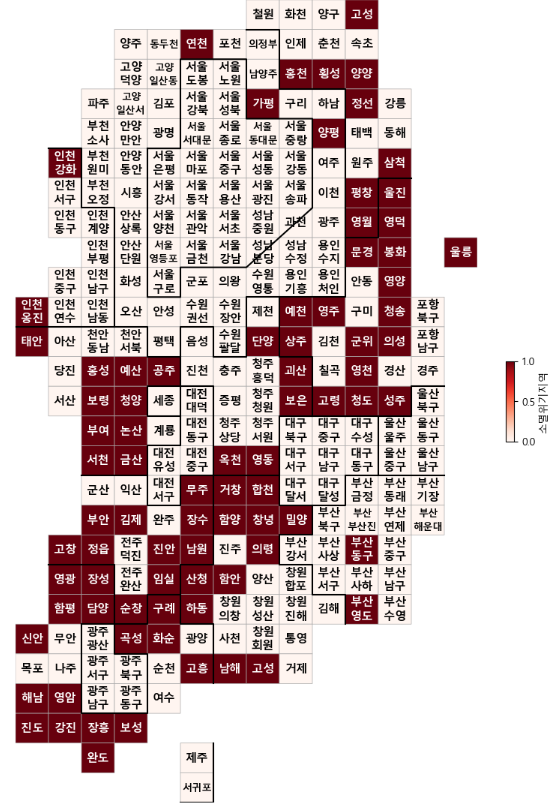
성비 정보도 알아보자
pop["여성비"] = (pop["인구수여자"] / pop["인구수합계"] - 0.5) * 100
drawKorea("여성비", pop, "RdBu", zeroCenter=True)
2030 여성비!
pop["2030여성비"] = (pop["20-39세여자"] / pop["20-39세합계"] - 0.5) * 100
drawKorea("2030여성비", pop, "RdBu", zeroCenter=True)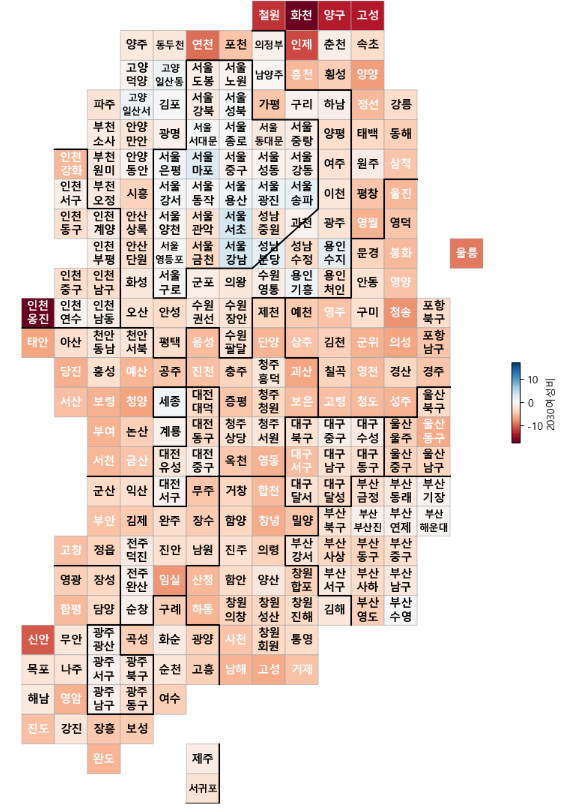
수도권 밖으로 갈수록 비율 똥망..
