Scaling Policy는 ASG의 인스턴스 수를 “언제, 얼마나” 바꿀지 결정하는 규칙. 실무 기본은 Target Tracking이고, 보조로 Step/Simple, Scheduled, Predictive를 상황에 맞게 조합.
1) 어떻게 스케일링이 일어나나?
- 지표(CloudWatch Metric) 를 모니터링
- 정책(Scaling Policy) 이 조건 충족 시 증설/축소 의사결정
- Instance Warmup 동안 신규 인스턴스의 지표는 무시하여 진동 방지
- ASG가 Desired 값을 조정 → ELB에 자동 등록/해제(드레이닝)
2) 정책 유형 한눈에
| 유형 | 추천도 | 개념 | 언제 쓰나 |
|---|---|---|---|
| Target Tracking | ⭐️⭐️⭐️⭐️⭐️ (권장) | “지표를 목표값으로 자동 추종” | 대부분의 웹/API, 안정적인 자동화 |
| Step Scaling | ⭐️⭐️⭐️⭐️ | 임계 초과 정도에 따른 단계적 증감 | 스파이크 대응(급격한 증설) |
| Simple Scaling | ⭐️⭐️ | 임계 초과시 고정 증감 + Cooldown | 레거시, 가급적 Step/Target로 대체 |
| Scheduled Scaling | ⭐️⭐️⭐️ | 시간표 기반 증감 | 업무시간/이벤트 예약 증설 |
| Predictive Scaling | ⭐️⭐️⭐️ | 패턴 예측 기반 선제 스케일 | 일/주기 패턴 뚜렷한 서비스 |
3) Target Tracking (가장 단순·강력)
-
원리:
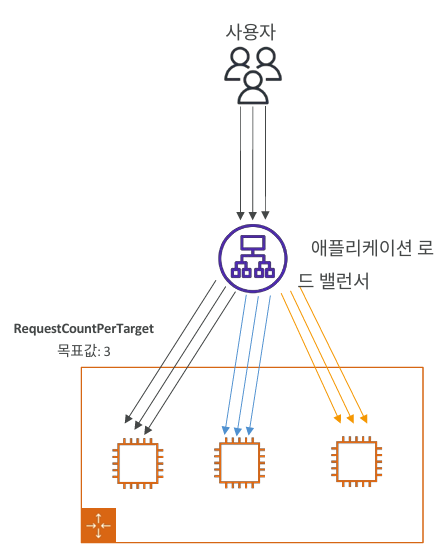
목표값(TargetValue)을 유지하도록 자동 증감- 예)
ASGAverageCPUUtilization = 50% - 예)
ALB RequestCountPerTarget = 100(타깃 1대당 초당 요청 수)
- 예)
-
장점: 알람/경계치 설계 불필요, 자동으로 상·하한을 추적
-
Warmup:
InstanceWarmup(또는 ASGDefaultInstanceWarmup)을 꼭 설정(예: 120s~300s) -
Scale-in 보호: 배포/캐시 워밍 등 상황에서
DisableScaleIn=true로 축소를 잠시 막을 수 있음 -
Predefined Metric (대표)
ASGAverageCPUUtilizationALBRequestCountPerTarget(필요: TargetGroup/LoadBalancer 지정)
-
Customized Metric
- 예) SQS 메시지/인스턴스 목표:
ApproximateNumberOfMessagesVisible / InServiceInstances
- 예) SQS 메시지/인스턴스 목표:
CLI 예시
aws autoscaling put-scaling-policy \
--auto-scaling-group-name asg-web \
--policy-name tt-cpu50 \
--policy-type TargetTrackingScaling \
--target-tracking-configuration '{
"PredefinedMetricSpecification":{"PredefinedMetricType":"ASGAverageCPUUtilization"},
"TargetValue":50.0,
"DisableScaleIn":false
}'4) Step Scaling (스파이크에 세밀 대응)
-
원리: 임계를 얼마나 넘었는지에 따라 증감 폭을 다르게
-
구성 요소
- CloudWatch Alarm(>= / <= 등)
- Step Adjustments: Upper/Lower bound, 증감 방식
- AdjustmentType:
ChangeInCapacity/PercentChangeInCapacity/ExactCapacity
-
Cooldown: 정책/그룹의 쿨다운을 활용해 플래핑 방지
-
팁: 상방(Scale-out)만 Step으로 크게, 하방(Scale-in)은 Target Tracking으로 완만히 조합 가능
CLI 예시 (요약)
# 1) 알람(예: CPU >= 70% 2분 지속)
aws cloudwatch put-metric-alarm \
--alarm-name cpu-high \
--metric-name CPUUtilization --namespace AWS/EC2 \
--statistic Average --period 60 --evaluation-periods 2 \
--threshold 70 --comparison-operator GreaterThanOrEqualToThreshold \
--dimensions Name=AutoScalingGroupName,Value=asg-web \
--alarm-actions arn:aws:autoscaling:...:scalingPolicy:policyID:autoScalingGroupName/asg-web:policyName/step-out \
--treat-missing-data notBreaching
# 2) 단계별 증설 정책
aws autoscaling put-scaling-policy \
--auto-scaling-group-name asg-web \
--policy-name step-out \
--policy-type StepScaling \
--adjustment-type PercentChangeInCapacity \
--step-adjustments '[
{"MetricIntervalLowerBound": 0, "MetricIntervalUpperBound": 10, "ScalingAdjustment": 20},
{"MetricIntervalLowerBound": 10, "MetricIntervalUpperBound": 30, "ScalingAdjustment": 40},
{"MetricIntervalLowerBound": 30, "ScalingAdjustment": 60}
]' \
--estimated-instance-warmup 1205) Simple Scaling (가급적 대체 권장)
- 원리: 임계 초과 시 고정 수치 증감, 이후 Cooldown 동안 재동작 금지
- 단점: 급변/진동에 취약 → Step/Target으로 대체하는 추세
6) Scheduled Scaling
- 원리: CRON/고정 시각에 Desired/Min/Max를 조정
