
이 문서는 머신러닝 학습 중 가장 중요한 개념 중 하나인 오버피팅(Overfitting)과
언더피팅(Underfitting)을 이해하고 극복하기 위한 개념인
바이어스(Bias)와 베리언스(Variance)를 중심으로 정리한 학습 기록입니다.
1. 오버피팅과 언더피팅 정의
| 용어 | 설명 |
|---|---|
| 언더피팅 (Underfitting) | 모델이 너무 단순해서 학습 데이터를 제대로 설명하지 못하는 상태 |
| 오버피팅 (Overfitting) | 모델이 너무 복잡해서 학습 데이터에 과하게 맞춰져, 새로운 데이터에 일반화가 되지 않는 상태 |
- 언더피팅은 바이어스가 높은 상태
- 오버피팅은 베리언스가 높은 상태
2. 바이어스와 베리언스
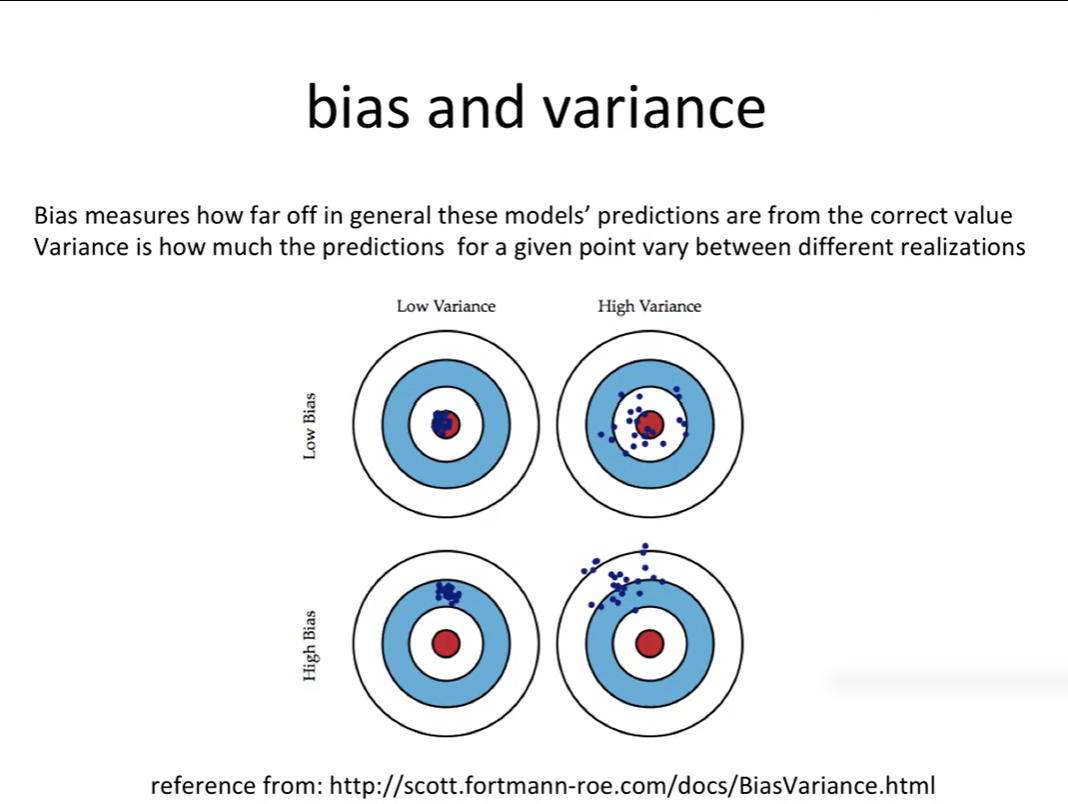
- Bias (편향): 예측값이 실제값과 얼마나 다른지를 나타내는 지표
- Variance (분산): 훈련 데이터가 바뀔 때 예측 결과가 얼마나 변하는지
| 모델 상태 | 바이어스 | 베리언스 |
|---|---|---|
| 언더피팅 | 높음 | 낮음 |
| 적절한 학습 | 낮음 | 낮음 |
| 오버피팅 | 낮음 | 높음 |
