SELECT
모든 레코드 반환
select * from table
출력명 변경 (AS)
as {변경값}
select animal_name as name from animal_table
중복 제거 (DISTINCT)
select distinct id, name from animal_ins
select count(distinct name) from animal_ins
형 변환 (CAST/CONVERT)
cast(값 as 타입)
convert (값, 타입)
정규 표현식
SELECT IF(SEX_UPON_INTAKE REGEXP 'Neutered|Spayed', 'O' , 'X') AS 중성화
FROM ANIMAL_INS
집계함수
- max / min / sum / avg / count
- null 자동으로 집계 X
- count(*)은 null도 포함하여 집계
select max(datatime) from animal_ins;
SELECT * from food_product where price=(select max(price) from food_product)
반올림
SELECT ROUND(1234.12345, 1) FROM TEST
SELECT ROUND(1234.12345, 4) FROM TEST
SELECT ROUND(1234.12345, -1) FROM TEST
SELECT ROUND(1234.12345, -2) FROM TEST
자릿수 버리기
SELECT TRUNCATE(1234.12345, 1) FROM TEST
SELECT TRUNCATE(1234.12345, 4) FROM TEST
SELECT TRUNCATE(1234.12345, -1) FROM TEST
SELECT TRUNCATE(1234.12345, -2) FROM TEST
문자열 합치기
select concat('010', '-', '0000', '-', '0000') from test
문자열 자르기
select left("thisistest", 5)
- 가운데 자르기
- mid(문자열, 시작, 길이)
- substr(문자열, 시작, 길이)
- substring(문자열, 시작, 길이)
select mid("thisistest", 5, 2)
select substr("thisistest", 5, 2)
select substring("thisistest", 5, 2)
select right("thisistest", 5)
WHERE
기본 연산자
- =, !=, <, >, <=, >=
- is null, is not null
- and / or
- between a and b
- char between num and num 가능!
- (ex. date_format(datetime, '%H') between 9 and 19)
- in (a, b, c, d)
문자열 포함 여부 (LIKE)
- 대소문자 구분함! → 대소문자 구분 안 하고 싶다면 LOWER/UPPER 등 함수 사용할 것!
like '%{문자열}%'
select factory_id from food_factory where address like '%강원도%'
ORDER BY
기본
order by {기준} asc/desc
다중 정렬
order by {column1} asc/desc, {column2} asc/desc, ...
n위 추출 (LIMIT)
order by {정렬 기준} limit {n};
order by {정렬 기준} desc limit 3, 6;
출력값 치환
CASE
- case when {조건1} then {값1}, ... , else {값n} end
case
