
1. Abstract
이전 프로젝트에서 대규모 시스템 설계 기초 정리를 읽으면서, 학습 목적으로 Message Queue를 RabbitMQ를 도입했었다.
하지만, 곱씹어보니 RabbitMQ 뿐만 아니라 Message Queue를 잘 모른다는 결론을 도출했다.
- 스스로에게 '왜 메시지큐가 필요할까?' 또는 '왜 RabbitMQ를 썼을까?'라는 질문을 던졌을 때, 대답하지 못하는 자신을 발견했다.
따라서 간략히 Queue와 Message Queue (이하, MQ)가 무엇인지부터 알아보고자 한다.
2. Queue
Queue는 Messenger다.
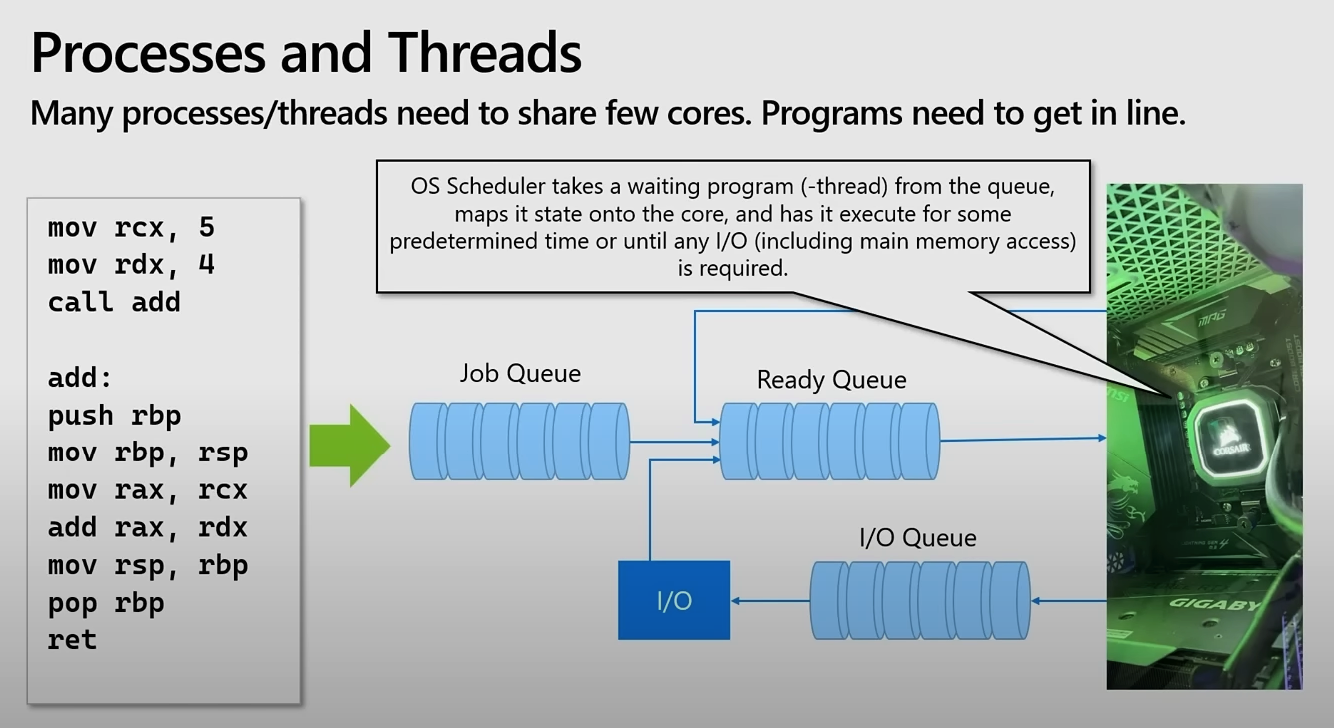
OS Scheduler
Job Queue -> Ready Queue -> OS Scheduler -> CPU mapping -> 정해진 시간 동안 실행 -> I/O Queue로 매핑 -> I/O 수행
여러 프로세스 및 스레드는 제한된 수의 CPU 코어를 공유해야 하며, 프로그램들은 순서를 기다려야 한다.
Process
- 프로그램은 맨 처음, Job Queue에서 대기한다.
- 이후, 실행 준비가 되었다면 Ready Queue에서 대기한다.
- OS Scheduler는 프로그램을 CPU에 매핑한다.
- 프로그램이 실행 중, I/O 작업을 요청하면 작업을 멈추고 스케쥴러가 I/O Queue로 보낸다.
- 프로그램은 I/O 작업이 완료될 때까지, I/O Queue에서 대기한다.
