조인 수행 원리
SQL에서 조인이란 두 개 이상의 테이블을 하나의 집합으로 만드는 연산을 뜻합니다. FROM 절에 두 개 이상의 테이블이 나열될 경우 조인이 수행되며, 조인 연산은 두 테이블 사이에서 수행됩니다.
FROM 절에 A, B, C라는 세 개의 테이블이 존재하더라도 세 개의 테이블이 동시에 조인이 수행되는 것은 아니고, 세 개의 테이블 중에서 먼저 두 개의 테이블에 대해 조인이 수행됩니다. 이러한 작업은 FROM 절에 나열된 모든 테이블을 조인할 때까지 반복 수행합니다.
NL Join(Nested Loop Join)
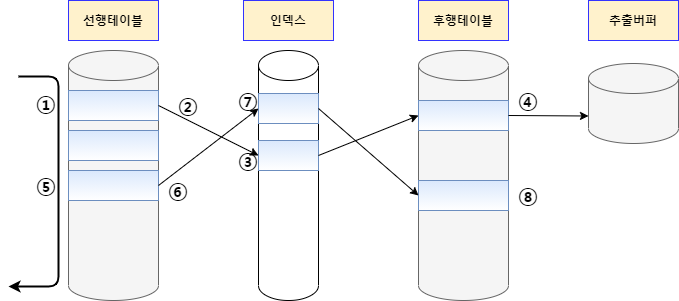
NL Join은 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행합니다. 반복문의 외부에 있는 테이블을 선행 테이블 또는 외부 테이블 (Outer Table)이라고 하고, 반복문의 내부에 있는 테이블을 후행 테이블 또는 내부 테이블(Inner Table)이라고 합니다.
-
선행 테이블에서 조건을 만족하는 첫 번째 행을 스캔
(이 때 선행 테이블에 주어진 조건을 만족하지 않는 경우 해당 데이터는 필터링) -
선행 테이블의 조인 키를 가지고 후행 테이블에 조인키가 존재하는지 스캔
-> 조인 시도 -
후행 테이블의 인덱스에 선행 테이블의 조인 키가 존재하는지 확인
-> 선행 테이블의 조인 값이 후행 테이블에 존재하지 않으면 선행 테이블 데이터는 필터링 (더 이상 조인 작업을 진행할 필요 없음) -
인덱스에서 추출한 레코드 식별자를 이용하여 후행 테이블을 액세스
-> 인덱스 스캔을 통한 테이블 액세스. 후행 테이블에 주어진 조건까지 모두 만족하면 해당 행을 추출버퍼에 넣음
코드예시
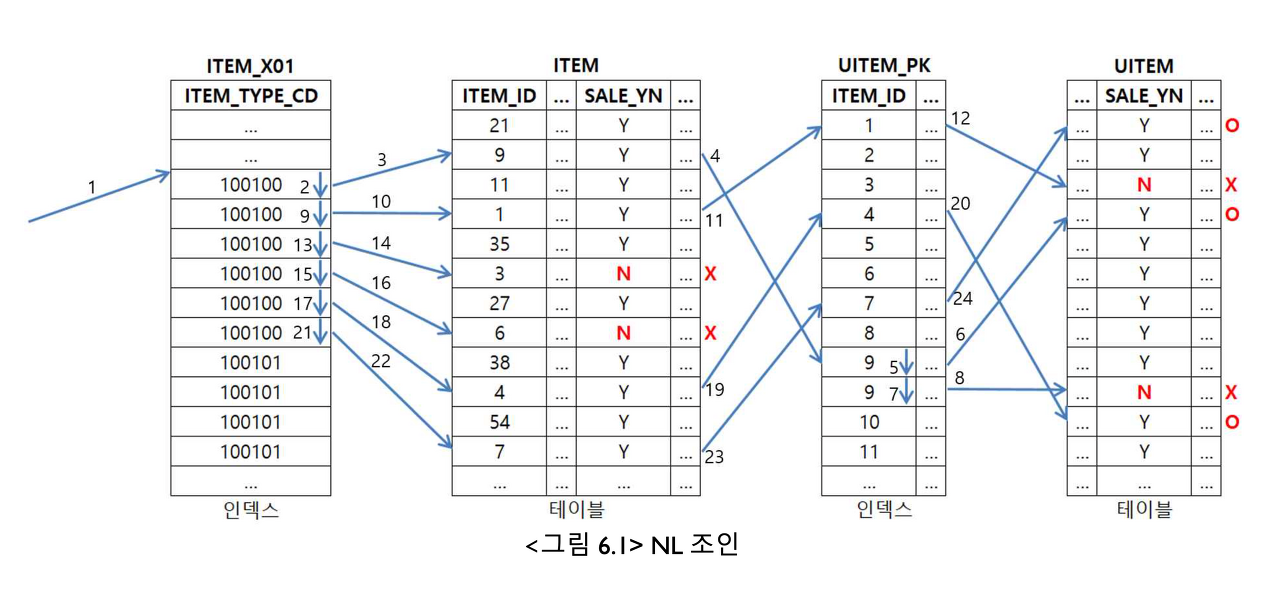
SELECT /*+ USE_NL (B) */
A.*
, B.*
FROM ITEM A, UITEM B
WHERE A.ITEM_ID=B.ITEM_ID --- 1
AND A.ITEM_TYPE_CD = '100100' --- 2
AND A.SALE_YN = 'Y' --- 3
AND B.SALE_YN = 'Y' --- 4
동작순서 : 2 -> 3 -> 1 -> 4
특징
-
절차적이며, 프로그래밍에서 FOR, WHILE문 과 같은 구조로 수행된다.