→ 좋은 모델은 낮은 바이어스와 낮은 베리언스를 동시에 만족해야 함
3. 바이어스-베리언스 트레이드오프 시각화
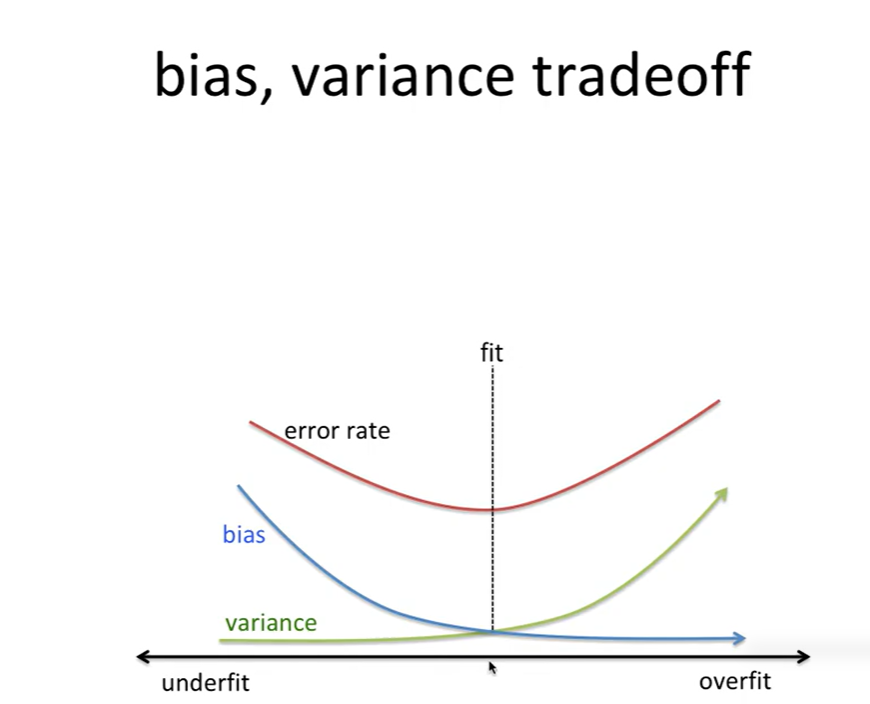
- 바이어스가 크면 전체적으로 예측이 빗나감
- 베리언스가 크면 데이터에 따라 예측이 요동침
- 두 값을 동시에 줄이기는 어렵기 때문에 균형 조절이 핵심
4. 계수(세타)를 줄여 모델을 단순화
- 세타(θ)는 선형 회귀나 로지스틱 회귀에서의 계수(가중치)
- 세타 값을 낮추면 모델이 부드러워지고, 베리언스가 감소함
- 이는 모델의 복잡도를 낮춰서 오버피팅을 줄이는 데 효과적
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0) # alpha 값이 클수록 계수 제약이 커짐5. 학습 곡선 분석
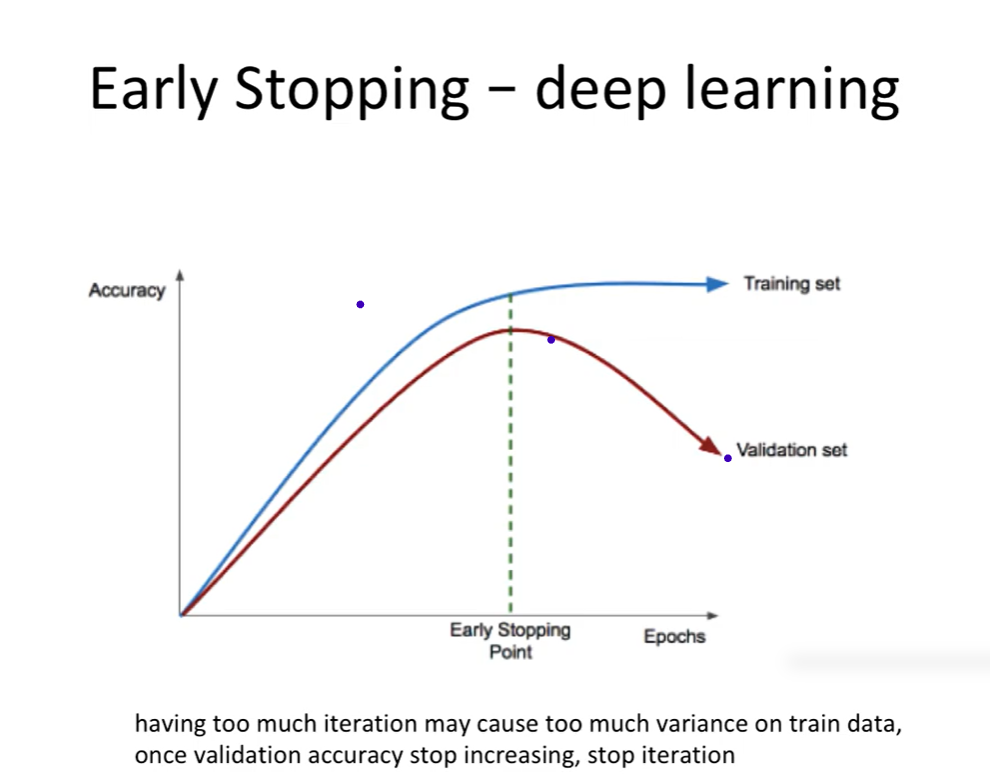
- 학습이 진행됨에 따라 훈련 정확도는 계속 증가
- 하지만 검증 정확도는 어느 순간부터 감소하는 구간이 발생
→ 이 구간에서 학습을 중단하는 전략 = Early Stopping
6. Dropout: 신경망의 과적합 방지 기법
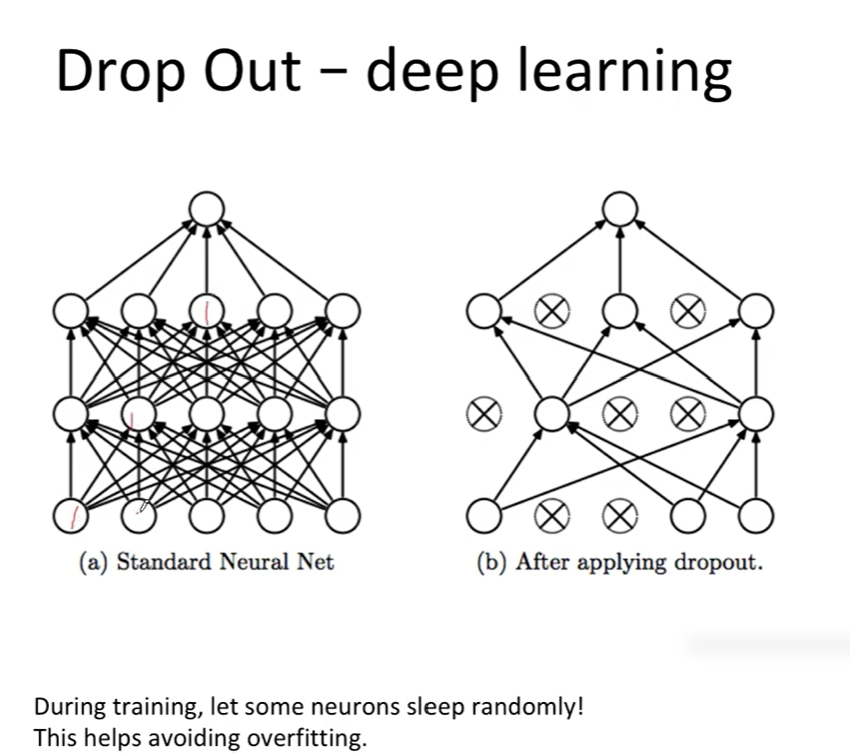