- I/O 작업이 완료되면, 프로그램은 다시 Ready Queue로 이동하여 CPU에서 실행될 준비를 한다.
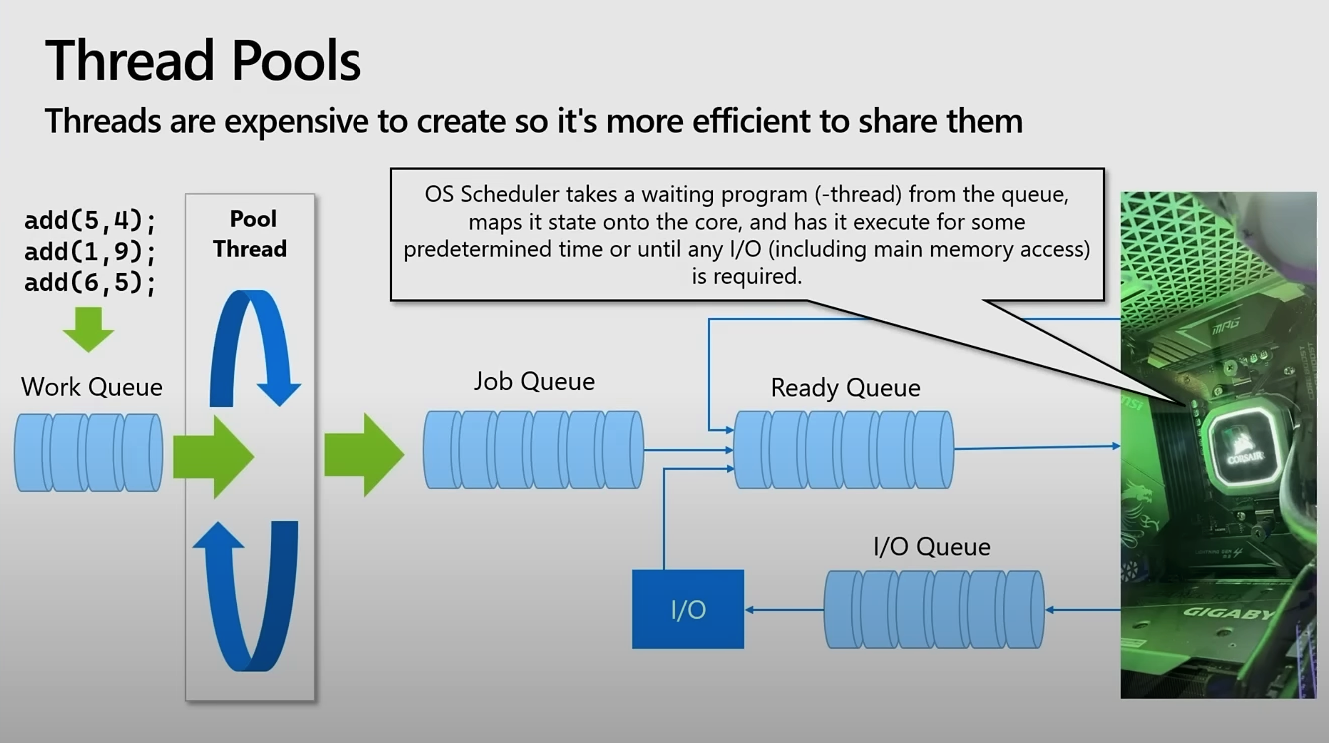
Thread Pools
Thread Pool과 Queue의 상호작용을 통해 스레드의 생성 비용을 절약하고, 시스템의 자원을 효과적으로 관리할 수 있다.
Why use thread pool?
스레드를 생성하고 관리하는 데는 많은 자원이 필요하다.
- 스레드가 생성될 때마다 메모리를 할당 / 초기화 / 스케줄링하기 때문에 시스템의 오버헤드가 증가한다.
Thread Pool은 미리 일정 수의 스레드를 생성해두고, 재사용한다.
새로운 작업이 도착할 때마다, 새로운 스레드를 생성하는 대신 이미 생성된 스레드를 사용하므로 자원 소모를 줄일 수 있다.
Process
- 프로그램이나 시스템이 처리해야할 작업들이 Work Queue에 쌓인다.
- Thread Pool의 스레드들은 작업을 가져와 실행(ex. 데이터 연산)한 후, 다시 Pool로 돌아와 다음 작업을 대기한다.
- 작업이 완료된 후, 결과를 처리하거나 후속 처리(ex. DB 저장)를 위해 Job Queue로 이동시킨다.
