Seaborn <계속 update>
데이터
seaborn 내장 데이터 살펴보기
sns.get_dataset_names()seaborn 내장 데이터 불러오기
data = sns.load_dataset('tips')
tips = data # 원본 데이터 저장
print(tip.shape)
tip.head()warning message 보고싶지 않은 경우
import warnings
warnings.filterwarnings('ignore')디자인
팔레트 색상 바꾸기
https://seaborn.pydata.org/generated/seaborn.color_palette.html
여기서 다양한 팔레트 확인 가능
sns.set_palette("Set2")
sns.set_palette("Paired")
sns.set_palette("husl")grid 색상 바꾸기
그리드 배경을 어둡게
sns.set(style='darkgrid')시각화
seaborn 기본 문법 구조
sns.[plot함수명](data = [DataFrame명], x = '[Column명]', y = '[Column명]')한번에 여러 시각화
subplot
plt.figure(figsize = (16, 8)) # 도화지 크기 정하기
plt.subplot(121) # 1행 2열 중 첫번째
sns. ...
plt.title('v1')
plt.subplot(122) # 1행 2열 중 두번째
sns. ...
plt.title('v2')
plt.show()Plot 종류
countplot
주어진 데이터의 카테고리별 빈도를 시각화하는데 사용
데이터가 이산형 변수일때 주로 사용
각 카테고리별 빈도를 막대그래프로 나타냄
sns.countplot(data = tips, x = 'sex') # 카테고리 : sex
plt.show()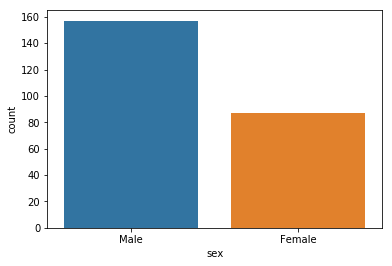
특정 속성을 다른 색상으로 표현하고 싶은 경우
hue 이용
# 시간별로 다르게
sns.countplot(data = tips, x = 'day', hue = 'time')
plt.show()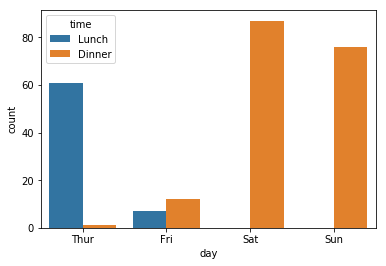
카테고리별 색상 지정하고 싶은 경우
palette = ['색상코드1', ...]
order = ['색상1에 매칭할 카테고리1, ...]
plt.figure(figsize = (5,5))
sns.countplot(data = df, x = 'color', palette = ['#8FBC8B', '#F0E68C', '#FA8072', '#C0C0C0'], order = ['GREEN', 'YELLOW', 'RED', 'GRAY'])countplot 함수 만들기
코드 복붙보다 함수를 쓰는게 효율적이니까
def count_plot(data, x):
plt.figure(figsize = (8, 6))
sns.countplot(data = data, x = x)
plt.show()
# 사용예시
count_plot(tips, 'sex')barplot
주어진 데이터의 평균 또는 다른 집계함수의 값을 시각화
하나의 이산형 변수와 하나의 연속형 변수를 시각화하는데 주로 사용
주어진 카테고리별 평균 값을 막대그래프로 나타냄
plt.figure(figsize = (16,8))
plt.subplot(121)
sns.barplot(data = tips, x = 'size', y = 'tip')
plt.title('tip')
plt.subplot(122)
sns.barplot(data = tips, x = 'size', y = 'total_bill')
plt.title('total_bill')
plt.show()lmplot
선형회귀모델을 시각화
scatter plot을 그린 후 선형회귀모델의 추세선을 함께 그리는 기능
sns.lmplot(data = tips, x = 'total_bill'm y = 'tip_rate', fit_reg = True, order = 1)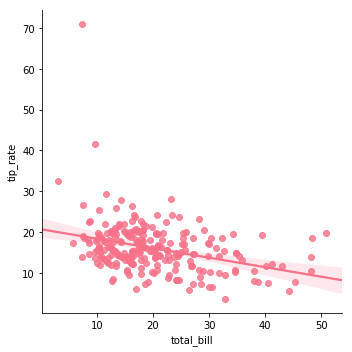
fit_reg : 추세선
order : 회귀모델의 차수 (1차함수, 2차함수 ...)
boxplot
상자수염그림을 시각화
데이터의 분포와 이상치를 파악하는데 유용
plt.figure(figsize = (3,6))
sns.boxplot(data = tips, y = 'tip_rate')
plt.show()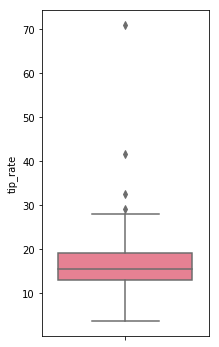


좋은 글 잘 읽었습니다, 감사합니다.