- 사례: 업무시간 9–18시에 Desired를 20으로, 야간엔 4로
- 주의: 시간대(Timezone)·공휴일·서머타임 고려, 예측 실패 시 Target Tracking과 병행
CLI 예시
aws autoscaling put-scheduled-update-group-action \
--auto-scaling-group-name asg-web \
--scheduled-action-name scale-office-hours \
--recurrence "0 0 0 ? * MON-FRI *" \
--desired-capacity 207) Predictive Scaling
- 원리: 과거 패턴(일/주 반복)을 학습해 미리 증설
- 구성:
PredictiveScaling정책 + Load Metric(예:ALBRequestCountPerTarget) 지정 - 모드:
ForecastOnly(예측만) /ForecastAndScale(예측+선제 증설) - 유리한 경우: 패턴이 뚜렷(업무시간/정기 이벤트), 콜드스타트 비용이 큰 앱
CLI 예시(요약)
aws autoscaling put-scaling-policy \
--auto-scaling-group-name asg-web \
--policy-name predictive-req \
--policy-type PredictiveScaling \
--predictive-scaling-configuration '{
"MetricSpecifications":[
{"TargetValue":100.0,
"PredefinedMetricPairSpecification":{
"PredefinedMetricType":"ALBRequestCount",
"ResourceLabel":"app/my-alb/1234567890abcdef/targetgroup/tg-web/abcdef1234567890"
}
}
],
"Mode":"ForecastAndScale",
"SchedulingBufferTime":300
}'실제 파라미터 이름/구성은 콘솔 가이드를 함께 확인해 세팅하세요. (리소스 라벨 형식 엄격)
8) Warmup / Cooldown / 보호 옵션
-
Instance Warmup: 새 인스턴스가 정상 처리가 가능해질 때까지 지표 반영 제외
- Target Tracking:
InstanceWarmup(정책별) 또는 ASGDefaultInstanceWarmup - Step/Simple:
EstimatedInstanceWarmup또는 그룹DefaultCooldown
- Target Tracking:
-
DisableScaleIn: 특정 정책에서 축소 금지
-
Scale-In Protection: 인스턴스 단위로 축소 보호
-
Lifecycle Hooks: Launch/Terminate 시 초기화/드레인 스크립트 실행
9) 어떤 지표를 써야 할까? (실무 매핑)
- 웹/API(균일한 요청 부하) →
ALBRequestCountPerTarget+ Target Tracking - CPU 바운드 →
ASGAverageCPUUtilization - SQS 소비형 워크로드 → 커스텀 목표: “메시지/인스턴스” (메트릭 매스 또는 애플리케이션 지표 발행)
- 메모리/GC 바운드 → CloudWatch Agent로 메모리 사용률 커스텀 지표 발행 + Target Tracking
- 스파이크 → Step Scaling 상방 결합(대폭 증설), 하방은 Target Tracking으로 완만
10) 함께 쓰면 좋은 것들
- ELB Deregistration Delay(연결 드레이닝): 축소/교체시 요청 안전 종료
- Instance Refresh: AMI/구성 변경을 롤링으로 적용
- Mixed Instances Policy: 다양한 Instance Type + On-Demand/Spot 믹스
- Capacity Rebalance: Spot 회수 신호에 사전 보충
11) CloudFormation 스니펫(요약)
Resources:
CpuTargetTracking:
Type: AWS::AutoScaling::ScalingPolicy
Properties:
AutoScalingGroupName: !Ref Asg
PolicyType: TargetTrackingScaling
TargetTrackingConfiguration:
PredefinedMetricSpecification:
PredefinedMetricType: ASGAverageCPUUtilization
TargetValue: 50
DisableScaleIn: false
StepOut:
Type: AWS::AutoScaling::ScalingPolicy
Properties:
AutoScalingGroupName: !Ref Asg
PolicyType: StepScaling
AdjustmentType: PercentChangeInCapacity
EstimatedInstanceWarmup: 120
StepAdjustments:
- MetricIntervalLowerBound: 0
MetricIntervalUpperBound: 10
ScalingAdjustment: 20
- MetricIntervalLowerBound: 10
ScalingAdjustment: 4012) 트러블슈팅 & 함정
- 플래핑(증설↔축소 반복): Warmup/Cooldown 부족, 목표값 과도하게 낮음 → Warmup↑, 목표 상향, DisableScaleIn
- 증설 느림: Warmup이 과도, Step 증설폭 작음 → Step 폭 확대 또는 Desired 최소치 상향
- 지표 부정확: Target Group/리소스 라벨 오입력, 커스텀 지표 누락 → 메트릭 존재/차원 확인
- 예측 실패: Predictive는 패턴이 반복적일 때만 효과적 → 신규 서비스엔 Target+Step로 시작
13) 요약
- 기본값: Target Tracking + 적절한 Warmup
- 스파이크: Step Scaling(상방만)으로 보강
- 예약 수요: Scheduled, 반복 패턴은 Predictive
- 안정성: Deregistration Delay, Instance Refresh, Scale-In Protection 동원
- 지표 선택: ALB RequestCountPerTarget, CPU, SQS/커스텀 등 업무 부하 특성에 맞추기