- (이후 과정은 동일)
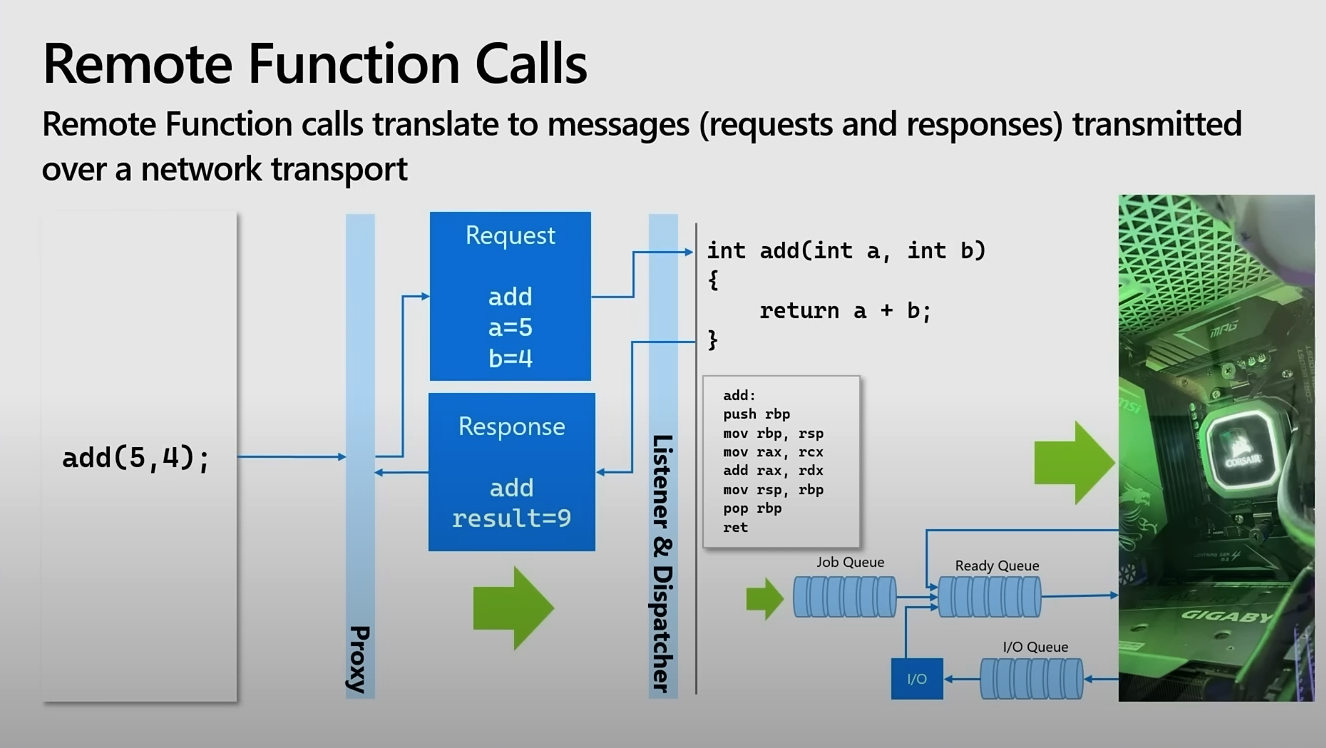
Remote Function Calls
원격 함수 호출은 네트워크를 통해 요청과 응답 메시지로 함수 호출을 수행하는 기법이다.
Process
- 클라이언트에서 함수 호출을 시작한다.
- Proxy가 요청을 받아서 Request 메시지를 생성하고, 네트워크를 통해 전달한다.
- Listener & Dispatcher가 요청을 받아 함수를 실행한다.
- 이때, 요청을 분배하는 역할도 수행
- 함수 실행 과정 중에 Job Queue와 Ready Queue, 그리고 I/O Queue가 사용된다.
- 이후, 결과는 응답 메세지로 생성하여 다시 Proxy를 통해 클라이언트로 전달한다.
