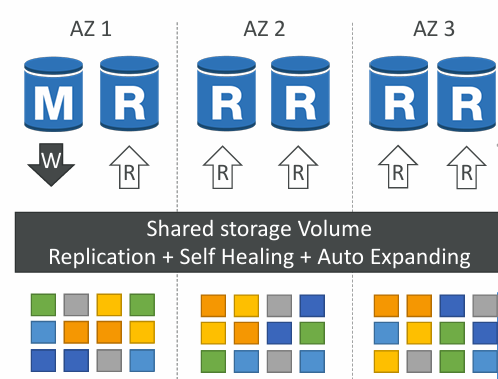
Aurora는 MySQL/PostgreSQL 호환의 고성능·고가용성 관리형 RDB. 분산 스토리지(6중 복제/3AZ), 초고속 장애 조치, 손쉬운 읽기 확장이 핵심
1) 왜 Aurora인가? (핵심 포인트)
-
호환성: Aurora MySQL / Aurora PostgreSQL 두 계열(대부분의 드라이버/툴 그대로 사용)
-
고가용성: 스토리지 6중 복제(3AZ), 인스턴스 장애 시 수십 초 내 자동 Failover
-
확장성: Reader(Replica)를 추가해 읽기 수평 확장(공유 스토리지로 지연 적고 승격 빠름)
-
성능/비용 최적화
- I/O-Optimized 옵션: I/O 요금 대신 고정 단가로 예측 가능한 비용 + 성능
- Serverless v2: 부하에 맞춰 세밀한 자동 스케일(ACU 기반)
-
백업/복구: S3 기반 지속 백업 + PITR, Snapshot 복원
-
보안: KMS 암호화, TLS, VPC/Security Group, IAM DB Auth(MySQL/PG)
숫자 한도(최대 스토리지 용량, 리전별 인스턴스 타입 등)는 엔진/리전에 따라 달라질 수 있음. 최신 콘솔 기준으로 확인
2) 아키텍처 한눈에
Writer(Primary) ──┐
Reader 1 ├── 같은 Cluster 스토리지(6중 복제, 3AZ)
Reader 2 ┘- Compute(인스턴스) 와 Storage 분리: 인스턴스는 스토리지 계층에 Redo/페이지 단위로 접근
- 공유 스토리지 덕분에 Reader 추가/승격(Promote) 이 빠르고 복제지연이 낮음
3) 엔드포인트(연결 방식)
- Cluster Endpoint (Writer): 쓰기/트랜잭션 엔드포인트(항상 현재 Writer 가리킴)
- Reader Endpoint: 연결을 건강한 Reader 들로 자동 분산(읽기 전용)
- Instance Endpoint: 특정 인스턴스로 직접 연결(특수 쿼리/진단용)
- Custom Endpoint: 일부 Reader 서브셋(예: BI용) 으로 트래픽 분리
앱에서 쓰기=Cluster, 읽기=Reader 로 분리하면 확장/장애조치에 강합니다.
4) 확장 & HA 시나리오
- 읽기 확장: Aurora Replicas(Reader) 추가 → Reader Endpoint 사용
- 장애 조치(Failover): Writer 장애 시 가장 적합한 Reader 가 빠르게 승격
- Global Database: 다중 리전에 초저지연 비동기 복제. 재해 발생 시 원격 리전 승격으로 DR 구현
5) 스토리지/성능 옵션
-
Storage (일반/자동 확장): 실제 사용량에 맞춰 자동 확장
-
I/O-Optimized: I/O가 많은 OLTP에 유리(비용 구조 단순화)
-
성능 기능(엔진별)
- Aurora MySQL: Parallel Query, Backtrack(시점 되감기), Lambda 연동(스토어드 프로시저로 호출)
- Aurora PostgreSQL: Logical Replication 등 PG 생태계 기능(확장/FDW 등)
6) Serverless v2 (간단 요약)
- 자동 스케일: 초단위로 부하를 추적해 미세 조정
- 과금: ACU 사용량 기반(아이들 시 비용↓)
- 사용처: 트래픽 변동이 크거나 예측이 어려운 서비스, 개발/QA, 멀티테넌트
7) 백업/복구/배포
- Automated Backups + PITR: 보존 기간 내 원하는 시점으로 Point-in-time Restore
- Snapshot: 장기 보관/리전 간 복사
- Blue/Green Deployments: 새 버전을 별도 클러스터(Green) 로 준비 후 신속 전환(롤백 쉬움)
8) 보안/운영
- 암호화: KMS(At-rest), TLS(In-transit)
- 접근 제어: VPC, Security Group 최소 허용, IAM DB Auth(패스워드 없는 접속)
- 비밀 관리: Secrets Manager로 DB 크리덴셜 순환
- 관측/튜닝: Performance Insights, CloudWatch, Slow Query/로그 내보내기
9) RDS vs Aurora (빠른 비교)
| 항목 | RDS(표준) | Aurora |
|---|---|---|
| 스토리지 | 인스턴스별 | 클러스터 공유(6중 복제) |
| Failover | 수십 초~수분 | 수십 초급 |
| 읽기 확장 | Read Replica(비동기) | Aurora Replica(공유 스토리지, 승격 빠름) |
| Serverless | 일부 엔진 없음 | Serverless v2 |
| 비용 최적화 | gp3/IOPS 조정 | I/O-Optimized, Serverless v2 |
10) 설계 베스트 프랙티스
- 커넥션 분리: Writer=Cluster, Reader=Reader Endpoint
- 장애조치 리허설: 정기적으로 Failover 테스트(클라이언트 재시도 로직 포함)
- 긴 트랜잭션 회피: Failover/백업 지연 원인 → 배치/락 전략 조정
- 파라미터 그룹: 엔진별 튜닝(innodb, autovacuum 등) 별도 Cluster/Instance Parameter Group 관리
- 캐시/큐와 협업: 앱단 캐시(ElastiCache), 큐(SQS) 로 급변 부하 흡수
- 데이터 이동: DMS/SCT로 마이그레이션, S3 import/export(엔진 옵션)
11) 트러블슈팅 체크
- 읽기 느림/편향: Reader 수 증설, Reader Endpoint 사용, BI용 Custom Endpoint 분리
- Failover 잦음: 인스턴스/네트워크/스토리지 경보 확인, 장시간 트랜잭션/락 점검
- CPU/I/O 병목: 인스턴스 클래스 상향, I/O-Optimized 고려, 쿼리/인덱스 튜닝
- 복제 지연: 대용량 쓰기/DDL 시 계획적 윈도우, 리더 전용 작업 분리
12) 생성/운영(CLI 예시)
# 1) 클러스터 생성 (Aurora MySQL 예)
aws rds create-db-cluster \
--db-cluster-identifier aurora-mysql-cluster \
--engine aurora-mysql \
--master-username admin --master-user-password '*****' \
--vpc-security-group-ids sg-xxxx \
--db-subnet-group-name my-aurora-subnet \
--backup-retention-period 7
# 2) Writer 인스턴스 추가
aws rds create-db-instance \
--db-instance-identifier aurora-mysql-writer \
--db-instance-class db.r6g.large \
--engine aurora-mysql \
--db-cluster-identifier aurora-mysql-cluster
# 3) Reader 인스턴스 추가
aws rds create-db-instance \
--db-instance-identifier aurora-mysql-reader-1 \
--db-instance-class db.r6g.large \
--engine aurora-mysql \
--db-cluster-identifier aurora-mysql-cluster \
--promotion-tier 15
# 4) 강제 Failover(테스트)
aws rds failover-db-cluster --db-cluster-identifier aurora-mysql-cluster13) 시험 포인트(암기)
- 공유 스토리지(6중 복제, 3AZ), Reader 확장, 빠른 Failover
- Endpoints: Cluster/Writer/Reader/Custom 차이
- Global Database: 다중 리전 DR/저지연 읽기
- Serverless v2 & I/O-Optimized: 비용/탄력성 옵션
- Backtrack(Aurora MySQL), Parallel Query(Aurora MySQL)
요약
- Aurora = 고가용성·확장성에 최적화된 MySQL/PG 호환 DB
- Writer/Reader 분리 + Reader Endpoint 로 쉽게 수평 확장
- Serverless v2 & I/O-Optimized 로 비용과 성능을 동시에 잡기
- Global Database 로 리전 DR/글로벌 읽기까지 깔끔하게 확장

`•.¸¸.•´´¯`••._.• 🎀 𝒸𝓇𝒶𝓏𝓎 𝓅𝓈𝓎𝒸𝒽💞𝓅𝒶𝓉𝒽 🎀 •._.••`¯´´•.¸¸.•`