Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto
1. ch1 용어정리

trial-and-error search 시행착오. 솔루션에 집중적이며, 특정 문제에 특화되있고, 환경이 정확하지 않아도 (knowledge가 적어도) 되는 특성이 있다delayed reward current reward만 영향을 주는것이 아니라 나중의 state, r
2021년 5월 7일
2.Reinforcement Learning 강화학습 개요
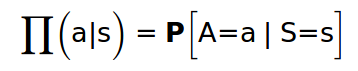
누군가는 강화학습은 학습과정을 게임화시키는 것과 같다고 했다. 이런 말이 나오게된 이유는 뭘까? 강화학습은 시행착오의 과정을 겪기 때문이다. 옳은 action을 취하면 보상을 받고 틀린 action을 취하면 환경에서 페널티를 준다. 한마디로 강화학습은 빨리 받아들이고
2021년 5월 7일
3.ch2 용어정리-1 stochastic이란
이 글은 shorturl.at/dgkpL 와 여러 reference의 내용을 번역, 정리한 글이며 가장 기초적인 개념을 담은 글입니다. 오역, 틀린 내용은 댓글로 부탁드립니다. 내용은 의역하여 정리 하였습니다.\- Stochastic 는 random = probabil
2021년 5월 14일
4.목적함수 손실함수 비용함수 차이
우리가 최소화 최대화 하고 싶어하는 함수를 목적함수라고 한다. 최소화 시킨 함수를 비용함수 (cost function), 손실 함수 (loss function), 또는 오류 함수 (error function)라고 부를 수 있다. 비용함수는 최적화 문제에 쓰이고 손실함수
2021년 5월 14일