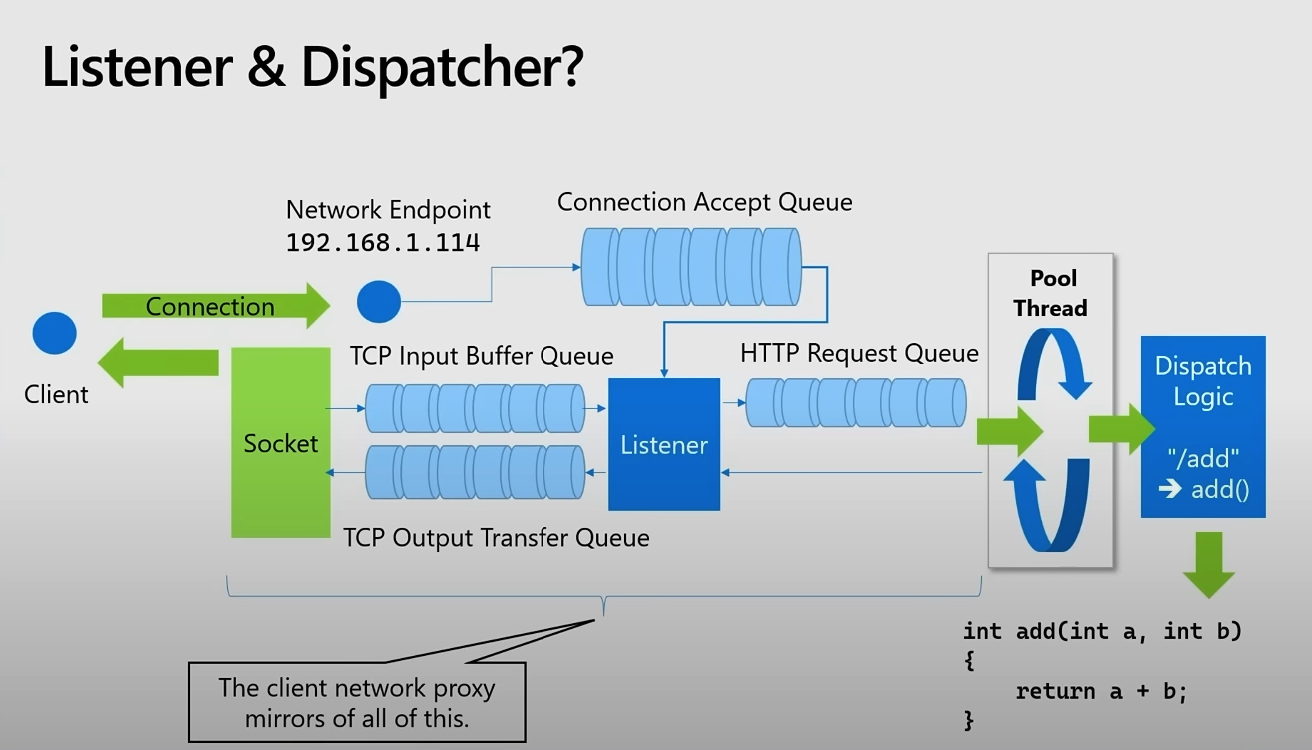
Listener & Dispatcher
Listener와 Dispatcher는 Queue를 통해 클라이언트의 요청을 처리한다.
Process
- 클라이언트가 서버에 연결을 요청한다.
- 서버의 네트워크 엔드포인트 (192.168.1.114)에서 연결을 수락한다.
- 새로운 연결 요청이 Connection Accept Queue에 대기한다.
- 소켓을 통해 TCP Input Buffer Queue로 데이터가 전송된다.
- Listener는 TCP Input Buffer Queue에서 데이터를 읽어, HTTP Request Queue로 전달한다.
- Dispatcher는 HTTP Request Queue에서 요청을 받아, URL 경로에 따라 적절한 작업으로 분배한다.
- Thread Pool이 Dispatcher의 요청을 받아 함수를 실행한다.
- 함수 실행 후, 결과를 생성하여 TCP Output Transfer Queue에 버퍼링된다.
- 클라이언트로 응답이 전송된다.
Synchronous
단일 동기 API 호출은 운영 체제와 런타임이 리소스 공유를 가능하게 하고, 확장성을 높이기 위해 사용하기 때문에 수십 개의 큐를 통해 실행된다.

여기까지 Queue를 사례와 함께 간단하게 살펴보았다.
그럼, 이론적으로 Queue가 무엇인지 살펴보자.
Queue
큐는 컴퓨팅에서 가장 기본적이고 중요한 데이터 구조 중 하나이다.
- FIFO(First In First Out)
- 큐는 일반적으로 도착한 순서대로 기록이 정렬된다.
- 데이터를 큐의 맨 아래(bottom)에 추가하고, 맨 위(top)에서 읽거나 소비한다.
- 읽거나 소비된 기록은 큐에서 제거된다.
- 큐의 길이는 항상 읽을 수 있다.