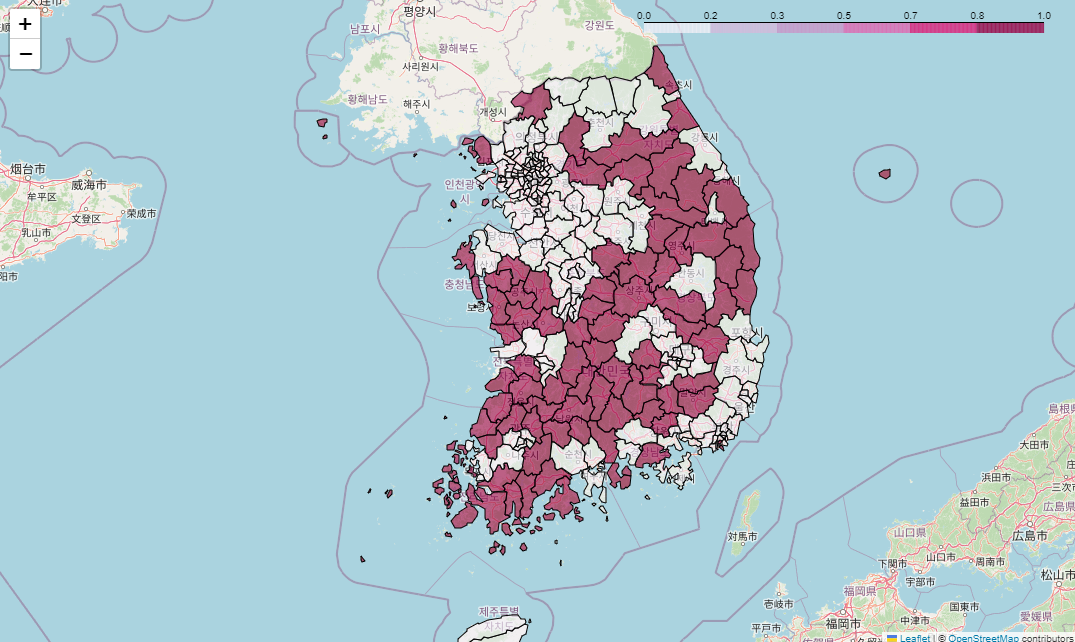
Folium 지도 시각화
import folium
import json
pop_folium = pop.set_index("ID")geo_path = "../data/07_skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding="utf-8"))
mymap = folium.Map(location=[36.2002, 127.054], zoom_start=7)
folium.Choropleth(
geo_data=geo_str,
data=pop_folium["인구수합계"],
key_on="feature.id",
columns=[pop_folium.index, pop_folium["인구수합계"]],
fill_color="YlGnBu"
).add_to(mymap)
mymap
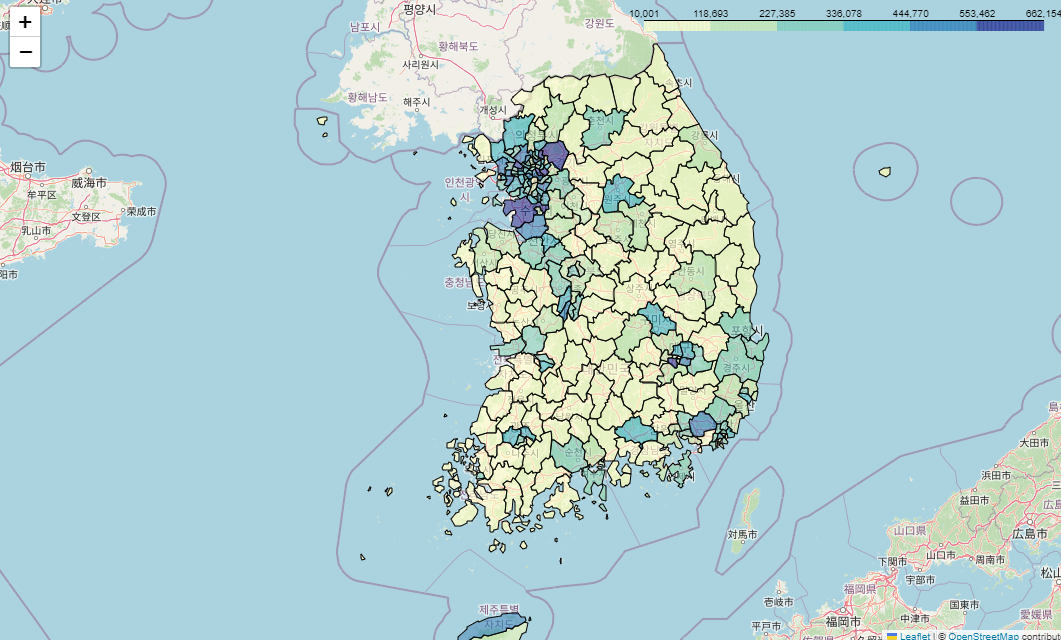
소멸위기지역 지도시각화: