해당 포스팅은 인프런에서 제공하는 김영한 님의 '자바 ORM 표준 JPA 프로그래밍 - 기본편'을 수강한 후 정리한 글입니다. 유료 강의를 정리한 내용이기에 제공되는 예제나 몇몇 내용들은 제외하였고, 정리한 내용을 바탕으로 글 작성자인 저의 언어로 다시 작성한 글이기에 서술이 부족하거나 잘못된 내용이 있을 수 있습니다. 그렇기에 해당 글은 개념에 대한 참고 정도만 해주시고, 강의를 통해 학습하시기를 추천합니다.
영속성 컨텍스트(Persistence)
JPA는 어플리케이션과 데이터 베이스 사이에서 영속성 컨텍스트라는 개념을 두고 데이터를 관리한다. 영속성 컨텍스트는 JPA를 이해하기 위해 가장 중요한 개념이며, "엔티티를 영구 저장하는 환경"이라는 뜻을 가지고 있다.
엔티티 매니저
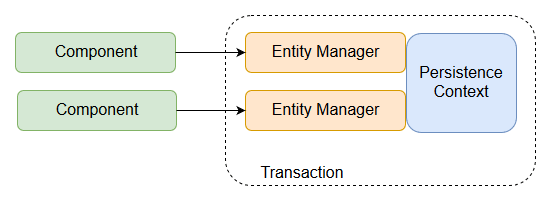
영속성 컨텍스트는 논리적인 개념으로 엔티티 매니저(Entity Manager)를 통해 접근할 수 있다. 엔티티 매니저는 엔티티의 저장, 수정, 삭제, 조회 등 엔티티와 관련된 모든 작업을 처리하는 관리자이며, 마치 엔티티를 저장하는 가상의 데이터베이스와 같다.
엔티티 매니저를 생성하기 위해서는 엔티티 매니저 팩토리(EntityManagerFactory)가 필요한데, 이를 생성하기 위해 드는 비용이 상당히 크다. 때문에 한 개의 엔티티 매니저 팩토리만을 생성해 어플리케이션 전체에서 공유되도록 설계되어 있다.
반면 엔티티 매니저를 생성하는 비용은 거의 들지 않는다. 다만 엔티티 매니저 팩토리가 여러 스레드에서 동시에 접근해도 안전한 반면, 엔티티 매니저는 동시성 문제가 발생할 수 있기에 스레드 간 공유되어서는 안된다.
J2SE 환경에서 엔티티 매니저와 영속성 컨텍스트는 1:1 관계를 가지며, J2EE나 스프링 프레임워크와 같은 컨테이너 환경에서는 N:1의 관계를 가진다.
엔티티의 생명주기
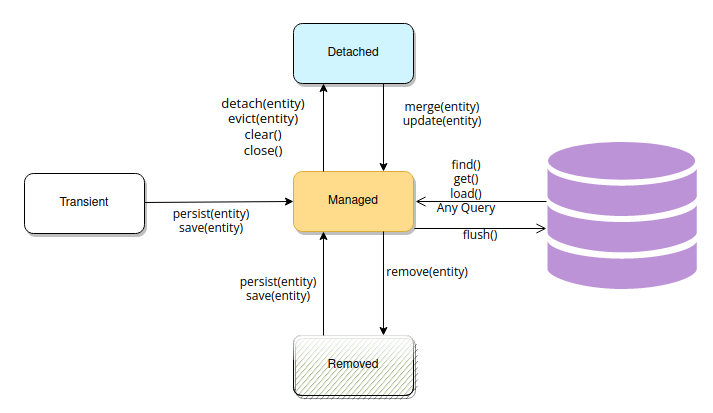
엔티티 객체는 비영속(new/transient), 영속(managed), 준영속(detached), 삭제(removed)의 생명주기를 갖는다.
비영속(removed)
영속성 컨텍스트와 전혀 관계 없는 새로운 상태로, 객체를 생성한 상태이다.
Sample sample = new Sample();
sample.setName("persistence sample");영속(managed)
영속성 컨텍스트에 관리되는 상태로 persist()를 통해 객체를 저장하여 관리한다.
엔티티매니저.getTransaction().begin();
엔티티매니저.persist(sample);준영속(detached)
영속성 컨텍스트에 저장되었던 객체가 분리된 상태를 말한다.
엔티티매니저.detach(sample);엔티티매니저.clear()를 통해 영속성 컨텍스트를 완전히 초기화 하거나, 엔티티매니저.close()를 통해 영속성 컨텍스트를 종료함으로 준영속 상태로 만들 수도 있다.
준영속 상태는 거의 비영속 상태에 가깝다. 영속성 컨텍스트가 관리하지 않으므로 1차 캐시, 쓰기 지연, 변경 감지, 지연 로딩 등 영속성 컨텍스트가 제공하는 어떠한 기능도 동작하지 않는다. 하지만 이미 한 번 영속 상태를 거쳤기 때문에 식별자 값을 반드시 가지고 있다.
삭제(removed)
영속성 컨텍스트로 부터 삭제된 상태를 말한다.
엔티티매니저.remove(sample);영속성 컨텍스트의 특징
식별자 값
영속성 컨텍스트는 엔티티를 식별자 값(@Id, 테이블의 PK와 매핑)로 구분한다. 그렇기에 영속 상태의 객체는 식별자 값이 반드시 있어야 한다. 식별자가 없다면 예외가 발생하게 된다.
데이터베이스 저장
영속성 컨텍스트에 저장된 엔티티는 보통 트랜잭션을 커밋하는 순간 데이터베이스에 반영하며, 이를 플러시(flush)라고 한다.
변경 감지(Dirty Cehcking)
영속성 컨텍스트를 통해 얻을 수 있는 이점은 이전 섹션인 JPA 톺아보기 - 기본 개념에서 서술한 1차 캐시, 동일성(identity) 보장, 트랜잭션을 지원하는 쓰기 지연(transactional write-behind), 지연 로딩(Lazy Loading) 외에도 변경 감지(Dirty Checking)가 있다.
영속성 컨텍스트는 트랜잭션이 끝나는 시점에 최초 조회 기준으로 변화가 있는 모든 엔티티 객체를 데이터 베이스에 자동으로 반영해준다.
트랜잭션.begin();
Sample findSample = 엔티티매니저.find(Sample.class, 1L);
findSample.setName("updated sample"); // 트랜잭션 시점에 자동 반영
트랜잭션.commit();플러시(Flush)
플러시란 영속성 컨텍스트의 변경 내용을 DB에 반영하는 것을 의미한다. 기본적으로 트랜잭션을 커밋할 때 동작하며, 쓰기 지연 저장소에 저장되어있던 변경 내용(INSERT, UPDATE, DELETE)이 DB에 동기화된다. 플러시 실행시의 프로세스는 다음과 같다.
1. 변경 감지 동작, 영속성 컨텍스트 내에 모든 엔티티를 스냅샷과 비교하여 수정된 엔티티를 찾는다.
2. 수정된 엔티티에 대한 수정 쿼리를 작성하여 쓰기지연 SQL 저장소에 등록한다.
3. 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송한다.(등록, 수정, 삭제)
플러시는 JPQL 쿼리 실행 직전에도 동작하며, 엔티티매니저.flush()를 통해 직접 호출도 가능하다.
플러시가 동작한다고 영속성 컨텍스트가 비워지지는 않는다. 영속성 컨텍스트의 변경 내용을 DB에 동기화할 뿐이다. 또한 모든 동작은 트랜잭션 안에서 이루어져야 한다.
플러시 모드 옵션
엔티티매니저.setFlushMode(FlushModeType.옵션)을 통해 플러시 모드 옵션을 지정해 줄 수 있다.
FlushModeType.AUTO: 커밋이나 쿼리를 실행할 때 플러시(default)FlushModeType.COMMIT: 커밋할 때만 플러시
엔티티 매핑
객체와 테이블 매핑
@Entity
@Entity가 붙은 클래스는 JPA가 관리하며, 엔티티라고 한다. JPA를 사용하여 테이블과 매핑하기 위해서는 클래스에 @Entity 어노테이션이 필수로 있어야 한다.
@Entity를 사용하기 위해서는 public이나 protected로 선언된 기본 생성자가 필수이며, name 속성을 사용하여 JPA에서 사용할 엔티티의 이름을 지정해줄 수 있다. 기본값이 클래스의 이름을 그대로 사용하기에 같은 클래스 이름이 존재하지 않는다면 가급적 기본값을 사용해준다.
@Table
엔티티와 매핑할 테이블을 지정할 때 사용된다.
name: 매핑할 테이블 이름을 지정, 기본값은 엔티티 이름을 사용한다.catalog: 데이터베이스 catalog 매핑schema: 데이터베이스 schema 매핑uniqueConstraints: DDL 생성 시 유니크 제약 조건 생성
데이터 베이스 스키마 자동 생성
ddl-auto 옵션을 통해 어플리케이션 실행 시점에 데이터 베이스 스키마를 자동으로 생성해줄 수 있다. ddl-auto 옵션 사용시 테이블 중심에서 객체 중심의 개발이 가능해지며, DB 변경시 해당 DB의 데이터 방언을 사용해 적절한 생성이 가능하다는 장점이 있지만, 운영 서버에서 사용할 경우 기존 테이블이 drop되는 등의 재앙이 발생할 수 있기 때문에 개발 장비에서만 사용하는 것이 좋다.
다음은 ddl-auto 옵션의 속성들이다.
- create : 기존 테이블 삭제 후 다시 생성(drop & create)
- create-drop : create와 같으나 어플리케이션 종료 시점에 테이블을 drop
- update : 변경된 부분만 반영
- validate : 엔티티와 테이블이 정상 매핑되었는지 여부만 확인
- none : 사용하지 않음
DDL 생성 기능
ddl-auto 옵션을 사용해서 ddl을 생성해줄 때 엔티티에 제약 조건을 설정해줄 수 있다.
- 컬럼별 제약 조건 추가 : ex -
@Column(nullable = false, length = 10) - 유니크 제약 조건 추가 : ex =
@Table(uniqueConstraints = {@UniqueConstraint(name = "NAME_AGE_UNIQUE", columnNames = {"NAME", "AGE"})})
필드와 컬럼 매핑
매핑 어노테이션 정리
@Column: 컬럼 매핑@Temporal: 날짜 타입 매핑@Enumerated: Eunm 타입 매핑@Lob: BLOB, CLOB 매핑@Transient: 특정 필드를 컬럼에 매핑하지 않을 때 사용
@Column
| 속성 | 설명 | 기본값 |
|---|---|---|
| name | 필드와 매핑할 테이블의 컬럼명 | 객체의 필드명 |
| insertable, updatable | 등록, 변경 가능 여부 | true |
| nullalble(DDL) | null 값의 허용 여부. false로 설정하면 DDL 생성 시 not null 제약 조건 | |
| unique(DDL) | @Table의 uniqueConstraints와 동일 | |
| columnDefinition(DDL) | 데이터 베이스 컬럼 정보를 직접 입력 가능 ex) varchar(100) default 'EMPTY' | 필드의 Java 타입과 방언 정보 사용 |
| length(DDL) | 문자 길이 제약 조건, String 타입에만 적용 | 255 |
| precision, scale(DDL) | BigDecimal 타입에서 사용(& BigInteger). precision은 소수점을 포함한 전체 자릿수를, scale은 소수의 자릿수를 지정. double, float 타입에는 적용되지 않으며, 아주 큰 수나 정밀한 소수를 다룰 때 사용 | precision=19, scale=2 |
@Temporal
날짜 타입(java.util.Date, java.util.Calendar)을 매핑할 때 사용딘다. 최신 하이버네이트는 LocalDate와 LocalDateTime을 지원해주며, 이 때 해당 어노테이션은 생략 가능하다.
value
TemporalType.DATE: 날짜, 데이터베이스 date 타입과 매핑TemporalType.TIME: 시간, 데이터베이스 time 타입과 매핑TemporalType.TIMESTAMP: 날짜와 시간, 데이터베이스 timestamp 타입과 매핑
@Enumerated
Java의 Enum 타입을 매핑할 때 사용
value
EnumType.ORDINAL: enum 순서를 데이터 베이스에 저장EnumType.STRING: enum의 이름을 데이터 베이스에 저장
기본값은 ORDINAL이지만, enum의 순서는 언제든 변할 수 있기 때문에 사용을 지양해야한다. STRING을 통해 이름을 저장하는 것이 좋다.
@Lob
데이터 베이스의 BLOB, CLOB 타입과 매핑할 때 사용 @Lob에는 지정할 수 있는 속성이 존재하지 않으며, 매핑하는 필드 타입이 문자면 CLOB, 나머지는 BLOB으로 매핑된다.
@Transient
필드 매핑에서 제외할 변수에 선언해줄 경우 데이터 베이스에 저장, 조회가 이루어지지 않는다. 주로 메모리상 임시 값을 보관하고 싶을 때 사용된다.
기본 키 매핑
@Id를 통해 기본 키(PK)를 지정해줄 수 있으며, @GeneratedValue를 통해 해당 키의 자동 생성 전략을 지정해줄 수 있다.
@GeneratedValue 속성
IDENTITY: 데이터 베이스에 위임. MySQLSEQUENCE: 데이터 베이스 스퀀스 오브젝트 사용, ORACLE,@SequenceGenerator필요TABLE: 키 생성용 테이블 사용. 모든 DB에서 사용 가능,@TableGEnerator필요AUTO: 방언에 따라 자동 지정, 기본값
IDENTITY 전략
기본 키 생성을 DB에 위임한다. 주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용된다.(ex - MySQL의 AUTO_INCREMENT)
JPA는 보통 트랜잭션 커밋 시점에 INSERT_SQL을 실행하지만 AUTO_INCREMENT는 데이터 베이스에 INSERT SQL을 실행한 후에야 ID 값을 알 수 있다. 때문에 IDENTIY 전략을 사용하면 엔티티매니저.persist() 시점에 즉시 INSERT SQL을 실행하여 DB에서 ID 식별자를 조회해온다.
SEQUENCE 전략
데이터 베이스 시퀀스는 유일한 값을 순서대로 생성하는 특별한 DB 오브젝트이며(ex - 오라클 시퀀스), 오라클, PostgreSQL, DB2, H2 데이터 베이스에서 사용된다.
@SequenceGenerator 속성
name: 식별자 생성기 이름. 필수 입력값sequenceName: 데이터 베이스에 등록되어 있는 시퀀스 이름 지정. 기본값 = hibernate_sequenceinitialValue: DDL 생성 시에만 사용되며, 시퀀스 DDL을 생성할 때 처음 시작하는 수를 지정. 기본값 = 1allocationSize: 시퀀스를 호출할 때 증가하는 수로 성능 최적화에 사용된다. DB의 시퀀스 값이 1이라면 이 값 또한 1로 설정해야 한다. 기본값 = 50catalog,schema: 데이터 베이스 catalog, schema 이름
TABLE 전략
키 생성 전용 테이블을 생성하여 데이터 베이스 시퀀스를 흉내내는 전략으로 모든 데이터 베이스에 적용 가능하다는 장점이 있지만, 성능이 떨어진다는 단점도 존재한다.
@TableGenerator 속성
name: 식별자 생성기의 이름. 필수 입력 값table: 키 생성 테이블명. 기본값 = hibernate_sequencepkColumnName: 시퀀스 컬럼명. 기본값 = sequence_namevalueColumnName: 시퀀스 값 컬럼명. 기본값 = next_valpkColumnValue: 키로 사용할 값 이름. 기본값 = 엔티티명initialValue: 초기 값. 마지막으로 생성된 값이 기준. 기본값 = 0allocationSize: 시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용). 기본값 = 50catalog,schema: 데이터 베이스 catalog, schema 이름uniqueConstraints- DDL : 유니크 제약 조건을 지정(DDL 생성시)