- 예시
- (1) 인쇄 작업이 프린터 큐에 추가될 경우
- (2) 웹 서버에서 클라이언트 요청을 처리하는 경우
- (3) 운영 체제가 CPU에서 실행할 작업을 큐에 추가하는 경우

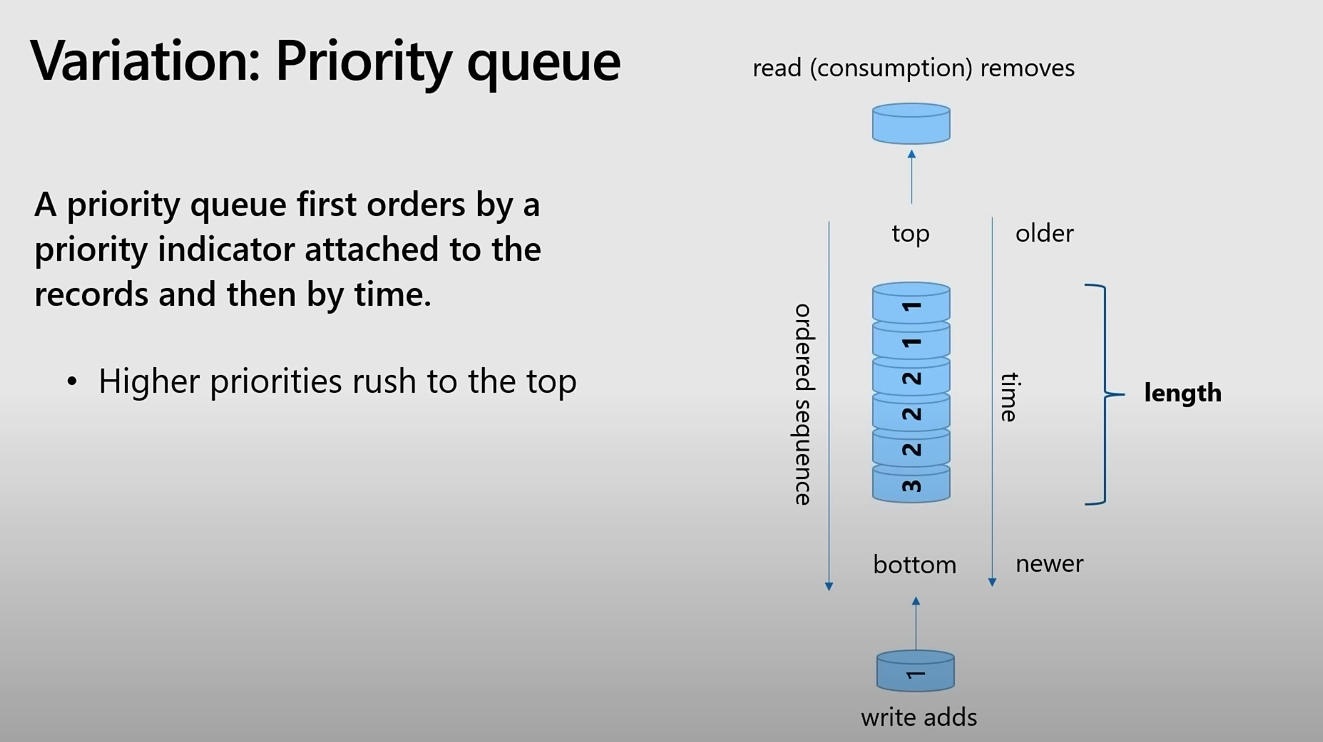
Priority Queue
우선 순위 큐는 각 항목에 부여된 우선 순위 지표를 기준으로 정렬하며, 동일한 우선 순위의 항목들은 도착한 시간 순서대로 정렬한다.
- 높은 우선 순위를 가진 항목이 큐의 맨 위로 이동하여, 먼저 처리된다.
- 우선 순위가 동일한 항목들은 도착한 시간 순서대로 정렬된다.