when out_date is null then '출고미정'
when out_date <='2022-05-01' then '출고완료'
when out_date >'2022-05-01' then '출고대기'
end as '출고여부'
IFNULL
select ifnull(name, '이름 없음') from student;
DATETIME
형식 지정
- DATE_FORMAT(날짜, 형식)
- %Y: 4자리 년도 (1998)
- %y: 2자리 년도 (98)
- %m: 숫자 월 (01~12)
- %c: 숫자 월 (1~12)
- %M: 긴 월 (October)
- %b: 짧은 월 (Oct)
- %W: 긴 요일 (Monday)
- %a: 짧은 요일 (Mon)
- %d: 일자 (01)
- %e: 일자 (1)
- %H: 시간 (24시간)
- %I: 시간 (12시간)
- %i: 분
- %S: 초
date_format(DATETIME, "%Y-%m-%d") as '날짜'
연산
- - : 뺄셈
- datediff(날짜1, 날짜2): 차이
- dateadd(기준, 숫자, 날짜) : 덧셈/뺄셈
order by o.datetime - i.datetime
select datediff('2021-07-12 22:30:00', '2022-08-09 11:30:00')
select dateadd(hour, -1, '2021-07-12 22:30:00')
현재 날짜시간
GROUP BY
- where: 그룹화 전 조건
- having: 그룹화 후 조건
SELECT 컬럼 FROM 테이블 [WHERE 조건식]
GROUP BY 그룹화할 컬럼 [HAVING 조건식] ORDER BY 컬럼1 [, 컬럼2, 컬럼3 ...];
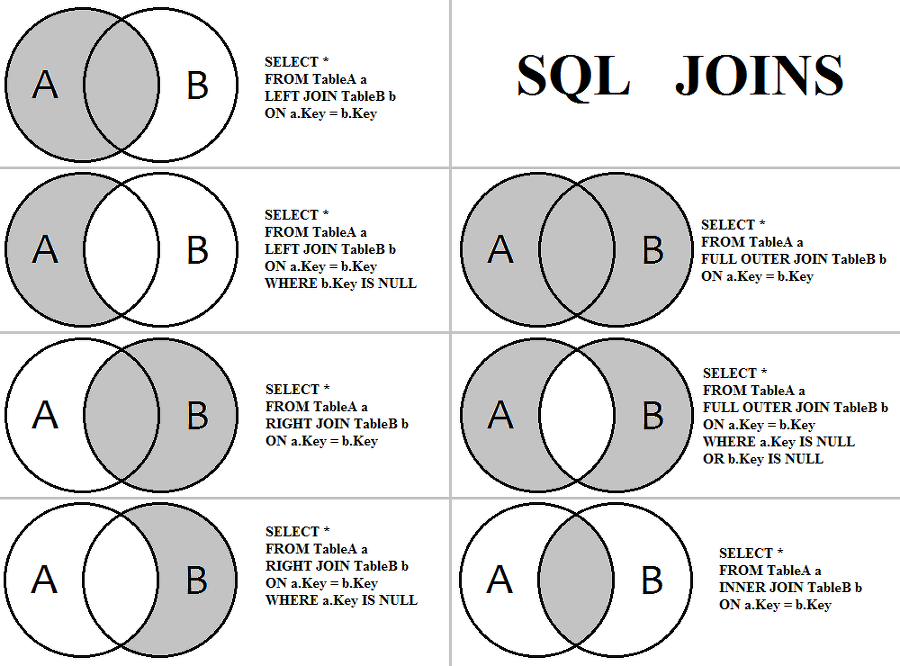
JOIN
기본
SELECT ~~
FROM TABLE_A as A
JOIN TABLE_B as B ON TABLE_A.KEY = TABLE_B.KEY
종류
- left join
- right join
- inner join
- outer join
다중 조인
select *
from a A join b B on A.id=B.id
join c C on A.name=C.name
기타
SELECT A.ANIMAL_ID, A.NAME
FROM ANIMAL_INS A, ANIMAL_OUTS B
WHERE A.ANIMAL_ID = B.ANIMAL_ID
REGEXP
REGEXP
REGEXP_LIKE
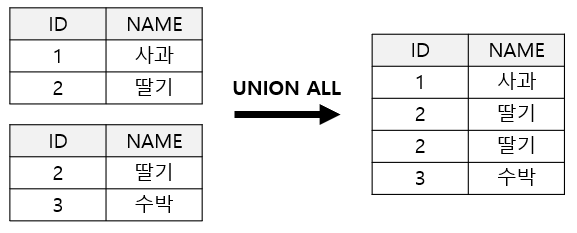
UNION
- union all
select id, name from table1;
union all
select id, name from table2;
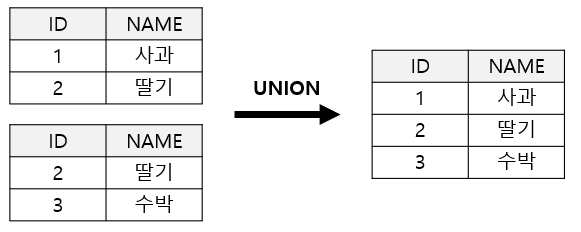
- union
select id, name from table1;
union
select id, name from table2;
ETC
쿼리 실행 순서
- FROM + JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- LIMIT
미지원
- 병렬처리 (ex. oracle-PARALLEL)
- 계층형 쿼리 (ex. Oracle-START WITH/CONNECT BY)
ETC
- 기본적으로 대소문자를 구분하지만 설정 변경 가능
- 서브쿼리에 alias 지정하지 않으면 오류!
- dual = 임시 dummy table
- alias 선언/사용가능한 범위는 쿼리 실행 순서 참고
- (ex. select에 선언한 alias는 where에서 사용불가하고 order by에서는 가능)