- 일부 뉴런을 무작위로 꺼서 학습
- 여러 서브모델을 조합해 학습하는 효과 → 일반화 성능 향상
- 베리언스가 낮은 예측을 유도해 오버피팅을 방지
from keras.layers import Dropout
model.add(Dropout(0.3))7. 오버피팅/언더피팅 극복 전략 요약
| 전략 | 설명 |
|---|---|
| 정규화 (Regularization) | 계수 값을 작게 제한하여 복잡한 모델을 억제 |
| Dropout | 신경망 학습 중 일부 뉴런 무작위 off |
| Early Stopping | 검증 정확도 기준으로 학습 조기 종료 |
| Feature Selection | 불필요한 입력 제거로 과적합 완화 |
| 데이터 확장 | 학습 데이터 양을 늘려 모델의 일반화 향상 |
8. 느낀 점
이번 정리를 통해 단순히 모델 성능이 좋다는 것이 아니라,
학습 데이터와 새로운 데이터 모두에서 잘 작동해야 좋은 모델이라는 기준을 배웠다.
앞으로 모델 학습 시 바이어스-베리언스 밸런스를 고려해서,
단순히 정확도가 아닌 일반화 성능 중심으로 판단해야겠다는 생각이 들었다.

기록과 회고를 통해 성장하는 데이터, AI 엔지니어 지망생입니다.