- 예시
- (1) 운영 체제가 우선 순위에 따라 작업을 스케줄링 하는 경우
Multiplex Queue
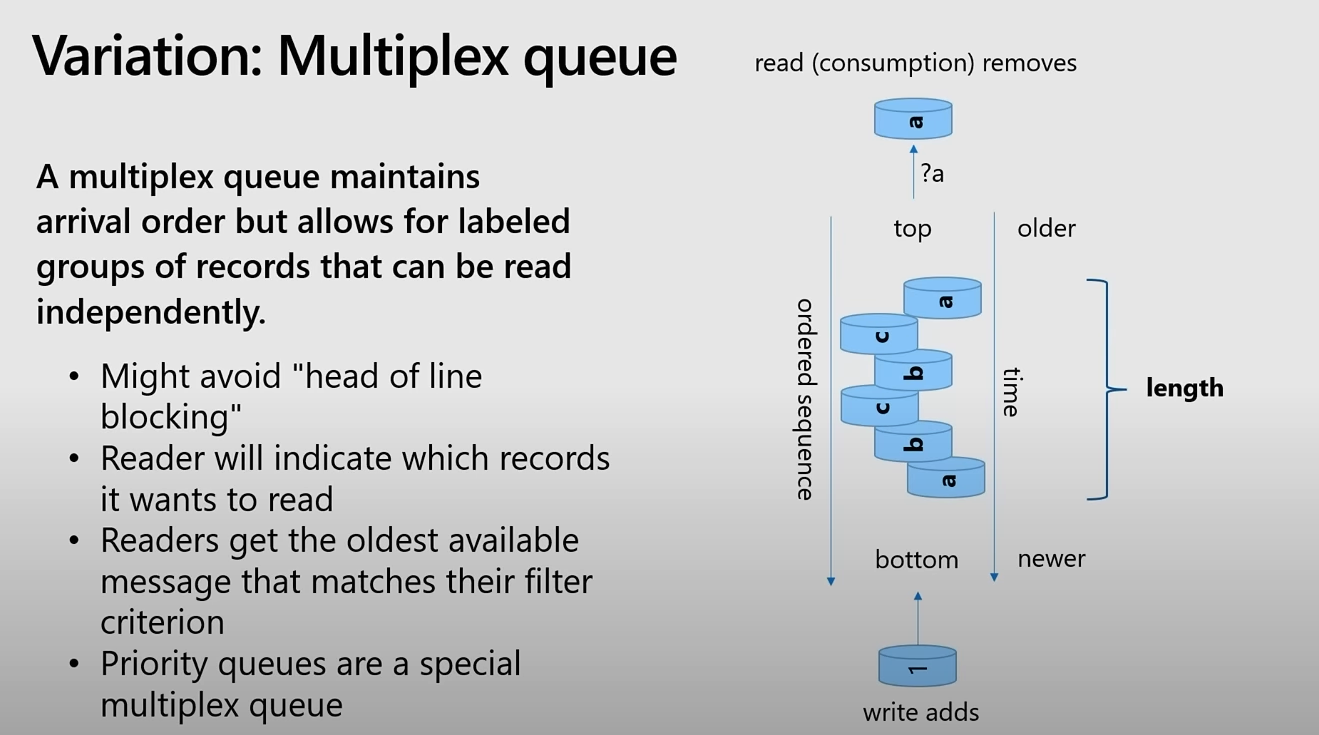
멀티플렉스 큐는 도착 순서를 유지하지만, (데이터에 붙은) 레이블이 붙은 그룹의 기록들을 독립적으로 읽을 수 있도록 한다.
-
첫 번째 항목이 블로킹되어 다른 항목들이 대기하는 상황을 방지할 수 있다.
-
읽는 측은 읽고자 하는 기록들을 명시할 수 있다.
- 또한, 자신이 지정한 필터 기준에 맞는 가장 오래된 메시지를 받는다.
-
우선 순위 큐는 멀티플렉스 큐의 특수한 형태이다.
-
예시
- (1) 로그 처리 시스템
- 로그는 도착 순서대로 추가되지만, 오류 로그를 우선적으로 읽고 처리할 수 있다.
- 경고 및 정보 로그는 오류 로그가 처리된 후, 읽을 수 있다.
- (2) 메시지 큐 시스템
- 메세지는 도착 순서대로 큐에 추가되지만, 특정 우선 순위의 메시지를 먼저 읽고 처리할 수 있다.
- (3) 이벤트 처리 시스템
- 이벤트는 도착 순서대로 추가되지만, 특정 유형의 이벤트를 먼저 처리할 수 있다.