-
선행테이블은 풀스캔하므로, 선행테이블의 크기가 작을수록 유리하다
(So. 두 테이블의 크기 차이가 있는 경우, 유리하게 사용될 수 있는 방법임) -
후행테이블에 대해서는 반드시 인덱스가 존재해야 NL 조인이 가능하다.
-
인덱스 구성 전략이 특히 중요하다. 조인 컬럼에 대한 인덱스가 있느냐 없느냐, 있다면 컬럼이 어떻게 구성됐느냐에 따라 조인 효율이 크게 달라진다.
-
랜덤 액세스 방식으로 데이터를 읽는다.-> 처리 범위가 좁은 것이 유리하다.
이런 여러가지 특징을 종합할 때, NL 조인은 소량의 데이터를 주로 처리하거나 부분범위처리가 가능한 온라인 트랜잭션 환경에 적합한 조인 방식이라고 할 수 있다.
Sort Merge Join
Sort Merge Join은 조인 컬럼을 기준으로 데이터를 정렬하여 조인을 수행합니다. NL Join은 주로 랜덤 액세스 방식으로 데이터를 읽는 반면 Sort Merge Join은 주로 스캔 방식으로 데이터를 읽습니다. Sort Merge Join은 랜덤 액세스로 NL Join에서 부담이 되던 넓은 범위의 데이터를 처리할 때 이용되던 조인 기법입니다. 그러나 Sort Merge Join은 정렬할 데이터가 많아 메모리에서 모든 정렬 작업을 수행하기 어려운 경우에는 임시 영역(디스크)을 사용하기 때문에 성능이 떨어질 수 있습니다.
일반적으로 대량의 조인 작업에서 정렬 작업을 필요로 하는 Sort Merge Join 보다는 CPU 작업 위주로 처리하는 Hash Join이 성능상 유리합니다. 그러나 Sort Merge Join은 Hash Join 과는 달리 동등 조인뿐만 아니라 비동등 조인에 대해서도 조인 작업이 가능하다는 장점이 있습니다.
-
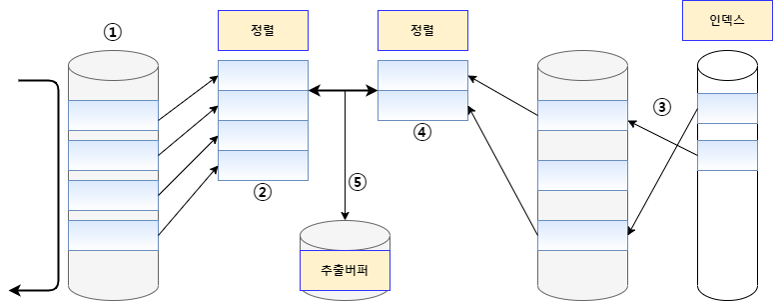
선행 테이블에서 주어진 조건을 만족하는 행을 찾음
-
선행 테이블의 조인 키를 기준으로 정렬작업을 수행
- 1 ~ 2번 작업을 선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
-
후행 테이블에서 주어진 조건을 만족하는 행을 찾음
-
후행 테이블의 조인 키를 기준으로 정렬 작업을 수행
- 3 ~ 4번 작업을 후행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
- 정렬된 결과를 이용하여 조인을 수행하며 조인에 성공하면 추출버퍼에 넣음
코드예시
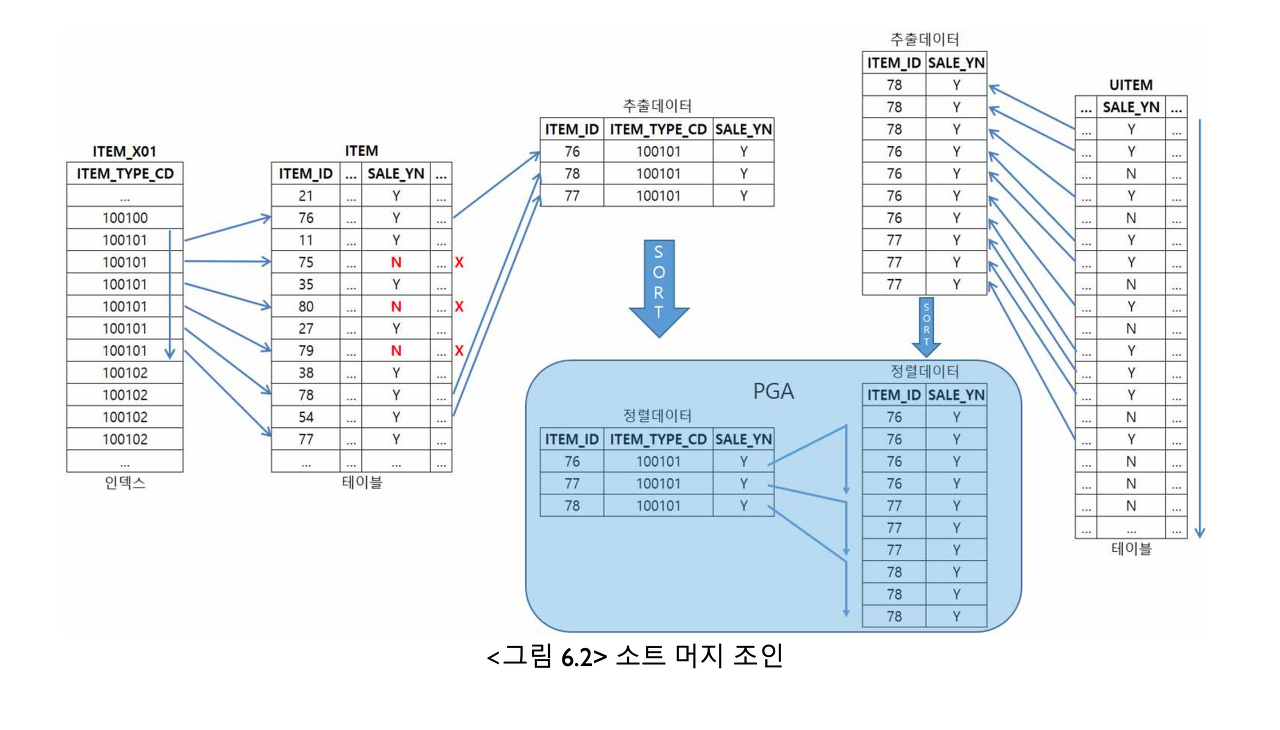
SELECT /*+ ORDERED USE_MERGE(B) */