3. Message Queue
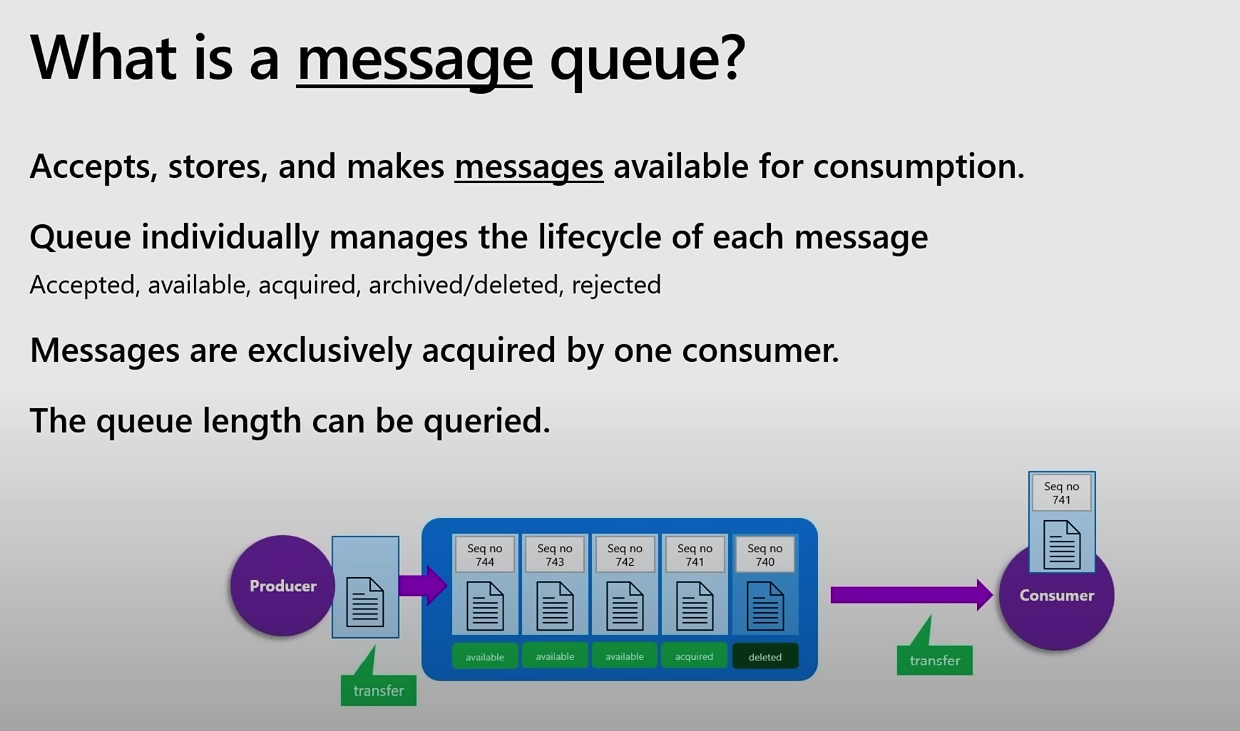
메시지 큐는 메시지를 수락하고 저장하며, 이를 소비할 수 있도록 한다.
- 메세지 브로커는 메세지를 안정적으로 전달하고 저장하는 역할을 수행한다.
- 단, 메세지를 전송하는 동안 네트워크 장애나 시스템 오류 등으로 인해 메시지가 손실될 가능성이 존재한다.
- 따라서, 대부분의 메시지 브로커는 메세지의 신뢰성을 높이기 위해 다양한 메커니즘(ex. 영구 저장) 등을 제공한다.
- 단, 메세지를 전송하는 동안 네트워크 장애나 시스템 오류 등으로 인해 메시지가 손실될 가능성이 존재한다.
-
큐는 메세지의 수명 주기를 개별적으로 관리한다.
Accepted(수락됨),Available (사용 가능),Acquired (획득됨),Archived/Delated(보관/삭제됨),Rejected(거부됨)
-
메세지는 한 Consumer에게 독점적으로 획득된다.
- 메세지는 한 번만 소비되고, 여러 소비자가 동시에 동일한 메세지를 처리하는 것을 방지한다.
Apache Kafka is not Message Queue
-
Apache Kafka는 전통적인 메세지 큐는 아니지만, 메세지 큐의 기능을 포함하여 메세지 스트리밍과 실시간 처리를 지원하는 분산 스트리밍 플랫폼이다.
-
메세지 수명 주기를 개별적으로 관리하지 않는다.
-
메세지 소비 상태를 개별적으로 관리하지 않지만, 소비자 그룹의 오프셋을 추적하여 메세지 소비 상태를 파악할 수 있으며, 토픽의 메세지 수를 통해 대기열 길이를 쿼리할 수 있다.
-
Kafka의 소비자는 항상 소비자 그룹에 속해 있으며, 소비자 그룹 내의 각 소비자는 파티션을 독점적으로 소비한다.
-
Apache Kafka는 주로 이벤트 스트림 엔진으로 사용되지만, 메시지 큐 브로커로도 사용할 수 있다.

Message
-
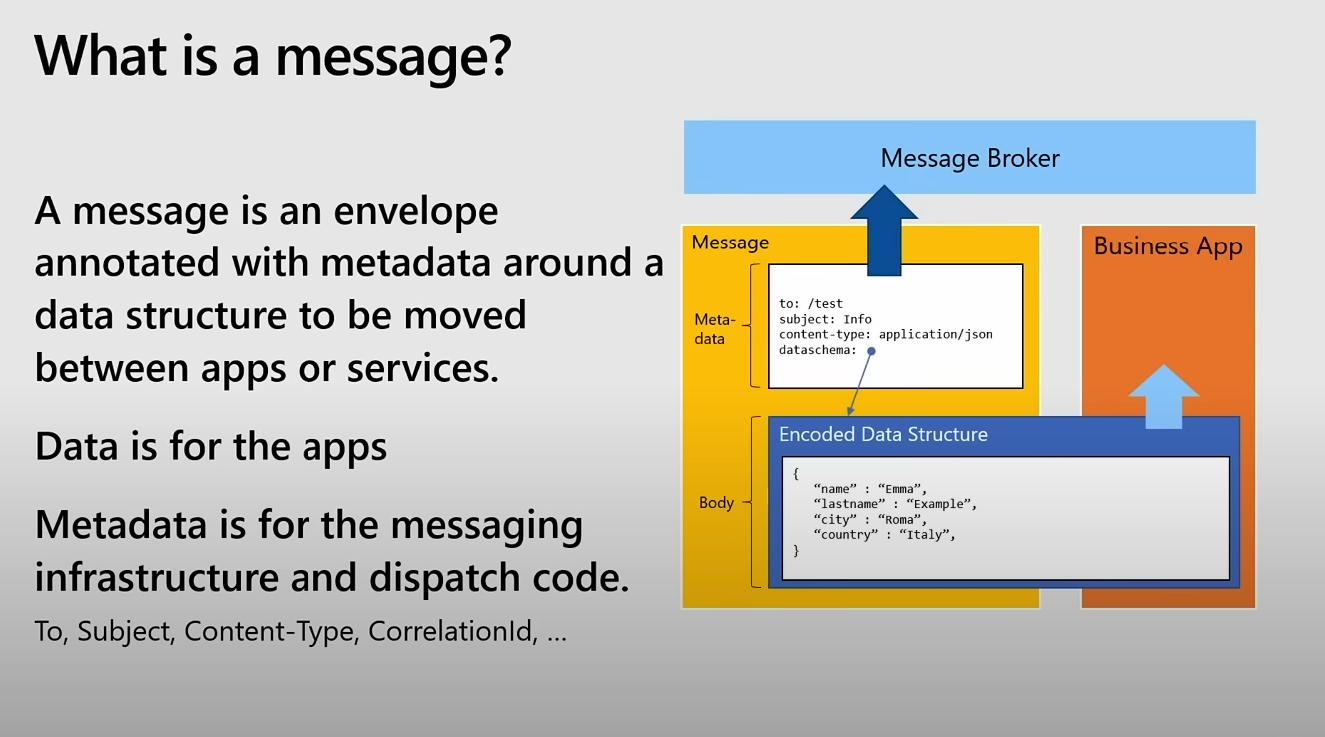
메세지는 데이터 및 메타 데이터를 감싸고 있는 외부 구조이다.
- (1) 메타데이터 : 메세지의 헤더 부분이며, 메세징 인프라와 디스패치 코드에 사용된다.
- 메세지 브로커와 메세징 인프라가 메세지를 처리하고, 라우팅하는 데 필요한 정보를 포함
- ex. content-type
- (2) 데이터 : 애플리케이션이 사용하는 실제 데이터이다.
- ex. JSON 형식으로 인코딩된 데이터 구조 { "name" : "Emma", "lastname" : "Example", .. }
- (1) 메타데이터 : 메세지의 헤더 부분이며, 메세징 인프라와 디스패치 코드에 사용된다.
-
메세지 브로커를 통해 전달되며, Producer Application에서 생성 및 Cosumer Application으로 전송된다.
-
메세지 브로커는 종단 간 암호화된 메세지의 내용에 접근이 가능하다.
- 메타데이터 및 암호화되어 있지 않은 페이로드를 참조할 수 있다.
-
메세지 큐는 메타데이터를 기반으로 라우팅 및 처리를 수행한다.
Process
- Producer가 메세지 및 메타데이터를 생성하고, 메세지 큐 또는 메세지 브로커로 전송한다.
- 이때, Producer(생산자)는 메세지를 생성하는 애플리케이션이나 시스템을 의미한다.
- 메세지가 메세지 큐에 추가된다.
- Consumer는 메세지를 수신하여, 큐에서 읽는다.
- 메세지 본문을 처리하며, 필요 시 후속 작업(ex. 데이터 저장, 알림 전송)을 위해 대기열에 추가한다.

Reference

깰롱 잘 읽었습니다 카프카는 메시지 큐가 아니라니 충격입니다