A.*
, B.*
FROM ITEM A, UITEM B
WHERE A.ITEM_ID=B.ITEM_ID -- 1
AND A.ITEM_TYPE_CD = '100101' -- 2
AND A.SALE_YN = 'Y' -- 3
AND B.SALE_YN = 'Y' -- 4동작 순서 2 -> 3 -> 4 -> 1
특징
-
인덱스가 없어도 가능한 조인법
-
대부분 해시조인인 보다 느린 성능을 보이나, 아래와 같은 상황에서는 소트머지 조인이 유용하다.
- First 테이블에 소트연산을 대체할 인덱스가 있을 때
- 조인할 First 집합이 이미 정렬되어 있을 때
- 조인 조건식이 등차(=)조건이 아닐 때
- 두 테이블의 사이즈가 비슷한경우에 유리하며, 사이즈 차이가 큰 경우에는 불리하고, 비효율적인 방법이다.
Hash Join
Hash Join은 해싱 기법을 이용하여 조인을 수행합니다. 조인될 두 테이블 중 하나를 해시 테이블로 선정하여 조인될 테이블의 조인 키 값을 Hash 알고리즘으로 비교하여 매치되는 결과값을 얻는 방식입니다.
HASH JOIN은 비용 기반 옵티마이저를 사용할 때만 사용될 수 있는 조인 방식이며 '=' 비교를 통한 조인에서만 사용될 수 있습니다. 주로 많은 양의 데이터를 조인해야 하는 경우에 주로 사용됩니다.
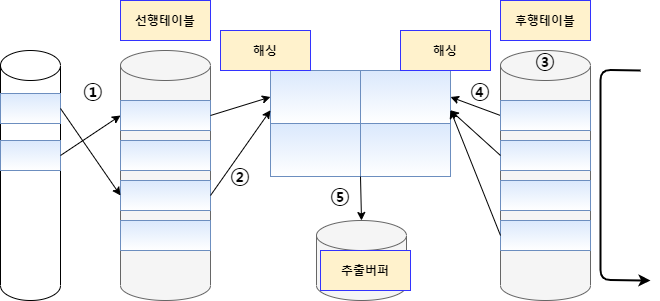
-
선행 테이블에서 주어진 조건을 만족하는 행을 찾음
-
선행 테이블의 조인 키를 기준으로 해시함수를 적용하여 해시 테이블을 생성 -> 조인 컬럼과 SELECT 절에서 필요로 하는 컬럼도 함께 저장
- 1 ~ 2번 작업을 선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
-
후행 테이블에서 주어진 조건을 만족하는 행을 찾음
-
후행 테이블의 조인 키를 기준으로 해시 함수를 적용하여 해당 버킷을 찾음 -> 조인 키를 이용해서 실제 조인될 데이터를 찾음
-
조인에 성공하면 추출버퍼에 넣음
- 3 ~ 5번 작업을 후행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
특징
-
조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우데도 사용할 수 있는 기법이다.
-
메모리 사용이 큰 대용량 테이블 조인시 메모리 외에 임시영역(PGA 메모리)까지 사용하여 저장할 수 있어 유리함
-
해쉬 함수를 이용하여 조인을 수행하기 때문에 '='로 수행하는 조인에서만 사용가능 합니다.
